[OracleCode SF] In memory analytics with apache spark and hazelcast
2 likes623 views

The document discusses the integration of Apache Spark with Hazelcast's in-memory data grid, highlighting the speed advantages of Spark and its fault-tolerance with resilient distributed datasets (RDDs). It provides code examples for configuration and uses cases, emphasizing parallel processing and operational benefits. Additionally, it mentions limitations regarding data updates while reading from Spark, suggesting potential issues like cursor inaccuracies.
1 of 42
Downloaded 22 times









































Ad
Recommended
[OracleCode - SF] Distributed caching for your next node.js project
[OracleCode - SF] Distributed caching for your next node.js projectViktor Gamov The document discusses the benefits of distributed caching in Node.js projects, highlighting its advantages for performance, scalability, and architectural efficiency. It emphasizes the importance of offloading expensive processes and suggests using caching to enhance system capability by either scaling up with single machines or scaling out with multiple machines. The author encourages developers to consider cache implementation as it is often quick and simple to apply.
Spark!
Spark!Przemek Maciolek This document discusses Spark, an open-source cluster computing framework. It notes that while Hadoop is useful for batch processing, it has limitations for interactive and iterative algorithms. Spark addresses these issues through its resilient distributed datasets (RDDs) which can be operated on in parallel and rebuilt if lost. RDDs support transformations like map and filter as well as actions that return values. The document provides examples of using Spark from Scala and discusses its architecture involving a DAG scheduler and task scheduler.
Ignite Your Big Data With a Spark!
Ignite Your Big Data With a Spark!Progress Apache Spark is a fast platform for large-scale data processing, significantly outperforming Hadoop with superior speed and versatility. Spark SQL offers integration of SQL queries and compatibility with various data sources, enhancing big data analytics. Datadirect drivers provide high-performance connectivity, enabling real-time analytics and improved business insights.
Dynamic Class-Based Spark Workload Scheduling and Resource Using YARN with L...
Dynamic Class-Based Spark Workload Scheduling and Resource Using YARN with L...Databricks The document discusses a solution by Mitylytics for dynamic class-based Spark workload scheduling and resource management using YARN in multi-tenant environments. It highlights existing challenges in job prioritization and lack of fine granularity controls, and presents a proactive scheduling solution that integrates machine learning for effective resource management without requiring code changes. The conclusion emphasizes that intelligent and automated scheduling can optimize job workflows based on infrastructure and workload analysis.
Accelerating Spark Genome Sequencing in Cloud—A Data Driven Approach, Case St...
Accelerating Spark Genome Sequencing in Cloud—A Data Driven Approach, Case St...Spark Summit The document discusses the transition of Spark deployments from on-premises to cloud environments, highlighting the benefits of elasticity and manageability while addressing performance challenges due to resource repartitioning. It emphasizes the importance of profiling applications to optimize performance and includes case studies demonstrating performance improvements through code changes in Spark and Scala. Key issues addressed include IO wait times, lock contention, and garbage collection performance tuning.
10 Things About Spark
10 Things About Spark Roger Brinkley The document outlines ten notable features of Apache Spark, emphasizing its speed, open-source nature, and strong integration with major data ecosystems. Spark is highlighted for its scalable performance, essential API stability, enterprise applicability, and security integration. Additionally, it mentions events and resources for learning about Apache Spark.
Spark, Tachyon and Mesos internals
Spark, Tachyon and Mesos internalsClaudiu Barbura The document discusses the internals of Spark, Tachyon, and Mesos, highlighting their architectures and performance considerations. It includes insights on data pipelines, job management, and the integration of components within these frameworks. Additionally, it addresses various technical challenges such as framework starvation and storage management while providing links to relevant resources and patches.
Hadoop at ayasdi
Hadoop at ayasdiMohit Jaggi The document provides an overview of Ayasdi's use of Hadoop, highlighting HDFS for storage, YARN for integration, and Parquet as the file format. It discusses the challenges and motivations behind using these technologies, the development of the BigDF framework for feature engineering, and its future direction. Additionally, it addresses the audience's background and experiences with big data tools during an interactive poll.
GPS Insight on Using Presto with Scylla for Data Analytics and Data Archival
GPS Insight on Using Presto with Scylla for Data Analytics and Data ArchivalScyllaDB The document discusses data analytics and archival solutions using Presto and Scylla, presented by Doug Stuns, a seasoned database architect. GPS Insight employs a 3 DC, 18 node Scylla cluster on AWS to manage significant amounts of diagnostic and GPS vehicle data, utilizing Presto for ad-hoc querying and data archival. Challenges related to querying non-partition keys are addressed, alongside a detailed installation guide for Presto in AWS EC2.
Scylla @ GumGum: Contextual Ads
Scylla @ GumGum: Contextual AdsScyllaDB The document outlines GumGum's contextual advertising capabilities, detailing the infrastructure and challenges faced by the ad server team, managed by Keith Sader. It compares old systems using Cassandra to a newer Scylla implementation, highlighting performance improvements and operational cost reductions. Initial results showed issues with query consistency under load, requiring adjustments in schema and configuration for optimal performance.
Wide Column Store NoSQL vs SQL Data Modeling
Wide Column Store NoSQL vs SQL Data ModelingScyllaDB The document discusses the concept of 'wide' in various contexts. It explores its implications in different fields. The term encompasses a broad range of meanings depending on usage.
Empowering the AWS DynamoDB™ application developer with Alternator
Empowering the AWS DynamoDB™ application developer with AlternatorScyllaDB Alternator is an open-source implementation of DynamoDB compatible with Scylla, aiming to provide scalability and high performance while allowing deployment on various platforms. It supports multi-table applications and offers extensive observability features for monitoring performance and diagnosing issues. The tool facilitates easy development and deployment without the constraints of traditional DynamoDB setups.
OOW Unconference 2010: Mining the AWR repository for Capacity Planning, Visua...
OOW Unconference 2010: Mining the AWR repository for Capacity Planning, Visua...Kristofferson A This document summarizes an unconference presentation about mining the Automatic Workload Repository (AWR) for capacity planning, visualization, and real-world examples. The presentation discusses using AWR and DBA_HIST tables to analyze metrics like average active sessions (AAS) and CPU utilization over time. It provides examples of using AWR data to identify performance bottlenecks, characterize workloads, and predict capacity needs. Tools mentioned include scripts for AWR analysis and visualization with PerfSheet.
Scylla: 1 Million CQL operations per second per server
Scylla: 1 Million CQL operations per second per serverAvi Kivity ScyllaDB is a high-performance NoSQL database designed to handle up to 1 million operations per second per node with low latency, fully compatible with Apache Cassandra. It utilizes a unique architecture that eliminates locks and threads, improving efficiency by exploiting hardware resources and enabling linear scaling. The technology supports existing Cassandra drivers and queries, promoting data modeling and eliminating the need for caching layers.
The Fifth Elephant 2016: Self-Serve Performance Tuning for Hadoop and Spark
The Fifth Elephant 2016: Self-Serve Performance Tuning for Hadoop and SparkAkshay Rai The document discusses self-serve performance tuning for Hadoop and Spark, highlighting the evolution of Hadoop at LinkedIn and the challenges faced in job tuning. It introduces 'Dr. Elephant,' a tool designed to help users analyze job performance, suggesting solutions to common problems like mapper data skew and memory allocation issues. The document also outlines customization options, integration with workflow schedulers, and ongoing open-source contributions for further development.
Apache spark online training - GoLogica
Apache spark online training - GoLogicaGoLogica Technologies Gologica Technologies offers Apache Spark training designed to enhance skills in big data and the Hadoop ecosystem, covering topics such as Spark streaming, SQL, machine learning, and GraphX programming. The course includes various modules focused on Spark architecture, data frames, RDDs, and data sources, as well as debugging and tuning techniques. Additional training programs in various technologies such as SAP, Oracle, and cloud computing are also available.
Managing your Black Friday Logs
Managing your Black Friday LogsJ On The Beach The document discusses managing logs for Black Friday in Elasticsearch. It covers the Elastic Stack components including Beats, Logstash, Elasticsearch and Kibana. It then discusses monitoring architectures, techniques for optimally sizing Elasticsearch clusters and shards, optimizing bulk indexing size, and distributing load across nodes. The presentation aims to provide guidance on log management strategies for handling high volume traffic periods like Black Friday.
Meeting the challenges of OLTP Big Data with Scylla
Meeting the challenges of OLTP Big Data with ScyllaScyllaDB The document discusses advancements in ScyllaDB, focusing on efficiencies in distributed systems and big data challenges. Key topics include performance enhancements, consistency improvements with Raft protocol, workload isolation, and flexible deployment solutions across various environments. It also highlights ongoing driver updates and monitoring capabilities for better observability in database management.
AWS Summit Milan - AWS RDS for your data (and your sleep)
AWS Summit Milan - AWS RDS for your data (and your sleep)Matteo Moretti The document discusses how Madisoft, a company that produces an education management platform called Nuvola, migrated their relational database infrastructure from self-managed MySQL instances to AWS RDS. Nuvola saw over 2 million active users and 400 million SQL queries per day, posing challenges for reliability, scaling, and maintenance of their previous infrastructure. By moving to AWS RDS, Madisoft gained automated backups, patching, monitoring, and scaling capabilities with 12 MySQL instances across multiple availability zones. The migration took only 50 minutes and saved significant costs and engineering time compared to their previous self-managed approach.
Redshift Introduction
Redshift IntroductionDataKitchen The document outlines an agenda for a workshop on Amazon Redshift conducted on December 6, 2014, covering topics such as the advantages of analytic databases, specific features of Redshift, and hands-on exercises for loading data and performing queries. Participants are guided on the necessary preparations, including AWS account setup and SQL Workbench installation, to effectively use Redshift. The session concludes with instructions on shutting down the database and resources for further learning.
Lessons learned from embedding Cassandra in xPatterns
Lessons learned from embedding Cassandra in xPatternsClaudiu Barbura The document discusses lessons learned from embedding Cassandra in the xPatterns big data analytics platform. It provides an agenda that includes discussing Cassandra usage in xPatterns, the necessary developments like data modeling optimizations, robust REST APIs, geo-replication, and a demo of exporting to NoSQL APIs. Key lessons learned since Cassandra versions 0.6 to 2.0.6 are also summarized, such as the need for consistent clocks, reducing column families, and monitoring.
Case Study: Troubleshooting Cassandra performance issues as a developer
Case Study: Troubleshooting Cassandra performance issues as a developerCarlos Alonso Pérez The document presents a case study on troubleshooting production issues faced by a developer at MyDrive Solutions, focusing on performance problems in a Cassandra environment. The study emphasizes the importance of measurement, metrics, and monitoring in identifying unexpected performance issues, highlighting the author's personal experience with a misdiagnosed problem. Additionally, it acknowledges the tools and community resources that aid in such troubleshooting efforts.
Hadoop + GPU
Hadoop + GPUVladimir Starostenkov The document discusses the emergence of data analytics on commodity clusters using technologies like Hadoop and GPU acceleration. It highlights the significant speed improvements possible with GPU-based computations, particularly in Java programming, showcasing examples and comparisons of performance. The document also introduces Aparapi, a tool that extends Java's capabilities to leverage GPU resources for data parallelism.
Building Data Quality pipelines with Apache Spark and Delta Lake
Building Data Quality pipelines with Apache Spark and Delta LakeDatabricks This document covers a presentation on building data quality pipelines using Apache Spark and Delta Lake, emphasizing the significance of addressing dirty data which costs companies significantly. The speakers outline key design decisions for creating a robust system that meets specific business needs while facilitating ease of use for developers. Conclusively, it highlights the benefits of building custom solutions over off-the-shelf products, particularly in enhancing data ingestion processes.
Introduction to df
Introduction to dfMohit Jaggi The document discusses the 'df' dataframe designed for use with Spark, offering a user experience similar to Python's pandas while handling larger datasets through distributed computing. It highlights the benefits of using Scala for enhanced performance and direct access to Spark libraries, providing code examples that demonstrate conversions from pandas to 'df'. The conclusion emphasizes the scalability and open-source nature of 'df', inviting contributions and announcing job openings at Ayasdi.
Using SparkML to Power a DSaaS (Data Science as a Service): Spark Summit East...
Using SparkML to Power a DSaaS (Data Science as a Service): Spark Summit East...Spark Summit The document discusses Sparkle, a solution built by Comcast to address challenges in processing massive amounts of data and enabling data science workflows at scale. Sparkle is a centralized processing system with SQL and machine learning capabilities that is highly scalable and accessible via a REST API. It is used by Comcast to power various use cases including churn modeling, price elasticity analysis, and direct mail campaign optimization.
«Почему Spark отнюдь не так хорош»
«Почему Spark отнюдь не так хорош»Olga Lavrentieva The document provides an overview of Apache Spark, emphasizing its ability to run programs significantly faster than MapReduce, with speeds up to 100x in memory and 10x on disk. It highlights Spark's functionalities, including resilient distributed datasets (RDDs), Spark Streaming for real-time data processing, and related technologies such as Google Cloud Dataflow. Additionally, the document touches on performance optimization techniques and mentions various resources and APIs associated with Spark.
ScyllaDB: NoSQL at Ludicrous Speed
ScyllaDB: NoSQL at Ludicrous SpeedJ On The Beach ScyllaDB is a high-performance, clustered NoSQL database compatible with Apache Cassandra, offering significant improvements in latency and resource management due to its unique architecture and use of Seastar for asynchronous processing. It demonstrates proficiency in handling workloads with mechanisms like efficient memory allocation and workload conditioning while maximizing throughput without requiring extensive tuning from the user. The document outlines its advantages, technical design, and how it contrasts with traditional systems like Cassandra.
Streamsets and spark
Streamsets and sparkHari Shreedharan StreamSets can process data using Apache Spark in three ways:
1) The Spark Evaluator stage allows user-provided Spark code to run on each batch of records in a pipeline and return results or errors.
2) A Cluster Pipeline can leverage Apache Spark's Direct Kafka DStream to partition data from Kafka across worker pipelines on a cluster.
3) A Spark Executor can kick off a Spark application when an event is received, allowing tasks like model updating to run on streaming data using Spark.
Apache Flink's Table & SQL API - unified APIs for batch and stream processing
Apache Flink's Table & SQL API - unified APIs for batch and stream processingTimo Walther The document discusses Apache Flink's unified API for batch and stream processing, emphasizing the importance of a relational API to simplify stream processing. It presents the Table API and SQL as tools for querying data in a consistent manner across both batch and streaming data. Additionally, it highlights the functionality of dynamic tables and the ongoing contributions for enhancing Flink's capabilities.
More Related Content
What's hot (20)
GPS Insight on Using Presto with Scylla for Data Analytics and Data Archival
GPS Insight on Using Presto with Scylla for Data Analytics and Data ArchivalScyllaDB The document discusses data analytics and archival solutions using Presto and Scylla, presented by Doug Stuns, a seasoned database architect. GPS Insight employs a 3 DC, 18 node Scylla cluster on AWS to manage significant amounts of diagnostic and GPS vehicle data, utilizing Presto for ad-hoc querying and data archival. Challenges related to querying non-partition keys are addressed, alongside a detailed installation guide for Presto in AWS EC2.
Scylla @ GumGum: Contextual Ads
Scylla @ GumGum: Contextual AdsScyllaDB The document outlines GumGum's contextual advertising capabilities, detailing the infrastructure and challenges faced by the ad server team, managed by Keith Sader. It compares old systems using Cassandra to a newer Scylla implementation, highlighting performance improvements and operational cost reductions. Initial results showed issues with query consistency under load, requiring adjustments in schema and configuration for optimal performance.
Wide Column Store NoSQL vs SQL Data Modeling
Wide Column Store NoSQL vs SQL Data ModelingScyllaDB The document discusses the concept of 'wide' in various contexts. It explores its implications in different fields. The term encompasses a broad range of meanings depending on usage.
Empowering the AWS DynamoDB™ application developer with Alternator
Empowering the AWS DynamoDB™ application developer with AlternatorScyllaDB Alternator is an open-source implementation of DynamoDB compatible with Scylla, aiming to provide scalability and high performance while allowing deployment on various platforms. It supports multi-table applications and offers extensive observability features for monitoring performance and diagnosing issues. The tool facilitates easy development and deployment without the constraints of traditional DynamoDB setups.
OOW Unconference 2010: Mining the AWR repository for Capacity Planning, Visua...
OOW Unconference 2010: Mining the AWR repository for Capacity Planning, Visua...Kristofferson A This document summarizes an unconference presentation about mining the Automatic Workload Repository (AWR) for capacity planning, visualization, and real-world examples. The presentation discusses using AWR and DBA_HIST tables to analyze metrics like average active sessions (AAS) and CPU utilization over time. It provides examples of using AWR data to identify performance bottlenecks, characterize workloads, and predict capacity needs. Tools mentioned include scripts for AWR analysis and visualization with PerfSheet.
Scylla: 1 Million CQL operations per second per server
Scylla: 1 Million CQL operations per second per serverAvi Kivity ScyllaDB is a high-performance NoSQL database designed to handle up to 1 million operations per second per node with low latency, fully compatible with Apache Cassandra. It utilizes a unique architecture that eliminates locks and threads, improving efficiency by exploiting hardware resources and enabling linear scaling. The technology supports existing Cassandra drivers and queries, promoting data modeling and eliminating the need for caching layers.
The Fifth Elephant 2016: Self-Serve Performance Tuning for Hadoop and Spark
The Fifth Elephant 2016: Self-Serve Performance Tuning for Hadoop and SparkAkshay Rai The document discusses self-serve performance tuning for Hadoop and Spark, highlighting the evolution of Hadoop at LinkedIn and the challenges faced in job tuning. It introduces 'Dr. Elephant,' a tool designed to help users analyze job performance, suggesting solutions to common problems like mapper data skew and memory allocation issues. The document also outlines customization options, integration with workflow schedulers, and ongoing open-source contributions for further development.
Apache spark online training - GoLogica
Apache spark online training - GoLogicaGoLogica Technologies Gologica Technologies offers Apache Spark training designed to enhance skills in big data and the Hadoop ecosystem, covering topics such as Spark streaming, SQL, machine learning, and GraphX programming. The course includes various modules focused on Spark architecture, data frames, RDDs, and data sources, as well as debugging and tuning techniques. Additional training programs in various technologies such as SAP, Oracle, and cloud computing are also available.
Managing your Black Friday Logs
Managing your Black Friday LogsJ On The Beach The document discusses managing logs for Black Friday in Elasticsearch. It covers the Elastic Stack components including Beats, Logstash, Elasticsearch and Kibana. It then discusses monitoring architectures, techniques for optimally sizing Elasticsearch clusters and shards, optimizing bulk indexing size, and distributing load across nodes. The presentation aims to provide guidance on log management strategies for handling high volume traffic periods like Black Friday.
Meeting the challenges of OLTP Big Data with Scylla
Meeting the challenges of OLTP Big Data with ScyllaScyllaDB The document discusses advancements in ScyllaDB, focusing on efficiencies in distributed systems and big data challenges. Key topics include performance enhancements, consistency improvements with Raft protocol, workload isolation, and flexible deployment solutions across various environments. It also highlights ongoing driver updates and monitoring capabilities for better observability in database management.
AWS Summit Milan - AWS RDS for your data (and your sleep)
AWS Summit Milan - AWS RDS for your data (and your sleep)Matteo Moretti The document discusses how Madisoft, a company that produces an education management platform called Nuvola, migrated their relational database infrastructure from self-managed MySQL instances to AWS RDS. Nuvola saw over 2 million active users and 400 million SQL queries per day, posing challenges for reliability, scaling, and maintenance of their previous infrastructure. By moving to AWS RDS, Madisoft gained automated backups, patching, monitoring, and scaling capabilities with 12 MySQL instances across multiple availability zones. The migration took only 50 minutes and saved significant costs and engineering time compared to their previous self-managed approach.
Redshift Introduction
Redshift IntroductionDataKitchen The document outlines an agenda for a workshop on Amazon Redshift conducted on December 6, 2014, covering topics such as the advantages of analytic databases, specific features of Redshift, and hands-on exercises for loading data and performing queries. Participants are guided on the necessary preparations, including AWS account setup and SQL Workbench installation, to effectively use Redshift. The session concludes with instructions on shutting down the database and resources for further learning.
Lessons learned from embedding Cassandra in xPatterns
Lessons learned from embedding Cassandra in xPatternsClaudiu Barbura The document discusses lessons learned from embedding Cassandra in the xPatterns big data analytics platform. It provides an agenda that includes discussing Cassandra usage in xPatterns, the necessary developments like data modeling optimizations, robust REST APIs, geo-replication, and a demo of exporting to NoSQL APIs. Key lessons learned since Cassandra versions 0.6 to 2.0.6 are also summarized, such as the need for consistent clocks, reducing column families, and monitoring.
Case Study: Troubleshooting Cassandra performance issues as a developer
Case Study: Troubleshooting Cassandra performance issues as a developerCarlos Alonso Pérez The document presents a case study on troubleshooting production issues faced by a developer at MyDrive Solutions, focusing on performance problems in a Cassandra environment. The study emphasizes the importance of measurement, metrics, and monitoring in identifying unexpected performance issues, highlighting the author's personal experience with a misdiagnosed problem. Additionally, it acknowledges the tools and community resources that aid in such troubleshooting efforts.
Hadoop + GPU
Hadoop + GPUVladimir Starostenkov The document discusses the emergence of data analytics on commodity clusters using technologies like Hadoop and GPU acceleration. It highlights the significant speed improvements possible with GPU-based computations, particularly in Java programming, showcasing examples and comparisons of performance. The document also introduces Aparapi, a tool that extends Java's capabilities to leverage GPU resources for data parallelism.
Building Data Quality pipelines with Apache Spark and Delta Lake
Building Data Quality pipelines with Apache Spark and Delta LakeDatabricks This document covers a presentation on building data quality pipelines using Apache Spark and Delta Lake, emphasizing the significance of addressing dirty data which costs companies significantly. The speakers outline key design decisions for creating a robust system that meets specific business needs while facilitating ease of use for developers. Conclusively, it highlights the benefits of building custom solutions over off-the-shelf products, particularly in enhancing data ingestion processes.
Introduction to df
Introduction to dfMohit Jaggi The document discusses the 'df' dataframe designed for use with Spark, offering a user experience similar to Python's pandas while handling larger datasets through distributed computing. It highlights the benefits of using Scala for enhanced performance and direct access to Spark libraries, providing code examples that demonstrate conversions from pandas to 'df'. The conclusion emphasizes the scalability and open-source nature of 'df', inviting contributions and announcing job openings at Ayasdi.
Using SparkML to Power a DSaaS (Data Science as a Service): Spark Summit East...
Using SparkML to Power a DSaaS (Data Science as a Service): Spark Summit East...Spark Summit The document discusses Sparkle, a solution built by Comcast to address challenges in processing massive amounts of data and enabling data science workflows at scale. Sparkle is a centralized processing system with SQL and machine learning capabilities that is highly scalable and accessible via a REST API. It is used by Comcast to power various use cases including churn modeling, price elasticity analysis, and direct mail campaign optimization.
«Почему Spark отнюдь не так хорош»
«Почему Spark отнюдь не так хорош»Olga Lavrentieva The document provides an overview of Apache Spark, emphasizing its ability to run programs significantly faster than MapReduce, with speeds up to 100x in memory and 10x on disk. It highlights Spark's functionalities, including resilient distributed datasets (RDDs), Spark Streaming for real-time data processing, and related technologies such as Google Cloud Dataflow. Additionally, the document touches on performance optimization techniques and mentions various resources and APIs associated with Spark.
ScyllaDB: NoSQL at Ludicrous Speed
ScyllaDB: NoSQL at Ludicrous SpeedJ On The Beach ScyllaDB is a high-performance, clustered NoSQL database compatible with Apache Cassandra, offering significant improvements in latency and resource management due to its unique architecture and use of Seastar for asynchronous processing. It demonstrates proficiency in handling workloads with mechanisms like efficient memory allocation and workload conditioning while maximizing throughput without requiring extensive tuning from the user. The document outlines its advantages, technical design, and how it contrasts with traditional systems like Cassandra.
Viewers also liked (20)
Streamsets and spark
Streamsets and sparkHari Shreedharan StreamSets can process data using Apache Spark in three ways:
1) The Spark Evaluator stage allows user-provided Spark code to run on each batch of records in a pipeline and return results or errors.
2) A Cluster Pipeline can leverage Apache Spark's Direct Kafka DStream to partition data from Kafka across worker pipelines on a cluster.
3) A Spark Executor can kick off a Spark application when an event is received, allowing tasks like model updating to run on streaming data using Spark.
Apache Flink's Table & SQL API - unified APIs for batch and stream processing
Apache Flink's Table & SQL API - unified APIs for batch and stream processingTimo Walther The document discusses Apache Flink's unified API for batch and stream processing, emphasizing the importance of a relational API to simplify stream processing. It presents the Table API and SQL as tools for querying data in a consistent manner across both batch and streaming data. Additionally, it highlights the functionality of dynamic tables and the ongoing contributions for enhancing Flink's capabilities.
Akka-chan's Survival Guide for the Streaming World
Akka-chan's Survival Guide for the Streaming WorldKonrad Malawski The document outlines the evolution and significance of reactive streams, particularly in the context of Akka and JDK 9, highlighting their role in building concurrent, distributed applications. It discusses the development timelines, key features, and comparisons between various streaming technologies and libraries. The author emphasizes the importance of reactive streams for handling back-pressure and asynchronous processing in modern data architectures.
Introduction to data flow management using apache nifi
Introduction to data flow management using apache nifiAnshuman Ghosh The document is an introduction to dataflow management using Apache NiFi, covering its history, features, architecture, and core components. It discusses how NiFi serves as an integrated platform for real-time data management and automation, highlighting common dataflow challenges and providing live demos and testing methodologies. The presentation aims to familiarize users with building dataflow processors, deploying dataflows, and future plans for NiFi enhancements.
[Jfokus] Riding the Jet Streams
[Jfokus] Riding the Jet StreamsViktor Gamov The document discusses Hazelcast Jet, a distributed data processing framework that utilizes Java 8 streams to handle large datasets across multiple machines. It emphasizes the need for distributed computing due to the limitations of single machine data processing, showcasing examples such as word count algorithms. Additionally, it outlines features of the Java Stream API and the benefits of Hazelcast IMDG and Jet in handling big data effectively.
[JokerConf] Верхом на реактивных стримах, 10/13/2016
[JokerConf] Верхом на реактивных стримах, 10/13/2016Viktor Gamov Документ представляет собой программу выступления на конференции по Java 8 Streams и распределенным вычислениям с использованием Hazelcast. Основное внимание уделяется абстракциям потоков в Java, их применению в распределенных данных и проблемам, связанным с хранением и обработкой данных. Также упоминается фреймворк Hazelcast Jet как потенциальный конкурент Apache Spark и Apache Flink.
[NYJavaSig] Riding the Distributed Streams - Feb 2nd, 2017
[NYJavaSig] Riding the Distributed Streams - Feb 2nd, 2017Viktor Gamov This slide deck discusses distributed data processing using Java 8 Streams and Hazelcast Jet. It provides an overview of Java Streams and their limitations for large datasets. It then introduces Hazelcast IMDG for distributed caching and collections. Hazelcast Jet is presented as a distributed data processing framework built on Hazelcast IMDG that can be used to distribute and parallelize stream processing. Examples of distributed streams and the directed acyclic graph (DAG) model used by Jet are shown.
[Codemash] Caching Made "Bootiful"!
[Codemash] Caching Made "Bootiful"!Viktor Gamov The document discusses optimizing architecture performance through caching techniques in Spring applications. It outlines steps for enabling caching and distributed caching using Hazelcast, with example code implementations for a city service. The content also emphasizes the importance of adhering to standards such as JCache for caching solutions.
Think Distributed: The Hazelcast Way
Think Distributed: The Hazelcast WayRahul Gupta Hazelcast provides scale-out computing capabilities that allow cluster capacity to be increased or decreased on demand. It enables resilience through automatic recovery from member failures without data loss. Hazelcast's programming model allows developers to easily program cluster applications as if they are a single process. It also provides fast application performance by holding large data sets in main memory.
Hazelcast Essentials
Hazelcast EssentialsRahul Gupta This document provides an overview of Hazelcast, an open source in-memory data grid. It discusses what Hazelcast is, common use cases, features, and how to configure and use distributed maps (IMap) and querying with predicates. Key points covered include that Hazelcast stores data in memory and distributes it across a cluster, supports caching, distributed computing and messaging use cases, and IMap implements a distributed concurrent map that can be queried using predicates and configured with eviction policies and persistence.
Apache Spark and Oracle Stream Analytics
Apache Spark and Oracle Stream AnalyticsPrabhu Thukkaram This document discusses Oracle Stream Analytics, which provides complex event processing capabilities for Apache Spark Streaming. It leverages Oracle's Continuous Query Engine for event-by-event processing and Apache Spark for distributed computing and fault tolerance. Key features highlighted include stateful and continuous query processing, flexible temporal windows, pattern detection, spatial analysis, and integrated business rules. It is described as reducing application development time by handling state management and fault tolerance, while also scaling linearly with Spark and providing automatic recovery from failures.
Complex Event Processing with Esper
Complex Event Processing with EsperTed Won This document discusses Complex Event Processing (CEP) using Esper. It defines CEP as detecting patterns among events. Esper is an open source CEP engine that provides an SQL-like Event Processing Language (EPL) to define queries over event streams. The document outlines Esper's architecture, features like filtering, windows, aggregation, and joins. It provides examples of EPL queries for topics detection, continuous queries, and pattern matching.
February 2017 HUG: Exactly-once end-to-end processing with Apache Apex
February 2017 HUG: Exactly-once end-to-end processing with Apache ApexYahoo Developer Network The document discusses the Apache Apex platform's features, focusing on its capabilities for in-memory, distributed stream processing with an emphasis on exactly-once processing guarantees. It highlights the importance of fault tolerance, checkpointing for state recovery, and various strategies for ensuring that data is not duplicated or lost during failures when interacting with external systems such as databases and message queues. Key mechanisms and existing implementations from the Malhar library are also detailed for achieving these guarantees.
WSO2Con USA 2017: Scalable Real-time Complex Event Processing at Uber
WSO2Con USA 2017: Scalable Real-time Complex Event Processing at UberWSO2 The document outlines Uber's scalable real-time complex event processing (CEP) architecture, which utilizes Apache Samza and SiddhiQL for efficient event handling and processing. It discusses key features, such as state management, fault tolerance, and various types of actions for real-time applications, including fraud detection and marketing campaigns. Challenges like out-of-order event handling, large checkpointing states, and upgrading jobs are also addressed, highlighting Uber's commitment to maintaining reliable and efficient event processing systems.
Dive into Spark Streaming
Dive into Spark StreamingGerard Maas The document discusses Spark Streaming and its execution model. It describes how Spark Streaming receives data streams, divides them into micro-batches, and processes the micro-batches using Spark. It also covers transformations and actions that can be performed on DStreams, window operations, and deployment options for Spark Streaming including local, standalone, and cluster modes.
Streaming all the things with akka streams
Streaming all the things with akka streams Johan Andrén This document provides an overview and introduction to Akka Streams and Reactive Streams. Some key points:
- Reactive Streams is a standard for asynchronous stream processing with non-blocking back pressure to prevent issues like out of memory errors.
- Akka Streams is a toolkit for building powerful concurrent and distributed applications simply using a Reactive Streams-compliant API. It includes sources, sinks, flows and other stages for stream processing.
- Examples show how to create simple stream graphs that process data asynchronously using Akka Streams APIs in both Java and Scala in just a few lines of code. More complex examples demonstrate features like parallelization.
- The community Alpakka
Building Streaming And Fast Data Applications With Spark, Mesos, Akka, Cassan...
Building Streaming And Fast Data Applications With Spark, Mesos, Akka, Cassan...Lightbend This webinar discusses building streaming and fast data applications with technologies like Spark, Mesos, Akka, Cassandra and Kafka. It covers how microservices and fast data architectures are converging due to similar design problems and data becoming the dominant problem. The webinar also introduces Lightbend's Fast Data Platform for building streaming data systems and microservices with best practices, sample applications and machine learning-based monitoring and management.
The Power of the Log
The Power of the LogBen Stopford The document discusses the use of log-structured merge (LSM) trees in modern databases, emphasizing their efficiency in handling writes by utilizing append-only data structures and sequential operations. It also highlights techniques to optimize reads, such as caching and bloom filters, and reframes database problems in a log-centric way for better system performance. Key examples and comparisons with existing technologies are provided to illustrate the advantages of adopting a log-centric approach.
Kafka & Couchbase Integration Patterns
Kafka & Couchbase Integration PatternsManuel Hurtado The document provides an overview of Kafka & Couchbase integration patterns. It introduces Couchbase and Kafka, describes how Kafka Connect enables real-time data pipelines between data systems, and how the Couchbase Kafka connector integrates Couchbase with Kafka pipelines. Use cases for the connector include using Couchbase as a data source or sink within Kafka streams. The document concludes with demos of Couchbase as a source and sink using the connector.
Kudu Forrester Webinar
Kudu Forrester WebinarCloudera, Inc. The document covers a Cloudera webinar series focused on Apache Kudu and its capabilities for real-time data analytics across various business use cases. It addresses the complexities of traditional lambda architectures, the technical architecture of Kudu, and the importance of real-time data pipelines for enhancing operational efficiencies and decision-making. The series also includes insights from Forrester on market trends and strategies for deploying scalable real-time data platforms.
Ad
Similar to [OracleCode SF] In memory analytics with apache spark and hazelcast (20)
JCConf 2016 - Cloud Computing Applications - Hazelcast, Spark and Ignite
JCConf 2016 - Cloud Computing Applications - Hazelcast, Spark and IgniteJoseph Kuo The document provides an overview of cloud computing technologies focused on Hazelcast, Spark, and Ignite, detailing their features, applications, and integration strategies. It explains Hazelcast as an in-memory data grid supporting distributed data caching and computation, while Spark is presented as a fast general-purpose cluster computing system, and Ignite is described as an in-memory data fabric for real-time data processing. The document also includes code examples, dependencies for integration, and comparisons between Hazelcast and Ignite regarding their functionalities and performance.
Intro to Spark development
Intro to Spark development Spark Summit The document is an agenda for an intro to Spark development class. It includes an overview of Databricks, the history and capabilities of Spark, and the agenda topics which will cover RDD fundamentals, transformations and actions, DataFrames, Spark UIs, and Spark Streaming. The class will include lectures, labs, and surveys to collect information on attendees' backgrounds and goals for the training.
Introduction to Spark Training
Introduction to Spark TrainingSpark Summit This document provides an agenda and overview for an introductory Spark development class. The class will cover the history of big data and Spark, RDD fundamentals, the Databricks UI, transformations and actions, DataFrames, Spark UIs, and resource managers. It includes surveys of students' backgrounds and use cases. Databricks is a platform for building data pipelines and advanced analytics with Spark.
Spark Summit East 2015 Advanced Devops Student Slides
Spark Summit East 2015 Advanced Devops Student SlidesDatabricks This document provides an agenda for an advanced Spark class covering topics such as RDD fundamentals, Spark runtime architecture, memory and persistence, shuffle operations, and Spark Streaming. The class will be held in March 2015 and include lectures, labs, and Q&A sessions. It notes that some slides may be skipped and asks attendees to keep Q&A low during the class, with a dedicated Q&A period at the end.
Big data clustering
Big data clusteringJagadeesan A S The document describes a workshop on parallel, cluster, and cloud computing focused on big data, held by the Computer Society of India. It covers various topics including data clustering concepts, advanced tools like Apache Hadoop and Apache Spark, and the importance of big data processing. The workshop also highlights Spark's capabilities in large-scale data processing, showcasing its advantages over traditional methods.
Intro to Apache Spark
Intro to Apache Sparkclairvoyantllc This document serves as an introduction to Apache Spark, outlining its ecosystem, architecture, and key components such as RDDs, Spark SQL, and Spark Streaming. It contrasts Apache Spark with MapReduce, highlighting performance benefits, and provides code examples for common operations such as word counting across different programming languages. Additionally, it discusses concepts like fault tolerance, persistence, and the advantages of DataFrames and Datasets in structured data processing.
Intro to Apache Spark
Intro to Apache SparkRobert Sanders The document is an introduction to Apache Spark, covering its ecosystem, capabilities, and differences compared to MapReduce. It outlines the essential components like RDDs, Spark SQL, Spark Streaming, and machine learning libraries, along with practical usage examples and code snippets in various programming languages. The presentation emphasizes Spark's advantages, such as performance improvements and its fault-tolerant architecture.
Unit II Real Time Data Processing tools.pptx
Unit II Real Time Data Processing tools.pptxRahul Borate Apache Spark is a lightning-fast cluster computing framework designed for real-time processing. It overcomes limitations of Hadoop by running 100 times faster in memory and 10 times faster on disk. Spark uses resilient distributed datasets (RDDs) that allow data to be partitioned across clusters and cached in memory for faster processing.
How Apache Spark fits into the Big Data landscape
How Apache Spark fits into the Big Data landscapePaco Nathan Apache Spark, developed at UC Berkeley and open-sourced in 2010, is a powerful open-source data processing platform that has grown into a leading technology in the big data landscape, favored for its in-memory computing capabilities and support for various data processing tasks. It has surpassed Hadoop in popularity and is recognized for its role in advanced analytics, machine learning, and complex data workflows. The evolution of Spark demonstrates the shift towards unified data processing solutions that can operate efficiently on commodity hardware.
Cassandra Summit 2014: Apache Spark - The SDK for All Big Data Platforms
Cassandra Summit 2014: Apache Spark - The SDK for All Big Data PlatformsDataStax Academy Apache Spark is an open-source framework for big data analytics, developed from UC Berkeley's AMPLab, offering fast, easy-to-use cluster computing. It significantly improves efficiency through in-memory processing and rich APIs, providing a unified system for various programming environments. Spark integrates with existing big data platforms like Hadoop and Cassandra, allowing seamless deployment and support for SQL, machine learning, and streaming applications.
Introduction to hazelcast
Introduction to hazelcastEmin Demirci The document is an introduction to Hazelcast, an open-source in-memory data grid designed for distributed computing. It discusses the advantages of using in-memory data grids, the architecture of Hazelcast, and its features such as dynamic clustering and data partitioning. The presentation also highlights its various applications and encourages audience engagement with a Q&A session.
Scala Meetup Hamburg - Spark
Scala Meetup Hamburg - SparkIvan Morozov Spark is an open-source cluster computing framework. It started as a project in 2009 at UC Berkeley and was open sourced in 2010. It has over 300 contributors from 50+ organizations. Spark uses Resilient Distributed Datasets (RDDs) that allow in-memory cluster computing across clusters. RDDs provide a programming model for distributed datasets that can be created from external storage or by transforming existing RDDs. RDDs support operations like map, filter, reduce to perform distributed computations lazily.
Distributed caching-computing v3.8
Distributed caching-computing v3.8Rahul Gupta Thinking Distributed: The Hazelcast Way document discusses Hazelcast, an in-memory data grid that provides distributed computing capabilities. It describes how Hazelcast enables scale-out computing, resilience to failures, and an easy programming model. It also outlines Hazelcast's features such as fast performance, persistence, SQL queries, and support for various APIs and languages.
Lighting up Big Data Analytics with Apache Spark in Azure
Lighting up Big Data Analytics with Apache Spark in AzureJen Stirrup The document discusses Apache Spark, a powerful open-source processing engine for large-scale data analytics, emphasizing its speed and ease of use. It includes details on the architecture, components like Resilient Distributed Datasets (RDDs), and the advantages of using Spark over traditional systems such as Hadoop. Additionally, the document outlines its integration with Azure HDInsight for simplified deployment and processing of big data applications.
Apache Spark Core
Apache Spark CoreGirish Khanzode Spark is an open-source cluster computing framework that uses in-memory processing to allow data sharing across jobs for faster iterative queries and interactive analytics, it uses Resilient Distributed Datasets (RDDs) that can survive failures through lineage tracking and supports programming in Scala, Java, and Python for batch, streaming, and machine learning workloads.
Spark Concepts - Spark SQL, Graphx, Streaming
Spark Concepts - Spark SQL, Graphx, StreamingPetr Zapletal This document provides an overview of Apache Spark modules including Spark SQL, GraphX, and Spark Streaming. Spark SQL allows querying structured data using SQL, GraphX provides APIs for graph processing, and Spark Streaming enables scalable stream processing. The document discusses Resilient Distributed Datasets (RDDs), SchemaRDDs, querying data with SQLContext, GraphX property graphs and algorithms, StreamingContext, and input/output operations in Spark Streaming.
Spark & Cassandra at DataStax Meetup on Jan 29, 2015
Spark & Cassandra at DataStax Meetup on Jan 29, 2015 Sameer Farooqui Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis. The document discusses Spark's architecture including its core abstraction of resilient distributed datasets (RDDs), and demos Spark's capabilities for streaming, SQL, machine learning and graph processing on large clusters.
Apache Spark - Lightning Fast Cluster Computing - Hyderabad Scalability Meetup
Apache Spark - Lightning Fast Cluster Computing - Hyderabad Scalability MeetupHyderabad Scalability Meetup This document provides an introduction and overview of Apache Spark, a lightning-fast cluster computing framework. It discusses Spark's ecosystem, how it differs from Hadoop MapReduce, where it shines well, how easy it is to install and start learning, includes some small code demos, and provides additional resources for information. The presentation introduces Spark and its core concepts, compares it to Hadoop MapReduce in areas like speed, usability, tools, and deployment, demonstrates how to use Spark SQL with an example, and shows a visualization demo. It aims to provide attendees with a high-level understanding of Spark without being a training class or workshop.
Dec6 meetup spark presentation
Dec6 meetup spark presentationRamesh Mudunuri This document provides an introduction and overview of Apache Spark, a lightning-fast cluster computing framework. It discusses Spark's ecosystem, how it differs from Hadoop MapReduce, where it shines well, how easy it is to install and start learning, includes some small code demos, and provides additional resources for information. The presentation introduces Spark and its core concepts, compares it to Hadoop MapReduce in areas like speed, usability, tools, and deployment, demonstrates how to use Spark SQL with an example, and shows a visualization demo. It aims to provide attendees with a high-level understanding of Spark without being a training class or workshop.
Apache Spark Introduction and Resilient Distributed Dataset basics and deep dive
Apache Spark Introduction and Resilient Distributed Dataset basics and deep diveSachin Aggarwal The document provides an overview of Apache Spark, highlighting its benefits over traditional MapReduce, such as unified batch, streaming, and interactive computations, as well as ease of developing complex algorithms. It explains key concepts like Resilient Distributed Datasets (RDDs), the importance of partitioning, and the internal workings of Spark including task scheduling and dynamic resource allocation. Additionally, it discusses the challenges associated with Spark, such as data sharing limitations and resource allocation inefficiencies, along with various optimization strategies.
Apache Spark - Lightning Fast Cluster Computing - Hyderabad Scalability Meetup
Apache Spark - Lightning Fast Cluster Computing - Hyderabad Scalability MeetupHyderabad Scalability Meetup
Ad
More from Viktor Gamov (11)
[DataSciCon] Divide, distribute and conquer stream v. batch
[DataSciCon] Divide, distribute and conquer stream v. batchViktor Gamov The document discusses the differences between batch and stream processing, highlighting the importance of time models and event-based semantics in data processing. It emphasizes the challenges of handling out-of-order and late data, as well as providing real-time computation results through windowing techniques. Additionally, it touches on the Lambda architecture and offers examples such as predicting flight arrivals using stream processing.
[Philly JUG] Divide, Distribute and Conquer: Stream v. Batch
[Philly JUG] Divide, Distribute and Conquer: Stream v. BatchViktor Gamov This document discusses stream processing versus batch processing. It notes that stream processing involves data that is in motion and processed in real-time using streaming platforms and directed acyclic graphs. Batch processing involves data at rest that is processed through queries on the full dataset. The document also discusses challenges of stream processing like out-of-order and late data, and how windowing can provide a finite view of infinite data streams.
Testing containers with TestContainers @ AJUG 7/18/2017
Testing containers with TestContainers @ AJUG 7/18/2017Viktor Gamov The document outlines a presentation by Viktor Gamov on using Docker and Testcontainers for Java development and integration testing. It discusses various Docker images, tooling automation, and the benefits of using Docker for creating reproducible environments in production with monitoring capabilities. The content also touches upon the integration of different frameworks and tools for enhanced testing and deployment strategies.
Distributed caching for your next node.js project cf summit - 06-15-2017
Distributed caching for your next node.js project cf summit - 06-15-2017Viktor Gamov This document discusses using distributed caching for Node.js projects. It describes how caching can improve performance by offloading expensive parts of an application's architecture and enabling scaling out to multiple machines. The document introduces Hazelcast, an open-source in-memory data grid that provides distributed caching and other capabilities. It also promotes following the Twitter account @gamussa for more information and provides a GitHub link for sample code related to using Hazelcast with Cloud Foundry.
[Philly ETE] Java Puzzlers NG
[Philly ETE] Java Puzzlers NGViktor Gamov The document contains a mix of humorous and puzzling content related to Java programming, often framed as interactive questions and answers. It highlights various Java features and concepts, such as semaphores, collections, and interfaces, often presented in a lighthearted manner. Additionally, it emphasizes community engagement through hashtags and social media references.
Распределяй и властвуй — 2: Потоки данных наносят ответный удар
Распределяй и властвуй — 2: Потоки данных наносят ответный ударViktor Gamov Документ обсуждает различные аспекты потоковой и пакетной обработки данных, выделяя важные методы и архитектуры, такие как потоковая обработка в Hazelcast. Упоминаются преимущества использования in-memory data grids и архитектур, таких как lambda architecture и cooperative multitasking. Также затрагиваются проблемы устойчивости к сбоям и обработки 'опоздавших' событий в системах обработки данных.
[JBreak] Блеск И Нищета Распределенных Стримов - 04-04-2017
[JBreak] Блеск И Нищета Распределенных Стримов - 04-04-2017Viktor Gamov Документ обсуждает использование распределенных потоков в Java 8, рассматривая их преимущества и методы обработки данных. Приводятся примеры кода для подсчета слов из файла и сравниваются такие решения, как Hazelcast Jet с другими фреймворками, такими как Spark и Flink. В конце подчеркивается важность распределенной обработки данных и стабильности результатов при использовании кластеров.
JavaOne 2013: «Java and JavaScript - Shaken, Not Stirred»
JavaOne 2013: «Java and JavaScript - Shaken, Not Stirred»Viktor Gamov This document is a presentation by Viktor Gamov discussing the integration of Java and JavaScript, particularly highlighting the Nashorn JavaScript engine for the JVM. It emphasizes Nashorn's capabilities, such as being fully compliant with ECMAScript 5.1 and offering a Java-centric API for interacting with JavaScript. Additionally, it covers potential use cases for JavaScript in applications beyond web browsers.
WebSockets: The Current State of the Most Valuable HTML5 API for Java Developers
WebSockets: The Current State of the Most Valuable HTML5 API for Java DevelopersViktor Gamov WebSockets provide a standardized way for web browsers and servers to establish two-way communications channels over a single TCP connection. They allow for more efficient real-time messaging compared to older techniques like polling and long-polling. The WebSocket API defines client-side and server-side interfaces that allow for full-duplex communications that some popular Java application servers and web servers support natively. Common use cases that benefit from WebSockets include chat applications, online games, and real-time updating of social streams.
Functional UI testing of Adobe Flex RIA
Functional UI testing of Adobe Flex RIAViktor Gamov The document discusses functional UI testing of Adobe Flex applications. It covers why testing is important, common testing approaches like unit testing and GUI testing, and automated testing tools for Flex like HP QTP, Selenium, Ranorex, and FlexMonkey. It also discusses best practices for creating test-friendly applications and instrumenting custom components and events to facilitate automated testing.
Testing Flex RIAs for NJ Flex user group
Testing Flex RIAs for NJ Flex user groupViktor Gamov The document discusses the importance and methods of testing in software development, specifically focusing on Flex applications. It provides an overview of automation testing tools like QTP, Selenium, Ranorex, and FlexMonkey, outlining their pros and cons. Additionally, it covers how to prepare components for automation testing, emphasizing the need for proper delegates and configurations to facilitate effective testing.
Recently uploaded (20)
Can We Use Rust to Develop Extensions for PostgreSQL? (POSETTE: An Event for ...
Can We Use Rust to Develop Extensions for PostgreSQL? (POSETTE: An Event for ...NTT DATA Technology & Innovation Can We Use Rust to Develop Extensions for PostgreSQL?
(POSETTE: An Event for Postgres 2025)
June 11, 2025
Shinya Kato
NTT DATA Japan Corporation
Artificial Intelligence in the Nonprofit Boardroom.pdf
Artificial Intelligence in the Nonprofit Boardroom.pdfOnBoard OnBoard recently partnered with Microsoft Tech for Social Impact on the AI in the Nonprofit Boardroom Survey, an initiative designed to uncover the current and future role of artificial intelligence in nonprofit governance.
War_And_Cyber_3_Years_Of_Struggle_And_Lessons_For_Global_Security.pdf
War_And_Cyber_3_Years_Of_Struggle_And_Lessons_For_Global_Security.pdfbiswajitbanerjee38 Russia is one of the most aggressive nations when it comes to state coordinated cyberattacks — and Ukraine has been at the center of their crosshairs for 3 years. This report, provided the State Service of Special Communications and Information Protection of Ukraine contains an incredible amount of cybersecurity insights, showcasing the coordinated aggressive cyberwarfare campaigns of Russia against Ukraine.
It brings to the forefront that understanding your adversary, especially an aggressive nation state, is important for cyber defense. Knowing their motivations, capabilities, and tactics becomes an advantage when allocating resources for maximum impact.
Intelligence shows Russia is on a cyber rampage, leveraging FSB, SVR, and GRU resources to professionally target Ukraine’s critical infrastructures, military, and international diplomacy support efforts.
The number of total incidents against Ukraine, originating from Russia, has steadily increased from 1350 in 2021 to 4315 in 2024, but the number of actual critical incidents has been managed down from a high of 1048 in 2022 to a mere 59 in 2024 — showcasing how the rapid detection and response to cyberattacks has been impacted by Ukraine’s improved cyber resilience.
Even against a much larger adversary, Ukraine is showcasing outstanding cybersecurity, enabled by strong strategies and sound tactics. There are lessons to learn for any enterprise that could potentially be targeted by aggressive nation states.
Definitely worth the read!
FIDO Seminar: Authentication for a Billion Consumers - Amazon.pptx
FIDO Seminar: Authentication for a Billion Consumers - Amazon.pptxFIDO Alliance FIDO Seminar: Authentication for a Billion Consumers - Amazon
Data Validation and System Interoperability
Data Validation and System InteroperabilitySafe Software A non-profit human services agency with specialized health record and billing systems. Challenges solved include access control integrations from employee electronic HR records, multiple regulations compliance, data migrations, benefits enrollments, payroll processing, and automated reporting for business intelligence and analysis.
National Fuels Treatments Initiative: Building a Seamless Map of Hazardous Fu...
National Fuels Treatments Initiative: Building a Seamless Map of Hazardous Fu...Safe Software The National Fuels Treatments Initiative (NFT) is transforming wildfire mitigation by creating a standardized map of nationwide fuels treatment locations across all land ownerships in the United States. While existing state and federal systems capture this data in diverse formats, NFT bridges these gaps, delivering the first truly integrated national view. This dataset will be used to measure the implementation of the National Cohesive Wildland Strategy and demonstrate the positive impact of collective investments in hazardous fuels reduction nationwide. In Phase 1, we developed an ETL pipeline template in FME Form, leveraging a schema-agnostic workflow with dynamic feature handling intended for fast roll-out and light maintenance. This was key as the initiative scaled from a few to over fifty contributors nationwide. By directly pulling from agency data stores, oftentimes ArcGIS Feature Services, NFT preserves existing structures, minimizing preparation needs. External mapping tables ensure consistent attribute and domain alignment, while robust change detection processes keep data current and actionable. Now in Phase 2, we’re migrating pipelines to FME Flow to take advantage of advanced scheduling, monitoring dashboards, and automated notifications to streamline operations. Join us to explore how this initiative exemplifies the power of technology, blending FME, ArcGIS Online, and AWS to solve a national business problem with a scalable, automated solution.
AudGram Review: Build Visually Appealing, AI-Enhanced Audiograms to Engage Yo...
AudGram Review: Build Visually Appealing, AI-Enhanced Audiograms to Engage Yo...SOFTTECHHUB AudGram changes everything by bridging the gap between your audio content and the visual engagement your audience craves. This cloud-based platform transforms your existing audio into scroll-stopping visual content that performs across all social media platforms.
Integration of Utility Data into 3D BIM Models Using a 3D Solids Modeling Wor...
Integration of Utility Data into 3D BIM Models Using a 3D Solids Modeling Wor...Safe Software Jacobs has developed a 3D utility solids modelling workflow to improve the integration of utility data into 3D Building Information Modeling (BIM) environments. This workflow, a collaborative effort between the New Zealand Geospatial Team and the Australian Data Capture Team, employs FME to convert 2D utility data into detailed 3D representations, supporting enhanced spatial analysis and clash detection.
To enable the automation of this process, Jacobs has also developed a survey data standard that standardizes the capture of existing utilities. This standard ensures consistency in data collection, forming the foundation for the subsequent automated validation and modelling steps. The workflow begins with the acquisition of utility survey data, including attributes such as location, depth, diameter, and material of utility assets like pipes and manholes. This data is validated through a custom-built tool that ensures completeness and logical consistency, including checks for proper connectivity between network components. Following validation, the data is processed using an automated modelling tool to generate 3D solids from 2D geometric representations. These solids are then integrated into BIM models to facilitate compatibility with 3D workflows and enable detailed spatial analyses.
The workflow contributes to improved spatial understanding by visualizing the relationships between utilities and other infrastructure elements. The automation of validation and modeling processes ensures consistent and accurate outputs, minimizing errors and increasing workflow efficiency.
This methodology highlights the application of FME in addressing challenges associated with geospatial data transformation and demonstrates its utility in enhancing data integration within BIM frameworks. By enabling accurate 3D representation of utility networks, the workflow supports improved design collaboration and decision-making in complex infrastructure projects
MuleSoft for AgentForce : Topic Center and API Catalog
MuleSoft for AgentForce : Topic Center and API Catalogshyamraj55 This presentation dives into how MuleSoft empowers AgentForce with organized API discovery and streamlined integration using Topic Center and the API Catalog. Learn how these tools help structure APIs around business needs, improve reusability, and simplify collaboration across teams. Ideal for developers, architects, and business stakeholders looking to build a connected and scalable API ecosystem within AgentForce.
FIDO Seminar: Evolving Landscape of Post-Quantum Cryptography.pptx
FIDO Seminar: Evolving Landscape of Post-Quantum Cryptography.pptxFIDO Alliance FIDO Seminar: Evolving Landscape of Post-Quantum Cryptography
“Why It’s Critical to Have an Integrated Development Methodology for Edge AI,...
“Why It’s Critical to Have an Integrated Development Methodology for Edge AI,...Edge AI and Vision Alliance For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/06/why-its-critical-to-have-an-integrated-development-methodology-for-edge-ai-a-presentation-from-lattice-semiconductor/
Sreepada Hegade, Director of ML Systems and Software at Lattice Semiconductor, presents the “Why It’s Critical to Have an Integrated Development Methodology for Edge AI” tutorial at the May 2025 Embedded Vision Summit.
The deployment of neural networks near sensors brings well-known advantages such as lower latency, privacy and reduced overall system cost—but also brings significant challenges that complicate development. These challenges can be addressed effectively by choosing the right solution and design methodology. The low-power FPGAs from Lattice are well poised to enable efficient edge implementation of models, while Lattice’s proven development methodology helps to mitigate the challenges and risks associated with edge model deployment.
In this presentation, Hegade explains the importance of an integrated framework that tightly consolidates different aspects of edge AI development, including training, quantization of networks for edge deployment, integration with sensors and inferencing. He also illustrates how Lattice’s simplified tool flow helps to achieve the best trade-off between power, performance and efficiency using low-power FPGAs for edge deployment of various AI workloads.
Tech-ASan: Two-stage check for Address Sanitizer - Yixuan Cao.pdf
Tech-ASan: Two-stage check for Address Sanitizer - Yixuan Cao.pdfcaoyixuan2019 A presentation at Internetware 2025.
Edge-banding-machines-edgeteq-s-200-en-.pdf
Edge-banding-machines-edgeteq-s-200-en-.pdfAmirStern2 מכונת קנטים המתאימה לנגריות קטנות או גדולות (כמכונת גיבוי).
מדביקה קנטים מגליל או פסים, עד עובי קנט – 3 מ"מ ועובי חומר עד 40 מ"מ. בקר ממוחשב המתריע על תקלות, ומנועים מאסיביים תעשייתיים כמו במכונות הגדולות.
Enabling BIM / GIS integrations with Other Systems with FME
Enabling BIM / GIS integrations with Other Systems with FMESafe Software Jacobs has successfully utilized FME to tackle the complexities of integrating diverse data sources in a confidential $1 billion campus improvement project. The project aimed to create a comprehensive digital twin by merging Building Information Modeling (BIM) data, Construction Operations Building Information Exchange (COBie) data, and various other data sources into a unified Geographic Information System (GIS) platform. The challenge lay in the disparate nature of these data sources, which were siloed and incompatible with each other, hindering efficient data management and decision-making processes.
To address this, Jacobs leveraged FME to automate the extraction, transformation, and loading (ETL) of data between ArcGIS Indoors and IBM Maximo. This process ensured accurate transfer of maintainable asset and work order data, creating a comprehensive 2D and 3D representation of the campus for Facility Management. FME's server capabilities enabled real-time updates and synchronization between ArcGIS Indoors and Maximo, facilitating automatic updates of asset information and work orders. Additionally, Survey123 forms allowed field personnel to capture and submit data directly from their mobile devices, triggering FME workflows via webhooks for real-time data updates. This seamless integration has significantly enhanced data management, improved decision-making processes, and ensured data consistency across the project lifecycle.
AI VIDEO MAGAZINE - June 2025 - r/aivideo
AI VIDEO MAGAZINE - June 2025 - r/aivideo1pcity Studios, Inc AI VIDEO MAGAZINE - r/aivideo community newsletter – Exclusive Tutorials: How to make an AI VIDEO from scratch, PLUS: How to make AI MUSIC, Hottest ai videos of 2025, Exclusive Interviews, New Tools, Previews, and MORE - JUNE 2025 ISSUE -
Raman Bhaumik - Passionate Tech Enthusiast
Raman Bhaumik - Passionate Tech EnthusiastRaman Bhaumik A Junior Software Developer with a flair for innovation, Raman Bhaumik excels in delivering scalable web solutions. With three years of experience and a solid foundation in Java, Python, JavaScript, and SQL, she has streamlined task tracking by 20% and improved application stability.
TrustArc Webinar - 2025 Global Privacy Survey
TrustArc Webinar - 2025 Global Privacy SurveyTrustArc How does your privacy program compare to your peers? What challenges are privacy teams tackling and prioritizing in 2025?
In the sixth annual Global Privacy Benchmarks Survey, we asked global privacy professionals and business executives to share their perspectives on privacy inside and outside their organizations. The annual report provides a 360-degree view of various industries' priorities, attitudes, and trends. See how organizational priorities and strategic approaches to data security and privacy are evolving around the globe.
This webinar features an expert panel discussion and data-driven insights to help you navigate the shifting privacy landscape. Whether you are a privacy officer, legal professional, compliance specialist, or security expert, this session will provide actionable takeaways to strengthen your privacy strategy.
This webinar will review:
- The emerging trends in data protection, compliance, and risk
- The top challenges for privacy leaders, practitioners, and organizations in 2025
- The impact of evolving regulations and the crossroads with new technology, like AI
Predictions for the future of privacy in 2025 and beyond
ENERGY CONSUMPTION CALCULATION IN ENERGY-EFFICIENT AIR CONDITIONER.pdf
ENERGY CONSUMPTION CALCULATION IN ENERGY-EFFICIENT AIR CONDITIONER.pdfMuhammad Rizwan Akram DC Inverter Air Conditioners are revolutionizing the cooling industry by delivering affordable,
energy-efficient, and environmentally sustainable climate control solutions. Unlike conventional
fixed-speed air conditioners, DC inverter systems operate with variable-speed compressors that
modulate cooling output based on demand, significantly reducing energy consumption and
extending the lifespan of the appliance.
These systems are critical in reducing electricity usage, lowering greenhouse gas emissions, and
promoting eco-friendly technologies in residential and commercial sectors. With advancements in
compressor control, refrigerant efficiency, and smart energy management, DC inverter air conditioners
have become a benchmark in sustainable climate control solutions
Can We Use Rust to Develop Extensions for PostgreSQL? (POSETTE: An Event for ...
Can We Use Rust to Develop Extensions for PostgreSQL? (POSETTE: An Event for ...NTT DATA Technology & Innovation
“Why It’s Critical to Have an Integrated Development Methodology for Edge AI,...
“Why It’s Critical to Have an Integrated Development Methodology for Edge AI,...Edge AI and Vision Alliance
[OracleCode SF] In memory analytics with apache spark and hazelcast
- 1. @gamussa @hazelcast #oraclecode IN-MEMORY ANALYTICS with APACHE SPARK and HAZELCAST
- 2. @gamussa @hazelcast #oraclecode Solutions Architect Developer Advocate @gamussa in internetz Please, follow me on Twitter I’m very interesting © Who am I?
- 3. @gamussa @hazelcast #oraclecode What’s Apache Spark? Lightning-Fast Cluster Computing
- 4. @gamussa @hazelcast #oraclecode Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
- 5. @gamussa @hazelcast #oraclecode When to use Spark? Data Science Tasks when questions are unknown Data Processing Tasks when you have to much data You’re tired of Hadoop
- 6. @gamussa @hazelcast #oraclecode Spark Architecture
- 9. @gamussa @hazelcast #oraclecode Resilient Distributed Datasets (RDD) are the primary abstraction in Spark – a fault-tolerant collection of elements that can be operated on in parallel
- 11. @gamussa @hazelcast #oraclecode RDD Operations
- 12. @gamussa @hazelcast #oraclecode operations on RDDs: transformations and actions
- 13. @gamussa @hazelcast #oraclecode transformations are lazy (not computed immediately) the transformed RDD gets recomputed when an action is run on it (default)
- 20. @gamussa @hazelcast #oraclecode RDD Fault Tolerance
- 23. @gamussa @hazelcast #oraclecode parallelized collections take an existing Scala collection and run functions on it in parallel
- 24. @gamussa @hazelcast #oraclecode Hadoop datasets run functions on each record of a file in Hadoop distributed file system or any other storage system supported by Hadoop
- 25. @gamussa @hazelcast #oraclecode What’s Hazelcast IMDG? The Fastest In-memory Data Grid
- 26. @gamussa @hazelcast #oraclecode Hazelcast IMDG is an operational, in-memory, distributed computing platform that manages data using in-memory storage, and performs parallel execution for breakthrough application speed and scale
- 27. @gamussa @hazelcast #oraclecode High-Density Caching In-Memory Data Grid Web Session Clustering Microservices Infrastructure
- 28. @gamussa @hazelcast #oraclecode What’s Hazelcast IMDG? In-memory Data Grid Apache v2 Licensed Distributed Caches (IMap, JCache) Java Collections (IList, ISet, IQueue) Messaging (Topic, RingBuffer) Computation (ExecutorService, M-R)
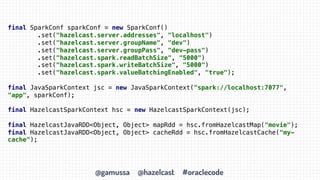
- 31. @gamussa @hazelcast #oraclecode final SparkConf sparkConf = new SparkConf() .set("hazelcast.server.addresses", "localhost") .set("hazelcast.server.groupName", "dev") .set("hazelcast.server.groupPass", "dev-pass") .set("hazelcast.spark.readBatchSize", "5000") .set("hazelcast.spark.writeBatchSize", "5000") .set("hazelcast.spark.valueBatchingEnabled", "true"); final JavaSparkContext jsc = new JavaSparkContext("spark://localhost:7077", "app", sparkConf); final HazelcastSparkContext hsc = new HazelcastSparkContext(jsc); final HazelcastJavaRDD<Object, Object> mapRdd = hsc.fromHazelcastMap("movie"); final HazelcastJavaRDD<Object, Object> cacheRdd = hsc.fromHazelcastCache("my- cache");
- 32. @gamussa @hazelcast #oraclecode final SparkConf sparkConf = new SparkConf() .set("hazelcast.server.addresses", "localhost") .set("hazelcast.server.groupName", "dev") .set("hazelcast.server.groupPass", "dev-pass") .set("hazelcast.spark.readBatchSize", "5000") .set("hazelcast.spark.writeBatchSize", "5000") .set("hazelcast.spark.valueBatchingEnabled", "true"); final JavaSparkContext jsc = new JavaSparkContext("spark://localhost:7077", "app", sparkConf); final HazelcastSparkContext hsc = new HazelcastSparkContext(jsc); final HazelcastJavaRDD<Object, Object> mapRdd = hsc.fromHazelcastMap("movie"); final HazelcastJavaRDD<Object, Object> cacheRdd = hsc.fromHazelcastCache("my- cache");
- 33. @gamussa @hazelcast #oraclecode final SparkConf sparkConf = new SparkConf() .set("hazelcast.server.addresses", "localhost") .set("hazelcast.server.groupName", "dev") .set("hazelcast.server.groupPass", "dev-pass") .set("hazelcast.spark.readBatchSize", "5000") .set("hazelcast.spark.writeBatchSize", "5000") .set("hazelcast.spark.valueBatchingEnabled", "true"); final JavaSparkContext jsc = new JavaSparkContext("spark://localhost:7077", "app", sparkConf); final HazelcastSparkContext hsc = new HazelcastSparkContext(jsc); final HazelcastJavaRDD<Object, Object> mapRdd = hsc.fromHazelcastMap("movie"); final HazelcastJavaRDD<Object, Object> cacheRdd = hsc.fromHazelcastCache("my- cache");
- 34. @gamussa @hazelcast #oraclecode final SparkConf sparkConf = new SparkConf() .set("hazelcast.server.addresses", "localhost") .set("hazelcast.server.groupName", "dev") .set("hazelcast.server.groupPass", "dev-pass") .set("hazelcast.spark.readBatchSize", "5000") .set("hazelcast.spark.writeBatchSize", "5000") .set("hazelcast.spark.valueBatchingEnabled", "true"); final JavaSparkContext jsc = new JavaSparkContext("spark://localhost:7077", "app", sparkConf); final HazelcastSparkContext hsc = new HazelcastSparkContext(jsc); final HazelcastJavaRDD<Object, Object> mapRdd = hsc.fromHazelcastMap("movie"); final HazelcastJavaRDD<Object, Object> cacheRdd = hsc.fromHazelcastCache("my- cache");
- 37. @gamussa @hazelcast #oraclecode DATA SHOULD NOT BE UPDATED WHILE READING FROM SPARK
- 39. @gamussa @hazelcast #oraclecode MAP EXPANSION SHUFFLES THE DATA INSIDE THE BUCKET
- 40. @gamussa @hazelcast #oraclecode CURSOR DOESN’T POINT TO CORRECT ENTRY ANYMORE, DUPLICATE OR MISSING ENTRIES COULD OCCUR
- 42. @gamussa @hazelcast #oraclecode THANKS! Any questions? You can find me at @gamussa [email protected]