Big data processing with apache spark part1
Download as pptx, pdf2 likes960 views

Apache Spark is an open source big data processing framework that is faster than Hadoop, easier to use, and supports more types of analytics. It provides high-level APIs, can run computations directly in memory for faster performance, and supports a variety of data processing workloads including SQL queries, streaming data, machine learning, and graph processing. Spark also has a large ecosystem of additional libraries and tools that expand its capabilities.





















Big data processing with apache spark part1
- 1. B I G D A T A W O R K G R O U P . I R
- 2. WHAT IS SPARK Apache Spark is an open source big data processing framework built around speed, ease of use, and sophisticated analytics. It was originally developed in 2009 in UC Berkeley’s AMPLab, and open sourced in 2010 as an Apache project. B I G D A T A W O R K G R O U P . I R
- 3. WHAT IS SPARK Advantages: In Memory Spark enables applications in Hadoop clusters to run up to 100 times faster in memory and 10 times faster even when running on disk. B I G D A T A W O R K G R O U P . I R
- 4. WHAT IS SPARK Advantages: Generic API Spark lets you quickly write applications in Java, Scala, or Python. It comes with a built-in set of over 80 high-level operators. And you can use it interactively to query data within the shell. B I G D A T A W O R K G R O U P . I R
- 5. WHAT IS SPARK Advantages: Many Applications Spark gives us a comprehensive, unified framework to manage big data processing requirements with a variety of data sets that are diverse in nature (text data, graph data etc) as well as the source of data (batch v. real-time streaming data). B I G D A T A W O R K G R O U P . I R
- 6. WHAT IS SPARK Advantages: Many Applications In addition to Map and Reduce operations, it supports SQL queries, streaming data, machine learning and graph data processing. Developers can use these capabilities stand-alone or combine them to run in a single data pipeline use case. B I G D A T A W O R K G R O U P . I R
- 7. HADOOP AND SPARK Hadoop Spark Map & Reduce -> suitable for on- pass computations multi-step data pipelines using directed acyclic graph (DAG) pattern. Clusters are hard to set up and manage supports in-memory data sharing across DAGs. need to integrate with Mahout (Machine Learning) and Storm (Streaming data processing) Spark as an alternative to Hadoop MapReduce B I G D A T A W O R K G R O U P . I R
- 8. SPARK FEATURES Less expensive shuffles in the data processing. With capabilities like in- memory data storage Lazy evaluation of big data queries, which helps with optimization of the steps in data processing workflows. Higher level API to improve developer productivity and a consistent architect model for big data solutions. B I G D A T A W O R K G R O U P . I R
- 9. SPARK FEATURES Spark holds intermediate results in memory rather than writing them to disk Spark can be used for processing datasets that larger than the aggregate memory in a cluster. B I G D A T A W O R K G R O U P . I R
- 10. SPARK ECOSYSTEM Spark Streaming micro batch style of computing and processing.(DStream) Spark SQL JDBC API, SQL like queries, ETL Spark Mlib including classification, regression, clustering, collaborative filtering, dimensionality reduction, as well as underlying optimization primitives B I G D A T A W O R K G R O U P . I R
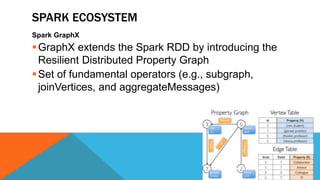
- 11. SPARK ECOSYSTEM Spark GraphX GraphX extends the Spark RDD by introducing the Resilient Distributed Property Graph Set of fundamental operators (e.g., subgraph, joinVertices, and aggregateMessages) B I G D A T A W O R K G R O U P . I R
- 12. SPARK ECOSYSTEM BlinkDB trade-off query accuracy for response time. Tachyon Caches working set files in memory Spark Cassandra Connector access data stored in a Cassandra database SparkR B I G D A T A W O R K G R O U P . I R
- 13. B I G D A T A W O R K G R O U P . I R
- 14. SPARK ARCHITECTURE B I G D A T A W O R K G R O U P . I R
- 15. RESILIENT DISTRIBUTED DATASETS Fault tolerance because an RDD know how to recreate and re-compute the datasets. RDDs are immutable. B I G D A T A W O R K G R O U P . I R
- 16. RDD OPERATIONS B I G D A T A W O R K G R O U P . I R
- 17. HOW TO RUN SPARK B I G D A T A W O R K G R O U P . I R
- 18. HOW TO INTERACT WITH SPARK spark-shell.cmd B I G D A T A W O R K G R O U P . I R
- 19. SPARK WEB CONSOLE http://localhost:4040 B I G D A T A W O R K G R O U P . I R
- 20. SHARED VARIABLES Broadcast Variables Accumulators B I G D A T A W O R K G R O U P . I R
- 21. SPARK ECOSYSTEM Spark SQL JDBC API, SQL like queries, ETL B I G D A T A W O R K G R O U P . I R
- 22. SPARK ECOSYSTEM Spark Streaming micro batch style of computing and processing.(DStream) B I G D A T A W O R K G R O U P . I R