How Kafka and Modern Databases Benefit Apps and Analytics
Download as pptx, pdf1 like374 views

This document provides an overview of how Kafka and modern databases like MemSQL can benefit applications and analytics. It discusses how businesses now require faster data access and intra-day processing to drive real-time decisions. Traditional database solutions struggle to meet these demands. MemSQL is presented as a solution that provides scalable SQL, fast ingestion of streaming data, and high concurrency to enable both transactions and analytics on large datasets. The document demonstrates how MemSQL distributes data and queries across nodes and allows horizontal scaling through its architecture.



































![[memsql.cnf]
master-agg=agg-1
1
2
3
4
Database Client
AggregatorAggregator
LeafLeafLeafLeaf
PARTITIONS PARTITIONS PARTITIONS PARTITIONS
Aggregators too](https://image.slidesharecdn.com/howkafkaandmoderndatabasesbenefitappsandanalytics-180823215340/85/How-Kafka-and-Modern-Databases-Benefit-Apps-and-Analytics-37-320.jpg)












How Kafka and Modern Databases Benefit Apps and Analytics
- 1. How Kafka and Modern Databases Benefit Apps and Analytics 1 Neil Dahlke, Sr. Sales Engineer, San Francisco August 20 2018
- 2. 2 ● Intro ● Possible Solutions ● New Data Architecture ● Scalable SQL ● CREATE PIPELINE ● Demo ● Q&A Agenda
- 3. Intro 3
- 4. AT MEMSQL Sr. Sales Engineer, San Francisco BEFORE MEMSQL Worked on Globus project out @ University of Chicago PREVIOUS TALKS Real Time, Geospatial, Maps Image Recognition on Streaming Real Time w/ Spark & MemSQL 4 Who am I?
- 5. 5 “Companies with data-driven environments have up to 50% higher market value than other businesses.”
- 6. 6 Organizations want more of their data to support faster decisions and optimize customer experiences This is putting pressure on database performance and scalability but without sacrificing familiar tooling and skills Data Driven Requirements Driving Database Modernization
- 7. 7 Businesses Require Intra-Day Slow Data Loading Batch processing Hours to load Sampled data views
- 8. 8 Growing Data Slows Performance Lengthy Query Execution Slow query responses Slow reports No real-time response
- 9. 9 Data Access Requirements Surging Limited User Access Single threaded operations Challenge with mixed workloads Single box performance
- 10. 10 Multi / Hybrid Cloud Strategy ● Existing solutions have unclear path to cloud ● Data growing exponentially year over year ● Still managing on-premises data ● Requires database to run anywhere
- 12. More CPUs or memory Specialized HW racks Database Options Boost hardware or add more DB options introduces cost 12 Double Down on Existing Database
- 13. Adding data grids, caches, and accelerators introduces complexity 13 Introduce Caching Tiers Limited data durability Weak SQL coverage Another layer To manage
- 14. 14 Try Object Store based NoSQL Solutions Slow performing analytics Developer intensive queries Breaks BI tool compatibility
- 15. 15 Latency Holding Back the Enterprise Lengthy Query Execution Slow query responses Slow reports No real-time response Limited User Access Single threaded operations Challenge with mixed workloads Single box performance Slow Data Loading Batch processing Hours to load Sampled data views
- 16. 16 The Enterprise Requires Performance Fast Queries Scalable ANSI SQL Petabyte scale Live and historical insights Scalable User Access Scale-out for performance Converged transactions and analytics Multi-threaded processing Live Loading Stream data On-the-fly transformation Multiple sources
- 17. MemSQL: The No Limits Database17 For Every Workload and Infrastructure On-premises or any cloud Transactions and analytics Familiar, standard scalable SQL Distributed architecture Relational ANSI SQL Performance for Demanding Applications Fast ingest Low latent queries
- 18. Ecosystem Overview High Speed Ingest Memory Optimized Rowstore Disk Optimized Columnstore Real-Time Data Messaging and Transforms Data Inputs BI Dashboards Kafka Spark Relational Hadoop Amazon S3 Bare Metal, Virtual Machines, Containers On-Premises, Multi-Cloud, Hybrid Cloud Real-Time Applications Tableau Looker Microstrategy 18 Relational Key-Value Document Geospatial
- 20. 20
- 21. 21
- 22. 22
- 23. 23
- 24. 24
- 25. 25
- 26. 26
- 27. 14 MemSQL: The No-Limits Database ● Massive Scale ● Query Performance ● High Concurrency The transactional scale of NoSQL with familiar relational SQL for fast analytics
- 28. Scalable SQL 28
- 29. MemSQL is a database, a Linux daemon ./memsqld
- 30. MemSQL is a distributed system ./memsqld./memsqld ./memsqld
- 32. Leaves Hold Partitions and Process Data ./memsqld./memsqld Aggregator LeafLeaf PARTITIONS Leaf PARTITIONS
- 33. Aggregators interact with clients and leverage leaf nodes aggregator-1> create database foo; Query OK, 1 row affected (5.48 sec) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Database Client LeafLeaf PARTITIONS PARTITIONS Aggregator
- 34. leaf-2> show databases; +--------------------+ | Database | +--------------------+ | cluster | | foo | | foo_1 | | foo_3 | | foo_5 | | foo_7 | | foo_9 | | foo_11 | | information_schema | | memsql | +--------------------+ 10 rows in set (0.01 sec) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Database Client LeafLeaf PARTITIONS PARTITIONS Aggregator Leaves store a partition per core on the machine (by default)
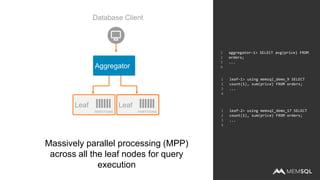
- 35. aggregator-1> SELECT avg(price) FROM orders; ... 1 2 3 4 leaf-1> using memsql_demo_9 SELECT count(1), sum(price) FROM orders; ... 1 2 3 4 leaf-2> using memsql_demo_17 SELECT count(1), sum(price) FROM orders; ... 1 2 3 4 Database Client LeafLeaf PARTITIONS PARTITIONS Aggregator Massively parallel processing (MPP) across all the leaf nodes for query execution
- 36. aggregator-1> ADD LEAF leaf-3… aggregator-1> REBALANCE PARTITIONS; 1 2 3 4 Database Client Aggregator LeafLeafLeafLeaf PARTITIONS PARTITIONS PARTITIONS PARTITIONS aggregator-1> ADD LEAF leaf-4… aggregator-1> REBALANCE PARTITIONS; 1 2 3 4 Scale up and down on the fly
- 37. [memsql.cnf] master-agg=agg-1 1 2 3 4 Database Client AggregatorAggregator LeafLeafLeafLeaf PARTITIONS PARTITIONS PARTITIONS PARTITIONS Aggregators too
- 38. Apache Kafka38 ● Messaging Queue ● Distributed ● Durable ● Publish-Subscribe ● Process ● “Source of Truth” ● Open Source
- 39. Deliver Faster Insights ● Scalable ANSI SQL ● Full ACID capabilities ● Support for JSON, Geospatial, and Full-Text Search ● Fast Query Vectorization and Compilation ● Extensibility with Stored Procedures, UDFs, UDAs 39
- 40. Fast Data Ingestion ● Stream ingestion ● Fast parallel bulk loading ● Built-in Create Pipeline ● Transactional Consistency ● Exactly-Once Semantics ● Native integrations with Kafka, AWS S3, Azure Blob, HDFS 40
- 41. 41 Stream ingestion Batch loading Fully parallel Arbitrary transforms Any language Transactional consistency Exactly-once semantics CREATE PIPELINE
- 42. 42 1 2 3 4 5 6 7 CREATE PIPELINE twitter_pipeline AS LOAD DATA KAFKA "public-kafka.memcompute.com:9092/tweets-json" INTO TABLE tweets WITH TRANSFORM (‘/path/to/executable’, ‘arg1’, ‘arg2’) (id, tweet); START PIPELINE twitter_pipeline;
- 43. 43 Data Source (ex: NFS, S3, HDFS, Kafka) MemSQLPIPELINE MemSQL polls for changes from a source system.1 1
- 44. 44 Data Source (ex: NFS, S3, HDFS, Kafka) MemSQLPIPELINE MemSQL polls for changes from a source system. MemSQL pulls the data into it’s memory space (no commit) where a transform can be applied. 1 2 1 2
- 45. 45 Data Source (ex: NFS, S3, HDFS, Kafka) MemSQLPIPELINE MemSQL polls for changes from a data source system. MemSQL pulls the data into it’s memory space (no commit) where a transform can be applied. The data is committed in a transaction (and in parallel) 1 1 3 3 2 2
- 46. 46 LeafPIPELINE Kafka Broker 1 Kafka Broker 2 Kafka Broker 3 Kafka Broker 4 LeafPIPELINE LeafPIPELINE LeafPIPELINE Data reshuffle AggregatorPIPELINE Metadata query
- 47. Demo 47
- 48. Q&A 48
- 49. Thank You