File Service Architecture in Distributed System
Last Updated :
26 Aug, 2024
File service architecture in distributed systems manages and provides access to files across multiple servers or locations. It ensures efficient storage, retrieval, and sharing of files while maintaining consistency, availability, and reliability. By using techniques like replication, caching, and load balancing, it addresses data distribution and access challenges in a scalable and fault-tolerant manner.
 File Service Architecture in Distributed System
File Service Architecture in Distributed SystemImportant Topics for File Service Architecture in Distributed System
Importance of File Service Architecture in Distributed Systems
File service architecture is a fundamental component of distributed systems, enabling efficient and reliable data storage, access, and management across multiple machines. Here are the key reasons for its importance:
- Scalability: File service architectures are designed to scale horizontally, accommodating increasing amounts of data and a growing number of clients without a significant drop in performance.
- Fault Tolerance: By incorporating redundancy and data replication, these architectures ensure data availability and reliability, even in the event of hardware failures or network issues.
- Consistency and Integrity: Advanced file service systems implement consistency models to ensure that all clients have a coherent view of the data, maintaining data integrity across the distributed environment.
- High Availability: Through techniques like load balancing and failover mechanisms, file service architectures provide continuous availability of data, which is crucial for applications that require real-time access and minimal downtime.
- Performance Optimization: By utilizing caching, data partitioning, and efficient access protocols, file service architectures enhance performance, reducing latency and increasing throughput for data-intensive applications.
- Data Management and Organization: These systems provide structured data storage and access, facilitating easy data management and retrieval, which is essential for large-scale applications and big-data analytics.
- Flexibility and Adaptability: They offer flexible storage solutions that can be tailored to various application needs, supporting diverse data types and access patterns, which is crucial for modern, dynamic computing environments.
Core Components of File Service Architecture
- File System Interface:
- Definition: The interface through which users and applications interact with the file system.
- Components: APIs, command-line tools, graphical user interfaces.
- Function: Provides operations like create, read, update, delete (CRUD) files and directories, and metadata management.
- Metadata Service:
- Definition: Manages metadata, which includes information about file locations, permissions, ownership, and timestamps.
- Components: Metadata servers or databases.
- Function: Ensures efficient lookup and management of file attributes and helps in organizing the file structure.
- Data Nodes:
- Definition: The storage units where the actual file data is stored.
- Components: Physical or virtual storage servers, storage arrays.
- Function: Store and retrieve the actual file contents as per requests from clients or metadata servers.
- Name Node:
- Definition: A centralized component that maintains the directory tree of all files and tracks where file data is stored across the data nodes.
- Components: High-availability server or cluster.
- Function: Coordinates the distribution and management of file data, maintaining an index of file metadata.
- Replication Mechanism:
- Definition: Ensures data redundancy and fault tolerance by duplicating data across multiple data nodes.
- Components: Data replication protocols, algorithms.
- Function: Copies data to multiple nodes to prevent data loss in case of hardware failure or corruption.
- Load Balancer:
- Definition: Distributes the workload evenly across data nodes to optimize resource utilization and performance.
- Components: Load balancing algorithms, hardware or software load balancers.
- Function: Manages incoming data requests and ensures that no single data node becomes a bottleneck.
- Caching Layer:
- Definition: Temporarily stores frequently accessed data to reduce access time and improve performance.
- Components: Cache servers, memory caches (e.g., Redis, Memcached).
- Function: Speeds up data retrieval by storing copies of frequently accessed data closer to the client.
- Access Control:
- Definition: Manages authentication and authorization to ensure that only authorized users can access the file system.
- Components: Authentication servers, access control lists (ACLs), role-based access control (RBAC) systems.
- Function: Protects data by enforcing security policies and permissions.
- Data Consistency Mechanism:
- Definition: Ensures that all copies of data across the distributed system are consistent.
- Components: Consistency protocols (e.g., Paxos, Raft), transaction managers.
- Function: Maintains data integrity and consistency across replicas and during concurrent access.
- Fault Tolerance and Recovery:
- Definition: Mechanisms to detect, handle, and recover from hardware or software failures.
- Components: Monitoring tools, automated failover systems, backup and restore services.
- Function: Enhances system reliability by automatically handling failures and ensuring quick recovery.
- Scalability Mechanisms:
- Definition: Techniques to add more resources to handle increasing data and user load.
- Components: Horizontal scaling methods, distributed storage frameworks.
- Function: Ensures the system can grow and handle more data and requests without performance degradation.
- Network Interface:
- Definition: The communication layer that facilitates data transfer between clients and servers.
- Components: Network protocols (e.g., TCP/IP, HTTP), network infrastructure (routers, switches).
- Function: Ensures reliable and efficient data transfer across the distributed system.
File Service Architecture
File Service Architecture is an architecture that provides the facility of file accessing by designing the file service as the following three components:
- A client module
- A flat file service
- A directory service
The implementation of exported interfaces by the client module is carried out by flat-file and directory services on the server side.
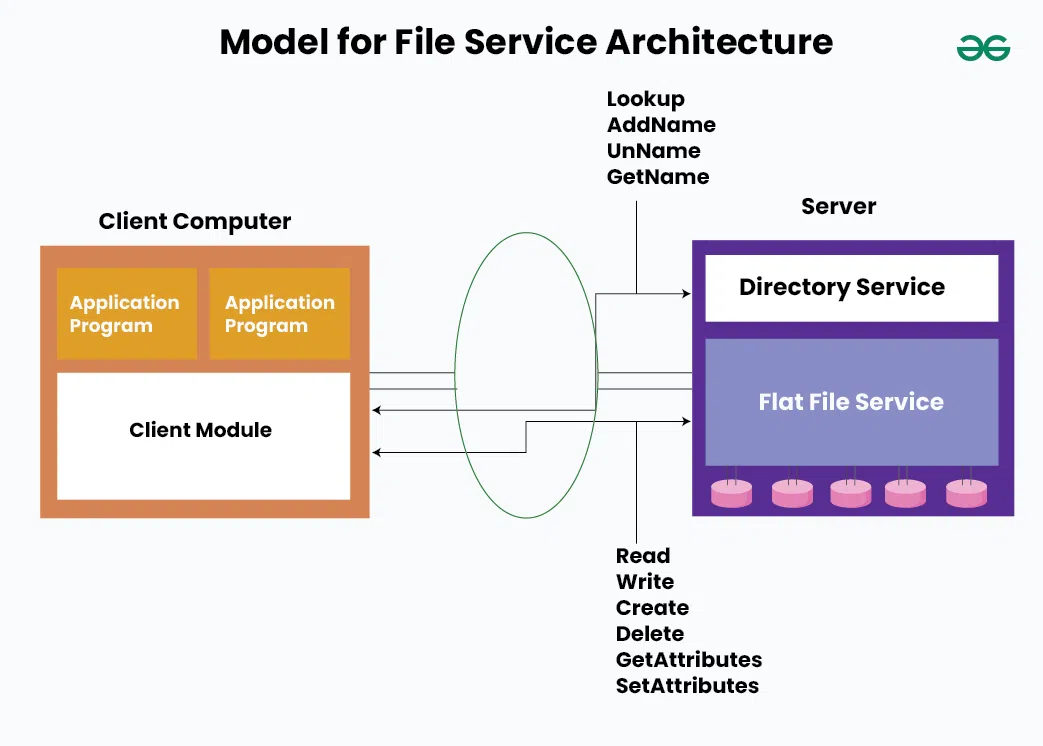 Model for File Service Architecture
Model for File Service ArchitectureLet's discuss the functions of these components in file service architecture in detail.
1. Flat file service
A flat file service is used to perform operations on the contents of a file. The Unique File Identifiers (UFIDs) are associated with each file in this service. For that long sequence of bits is used to uniquely identify each file among all of the available files in the distributed system. When a request is received by the Flat file service for the creation of a new file then it generates a new UFID and returns it to the requester.
Flat File Service Model Operations:
- Read(FileId, i, n) -> Data: Reads up to n items from a file starting at item 'i' and returns it in Data.
- Write(FileId, i, Data): Write a sequence of Data to a file, starting at item I and extending the file if necessary.
- Create() -> FileId: Creates a new file with length 0 and assigns it a UFID.
- Delete(FileId): The file is removed from the file store.
- GetAttributes(FileId) -> Attr: Returns the file's file characteristics.
- SetAttributes(FileId, Attr): Sets the attributes of the file.
2. Directory Service
The directory service serves the purpose of relating file text names with their UFIDs (Unique File Identifiers). The fetching of UFID can be made by providing the text name of the file to the directory service by the client. The directory service provides operations for creating directories and adding new files to existing directories.
Directory Service Model Operations:
- Lookup(Dir, Name) -> FileId : Returns the relevant UFID after finding the text name in the directory. Throws an exception if Name is not found in the directory.
- AddName(Dir, Name, File): Adds(Name, File) to the directory and modifies the file's attribute record if Name is not in the directory. If a name already exists in the directory, an exception is thrown.
- UnName(Dir, Name): If Name is in the directory, the directory entry containing Name is removed. An exception is thrown if the Name is not found in the directory.
- GetNames(Dir, Pattern) -> NameSeq: Returns all the text names that match the regular expression Pattern in the directory.
3. Client Module
The client module executes on each computer and delivers an integrated service (flat file and directory services) to application programs with the help of a single API. It stores information about the network locations of flat files and directory server processes. Here, recently used file blocks hold in a cache at the client-side, thus, resulting in improved performance.
File Access Protocols
Below are some of the File Access Protocols:
- NFS (Network File System)
- Definition: A distributed file system protocol allowing a user on a client computer to access files over a network in a manner similar to how local storage is accessed.
- Components: NFS server, NFS client.
- Use Cases: Widely used in UNIX/Linux environments for sharing directories and files across networks.
- Advantages: Transparent file access, central management.
- Disadvantages: Performance can degrade with high loads, security vulnerabilities if not configured properly.
- SMB/CIFS (Server Message Block/Common Internet File System)
- Definition: A network protocol primarily used for providing shared access to files, printers, and serial ports between nodes on a network.
- Components: SMB server (e.g., Samba), SMB client.
- Use Cases: Predominantly used in Windows environments for file and printer sharing.
- Advantages: Robust and feature-rich, good integration with Windows.
- Disadvantages: Complex setup, potential security issues.
- FTP (File Transfer Protocol)
- Definition: A standard network protocol used to transfer files from one host to another over a TCP-based network, such as the Internet.
- Components: FTP server, FTP client.
- Use Cases: File transfers between systems, website management.
- Advantages: Simple to implement, widely supported.
- Disadvantages: Data is not encrypted by default, leading to security risks.
- SFTP (SSH File Transfer Protocol)
- Definition: A secure version of FTP that uses SSH to encrypt all data transfers.
- Components: SFTP server, SFTP client.
- Use Cases: Secure file transfers over untrusted networks, remote server management.
- Advantages: Secure, robust authentication methods.
- Disadvantages: Slightly more complex to set up than FTP.
- HDFS (Hadoop Distributed File System)
- Definition: A distributed file system designed to run on commodity hardware, part of the Hadoop ecosystem.
- Components: NameNode, DataNodes, client.
- Use Cases: Big data storage and processing, high-throughput data applications.
- Advantages: Scalable, fault-tolerant.
- Disadvantages: High latency for small files, complex setup.
Data Distribution Techniques for File Service Architecture
1. Replication
- Definition: Creating and maintaining copies of data across multiple servers or locations.
- Components: Primary server, replica servers, synchronization mechanism.
- Advantages: Improved data availability and fault tolerance.
- Disadvantages: Increased storage requirements, potential for data inconsistency.
2. Sharding
- Definition: Dividing a database into smaller, more manageable pieces called shards, where each shard contains a subset of the data.
- Components: Shard keys, shard servers, shard management system.
- Advantages: Improved performance and scalability, reduced latency.
- Disadvantages: Increased complexity in query processing and data management.
3. Partitioning
- Definition: Splitting a database into distinct, independent sections (partitions), each of which can be managed and accessed separately.
- Components: Partition keys, partitioned tables, partition management system.
- Advantages: Improved query performance, simplified data management.
- Disadvantages: Complexity in partitioning logic, potential for uneven data distribution.
4. Caching
- Definition: Storing frequently accessed data in memory to reduce access time and load on the primary data store.
- Components: Cache servers, cache management system.
- Advantages: Faster data access, reduced load on primary data store.
- Disadvantages: Data consistency challenges, limited by memory size.
1. Caching
Caching temporarily stores frequently accessed data in memory to reduce access times and server load. This improves performance by allowing quicker data retrieval. For example, a Content Delivery Network (CDN) caches static website content to enhance load times for users globally. While caching can lead to faster performance and reduced server strain, it may introduce data consistency challenges and has limitations due to memory constraints.
2. Data Compression
Data compression reduces the size of files to save storage space and speed up data transfer. This technique is particularly beneficial for large files and bandwidth-constrained environments. For instance, cloud storage services like Google Drive use data compression to optimize storage and transmission efficiency. However, the compression and decompression process can introduce additional processing overhead and potential data fidelity loss in the case of lossy compression.
Load balancing distributes file access requests evenly across multiple servers to prevent any single server from becoming overwhelmed. This technique is essential in high-traffic environments and distributed file systems, as it enhances availability and resource utilization. An e-commerce platform, for example, uses load balancing to manage user requests for product images across multiple servers, ensuring smooth and uninterrupted service. The main challenge with load balancing is the added complexity and potential single points of failure if the load balancer itself fails.
4. Replication
Replication involves creating copies of files across different servers or locations to improve access speed and fault tolerance. This technique is vital for high availability and disaster recovery scenarios. A global cloud storage service, for instance, replicates user files across various data centers to ensure fast and reliable access. While replication enhances data redundancy and accessibility, it increases storage requirements and can complicate data consistency management.
Sharding splits a large dataset into smaller, more manageable pieces called shards. This approach improves performance and allows horizontal scaling. Social media platforms, for instance, shard user-generated content to distribute storage and access loads across multiple servers efficiently. However, sharding can be complex to manage and may result in uneven data distribution, posing additional challenges.
6. Asynchronous Processing
Asynchronous processing decouples file operations to run in the background, enabling the system to handle other requests concurrently. This technique is beneficial for time-consuming file operations and batch processing. An image hosting service, for example, processes image uploads asynchronously, allowing users to continue interacting with the platform while their images are being processed. The downside is the increased complexity and potential task synchronization issues.
7. Indexing
Indexing creates indexes to quickly locate and access files based on specific attributes, making search operations more efficient. Document management systems, for instance, use indexing to allow users to rapidly search and retrieve documents based on keywords or metadata. While indexing speeds up file retrieval, it requires additional storage and maintenance overhead.
Similar Reads
Distributed Systems Tutorial A distributed system is a system of multiple nodes that are physically separated but linked together using the network. Each of these nodes includes a small amount of the distributed operating system software. Every node in this system communicates and shares resources with each other and handles pr
8 min read
Basics of Distributed System
What is a Distributed System?A distributed system is a collection of independent computers that appear to the users of the system as a single coherent system. These computers or nodes work together, communicate over a network, and coordinate their activities to achieve a common goal by sharing resources, data, and tasks.Table o
7 min read
Types of Transparency in Distributed SystemIn distributed systems, transparency plays a pivotal role in abstracting complexities and enhancing user experience by hiding system intricacies. This article explores various types of transparency—ranging from location and access to failure and security—essential for seamless operation and efficien
6 min read
What is Scalable System in Distributed System?In distributed systems, a scalable system refers to the ability of a networked architecture to handle increasing amounts of work or expand to accommodate growth without compromising performance or reliability. Scalability ensures that as demand grows—whether in terms of user load, data volume, or tr
10 min read
Difference between Hardware and MiddlewareHardware and Middleware are both parts of a Computer. Hardware is the combination of physical components in a computer system that perform various tasks such as input, output, processing, and many more. Middleware is the part of software that is the communication medium between application and opera
4 min read
Difference between Parallel Computing and Distributed ComputingIntroductionParallel Computing and Distributed Computing are two important models of computing that have important roles in today’s high-performance computing. Both are designed to perform a large number of calculations breaking down the processes into several parallel tasks; however, they differ in
5 min read
Difference between Loosely Coupled and Tightly Coupled Multiprocessor SystemWhen it comes to multiprocessor system architecture, there is a very fine line between loosely coupled and tightly coupled systems, and this is why that difference is very important when choosing an architecture for a specific system. A multiprocessor system is a system in which there are two or mor
5 min read
Design Issues of Distributed SystemDistributed systems are used in many real-world applications today, ranging from social media platforms to cloud storage services. They provide the ability to scale up resources as needed, ensure data is available even when a computer fails, and allow users to access services from anywhere. However,
8 min read
Communication & RPC in Distributed Systems
Features of Good Message Passing in Distributed SystemMessage passing is the interaction of exchanging messages between at least two processors. The cycle which is sending the message to one more process is known as the sender and the process which is getting the message is known as the receiver. In a message-passing system, we can send the message by
3 min read
What is Message Buffering?Remote Procedure Call (RPC) is a communication technology that is used by one program to make a request to another program for utilizing its service on a network without even knowing the network's details. The inter-process communication in distributed systems is performed using Message Passing. It
6 min read
Group Communication in Distributed SystemsIn distributed systems, efficient group communication is crucial for coordinating activities among multiple entities. This article explores the challenges and solutions involved in facilitating reliable and ordered message delivery among members of a group spread across different nodes or networks.G
8 min read
What is Remote Procedural Call (RPC) Mechanism in Distributed System?A remote Procedure Call (RPC) is a protocol in distributed systems that allows a client to execute functions on a remote server as if they were local. RPC simplifies network communication by abstracting the complexities, making it easier to develop and integrate distributed applications efficiently.
9 min read
Stub Generation in Distributed SystemA stub is a piece of code that translates parameters sent between the client and server during a remote procedure call in distributed computing. An RPC's main purpose is to allow a local computer (client) to call procedures on another computer remotely (server) because the client and server utilize
3 min read
Server Management in Distributed SystemEffective server management in distributed systems is crucial for ensuring performance, reliability, and scalability. This article explores strategies and best practices for managing servers across diverse environments, focusing on configuration, monitoring, and maintenance to optimize the operation
12 min read
Difference Between RMI and DCOMIn this article, we will see differences between Remote Method Invocation(RMI) and Distributed Component Object Model(DCOM). Before getting into the differences, let us first understand what each of them actually means. RMI applications offer two separate programs, a server, and a client. There are
2 min read
Synchronization in Distributed System
Source & Process Management
What is Task Assignment Approach in Distributed System?A Distributed System is a Network of Machines that can exchange information with each other through Message-passing. It can be very useful as it helps in resource sharing. In this article, we will see the concept of the Task Assignment Approach in Distributed systems. Resource Management:One of the
6 min read
Difference Between Load Balancing and Load Sharing in Distributed SystemA distributed system is a computing environment in which different components are dispersed among several computers (or other computing devices) connected to a network. This article clarifies the distinctions between load balancing and load sharing in distributed systems, highlighting their respecti
4 min read
Process Migration in Distributed SystemProcess migration in distributed systems involves relocating a process from one node to another within a network. This technique optimizes resource use, balances load, and improves fault tolerance, enhancing overall system performance and reliability.Process Migration in Distributed SystemImportant
9 min read
Distributed Database SystemA distributed database is basically a database that is not limited to one system, it is spread over different sites, i.e, on multiple computers or over a network of computers. A distributed database system is located on various sites that don't share physical components. This may be required when a
5 min read
Multimedia DatabaseA Multimedia database is a collection of interrelated multimedia data that includes text, graphics (sketches, drawings), images, animations, video, audio etc and have vast amounts of multisource multimedia data. The framework that manages different types of multimedia data which can be stored, deliv
5 min read
Mechanism for Building Distributed File SystemBuilding a Distributed File System (DFS) involves intricate mechanisms to manage data across multiple networked nodes. This article explores key strategies for designing scalable, fault-tolerant systems that optimize performance and ensure data integrity in distributed computing environments.Mechani
8 min read
Distributed File System
What is DFS (Distributed File System)? A Distributed File System (DFS) is a file system that is distributed on multiple file servers or multiple locations. It allows programs to access or store isolated files as they do with the local ones, allowing programmers to access files from any network or computer. In this article, we will discus
8 min read
File Service Architecture in Distributed SystemFile service architecture in distributed systems manages and provides access to files across multiple servers or locations. It ensures efficient storage, retrieval, and sharing of files while maintaining consistency, availability, and reliability. By using techniques like replication, caching, and l
12 min read
File Models in Distributed SystemFile Models in Distributed Systems" explores how data organization and access methods impact efficiency across networked nodes. This article examines structured and unstructured models, their performance implications, and the importance of scalability and security in modern distributed architectures
6 min read
File Caching in Distributed File SystemsFile caching enhances I/O performance because previously read files are kept in the main memory. Because the files are available locally, the network transfer is zeroed when requests for these files are repeated. Performance improvement of the file system is based on the locality of the file access
12 min read
What is Replication in Distributed System?Replication in distributed systems involves creating duplicate copies of data or services across multiple nodes. This redundancy enhances system reliability, availability, and performance by ensuring continuous access to resources despite failures or increased demand.Replication in Distributed Syste
9 min read
What is Distributed Shared Memory and its Advantages?Distributed shared memory can be achieved via both software and hardware. Hardware examples include cache coherence circuits and network interface controllers. In contrast, software DSM systems implemented at the library or language level are not transparent and developers usually have to program th
4 min read
Consistency Model in Distributed SystemIt might be difficult to guarantee that all data copies in a distributed system stay consistent over several nodes. The guidelines for when and how data updates are displayed throughout the system are established by consistency models. Various approaches, including strict consistency or eventual con
6 min read
Distributed Algorithm
Advanced Distributed System
Flat & Nested Distributed TransactionsIntroduction : A transaction is a series of object operations that must be done in an ACID-compliant manner. Atomicity - The transaction is completed entirely or not at all.Consistency - It is a term that refers to the transition from one consistent state to another.Isolation - It is carried out sep
6 min read
Transaction Recovery in Distributed SystemIn distributed systems, ensuring the reliable recovery of transactions after failures is crucial. This article explores essential recovery techniques, including checkpointing, logging, and commit protocols, while addressing challenges in maintaining ACID properties and consistency across nodes to en
10 min read
Two Phase Commit Protocol (Distributed Transaction Management)Consider we are given with a set of grocery stores where the head of all store wants to query about the available sanitizers inventory at all stores in order to move inventory store to store to make balance over the quantity of sanitizers inventory at all stores. The task is performed by a single tr
5 min read
Scheduling and Load Balancing in Distributed SystemIn this article, we will go through the concept of scheduling and load balancing in distributed systems in detail. Scheduling in Distributed Systems:The techniques that are used for scheduling the processes in distributed systems are as follows: Task Assignment Approach: In the Task Assignment Appro
7 min read
Distributed System - Types of Distributed DeadlockA Deadlock is a situation where a set of processes are blocked because each process is holding a resource and waiting for another resource occupied by some other process. When this situation arises, it is known as Deadlock. DeadlockA Distributed System is a Network of Machines that can exchange info
4 min read
Difference between Uniform Memory Access (UMA) and Non-uniform Memory Access (NUMA)In computer architecture, and especially in Multiprocessors systems, memory access models play a critical role that determines performance, scalability, and generally, efficiency of the system. The two shared-memory models most frequently used are UMA and NUMA. This paper deals with these shared-mem
5 min read