Bigdata processing with Spark - part II

This document provides a summary of Spark RDDs and the Spark execution model: - RDDs (Resilient Distributed Datasets) are Spark's fundamental data structure, representing an immutable distributed collection of objects that can be operated on in parallel. RDDs track lineage to support fault tolerance and optimization. - Spark uses a logical plan built from transformations on RDDs, which is then optimized and scheduled into physical stages and tasks by the Spark scheduler. Tasks operate on partitions of RDDs in a data-parallel manner. - The scheduler pipelines transformations where possible, truncates redundant work, and leverages caching and data locality to improve performance. It splits the graph into stages separated by shuffle operations or parent RDD boundaries











































![Challenge: Data
Representation
Java objects often many times larger than
data
class User(name: String, friends: Array[Int])
User(“Bobby”, Array(1, 2))
User 0x… 0x…
String
3
0
1 2
Bobby
5 0x…
int[]
char[] 5](https://image.slidesharecdn.com/bigdata-part-two-161207131918/85/Bigdata-processing-with-Spark-part-II-45-320.jpg)


![DataFrame API
DataFrames hold rows with a known
schema and offer relational operations
through a DSL
c = HiveContext()
users = c.sql(“select * from users”)
ma_users = users[users.state == “MA”]
ma_users.count()
ma_users.groupBy(“name”).avg(“age”)
ma_users.map(lambda row: row.user.toUpper())
Expression AST](https://image.slidesharecdn.com/bigdata-part-two-161207131918/85/Bigdata-processing-with-Spark-part-II-48-320.jpg)



![Data Sources
Uniform way to access structured data
» Apps can migrate across Hive, Cassandra, JSON, …
» Rich semantics allows query pushdown into data
sources
Spark
SQL
users[users.age > 20]
select * from users](https://image.slidesharecdn.com/bigdata-part-two-161207131918/85/Bigdata-processing-with-Spark-part-II-52-320.jpg)


Recommended
More Related Content
What's hot (20)
Similar to Bigdata processing with Spark - part II (20)
More from Arjen de Vries (20)
Recently uploaded (20)
Bigdata processing with Spark - part II
- 1. SIKS Big Data Course Part Two Prof.dr.ir. Arjen P. de Vries [email protected] Enschede, December 7, 2016
- 3. Recap Spark Data Sharing Crucial for: - Interactive Analysis - Iterative machine learning algorithms Spark RDDs - Distributed collections, cached in memory across cluster nodes Keep track of Lineage - To ensure fault-tolerance - To optimize processing based on knowledge of the data partitioning
- 4. RDDs in More Detail RDDs additionally provide: - Control over partitioning, which can be used to optimize data placement across queries. - usually more efficient than the sort-based approach of Map Reduce - Control over persistence (e.g. store on disk vs in RAM) - Fine-grained reads (treat RDD as a big table) Slide by Matei Zaharia, creator Spark, http://spark-project.org
- 5. Scheduling Process rdd1.join(rdd2) .groupBy(…) .filter(…) RDD Objects build operator DAG agnostic to operators! agnostic to operators! doesn’t know about stages doesn’t know about stages DAGScheduler split graph into stages of tasks submit each stage as ready DAG TaskScheduler TaskSet launch tasks via cluster manager retry failed or straggling tasks Cluster manager Worker execute tasks store and serve blocks Block manager Threads Task stage failed
- 6. RDD API Example // Read input file val input = sc.textFile("input.txt") val tokenized = input .map(line => line.split(" ")) .filter(words => words.size > 0) // remove empty lines val counts = tokenized // frequency of log levels .map(words => (words(0), 1)). .reduceByKey{ (a, b) => a + b, 2 } 6
- 7. RDD API Example // Read input file val input = sc.textFile( ) val tokenized = input .map(line => line.split(" ")) .filter(words => words.size > 0) // remove empty lines val counts = tokenized // frequency of log levels .map(words => (words(0), 1)). .reduceByKey{ (a, b) => a + b } 7
- 9. DAG View of RDD’s textFile() map() filter() map() reduceByKey() 9 Mapped RDD Partition 1 Partition 2 Partition 3 Filtered RDD Partition 1 Partition 2 Partition 3 Mapped RDD Partition 1 Partition 2 Partition 3 Shuffle RDD Partition 1 Partition 2 Hadoop RDD Partition 1 Partition 2 Partition 3 input tokenized counts
- 10. Transformations build up a DAG, but don’t “do anything” 10
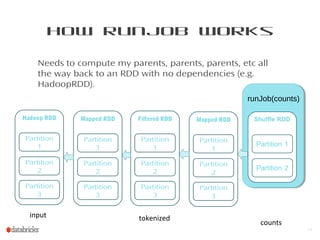
- 11. How runJob Works Needs to compute my parents, parents, parents, etc all the way back to an RDD with no dependencies (e.g. HadoopRDD). 11 Mapped RDD Partition 1 Partition 2 Partition 3 Filtered RDD Partition 1 Partition 2 Partition 3 Mapped RDD Partition 1 Partition 2 Partition 3 Hadoop RDD Partition 1 Partition 2 Partition 3 input tokenized counts runJob(counts)
- 12. Physical Optimizations 1. Certain types of transformations can be pipelined. 2. If dependent RDD’s have already been cached (or persisted in a shuffle) the graph can be truncated. Pipelining and truncation produce a set of stages where each stage is composed of tasks 12
- 13. Scheduler Optimizations Pipelines narrow ops. within a stage Picks join algorithms based on partitioning (minimize shuffles) Reuses previously cached data join union groupBy map Stage 3 Stage 1 Stage 2 A: B: C: D: E: F: G: = previously computed partition Task
- 14. Task Details Stage boundaries are only at input RDDs or “shuffle” operations So, each task looks like this: Task f1 f2 … Task f1 f2 … map output file or master external storage fetch map outputs and/or
- 15. How runJob Works Needs to compute my parents, parents, parents, etc all the way back to an RDD with no dependencies (e.g. HadoopRDD). 15 Mapped RDD Partition 1 Partition 2 Partition 3 Filtered RDD Partition 1 Partition 2 Partition 3 Mapped RDD Partition 1 Partition 2 Partition 3 Shuffle RDD Partition 1 Partition 2 Hadoop RDD Partition 1 Partition 2 Partition 3 input tokenized counts runJob(counts)
- 16. 16 How runJob Works Needs to compute my parents, parents, parents, etc all the way back to an RDD with no dependencies (e.g. HadoopRDD). input tokenized counts Mapped RDD Partition 1 Partition 2 Partition 3 Filtered RDD Partition 1 Partition 2 Partition 3 Mapped RDD Partition 1 Partition 2 Partition 3 Shuffle RDD Partition 1 Partition 2 Hadoop RDD Partition 1 Partition 2 Partition 3 runJob(counts)
- 17. Stage Graph Task 1 Task 2 Task 3 Task 1 Task 2 Stage 1 Stage 2 Each task will: 1.Read Hadoop input 2.Perform maps and filters 3.Write partial sums Each task will: 1.Read partial sums 2.Invoke user function passed to runJob. Shuffle write Shuffle readInput read
- 18. Physical Execution Model Distinguish between: - Jobs: complete work to be done - Stages: bundles of work that can execute together - Tasks: unit of work, corresponds to one RDD partition Defining stages and tasks should not require deep knowledge of what these actually do - Goal of Spark is to be extensible, letting users define new RDD operators
- 19. RDD Interface Set of partitions (“splits”) List of dependencies on parent RDDs Function to compute a partition given parents Optional preferred locations Optional partitioning info (Partitioner) Captures all current Spark operations!Captures all current Spark operations!
- 20. Example: HadoopRDD partitions = one per HDFS block dependencies = none compute(partition) = read corresponding block preferredLocations(part) = HDFS block location partitioner = none
- 21. Example: FilteredRDD partitions = same as parent RDD dependencies = “one-to-one” on parent compute(partition) = compute parent and filter it preferredLocations(part) = none (ask parent) partitioner = none
- 22. Example: JoinedRDD partitions = one per reduce task dependencies = “shuffle” on each parent compute(partition) = read and join shuffled data preferredLocations(part) = none partitioner = HashPartitioner(numTasks) Spark will now know this data is hashed! Spark will now know this data is hashed!
- 23. DependencyTypes union join with inputs not co-partitioned map, filter join with inputs co- partitioned “Narrow” deps: groupByKey “Wide” (shuffle) deps:
- 24. Improving Efficiency Basic Principle: Avoid Shuffling!
- 26. Avoid groupByKey on Pair RDDs All key-value pairs will be shuffled accross the network, to a reducer where the values are collected together groupByKey “Wide” (shuffle) deps:
- 27. aggregateByKey Three inputs - Zero-element - Merging function within partition - Merging function across partitions val initialCount = 0; val addToCounts = (n: Int, v: String) => n + 1 val sumPartitionCounts = (p1: Int, p2: Int) => p1 + p2 val countByKey = kv.aggregateByKey(initialCount) (addToCounts,sumPartitionCounts) Combiners!
- 28. combineByKey val result = input.combineByKey( (v) => (v, 1), (acc: (Int, Int), v) => (acc.1 + v, acc.2 + 1), (acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) ) .map{ case (key, value) => (key, value._1 / value._2.toFloat) } result.collectAsMap().map(println(_))
- 29. Control the Degree of Parallellism Repartition - Concentrate effort - increase use of nodes Coalesce - Reduce number of tasks
- 30. Broadcast Values In case of a join with a small RHS or LHS, broadcast the small set to every node in the cluster
- 34. Broadcast Variables Create with SparkContext.broadcast(initVal) Access with .value inside tasks Immutable! - If you modify the broadcast value after creation, that change is local to the node
- 35. Maintaining Partitioning mapValues instead of map flatMapValues instead of flatMap - Good for tokenization!
- 37. The best trick of all, however…
- 38. Use Higher Level API’s! DataFrame APIs for core processing Works across Scala, Java, Python and R Spark ML for machine learning Spark SQL for structured query processing 38
- 40. Combining Processing Types // Load data using SQL points = ctx.sql(“select latitude, longitude from tweets”) // Train a machine learning model model = KMeans.train(points, 10) // Apply it to a stream sc.twitterStream(...) .map(t => (model.predict(t.location), 1)) .reduceByWindow(“5s”, (a, b) => a + b)
- 41. Performance of Composition Separate computing frameworks: … HDFS read HDFS write HDFS read HDFS write HDFS read HDFS write HDFS write HDFS read Spark:
- 42. Encode Domain Knowledge In essence, nothing more than libraries with pre-cooked code – that still operates over the abstraction of RDDs Focus on optimizations that require domain knowledge
- 43. Spark MLLib
- 44. Data Sets
- 45. Challenge: Data Representation Java objects often many times larger than data class User(name: String, friends: Array[Int]) User(“Bobby”, Array(1, 2)) User 0x… 0x… String 3 0 1 2 Bobby 5 0x… int[] char[] 5
- 46. DataFrames / Spark SQL Efficient library for working with structured data » Two interfaces: SQL for data analysts and external apps, DataFrames for complex programs » Optimized computation and storage underneath Spark SQL added in 2014, DataFrames in 2015
- 48. DataFrame API DataFrames hold rows with a known schema and offer relational operations through a DSL c = HiveContext() users = c.sql(“select * from users”) ma_users = users[users.state == “MA”] ma_users.count() ma_users.groupBy(“name”).avg(“age”) ma_users.map(lambda row: row.user.toUpper()) Expression AST
- 49. What DataFrames Enable 1. Compact binary representation • Columnar, compressed cache; rows for processing 1. Optimization across operators (join reordering, predicate pushdown, etc) 2. Runtime code generation
- 50. Performance
- 51. Performance
- 52. Data Sources Uniform way to access structured data » Apps can migrate across Hive, Cassandra, JSON, … » Rich semantics allows query pushdown into data sources Spark SQL users[users.age > 20] select * from users
- 53. Examples JSON: JDBC: Together: select user.id, text from tweets { “text”: “hi”, “user”: { “name”: “bob”, “id”: 15 } } tweets.json select age from users where lang = “en” select t.text, u.age from tweets t, users u where t.user.id = u.id and u.lang = “en” Spark SQL {JSON} select id, age from users where lang=“en”
- 54. Thanks Matei Zaharia, MIT (https://cs.stanford.edu/~matei/) Paul Wendell, Databricks http://spark-project.org
Editor's Notes
- #14: NOT a modified version of Hadoop