Agreement Protocols, distributed File Systems, Distributed Shared Memory
15 likes27,091 views

The document discusses distributed systems, focusing on agreement protocols, distributed resource management, and issues in distributed file systems and shared memory. It explains the necessity of agreement protocols for fault tolerance and synchronization in a distributed environment, covering various agreement problems such as Byzantine agreement and consensus, along with algorithms like the Lamport-Shostak-Pease algorithm. Additionally, it highlights the design issues in building distributed file systems and shared memory, emphasizing aspects like caching, consistency, scalability, and security.



























![3. The Interactive Consistency Problem
Every processor broadcasts its initial value to all other processors.
The initial values of the processors may be different . A protocol for
the interactive consistency problem should meet the following
conditions:
Agreement: All non-faulty processes must agree on the same array of
values A[v1 : : : vn].
Validity: If processor Pi is non-faulty and its initial value is vi , then all
non-faulty processes agree on vi as the ith element of the array A. If
process j is faulty, then the non-faulty processes can agree on any
value for A[j].
Termination: Each non-faulty process must eventually decide on the
array A.](https://image.slidesharecdn.com/4-191003050127/85/Agreement-Protocols-distributed-File-Systems-Distributed-Shared-Memory-28-320.jpg)






























































Agreement Protocols, distributed File Systems, Distributed Shared Memory
- 1. DISTRIBUTED SYSTEMS Shikha Gautam Assistant Professor KIET, Ghaziabad
- 2. UNIT-3 • Agreement Protocols • Distributed Resource Management: Issues in distributed File Systems, Mechanism for building distributed file systems, Design issues in Distributed Shared Memory, Algorithm for Implementation of Distributed Shared Memory.
- 3. Agreement Protocols • A kind of co-operation or unity or accordance among processes. • As we know that all the nodes in a distributed system are working together in a cooperation to achieve a common goals. Hence cooperation among the process is very necessary . • Agreement protocol is used to ensure that DS is able to achieve the common goal even after occurrence of various failures in Distributed system. • There are some standard agreement problem in DC. We will see each problem and try to find some protocol or algorithm to solve the agreement problem.
- 5. Why Agreement Protocol • Agreement is always required to achieve a common goal in distributed system. • When there are some types of faulty processes present in the distributed system at that time we need to make sure that performance of distributed system should not be affected at that time we implement some agreement protocol (algorithms) ,so that output of distributed should not be incorrect or should not be affected. • To achieve reliability of Distributed system. So, mainly agreement protocols are used for fault (failure) tolerance in DS
- 6. Problem which require Agreement • Leader Election • Distributed Transaction • Mutual exclusion • Any many more ….
- 7. System Model Agreement Problems have been studied under following System Model: 1. ‘n’ processors and at most ‘m’ of the processors can be faulty. 2. Processors can directly communicate with other processors by message passing. 3. Receiver knows the identity of the sender. 4. Communication medium is reliable.
- 8. Model of processor Failures Processor Can Fail in three modes: 1. Crash Failure : Processor stops and never resumes operation. 2. Send/ Receive Omission : Processor Omits to send/receive message to some processors 3. Malicious Failure : most dangerous one (i) Also known as Byzantine Failure. (ii) Processor may send fictitious values/message to other processes to confuse them. (iii) Tough to detect/correct.
- 9. Classification of Messages in DS 1. Authenticated Messages: Also known as signed Message. Processor can not forge/change a received message. Processor can verify the authenticity of the message. It is easier to reach on an agreement in this case because faulty processors are capable of doing less damage. 2. Non-Authenticated Messages: Also known as Oral Message. Processor can forge/change a received message and claims to have received it from others. Processor can not verify the authenticity of the message in this case.
- 10. We will find agreement solution in two mode of communication under various failure
- 11. Classification of Computation: 1. Synchronous mode: • Finite message delay. • This model specify that the process in the system execute step by step i.e. lockup step manner. • One step is known as round. • A process receives messages (1 round), performs a computation (2 round), and send messages to other processes (3 round). • If there is any delay between messages then computation work will slow down and decrease the performance of the system.
- 12. 2. Asynchronous mode: • Infinite message delay. • Non lockup step manner. • The computation at processes does not proceed in steps. • A process can send and receive messages and perform computation at any time without any sequence of steps.
- 13. Agreement Problem Types 1. Byzantine Agreement problem. The Byzantine Agreement problem is a primitive to the other two problems. So, The other two Agreement Problems are: 2. The Consensus Problem. 3. The Interactive Consistency Problem.
- 14. Problem Who Initiates Value Final Agreement Byzantine Agreement One Processor Single Value Consensus All Processors Single Value Interactive Consistency All Processors A Vector of Values
- 15. Byzantine General Problem (Inspired from Byzantine Empire) There was byzantine empire in middle ages ….there were some army generals who were protecting the city. Now all general have to make an agreement or some negotiation to protect the city . If any general is found to be traitors they will not be able to protect the city .hence they have to agree on some common terms and then only they can protect the byzantine empire. Present part of Byzantine Empire is knowns Turkey (Istanbul).
- 17. 1. Byzantine Problem in DS An arbitrarily chosen processor, called the source processor, broadcasts its initial value to all other processors. Agreement: All non-faulty processors should agree on the same value. Validity: If the source processor is non-faulty, then the common agreed upon value by all non- faulty processors must be same as the initial value of the source.
- 18. Termination: Each non-faulty processor must eventually decide on a value. • Two Important Points to be remember: 1. If source is faulty then all non- faulty processes can agree on any common value. 2. Value agreed upon by faulty processors is irrelevant.
- 19. Agreement algorithm for No-failure • Agreement can easily achieved in constant no of message exchange. • Both synchronous and asynchronous mode will always achieve agreement .Because when all process are working fine then they are eventually satisfying the property of Distributed system and with constant no of message exchange we can achieve i.e. all nodes in a distributed system are working in a cooperation to achieve some common goal.
- 20. Agreement Protocol in Crash Failure Process
- 21. Solution for Byzantine Agreement Problem Lamport et. al proposed an algorithm for byzantine agreement problem which is known as Lamport-Shostak-Pease Algorithm. • Source Broadcasts its initial value to all other processors. • Processors send their values to other processors and also received values from others. • During Execution faulty processors may confuse by sending conflicting values. • However if faulty processors dominate in number, they can prevent non-faulty processors from reaching an agreement. • So, the no of faulty processors should not exceed certain limit.
- 22. Lamport-Shostak-Pease Algorithm This algorithm is also known as Oral Message Algorithm (OM). • Considering there are ‘n’ processors and ‘m’ faulty processors. • Pease showed that in a fully connected network, it is impossible to reach an agreement if number faulty processors ‘m’ exceeds (n-1)/3 • i.e. n >= (3m+1)
- 23. Algorithm is Recursively defined as follows: • Algorithm OM(0), i.e. (m=0) Step 1: Source processor sends its values to every processor. Step 2: Each processor uses the value it receives from source (If no value is received default value 0 is used).
- 24. • Algorithm OM(m), i.e. (m>0) Step 1: The source processor sends its value to every processor. Step 2: If a processor does not receive value it uses a default value of zero. Step 3: For each processor Pi, let vi be the value processor receives from source, then it behaves like source processor. Step 4: If for a processor Pi, Vj (j!=i) is the value received from Pj, the Pi uses the majority value as agreement value.
- 25. Byzantine Agreement can not have solution when among three processors if one processor is faulty.
- 26. 2. The Consensus Problem Here all process have some initial value they broadcast their initial values to all others process and satisfy the following condition: Agreement: All non-faulty processes must agree on same single values. Validity: if all non faulty processes have the same initial value , then the agreed value by all the non- faulty processes must be that same value.
- 27. Termination: Each non-faulty process must eventually decide on a value. • Two Important Points to be remember: 1. If initial value of non-faulty processors are different then all non-faulty then processors can agree on any common value. 2. Value agreed upon by faulty processors is irrelevant.
- 28. 3. The Interactive Consistency Problem Every processor broadcasts its initial value to all other processors. The initial values of the processors may be different . A protocol for the interactive consistency problem should meet the following conditions: Agreement: All non-faulty processes must agree on the same array of values A[v1 : : : vn]. Validity: If processor Pi is non-faulty and its initial value is vi , then all non-faulty processes agree on vi as the ith element of the array A. If process j is faulty, then the non-faulty processes can agree on any value for A[j]. Termination: Each non-faulty process must eventually decide on the array A.
- 30. Metrics to measure performance of Agreement Protocol • Time: Time taken to reach an agreement under a protocol. The time is usually expressed as the number of rounds needed to reach an agreement. • Message Traffic: Number of messages exchanged to reach an agreement. • Storage Overhead: Amount of information that need to be stored at processors during execution of the protocol.
- 31. • There are some solution that solve agreement problems by satisfying all condition of agreement problem in case of synchronous system. • But in case of asynchronous models , agreement problem are not solvable. However we can solve agreement problem in asynchronous System after converting agreement problem in its weaker version. That means agreement problem are reduce to some weaker version : Weaker version of agreement problem are: 1.k-set consensus 2.Approximate consensus 3.Renaming problem 4.Terminating reliable broadcast ( it is a kind of problem which require consensus.)
- 32. Applications of Agreement Protocol 1. Clock Synchronization in Distributed Systems: • Distributed Systems require physical clocks to synchronized but physical clocks have drift problem. So, they must periodically resynchronized. • Such periodically synchronization becomes extremely difficult if the Byzantine failures are allowed. • This is due to the fact that faulty processors can report different clock value to different processors. • Agreement Protocols may help to reach a common clock value.
- 33. 2. Atomic Commit in Distributed Database: • DDBS sites must agree whether to commit or abort the transaction. • In first Phase, sites execute their part of a distributed transaction and broadcast their decisions to all other sites. • In Second Phase, each site based on what is received from other sites in the first phase, decides whether to commit or abort.
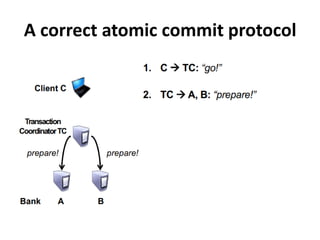
- 34. Two-phase commit in Distributed Systems Motivation: sending money
- 41. A correct atomic commit protocol
- 42. A correct atomic commit protocol
- 43. A correct atomic commit protocol
- 44. A correct atomic commit protocol
- 46. Distributed Resource Management Issues in distributed File Systems, Mechanism for building distributed file systems, Design issues in Distributed Shared Memory, Algorithm for Implementation of Distributed Shared Memory.
- 47. • File System work as the resource management component, which manages the availability of files in distributed system. • A common file system that can be shared by all the autonomous computers in the system. i.e. files can be stored at any machine and the computation can be performed at any machine. Two important goals : 1. Network transparency – to access files distributed over a network. Ideally, users do not have to be aware of the location of files to access them. 2. High Availability - to provide high availability. Users should have the same easy access to files, irrespective of their physical location. Distributed File Systems
- 49. Figure: Architecture of a Distributed File System
- 50. Architecture • File servers and File clients interconnected by a communication network. • Two most important components: 1. Name Server: map logical names to stored object’s (files, directories) physical location. 2. Cache Manager: perform file caching. Can present on both servers and clients. 1. Cache on the client deals with network latency 2. Cache on the server deals with disk latency
- 51. • Typical steps to access data: 1. check client cache, if present, return data. 2. Check local disk, if present, load into local cache, return data. 3. Send request to file server 4. ... 5. server checks cache, if present, load into client cache, return data 6. disk read 7. load into server cache 8. load into client cache 9. return data
- 52. 1. Naming and Transparency 2. Remote file access and Caching 3. Replication and Concurrent file updates 4. Availability 5. Scalability 6. Semantics Issues in distributed File Systems
- 53. 1. Naming and Transparency
- 54. • Transparency should also be achieved at various levels: 1. Structure Transparency 2. Access Transparency 3. Naming Transparency 4. Replication Transparency 5. Location Transparency 6. Mobility Transparency 7. Performance Transparency 8. Scaling Transparency
- 55. 2. Remote file access and Caching
- 56. 3. Concurrent file updates • Server data is replicated across multiple machines. • Need to ensure consistency of files when a file is updated by multiple clients. • Changes to a file by one client should not interfere with the operations of other clients.
- 57. 4. Availability • how to keep replicas consistent. • how to detect inconsistencies among replicas. • consistency problem may decrease the availability. • Replica Management: voting mechanism to read and write to replica.
- 58. 5. Scalability • How to meet the demand of a growing system? • The biggest hurdle: consistency issue
- 59. 6. Semantics • What a user wants? strict consistency. • Users can usually tolerate a certain degree of errors in file handling -- no need to enforce strict consistency.
- 60. Mechanism for building Distributed File Systems 1. Mounting: A mount mechanism allows the binding together of different filename spaces to form a single hierarchically structured name space.
- 62. 2. Caching • Caching is commonly employed in distributed files systems to reduce delays in the accessing of data. • In file caching, a copy of data stored at a remote file server is brought to the client when referenced by the client. • Subsequent access to the data is performed locally at the client, thereby reducing access delays due to network latency. • Caching exploits the temporal locality of reference exhibited by programs. • The temporal locality of reference refers to the fact that a file recently accessed is likely to be accessed again in the near future.
- 63. 3. Hint • An alternative approach is used when cached data are not expected to be completely accurate. • However, valid cache entries improve performance substantially without incurring the cost of maintaining cost consistency. • The class of applications that can utilize hints are those which can recover after discovering that the cached data are invalid. • For example, after the name of a file or directory is mapped to the physical object, the address of the object can be stored as a hint in the cache. • If the address fails to map to the object in the following attempt, the cached address is purged from the cache. • The file server consults the name server to determine the actual location of the file or directory and updates the cache.
- 64. 4. Bulk Data Transfer • Transferring data in bulk reduces the protocol processing overhead at both servers and clients. • In bulk data transfer, multiple consecutive data blocks are transferred from servers to clients instead of just the block referenced by clients. • Bulk transfers reduce file access overhead through obtaining a multiple number of blocks with a single seek; by formatting and transmitting a multiple number of large packets in a single context switch; and by reducing the number of acknowledgements that need to be sent.
- 65. 5. Encryption • Encryption is used for enforcing security in distributed systems. • In this scheme, two entities wishing to communicate with each other establish a key for conversation with the help of an authentication server. • It is important to note that the conversation key is determined by the authentication server, but is never spent in plain (unencrypted) text to either of the entities.
- 66. Distributed Shared Memory • Idea of distributed shared memory is to provide an environment where computers support a shared address space that is made by physically dispersed memories. • It refers to shared memory paradigm applied to loosely coupled distributed memory systems. It gives the systems illusion of physically shared memory. • Memory mapping manager is responsible for mapping between local memories and the shared memory address space. • Any processor can access any memory location in the address space directly. • Chief responsibility is to keep the address space coherent at the times.
- 68. Architecture • Each node of the system consist of one or more CPUs and memory unit. • Nodes are connected by high speed communication network. • Simple message passing system for nodes to exchange information. • Main memory of individual nodes is used to cache pieces of shared memory space. • Shared memory exist only virtually. • Memory mapping manager routine maps local memory to shared virtual memory.
- 70. • The shared memory model provides a virtual address space which is shared by all nodes in a distributed system. • The basic unit of caching is a memory block. • Shared memory space is partitioned into blocks. • Data caching is used to reduce network latency. • The missing block is migrate from the remote node to the client process’s node and operating system maps into the application’s address space. • Data block keep migrating from one node to another on demand but no communication is visible to the user processes.
- 71. Advantages of DSM(or DSVM) 1. Simpler Abstraction: shields the application programmers from low level concern. 2. Better portability of distributed application programs: The access protocol used in case of DSM is consistent with the way sequential application access data this allows for a more natural transition from sequential to distributed application.
- 72. 3. Better performance: due to Locality of data, On demand data moment, Large memory space as total memory size is the sum of the memory size of all the nodes in the system. 4. Flexible communication environment 5. On demand migration of data between processors.
- 73. Design issues in Distributed Shared Memory 1. Granularity 2. Structure of Shared memory 3. Memory coherence and access synchronization 4. Data location and access 5. Replacement strategy 6. Thrashing 7. Heterogeneity
- 74. 1. Granularity: • Computation granularity refers to the size of the sharing unit. It can be a byte, a word, a page or other type of unit. • Choosing the right granularity is a major issue in distributed shared memory because it deals with the amount of computation done between synchronization or communication points. • Other issue is, moving around code and data in the networks involves latency and overhead from network protocols.
- 75. 2. Structure of Shared memory • Structure refers to the layout of the shared data in memory. • Dependent on the type of applications that the distributed shared memory system is intended to support.
- 76. 3. Memory coherence and access synchronization • In a DSM system that allows replication of shared data item, copies of shared data item may simultaneously be available in the main memories of a number of nodes. • To solve the memory coherence problem that deal with the consistency of a piece of shared data lying in the main memories of two or more nodes. • There might be some potential consistency problems when different processors access, cache and update the shared single memory space.
- 77. 4. Data location and access • To share data in a DSM, should be possible to locate and retrieve the data accessed by a user process.
- 78. 5. Replacement strategy • If the local memory of a node is full, a cache miss at that node implies not only a fetch of accessed data block from a remote node but also a replacement. • Data block must be replaced by the new data block.
- 79. 6. Thrashing • Thrashing occurs when a computer's virtual memory resources are overused, this causes the performance of the computer to degrade or collapse. • The problem of thrashing may occur when data item in the same data block are being updated by multiple node at the same time. • Problem may occur with any block size, it is more likely with larger block size.
- 80. 7. Heterogeneity • The DSM system built for homogeneous system need not address the heterogeneity issue.
- 81. • So most the important issues are: - How to keep track of the location of remote data - How to minimize communication overhead when accessing remote data - How to access concurrently remote data at several nodes
- 82. Algorithm for Implementation of Distributed Shared Memory 1. The Central Server Algorithm 2. The Migration Algorithm 3. The Read-Replication Algorithm 4. The Full–Replication Algorithm
- 83. 1. The Central Server Algorithm • Central server maintains all shared data: – Read request: returns data item. – Write request: updates data and returns acknowledgement message.
- 84. • Implementation: – A timeout is used to resend a request if acknowledgment fails. – Associated sequence numbers can be used to detect duplicate write requests – If an application’s request to access shared data fails repeatedly, a failure condition is sent to the application – It is simpler to implement but the central server can become bottleneck and to overcome this shared data can be distributed among several servers. • Issues: performance and reliability. • Possible solutions: – Partition shared data between several servers – Use a mapping function to distribute/locate data
- 85. 2. The Migration Algorithm • Every data access request is forwarded to location of data while in this data is shipped to location of data access request which allows subsequent access to be performed locally. • It allows only one node to access a shared data at a time. • The whole block containing data item migrates instead of individual item requested. • This algorithm provides an opportunity to integrate DSM with virtual memory provided by operating system at individual nodes.
- 86. • Advantages: Takes advantage of the locality of reference. • To locate a remote data object: – Use a location server – Maintain hints at each node – Broadcast query • Issues – Only one node can access a data object at a time – Thrashing can occur: to minimize it, set minimum time data object resides at a node
- 87. • This extends the migration algorithm by replicating data blocks to multiple nodes and allowing multiple nodes to have read access or one node to have both read write access. • After a write, all copies are invalidated or updated. • DSM has to keep track of locations of all copies of data objects. • Advantage: The read-replication can lead to substantial performance improvements if the ratio of reads to writes is large. It improves system performance by allowing multiple nodes to access data concurrently. 3. The Read-Replication Algorithm
- 88. The write operation in this is expensive as all copies of a shared block at various nodes will either have to invalidated or updated with the current value to maintain consistency of shared data block.
- 89. • It is an extension of read replication algorithm which allows multiple nodes to have both read and write access to shared data blocks. • Issue: Since many nodes can write shared data concurrently, the access to shared data must be controlled to maintain it’s consistency. 4. The Full–Replication Algorithm
- 90. • Solution: use of gap-free sequencer All writes sent to sequencer. all nodes wishing to modify shared data will send the modification to sequencer which will then assign a sequence number and multicast the modification with sequence number to all nodes that have a copy of shared data item. Each node performs writes according to sequence numbers. A gap in sequence numbers indicates a missing write request: node asks for retransmission of missing write requests.