Text classification using Text kernels
Download as ppt, pdf3 likes3,676 views

This document summarizes a presentation on using string kernels for text classification. It introduces text classification and the challenge of representing text documents as feature vectors. It then discusses how kernel methods can be used as an alternative, by mapping documents into a feature space without explicitly extracting features. Different string kernel algorithms are described that measure similarity between documents based on common subsequences of characters. The document evaluates the performance of these kernels on a text dataset and explores ways to improve efficiency, such as through kernel approximation.
1 of 42
Downloaded 104 times








![Kernels for Sequences
• Word Kernels [WK] - Bag of Words
- Sequence of characters followed by punctuation
or space
• N-Grams Kernel [NGK]
• Sequence of n consecutive substrings
• Example : “quick brown”
3-gram - qui, uic, ick, ck_, _br, bro, row, own
• String Subsequence Kernel [SSK]
• All (non-contiguous) substrings of n-symbols](https://image.slidesharecdn.com/textclassificationusingtextkernels-150304154439-conversion-gate01/85/Text-classification-using-Text-kernels-10-320.jpg)




![Algorithm Definitions
• Alphabet
Let Σ be the finite alphabet
• String
A string is a finite sequence of characters from alphabet with
length |s|
• Subsequence
A vector of indices ij, sorted in ascending order, in a string ‘s’
such that they form the letters of a sequence
Eg: ‘lancasters’ = [4,5,9]
Length of subsequence = in – i1 +1 = 9 - 4 + 1 = 6](https://image.slidesharecdn.com/textclassificationusingtextkernels-150304154439-conversion-gate01/85/Text-classification-using-Text-kernels-15-320.jpg)


















![Evaluation
Effectiveness of Sequence Length
[k = 7] [k = 5]
[k = 6] [k = 5]
[k = 5]
[k = 5][k = 5]
[k = 5]](https://image.slidesharecdn.com/textclassificationusingtextkernels-150304154439-conversion-gate01/85/Text-classification-using-Text-kernels-35-320.jpg)







Ad
Recommended
LSTM Tutorial
LSTM TutorialRalph Schlosser The document provides an overview of Long Short-Term Memory (LSTM) neural networks, highlighting their advantages over traditional Recurrent Neural Networks (RNNs) in handling sequence data, while addressing challenges like the vanishing and exploding gradient problems. It explains the internal gating mechanisms of LSTMs that aid in managing long-range dependencies in input data and introduces Keras as a user-friendly framework for implementing these neural networks. Recent advances indicate that LSTMs can function as universal program approximators, prompting discussions on the future of software development.
Text Classification
Text ClassificationRAX Automation Suite The document outlines a research overview on text classification for Rax Studio, emphasizing natural language processing applications such as sentiment analysis and intent classification. It details the data preprocessing steps, feature extraction methods like one-hot encoding and word2vec, and various machine learning models including Naive Bayes and multilayer perceptron. Additionally, it suggests an implementation plan focused on email management and cleaning, with a framework for model updating and retraining.
"An Introduction to Machine Learning and How to Teach Machines to See," a Pre...
"An Introduction to Machine Learning and How to Teach Machines to See," a Pre...Edge AI and Vision Alliance The document is an introduction to machine learning, covering its definition, types, and practical applications. It outlines the steps essential for solving machine learning problems, including data gathering, preprocessing, feature engineering, model selection, and prediction. It also discusses deep learning techniques, particularly focusing on convolutional neural networks for image classification and emphasizes the importance of data quality in machine learning outcomes.
Recurrent Neural Networks (RNN) | RNN LSTM | Deep Learning Tutorial | Tensorf...
Recurrent Neural Networks (RNN) | RNN LSTM | Deep Learning Tutorial | Tensorf...Edureka! This document discusses recurrent neural networks (RNNs) and their advantages over feedforward networks, particularly in handling sequential data and maintaining context over time. It highlights the issues of vanishing and exploding gradients during training and introduces long short-term memory units (LSTMs) as a solution. The document also includes a use-case for LSTMs in predicting sequences from text data.
PyTorch Introduction
PyTorch IntroductionYash Kawdiya PyTorch is an open-source machine learning framework popular for flexibility and ease-of-use. It is built on Python and supports neural networks using tensors as the primary data structure. Key features include tensor computation, automatic differentiation for training networks, and dynamic graph computation. PyTorch is used for applications like computer vision, natural language processing, and research due to its flexibility and Python integration. Major companies like Facebook, Uber, and Salesforce use PyTorch for machine learning tasks.
Automatic Machine Learning, AutoML
Automatic Machine Learning, AutoMLHimadri Mishra The document provides an overview of Automatic Machine Learning (AutoML), detailing its purpose and methods, including the automation of algorithm selection and hyperparameter tuning to enhance machine learning processes. It highlights various components of the AutoML framework, such as data preprocessing and model selection, and discusses recent advancements like the Auto-Net system that achieved high performance in a competitive setting. Overall, the document emphasizes the growing significance of AutoML in facilitating machine learning for non-experts and its potential to challenge existing methodologies.
Feature Engineering - Getting most out of data for predictive models
Feature Engineering - Getting most out of data for predictive modelsGabriel Moreira The document discusses feature engineering techniques essential for enhancing machine learning models, detailing processes like data munging, numerical and categorical feature transformations, and missing value imputation. It presents an Outbrain click prediction case study exemplifying practical applications of these techniques, along with numerous examples demonstrating feature selection, binning, normalization, and interactions. Key methods such as one-hot encoding, feature hashing, and embeddings for categorical data are highlighted to improve model accuracy and performance.
Support Vector Machines
Support Vector Machinesnextlib This document summarizes support vector machines (SVMs), a machine learning technique for classification and regression. SVMs find the optimal separating hyperplane that maximizes the margin between positive and negative examples in the training data. This is achieved by solving a convex optimization problem that minimizes a quadratic function under linear constraints. SVMs can perform non-linear classification by implicitly mapping inputs into a higher-dimensional feature space using kernel functions. They have applications in areas like text categorization due to their ability to handle high-dimensional sparse data.
bag-of-words models
bag-of-words models Xiaotao Zou This document provides an overview of bag-of-words models for image classification. It discusses how bag-of-words models originated from texture recognition and document classification. Images are represented as histograms of visual word frequencies. A visual vocabulary is learned by clustering local image features, and each cluster center becomes a visual word. Both discriminative methods like support vector machines and generative methods like Naive Bayes are used to classify images based on their bag-of-words representations.
Introduction to NP Completeness
Introduction to NP CompletenessGene Moo Lee This document provides an introduction to NP-completeness, including: definitions of key concepts like decision problems, classes P and NP, and polynomial time reductions; examples of NP-complete problems like satisfiability and the traveling salesman problem; and approaches to dealing with NP-complete problems like heuristic algorithms, approximation algorithms, and potential help from quantum computing in the future. The document establishes NP-completeness as a central concept in computational complexity theory.
Text classification presentation
Text classification presentationMarijn van Zelst The document discusses text classification and different techniques for performing classification on text data, including dimensionality reduction, text embedding, and classification pipelines. It describes using dimensionality reduction techniques like TSNE to visualize high-dimensional text data in 2D and how this can aid classification. Text embedding techniques like doc2vec are discussed for converting text into fixed-dimensional vectors before classification. Several examples show doc2vec outperforming classification directly on word counts. The document concludes that extracting the right features from data is key and visualization can provide insight into feature quality.
Unit 2 unsupervised learning.pptx
Unit 2 unsupervised learning.pptxDr.Shweta The document provides a comprehensive overview of unsupervised learning in machine learning, focusing on its definition, goals, and techniques such as clustering, k-means clustering, hierarchical clustering, and association rule mining. It highlights the significance of unsupervised learning in discovering hidden patterns in unlabeled data and discusses various algorithms, their advantages, and disadvantages. Key applications and methods for determining optimal cluster numbers, like the elbow method, are also described.
Introduction to Statistical Machine Learning
Introduction to Statistical Machine Learningmahutte The document provides a comprehensive introduction to statistical machine learning, outlining key methods and practices for developing algorithms that learn from data. It covers various topics including supervised and unsupervised learning, regression, classification, optimization techniques, and model assessment. Key applications are identified in fields such as natural language processing, medical diagnosis, and bioinformatics.
Naive bayes
Naive bayesumeskath This document discusses Naive Bayes classifiers. It begins with an overview of probabilistic classification and the Naive Bayes approach. The Naive Bayes classifier makes a strong independence assumption that features are conditionally independent given the class. It then presents the algorithm for Naive Bayes classification with discrete and continuous features. An example of classifying whether to play tennis is used to illustrate the learning and classification phases. The document concludes with a discussion of some relevant issues and a high-level summary of Naive Bayes.
Natural language processing: feature extraction
Natural language processing: feature extractionGabriel Hamilton This document discusses natural language processing (NLP) and feature extraction. It explains that NLP can be used for applications like search, translation, and question answering. The document then discusses extracting features from text like paragraphs, sentences, words, parts of speech, entities, sentiment, topics, and assertions. Specific features discussed in more detail include frequency, relationships between words, language features, supervised machine learning, classifiers, encoding words, word vectors, and parse trees. Tools mentioned for NLP include Google Cloud NLP, Spacy, OpenNLP, and Stanford Core NLP.
Markov Chain Monte Carlo Methods
Markov Chain Monte Carlo MethodsFrancesco Casalegno The document discusses various Markov Chain Monte Carlo (MCMC) methods, including Gibbs sampling, Metropolis–Hastings, Hamiltonian Monte Carlo, and Reversible-Jump MCMC, highlighting their applications in Bayesian networks and inference on complex distributions. It emphasizes the motivations behind using MCMC for sampling from challenging posterior distributions and outlines the basic principles, algorithms, and pros and cons of each method. Additionally, the document provides examples to illustrate how these methods can be applied effectively in hierarchical regression, change-point models, and topic modeling.
Optimization for Neural Network Training - Veronica Vilaplana - UPC Barcelona...
Optimization for Neural Network Training - Veronica Vilaplana - UPC Barcelona...Universitat Politècnica de Catalunya The document discusses optimization techniques for training neural networks, covering concepts such as stochastic gradient descent, surrogate loss functions, and early stopping. It addresses the challenges posed by non-convex optimization landscapes, including local minima and saddle points, and offers practical algorithms to mitigate these issues. Various learning rate adjustment methods, including adaptive techniques like Adam and RMSprop, are also detailed to improve convergence during training.
44 randomized-algorithms
44 randomized-algorithmsAjitSaraf1 This document discusses randomized algorithms and how they use random numbers to help solve problems. It covers topics like pseudorandom number generation, shuffling arrays randomly, and using randomization to approximate optimal strategies for problems like the 0-1 knapsack problem that are difficult to solve deterministically. Randomized algorithms are presented as a useful technique for simulation, finding good solutions when perfect solutions are intractable, or as an alternative approach when no other algorithms are known.
Knn 160904075605-converted
Knn 160904075605-convertedrameswara reddy venkat This document discusses the K-nearest neighbors (KNN) algorithm, an instance-based learning method used for classification. KNN works by identifying the K training examples nearest to a new data point and assigning the most common class among those K neighbors to the new point. The document covers how KNN calculates distances between data points, chooses the value of K, handles feature normalization, and compares strengths and weaknesses of the approach. It also briefly discusses clustering, an unsupervised learning technique where data is grouped based on similarity.
Machine Learning
Machine LearningShrey Malik Active learning is a machine learning technique where the learner is able to interactively query the oracle (e.g. a human) to obtain labels for new data points in an effort to learn more accurately from fewer labeled examples. The learner selects the most informative samples to be labeled by the oracle, such as samples closest to the decision boundary or where models disagree most. This allows the learner to minimize the number of labeled samples needed, thus reducing the cost of training an accurate model. Suggested improvements include querying batches of samples instead of single samples and accounting for varying labeling costs.
Deep Dive into Hyperparameter Tuning
Deep Dive into Hyperparameter TuningShubhmay Potdar This document provides an overview of different techniques for hyperparameter tuning in machine learning models. It begins with introductions to grid search and random search, then discusses sequential model-based optimization techniques like Bayesian optimization and Tree-of-Parzen Estimators. Evolutionary algorithms like CMA-ES and particle-based methods like particle swarm optimization are also covered. Multi-fidelity methods like successive halving and Hyperband are described, along with recommendations on when to use different techniques. The document concludes by listing several popular libraries for hyperparameter tuning.
Machine Learning With Logistic Regression
Machine Learning With Logistic RegressionKnoldus Inc. The document discusses machine learning with a focus on logistic regression, including definitions, techniques, and comparisons between regression and classification. It explains logistic regression as a classification algorithm that employs the logit function to evaluate outputs and minimize errors. Key components such as the nature of outputs in regression versus classification and the importance of the logit function in making predictions are highlighted.
K-Nearest Neighbor Classifier
K-Nearest Neighbor ClassifierNeha Kulkarni The document provides a comprehensive overview of the k-nearest neighbor (KNN) classifier, comparing it to eager and lazy learners, and discussing various aspects such as choosing the value of k, handling categorical attributes, and missing values. It explains the KNN algorithm in detail, illustrated with examples and applications in different domains, while also noting its advantages and disadvantages compared to other classifiers. Additionally, it highlights considerations for selecting the appropriate distance measures and the importance of sample size for effective classification.
Machine learning Lecture 2
Machine learning Lecture 2Srinivasan R The document summarizes key concepts in machine learning including concept learning as search, general-to-specific learning, version spaces, candidate elimination algorithm, and decision trees. It discusses how concept learning can be viewed as searching a hypothesis space to find the hypothesis that best fits the training examples. The candidate elimination algorithm represents the version space using the most general and specific hypotheses to efficiently learn from examples.
K - Nearest neighbor ( KNN )
K - Nearest neighbor ( KNN )Mohammad Junaid Khan The document discusses the k-nearest neighbors (KNN) algorithm, a lazy learning method used for classification and regression in both supervised and unsupervised learning. It explains how KNN works by making predictions based on the majority vote of the 'k' closest points to an unlabeled data point, while using distance metrics like Euclidean and Hamming distance. The text also highlights the influence of the 'k' value on model performance, its advantages and disadvantages, and various applications in fields such as finance and medicine.
K-Nearest Neighbor(KNN)
K-Nearest Neighbor(KNN)Abdullah al Mamun The k-nearest neighbors (k-NN) algorithm is a non-parametric, lazy learner method used for classification and regression by categorizing a new data point based on its similarity to existing data points. Choosing the correct value of 'k' is crucial for accuracy, and the algorithm operates by calculating the Euclidean distance between points to determine the nearest neighbors. Applications of k-NN include banking for loan approval predictions and calculating credit ratings.
Learning With Complete Data
Learning With Complete DataVishnuprabhu Gopalakrishnan This document discusses different approaches for learning with complete data, including:
1) Parameter learning aims to find numerical parameters for a fixed probability model given complete data for all variables.
2) Maximum likelihood parameter learning derives parameter expressions as log terms and finds values by equating logs to 0.
3) Naive Bayes models assume attributes are conditionally independent, and truth is not representable as a decision tree.
4) Continuous models represent real-world applications using linear Gaussian models that minimize sum of squared errors via standard linear recursion.
Svm and kernel machines
Svm and kernel machinesNawal Sharma Support vector machines (SVM) are a supervised learning method used for classification and regression analysis. SVMs find a hyperplane that maximizes the margin between two classes of objects. They can handle non-linear classification problems by projecting data into a higher dimensional space. The training points closest to the separating hyperplane are called support vectors. SVMs learn the discrimination boundary between classes rather than modeling each class individually.
ECO_TEXT_CLUSTERING
ECO_TEXT_CLUSTERINGGeorge Simov This document describes LSI text clustering. It discusses vector space models, term weighting using TF-IDF, similarity measures, latent semantic indexing using singular value decomposition, suffix arrays and longest common prefix arrays for phrase discovery. The clustering algorithm involves preprocessing text, feature extraction to find terms and phrases, applying LSI to discover concepts and determine cluster labels, assigning documents to clusters, and calculating cluster scores. Parameters and issues with the algorithm are also outlined. A demo clusters a set of question and answer documents.
KNN Neural Network In minimax search, alpha-beta pruning can be applied to pr...
KNN Neural Network In minimax search, alpha-beta pruning can be applied to pr...movocode The document discusses k-nearest neighbor (k-NN) classifiers, explaining its basic principles, including instance-based learning, distance metrics, and the selection of the optimal value of k. It also introduces the bag-of-words model for document classification, demonstrating how to transform text data into numerical representations for machine learning, and highlights the computational complexities associated with k-NN in high-dimensional data. Additionally, it includes examples such as predicting class labels and email spam filtering using k-NN.
More Related Content
What's hot (20)
bag-of-words models
bag-of-words models Xiaotao Zou This document provides an overview of bag-of-words models for image classification. It discusses how bag-of-words models originated from texture recognition and document classification. Images are represented as histograms of visual word frequencies. A visual vocabulary is learned by clustering local image features, and each cluster center becomes a visual word. Both discriminative methods like support vector machines and generative methods like Naive Bayes are used to classify images based on their bag-of-words representations.
Introduction to NP Completeness
Introduction to NP CompletenessGene Moo Lee This document provides an introduction to NP-completeness, including: definitions of key concepts like decision problems, classes P and NP, and polynomial time reductions; examples of NP-complete problems like satisfiability and the traveling salesman problem; and approaches to dealing with NP-complete problems like heuristic algorithms, approximation algorithms, and potential help from quantum computing in the future. The document establishes NP-completeness as a central concept in computational complexity theory.
Text classification presentation
Text classification presentationMarijn van Zelst The document discusses text classification and different techniques for performing classification on text data, including dimensionality reduction, text embedding, and classification pipelines. It describes using dimensionality reduction techniques like TSNE to visualize high-dimensional text data in 2D and how this can aid classification. Text embedding techniques like doc2vec are discussed for converting text into fixed-dimensional vectors before classification. Several examples show doc2vec outperforming classification directly on word counts. The document concludes that extracting the right features from data is key and visualization can provide insight into feature quality.
Unit 2 unsupervised learning.pptx
Unit 2 unsupervised learning.pptxDr.Shweta The document provides a comprehensive overview of unsupervised learning in machine learning, focusing on its definition, goals, and techniques such as clustering, k-means clustering, hierarchical clustering, and association rule mining. It highlights the significance of unsupervised learning in discovering hidden patterns in unlabeled data and discusses various algorithms, their advantages, and disadvantages. Key applications and methods for determining optimal cluster numbers, like the elbow method, are also described.
Introduction to Statistical Machine Learning
Introduction to Statistical Machine Learningmahutte The document provides a comprehensive introduction to statistical machine learning, outlining key methods and practices for developing algorithms that learn from data. It covers various topics including supervised and unsupervised learning, regression, classification, optimization techniques, and model assessment. Key applications are identified in fields such as natural language processing, medical diagnosis, and bioinformatics.
Naive bayes
Naive bayesumeskath This document discusses Naive Bayes classifiers. It begins with an overview of probabilistic classification and the Naive Bayes approach. The Naive Bayes classifier makes a strong independence assumption that features are conditionally independent given the class. It then presents the algorithm for Naive Bayes classification with discrete and continuous features. An example of classifying whether to play tennis is used to illustrate the learning and classification phases. The document concludes with a discussion of some relevant issues and a high-level summary of Naive Bayes.
Natural language processing: feature extraction
Natural language processing: feature extractionGabriel Hamilton This document discusses natural language processing (NLP) and feature extraction. It explains that NLP can be used for applications like search, translation, and question answering. The document then discusses extracting features from text like paragraphs, sentences, words, parts of speech, entities, sentiment, topics, and assertions. Specific features discussed in more detail include frequency, relationships between words, language features, supervised machine learning, classifiers, encoding words, word vectors, and parse trees. Tools mentioned for NLP include Google Cloud NLP, Spacy, OpenNLP, and Stanford Core NLP.
Markov Chain Monte Carlo Methods
Markov Chain Monte Carlo MethodsFrancesco Casalegno The document discusses various Markov Chain Monte Carlo (MCMC) methods, including Gibbs sampling, Metropolis–Hastings, Hamiltonian Monte Carlo, and Reversible-Jump MCMC, highlighting their applications in Bayesian networks and inference on complex distributions. It emphasizes the motivations behind using MCMC for sampling from challenging posterior distributions and outlines the basic principles, algorithms, and pros and cons of each method. Additionally, the document provides examples to illustrate how these methods can be applied effectively in hierarchical regression, change-point models, and topic modeling.
Optimization for Neural Network Training - Veronica Vilaplana - UPC Barcelona...
Optimization for Neural Network Training - Veronica Vilaplana - UPC Barcelona...Universitat Politècnica de Catalunya The document discusses optimization techniques for training neural networks, covering concepts such as stochastic gradient descent, surrogate loss functions, and early stopping. It addresses the challenges posed by non-convex optimization landscapes, including local minima and saddle points, and offers practical algorithms to mitigate these issues. Various learning rate adjustment methods, including adaptive techniques like Adam and RMSprop, are also detailed to improve convergence during training.
44 randomized-algorithms
44 randomized-algorithmsAjitSaraf1 This document discusses randomized algorithms and how they use random numbers to help solve problems. It covers topics like pseudorandom number generation, shuffling arrays randomly, and using randomization to approximate optimal strategies for problems like the 0-1 knapsack problem that are difficult to solve deterministically. Randomized algorithms are presented as a useful technique for simulation, finding good solutions when perfect solutions are intractable, or as an alternative approach when no other algorithms are known.
Knn 160904075605-converted
Knn 160904075605-convertedrameswara reddy venkat This document discusses the K-nearest neighbors (KNN) algorithm, an instance-based learning method used for classification. KNN works by identifying the K training examples nearest to a new data point and assigning the most common class among those K neighbors to the new point. The document covers how KNN calculates distances between data points, chooses the value of K, handles feature normalization, and compares strengths and weaknesses of the approach. It also briefly discusses clustering, an unsupervised learning technique where data is grouped based on similarity.
Machine Learning
Machine LearningShrey Malik Active learning is a machine learning technique where the learner is able to interactively query the oracle (e.g. a human) to obtain labels for new data points in an effort to learn more accurately from fewer labeled examples. The learner selects the most informative samples to be labeled by the oracle, such as samples closest to the decision boundary or where models disagree most. This allows the learner to minimize the number of labeled samples needed, thus reducing the cost of training an accurate model. Suggested improvements include querying batches of samples instead of single samples and accounting for varying labeling costs.
Deep Dive into Hyperparameter Tuning
Deep Dive into Hyperparameter TuningShubhmay Potdar This document provides an overview of different techniques for hyperparameter tuning in machine learning models. It begins with introductions to grid search and random search, then discusses sequential model-based optimization techniques like Bayesian optimization and Tree-of-Parzen Estimators. Evolutionary algorithms like CMA-ES and particle-based methods like particle swarm optimization are also covered. Multi-fidelity methods like successive halving and Hyperband are described, along with recommendations on when to use different techniques. The document concludes by listing several popular libraries for hyperparameter tuning.
Machine Learning With Logistic Regression
Machine Learning With Logistic RegressionKnoldus Inc. The document discusses machine learning with a focus on logistic regression, including definitions, techniques, and comparisons between regression and classification. It explains logistic regression as a classification algorithm that employs the logit function to evaluate outputs and minimize errors. Key components such as the nature of outputs in regression versus classification and the importance of the logit function in making predictions are highlighted.
K-Nearest Neighbor Classifier
K-Nearest Neighbor ClassifierNeha Kulkarni The document provides a comprehensive overview of the k-nearest neighbor (KNN) classifier, comparing it to eager and lazy learners, and discussing various aspects such as choosing the value of k, handling categorical attributes, and missing values. It explains the KNN algorithm in detail, illustrated with examples and applications in different domains, while also noting its advantages and disadvantages compared to other classifiers. Additionally, it highlights considerations for selecting the appropriate distance measures and the importance of sample size for effective classification.
Machine learning Lecture 2
Machine learning Lecture 2Srinivasan R The document summarizes key concepts in machine learning including concept learning as search, general-to-specific learning, version spaces, candidate elimination algorithm, and decision trees. It discusses how concept learning can be viewed as searching a hypothesis space to find the hypothesis that best fits the training examples. The candidate elimination algorithm represents the version space using the most general and specific hypotheses to efficiently learn from examples.
K - Nearest neighbor ( KNN )
K - Nearest neighbor ( KNN )Mohammad Junaid Khan The document discusses the k-nearest neighbors (KNN) algorithm, a lazy learning method used for classification and regression in both supervised and unsupervised learning. It explains how KNN works by making predictions based on the majority vote of the 'k' closest points to an unlabeled data point, while using distance metrics like Euclidean and Hamming distance. The text also highlights the influence of the 'k' value on model performance, its advantages and disadvantages, and various applications in fields such as finance and medicine.
K-Nearest Neighbor(KNN)
K-Nearest Neighbor(KNN)Abdullah al Mamun The k-nearest neighbors (k-NN) algorithm is a non-parametric, lazy learner method used for classification and regression by categorizing a new data point based on its similarity to existing data points. Choosing the correct value of 'k' is crucial for accuracy, and the algorithm operates by calculating the Euclidean distance between points to determine the nearest neighbors. Applications of k-NN include banking for loan approval predictions and calculating credit ratings.
Learning With Complete Data
Learning With Complete DataVishnuprabhu Gopalakrishnan This document discusses different approaches for learning with complete data, including:
1) Parameter learning aims to find numerical parameters for a fixed probability model given complete data for all variables.
2) Maximum likelihood parameter learning derives parameter expressions as log terms and finds values by equating logs to 0.
3) Naive Bayes models assume attributes are conditionally independent, and truth is not representable as a decision tree.
4) Continuous models represent real-world applications using linear Gaussian models that minimize sum of squared errors via standard linear recursion.
Svm and kernel machines
Svm and kernel machinesNawal Sharma Support vector machines (SVM) are a supervised learning method used for classification and regression analysis. SVMs find a hyperplane that maximizes the margin between two classes of objects. They can handle non-linear classification problems by projecting data into a higher dimensional space. The training points closest to the separating hyperplane are called support vectors. SVMs learn the discrimination boundary between classes rather than modeling each class individually.
Optimization for Neural Network Training - Veronica Vilaplana - UPC Barcelona...
Optimization for Neural Network Training - Veronica Vilaplana - UPC Barcelona...Universitat Politècnica de Catalunya
Similar to Text classification using Text kernels (20)
ECO_TEXT_CLUSTERING
ECO_TEXT_CLUSTERINGGeorge Simov This document describes LSI text clustering. It discusses vector space models, term weighting using TF-IDF, similarity measures, latent semantic indexing using singular value decomposition, suffix arrays and longest common prefix arrays for phrase discovery. The clustering algorithm involves preprocessing text, feature extraction to find terms and phrases, applying LSI to discover concepts and determine cluster labels, assigning documents to clusters, and calculating cluster scores. Parameters and issues with the algorithm are also outlined. A demo clusters a set of question and answer documents.
KNN Neural Network In minimax search, alpha-beta pruning can be applied to pr...
KNN Neural Network In minimax search, alpha-beta pruning can be applied to pr...movocode The document discusses k-nearest neighbor (k-NN) classifiers, explaining its basic principles, including instance-based learning, distance metrics, and the selection of the optimal value of k. It also introduces the bag-of-words model for document classification, demonstrating how to transform text data into numerical representations for machine learning, and highlights the computational complexities associated with k-NN in high-dimensional data. Additionally, it includes examples such as predicting class labels and email spam filtering using k-NN.
is2015_poster
is2015_posterJan Svec The document presents a novel method for processing automatic speech recognition (ASR) lattices using convolutional neural networks (CNNs). The method generalizes the convolutional layer to process both the posterior probabilities and lexical information in an ASR lattice. It was used in a CNN-based hierarchical discriminative model (HDM) for spoken language understanding. Evaluation on two corpora showed the CNN-based HDM improved over an original HDM based on support vector machines, achieving up to a 3% absolute improvement in concept accuracy.
CNN for modeling sentence
CNN for modeling sentenceANISH BHANUSHALI This paper aims to develop an effective sentence model using a dynamic convolutional neural network (DCNN) architecture. The DCNN applies 1D convolutions and dynamic k-max pooling to capture syntactic and semantic information from sentences with varying lengths. This allows the model to relate phrases far apart in the input sentence and draw together important features. Experiments show the DCNN approach achieves strong performance on tasks like sentiment analysis of movie reviews and question type classification.
Clique and sting
Clique and stingSubramanyam Natarajan CLIQUE is an algorithm for subspace clustering of high-dimensional data. It works in two steps: (1) It partitions each dimension of the data space into intervals of equal length to form a grid, (2) It identifies dense units within this grid and finds clusters as maximal sets of connected dense units. CLIQUE efficiently discovers clusters by identifying dense units in subspaces and intersecting them to obtain candidate dense units in higher dimensions. It automatically determines relevant subspaces for clustering and scales well with large, high-dimensional datasets.
19EC4073_PR_CO3 PPdcdfvsfgfvgfdgbtvfT.pptx
19EC4073_PR_CO3 PPdcdfvsfgfvgfdgbtvfT.pptxlingaswamy16 3rq3gr3ojfwekfngknwerkg ewrgf rgj wpgjewfjewlfjewkfhewipgf efgiwefwe fg3hgfifhief efiwh
Db Scan
Db ScanInternational Islamic University DBSCAN is a density-based clustering algorithm that groups together densely populated areas of points. It requires two parameters: epsilon, which defines the neighborhood distance, and MinPts, the minimum number of points required to form a cluster. DBSCAN iteratively retrieves all points density-reachable from each point and forms clusters from core points with sufficient neighbors within epsilon distance. It can find clusters of arbitrary shape and handle noise without requiring the number of clusters to be specified.
The science behind predictive analytics a text mining perspective
The science behind predictive analytics a text mining perspectiveankurpandeyinfo This document summarizes techniques for predictive analytics using text mining and unstructured text data. It discusses representing text data using bag-of-words models and vector space models. Dimensionality reduction techniques like latent semantic analysis and topic models like latent Dirichlet allocation are described for extracting semantic information from text. Clustering methods like k-means clustering and hierarchical clustering are discussed for grouping similar documents. The document also covers classification techniques like rule-based classifiers, decision trees, and linear classifiers like logistic regression for assigning labels to documents.
Deduplication on large amounts of code
Deduplication on large amounts of codesource{d} The document discusses methods for deduplication of large code repositories, showcased at FOSDEM 2019. It outlines various approaches for feature extraction, similarity detection, and community analysis of code snippets, emphasizing the use of techniques like local-sensitive hashing and community detection algorithms. The analysis utilized a dataset of over 182,000 code repositories, resulting in the identification of numerous clone communities across distinct features.
Presentation on Text Classification
Presentation on Text ClassificationSai Srinivas Kotni This document discusses using support vector machines (SVMs) for text classification. It begins by outlining the importance and applications of automated text classification. The objective is then stated as creating an efficient SVM model for text categorization and measuring its performance. Common text classification methods like Naive Bayes, k-Nearest Neighbors, and SVMs are introduced. The document then provides examples of different types of text classification labels and decisions involved. It proceeds to explain decision tree models, Naive Bayes algorithms, and the main ideas behind SVMs. The methodology section outlines the preprocessing, feature selection, and performance measurement steps involved in building an SVM text classification model in R.
Text clustering
Text clusteringKU Leuven Text clustering involves grouping text documents into clusters such that documents within a cluster are similar to each other and dissimilar to documents in other clusters. Common text clustering methods include bisecting k-means clustering, which recursively partitions clusters, and agglomerative hierarchical clustering, which iteratively merges clusters. Text clustering is used to automatically organize large document collections and improve search by returning related groups of documents.
[Paper Reading] Attention is All You Need
[Paper Reading] Attention is All You NeedDaiki Tanaka The document summarizes the "Attention Is All You Need" paper, which introduced the Transformer model for natural language processing. The Transformer uses attention mechanisms rather than recurrent or convolutional layers, allowing for more parallelization. It achieved state-of-the-art results in machine translation tasks using techniques like multi-head attention, positional encoding, and beam search decoding. The paper demonstrated the Transformer's ability to draw global dependencies between input and output with constant computational complexity.
Encoding survey
Encoding surveyRajeev Raman This document discusses encoding data structures to answer range maximum queries (RMQs) in an optimal way. It describes how the shape of the Cartesian tree of an array A can be encoded in 2n bits to answer RMQ queries, returning the index of the maximum element rather than its value. It also discusses encodings for other problems like nearest larger values, range selection, and others. Many of these encodings use asymptotically optimal space of roughly n log k bits for an input of size n with parameter k.
Mining the social web 6
Mining the social web 6HyeonSeok Choi This chapter discusses clustering connections on LinkedIn based on job title to find similarities. It covers standardizing job titles, common similarity metrics like edit distance and Jaccard distance, and clustering algorithms like greedy clustering, hierarchical clustering and k-means clustering. It also discusses fetching extended profile information using OAuth authorization to access private LinkedIn data without credentials. The goal is to answer questions about connections by clustering them based on attributes like job title, company or location.
Instance Based Learning in Machine Learning
Instance Based Learning in Machine LearningPavithra Thippanaik The document provides an overview of instance-based learning, contrasting it with eager learning and discussing methods such as the nearest neighbor algorithm. It highlights the advantages and disadvantages of the nearest neighbor approach, including high storage requirements and computational cost, as well as techniques like locally weighted regression and case-based reasoning. Additionally, it touches on concepts like distance functions and error criteria in regression, emphasizing the lazy learning nature of instance-based methods.
Cluster
Clusterguest1babda The document discusses various techniques for document clustering and choosing the number of clusters. It describes how clustering can help address issues like ambiguous queries by grouping query results by topic. It also covers partitioning and hierarchical clustering approaches, as well as methods for choosing the number of clusters like hypothesis testing, Bayesian estimation, and penalizing model complexity. Visualization techniques like multidimensional scaling and self-organizing maps are also summarized.
Space-efficient Feature Maps for String Alignment Kernels
Space-efficient Feature Maps for String Alignment KernelsYasuo Tabei This document proposes space-efficient feature maps for approximating string alignment kernels. It introduces edit-sensitive parsing (ESP) to map strings to integer vectors, and then uses feature maps to map the integer vectors to compact feature vectors. Linear SVMs trained on these feature vectors can achieve similar performance as non-linear SVMs using alignment kernels, with greatly improved scalability. Experimental results on real-world string datasets show the proposed method significantly reduces training time and memory usage compared to state-of-the-art string kernel methods, while maintaining high classification accuracy.
Lect4
Lect4sumit621 The document discusses various clustering algorithms and concepts:
1) K-means clustering groups data by minimizing distances between points and cluster centers, but it is sensitive to initialization and may find local optima.
2) K-medians clustering is similar but uses point medians instead of means as cluster representatives.
3) K-center clustering aims to minimize maximum distances between points and clusters, and can be approximated with a farthest-first traversal algorithm.
Unsupervised learning clustering
Unsupervised learning clusteringArshad Farhad This document discusses unsupervised learning and clustering. It defines unsupervised learning as modeling the underlying structure or distribution of input data without corresponding output variables. Clustering is described as organizing unlabeled data into groups of similar items called clusters. The document focuses on k-means clustering, describing it as a method that partitions data into k clusters by minimizing distances between points and cluster centers. It provides details on the k-means algorithm and gives examples of its steps. Strengths and weaknesses of k-means clustering are also summarized.
UnSupervised Machincs4811-ch23a-clustering.ppt
UnSupervised Machincs4811-ch23a-clustering.pptRamanamurthy Banda This document provides an overview of clustering techniques for probabilistic language processing. It discusses how clustering can be used to group similar examples or documents together based on a distance or similarity metric. Several clustering algorithms are described, including k-means clustering which assigns documents to clusters based on proximity to centroid points, and conceptual clustering which aims to represent clusters with general rules rather than just enumerating members. The document also discusses challenges like the curse of dimensionality for high-dimensional data and evaluating the optimal number of clusters k.
Ad
Recently uploaded (20)
The Influence off Flexible Work Policies
The Influence off Flexible Work Policiessales480687 This topic explores how flexible work policies—such as remote work, flexible hours, and hybrid models—are transforming modern workplaces. It examines the impact on employee productivity, job satisfaction, work-life balance, and organizational performance. The topic also addresses challenges such as communication gaps, maintaining company culture, and ensuring accountability. Additionally, it highlights how flexible work arrangements can attract top talent, promote inclusivity, and adapt businesses to an evolving global workforce. Ultimately, it reflects the shift in how and where work gets done in the 21st century.
All the DataOps, all the paradigms .
All the DataOps, all the paradigms .Lars Albertsson Data warehouses, lakes, lakehouses, streams, fabrics, hubs, vaults, and meshes. We sometimes choose deliberately, sometimes influenced by trends, yet often get an organic blend. But the choices have orders of magnitude in impact on operations cost and iteration speed. Let's dissect the paradigms and their operational aspects once and for all.
Data Visualisation in data science for students
Data Visualisation in data science for studentsconfidenceascend Data visualisation is explained in a simple manner.
Model Evaluation & Visualisation part of a series of intro modules for data ...
Model Evaluation & Visualisation part of a series of intro modules for data ...brandonlee626749 Model Evaluation & Visualisation part of a series of intro modules for data science
英国毕业证范本利物浦约翰摩尔斯大学成绩单底纹防伪LJMU学生证办理学历认证
英国毕业证范本利物浦约翰摩尔斯大学成绩单底纹防伪LJMU学生证办理学历认证 taqyed LJMU利物浦约翰摩尔斯大学毕业证书多少钱【q薇1954292140】1:1原版利物浦约翰摩尔斯大学毕业证+LJMU成绩单【q薇1954292140】完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。
【主营项目】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理毕业证|办理文凭: 买大学毕业证|买大学文凭【q薇1954292140】学位证明书如何办理申请?
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理利物浦约翰摩尔斯大学毕业证|LJMU成绩单【q薇1954292140】国外大学毕业证, 文凭办理, 国外文凭办理, 留信网认证
三.材料咨询办理、认证咨询办理请加学历顾问【微信:1954292140】毕业证购买指大学文凭购买,毕业证办理和文凭办理。学院文凭定制,学校原版文凭补办,扫描件文凭定做,100%文凭复刻。
Artigo - Playing to Win.planejamento docx
Artigo - Playing to Win.planejamento docxKellyXavier15 Excelente artifo para quem está iniciando processo de aquisiçãode planejamento estratégico
最新版意大利米兰大学毕业证(UNIMI毕业证书)原版定制
最新版意大利米兰大学毕业证(UNIMI毕业证书)原版定制taqyea 2025原版米兰大学毕业证书pdf电子版【q薇1954292140】意大利毕业证办理UNIMI米兰大学毕业证书多少钱?【q薇1954292140】海外各大学Diploma版本,因为疫情学校推迟发放证书、证书原件丢失补办、没有正常毕业未能认证学历面临就业提供解决办法。当遭遇挂科、旷课导致无法修满学分,或者直接被学校退学,最后无法毕业拿不到毕业证。此时的你一定手足无措,因为留学一场,没有获得毕业证以及学历证明肯定是无法给自己和父母一个交代的。
【复刻米兰大学成绩单信封,Buy Università degli Studi di MILANO Transcripts】
购买日韩成绩单、英国大学成绩单、美国大学成绩单、澳洲大学成绩单、加拿大大学成绩单(q微1954292140)新加坡大学成绩单、新西兰大学成绩单、爱尔兰成绩单、西班牙成绩单、德国成绩单。成绩单的意义主要体现在证明学习能力、评估学术背景、展示综合素质、提高录取率,以及是作为留信认证申请材料的一部分。
米兰大学成绩单能够体现您的的学习能力,包括米兰大学课程成绩、专业能力、研究能力。(q微1954292140)具体来说,成绩报告单通常包含学生的学习技能与习惯、各科成绩以及老师评语等部分,因此,成绩单不仅是学生学术能力的证明,也是评估学生是否适合某个教育项目的重要依据!
我们承诺采用的是学校原版纸张(原版纸质、底色、纹路)我们工厂拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有成品以及工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!
【主营项目】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理毕业证|办理文凭: 买大学毕业证|买大学文凭【q薇1954292140】米兰大学学位证明书如何办理申请?
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理意大利成绩单米兰大学毕业证【q薇1954292140】国外大学毕业证, 文凭办理, 国外文凭办理, 留信网认证
Shifting Focus on AI: How it Can Make a Positive Difference
Shifting Focus on AI: How it Can Make a Positive Difference1508 A/S This morgenbooster will share how to find the positive impact of AI and how to integrate it into your own digital process.
Starbucks in the Indian market through its joint venture.
Starbucks in the Indian market through its joint venture.sales480687 This topic focuses on the growth and challenges of Starbucks in the Indian market through its joint venture with Tata. It covers localization strategies, menu adaptations, expansion goals, and financial performance. The topic also examines consumer perceptions, market competition, and how Starbucks navigates economic and cultural factors in one of its most promising international markets.
YEAP !NOT WHAT YOU THINK aakshdjdncnkenfj
YEAP !NOT WHAT YOU THINK aakshdjdncnkenfjpayalmistryb Skdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnneodnrodndocndodnd0dndjxoxnxndkxnxkdndkxndkdjndnrnidnroz doendodnrodnxkdnrocngksjrndkdnr dnkxnddnkxndnrkdnxnxkdSkdnne
最新版美国佐治亚大学毕业证(UGA毕业证书)原版定制
最新版美国佐治亚大学毕业证(UGA毕业证书)原版定制Taqyea 2025原版佐治亚大学毕业证书pdf电子版【q薇1954292140】美国毕业证办理UGA佐治亚大学毕业证书多少钱?【q薇1954292140】海外各大学Diploma版本,因为疫情学校推迟发放证书、证书原件丢失补办、没有正常毕业未能认证学历面临就业提供解决办法。当遭遇挂科、旷课导致无法修满学分,或者直接被学校退学,最后无法毕业拿不到毕业证。此时的你一定手足无措,因为留学一场,没有获得毕业证以及学历证明肯定是无法给自己和父母一个交代的。
【复刻佐治亚大学成绩单信封,Buy The University of Georgia Transcripts】
购买日韩成绩单、英国大学成绩单、美国大学成绩单、澳洲大学成绩单、加拿大大学成绩单(q微1954292140)新加坡大学成绩单、新西兰大学成绩单、爱尔兰成绩单、西班牙成绩单、德国成绩单。成绩单的意义主要体现在证明学习能力、评估学术背景、展示综合素质、提高录取率,以及是作为留信认证申请材料的一部分。
佐治亚大学成绩单能够体现您的的学习能力,包括佐治亚大学课程成绩、专业能力、研究能力。(q微1954292140)具体来说,成绩报告单通常包含学生的学习技能与习惯、各科成绩以及老师评语等部分,因此,成绩单不仅是学生学术能力的证明,也是评估学生是否适合某个教育项目的重要依据!
我们承诺采用的是学校原版纸张(原版纸质、底色、纹路)我们工厂拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有成品以及工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!
【主营项目】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理毕业证|办理文凭: 买大学毕业证|买大学文凭【q薇1954292140】佐治亚大学学位证明书如何办理申请?
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理美国成绩单佐治亚大学毕业证【q薇1954292140】国外大学毕业证, 文凭办理, 国外文凭办理, 留信网认证
Ad
Text classification using Text kernels
- 1. Text Classification Using String Kernels Presented by Dibyendu Nath & Divya Sambasivan CS 290D : Spring 2014 Huma Lodhi, Craig Saunders, et al Department of Computer Science, Royal Holloway, University of London
- 2. Intro: Text Classification • Task of assigning a document to one or more categories. • Done manually (library science) or algorithmically (information science, data mining, machine learning). • Learning systems (neural networks or decision trees) work on feature vectors, transformed from the input space. • Text documents cannot readily be described by explicit feature vectors. lingua-systems.eu
- 3. Problem Definition • Input : A corpus of documents. • Output : A kernel representing the documents. • This kernel can then be used to classify, cluster etc. using existing algorithms which work on kernels, eg: SVM, perceptron. • Methodology : Find a mapping and a kernel function so that we can apply any of the standard kernel methods of classification, clustering etc. to the corpus of documents.
- 4. Overview • Motivation • Kernel Methods • Algorithms - with increasingly better efficiency • Approximation • Evaluation • Follow Up • Conclusion
- 5. Overview • Motivation • Kernel Methods • Algorithms - with increasingly better efficiency • Approximation • Evaluation • Follow Up • Conclusion
- 6. Motivation • Text documents cannot readily be described by explicit feature vectors. • Feature Extraction - Requires extensive domain knowledge - Possible loss of important information. • Kernel Methods – an alternative to explicit feature extraction
- 7. Overview • Motivation • Kernel Methods • Algorithms - with increasingly better efficiency • Approximation • Evaluation • Follow Up • Conclusion
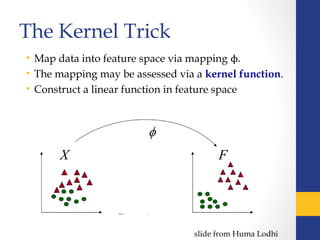
- 8. The Kernel Trick • Map data into feature space via mapping ϕ. • The mapping may be assessed via a kernel function. • Construct a linear function in feature space slide from Huma Lodhi
- 9. Kernel Function slide from Huma Lodhi Kernel Function – Measure of Similarity, returns the inner product between mapped data points K(xi, xj) = < Φ(xi), Φ(xj)> Example –
- 10. Kernels for Sequences • Word Kernels [WK] - Bag of Words - Sequence of characters followed by punctuation or space • N-Grams Kernel [NGK] • Sequence of n consecutive substrings • Example : “quick brown” 3-gram - qui, uic, ick, ck_, _br, bro, row, own • String Subsequence Kernel [SSK] • All (non-contiguous) substrings of n-symbols
- 11. Word Kernels • Documents are mapped to very high dimensional space where dimensionality of the feature space is equal to the number of unique words in the corpus. • Each entry of the vector represents the occurrence or non-occurrence of the word. • Kernel - inner product between mapped sequences give a sum over all common (weighted) words fish tank sea Doc 1 2 0 1 Doc 2 1 1 0
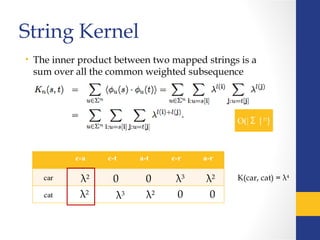
- 12. String Subsequence Kernels Basic Idea Non-contiguous substrings : substring “c-a-r” card – length of sequence = 3 custard – length of sequence = 6 The more subsequences (of length n) two strings have in common, the more similar they are considered Decay Factor Substrings are weighted according to the degree of contiguity in a string by a decay factor λ ∊ (0,1)
- 13. Example c-a c-t a-t c-r a-r car cat car cat Documents we want to compare λ2 λ2 λ3 0 0 λ2 λ2 λ3 0 0 K(car, car) = 2λ4 + λ6 K(cat, cat) = 2λ4 + λ6 n=2 K(car, cat) = K(car, cat) = λ4
- 14. Overview • Motivation • Kernel Methods • Algorithms - with increasingly better efficiency • Approximation • Evaluation • Follow Up • Conclusion
- 15. Algorithm Definitions • Alphabet Let Σ be the finite alphabet • String A string is a finite sequence of characters from alphabet with length |s| • Subsequence A vector of indices ij, sorted in ascending order, in a string ‘s’ such that they form the letters of a sequence Eg: ‘lancasters’ = [4,5,9] Length of subsequence = in – i1 +1 = 9 - 4 + 1 = 6
- 16. Algorithm Definitions • Feature Spaces • Feature Mapping The feature mapping φ for a string s is given by defining the u coordinate φu(s) for each u Σ∈ n These features measure the number of occurrences of subsequences in the string s weighting them according to their lengths.
- 17. String Kernel • The inner product between two mapped strings is a sum over all the common weighted subsequence λ2 λ2 λ3 0 0 λ2 λ2 λ3 0 0 K(car, cat) = λ4
- 18. Intermediate Kernel c-a c-t a-t c-r a-r car cat λ2 λ2 λ3 0 0 λ2 λ2λ3 0 0 λ3 λ3 Count the length from the beginning of the sequence through the end of the strings s and t. K’
- 19. Recursive Computation Null sub-string Target string is shorter than search sub-string
- 20. c-a c-t a-t c-r a-r car cat λ2 λ30 0 λ2 λ3 0 0 λ3 λ3 c-a c-t a-t c-r a-r cart 3 cat λ2 λ3 0 0λ3 s t sx t λ4 λλ40 0 K’(car,cat) = λ6 K’(cart,cat) = λ7 λ3λ4 +λ7 +λ5 K’ K’
- 21. λ2 λ2 λ3 0 0 λ2 λ2 λ3 0 0 K(car,cat) = λ4 s t c-a c-t a-t c-r a-r cart cat λ2 λ2 λ3 λ4 λ2 λ3 0 λ3 λ2 0 K(cart,cat) = λ4 sx t +λ7 +λ5 K K
- 22. Recursive Computation Null sub-string Target string is shorter than search sub-string O(n |s||t|2 ) O(n |s||t|) Dynamic Programming Recursion
- 23. Efficiency O(|Σ|n ) O(n |s||t|) O(n |s||t|2 ) All subsequences of length n.
- 26. Overview • Motivation • Kernel Methods • Algorithms - with increasingly better efficiency • Approximation • Evaluation • Follow Up • Conclusion
- 27. Kernel Approximation Suppose, we have some training points (x i , y i ) X × Y∈ , and some kernel function K(x,z) corresponding to a feature space mapping φ : X → F such that K(x, z) = φ(x), φ(z)⟨ ⟩. Consider a set S of vectors S = {s i X }∈ . If the cardinality of S is equal to the dimensionality of the space F and the vectors φ(s i ) are orthogonal *
- 28. Kernel Approximation If instead of forming a complete orthonormal basis, the cardinality of S S is less than the dimensionality of X or thẽ ⊆ vectors si are not fully orthogonal, then we can construct an approximation to the kernel K: If the set S is carefully constructed, then the production of ã Gram matrix which is closely aligned to the true Gram matrix can be achieved with a fraction of the computational cost. Problem : Choose the set S to ensure that the vectors φ(s̃ i) are orthogonal.
- 29. Selecting Feature Subset Heuristic for obtaining the set S is as follows:̃ 1.We choose a substring size n. 2.We enumerate all possible contiguous strings of length n. 3.We choose the x strings of length n which occur most frequently in the dataset and this forms our set S .̃ By definition, all such strings of length n are orthogonal (i.e. K(si,sj) = Cδij for some constant C) when used in conjunction with the string kernel of degree n.
- 31. Overview • Motivation • Kernel Methods • Algorithms - with increasingly better efficiency • Approximation • Evaluation • Follow Up • Conclusion
- 32. Evaluation Dataset : Reuters-21578, ModeApte Split Categoried Selected: Precision = relevant documents categorized relevant / total documents categorized relevant Recall = relevant documents categorized relevant/total relevant documents F1 = 2*Precision*Recall/Precision+R ecall
- 33. Evaluation
- 34. Evaluation
- 35. Evaluation Effectiveness of Sequence Length [k = 7] [k = 5] [k = 6] [k = 5] [k = 5] [k = 5][k = 5] [k = 5]
- 36. Evaluation Effectiveness of Decay Factor λ = 0.3 λ = 0.03 λ = 0.05 λ = 0.03
- 37. Overview • Motivation • Kernel Methods • Algorithms - with increasingly better efficiency • Approximation • Evaluation • Follow Up • Conclusion
- 38. Follow Up • String Kernel using sequences of words rather than characters, less computationally demanding, no fixed decay factor, combination of string kernels Cancedda, Nicola, et al. "Word sequence kernels." The Journal of Machine Learning Research 3 (2003): 1059-1082. • Extracting semantic relations between entities in natural language text, based on a generalization of subsequence kernels. Bunescu, Razvan, and Raymond J. Mooney. "Subsequence kernels for relation extraction." NIPS. 2005.
- 39. Follow Up •Homology – Computational biology method to identify the ancestry of proteins. Model should be able to tolerate upto m-mismatches. The kernels used in this method measure sequence similarity based on shared occurrences of k-length subsequences, counted with up to m-mismatches.
- 40. Overview • Motivation • Kernel Methods • Algorithms - with increasingly better efficiency • Approximation • Evaluation • Follow Up • Conclusion
- 41. Conclusion Key Idea: Using non-contiguous string subsequences to compute similarity between documents with a decay factor which discounts similarity according to the degree of contiguity •Highly computationally intensive method – authors reduced the time complexity from O(|Σ|n ) to O(n|s||t|) by a dynamic programming approach •Still less intensive method – Kernel Approximation by Feature Subset Selection. •Empirical estimation of k and λ, from experimental results •Showed promising results only for small datasets •Seems to mimic stemming for small datasets
- 42. Any Q? Thank You :)