Algorithm and Programming (Array)
9 likes965 views

This file contains explanation about array in programming. This file was used in my Algorithm and Programming Class.










![Declaration As Variable (Algorithm)
Kamus:
NamaArray : array [1..MaxSize] of TipeData
Contoh:
Kamus:
bil : array [1..5] of integer
NamaDosen : array [1..20] of string
Pecahan : array [1..100] of real](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-11-320.jpg)
![Declaration As Variable (Pascal)
var
NamaArray : array [1..MaxSize] of TipeData;
Contoh:
var
bil : array [1..5] of integer;
NamaDosen : array [1..20] of string[30];
Pecahan : array [1..100] of real;](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-12-320.jpg)
![Declaration As User-Defined Data Type (Algorithm)
Kamus:
type
NamaArray = array [1..MaxSize] of TipeData
NamaVariabel_1:NamaArray
NamaVariabel_2:NamaArray](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-13-320.jpg)
![Declaration As User-Defined Data Type (Algorithm)
Contoh:
Kamus:
type
bil = array [1..5] of integer
bilbulat:bil
bilpositif:bil](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-14-320.jpg)
![type
NamaArray = array [1..MaxSize] of TipeData;
var
NamaVariabel_1:NamaArray;
NamaVariabel_2:NamaArray;
Declaration As User-Defined Data Type (Pascal)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-15-320.jpg)
![Contoh:
type
bil = array [1..5] of integer;
var
bilbulat:bil;
bilpositif:bil;
Declaration As User-Defined Data Type (Pascal)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-16-320.jpg)
![Define Size of Array As Constant (Algorithm)
Kamus:
const
MaxSize = VALUE
type
NamaArray = array [1..MaxSize] of TipeData
NamaVariabel_1:NamaArray
NamaVariabel_2:NamaArray](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-17-320.jpg)
![Contoh:
Kamus:
const
maks = 5
type
bil = array [1..maks] of integer
bilbulat:bil
Define Size of Array As Constant (Algorithm)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-18-320.jpg)
![const
MaxSize = VALUE;
type
NamaArray : array [1..MaxSize] of TipeData;
var
NamaVariabel:NamaArray;
Define Size of Array As Constant (Pascal)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-19-320.jpg)
![Contoh:
const
maks = 5;
type
bil = array [1..maks] of integer;
var
bilbulat:bil;
Define Size of Array As Constant (Pascal)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-20-320.jpg)

![IlustrationofSettingand
GettingValueinArray
bil[1]=5 it means fill 5 in [1]
a=bil[2] a will be filled by 1](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-22-320.jpg)
![Format of Accessing Array (Algorithm)
namaarray[indeks] nilai
input(namaarray[indeks])
namaarray[indeks] namaarray[indeks] + 1
output(namaarray[indeks])](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-23-320.jpg)
![Format of Accessing Array (Algorithm)
namaarray[indeks] := nilai;
readln(namaarray[indeks]);
namaarray[indeks] := namaarray[indeks] + 1;
writeln(namaarray[indeks]);](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-24-320.jpg)


![Procedure create (output NamaVarArray:NamaArray)
{I.S: elemen array diberi harga awal agar siap digunakan}
{F.S: menghasilkan array yang siap digunakan}
Kamus:
indeks:integer
Algoritma:
for indeks 1 to maks_array do
nama_var_array[indeks] 0 {sesuaikan dengan tipe array}
endfor
EndProcedure
Array Creation (Algorithm)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-27-320.jpg)
![procedure create (var NamaVarArray:NamaArray);
var
indeks:integer;
begin
for indeks := 1 to maks do
NamaVarArray[indeks] := 0;
end;
Array Creation (Pascal)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-28-320.jpg)






![Example of One Dimension Array (Algorithm)
1
2
3
4
5
6
7
8
9
10
11
12
13
Algoritma ArrayDasar
{I.S.: Dideklarasikan dua buah array satu dimensi}
{F.S.: Menampilkan array beserta hasil perhitungan}
Kamus:
const
maks=5
type
bil=array[1..maks] of integer
bil1,bil2:bil
i:integer
jumlah,jumlah2:integer](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-35-320.jpg)
![Example of One Dimension Array (Algorithm)
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Algoritma:
{input elemen array}
for i 1 to maks do
input(bil1[i])
endfor
for i 1 to maks do
input(bil2[i])
endfor
{output elemen array}
for i 1 to maks do
output(bil1[i])
endfor](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-36-320.jpg)
![Example of One Dimension Array (Algorithm)
28
29
30
31
32
33
34
35
37
38
39
40
for i 1 to maks do
output(bil2[i])
endfor
{proses perhitungan array}
jumlah0;
for i 1 to maks do
jumlahjumlah+bil1[i]
endfor
output(jumlah)
jumlah20;](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-37-320.jpg)
![Example of One Dimension Array (Algorithm)
41
42
43
44
for i 1 to maks do
jumlah2jumlah2+bil2[i]
endfor
output(jumlah2)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-38-320.jpg)
![Example of One Dimension Array (Pascal)
1
2
3
4
5
6
7
8
9
10
11
12
13
program ArrayDasar;
uses crt;
const
maks=5;
type
bil=array[1..maks] of integer;
var
bil1,bil2:bil;
i:integer;
jumlah,jumlah2:integer;](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-39-320.jpg)
![Example of One Dimension Array (Pascal)
14
15
16
17
18
19
20
21
22
23
24
25
26
27
begin
{input elemen array}
for i:=1 to maks do
begin
write('Masukkan nilai ke bil 1 [',i,'] : ');
readln(bil1[i]);
end;
writeln();
for i:=1 to maks do
begin
write('Masukkan nilai ke bil 2 [',i,'] : ');
readln(bil2[i]);
end;](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-40-320.jpg)
![Example of One Dimension Array (Pascal)
28
29
30
31
32
33
34
35
37
38
39
40
{output elemen array}
for i:=1 to maks do
begin
writeln('Bil 1[',i,'] = ',bil1[i]);
end;
writeln();
for i:=1 to maks do
begin
writeln('Bil 2[',i,'] = ',bil2[i]);
end;](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-41-320.jpg)
![Example of One Dimension Array (Pascal)
41
42
43
44
45
46
47
48
49
50
51
52
53
{proses perhitungan array}
writeln();
jumlah:=0;
for i:=1 to maks do
begin
jumlah:=jumlah+bil1[i];
end;
writeln('Jumlah elemen array bil 1 = ',jumlah);
writeln();
jumlah2:=0;
for i:=1 to maks do
begin](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-42-320.jpg)
![Example of One Dimension Array (Pascal)
54
55
56
57
58
59
60
61
jumlah2:=jumlah2+bil2[i];
end;
writeln('Jumlah elemen array bil 2 = ',jumlah2);
writeln();
write('Tekan sembarang tombol untuk menutup...');
readkey();
end.](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-43-320.jpg)


![Declaration As Variable (Algorithm)
Kamus:
NamaArray : array [1..MaxBaris,1..MaxKolom] of TipeData
Contoh:
Kamus:
matriks : array [1..5,1..5] of integer](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-47-320.jpg)
![Declaration As Variable (Pascal)
var
NamaArray : array [1..MaxBaris,1..MaxKolom] of TipeData;
Contoh:
var
matriks: array [1..5,1..5] of integer;](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-48-320.jpg)
![Declaration As User-Defined Data Type (Algorithm)
Kamus:
type
NamaArray = array [1..MaxBaris,1..MaxKolom] of TipeData
NamaVariabel_1:NamaArray
NamaVariabel_2:NamaArray](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-49-320.jpg)
![Declaration As User-Defined Data Type (Algorithm)
Contoh:
Kamus:
type
matriks = array [1..5,1..5] of integer
matriks1:matriks](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-50-320.jpg)
![type
NamaArray = array [1..MaxBaris,1..MaxKolom] of TipeData;
var
NamaVariabel_1:NamaArray;
NamaVariabel_2:NamaArray;
Declaration As User-Defined Data Type (Pascal)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-51-320.jpg)
![Contoh:
type
matriks = array [1..5,1..5] of integer;
var
matriks1:bil;
matriks2:bil;
Declaration As User-Defined Data Type (Pascal)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-52-320.jpg)
![Define Size of Array As Constant (Algorithm)
Kamus:
const
MaxBaris = VALUE1
MaxKolom = VALUE2
type
NamaArray = array [1..MaxBaris,1..MaxKolom] of TipeData
NamaVariabel_1:NamaArray
NamaVariabel_2:NamaArray](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-53-320.jpg)
![Contoh:
Kamus:
const
MaksBaris = 5
MaksKolom = 5
type
matriks = array [1..MaksBaris,1..MaksKolom] of integer
matriks1,matriks2:bil
Define Size of Array As Constant (Algorithm)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-54-320.jpg)
![const
MaxBaris = VALUE1;
MaxKolom = VALUE2;
type
NamaArray : array [1..MaxBaris,1..MaxKolom] of TipeData;
var
NamaVariabel:NamaArray;
Define Size of Array As Constant (Pascal)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-55-320.jpg)
![Contoh:
const
MaksBaris = 5;
MaksKolom = 5;
type
matriks = array [1..MaksBaris,1..MaksKolom] of integer;
var
bilbulat:bil;
Define Size of Array As Constant (Pascal)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-56-320.jpg)



![Procedure create (output NamaVarArray:NamaArray)
{I.S: elemen array diberi harga awal agar siap digunakan}
{F.S: menghasilkan array yang siap digunakan}
Kamus:
i,j:integer
Algoritma:
for i 1 to MaksBaris do
for j 1 to MaksKolom do
nama_var_array[i,j] 0 {sesuaikan dengan tipe array}
endfor
endfor
EndProcedure
Array Creation (Algorithm)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-60-320.jpg)
![procedure create (var NamaVarArray:NamaArray);
var
i,j:integer;
begin
for i := 1 to MaksBaris do
begin
for j := 1 to MaksKolom do
NamaVarArray[i,j] := 0;
end;
end;
Array Creation (Pascal)](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-61-320.jpg)






![Example of Two Dimensions Array (Algorithm)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Algoritma ArrayDasar
{I.S.: Dideklarasikan dua buah array dua dimensi}
{F.S.: Menampilkan isi array}
Kamus:
const
MaksBaris=5
MaksKolom=5
type
bil=array[1..MaksBaris,1..MaksKolom] of integer
matriks1,matriks2:bil
i,j:integer](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-68-320.jpg)
![Example of Two Dimensions Array (Algorithm)
15
16
17
18
19
20
21
22
23
24
25
26
27
28
Algoritma:
{input elemen array}
for i 1 to MaksBaris do
for j 1 to MaksKolom do
input(bil1[i,j])
endfor
endfor
for i 1 to MaksBaris do
for j 1 to MaksKolom do
input(bil2[i,j])
endfor
endfor](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-69-320.jpg)
![Example of Two Dimensions Array (Algorithm)
29
30
31
32
33
34
35
37
38
39
40
41
{output elemen array}
for i 1 to MaksBaris do
for j 1 to MaksKolom do
output(bil1[i,j])
endfor
endfor
for i 1 to MaksBaris do
for j 1 to MaksKolom do
output(bil1[i,j])
endfor
endfor](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-70-320.jpg)
![Example of Two Dimensions Array (Pascal)
1
2
3
4
5
6
7
8
9
10
11
12
13
program ArrayDuaDimensiDasar;
uses crt;
const
MaksBaris=3;
MaksKolom=3;
type
matriks = array[1..MaksBaris,1..MaksKolom] of
integer;
var
matriks1,matriks2:matriks;
baris,kolom:integer;](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-71-320.jpg)
![Example of Two Dimensions Array (Pascal)
14
15
16
17
18
19
20
21
22
23
24
25
26
27
begin
{input matriks}
writeln('Input Matriks Pertama');
for baris:=1 to MaksBaris do
begin
for kolom:=1 to MaksKolom do
begin
gotoxy(kolom*5+1,baris+3);
readln(matriks1[baris,kolom]);
end;
end;
writeln();
writeln('Input Matriks Kedua');](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-72-320.jpg)
![Example of Two Dimensions Array (Pascal)
28
29
30
31
32
33
34
35
37
38
39
40
for baris:=1 to MaksBaris do
begin
for kolom:=1 to MaksKolom do
begin
gotoxy(kolom*5+1,baris+9);
readln(matriks2[baris,kolom]);
end;
end;
{output matriks}
clrscr();
writeln('Output Matriks Pertama');](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-73-320.jpg)
![Example of Two Dimensions Array (Pascal)
41
42
43
44
45
46
47
48
49
50
51
52
53
for baris:=1 to MaksBaris do
begin
for kolom:=1 to MaksKolom do
begin
gotoxy(kolom*5+1,baris+3);
write(matriks1[baris,kolom]);
end;
end;
writeln();writeln();
writeln('Output Matriks Kedua');
for baris:=1 to MaksBaris do
begin](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-74-320.jpg)
![Example of Two Dimensions Array (Pascal)
54
55
56
57
58
59
60
61
62
63
64
for kolom:=1 to MaksKolom do
begin
gotoxy(kolom*5+1,baris+9);
write(matriks2[baris,kolom]);
end;
end;
writeln();
write('Tekan sembarang tombol untuk menutup...');
readkey();
end.](https://image.slidesharecdn.com/chapter8-array-161018111838/85/Algorithm-and-Programming-Array-75-320.jpg)































More Related Content
What's hot (20)
Viewers also liked (20)


















Similar to Algorithm and Programming (Array) (20)




















More from Adam Mukharil Bachtiar (20)




















Recently uploaded (20)



















Algorithm and Programming (Array)
- 1. Adam Mukharil Bachtiar English Class Informatics Engineering 2011 Algorithms and Programming Array
- 2. Steps of the Day Let’s Start Definition of Array One Dimension Array Two Dimensions Array
- 3. Definition of Array All About Array
- 4. BackgroundofArray I need a program to process students data but i want it to keep all data temporary in memory so i can use it until the program is shut down.
- 5. WhatisArray Data structure that saves a group of variables which have same type.
- 6. IlustrationofArray An Array was named bil, has integer type, and consists of five elemens. SUBSCRIPT / INDEX
- 7. TypesofArray • One Dimension Array • Two Dimensions Array • Many Dimensions Array (i will not explain THIS!!!)
- 8. One Dimension Array Definition and Structures of One Dimension Array
- 9. WhatisOneDimensionArray Array that only has one subscript / index.
- 10. DeclarationofOneDimension Array • As variable • As user-defined data type • Define size of array as constant
- 11. Declaration As Variable (Algorithm) Kamus: NamaArray : array [1..MaxSize] of TipeData Contoh: Kamus: bil : array [1..5] of integer NamaDosen : array [1..20] of string Pecahan : array [1..100] of real
- 12. Declaration As Variable (Pascal) var NamaArray : array [1..MaxSize] of TipeData; Contoh: var bil : array [1..5] of integer; NamaDosen : array [1..20] of string[30]; Pecahan : array [1..100] of real;
- 13. Declaration As User-Defined Data Type (Algorithm) Kamus: type NamaArray = array [1..MaxSize] of TipeData NamaVariabel_1:NamaArray NamaVariabel_2:NamaArray
- 14. Declaration As User-Defined Data Type (Algorithm) Contoh: Kamus: type bil = array [1..5] of integer bilbulat:bil bilpositif:bil
- 15. type NamaArray = array [1..MaxSize] of TipeData; var NamaVariabel_1:NamaArray; NamaVariabel_2:NamaArray; Declaration As User-Defined Data Type (Pascal)
- 16. Contoh: type bil = array [1..5] of integer; var bilbulat:bil; bilpositif:bil; Declaration As User-Defined Data Type (Pascal)
- 17. Define Size of Array As Constant (Algorithm) Kamus: const MaxSize = VALUE type NamaArray = array [1..MaxSize] of TipeData NamaVariabel_1:NamaArray NamaVariabel_2:NamaArray
- 18. Contoh: Kamus: const maks = 5 type bil = array [1..maks] of integer bilbulat:bil Define Size of Array As Constant (Algorithm)
- 19. const MaxSize = VALUE; type NamaArray : array [1..MaxSize] of TipeData; var NamaVariabel:NamaArray; Define Size of Array As Constant (Pascal)
- 20. Contoh: const maks = 5; type bil = array [1..maks] of integer; var bilbulat:bil; Define Size of Array As Constant (Pascal)
- 21. GetandsettheValuefrom Array To fill and access the value in array, call the name of array and its subscript that you want to access
- 22. IlustrationofSettingand GettingValueinArray bil[1]=5 it means fill 5 in [1] a=bil[2] a will be filled by 1
- 23. Format of Accessing Array (Algorithm) namaarray[indeks] nilai input(namaarray[indeks]) namaarray[indeks] namaarray[indeks] + 1 output(namaarray[indeks])
- 24. Format of Accessing Array (Algorithm) namaarray[indeks] := nilai; readln(namaarray[indeks]); namaarray[indeks] := namaarray[indeks] + 1; writeln(namaarray[indeks]);
- 25. OperationinArray • Creation • Traversal • Searching • Sorting • Destroy
- 26. ArrayCreation • Prepare array to be accessed/processed. Array will be filled with default value. • For numeric array will be filled with 0 and for alphanumeric array will be filled with ‘ ’ (Null Character)
- 27. Procedure create (output NamaVarArray:NamaArray) {I.S: elemen array diberi harga awal agar siap digunakan} {F.S: menghasilkan array yang siap digunakan} Kamus: indeks:integer Algoritma: for indeks 1 to maks_array do nama_var_array[indeks] 0 {sesuaikan dengan tipe array} endfor EndProcedure Array Creation (Algorithm)
- 28. procedure create (var NamaVarArray:NamaArray); var indeks:integer; begin for indeks := 1 to maks do NamaVarArray[indeks] := 0; end; Array Creation (Pascal)
- 29. ArrayTraversal The process of visiting all elements of array one by one, from the first element until last element.
- 30. TraversalProcesses • Fill elements array with data • Output all elements of array • Adding data to array • Insert data in particular index • Delete data in particular index • Determine maximum and minimum data in array • Count mean value in array
- 31. Procedure traversal (I/O NamaVarArray:NamaArray) {I.S: maksimum array sudah terdefinisi} {F.S: menghasilkan array yang sudah diproses} Kamus: Algoritma: for indeks 1 to maks do {proses traversal} endfor Terminasi {sifatnya optional} EndProcedure General Form for Array Traversal (Algorithm)
- 32. procedure traversal(var NamaVarArray:NamaArray); begin for indeks := 1 to maks do {proses traversal yang dipilih} terminasi {sifatnya optional} end; General Form for Array Traversal (Pascal)
- 33. DestroytheArray The process to return value of array into default value that was given in array creation.
- 35. Example of One Dimension Array (Algorithm) 1 2 3 4 5 6 7 8 9 10 11 12 13 Algoritma ArrayDasar {I.S.: Dideklarasikan dua buah array satu dimensi} {F.S.: Menampilkan array beserta hasil perhitungan} Kamus: const maks=5 type bil=array[1..maks] of integer bil1,bil2:bil i:integer jumlah,jumlah2:integer
- 36. Example of One Dimension Array (Algorithm) 14 15 16 17 18 19 20 21 22 23 24 25 26 27 Algoritma: {input elemen array} for i 1 to maks do input(bil1[i]) endfor for i 1 to maks do input(bil2[i]) endfor {output elemen array} for i 1 to maks do output(bil1[i]) endfor
- 37. Example of One Dimension Array (Algorithm) 28 29 30 31 32 33 34 35 37 38 39 40 for i 1 to maks do output(bil2[i]) endfor {proses perhitungan array} jumlah0; for i 1 to maks do jumlahjumlah+bil1[i] endfor output(jumlah) jumlah20;
- 38. Example of One Dimension Array (Algorithm) 41 42 43 44 for i 1 to maks do jumlah2jumlah2+bil2[i] endfor output(jumlah2)
- 39. Example of One Dimension Array (Pascal) 1 2 3 4 5 6 7 8 9 10 11 12 13 program ArrayDasar; uses crt; const maks=5; type bil=array[1..maks] of integer; var bil1,bil2:bil; i:integer; jumlah,jumlah2:integer;
- 40. Example of One Dimension Array (Pascal) 14 15 16 17 18 19 20 21 22 23 24 25 26 27 begin {input elemen array} for i:=1 to maks do begin write('Masukkan nilai ke bil 1 [',i,'] : '); readln(bil1[i]); end; writeln(); for i:=1 to maks do begin write('Masukkan nilai ke bil 2 [',i,'] : '); readln(bil2[i]); end;
- 41. Example of One Dimension Array (Pascal) 28 29 30 31 32 33 34 35 37 38 39 40 {output elemen array} for i:=1 to maks do begin writeln('Bil 1[',i,'] = ',bil1[i]); end; writeln(); for i:=1 to maks do begin writeln('Bil 2[',i,'] = ',bil2[i]); end;
- 42. Example of One Dimension Array (Pascal) 41 42 43 44 45 46 47 48 49 50 51 52 53 {proses perhitungan array} writeln(); jumlah:=0; for i:=1 to maks do begin jumlah:=jumlah+bil1[i]; end; writeln('Jumlah elemen array bil 1 = ',jumlah); writeln(); jumlah2:=0; for i:=1 to maks do begin
- 43. Example of One Dimension Array (Pascal) 54 55 56 57 58 59 60 61 jumlah2:=jumlah2+bil2[i]; end; writeln('Jumlah elemen array bil 2 = ',jumlah2); writeln(); write('Tekan sembarang tombol untuk menutup...'); readkey(); end.
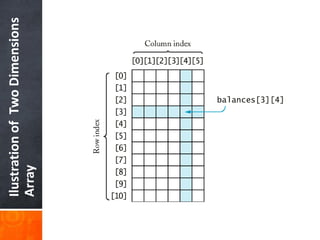
- 44. Two Dimensions Array Definition and Structures of Two Dimensions Array
- 45. WhatisTwoDimensionsArray Array that has two subscripts in its declaration. It often was called matrix.
- 47. Declaration As Variable (Algorithm) Kamus: NamaArray : array [1..MaxBaris,1..MaxKolom] of TipeData Contoh: Kamus: matriks : array [1..5,1..5] of integer
- 48. Declaration As Variable (Pascal) var NamaArray : array [1..MaxBaris,1..MaxKolom] of TipeData; Contoh: var matriks: array [1..5,1..5] of integer;
- 49. Declaration As User-Defined Data Type (Algorithm) Kamus: type NamaArray = array [1..MaxBaris,1..MaxKolom] of TipeData NamaVariabel_1:NamaArray NamaVariabel_2:NamaArray
- 50. Declaration As User-Defined Data Type (Algorithm) Contoh: Kamus: type matriks = array [1..5,1..5] of integer matriks1:matriks
- 51. type NamaArray = array [1..MaxBaris,1..MaxKolom] of TipeData; var NamaVariabel_1:NamaArray; NamaVariabel_2:NamaArray; Declaration As User-Defined Data Type (Pascal)
- 52. Contoh: type matriks = array [1..5,1..5] of integer; var matriks1:bil; matriks2:bil; Declaration As User-Defined Data Type (Pascal)
- 53. Define Size of Array As Constant (Algorithm) Kamus: const MaxBaris = VALUE1 MaxKolom = VALUE2 type NamaArray = array [1..MaxBaris,1..MaxKolom] of TipeData NamaVariabel_1:NamaArray NamaVariabel_2:NamaArray
- 54. Contoh: Kamus: const MaksBaris = 5 MaksKolom = 5 type matriks = array [1..MaksBaris,1..MaksKolom] of integer matriks1,matriks2:bil Define Size of Array As Constant (Algorithm)
- 55. const MaxBaris = VALUE1; MaxKolom = VALUE2; type NamaArray : array [1..MaxBaris,1..MaxKolom] of TipeData; var NamaVariabel:NamaArray; Define Size of Array As Constant (Pascal)
- 56. Contoh: const MaksBaris = 5; MaksKolom = 5; type matriks = array [1..MaksBaris,1..MaksKolom] of integer; var bilbulat:bil; Define Size of Array As Constant (Pascal)
- 57. OperationinTwoDimensions Array Operation in two dimensions array is same as operation in one dimensions array.
- 58. OperationinArray • Creation • Traversal • Searching • Sorting • Destroy
- 59. ArrayCreation • Prepare array to be accessed/processed. Array will be filled with default value. • For numeric array will be filled with 0 and for alphanumeric array will be filled with ‘ ’ (Null Character)
- 60. Procedure create (output NamaVarArray:NamaArray) {I.S: elemen array diberi harga awal agar siap digunakan} {F.S: menghasilkan array yang siap digunakan} Kamus: i,j:integer Algoritma: for i 1 to MaksBaris do for j 1 to MaksKolom do nama_var_array[i,j] 0 {sesuaikan dengan tipe array} endfor endfor EndProcedure Array Creation (Algorithm)
- 61. procedure create (var NamaVarArray:NamaArray); var i,j:integer; begin for i := 1 to MaksBaris do begin for j := 1 to MaksKolom do NamaVarArray[i,j] := 0; end; end; Array Creation (Pascal)
- 62. ArrayTraversal The process of visiting all elements of array one by one, from the first element until last element.
- 63. TraversalProcesses • Fill elements array with data • Output all elements of array • Adding data to array • Insert data in particular index • Delete data in particular index • Determine maximum and minimum data in array • Count mean value in array
- 64. Procedure traversal (I/O NamaVarArray:NamaArray) {I.S: maksimum array sudah terdefinisi} {F.S: menghasilkan array yang sudah diproses} Kamus: Algoritma: for i 1 to MaksBaris do for j 1 to MaksKolom do {proses traversal} endfor endfor Terminasi {sifatnya optional} EndProcedure General Form for Array Traversal (Algorithm)
- 65. procedure traversal(var NamaVarArray:NamaArray); begin for i := 1 to MaksBaris do begin for j := 1 to MaksKolom do {proses traversal yang dipilih} end; terminasi {sifatnya optional} end; General Form for Array Traversal (Pascal)
- 66. DestroytheArray The process to return value of array into default value that was given in array creation.
- 68. Example of Two Dimensions Array (Algorithm) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Algoritma ArrayDasar {I.S.: Dideklarasikan dua buah array dua dimensi} {F.S.: Menampilkan isi array} Kamus: const MaksBaris=5 MaksKolom=5 type bil=array[1..MaksBaris,1..MaksKolom] of integer matriks1,matriks2:bil i,j:integer
- 69. Example of Two Dimensions Array (Algorithm) 15 16 17 18 19 20 21 22 23 24 25 26 27 28 Algoritma: {input elemen array} for i 1 to MaksBaris do for j 1 to MaksKolom do input(bil1[i,j]) endfor endfor for i 1 to MaksBaris do for j 1 to MaksKolom do input(bil2[i,j]) endfor endfor
- 70. Example of Two Dimensions Array (Algorithm) 29 30 31 32 33 34 35 37 38 39 40 41 {output elemen array} for i 1 to MaksBaris do for j 1 to MaksKolom do output(bil1[i,j]) endfor endfor for i 1 to MaksBaris do for j 1 to MaksKolom do output(bil1[i,j]) endfor endfor
- 71. Example of Two Dimensions Array (Pascal) 1 2 3 4 5 6 7 8 9 10 11 12 13 program ArrayDuaDimensiDasar; uses crt; const MaksBaris=3; MaksKolom=3; type matriks = array[1..MaksBaris,1..MaksKolom] of integer; var matriks1,matriks2:matriks; baris,kolom:integer;
- 72. Example of Two Dimensions Array (Pascal) 14 15 16 17 18 19 20 21 22 23 24 25 26 27 begin {input matriks} writeln('Input Matriks Pertama'); for baris:=1 to MaksBaris do begin for kolom:=1 to MaksKolom do begin gotoxy(kolom*5+1,baris+3); readln(matriks1[baris,kolom]); end; end; writeln(); writeln('Input Matriks Kedua');
- 73. Example of Two Dimensions Array (Pascal) 28 29 30 31 32 33 34 35 37 38 39 40 for baris:=1 to MaksBaris do begin for kolom:=1 to MaksKolom do begin gotoxy(kolom*5+1,baris+9); readln(matriks2[baris,kolom]); end; end; {output matriks} clrscr(); writeln('Output Matriks Pertama');
- 74. Example of Two Dimensions Array (Pascal) 41 42 43 44 45 46 47 48 49 50 51 52 53 for baris:=1 to MaksBaris do begin for kolom:=1 to MaksKolom do begin gotoxy(kolom*5+1,baris+3); write(matriks1[baris,kolom]); end; end; writeln();writeln(); writeln('Output Matriks Kedua'); for baris:=1 to MaksBaris do begin
- 75. Example of Two Dimensions Array (Pascal) 54 55 56 57 58 59 60 61 62 63 64 for kolom:=1 to MaksKolom do begin gotoxy(kolom*5+1,baris+9); write(matriks2[baris,kolom]); end; end; writeln(); write('Tekan sembarang tombol untuk menutup...'); readkey(); end.
- 76. Contact Person: Adam Mukharil Bachtiar Informatics Engineering UNIKOM Jalan Dipati Ukur Nomor. 112-114 Bandung 40132 Email: [email protected] Blog: http://adfbipotter.wordpress.com Copyright © Adam Mukharil Bachtiar 2011