Java Thread and Process Performance for Parallel Machine Learning on Multicore HPC Clusters
Download as pptx, pdf1 like730 views

The document explores performance optimization for Java in parallel machine learning on multicore HPC clusters, particularly focusing on thread models, communication mechanisms, and garbage collection. It compares long-running thread models like LRT-FJ and LRT-BSP and discusses affinity patterns for improving performance, highlighting significant speedup achieved through optimizations. Performance results for k-means and multidimensional scaling are presented, demonstrating the effectiveness of various configurations and the necessity of reducing communication costs in distributed environments.
















Java Thread and Process Performance for Parallel Machine Learning on Multicore HPC Clusters
- 1. Java Thread and Process Performance for Parallel Machine Learning on Multicore HPC Clusters 12/08/2016 1IEEE BigData 2016 IEEE BigData 2016 December 5-8, Washington D.C. Saliya Ekanayake Supun Kamburugamuve |Pulasthi Wickramasinghe|Geoffrey Fox
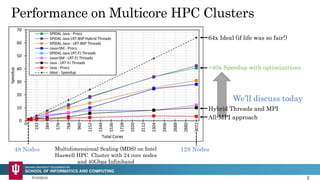
- 2. Performance on Multicore HPC Clusters 5/16/2016 48 Nodes 128 Nodes >40x Speedup with optimizations All-MPI approach Hybrid Threads and MPI 64x Ideal (if life was so fair!) We’ll discuss today Multidimensional Scaling (MDS) on Intel Haswell HPC Cluster with 24 core nodes and 40Gbps Infiniband 2
- 3. Performance Factors • Thread models. • Affinity • Communication. • Other factors of high-level languages. Garbage collection Serialization/Deserialization Memory references and cache Data read/write 9/28/2016 Ph.D. Dissertation Defense 3
- 4. • Long Running Threads – Bulk Synchronous Parallel (LRT-BSP). Resembles the classic BSP model of processes. A long running thread pool similar to FJ. Threads occupy CPUs always – “hot” threads. Thread Models • Long Running Threads – Fork Join (LRT-FJ). Serial work followed by parallel regions. A long running thread pool handles parallel tasks. Threads sleep after parallel work. 9/28/2016 Ph.D. Dissertation Defense 4 Serial work Non-trivial parallel work LRT-FJ LRT-BSP Serial work Non-trivial parallel work Busy thread synchronization • LRT-FJ vs. LRT-BSP. High context switch overhead in FJ. BSP replicates serial work but reduced overhead. Implicit synchronization in FJ. BSP use explicit busy synchronizations.
- 5. Ph.D. Dissertation Defense Affinity • Six affinity patterns • E.g. 2x4 Two threads per process Four processes per node Assume two 4 core sockets 9/28/2016 5 Threads Affinity Processes Affinity Cores Socket None (All) Inherit CI SI NI Explicit per core CE SE NE 2x4 CI C0 C1 C2 C3 C4 C5 C6 C7 Socket 0 Socket 1 P0 P1 P3 P4 2x4 SI C0 C1 C2 C3 C4 C5 C6 C7 Socket 0 Socket 1 P0,P1 P2,P3 2x4 NI C0 C1 C2 C3 C4 C5 C6 C7 Socket 0 Socket 1 P0,P1,P2,P3 2x4 CE C0 C1 C2 C3 C4 C5 C6 C7 Socket 0 Socket 1 P0 P1 P3 P4 2x4 SE C0 C1 C2 C3 C4 C5 C6 C7 Socket 0 Socket 1 P0,P1 P2,P3 2x4 NE C0 C1 C2 C3 C4 C5 C6 C7 Socket 0 Socket 1 P0,P1,P2,P3 Worker thread Background thread (GC and other JVM threads) Process (JVM)
- 6. A Quick Peek into Performance 9/28/2016 Ph.D. Dissertation Defense 6 1.5E+4 2.0E+4 2.5E+4 3.0E+4 3.5E+4 4.0E+4 4.5E+4 5.0E+4 1x24 2x12 3x8 4x6 6x4 8x3 12x2 24x1 Time(ms) Threads per process x Processes per node LRT-FJ NI 1.5E+4 2.0E+4 2.5E+4 3.0E+4 3.5E+4 4.0E+4 4.5E+4 5.0E+4 1x24 2x12 3x8 4x6 6x4 8x3 12x2 24x1 Time(ms) Threads per process x Processes per node LRT-FJ NI LRT-FJ NE 1.5E+4 2.0E+4 2.5E+4 3.0E+4 3.5E+4 4.0E+4 4.5E+4 5.0E+4 1x24 2x12 3x8 4x6 6x4 8x3 12x2 24x1 Time(ms) Threads per process x Processes per node LRT-FJ NI LRT-FJ NE LRT-BSP NI 1.5E+4 2.0E+4 2.5E+4 3.0E+4 3.5E+4 4.0E+4 4.5E+4 5.0E+4 1x24 2x12 3x8 4x6 6x4 8x3 12x2 24x1 Time(ms) Threads per process x Processes per node LRT-FJ NI LRT-FJ NE LRT-BSP NI LRT-BSP NE No thread pinning and FJ Threads pinned to cores and FJ No thread pinning and BSP Threads pinned to cores and BSP K-Means 10K performance on 16 nodes
- 7. Communication Mechanisms • Collective communications are expensive. Allgather, allreduce, broadcast. Frequently used in parallel machine learning E.g. 9/28/2016 Ph.D. Dissertation Defense 7 3 million double values distributed uniformly over 48 nodes • Identical message size per node, yet 24 MPI is ~10 times slower than 1 MPI • Suggests #ranks per node should be 1 for the best performance • How to reduce this cost?
- 8. Communication Mechanisms • Shared Memory (SM) for inter-process communication (IPC). Custom Java implementation in SPIDAL. Uses OpenHFT’s Bytes API. Reduce network communications to the number of nodes. 9/28/2016 Ph.D. Dissertation Defense 8 Java SM architecture Java DA-MDS 100k communication on 48 of 24-core nodes Java DA-MDS 200k communication on 48 of 24-core nodes
- 9. Performance: K-Means 12/08/2016 IEEE BigData 2016 9 Java K-Means 1 mil points and 1k centers performance on 16 nodes for LRT-FJ and LRT-BSP with varying affinity patterns over varying threads and processes. Java vs C K-Means LRT-BSP affinity CE performance for 1 mil points with 1k,10k,50k,100k, and 500k centers on 16 nodes over varying threads and processes.
- 10. Performance: K-Means 9/28/2016 Ph.D. Dissertation Defense 10 Java and C K-Means 1 mil points with 100k centers performance on 16 nodes for LRT-FJ and LRT-BSP over varying intra-node parallelisms. The affinity pattern is CE. • All-Procs. #processes = total parallelism. Each pinned to a separate core. Balanced across the two sockets. • Threads internal. 1 process per node, pinned to T cores, where T = #threads. Threads pinned to separate cores. Threads balanced across the two sockets. • Hybrid 2 processes per node, pinned to T cores. Total parallelism = Tx2 where T is 8 or 12. Threads pinned to separate cores and balanced across the two sockets. Java LRT-BSP -{All Procs, Threads Internal, Hybrid} C
- 11. K-Means Clustering • Flink and Spark 9/28/2016 Ph.D. Dissertation Defense 11 Map (nearest centroid calculation) Reduce (update centroids) Data Set <Points> Data Set <Initial Centroids> Data Set <Updated Centroids> Broadcast K-Means total and compute times for 1 million 2D points and 1k,10,50k,100k, and 500k centroids for Spark, Flink, and MPI Java LRT-BSP CE. Run on 16 nodes as 24x1. K-Means total and compute times for 100k 2D points and 1k,2k,4k,8k, and 16k centroids for Spark, Flink, and MPI Java LRT-BSP CE. Run on 1 node as 24x1.
- 12. 12/08/2016 IEEE BigData 2016 Performance: Multidimensional Scaling 12 Java DA-MDS 50k on 16 of 24-core nodes Java DA-MDS 100k on 16 of 24-core nodes Java DA-MDS speedup comparison for LRT-FJ and LRT-BSP Linux perf statistics for DA-MDS run of 18x2 on 32 nodes. Affinity pattern is CE. 15x 74x 2.6x
- 13. Performance: Multidimensional Scaling 5/16/2016 48 Nodes 128 Nodes >40x Speedup with optimizations All-MPI approach Hybrid Threads and MPI 64x Ideal (if life was so fair!) Multidimensional Scaling (MDS) on Intel Haswell HPC Cluster with 24 core nodes and 40Gbps Infiniband 13
- 14. Acknowledgement • Grants: NSF CIF21 DIBBS 1443054 and NSF RaPyDLI 1415459 • Digital Science Center (DSC) at Indiana University • Network Dynamics and Simulation Science Laboratory (NDSSL) at Virginia Tech 12/08/2016 IEEE BigData 2016 14 Thank you!
- 15. Backup Slides 12/08/2016 IEEE BigData 2016 15
- 16. Other Factors • Garbage Collection (GC) “Stop the world” events are expensive. Especially, for parallel machine learning. Typical OOP allocate – use – forget. Original SPIDAL code produced frequent garbage of small arrays. Solutions. Unavoidable, but can be reduced. Static allocation. Object reuse. Advantage. Less GC – obvious. Scale to larger problem sizes. E.g. Original SPIDAL code required 5GB (x 24 = 120 GB per node) heap per process to handle 200K DA-MDS. Optimized code use < 1GB heap to finish within the same timing. Note. Physical memory is 128GB, so with optimized SPIDAL can now do 1 million point MDS within hardware limits. 9/28/2016 Ph.D. Dissertation Defense 16 Heap size per process reaches –Xmx (2.5GB) early in the computation Frequent GC Heap size per process is well below (~1.1GB) of –Xmx (2.5GB) Virtually no GC activity after optimizing
- 17. Other Factors • Serialization/Deserialization. Default implementations are verbose, especially in Java. Kryo is by far the best in compactness. Off-heap buffers are another option. • Memory references and cache. Nested structures are expensive. Even 1D arrays are preferred over 2D when possible. Adopt HPC techniques – loop ordering, blocked arrays. • Data read/write. Stream I/O is expensive for large data Memory mapping is much faster and JNI friendly in Java Native calls require extra copies as objects move during GC. Memory maps are in off-GC space, so no extra copying is necessary 9/28/2016 Ph.D. Dissertation Defense 17
Editor's Notes
- #12: Note the differences in communication architectures Note times are in log scale Bars indicate compute only times, which is similar across these frameworks Overhead is dominated by communications in Flink and Spark