Algorithms Lecture 7: Graph Algorithms
8 likes5,002 views

We will discuss the following: Graph, Directed vs Undirected Graph, Acyclic vs Cyclic Graph, Backedge, Search vs Traversal, Breadth First Traversal, Depth First Traversal, Detect Cycle in a Directed Graph.

































































































































More Related Content
What's hot (20)
Similar to Algorithms Lecture 7: Graph Algorithms (20)


















More from Mohamed Loey (20)




















Recently uploaded (20)




















Algorithms Lecture 7: Graph Algorithms
- 1. Analysis and Design of Algorithms Graph Algorithms
- 2. Analysis and Design of Algorithms Graph Directed vs Undirected Graph Acyclic vs Cyclic Graph Backedge Search vs Traversal Breadth First Traversal Depth First Traversal Detect Cycle in a Directed Graph
- 3. Analysis and Design of Algorithms Graph data structure consists of a finite set of vertices or nodes. The interconnected objects are represented by points termed as vertices, and the links that connect the vertices are called edges. A B C D E F Node or Vertices Edge
- 4. Analysis and Design of Algorithms Vertex: Each node of the graph is represented as a vertex. V={A,B,C,D,E,F} Edge: Edge represents a path between two vertices or a line between two vertices. E={AB,AC,BD,BE,CE,DE,DF,EF} A B C D E F Node or Vertices Edge
- 5. Analysis and Design of Algorithms A B C A B C Directed Graph Undirected Graph
- 6. Analysis and Design of Algorithms A B C Acyclic Graph Cyclic Graph A B C
- 7. Analysis and Design of Algorithms Backedge is an edge that is from node to itself (selfloop), or one to its ancestor. A B A
- 8. Analysis and Design of Algorithms Search: Look for a given node Traversal: Always visit all nodes
- 9. Analysis and Design of Algorithms Breadth First Traversal
- 10. Analysis and Design of Algorithms Breadth First Traversal (BFT) algorithm traverses all nodes on graph in a breadthward motion and uses a queue to remember to get the next vertex.
- 11. Analysis and Design of Algorithms Layers A B C D E F Layer1 Layer2 Layer3 Layer4
- 12. Analysis and Design of Algorithms Visited= Queue= Print: A B C D E F 0 0 0 0 0 0 A B C D E F
- 13. Analysis and Design of Algorithms Visited= Queue= Print: A B C D E F 1 0 0 0 0 0 A B C D E F
- 14. Analysis and Design of Algorithms Visited= Queue= A Print: A B C D E F 1 0 0 0 0 0 A B C D E F
- 15. Analysis and Design of Algorithms Visited= Queue= Print: A A B C D E F 1 0 0 0 0 0 A B C D E F
- 16. Analysis and Design of Algorithms Visited= Queue= Print: A A B C D E F 1 0 0 0 0 0 A B C D E F
- 17. Analysis and Design of Algorithms Visited= Queue= Print: A A B C D E F 1 0 0 0 0 0 A B C D E F
- 18. Analysis and Design of Algorithms Visited= Queue= Print: A A B C D E F 1 1 1 0 0 0 A B C D E F
- 19. Analysis and Design of Algorithms Visited= Queue= B C Print: A A B C D E F 1 1 1 0 0 0 A B C D E F
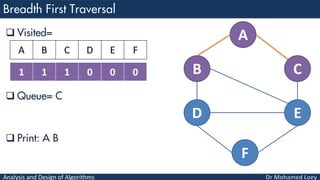
- 20. Analysis and Design of Algorithms Visited= Queue= C Print: A B A B C D E F 1 1 1 0 0 0 A B C D E F
- 21. Analysis and Design of Algorithms Visited= Queue= C Print: A B A B C D E F 1 1 1 0 0 0 A B C D E F
- 22. Analysis and Design of Algorithms Visited= Queue= C Print: A B A B C D E F 1 1 1 0 0 0 A B C D E F
- 23. Analysis and Design of Algorithms Visited= Queue= C Print: A B A B C D E F 1 1 1 1 1 0 A B C D E F
- 24. Analysis and Design of Algorithms Visited= Queue= C D E Print: A B A B C D E F 1 1 1 1 1 0 A B C D E F
- 25. Analysis and Design of Algorithms Visited= Queue= D E Print: A B C A B C D E F 1 1 1 1 1 0 A B C D E F
- 26. Analysis and Design of Algorithms Visited= Queue= D E Print: A B C A B C D E F 1 1 1 1 1 0 A B C D E F
- 27. Analysis and Design of Algorithms Visited= Queue= E Print: A B C A B C D E F 1 1 1 1 1 0 A B C D E F
- 28. Analysis and Design of Algorithms Visited= Queue= E Print: A B C D A B C D E F 1 1 1 1 1 0 A B C D E F
- 29. Analysis and Design of Algorithms Visited= Queue= E Print: A B C D A B C D E F 1 1 1 1 1 0 A B C D E F
- 30. Analysis and Design of Algorithms Visited= Queue= E Print: A B C D A B C D E F 1 1 1 1 1 1 A B C D E F
- 31. Analysis and Design of Algorithms Visited= Queue= E F Print: A B C D A B C D E F 1 1 1 1 1 1 A B C D E F
- 32. Analysis and Design of Algorithms Visited= Queue= F Print: A B C D E A B C D E F 1 1 1 1 1 1 A B C D E F
- 33. Analysis and Design of Algorithms Visited= Queue= F Print: A B C D E A B C D E F 1 1 1 1 1 1 A B C D E F
- 34. Analysis and Design of Algorithms Visited= Queue= F Print: A B C D E A B C D E F 1 1 1 1 1 1 A B C D E F
- 35. Analysis and Design of Algorithms Visited= Queue= Print: A B C D E A B C D E F 1 1 1 1 1 1 A B C D E F
- 36. Analysis and Design of Algorithms Visited= Queue= Print: A B C D E F A B C D E F 1 1 1 1 1 1 A B C D E F
- 37. Analysis and Design of Algorithms Breadth First on Tree
- 38. Analysis and Design of Algorithms
- 39. Analysis and Design of Algorithms V={0,1,2,3,4,5} E={01,02,13,14,24,34,35,45} 0 1 2 3 4 5
- 40. Analysis and Design of Algorithms
- 41. Analysis and Design of Algorithms Another Example:
- 42. Analysis and Design of Algorithms Depth First Traversal
- 43. Analysis and Design of Algorithms Depth First Traversal (DFT) algorithm traverses a graph in a depthward motion and uses a stack to remember to get the next vertex to start a search.
- 44. Analysis and Design of Algorithms depthward motion A B C D E F
- 45. Analysis and Design of Algorithms Visited= Stack= Print: A B C D E F 0 0 0 0 0 0 A B C D E F
- 46. Analysis and Design of Algorithms Visited= Stack= Print: A B C D E F 0 0 0 0 0 0 A B C D E F
- 47. Analysis and Design of Algorithms Visited= Stack= Print: A B C D E F 1 0 0 0 0 0 A B C D E F
- 48. Analysis and Design of Algorithms Visited= Stack= Print: A B C D E F 1 0 0 0 0 0 A B C D E F A
- 49. Analysis and Design of Algorithms Visited= Stack= Print: A A B C D E F 1 0 0 0 0 0 A B C D E F A
- 50. Analysis and Design of Algorithms Visited= Stack= Print: A A B C D E F 1 0 0 0 0 0 A B C D E F A
- 51. Analysis and Design of Algorithms Visited= Stack= Print: A A B C D E F 1 1 0 0 0 0 A B C D E F A
- 52. Analysis and Design of Algorithms Visited= Stack= Print: A A B C D E F 1 1 0 0 0 0 A B C D E F B A
- 53. Analysis and Design of Algorithms Visited= Stack= Print: A B A B C D E F 1 1 0 0 0 0 A B C D E F B A
- 54. Analysis and Design of Algorithms Visited= Stack= Print: A B A B C D E F 1 1 0 0 0 0 A B C D E F B A
- 55. Analysis and Design of Algorithms Visited= Stack= Print: A B A B C D E F 1 1 0 1 0 0 A B C D E F B A
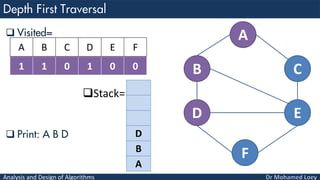
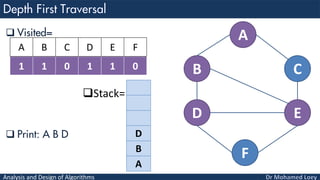
- 56. Analysis and Design of Algorithms Visited= Stack= Print: A B A B C D E F 1 1 0 1 0 0 A B C D E F D B A
- 57. Analysis and Design of Algorithms Visited= Stack= Print: A B D A B C D E F 1 1 0 1 0 0 A B C D E F D B A
- 58. Analysis and Design of Algorithms Visited= Stack= Print: A B D A B C D E F 1 1 0 1 0 0 A B C D E F D B A
- 59. Analysis and Design of Algorithms Visited= Stack= Print: A B D A B C D E F 1 1 0 1 0 0 A B C D E F D B A
- 60. Analysis and Design of Algorithms Visited= Stack= Print: A B D A B C D E F 1 1 0 1 1 0 A B C D E F D B A
- 61. Analysis and Design of Algorithms Visited= Stack= Print: A B D A B C D E F 1 1 0 1 1 0 A B C D E F E D B A
- 62. Analysis and Design of Algorithms Visited= Stack= Print: A B D E A B C D E F 1 1 0 1 1 0 A B C D E F E D B A
- 63. Analysis and Design of Algorithms Visited= Stack= Print: A B D E A B C D E F 1 1 0 1 1 0 A B C D E F E D B A
- 64. Analysis and Design of Algorithms Visited= Stack= Print: A B D E A B C D E F 1 1 0 1 1 0 A B C D E F E D B A
- 65. Analysis and Design of Algorithms Visited= Stack= Print: A B D E A B C D E F 1 1 0 1 1 1 A B C D E F E D B A
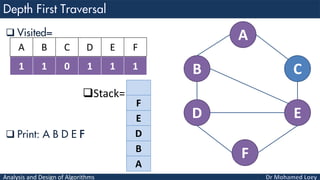
- 66. Analysis and Design of Algorithms Visited= Stack= Print: A B D E A B C D E F 1 1 0 1 1 1 A B C D E F F E D B A
- 67. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F A B C D E F 1 1 0 1 1 1 A B C D E F F E D B A
- 68. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F A B C D E F 1 1 0 1 1 1 A B C D E F E D B A
- 69. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F A B C D E F 1 1 0 1 1 1 A B C D E F E D B A
- 70. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F A B C D E F 1 1 0 1 1 1 A B C D E F E D B A
- 71. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F A B C D E F 1 1 1 1 1 1 A B C D E F E D B A
- 72. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F C A B C D E F 1 1 1 1 1 1 A B C D E F C E D B A
- 73. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F C A B C D E F 1 1 1 1 1 1 A B C D E F E D B A
- 74. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F C A B C D E F 1 1 1 1 1 1 A B C D E F E D B A
- 75. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F C A B C D E F 1 1 1 1 1 1 A B C D E F D B A
- 76. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F C A B C D E F 1 1 1 1 1 1 A B C D E F D B A
- 77. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F C A B C D E F 1 1 1 1 1 1 A B C D E F B A
- 78. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F C A B C D E F 1 1 1 1 1 1 A B C D E F A
- 79. Analysis and Design of Algorithms Visited= Stack= Print: A B D E F C A B C D E F 1 1 1 1 1 1 A B C D E F
- 80. Analysis and Design of Algorithms Depth First on tree
- 81. Analysis and Design of Algorithms
- 82. Analysis and Design of Algorithms V={0,1,2,3,4,5} E={01,02,13,14,24,34,35,45} 0 1 2 3 4 5
- 83. Analysis and Design of Algorithms
- 84. Analysis and Design of Algorithms Another Example:
- 85. Analysis and Design of Algorithms Given a directed graph, check whether the graph contains a cycle or not. Your function should return true if the given graph contains at least one cycle, else return false.
- 86. Analysis and Design of Algorithms Depth First Traversal can be used to detect cycle in a Graph. There is a cycle in a graph only if there is a back edge present in the graph.
- 87. Analysis and Design of Algorithms Visited= Stack= A C B D 0 0 0 0 A B C D
- 88. Analysis and Design of Algorithms Visited= Stack= A C B D 0 0 0 0 A B C D
- 89. Analysis and Design of Algorithms Visited= Stack= A C B D 1 0 0 0 A B C D
- 90. Analysis and Design of Algorithms Visited= Stack= A C B D 1 0 0 0 A B C D A
- 91. Analysis and Design of Algorithms Visited= Stack= A C B D 1 0 0 0 A B C D A
- 92. Analysis and Design of Algorithms Visited= Stack= A C B D 1 1 0 0 A B C D A
- 93. Analysis and Design of Algorithms Visited= Stack= A C B D 1 1 0 0 A B C D B A
- 94. Analysis and Design of Algorithms Visited= Stack= A C B D 1 1 0 0 A B C D B A
- 95. Analysis and Design of Algorithms Visited= Stack= A C B D 1 1 1 0 A B C D B A
- 96. Analysis and Design of Algorithms Visited= Stack= A C B D 1 1 1 0 A B C D C B A
- 97. Analysis and Design of Algorithms Visited= Stack= A C B D 1 1 1 0 A B C D C B A
- 98. Analysis and Design of Algorithms Visited= Stack= A C B D 1 1 1 0 A B C D C B A
- 99. Analysis and Design of Algorithms Graph contains cycle A C B D
- 100. Analysis and Design of Algorithms
- 101. Analysis and Design of Algorithms
- 102. Analysis and Design of Algorithms facebook.com/mloey [email protected] twitter.com/mloey linkedin.com/in/mloey [email protected] mloey.github.io
- 103. Analysis and Design of Algorithms www.YourCompany.com © 2020 Companyname PowerPoint Business Theme. All Rights Reserved. THANKS FOR YOUR TIME