Applying Machine Learning to IOT: End to End Distributed Pipeline for Real-Time Uber Data Using Apache APIs: Kafka, Spark, HBase
4 likes1,089 views

This document discusses using Apache technologies like Kafka, Spark, and HBase to build an end-to-end machine learning pipeline for real-time analysis of Uber trip data. It provides an example of using K-means clustering on streaming Uber trip data to identify geographic patterns and visualize them in a dashboard. The document also provides background on machine learning, streaming data, Spark, and why combining IoT with machine learning is useful for applications like predictive maintenance, smart cities, healthcare, and more.












































![© 2017 MapR Technologies
Spark Distributed Datasets
Dataset
W
Executor
P4
W
Executor
P1 P3
W
Executor
P2
partitioned
Partition 1
8213034705, 95,
2.927373,
jake7870, 0……
Partition 2
8213034705,
115, 2.943484,
Davidbresler2,
1….
Partition 3
8213034705,
100, 2.951285,
gladimacowgirl,
58…
Partition 4
8213034705,
117, 2.998947,
daysrus, 95….
• Read only collection of typed objects
Dataset[T]
• Partitioned across a cluster
• Operated on in parallel
• in memory can be Cached](https://image.slidesharecdn.com/atlantalong-180223154316/85/Applying-Machine-Learning-to-IOT-End-to-End-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-45-320.jpg)

![© 2017 MapR Technologies
Example loading a Dataset
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count Worker
Worker
Worker
Driver
Block 1
Block 2
Block 3](https://image.slidesharecdn.com/atlantalong-180223154316/85/Applying-Machine-Learning-to-IOT-End-to-End-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-47-320.jpg)



![© 2017 MapR Technologies
Example:
Worker
Worker
Worker
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
results
results
results
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count
res9: Long = 829275](https://image.slidesharecdn.com/atlantalong-180223154316/85/Applying-Machine-Learning-to-IOT-End-to-End-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-51-320.jpg)
![© 2017 MapR Technologies
Example
Worker
Worker
Worker
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count
df.show](https://image.slidesharecdn.com/atlantalong-180223154316/85/Applying-Machine-Learning-to-IOT-End-to-End-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-52-320.jpg)

![© 2017 MapR Technologies
Example: Log Mining
Worker
Worker
Worker
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
Driver
Process
from
Cache
Process
from
Cache
Process
from
Cache
Cached, does
not have to read
from file again
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count
df.show](https://image.slidesharecdn.com/atlantalong-180223154316/85/Applying-Machine-Learning-to-IOT-End-to-End-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-54-320.jpg)
![© 2017 MapR Technologies
Example:
Worker
Worker
Worker
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
Driver
results
results
results
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count
df.show](https://image.slidesharecdn.com/atlantalong-180223154316/85/Applying-Machine-Learning-to-IOT-End-to-End-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-55-320.jpg)
![© 2017 MapR Technologies
Example:
Worker
Worker
Worker
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
Driver
Cache your data è Faster Results
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count
df.show](https://image.slidesharecdn.com/atlantalong-180223154316/85/Applying-Machine-Learning-to-IOT-End-to-End-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-56-320.jpg)









![© 2017 MapR Technologies
Dataset
Load data
Load the data into a Dataset
case class Uber(dt: String, lat: Double, lon: Double, base: String) extends Serializable
val schema = StructType(Array(
StructField("dt", TimestampType, true),
StructField("lat", DoubleType, true),
StructField("lon", DoubleType, true),
StructField("base", StringType, true)
))
val df = spark.read.option("inferSchema", "false").schema(schema)
.csv("/user/user01/data/uber.csv") .as[Uber]
df.show](https://image.slidesharecdn.com/atlantalong-180223154316/85/Applying-Machine-Learning-to-IOT-End-to-End-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-67-320.jpg)






![© 2017 MapR Technologies
Data
Frame
Load data transform
Estimator
model.clusterCenters.foreach(println)
[40.76930621976264,-73.96034885367698]
[40.67562793272868,-73.79810579052476]
[40.68848772848041,-73.9634449047477]
[40.78957777777776,-73.14270740740741]
[40.32418330308531,-74.18665245009073]
[40.732808848486286,-74.00150153727878]
[40.75396549974632,-73.57692359208531]
[40.901700842900674,-73.868760398198]
Clusters from fitted model
DataFrame +
Features
fit fitted
model
input](https://image.slidesharecdn.com/atlantalong-180223154316/85/Applying-Machine-Learning-to-IOT-End-to-End-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-74-320.jpg)























![© 2017 MapR Technologies
Create a DStream
DStream: a sequence of RDDs
representing a stream of data
val messagesDStream = KafkaUtils.createDirectStream[String,String]
(ssc, LocationStrategies.PreferConsistent,consumerStrategy)
// get message values from key,value and parse to Uber objects
val uDStream = linesDStream.map(_.value())
batch
time 0 to 1
batch
time 1 to 2
batch
time 2 to 3
dStream
Stored in memory
as an RDD](https://image.slidesharecdn.com/atlantalong-180223154316/85/Applying-Machine-Learning-to-IOT-End-to-End-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-98-320.jpg)


















































Applying Machine Learning to IOT: End to End Distributed Pipeline for Real-Time Uber Data Using Apache APIs: Kafka, Spark, HBase
- 1. © 2017 MapR Technologies Applying Machine Learning to IOT: End to End Distributed Pipeline for Real- Time Uber Data Using Apache APIs: Kafka, Spark, HBase Carol McDonald @caroljmcdonald
- 2. © 2017 MapR Technologies Use Case: Real-Time Analysis of Geographically Clustered Vehicles Uber trip data enrich with K-means Cluster location Stream Topic Stream Topic Spark Streaming Spark Streaming Write to MapR-DB SQL
- 3. © 2017 MapR Technologies Uber trip cluster dashboard
- 4. © 2017 MapR Technologies Data Collect Process Store Spark Streami ng Analyze HBase SQL ML Model Stream Input Spark Streami ng Stream Enriched Use Case: Real-Time Analysis of Geographically Clustered Vehicles
- 5. © 2017 MapR Technologies Fast data Pipeline for Uber Data Using Apache APIs: Kafka, Spark, Hba • Why combine Machine Learning with Streaming Events? • Machine Learning and Spark intro • Kafka & Spark Streaming intro • Spark Streaming and NoSQL Hbase Note: this code example is from me, only the data is from Uber
- 6. © 2017 MapR Technologies Why combine Streaming events with Machine Learning?
- 7. © 2017 MapR Technologies Why IOT? Lots of Things are Producing Streaming Data Data Collection Devices Smart Machinery Phones and Tablets Home Automation RFID Systems Digital Signage Security Systems Medical Devices
- 8. © 2017 MapR Technologies What’s a Stream ? Producers ConsumersEvents_Stream an unbounded sequence of events Events
- 9. © 2017 MapR Technologies Why Stream Processing? 6:05 P.M.: 90° To pic Stream Temperature Turn on the air conditioning! It’s becoming important to process events as they arrive
- 10. © 2017 MapR Technologies Why combine Streaming Events with Machine Learning? Fraud detection Smart Machinery Utility Smart Meters Home Automation Networks Manufacturing Security Systems Patient Monitoring
- 11. © 2017 MapR Technologies Why combine IOT with Machine Learning? • Audi and Daimler deep learning for autonomous vehicles – Using MapR platform to scale deep learning efforts https://mapr.com/company/press-releases/norcom-selects-mapr-deep- learning/
- 12. © 2017 MapR Technologies Why combine IOT with Machine Learning? • sensors and machine learning smart medicine – https://www.wsj.com/articles/the-smart-medicine-solution-to-the-health-care- crisis-1499443449
- 13. © 2017 MapR Technologies Why combine IOT with Machine Learning? • A Stanford team has shown that a machine-learning model can identify heart arrhythmias from an electrocardiogram (ECG) better than an expert – https://www.technologyreview.com/s/608234/the-machines-are-getting-ready-to-play-doctor/
- 14. © 2017 MapR Technologies Applying Machine Learning to Live Patient Data • https://www.slideshare.net/caroljmcdonald/applying-machine-learning-to- live-patient-data
- 15. © 2017 MapR Technologies Why combine IOT with Machine Learning? • Connected care ensuring quicker Sepsis treatment: – Blood pressures, pulse rates and oxygen levels from monitoring devices combined with algorithms to automatically calculate a score, and provide alerts – http://www.computerweekly.com/news/450422258/Putting-sepsis-algorithms-into-electronic- patient-records
- 16. © 2017 MapR Technologies Why combine IOT with Machine Learning? • Location and behavior patterns within cities – Optimize traffic… • http://www.cisco.com/c/en/us/solutions/ industries/smart-connected-communities.html
- 17. © 2017 MapR Technologies What if BP had detected problems before the oil hit the water ? • 1M samples/sec • High performance at scale is necessary!
- 18. © 2017 MapR Technologies Why combine IOT with Machine Learning? • Uber Near Realtime Price Surging – https://www.slideshare.net/ConfluentInc/kafka-uber- the-worlds-realtime-transit-infrastructure-aaron- schildkrout • machine learning & geolocation data: – identify patterns and trends: – telecom, travel, marketing... NEAR REALTIME PRICE SURGING
- 19. © 2017 MapR Technologies What has changed in the past 10 years? Distributed computing Streaming analytics Improved machine learning
- 20. © 2017 MapR Technologies Intro to Machine Learning
- 21. © 2017 MapR Technologies What is Machine Learning? Data Build ModelTrain Algorithm Finds patterns New Data Use Model (prediction function) Predictions Contains patterns Recognizes patterns
- 22. © 2017 MapR Technologies ML Discovery Model Building Model Training/ Building Training Set Test Model Predictions Test Set Evaluate Results Historical Data Deployed Model Insights Data Discovery, Model Creation Production Feature Extraction Feature Extraction ● Churn Modelling Uber trips Stream TopicUber trips New Data
- 23. © 2017 MapR Technologies End to End Application Architecture
- 24. © 2017 MapR Technologies Machine Learning Logistics Input Data + Actual Delay Input Data + Predictions Consumer withML Model 2 Consumer withML Model 1 Decoy results Consumer Consumer withML Model 3 Consumer Stream Archive Stream Scores Stream Input SQL SQL Real time Data Stream Input Delayed data Input Data + Predictions + Actual Delay Real Time dashboard + Historical Analysis
- 25. © 2017 MapR Technologies What is Supervised Machine Learning? Supervised • Classification – Naïve Bayes – SVM – Random Decision Forests • Regression – Linear – Logistic Machine Learning Unsupervised • Clustering – K-means • Dimensionality reduction – Principal Component Analysis – SVD
- 26. © 2017 MapR Technologies Supervised Algorithms use labeled data Data features Build Model New Data features Predict Use Model X1, X2 Y f(X1, X2) =Y X1, X2 Y
- 27. © 2017 MapR Technologies Supervised Machine Learning: Classification & Regression Classification Identifies category for item
- 28. © 2017 MapR Technologies Classification: Definition Form of ML that: • Identifies which category an item belongs to • Uses supervised learning algorithms – Data is labeled Sentiment
- 29. © 2017 MapR Technologies If it Walks/Swims/Quacks Like a Duck …… Then It Must Be a Duck swims walks quacks Features: walks quacks swims Features:
- 30. © 2017 MapR Technologies Debit Card Fraud Example • What are we trying to predict? – This is the Label or Target outcome: – Fraud or Not Fraud • What are the “if questions” or properties we can use to predict? – These are the Features: – Is the amount spent today > historical average? – Unusual region for card history ? – Known merchant or not ?
- 31. © 2017 MapR Technologies Decision Tree For Classification • Tree of decisions about features • IF THEN ELSE questions using features at each tree node • Answers branch to child nodes Is the amount spent in 24 hours > average Is the number of states used from > 2 Are there multiple Purchases today from risky merchants? YES NO NoYES Fraud 90% Not Fraud 50% Fraud 90% Not Fraud 30% YES No
- 32. © 2017 MapR Technologies What is Unsupervised Machine Learning? Machine Learning Unsupervised • Clustering – K-means • Dimensionality reduction – Principal Component Analysis – SVD Supervised • Classification – Naïve Bayes – SVM – Random Decision Forests • Regression – Linear – Logistic
- 33. © 2017 MapR Technologies Unsupervised Algorithms use Unlabeled data Customer GroupsBuild ModelTrain Algorithm Finds patterns New Customer Purchase Data Use Model Similar Customer Group Contains patterns Recognizes patterns Customer purchase data
- 34. © 2017 MapR Technologies Unsupervised Machine Learning: Clustering Clustering group news articles into different categories
- 35. © 2017 MapR Technologies Clustering: Definition • Unsupervised learning task • Groups objects into clusters of high similarity
- 36. © 2017 MapR Technologies Clustering: Definition • Unsupervised learning task • Groups objects into clusters of high similarity – Search results grouping – Grouping of customers, patients – Text categorization – recommendations • Anomaly detection: find what’s not similar
- 37. © 2017 MapR Technologies Clustering: Example • Group similar objects
- 38. © 2017 MapR Technologies Clustering: Example • Group similar objects • Use MLlib K-means algorithm 1. Initialize coordinates to center of clusters (centroid) x x x x x
- 39. © 2017 MapR Technologies Clustering: Example • Group similar objects • Use MLlib K-means algorithm 1. Initialize coordinates to center of clusters (centroid) 2. Assign all points to nearest centroid x x x x x
- 40. © 2017 MapR Technologies Clustering: Example • Group similar objects • Use MLlib K-means algorithm 1. Initialize coordinates to center of clusters (centroid) 2. Assign all points to nearest centroid 3. Update centroids to center of points x x x x x
- 41. © 2017 MapR Technologies Clustering: Example • Group similar objects • Use MLlib K-means algorithm 1. Initialize coordinates to center of clusters (centroid) 2. Assign all points to nearest centroid 3. Update centroids to center of points 4. Repeat until conditions met x x x x x
- 42. © 2017 MapR Technologies Spark intro
- 43. © 2017 MapR Technologies Apache Spark Streaming • Task scheduling • Memory Management • Fault recovery • Interacting with storage systems • DataFrame API • Catalyst Optimizer • Processing of live streams • Micro-batching • Machine Learning • Multiple types of ML algorithms • Graph processing • Graph parallel computations Distributed Parallel Cluster computing Programming Framework
- 44. © 2017 MapR Technologies Spark Distributed Computation on Distributed Data Spark Program Data Sources MapR Cluster Result sc=new SparkContext rDD=sc.textfile(“hdfs://…”) rDD.map Driver Program SparkContext Task Worker Nodes Task Task
- 45. © 2017 MapR Technologies Spark Distributed Datasets Dataset W Executor P4 W Executor P1 P3 W Executor P2 partitioned Partition 1 8213034705, 95, 2.927373, jake7870, 0…… Partition 2 8213034705, 115, 2.943484, Davidbresler2, 1…. Partition 3 8213034705, 100, 2.951285, gladimacowgirl, 58… Partition 4 8213034705, 117, 2.998947, daysrus, 95…. • Read only collection of typed objects Dataset[T] • Partitioned across a cluster • Operated on in parallel • in memory can be Cached
- 46. © 2017 MapR Technologies Tolerate Failures W Executor P4 W Executor P1 P3 W Executor P2 W Executor W Executor P1 P3 W Executor P2 P4 Distribute Data Tolerate Failures Distribute Computation
- 47. © 2017 MapR Technologies Example loading a Dataset val df: Dataset[Uber] = spark.read.option("inferSchema", "false").schema(schema).csv(“data/uber.csv").as[Uber] df.cache df.count Worker Worker Worker Driver Block 1 Block 2 Block 3
- 48. © 2017 MapR Technologies Example: Worker Worker Worker Block 1 Block 2 Block 3 Driver tasks tasks tasks
- 49. © 2017 MapR Technologies Example Worker Worker Worker Block 1 Block 2 Block 3 Driver Read HDFS Block Read HDFS Block Read HDFS Block
- 50. © 2017 MapR Technologies Example Worker Worker Worker Block 1 Block 2 Block 3 Driver Cache 1 Cache 2 Cache 3 Process & Cache Data Process & Cache Data Process & Cache Data
- 51. © 2017 MapR Technologies Example: Worker Worker Worker Block 1 Block 2 Block 3 Driver Cache 1 Cache 2 Cache 3 results results results val df: Dataset[Uber] = spark.read.option("inferSchema", "false").schema(schema).csv(“data/uber.csv").as[Uber] df.cache df.count res9: Long = 829275
- 52. © 2017 MapR Technologies Example Worker Worker Worker Block 1 Block 2 Block 3 Driver Cache 1 Cache 2 Cache 3 val df: Dataset[Uber] = spark.read.option("inferSchema", "false").schema(schema).csv(“data/uber.csv").as[Uber] df.cache df.count df.show
- 53. © 2017 MapR Technologies Example Worker Worker Worker Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 tasks tasks tasks Driver
- 54. © 2017 MapR Technologies Example: Log Mining Worker Worker Worker Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 Driver Process from Cache Process from Cache Process from Cache Cached, does not have to read from file again val df: Dataset[Uber] = spark.read.option("inferSchema", "false").schema(schema).csv(“data/uber.csv").as[Uber] df.cache df.count df.show
- 55. © 2017 MapR Technologies Example: Worker Worker Worker Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 Driver results results results val df: Dataset[Uber] = spark.read.option("inferSchema", "false").schema(schema).csv(“data/uber.csv").as[Uber] df.cache df.count df.show
- 56. © 2017 MapR Technologies Example: Worker Worker Worker Block 1 Block 2 Block 3 Cache 1 Cache 2 Cache 3 Driver Cache your data è Faster Results val df: Dataset[Uber] = spark.read.option("inferSchema", "false").schema(schema).csv(“data/uber.csv").as[Uber] df.cache df.count df.show
- 57. © 2017 MapR Technologies Spark Use Cases Iterative Algorithms on large amounts of data Some Algorithms that need iterations • Clustering (K-Means) • Linear Regression • Graph Algorithms (e.g., PageRank) • Alternating Least Squares ALS Some Example Use Cases: • Anomaly detection • Classification • Recommendations
- 58. © 2017 MapR Technologies Cluster Uber Trip Locations
- 59. © 2017 MapR Technologies Part 1: Spark Machine Learning • End to End Application for Monitoring Uber Data using Spark ML • https://mapr.com/blog/monitoring-real-time-uber-data-using-spark-machine- learning-streaming-and-kafka-api-part-1/
- 60. © 2017 MapR Technologies Zeppelin Notebook with Spark Data Engineer Data Scientist
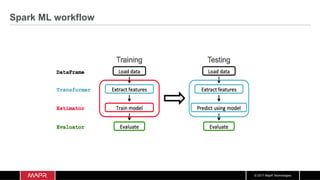
- 61. © 2017 MapR Technologies Spark ML workflow
- 62. © 2017 MapR Technologies Dataset merged with Dataframe • in Spark 2.0, DataFrame APIs merged with Datasets APIs • A Dataset is a collection of typed objects (SQL and functions) • A DataFrame is a Dataset of generic Row objects (SQL)
- 63. © 2017 MapR Technologies Uber Data • Date/Time: The date and time of the Uber pickup • Lat: The latitude of the Uber pickup • Lon: The longitude of the Uber pickup • Base: The TLC base company affiliated with the Uber pickup The Data Records are in CSV format. An example line is shown below: • 2014-08-01 00:00:00,40.729,-73.9422,B02598
- 64. © 2017 MapR Technologies Load the data into a Dataframe: Define the Schema case class Uber(dt: String, lat: Double, lon: Double, base: String) val schema = StructType(Array( StructField("dt", TimestampType, true), StructField("lat", DoubleType, true), StructField("lon", DoubleType, true), StructField("base", StringType, true) )) Input Comma Separated Values: datetime, lattitude, longitude, base 2014-08-01 00:00:00,40.729,-73.9422,B02598
- 65. © 2017 MapR Technologies Data Frame Load data Load the data into a Dataframe val schema = StructType(Array( StructField("dt", TimestampType, true), StructField("lat", DoubleType, true), StructField("lon", DoubleType, true), StructField("base", StringType, true) )) val df = spark.read.option("inferSchema", "false").schema(schema) .csv("/user/user01/data/uber.csv") df.show
- 66. © 2017 MapR Technologies Load the data into a Dataframe Dataframe row columns
- 67. © 2017 MapR Technologies Dataset Load data Load the data into a Dataset case class Uber(dt: String, lat: Double, lon: Double, base: String) extends Serializable val schema = StructType(Array( StructField("dt", TimestampType, true), StructField("lat", DoubleType, true), StructField("lon", DoubleType, true), StructField("base", StringType, true) )) val df = spark.read.option("inferSchema", "false").schema(schema) .csv("/user/user01/data/uber.csv") .as[Uber] df.show
- 68. © 2017 MapR Technologies Load the data into a Dataset Dataset Collection of Uber objects columns row
- 69. © 2017 MapR Technologies Uber Example • What are the “if questions” or properties we can use to group? – These are the Features: – We will group by Lattitude, longitude • Use Spark SQL to analyze: Day of the week, time, rush hour … NEAR REALTIME PRICE SURGING
- 70. © 2017 MapR Technologies Extract the Features Image reference O’Reilly Learning Spark + + ̶+ ̶ ̶ Feature Vectors Model Featurization Training Model Evaluation Best Model Training Data + + ̶+ ̶ ̶ + + ̶+ ̶ ̶ + + ̶+ ̶ ̶ + + ̶+ ̶ ̶ Feature Vectors are vectors of numbers representing the value for each feature
- 71. © 2017 MapR Technologies Use VectorAssembler to put features in vector column val featureCols = Array("lat", "lon") val assembler = new VectorAssembler() .setInputCols(featureCols) .setOutputCol("features") val df2 = assembler.transform(df) Data Frame Load data transform DataFrame + Features
- 72. © 2017 MapR Technologies Data Frame Load data transform Estimator val kmeans = new KMeans() .setK(8) .setFeaturesCol("features") .setMaxIter(5) Create Kmeans Estimator, Set Features DataFrame + Features
- 73. © 2017 MapR Technologies Data Frame Load data transform Estimator val model = kmeans.fit(df2) Fit the Model on the Training Data Features DataFrame + Features fit fitted model input
- 74. © 2017 MapR Technologies Data Frame Load data transform Estimator model.clusterCenters.foreach(println) [40.76930621976264,-73.96034885367698] [40.67562793272868,-73.79810579052476] [40.68848772848041,-73.9634449047477] [40.78957777777776,-73.14270740740741] [40.32418330308531,-74.18665245009073] [40.732808848486286,-74.00150153727878] [40.75396549974632,-73.57692359208531] [40.901700842900674,-73.868760398198] Clusters from fitted model DataFrame + Features fit fitted model input
- 75. © 2017 MapR Technologies fitted model Analyze Clusters summary val clusters = model.summary.predictions clusters.show() prediction DataFrame + Features + prediciton
- 76. © 2017 MapR Technologies fitted model Transform new data, adds column with Clusters transform features val clusters = model.transform(newdata) prediction DataFrame + Features DataFrame + Features + prediciton
- 77. © 2017 MapR Technologies fitted model Save the model to distributed file system save model.write.overwrite().save("/path/savemodel") Use later val sameModel = KMeansModel.load("/user/user01/data/savemodel") DataFrame + Features
- 78. © 2017 MapR Technologies Kafka API and Streaming Data
- 79. © 2017 MapR Technologies Part 2: MapR Event Streams with Kafka API and Spark Streaming • End to End Application for Monitoring Uber Data using Spark ML • https://mapr.com/blog/monitoring-real-time-uber-data-using-spark-machine- learning-streaming-and-kafka-api-part-2/
- 80. © 2017 MapR Technologies Serve DataStore DataCollect Data What Do We Need to Do ? Process DataData Sources ? ? ? ?
- 81. © 2017 MapR Technologies Collect the Data Data IngestSource Stream Topic • Data Ingest: – Network Based: MapR Event Streams using the Kafka API
- 82. © 2017 MapR Technologies Organize Data into Topics with MapR Streams Topics Organize Events into Categories and Decouple Producers from Consumers Consumers MapR Cluster Topic: Pressure Topic: Temperature Topic: Warnings Consumers Consumers Kafka API Kafka API
- 83. © 2017 MapR Technologies Scalable Messaging with MapR Streams Server 1 Partition1: Topic - Pressure Partition1: Topic - Temperature Partition1: Topic - Warning Server 2 Partition2: Topic - Pressure Partition2: Topic - Temperature Partition2: Topic - Warning Server 3 Partition3: Topic - Pressure Partition3: Topic - Temperature Partition3: Topic - Warning Topics are partitioned for throughput and scalability
- 84. © 2017 MapR Technologies Scalable Messaging with MapR Streams Partition1: Topic - Pressure Partition1: Topic - Temperature Partition1: Topic - Warning Partition2: Topic - Pressure Partition2: Topic - Temperature Partition2: Topic - Warning Partition3: Topic - Pressure Partition3: Topic - Temperature Partition3: Topic - Warning Producers are load balanced between partitions Kafka API
- 85. © 2017 MapR Technologies Scalable Messaging with MapR Streams Partition1: Topic - Pressure Partition1: Topic - Temperature Partition1: Topic - Warning Partition2: Topic - Pressure Partition2: Topic - Temperature Partition2: Topic - Warning Partition3: Topic - Pressure Partition3: Topic - Temperature Partition3: Topic - Warning Consumers Consumers Consumers Consumer groups can read in parallel Kafka API
- 86. © 2017 MapR Technologies Partition is like a Queue Consumers MapR Cluster Topic: Admission / Server 1 Topic: Admission / Server 2 Topic: Admission / Server 3 Consumers Consumers Partition 1 New Messages are appended to the end Partition 2 Partition 3 6 5 4 3 2 1 3 2 1 5 4 3 2 1 Producers Producers Producers New Message 6 5 4 3 2 1 Old Message
- 87. © 2017 MapR Technologies Events are delivered in the order they are received, like a queue messages are delivered in the order they are received MapR Cluster 6 5 4 3 2 1 Consumer groupProducers Read cursors Consumer group
- 88. © 2017 MapR Technologies Unlike a queue, events are persisted even after they’re delivered Messages remain on the partition, available to other consumers MapR Cluster (1 Server) Topic: Warning Partition 1 3 2 1 Unread Events Get Unread 3 2 1 Client Library ConsumerPoll
- 89. © 2017 MapR Technologies How do we do this with High Performance at Scale? • Parallel operations • minimizes disk read/writes
- 90. © 2017 MapR Technologies Processing Same Message for Different Purposes Consumers Consumers Consumers Producers Producers Producers MapR-FS Kafka API Kafka API
- 91. © 2017 MapR Technologies Use the Model with Streaming Data
- 92. © 2017 MapR Technologies Collect Data Process the Data with Spark Streaming and Spark Machine Learning Process Data Stream Topic • Extension of the core Spark AP • scalable, high-throughput, fault- tolerant stream processing
- 93. © 2017 MapR Technologies ML Discovery Model Building Model Training/ Building Training Set Test Model Predictions Test Set Evaluate Results Historical Data Deployed Model Insights Data Discovery, Model Creation Production Feature Extraction Feature Extraction Uber trips Stream TopicUber trips New Data
- 94. © 2017 MapR Technologies Use Case: Real-Time Analysis of Geographically Clustered Vehicles Uber trip data enrich with K-means Cluster location Stream Topic Stream Topic Spark Streaming Spark Streaming Write to MapR-DB SQL
- 95. © 2017 MapR Technologies Use Case: Time Series Data Uber trip data Stream Topic 2014-08-01 00:00:00, 40.729,-73.9422,B02598 {"dt":"2014-08-01 00:00:00.0”, "lat":40.3495,"lon":-74.0667, "base":"B02682","cluster":5} Enrich with K-means cluster id Spark Streaming read Stream Topic
- 96. © 2017 MapR Technologies Processing Spark DStreams Data stream divided into batches of X milliseconds = DStreams
- 97. © 2017 MapR Technologies Load the saved model // load model for getting clusters val model = KMeansModel.load(modelpath)
- 98. © 2017 MapR Technologies Create a DStream DStream: a sequence of RDDs representing a stream of data val messagesDStream = KafkaUtils.createDirectStream[String,String] (ssc, LocationStrategies.PreferConsistent,consumerStrategy) // get message values from key,value and parse to Uber objects val uDStream = linesDStream.map(_.value()) batch time 0 to 1 batch time 1 to 2 batch time 2 to 3 dStream Stored in memory as an RDD
- 99. © 2017 MapR Technologies Parse message txt to Uber Object and convert to DataFrame uDStream.foreachRDD{ rdd => // get cluster centers and add to df // send to Topic } ssc.start() ssc.awaitTermination()
- 100. © 2017 MapR Technologies Enrich Data with Cluster
- 101. © 2017 MapR Technologies Convert to JSON send to Topic, Send the Enriched Message
- 102. © 2017 MapR Technologies Process Dstream Streaming Applicaton Output dStream batch time 2 to 3 batch time 1 to 2 batch time 0 to 1 Result Dstream Transformed RDDs map map map Stream Topic
- 103. © 2017 MapR Technologies Real Time Dashboard
- 104. © 2017 MapR Technologies Part 3: Realtime Dashboard using Vert.x • End to End Application for Monitoring Uber Data using Spark ML • https://mapr.com/blog/monitoring-uber-with-spark-streaming-kafka-and- vertx/
- 105. © 2017 MapR Technologies Serve DataCollect Data Serving the Data MapR-FS Process DataData Sources Stream Topic
- 106. © 2017 MapR Technologies Use Case: Real-Time Analysis of Geographically Clustered Vehicles Uber trip data enrich with K-means Cluster location Stream Topic Stream Topic Spark Streaming Spark Streaming Write to MapR-DB SQL
- 107. © 2017 MapR Technologies Use Case Dashboard
- 108. © 2017 MapR Technologies The Vert.x toolkit and Web Application Architecture • Event-driven • Event Bus • Verticles single threaded
- 109. © 2017 MapR Technologies Dashboard Architecture
- 110. © 2017 MapR Technologies Create a Vert.x Service create a Router object, which routes HTTP request URLs to handlers
- 111. © 2017 MapR Technologies Create a Vert.x Service Route paths that match /eventbus/* to be associated with an event bus bridge SockJSHandler
- 112. © 2017 MapR Technologies Create a Vert.x Service create an HttpServer object tell the server to listen on the configured port for incoming requests
- 113. © 2017 MapR Technologies Dashboard Architecture
- 114. © 2017 MapR Technologies Vert.x Service Kafka consumer
- 115. © 2017 MapR Technologies Vert.x Service Kafka consumer Create Kafka Consumer Subscribe to Uber topic
- 116. © 2017 MapR Technologies Vert.x Service Kafka consumer Publish received messages to the Vert.x event bus address “dashboard.”
- 117. © 2017 MapR Technologies The Dashboard Vert.x HTML5 Javascript Client
- 118. © 2017 MapR Technologies Javascript packages
- 119. © 2017 MapR Technologies Initializing the Heatmap
- 120. © 2017 MapR Technologies Dashboard Architecture
- 121. © 2017 MapR Technologies Creating the Vertx EventBus • create an instance of the vertx.EventBus object • add an onopen listener, which registers an event bus handler for the address “dashboard.” • handler will receive all messages published to the “dashboard” address
- 122. © 2017 MapR Technologies Add Event Trip location points to Map
- 123. © 2017 MapR Technologies Add Event Trip location points to Map Parse JSON message
- 124. © 2017 MapR Technologies Add Event Trip location points to Map Add lattitude and longitude points to heatmap
- 125. © 2017 MapR Technologies Add Event Trip location points to Map If cluster center is new then add marker
- 126. © 2017 MapR Technologies Spark and HBase
- 127. © 2017 MapR Technologies Part 4: using MapR-DB with HBase API • https://mapr.com/blog/monitoring-uber-pt4/
- 128. © 2017 MapR Technologies Serve DataStore DataCollect Data What Do We Need to Do ? MapR-FS Process DataData Sources MapR-FS Stream Topic
- 129. © 2017 MapR Technologies Use Case: Real-Time Analysis of Geographically Clustered Vehicles Uber trip data enrich with K-means Cluster location Stream Topic Stream Topic Spark Streaming Spark Streaming Write to MapR-DB SQL
- 130. © 2017 MapR Technologies MapR-DB (HBase API) is Designed to Scale Key Range xxxx xxxx Key Range xxxx xxxx Key Range xxxx xxxx Fast Reads and Writes by Key! Data is automatically partitioned by Key Range! Key colB colC xxx val val xxx val val Key colB colC xxx val val xxx val val Key colB colC xxx val val xxx val val
- 131. © 2017 MapR Technologies Store Lots of Data with NoSQL MapR-DB bottleneck Storage ModelRDBMS MapR-DB Normalized schema à Joins for queries can cause bottleneck De-Normalized schema à Data that is read together is stored together Key colB colC xxx val val xxx val val Key colB colC xxx val val xxx val val Key colB colC xxx val val xxx val val
- 132. © 2017 MapR Technologies HBase Schema With Hbase/MapR-DB data is automatically partitioned by Key Range
- 133. © 2017 MapR Technologies Spark Streaming writing to MapR-DB (HBase API)
- 134. © 2017 MapR Technologies Spark HBase and MapR-DB Binary Connector • HConnection object in every Spark Executor: • allowing for distributed parallel writes, reads, or scans
- 135. © 2017 MapR Technologies Spark Hbase streamBulkPut • HBaseContext streamBulkPut method parameters: • message value DStream, the TableName to write to, function to convert the Dstream values to HBase put records.
- 136. © 2017 MapR Technologies Massively Parrallel writes to HBase The Spark Streaming bulk put enables massively parallel sending of puts to HBase
- 137. © 2017 MapR Technologies HBase Schema To use the Spark HBase Connector for reads, you need to define the Catalog for the schema mapping between the HBase and Spark
- 138. © 2017 MapR Technologies SparkSQL and DataFrames: Define the Schema define the Catalog for the schema mapping between the HBase and Spark
- 139. © 2017 MapR Technologies Loading data from MapR-DB into a Spark DataFrame Use Catalog defining schema
- 140. © 2017 MapR Technologies Spark Dataframes combine filters and select filters rows for cluster ids (the beginning of the row key) >= 9. The select selects a set of columns: key, lat, and lon.
- 141. © 2017 MapR Technologies Use Case: Real-Time Data Pipelines Input Data + Actual Delay Input Data + Predictions Consumer withML Model 2 Consumer withML Model 1 Decoy results Consumer Consumer withML Model 3 Consumer Stream Archive Stream Scores Stream Input SQL SQL Real time Flight Data Stream Input Actual Delay Input Data + Predictions + Actual Delay Real Time dashboard + Historical Analysis
- 142. © 2017 MapR Technologies
- 143. © 2017 MapR Technologies To Learn More: • MapR Free ODT http://learn.mapr.com/
- 144. © 2017 MapR Technologies MapR Blog • https://www.mapr.com/blog/
- 145. © 2017 MapR Technologies MapR Container for Developers • https://maprdocs.mapr.com/home/MapRContainerDevelopers/ MapRContainerDevelopersOverview.html
- 146. © 2017 MapR Technologies …helping you put data technology to work ● Find answers ● Ask technical questions ● Join on-demand training course discussions ● Follow release announcements ● Share and vote on product ideas ● Find Meetup and event listings Connect with fellow Apache Hadoop and Spark professionals community.mapr.com
- 147. © 2017 MapR Technologies Stream Processing Building a Complete Data Architecture MapR File System (MapR-XD) MapR Converged Data Platform MapR Database (MapR-DB) MapR Event Streams Sources/Apps Bulk Processing
- 148. © 2017 MapR Technologies Q&A ENGAGE WITH US