Using GPUs to Handle Big Data with Java
9 likes4,192 views

The document discusses the use of GPUs for handling big data with Java, emphasizing the capabilities of modern GPUs as general-purpose processors that can outperform CPUs in parallel processing tasks. It outlines the programming model for integrating GPU capabilities into Java applications, particularly using NVIDIA's CUDA, and presents examples such as k-means clustering for data analysis. The presentation concludes with insights on optimizing standard Java APIs for GPU usage, highlighting potential speed-ups for large data sets.







![CUDA – a simple example
Vector addition
a b c
++
+
=
==
+
++
===
Serially on the CPU...
void add( int *a, int *b, int *c ) {
for (i=0; i < N; i++) {
c[i] = a[i] + b[i];
}
}
On the CPU ...
void cuda_add(int *a, int *b, int *c) {
int *dev_a, *dev_b, *dev_c;
int len = N*sizeof(int);
cudaMalloc((void**)&dev_a, len);
cudaMalloc((void**)&dev_b, len);
cudaMalloc((void**)&dev_c, len);
cudaMemcpy(dev_a, a, len, cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, len, cudaMemcpyHostToDevice);
add<<<N,1>>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, len, cudaMemcpyDeviceToHost);
cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c);
}
...and GPU
__global__ void add(int *a, int *b, int *c) {
int tid = blockIdx.x;
c[tid] = a[tid] + b[tid];
}
© 2014 8 IBM Corporation](https://image.slidesharecdn.com/javaone2014-gpu-141005170142-conversion-gate01/85/Using-GPUs-to-Handle-Big-Data-with-Java-8-320.jpg)
![A simple example
void cuda_add(int *a, int *b, int *c) {
int *dev_a, *dev_b, *dev_c;
int len = N*sizeof(int);
cudaMalloc((void**)&dev_a, len);
cudaMalloc((void**)&dev_b, len);
cudaMalloc((void**)&dev_c, len);
cudaMemcpy(dev_a, a, len, cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, len, cudaMemcpyHostToDevice);
add<<<N,1>>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, len, cudaMemcpyDeviceToHost);
cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c);
}
__global__ void add(int *a, int *b, int *c) {
int tid = blockIdx.x;
c[tid] = a[tid] + b[tid];
}
a b c
+
++
===
+++
===
Language extension to
invoke our kernel with 'N'
blocks executing in parallel
one thread per block
Identify your block number
Add the single element whose
index matches your block number
© 2014 9 IBM Corporation](https://image.slidesharecdn.com/javaone2014-gpu-141005170142-conversion-gate01/85/Using-GPUs-to-Handle-Big-Data-with-Java-9-320.jpg)
![A simple example – the effect at runtime
void cuda_add(int *a, int *b, int *c) {
int *dev_a, *dev_b, *dev_c;
int len = N*sizeof(int);
cudaMalloc((void**)&dev_a, len);
cudaMalloc((void**)&dev_b, len);
cudaMalloc((void**)&dev_c, len);
cudaMemcpy(dev_a, a, len, cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, len, cudaMemcpyHostToDevice);
add<<<N,1>>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, len, cudaMemcpyDeviceToHost);
cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c);
}
__global__ void add(int *a,...
c[2] = a[2] + b[2];
__g}lobal__ void add(int *a,...
c[1] = a[1] + b[1];
__g}lobal__ void add(int *a,...
c[0] = a[0] + b[0];
Grid of 'N' blocks
executing in parallel
© 2014 10 IBM Corporation
}](https://image.slidesharecdn.com/javaone2014-gpu-141005170142-conversion-gate01/85/Using-GPUs-to-Handle-Big-Data-with-Java-10-320.jpg)







![GPU-enabling standard Java SE APIs
Natural question after seeing the good speed-ups using explicit programming …
What areas of the standard Java API implementation are suitable for off-loading onto GPU?
We picked two candidates initially:
java.util.Arrays.sort(int[] a) and friends
– GPU modules exist that do efficient sorting
java.nio.charset.CharsetEncoder
– data-driven character set mapping of Strings
IBM Developer Kits for Java
ibm.com/java/jdk
© 2014 19 IBM Corporation](https://image.slidesharecdn.com/javaone2014-gpu-141005170142-conversion-gate01/85/Using-GPUs-to-Handle-Big-Data-with-Java-19-320.jpg)



![Beyond specific APIs – Java 8 streams
Streams allow developers to express computation as aggregate parallel operations on data
For example:
IntStream.range(0, N).parallel().forEach(i >
c[i] = a[i] + b[i]);
creates a stream whose operations can be executed in parallel
What if we could recognize the terminal operation and conduct it on the GPU?
Reuses standard Java idioms, so no code changes required
No knowledge of GPU programming model required by the application developer
But no low-level manipulation of the device – the Java implementation has the controls
Future smarts introduced into the JIT do not require application code changes
© 2014 23 IBM Corporation](https://image.slidesharecdn.com/javaone2014-gpu-141005170142-conversion-gate01/85/Using-GPUs-to-Handle-Big-Data-with-Java-23-320.jpg)





Using GPUs to Handle Big Data with Java
- 1. Tim Ellison – IBM Java Technology Center October 2nd, 2014 Using GPUs to Handle Big Data with Java CON3285 © 2014 IBM Corporation
- 2. © 2014 IBM Corporation Important Disclaimers THE INFORMATION CONTAINED IN THIS PRESENTATION IS PROVIDED FOR INFORMATIONAL PURPOSES ONLY. WHILST EFFORTS WERE MADE TO VERIFY THE COMPLETENESS AND ACCURACY OF THE INFORMATION CONTAINED IN THIS PRESENTATION, IT IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. ALL PERFORMANCE DATA INCLUDED IN THIS PRESENTATION HAVE BEEN GATHERED IN A CONTROLLED ENVIRONMENT. YOUR OWN TEST RESULTS MAY VARY BASED ON HARDWARE, SOFTWARE OR INFRASTRUCTURE DIFFERENCES. ALL DATA INCLUDED IN THIS PRESENTATION ARE MEANT TO BE USED ONLY AS A GUIDE. IN ADDITION, THE INFORMATION CONTAINED IN THIS PRESENTATION IS BASED ON IBM’S CURRENT PRODUCT PLANS AND STRATEGY, WHICH ARE SUBJECT TO CHANGE BY IBM, WITHOUT NOTICE. IBM AND ITS AFFILIATED COMPANIES SHALL NOT BE RESPONSIBLE FOR ANY DAMAGES ARISING OUT OF THE USE OF, OR OTHERWISE RELATED TO, THIS PRESENTATION OR ANY OTHER DOCUMENTATION. NOTHING CONTAINED IN THIS PRESENTATION IS INTENDED TO, OR SHALL HAVE THE EFFECT OF: - CREATING ANY WARRANT OR REPRESENTATION FROM IBM, ITS AFFILIATED COMPANIES OR ITS OR THEIR SUPPLIERS AND/OR LICENSORS 2
- 3. About me Based in the Java Technology Centre, Hursley UK Working on various runtime technologies for >20 years Experience of open source communities Currently focused on class library design and delivery Overall technical lead for IBM Java 8 SE [email protected] @tpellison © 2014 3 IBM Corporation
- 4. Goals of this talk Provide an introduction to programming with GPUs Show how we can bring a popular GPU programming model to Java Demonstrate the effect of GPUs on solving Big Data problems Describe seamlessly enabling the Java implementation to use GPUs © 2014 4 IBM Corporation
- 5. Introduction to Graphics Processing Units GPUs are no longer solely targeted at single purpose graphical operations such as rendering and texture mapping Modern high-end GPUs are general purpose “stream processors” Provide substantially more FLOPs per $ and per watt than CPUs Programming language extensions allow a flow of control from the CPU to the single instruction, multiple thread (SIMT) engine © 2014 5 IBM Corporation
- 6. Harnessing the power of GPUs Theoretical GFLOP/s With their massively parallel architecture, GPUs far exceed the computational power of CPUs when operating on large sets of floating point numbers. How can we bring this capability to Java? http://docs.nvidia.com/cuda/cudacprogrammingguide © 2014 6 IBM Corporation
- 7. Introduction to Programming GPUs Typical scenario for heterogeneous programming: – Host computer with CPU(s) and GPU(s) installed on PCIe bus – Programmer identifies parallelizable, compute intensive routine, and codes to GPU – Flow of data and control passes between CPU host and GPU device under control of host device Particularly suited to scientific and numerical analysis problems (e.g. linear algebra) We have focused on Nvidia CUDA as the programming model for exploiting GPUs. © 2014 7 IBM Corporation
- 8. CUDA – a simple example Vector addition a b c ++ + = == + ++ === Serially on the CPU... void add( int *a, int *b, int *c ) { for (i=0; i < N; i++) { c[i] = a[i] + b[i]; } } On the CPU ... void cuda_add(int *a, int *b, int *c) { int *dev_a, *dev_b, *dev_c; int len = N*sizeof(int); cudaMalloc((void**)&dev_a, len); cudaMalloc((void**)&dev_b, len); cudaMalloc((void**)&dev_c, len); cudaMemcpy(dev_a, a, len, cudaMemcpyHostToDevice); cudaMemcpy(dev_b, b, len, cudaMemcpyHostToDevice); add<<<N,1>>>(dev_a, dev_b, dev_c); cudaMemcpy(c, dev_c, len, cudaMemcpyDeviceToHost); cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c); } ...and GPU __global__ void add(int *a, int *b, int *c) { int tid = blockIdx.x; c[tid] = a[tid] + b[tid]; } © 2014 8 IBM Corporation
- 9. A simple example void cuda_add(int *a, int *b, int *c) { int *dev_a, *dev_b, *dev_c; int len = N*sizeof(int); cudaMalloc((void**)&dev_a, len); cudaMalloc((void**)&dev_b, len); cudaMalloc((void**)&dev_c, len); cudaMemcpy(dev_a, a, len, cudaMemcpyHostToDevice); cudaMemcpy(dev_b, b, len, cudaMemcpyHostToDevice); add<<<N,1>>>(dev_a, dev_b, dev_c); cudaMemcpy(c, dev_c, len, cudaMemcpyDeviceToHost); cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c); } __global__ void add(int *a, int *b, int *c) { int tid = blockIdx.x; c[tid] = a[tid] + b[tid]; } a b c + ++ === +++ === Language extension to invoke our kernel with 'N' blocks executing in parallel one thread per block Identify your block number Add the single element whose index matches your block number © 2014 9 IBM Corporation
- 10. A simple example – the effect at runtime void cuda_add(int *a, int *b, int *c) { int *dev_a, *dev_b, *dev_c; int len = N*sizeof(int); cudaMalloc((void**)&dev_a, len); cudaMalloc((void**)&dev_b, len); cudaMalloc((void**)&dev_c, len); cudaMemcpy(dev_a, a, len, cudaMemcpyHostToDevice); cudaMemcpy(dev_b, b, len, cudaMemcpyHostToDevice); add<<<N,1>>>(dev_a, dev_b, dev_c); cudaMemcpy(c, dev_c, len, cudaMemcpyDeviceToHost); cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c); } __global__ void add(int *a,... c[2] = a[2] + b[2]; __g}lobal__ void add(int *a,... c[1] = a[1] + b[1]; __g}lobal__ void add(int *a,... c[0] = a[0] + b[0]; Grid of 'N' blocks executing in parallel © 2014 10 IBM Corporation }
- 11. Goal: Bringing GPU programming into Java There are times when you want this low level GPU control from Java Produce an API that reflects the concepts familiar in CUDA programming Make use of Java exceptions, automatic resource management, etc. Handle copying data to/from the GPU, flow of control from Java to GPU and back, etc Ability to invoke existing GPU module code from Java applications e.g. Thrust CudaDevice – a CUDA capable GPU device CudaBuffer – a region of memory on the GPU CudaModule – user library of kernels to load into GPU CudaKernel – for launching a device function CudaFunction – a kernel's entry point CudaEvent – for timing and synchronization CudaException – for when something goes wrong new Java APIs © 2014 11 IBM Corporation
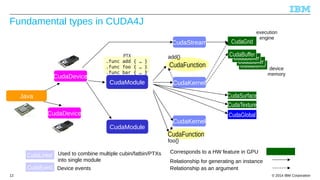
- 12. Fundamental types in CUDA4J CudaGrid execution engine CuCduadBauBffuefrfer CCuuddaaBBuufffeferr PTX .func add { … } .func foo { … } .func bar { … } CudaDevice CudaStream add{} CudaModule CudaKernel Java CudaSurface CudaDevice CudaLinker CudaEvent CudaFunction CudaTexture CudaGlobal CudaKernel Used to combine multiple cubin/fatbin/PTXs into single module Device events CudaModule CudaFunction foo{} Corresponds to a HW feature in GPU Relationship for generating an instance Relationship as an argument device memory © 2014 12 IBM Corporation
- 13. first GPU device native module containing the kernel grid of kernels that will execute this task move data from Java heap to device invoke the task Explicit GPU vector addition in Java move the result back to the Java heap © 2014 13 IBM Corporation
- 14. Limitations and considerations Allows developers to code explicitly for the GPU – These are new APIs that give close control of the device – Uses familiar concepts and paradigms for GPU experts – Convenience and productivity improvements from language – Fundamental building blocks for higher level algorithms Requires the developer to identify suitable GPU workloads – Re-code routines to operate on data in parallel – Minimize branching flow of control in kernels Amortizing overhead of moving work to GPU – Time taken to copy data between host and device over PCIe – Overhead of switching flow of control from CPU to GPU © 2014 14 IBM Corporation Flickr: Gareth Halfacree
- 15. Applying GPUs to Big Data problems Large retailers are collecting petabytes of information based on customer transactions. Can we identify customers with similar behavior, such that retailers can create customized products, effective marketing campaigns, etc? Businesses that react quickly to changes in market segments have an advantage. Challenge: Can we bring the power of GPUs to big data problems written in Java? Problem: Identify 20 – 25 year olds who are interested in smart phone products Solution: Put a K-means algorithm onto the GPU to identify clusters in large dataset – Apache Mahout is a machine learning library for clustering and collaboration built on Apache Hadoop © 2014 15 IBM Corporation
- 16. K-means clustering – finding groups of data points Problem: Iteratively refine the location of 'K' loci, identifying clusters of 'N' data points, where each data point has 'D' dimensions Approach: For each data point, which of the loci is closest? – NP-hard problem requiring N x K x D independent operations – Adjust K loci and iterate towards a stable answer The map computation can be parallelized (at a finer granularity than managed by Apache Hadoop) A new GPU-enabled mapper class was created: – batches of points are transferred from Java to a GPU for mapping – a partial reduction is returned to the host – a single Apache Mahout class was modified – to use our new mapper class Wikimedia: Chire © 2014 16 IBM Corporation
- 17. Mapper speed-up GPU vs. CPU – Speed-up factor just doing the map/reduce for different values of K and D – Baseline is standard Apache Mahout implementation on CPU – Comparison excludes Apache Hadoop framework and I/O Number of loci being considered Speed-up multiplier for GPU compared to CPU Number of variables per data point End-to-end speed-up solving the problem was ~8x IBM Power 8 with Nvidia K40m GPU © 2014 17 IBM Corporation
- 18. © 2014 18 IBM Corporation
- 19. GPU-enabling standard Java SE APIs Natural question after seeing the good speed-ups using explicit programming … What areas of the standard Java API implementation are suitable for off-loading onto GPU? We picked two candidates initially: java.util.Arrays.sort(int[] a) and friends – GPU modules exist that do efficient sorting java.nio.charset.CharsetEncoder – data-driven character set mapping of Strings IBM Developer Kits for Java ibm.com/java/jdk © 2014 19 IBM Corporation
- 20. GPU-enhanced sorting from Java – heuristics We employ heuristics that determine if the work should be off-loaded to the GPU. Overhead of moving data to GPU, invoking kernel, and returning results means small sorts (<~20k elements) are faster on the CPU. Host may have multiple GPUs. Are any available for the task? Is there space for conducting the sort on the device? Arrays.sort(myData); Is the problem large enough? yes Is there a GPU currently available? yes Is the device capable? yes no no no Sort on GPU Sort on CPU © 2014 20 IBM Corporation
- 21. GPU-enabled array sort method IBM Power 8 with Nvidia K40m GPU © 2014 21 IBM Corporation
- 22. GPU-enabled charset conversion Did not achieve speed-ups on charset encoding/decoding Cost of moving the data to/from GPU outweighed the benefit We have spent effort optimizing the CPU version with a number of JIT specials Rule of thumb on the system we have is that you need to execute 'tens of instructions per data point' on the GPU in order to see a benefit over the CPU Flickr: rifqidahlgren © 2014 22 IBM Corporation
- 23. Beyond specific APIs – Java 8 streams Streams allow developers to express computation as aggregate parallel operations on data For example: IntStream.range(0, N).parallel().forEach(i > c[i] = a[i] + b[i]); creates a stream whose operations can be executed in parallel What if we could recognize the terminal operation and conduct it on the GPU? Reuses standard Java idioms, so no code changes required No knowledge of GPU programming model required by the application developer But no low-level manipulation of the device – the Java implementation has the controls Future smarts introduced into the JIT do not require application code changes © 2014 23 IBM Corporation
- 24. JIT optimized GPU acceleration As the JIT compiles a stream expression we can identify candidates for GPU off-loading – Arrays copied to and from the device implicitly – Java operations mapped to GPU kernel operations – Preserves the standard Java syntax and semantics bytecodes Early steps – Recognize a limited set of operations within the lambda expressions, • notably no object references maintained on GPU – Default grid dimensions and operating parameters for the GPU workload – Redundant/pessimistic data transfer between host and device • Not using GPU shared memory – Limited heuristics about when to invoke the GPU and when to generate CPU instructions intermediate representation optimizer code generator code generator CPU native PTX ISA CPU GPU © 2014 24 IBM Corporation
- 25. JIT / GPU optimization of Lambda expression JIT recognized Java code for matrix multiplication using Java 8 parallel stream Speed-up factor when run on a GPU enabled host IBM Power 8 with Nvidia K40m GPU © 2014 25 IBM Corporation
- 26. Conclusions ✔ GPUs provide a powerful co-processor suited to handling large amounts of data ✔Workloads need to be carefully chosen to exploit the GPU's specific capabilities ✔ Custom APIs make the GPU accessible to Java application developers ✔ IBM's Java implementation is introducing heuristics to off-load calls to standard library APIs from CPU to GPU ✔ JIT optimization of user code will increasingly move your application code to custom co-processors, including GPU ✔We have seen good speed-ups of around 8x to 10x with real world Big Data applications running on GPU devices © 2014 26 IBM Corporation
- 27. http://ibm.biz/javaone2014 © 2014 27 IBM Corporation
- 28. Copyright and Trademarks © IBM Corporation 2014. All Rights Reserved. IBM, the IBM logo, and ibm.com are trademarks or registered trademarks of International Business Machines Corp., and registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the Web – see the IBM “Copyright and trademark information” page at URL: www.ibm.com/legal/copytrade.shtml © 2014 28 IBM Corporation