Build, Scale, and Deploy Deep Learning Pipelines Using Apache Spark
4 likes2,720 views

The presentation by Tim Hunter at the Databricks Spark Meetup discusses deep learning at scale using Apache Spark, highlighting its potential and current limitations in industry adoption. It introduces Deep Learning Pipelines, an open-source library designed for ease of use and integration with Spark, catering primarily to Python users while aiming to simplify the deep learning workflow from data loading to model evaluation. Future developments include support for more backends and improved functionalities such as distributed training and text featurization.
1 of 51
Downloaded 124 times






























![Transfer Learning as a Pipeline
31put your #assignedhashtag here by setting the
featurizer = DeepImageFeaturizer(inputCol="image",
outputCol="features",
modelName="InceptionV3")
lr = LogisticRegression(labelCol="label")
p = Pipeline(stages=[featurizer, lr])
p_model = p.fit(train_df)](https://image.slidesharecdn.com/18-03-14meetupdeeplearningpipelines-180316185245/85/Build-Scale-and-Deploy-Deep-Learning-Pipelines-Using-Apache-Spark-31-320.jpg)







![39
Keras Estimator in Model Selection
estimator = KerasImageFileEstimator(
kerasOptimizer=“adam“,
kerasLoss=“categorical_crossentropy“)
paramGrid = ( ParamGridBuilder()
.addGrid(kerasFitParams=[{“batch_size“:100}, {“batch_size“:200}])
.addGrid(modelFile=[model1, model2]) )
cv = CrossValidator(estimator=estimator,
estimatorParamMaps=paramGrid,
evaluator=BinaryClassificationEvaluator(),
numFolds=3)
best_model = cv.fit(train_df)](https://image.slidesharecdn.com/18-03-14meetupdeeplearningpipelines-180316185245/85/Build-Scale-and-Deploy-Deep-Learning-Pipelines-Using-Apache-Spark-39-320.jpg)











Ad
Recommended
Build, Scale, and Deploy Deep Learning Pipelines Using Apache Spark
Build, Scale, and Deploy Deep Learning Pipelines Using Apache SparkDatabricks The document discusses the development and deployment of deep learning pipelines using Apache Spark, highlighting the current state of deep learning and its challenges in industry. It emphasizes the use of Databricks' open-source library to simplify deep learning workflows, integrate with common model architectures, and leverage pre-trained models. It also outlines the typical deep learning workflow and future directions, including non-image data domains and enhanced model support.
Build, Scale, and Deploy Deep Learning Pipelines with Ease Using Apache Spark
Build, Scale, and Deploy Deep Learning Pipelines with Ease Using Apache SparkDatabricks The document presents a talk on building, scaling, and deploying deep learning pipelines using Apache Spark, highlighting its advantages over traditional methods. It covers topics such as the workflow of deep learning, the integration of Spark with deep learning libraries, and examples of applying pre-trained models. The presentation emphasizes the simplicity and efficiency of Spark for deep learning tasks, along with future developments in this area.
Build, Scale, and Deploy Deep Learning Pipelines with Ease
Build, Scale, and Deploy Deep Learning Pipelines with EaseDatabricks The document discusses the process of building, scaling, and deploying deep learning pipelines using Databricks and Apache Spark, emphasizing ease of integration and performance. It covers topics such as the definition of deep learning, successful applications, and a typical workflow, while highlighting the advantages of using Spark for distributed computation. Additionally, it provides insights into the development of deep learning models with transfer learning and model deployment in SQL.
Deep Learning on Apache® Spark™ : Workflows and Best Practices
Deep Learning on Apache® Spark™ : Workflows and Best PracticesJen Aman The document presents an overview of deep learning workflows and best practices using Apache Spark, highlighting its integration with various deep learning frameworks such as TensorFlow and Caffe. It discusses the architecture of Databricks, which simplifies data processing and machine learning for users, as well as monitoring techniques and solutions for managing distributed deep learning tasks. The presentation emphasizes the importance of experimentation and provides resources for further learning.
Composable Parallel Processing in Apache Spark and Weld
Composable Parallel Processing in Apache Spark and WeldDatabricks The document discusses composable parallel processing in Apache Spark and introduces the Weld runtime, emphasizing the need for efficient composition of libraries in big data processing. It highlights Spark's goals to provide a unified engine and API for batch, interactive, and streaming applications, as well as the benefits of structured APIs in Spark 2.0 for performance and programmability. Additionally, it addresses challenges regarding data representation and the inefficiencies of traditional library composition, proposing new composition interfaces like Weld to optimize data movement and execution across various workloads.
Integrating Deep Learning Libraries with Apache Spark
Integrating Deep Learning Libraries with Apache SparkDatabricks The document discusses integrating deep learning libraries with Apache Spark, highlighting various frameworks such as TensorFlow, Keras, and MXNet that can be utilized within the Spark environment. It emphasizes the development of a deep learning pipeline API to streamline processes like featurization and model training, aiming for easier integration and scalability. The talk outlines challenges pertaining to communication patterns, flexible cluster deployments, and the importance of proper resource management in deep learning applications.
Extending Spark's Ingestion: Build Your Own Java Data Source with Jean George...
Extending Spark's Ingestion: Build Your Own Java Data Source with Jean George...Databricks The document outlines a presentation by Jean Georges Perrin on extending Apache Spark's ingestion capabilities using Java to create custom data sources. It discusses different data ingestion solutions, including leveraging existing libraries and building new ones, along with practical examples of coding. The presentation targets software and data engineers looking to enhance Spark's versatility with non-standard data formats.
Spark DataFrames and ML Pipelines
Spark DataFrames and ML PipelinesDatabricks The document discusses Spark DataFrames and machine learning pipelines, highlighting their advantages in data manipulation and workflow construction. It emphasizes the use of familiar APIs inspired by R and Python pandas, showcasing Spark's ability to handle distributed data efficiently. Additionally, it covers various machine learning algorithms and the integration of these capabilities into user-friendly pipelines.
Resource-Efficient Deep Learning Model Selection on Apache Spark
Resource-Efficient Deep Learning Model Selection on Apache SparkDatabricks The document discusses resource-efficient deep learning model selection using Apache Spark, focusing on the challenges of training deep networks with various hyperparameters and architectures. It introduces Model Hopper Parallelism (MOP) as a method to improve efficiency through task parallelism and data parallelism while minimizing resource wastage. Additionally, it details the implementation of MOP on Spark, testing results, and comparisons with other tuning algorithms.
What's New in Apache Spark 2.3 & Why Should You Care
What's New in Apache Spark 2.3 & Why Should You CareDatabricks The document discusses the major features and enhancements in Apache Spark 2.3, including improvements in continuous processing, stream-stream joins, and PySpark performance. Key elements include the new structured streaming execution mode that offers low latency, support for various data formats, and integration with Kubernetes. The emphasis is placed on building robust streaming applications and the advantages of using Spark's unified analytics platform.
Getting Ready to Use Redis with Apache Spark with Dvir Volk
Getting Ready to Use Redis with Apache Spark with Dvir VolkSpark Summit The document outlines a presentation on using Redis for real-time machine learning, focusing on Redis-ML integrated with Apache Spark. It covers the capabilities of Redis as a key-value store, the functionalities of Redis-ML for model serving, and a case study involving a recommendation system. The concluding remarks emphasize the advantages of combining Spark for training with Redis for efficient model serving, highlighting reduced resource costs and simplified machine learning lifecycle.
Improving the Life of Data Scientists: Automating ML Lifecycle through MLflow
Improving the Life of Data Scientists: Automating ML Lifecycle through MLflowDatabricks This document discusses platforms for democratizing data science and enabling enterprise grade machine learning applications. It introduces Flock, a platform that aims to automate the machine learning lifecycle including tracking experiments, managing models, and deploying models for production. It demonstrates Flock by instrumenting Python code for a light gradient boosted machine model to track parameters, log models to MLFlow, convert the model to ONNX, optimize it, and deploy it as a REST API. Future work discussed includes improving Flock's data governance, generalizing auto-tracking capabilities, and integrating with other systems like SQL and Spark for end-to-end pipeline provenance.
No More Cumbersomeness: Automatic Predictive Modeling on Apache Spark with Ma...
No More Cumbersomeness: Automatic Predictive Modeling on Apache Spark with Ma...Databricks The document discusses the development of automatic predictive modeling using Apache Spark by researchers Masato Asahara and Ryohei Fujimaki from NEC Corporation. It highlights the transition from traditional manual modeling to automated systems that generate accurate predictive models in hours, showcasing various applications and the technological challenges faced. Future work includes improving speed through advanced hardware and extending the modeling capabilities to deep learning.
Jump Start with Apache Spark 2.0 on Databricks
Jump Start with Apache Spark 2.0 on DatabricksAnyscale This document provides an agenda for a 3+ hour workshop on Apache Spark 2.x on Databricks. It includes introductions to Databricks, Spark fundamentals and architecture, new features in Spark 2.0 like unified APIs, and workshops on DataFrames/Datasets, Spark SQL, and structured streaming concepts. The agenda covers lunch and breaks and is divided into hour and half hour segments.
A Tale of Three Deep Learning Frameworks: TensorFlow, Keras, & Deep Learning ...
A Tale of Three Deep Learning Frameworks: TensorFlow, Keras, & Deep Learning ...Databricks The document discusses three deep learning frameworks: TensorFlow, Keras, and Deep Learning Pipelines, highlighting their unique features, advantages, and use cases. It emphasizes the challenges posed by big data to machine learning systems and the importance of frameworks like Apache Spark for data processing. Additionally, the content provides insights on transfer learning, ease of integration, and the potential for deploying deep learning applications.
Spark Machine Learning: Adding Your Own Algorithms and Tools with Holden Kara...
Spark Machine Learning: Adding Your Own Algorithms and Tools with Holden Kara...Databricks The document discusses extending Spark ML estimators and transformers, focusing on implementing pipelines, estimators, and transformers in Apache Spark. It introduces key contributors, outlines the Spark Technology Center's mission, and details the process of loading data and training machine learning models using Spark SQL and various classes like StringIndexer and DecisionTreeClassifier. Additionally, it highlights how to create custom estimators and transformers, manage pipeline stages, and the advantages of utilizing ML pipelines for machine learning tasks.
Building, Debugging, and Tuning Spark Machine Leaning Pipelines-(Joseph Bradl...
Building, Debugging, and Tuning Spark Machine Leaning Pipelines-(Joseph Bradl...Spark Summit This document discusses Spark ML pipelines for machine learning workflows. It begins with an introduction to Spark MLlib and the various algorithms it supports. It then discusses how ML workflows can be complex, involving multiple data sources, feature transformations, and models. Spark ML pipelines allow specifying the entire workflow as a single pipeline object. This simplifies debugging, re-running on new data, and parameter tuning. The document provides an example text classification pipeline and demonstrates how data is transformed through each step via DataFrames. It concludes by discussing upcoming improvements to Spark ML pipelines.
From Pipelines to Refineries: scaling big data applications with Tim Hunter
From Pipelines to Refineries: scaling big data applications with Tim HunterDatabricks The document discusses the future challenges and foundations for scaling big data applications using Apache Spark, emphasizing the need for a robust theoretical framework. It outlines the current state of Spark, the potential complexities in data flows, and the importance of lazy evaluation and declarative APIs to manage those complexities. The presentation also highlights trends in data processing and proposals for enhancing Spark's capabilities, such as a more complete Python interface.
Lessons Learned while Implementing a Sparse Logistic Regression Algorithm in ...
Lessons Learned while Implementing a Sparse Logistic Regression Algorithm in ...Spark Summit The document discusses lessons learned from implementing a sparse logistic regression algorithm in Spark, highlighting optimization techniques and the importance of using suitable representations for distributed implementations. Key insights include the use of mini-batch gradient descent, better bias initialization, and the Adam optimizer for improved convergence speed. Final performance improvements resulted in a 40x reduction in iteration time.
Apache Spark MLlib's Past Trajectory and New Directions with Joseph Bradley
Apache Spark MLlib's Past Trajectory and New Directions with Joseph BradleyDatabricks - MLlib has rapidly developed over the past 5 years, growing from a few algorithms to over 50 algorithms and featurizers for classification, regression, clustering, recommendation, and more.
- This growth has shifted from just adding algorithms to improving algorithms, infrastructure, and integrating ML workflows with Spark's broader capabilities like SQL, DataFrames, and streaming.
- Going forward, areas of focus include continued scalability improvements, enhancing core algorithms, extensible APIs, and making MLlib a more comprehensive standard library.
DASK and Apache Spark
DASK and Apache SparkDatabricks Gurpreet Singh from Microsoft gave a talk on scaling Python for data analysis and machine learning using DASK and Apache Spark. He discussed the challenges of scaling the Python data stack and compared options like DASK, Spark, and Spark MLlib. He provided examples of using DASK and PySpark DataFrames for parallel processing and showed how DASK-ML can be used to parallelize Scikit-Learn models. Distributed deep learning with tools like Project Hydrogen was also covered.
Dev Ops Training
Dev Ops TrainingSpark Summit The document provides an agenda for a DevOps advanced class on Spark being held in June 2015. The class will cover topics such as RDD fundamentals, Spark runtime architecture, memory and persistence, Spark SQL, PySpark, and Spark Streaming. It will include labs on DevOps 101 and 102. The instructor has over 5 years of experience providing Big Data consulting and training, including over 100 classes taught.
Large-Scale Data Science in Apache Spark 2.0
Large-Scale Data Science in Apache Spark 2.0Databricks This document discusses the enhancements in Apache Spark 2.0, focusing on its scalability for large-scale data science and AI through improved hardware and user scalability. It emphasizes the use of structured APIs for efficient data manipulation and introduces new features for deep learning and integration with existing Python and R libraries. The content highlights Spark's capabilities in parallelizing computations and the ease of building complex data science models with high-level APIs.
Accelerating Data Science with Better Data Engineering on Databricks
Accelerating Data Science with Better Data Engineering on DatabricksDatabricks Mediamath is a demand-side media buying platform that enhances ad performance using data analytics, facilitated by Databricks for efficient data processing. The document outlines the challenges faced with Hive due to the massive data volume and highlights the successful transition to Spark, resulting in significant performance improvements. The new workflow enables rapid development of data pipelines, increased productivity, and easy integration of data insights for reporting purposes.
Designing Distributed Machine Learning on Apache Spark
Designing Distributed Machine Learning on Apache SparkDatabricks This document summarizes Joseph Bradley's presentation on designing distributed machine learning on Apache Spark. Bradley is a committer and PMC member of Apache Spark and works as a software engineer at Databricks. He discusses how Spark provides a unified engine for distributed workloads and libraries like MLlib make it possible to perform scalable machine learning. Bradley outlines different methods for distributing ML algorithms, using k-means clustering as an example of reorganizing an algorithm to fit the MapReduce framework in a way that minimizes communication costs.
Simplify Distributed TensorFlow Training for Fast Image Categorization at Sta...
Simplify Distributed TensorFlow Training for Fast Image Categorization at Sta...Databricks This document discusses the use of Horovodrunner at Starbucks to simplify deep learning processes, particularly in distributed environments. The presenters, Denny Lee and Vishwanath Subramanian, emphasize the importance of providing efficient analytics solutions and facilitating machine learning capabilities for large-scale data processing. Key features include on-demand infrastructure provisioning, secured data connectivity, and templates for deploying experiments and applications.
Extending Apache Spark SQL Data Source APIs with Join Push Down with Ioana De...
Extending Apache Spark SQL Data Source APIs with Join Push Down with Ioana De...Databricks This document summarizes a presentation on extending Spark SQL Data Sources APIs with join push down. The presentation discusses how join push down can significantly improve query performance by reducing data transfer and exploiting data source capabilities like indexes. It provides examples of join push down in enterprise data pipelines and SQL acceleration use cases. The presentation also outlines the challenges of network speeds and exploiting data source capabilities, and how join push down addresses these challenges. Future work discussed includes building a cost model for global optimization across data sources.
Ray: A Cluster Computing Engine for Reinforcement Learning Applications with ...
Ray: A Cluster Computing Engine for Reinforcement Learning Applications with ...Databricks Ray is a distributed execution framework designed for emerging AI applications, particularly reinforcement learning. It enables the parallel processing of tasks, manages dynamic task graphs, and seamlessly integrates with Python, allowing for efficient scheduling and execution of machine learning algorithms. Ray's architecture supports high performance and fault tolerance, aiming to progress AI capabilities by simplifying the implementation of complex simulations and policy updates.
Deep-Dive into Deep Learning Pipelines with Sue Ann Hong and Tim Hunter
Deep-Dive into Deep Learning Pipelines with Sue Ann Hong and Tim HunterDatabricks This document discusses the use of Apache Spark for building, scaling, and deploying deep learning pipelines, emphasizing the integration of various libraries such as TensorFlow, Keras, and others. It outlines the typical workflow of deep learning, covers the benefits of using Spark for distributed training and efficient data handling, and highlights features of Databricks' deep learning pipelines which simplify the process without sacrificing performance. Additionally, it addresses future developments and current practices in the industry for enhancing deep learning accessibility.
Combining Machine Learning frameworks with Apache Spark
Combining Machine Learning frameworks with Apache SparkDataWorks Summit/Hadoop Summit This document discusses combining machine learning frameworks like TensorFlow with Apache Spark. It describes how Spark can be used to schedule and distribute machine learning tasks across a cluster in order to speed up model training. Specific examples are provided of using TensorFlow for neural network training on image data and distributing those computations using Spark. The document also outlines Apache Spark MLlib and its DataFrame-based APIs for building machine learning pipelines that can be trained and deployed at scale.
More Related Content
What's hot (20)
Resource-Efficient Deep Learning Model Selection on Apache Spark
Resource-Efficient Deep Learning Model Selection on Apache SparkDatabricks The document discusses resource-efficient deep learning model selection using Apache Spark, focusing on the challenges of training deep networks with various hyperparameters and architectures. It introduces Model Hopper Parallelism (MOP) as a method to improve efficiency through task parallelism and data parallelism while minimizing resource wastage. Additionally, it details the implementation of MOP on Spark, testing results, and comparisons with other tuning algorithms.
What's New in Apache Spark 2.3 & Why Should You Care
What's New in Apache Spark 2.3 & Why Should You CareDatabricks The document discusses the major features and enhancements in Apache Spark 2.3, including improvements in continuous processing, stream-stream joins, and PySpark performance. Key elements include the new structured streaming execution mode that offers low latency, support for various data formats, and integration with Kubernetes. The emphasis is placed on building robust streaming applications and the advantages of using Spark's unified analytics platform.
Getting Ready to Use Redis with Apache Spark with Dvir Volk
Getting Ready to Use Redis with Apache Spark with Dvir VolkSpark Summit The document outlines a presentation on using Redis for real-time machine learning, focusing on Redis-ML integrated with Apache Spark. It covers the capabilities of Redis as a key-value store, the functionalities of Redis-ML for model serving, and a case study involving a recommendation system. The concluding remarks emphasize the advantages of combining Spark for training with Redis for efficient model serving, highlighting reduced resource costs and simplified machine learning lifecycle.
Improving the Life of Data Scientists: Automating ML Lifecycle through MLflow
Improving the Life of Data Scientists: Automating ML Lifecycle through MLflowDatabricks This document discusses platforms for democratizing data science and enabling enterprise grade machine learning applications. It introduces Flock, a platform that aims to automate the machine learning lifecycle including tracking experiments, managing models, and deploying models for production. It demonstrates Flock by instrumenting Python code for a light gradient boosted machine model to track parameters, log models to MLFlow, convert the model to ONNX, optimize it, and deploy it as a REST API. Future work discussed includes improving Flock's data governance, generalizing auto-tracking capabilities, and integrating with other systems like SQL and Spark for end-to-end pipeline provenance.
No More Cumbersomeness: Automatic Predictive Modeling on Apache Spark with Ma...
No More Cumbersomeness: Automatic Predictive Modeling on Apache Spark with Ma...Databricks The document discusses the development of automatic predictive modeling using Apache Spark by researchers Masato Asahara and Ryohei Fujimaki from NEC Corporation. It highlights the transition from traditional manual modeling to automated systems that generate accurate predictive models in hours, showcasing various applications and the technological challenges faced. Future work includes improving speed through advanced hardware and extending the modeling capabilities to deep learning.
Jump Start with Apache Spark 2.0 on Databricks
Jump Start with Apache Spark 2.0 on DatabricksAnyscale This document provides an agenda for a 3+ hour workshop on Apache Spark 2.x on Databricks. It includes introductions to Databricks, Spark fundamentals and architecture, new features in Spark 2.0 like unified APIs, and workshops on DataFrames/Datasets, Spark SQL, and structured streaming concepts. The agenda covers lunch and breaks and is divided into hour and half hour segments.
A Tale of Three Deep Learning Frameworks: TensorFlow, Keras, & Deep Learning ...
A Tale of Three Deep Learning Frameworks: TensorFlow, Keras, & Deep Learning ...Databricks The document discusses three deep learning frameworks: TensorFlow, Keras, and Deep Learning Pipelines, highlighting their unique features, advantages, and use cases. It emphasizes the challenges posed by big data to machine learning systems and the importance of frameworks like Apache Spark for data processing. Additionally, the content provides insights on transfer learning, ease of integration, and the potential for deploying deep learning applications.
Spark Machine Learning: Adding Your Own Algorithms and Tools with Holden Kara...
Spark Machine Learning: Adding Your Own Algorithms and Tools with Holden Kara...Databricks The document discusses extending Spark ML estimators and transformers, focusing on implementing pipelines, estimators, and transformers in Apache Spark. It introduces key contributors, outlines the Spark Technology Center's mission, and details the process of loading data and training machine learning models using Spark SQL and various classes like StringIndexer and DecisionTreeClassifier. Additionally, it highlights how to create custom estimators and transformers, manage pipeline stages, and the advantages of utilizing ML pipelines for machine learning tasks.
Building, Debugging, and Tuning Spark Machine Leaning Pipelines-(Joseph Bradl...
Building, Debugging, and Tuning Spark Machine Leaning Pipelines-(Joseph Bradl...Spark Summit This document discusses Spark ML pipelines for machine learning workflows. It begins with an introduction to Spark MLlib and the various algorithms it supports. It then discusses how ML workflows can be complex, involving multiple data sources, feature transformations, and models. Spark ML pipelines allow specifying the entire workflow as a single pipeline object. This simplifies debugging, re-running on new data, and parameter tuning. The document provides an example text classification pipeline and demonstrates how data is transformed through each step via DataFrames. It concludes by discussing upcoming improvements to Spark ML pipelines.
From Pipelines to Refineries: scaling big data applications with Tim Hunter
From Pipelines to Refineries: scaling big data applications with Tim HunterDatabricks The document discusses the future challenges and foundations for scaling big data applications using Apache Spark, emphasizing the need for a robust theoretical framework. It outlines the current state of Spark, the potential complexities in data flows, and the importance of lazy evaluation and declarative APIs to manage those complexities. The presentation also highlights trends in data processing and proposals for enhancing Spark's capabilities, such as a more complete Python interface.
Lessons Learned while Implementing a Sparse Logistic Regression Algorithm in ...
Lessons Learned while Implementing a Sparse Logistic Regression Algorithm in ...Spark Summit The document discusses lessons learned from implementing a sparse logistic regression algorithm in Spark, highlighting optimization techniques and the importance of using suitable representations for distributed implementations. Key insights include the use of mini-batch gradient descent, better bias initialization, and the Adam optimizer for improved convergence speed. Final performance improvements resulted in a 40x reduction in iteration time.
Apache Spark MLlib's Past Trajectory and New Directions with Joseph Bradley
Apache Spark MLlib's Past Trajectory and New Directions with Joseph BradleyDatabricks - MLlib has rapidly developed over the past 5 years, growing from a few algorithms to over 50 algorithms and featurizers for classification, regression, clustering, recommendation, and more.
- This growth has shifted from just adding algorithms to improving algorithms, infrastructure, and integrating ML workflows with Spark's broader capabilities like SQL, DataFrames, and streaming.
- Going forward, areas of focus include continued scalability improvements, enhancing core algorithms, extensible APIs, and making MLlib a more comprehensive standard library.
DASK and Apache Spark
DASK and Apache SparkDatabricks Gurpreet Singh from Microsoft gave a talk on scaling Python for data analysis and machine learning using DASK and Apache Spark. He discussed the challenges of scaling the Python data stack and compared options like DASK, Spark, and Spark MLlib. He provided examples of using DASK and PySpark DataFrames for parallel processing and showed how DASK-ML can be used to parallelize Scikit-Learn models. Distributed deep learning with tools like Project Hydrogen was also covered.
Dev Ops Training
Dev Ops TrainingSpark Summit The document provides an agenda for a DevOps advanced class on Spark being held in June 2015. The class will cover topics such as RDD fundamentals, Spark runtime architecture, memory and persistence, Spark SQL, PySpark, and Spark Streaming. It will include labs on DevOps 101 and 102. The instructor has over 5 years of experience providing Big Data consulting and training, including over 100 classes taught.
Large-Scale Data Science in Apache Spark 2.0
Large-Scale Data Science in Apache Spark 2.0Databricks This document discusses the enhancements in Apache Spark 2.0, focusing on its scalability for large-scale data science and AI through improved hardware and user scalability. It emphasizes the use of structured APIs for efficient data manipulation and introduces new features for deep learning and integration with existing Python and R libraries. The content highlights Spark's capabilities in parallelizing computations and the ease of building complex data science models with high-level APIs.
Accelerating Data Science with Better Data Engineering on Databricks
Accelerating Data Science with Better Data Engineering on DatabricksDatabricks Mediamath is a demand-side media buying platform that enhances ad performance using data analytics, facilitated by Databricks for efficient data processing. The document outlines the challenges faced with Hive due to the massive data volume and highlights the successful transition to Spark, resulting in significant performance improvements. The new workflow enables rapid development of data pipelines, increased productivity, and easy integration of data insights for reporting purposes.
Designing Distributed Machine Learning on Apache Spark
Designing Distributed Machine Learning on Apache SparkDatabricks This document summarizes Joseph Bradley's presentation on designing distributed machine learning on Apache Spark. Bradley is a committer and PMC member of Apache Spark and works as a software engineer at Databricks. He discusses how Spark provides a unified engine for distributed workloads and libraries like MLlib make it possible to perform scalable machine learning. Bradley outlines different methods for distributing ML algorithms, using k-means clustering as an example of reorganizing an algorithm to fit the MapReduce framework in a way that minimizes communication costs.
Simplify Distributed TensorFlow Training for Fast Image Categorization at Sta...
Simplify Distributed TensorFlow Training for Fast Image Categorization at Sta...Databricks This document discusses the use of Horovodrunner at Starbucks to simplify deep learning processes, particularly in distributed environments. The presenters, Denny Lee and Vishwanath Subramanian, emphasize the importance of providing efficient analytics solutions and facilitating machine learning capabilities for large-scale data processing. Key features include on-demand infrastructure provisioning, secured data connectivity, and templates for deploying experiments and applications.
Extending Apache Spark SQL Data Source APIs with Join Push Down with Ioana De...
Extending Apache Spark SQL Data Source APIs with Join Push Down with Ioana De...Databricks This document summarizes a presentation on extending Spark SQL Data Sources APIs with join push down. The presentation discusses how join push down can significantly improve query performance by reducing data transfer and exploiting data source capabilities like indexes. It provides examples of join push down in enterprise data pipelines and SQL acceleration use cases. The presentation also outlines the challenges of network speeds and exploiting data source capabilities, and how join push down addresses these challenges. Future work discussed includes building a cost model for global optimization across data sources.
Ray: A Cluster Computing Engine for Reinforcement Learning Applications with ...
Ray: A Cluster Computing Engine for Reinforcement Learning Applications with ...Databricks Ray is a distributed execution framework designed for emerging AI applications, particularly reinforcement learning. It enables the parallel processing of tasks, manages dynamic task graphs, and seamlessly integrates with Python, allowing for efficient scheduling and execution of machine learning algorithms. Ray's architecture supports high performance and fault tolerance, aiming to progress AI capabilities by simplifying the implementation of complex simulations and policy updates.
Similar to Build, Scale, and Deploy Deep Learning Pipelines Using Apache Spark (20)
Deep-Dive into Deep Learning Pipelines with Sue Ann Hong and Tim Hunter
Deep-Dive into Deep Learning Pipelines with Sue Ann Hong and Tim HunterDatabricks This document discusses the use of Apache Spark for building, scaling, and deploying deep learning pipelines, emphasizing the integration of various libraries such as TensorFlow, Keras, and others. It outlines the typical workflow of deep learning, covers the benefits of using Spark for distributed training and efficient data handling, and highlights features of Databricks' deep learning pipelines which simplify the process without sacrificing performance. Additionally, it addresses future developments and current practices in the industry for enhancing deep learning accessibility.
Combining Machine Learning frameworks with Apache Spark
Combining Machine Learning frameworks with Apache SparkDataWorks Summit/Hadoop Summit This document discusses combining machine learning frameworks like TensorFlow with Apache Spark. It describes how Spark can be used to schedule and distribute machine learning tasks across a cluster in order to speed up model training. Specific examples are provided of using TensorFlow for neural network training on image data and distributing those computations using Spark. The document also outlines Apache Spark MLlib and its DataFrame-based APIs for building machine learning pipelines that can be trained and deployed at scale.
Combining Machine Learning Frameworks with Apache Spark
Combining Machine Learning Frameworks with Apache SparkDatabricks This document discusses combining machine learning frameworks with Apache Spark. It provides an overview of Apache Spark and MLlib, describes how to distribute TensorFlow computations using Spark, and discusses managing machine learning workflows with Spark through features like cross validation, persistence, and distributed data sources. The goal is to make machine learning easy, scalable, and integrate with existing workflows.
Deep learning and Apache Spark
Deep learning and Apache SparkQuantUniversity The document is a presentation about a QuantUniversity meetup on deep learning and Apache Spark, featuring Sri Krishnamurthy, who discusses various deep learning frameworks and their integration with Spark for efficient data processing. It highlights the use of technologies like TensorFlow, BigDL, and DeepLearning4J for distributed deep learning, showcasing benefits such as reduced training time and resource efficiency. Upcoming workshops and events related to deep learning are also announced, along with resources for further learning.
Fighting Fraud with Apache Spark
Fighting Fraud with Apache SparkMiklos Christine Miklos Christine is a solutions architect at Databricks who helps customers build big data platforms using Apache Spark. Databricks is the main contributor to the Apache Spark project. Spark is an open source engine for large-scale data processing that can be used for machine learning. Spark ML provides machine learning algorithms and pipelines to make machine learning scalable and easier to use at an enterprise level. Spark 2.0 includes improvements to Spark ML such as new algorithms and better support for Python.
A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and ...
A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and ...Jose Quesada (hiring) The document compares machine learning pipelines in scikit-learn and Scala-Spark, discussing the advantages of Spark for distributed machine learning workloads. It emphasizes Spark's capacity for real-time processing, ease of programming, and its unified DataFrame-based API in Spark 2.0, while also pointing out the potential challenges within Spark ML, such as feature indexing and the maximum depth limit for trees. Overall, it highlights Spark's evolution and its significant improvements over Hadoop in the context of machine learning.
Apache Spark MLlib
Apache Spark MLlib Zahra Eskandari This document provides an overview and agenda for a course on Spark MLlib. The course covers Spark fundamentals, SQL, streaming and MLlib. The MLlib section includes an overview of MLlib, a quick review of machine learning concepts, and why MLlib is useful. It describes the main concepts in MLlib like DataFrames, transformers, estimators and pipelines. It provides examples of classification using logistic regression on text data, regression to predict tweet impressions, and topic modeling on tweets. Finally, it lists some of the algorithms in MLlib, including classification, regression, clustering and tree ensemble methods.
Build Deep Learning Applications for Big Data Platforms (CVPR 2018 tutorial)
Build Deep Learning Applications for Big Data Platforms (CVPR 2018 tutorial)Jason Dai This document outlines an agenda for a talk on building deep learning applications on big data platforms using Analytics Zoo. The agenda covers motivations around trends in big data, deep learning frameworks on Apache Spark like BigDL and TensorFlowOnSpark, an introduction to Analytics Zoo and its high-level pipeline APIs, built-in models, and reference use cases. It also covers distributed training in BigDL, advanced applications, and real-world use cases of deep learning on big data at companies like JD.com and World Bank. The talk concludes with a question and answer session.
Data Science at Scale with Apache Spark and Zeppelin Notebook
Data Science at Scale with Apache Spark and Zeppelin NotebookCarolyn Duby The document discusses the capabilities of Apache Spark and Zeppelin for scalable data science, focusing on distributed computing to overcome desktop limitations. It highlights features such as data cleaning, analysis, and collaborative result sharing, along with various libraries and tools for machine learning, streaming, and visualization. Additionally, it provides guidance on getting started with these technologies, including environment setup and best practices for data pipelines and notebook sharing.
Apache® Spark™ MLlib: From Quick Start to Scikit-Learn
Apache® Spark™ MLlib: From Quick Start to Scikit-LearnDatabricks The document provides an overview of Apache Spark's MLlib, highlighting its capabilities for machine learning at scale, emphasizing its design advantages like simplicity and scalability. It features insights from Joseph K. Bradley and Denny Lee, discussing the integration of MLlib with tools like scikit-learn, and the advantages of automating decision-making for large datasets. The document also includes examples and workflows for using MLlib effectively in data analysis scenarios.
Metail and Elastic MapReduce
Metail and Elastic MapReduceGareth Rogers Metail provides an online fitting tool that enhances customer return rates and sales through personalized garment suggestions. The document outlines the data architecture and ETL processes utilized in their system, emphasizing the use of Snowplow, AWS EMR, and Redshift for data handling. The pipeline, managed by a small team, illustrates the integration of various technologies to support evolving data needs.
BDM25 - Spark runtime internal
BDM25 - Spark runtime internalDavid Lauzon Nan Zhu is a PhD candidate at McGill University, specializing in computer networks and large-scale data processing, contributing to Spark through various code patches. His work at the startup Faimdata involves building customer-centric analytical solutions. The document explains Spark's advantages as a distributed computing framework, emphasizing its resilient distributed datasets (RDD), fault-tolerance, and caching capabilities for improved performance.
MLlib: Spark's Machine Learning Library
MLlib: Spark's Machine Learning Libraryjeykottalam This document summarizes the history and ongoing development of MLlib, Spark's machine learning library. MLlib was initially developed by the MLbase team in 2013 and has since grown significantly with over 80 contributors. It provides algorithms for classification, regression, clustering, collaborative filtering, and linear algebra/optimization. Recent improvements include new algorithms like random forests, pipelines for simplified ML workflows, and continued performance gains.
The Nitty Gritty of Advanced Analytics Using Apache Spark in Python
The Nitty Gritty of Advanced Analytics Using Apache Spark in PythonMiklos Christine The document outlines the evolution and features of Apache Spark, highlighting its capabilities in advanced analytics and machine learning. It details Spark's architecture, usage statistics, best practices for ETL processes, and challenges like the small files problem. Additionally, it emphasizes the importance of using built-in functions and pipelines in Spark ML for efficient model building and data processing.
Apache ® Spark™ MLlib 2.x: How to Productionize your Machine Learning Models
Apache ® Spark™ MLlib 2.x: How to Productionize your Machine Learning ModelsAnyscale This document provides an overview of how to productionize machine learning models using Apache Spark MLlib 2.x, highlighting key concepts like model serialization, scoring architectures, and the importance of agile deployment. It discusses the evolution of Spark MLlib, its integration within data science workflows, and various deployment strategies tailored for different environments. The goal is to enable efficient model deployment that supports rapid updates and performance monitoring.
Apache Spark's MLlib's Past Trajectory and new Directions
Apache Spark's MLlib's Past Trajectory and new DirectionsDatabricks - MLlib has rapidly developed over the past 5 years, growing from a few initial algorithms to over 50 algorithms and featurizers today.
- It has shifted focus from just adding algorithms to improving existing algorithms and infrastructure like DataFrame integration.
- This allows for scalable machine learning workflows on big data from small laptop datasets to large clusters, with seamless integration between SQL, DataFrames, streaming, and other Spark components.
- Going forward, areas of focus include continued improvements to scalability, enhancing core algorithms, extending APIs to support custom algorithms, and building out a standard library of machine learning components.
Enterprise Deep Learning with DL4J
Enterprise Deep Learning with DL4JJosh Patterson Josh Patterson presented on deep learning and DL4J. He began with an overview of deep learning, explaining it as automated feature engineering where machines learn representations of the world. He then discussed DL4J, describing it as the "Hadoop of deep learning" - an open source deep learning library with Java, Scala, and Python APIs that supports parallelization on Hadoop, Spark, and GPUs. He demonstrated building deep learning workflows with DL4J and Canova, using the Iris dataset as an example to show how data can be vectorized with Canova and then a model trained on it using DL4J from the command line. He concluded by describing Skymind as a distribution of DL4J with enterprise
A machine learning and data science pipeline for real companies
A machine learning and data science pipeline for real companiesDataWorks Summit Comcast is implementing a data science pipeline that integrates multi-datacenter, cloud, and on-premise machine learning to enhance customer experience and operational efficiency. The approach focuses on a standardized system for managing features and models, leveraging frameworks like Spark and Databricks, while promoting accessibility and self-service capabilities for users. Key components include a feature store, model store, job scheduler, and workflow management to enable streamlined data transformations and machine learning operations.
Apache spark
Apache sparkHitesh Dua Apache Spark is an open-source parallel processing framework for large-scale data analytics, significantly outperforming MapReduce in speed for certain applications. It supports both in-memory and disk-based processing, and offers a range of high-level libraries for tasks such as machine learning (MLlib), streaming (Spark Streaming), and graph processing (GraphX). Spark SQL facilitates querying structured data through SQL and integrates various Spark components seamlessly.
Using SparkML to Power a DSaaS (Data Science as a Service): Spark Summit East...
Using SparkML to Power a DSaaS (Data Science as a Service): Spark Summit East...Spark Summit The document discusses Sparkle, a solution built by Comcast to address challenges in processing massive amounts of data and enabling data science workflows at scale. Sparkle is a centralized processing system with SQL and machine learning capabilities that is highly scalable and accessible via a REST API. It is used by Comcast to power various use cases including churn modeling, price elasticity analysis, and direct mail campaign optimization.
A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and ...
A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and ...Jose Quesada (hiring)
Ad
More from Databricks (20)
DW Migration Webinar-March 2022.pptx
DW Migration Webinar-March 2022.pptxDatabricks The document discusses migrating a data warehouse to the Databricks Lakehouse Platform. It outlines why legacy data warehouses are struggling, how the Databricks Platform addresses these issues, and key considerations for modern analytics and data warehousing. The document then provides an overview of the migration methodology, approach, strategies, and key takeaways for moving to a lakehouse on Databricks.
Data Lakehouse Symposium | Day 1 | Part 1
Data Lakehouse Symposium | Day 1 | Part 1Databricks The document discusses the concept of a data lakehouse, highlighting the integration of structured, textual, and analog/IOT data. It emphasizes the importance of common identifiers and universal connectors for meaningful analytics across different data types, ultimately aiming to improve healthcare and manufacturing outcomes through effective data analysis. The presentation outlines the challenges of managing diverse data formats and the potential for data-driven insights to enhance quality of life.
Data Lakehouse Symposium | Day 1 | Part 2
Data Lakehouse Symposium | Day 1 | Part 2Databricks The document compares data lakehouses and data warehouses, outlining their similarities and differences. Both serve analytical processing and contain vetted, historical data, but the data lakehouse handles a much larger volume of machine-generated data and features fundamentally different structures from transaction-based data warehouses. Ultimately, they are presented as related yet distinct entities in the realm of data management.
Data Lakehouse Symposium | Day 2
Data Lakehouse Symposium | Day 2Databricks The Data Lakehouse Symposium held in February 2022 discussed the evolution of data management from data warehouses to lakehouses, emphasizing the integration of governance and metadata. It highlighted the challenges companies face in utilizing various types of data, particularly unstructured textual data, and the importance of adding context for effective analysis. The presentation also examined strategies for transforming unstructured data into structured formats to enable better decision-making and analytical processes.
Data Lakehouse Symposium | Day 4
Data Lakehouse Symposium | Day 4Databricks The document discusses the challenges of modern data, analytics, and AI workloads. Most enterprises struggle with siloed data systems that make integration and productivity difficult. The future of data lies with a data lakehouse platform that can unify data engineering, analytics, data warehousing, and machine learning workloads on a single open platform. The Databricks Lakehouse platform aims to address these challenges with its open data lake approach and capabilities for data engineering, SQL analytics, governance, and machine learning.
5 Critical Steps to Clean Your Data Swamp When Migrating Off of Hadoop
5 Critical Steps to Clean Your Data Swamp When Migrating Off of HadoopDatabricks The document outlines the challenges and considerations for migrating from Hadoop to Databricks, emphasizing the complexities of the Hadoop ecosystem and the advantages of a modern cloud-based data architecture. It provides a comprehensive migration plan that includes internal assessments, technical planning, and execution while addressing key topics such as data migration, security, and SQL integration. Specific tools and methodologies for effective transition and enhanced performance in data analytics are also discussed.
Democratizing Data Quality Through a Centralized Platform
Democratizing Data Quality Through a Centralized PlatformDatabricks Zillow's Data Governance Platform team addresses data quality challenges by creating a centralized platform that enhances visibility and standardizes data quality rules. The platform includes self-service capabilities and integrates with data lineage, allowing for built-in alerting and scalable onboarding. Key takeaways emphasize the importance of early alerting, collaboration, and the shared responsibility for maintaining high-quality data to improve decision-making.
Learn to Use Databricks for Data Science
Learn to Use Databricks for Data ScienceDatabricks The document outlines the challenges and workflows involved in data science, emphasizing the need for proper setup and resource management. It highlights the importance of sharing results with stakeholders and describes how Databricks' lakehouse platform simplifies these processes by integrating data sources and providing essential tools for data analysis. Overall, the goal is to help data scientists focus on their core analytical work rather than dealing with setup complexities.
Why APM Is Not the Same As ML Monitoring
Why APM Is Not the Same As ML MonitoringDatabricks The document discusses the distinctions between application performance monitoring (APM) and machine learning (ML) monitoring, emphasizing the unique challenges of ML monitoring, such as the need for intelligent detection and alerting. It outlines the essential components of ML monitoring, including statistical summarization, distribution comparison, and actionable alerts based on model performance. Additionally, it introduces Verta's end-to-end MLOps platform designed to meet the specialized needs of ML monitoring throughout the entire model lifecycle.
The Function, the Context, and the Data—Enabling ML Ops at Stitch Fix
The Function, the Context, and the Data—Enabling ML Ops at Stitch FixDatabricks Elijah Ben Izzy, a Data Platform Engineer at Stitch Fix, discusses building abstractions for machine learning operations to optimize workflows and enhance the separation of concerns between data science and platform engineering. The presentation highlights the importance of a custom-built model envelope for seamless integration and management of ML models, as well as advancements in deployment and inference processes. Future directions include enhanced production monitoring and sophisticated feature integration to further streamline data science workflows.
Stage Level Scheduling Improving Big Data and AI Integration
Stage Level Scheduling Improving Big Data and AI IntegrationDatabricks The document discusses stage-level scheduling and resource allocation in Apache Spark to enhance big data and AI integration. It outlines various resource requirements such as executors, memory, and accelerators, while presenting benefits like improved hardware utilization and simplified application pipelines. Additionally, it introduces the RAPIDS Accelerator for Spark and distributed deep learning with Horovod, emphasizing performance optimizations and future enhancements.
Simplify Data Conversion from Spark to TensorFlow and PyTorch
Simplify Data Conversion from Spark to TensorFlow and PyTorchDatabricks The document discusses the importance of data conversion between Spark and deep learning frameworks like TensorFlow and PyTorch. It highlights key pain points, such as challenges in migrating from single-node to distributed training and the complexity of saving and loading data. Additionally, it introduces the Spark Dataset Converter, which simplifies data handling while training deep learning models and offers best practices for efficient usage.
Scaling your Data Pipelines with Apache Spark on Kubernetes
Scaling your Data Pipelines with Apache Spark on KubernetesDatabricks This document discusses the integration of Apache Spark with Kubernetes on Google Cloud, highlighting its advantages for running data engineering and machine learning workloads within existing infrastructure. It outlines benefits such as improved cost optimization, faster scaling, and enhanced resource management through Google Kubernetes Engine (GKE) and Dataproc, while detailing implementation steps and monitoring options. Additionally, it covers the compatibility with big data ecosystem tools, job execution, and enterprise security features.
Scaling and Unifying SciKit Learn and Apache Spark Pipelines
Scaling and Unifying SciKit Learn and Apache Spark PipelinesDatabricks The document discusses the integration and scaling of AI/ML pipelines using Ray, aiming to unify Scikit-learn and Spark pipelines. Key features include Python functions as computation units, data exchange capabilities, and support for advanced execution strategies. It concludes with contact information for collaboration and emphasizes the importance of feedback from the community.
Sawtooth Windows for Feature Aggregations
Sawtooth Windows for Feature AggregationsDatabricks The document discusses the Sawtooth Windows Zipline, a feature engineering framework focusing on machine learning with structured data. It emphasizes the importance of real-time, stable, and consistent features for model training and serving, while highlighting the challenges of data sources and the intricacies of aggregations. Key topics include model complexity, data quality, and various types of windowed aggregations for efficient data processing.
Redis + Apache Spark = Swiss Army Knife Meets Kitchen Sink
Redis + Apache Spark = Swiss Army Knife Meets Kitchen SinkDatabricks The document discusses the integration of Redis with Apache Spark for managing long-running batch jobs and distributed counters. It outlines the challenges faced in submitting queries and the inefficiencies of existing solutions, proposing a system that utilizes Redis for queuing and job status communication. Key workflows and code views are provided to demonstrate the proposed solutions for efficient query handling and data processing.
Re-imagine Data Monitoring with whylogs and Spark
Re-imagine Data Monitoring with whylogs and SparkDatabricks The document discusses the challenges of monitoring machine learning data, emphasizing how traditional data analysis techniques fall short in addressing issues in ML data pipelines. It introduces the open-source library Whylogs for data logging, highlighting its lightweight profiling methods suitable for large datasets and integration with Apache Spark. Key topics include data quality problems, the need for scalable monitoring, and approaches for logging and analyzing ML data effectively.
Raven: End-to-end Optimization of ML Prediction Queries
Raven: End-to-end Optimization of ML Prediction QueriesDatabricks The document discusses Raven, an optimizer for machine learning prediction queries at Microsoft, focusing on its ability to improve the performance of SQL-based ML operations. It details how Raven integrates with Azure data engines, utilizing techniques like model projection pushdown and model-to-SQL translation to enhance query efficiency. Performance evaluations indicate that Raven significantly outperforms existing ML runtimes in various scenarios, achieving speed increases of up to 44 times compared to traditional approaches.
Processing Large Datasets for ADAS Applications using Apache Spark
Processing Large Datasets for ADAS Applications using Apache SparkDatabricks The document outlines the use of Spark for processing large datasets in automated driving applications, focusing on semantic segmentation and the challenges of moving from prototype to production. It presents the architecture of the system, covering ETL processes, model training, and inference, while addressing design considerations like scaling, security, and governance. Key takeaways emphasize the importance of leveraging cloud-based solutions and effective workflow management to enhance the development of perception software for autonomous vehicles.
Massive Data Processing in Adobe Using Delta Lake
Massive Data Processing in Adobe Using Delta LakeDatabricks The document discusses massive data processing at Adobe using Delta Lake, highlighting various aspects such as data representation, schema evolution, and challenges in data ingestion. It emphasizes the performance benefits of utilizing Delta Lake for handling large-scale data efficiently, while considering issues like schema management and replication lag. Key features like ACID transactions and lazy schema on-read approaches are also outlined to address the complexities of multi-tenant data architecture.
Ad
Recently uploaded (20)
You are not excused! How to avoid security blind spots on the way to production
You are not excused! How to avoid security blind spots on the way to productionMichele Leroux Bustamante We live in an ever evolving landscape for cyber threats creating security risk for your production systems. Mitigating these risks requires participation throughout all stages from development through production delivery - and by every role including architects, developers QA and DevOps engineers, product owners and leadership. No one is excused! This session will cover examples of common mistakes or missed opportunities that can lead to vulnerabilities in production - and ways to do better throughout the development lifecycle.
Edge-banding-machines-edgeteq-s-200-en-.pdf
Edge-banding-machines-edgeteq-s-200-en-.pdfAmirStern2 מכונת קנטים המתאימה לנגריות קטנות או גדולות (כמכונת גיבוי).
מדביקה קנטים מגליל או פסים, עד עובי קנט – 3 מ"מ ועובי חומר עד 40 מ"מ. בקר ממוחשב המתריע על תקלות, ומנועים מאסיביים תעשייתיים כמו במכונות הגדולות.
War_And_Cyber_3_Years_Of_Struggle_And_Lessons_For_Global_Security.pdf
War_And_Cyber_3_Years_Of_Struggle_And_Lessons_For_Global_Security.pdfbiswajitbanerjee38 Russia is one of the most aggressive nations when it comes to state coordinated cyberattacks — and Ukraine has been at the center of their crosshairs for 3 years. This report, provided the State Service of Special Communications and Information Protection of Ukraine contains an incredible amount of cybersecurity insights, showcasing the coordinated aggressive cyberwarfare campaigns of Russia against Ukraine.
It brings to the forefront that understanding your adversary, especially an aggressive nation state, is important for cyber defense. Knowing their motivations, capabilities, and tactics becomes an advantage when allocating resources for maximum impact.
Intelligence shows Russia is on a cyber rampage, leveraging FSB, SVR, and GRU resources to professionally target Ukraine’s critical infrastructures, military, and international diplomacy support efforts.
The number of total incidents against Ukraine, originating from Russia, has steadily increased from 1350 in 2021 to 4315 in 2024, but the number of actual critical incidents has been managed down from a high of 1048 in 2022 to a mere 59 in 2024 — showcasing how the rapid detection and response to cyberattacks has been impacted by Ukraine’s improved cyber resilience.
Even against a much larger adversary, Ukraine is showcasing outstanding cybersecurity, enabled by strong strategies and sound tactics. There are lessons to learn for any enterprise that could potentially be targeted by aggressive nation states.
Definitely worth the read!
OpenPOWER Foundation & Open-Source Core Innovations
OpenPOWER Foundation & Open-Source Core InnovationsIBM penPOWER offers a fully open, royalty-free CPU architecture for custom chip design.
It enables both lightweight FPGA cores (like Microwatt) and high-performance processors (like POWER10).
Developers have full access to source code, specs, and tools for end-to-end chip creation.
It supports AI, HPC, cloud, and embedded workloads with proven performance.
Backed by a global community, it fosters innovation, education, and collaboration.
“Key Requirements to Successfully Implement Generative AI in Edge Devices—Opt...
“Key Requirements to Successfully Implement Generative AI in Edge Devices—Opt...Edge AI and Vision Alliance For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/06/key-requirements-to-successfully-implement-generative-ai-in-edge-devices-optimized-mapping-to-the-enhanced-npx6-neural-processing-unit-ip-a-presentation-from-synopsys/
Gordon Cooper, Principal Product Manager at Synopsys, presents the “Key Requirements to Successfully Implement Generative AI in Edge Devices—Optimized Mapping to the Enhanced NPX6 Neural Processing Unit IP” tutorial at the May 2025 Embedded Vision Summit.
In this talk, Cooper discusses emerging trends in generative AI for edge devices and the key role of transformer-based neural networks. He reviews the distinct attributes of transformers, their advantages over conventional convolutional neural networks and how they enable generative AI.
Cooper then covers key requirements that must be met for neural processing units (NPU) to support transformers and generative AI in edge device applications. He uses transformer-based generative AI examples to illustrate the efficient mapping of these workloads onto the enhanced Synopsys ARC NPX NPU IP family.
Turning the Page – How AI is Exponentially Increasing Speed, Accuracy, and Ef...
Turning the Page – How AI is Exponentially Increasing Speed, Accuracy, and Ef...Impelsys Inc. Artificial Intelligence (AI) has become a game-changer in content creation, automating tasks that were once very time-consuming and labor-intensive. AI-powered tools are now capable of generating high-quality articles, blog posts, and even poetry by analyzing large datasets of text and producing human-like writing.
However, AI’s influence on content generation is not limited to text; it has also made advancements in multimedia content, such as image, video, and audio generation. AI-powered tools can now transform raw images and footage into visually stunning outputs, and are all set to have a profound impact on the publishing industry.
Enabling BIM / GIS integrations with Other Systems with FME
Enabling BIM / GIS integrations with Other Systems with FMESafe Software Jacobs has successfully utilized FME to tackle the complexities of integrating diverse data sources in a confidential $1 billion campus improvement project. The project aimed to create a comprehensive digital twin by merging Building Information Modeling (BIM) data, Construction Operations Building Information Exchange (COBie) data, and various other data sources into a unified Geographic Information System (GIS) platform. The challenge lay in the disparate nature of these data sources, which were siloed and incompatible with each other, hindering efficient data management and decision-making processes.
To address this, Jacobs leveraged FME to automate the extraction, transformation, and loading (ETL) of data between ArcGIS Indoors and IBM Maximo. This process ensured accurate transfer of maintainable asset and work order data, creating a comprehensive 2D and 3D representation of the campus for Facility Management. FME's server capabilities enabled real-time updates and synchronization between ArcGIS Indoors and Maximo, facilitating automatic updates of asset information and work orders. Additionally, Survey123 forms allowed field personnel to capture and submit data directly from their mobile devices, triggering FME workflows via webhooks for real-time data updates. This seamless integration has significantly enhanced data management, improved decision-making processes, and ensured data consistency across the project lifecycle.
ENERGY CONSUMPTION CALCULATION IN ENERGY-EFFICIENT AIR CONDITIONER.pdf
ENERGY CONSUMPTION CALCULATION IN ENERGY-EFFICIENT AIR CONDITIONER.pdfMuhammad Rizwan Akram DC Inverter Air Conditioners are revolutionizing the cooling industry by delivering affordable,
energy-efficient, and environmentally sustainable climate control solutions. Unlike conventional
fixed-speed air conditioners, DC inverter systems operate with variable-speed compressors that
modulate cooling output based on demand, significantly reducing energy consumption and
extending the lifespan of the appliance.
These systems are critical in reducing electricity usage, lowering greenhouse gas emissions, and
promoting eco-friendly technologies in residential and commercial sectors. With advancements in
compressor control, refrigerant efficiency, and smart energy management, DC inverter air conditioners
have become a benchmark in sustainable climate control solutions
FME for Distribution & Transmission Integrity Management Program (DIMP & TIMP)
FME for Distribution & Transmission Integrity Management Program (DIMP & TIMP)Safe Software Peoples Gas in Chicago, IL has changed to a new Distribution & Transmission Integrity Management Program (DIMP & TIMP) software provider in recent years. In order to successfully deploy the new software we have created a series of ETL processes using FME Form to transform our gas facility data to meet the required DIMP & TIMP data specifications. This presentation will provide an overview of how we used FME to transform data from ESRI’s Utility Network and several other internal and external sources to meet the strict data specifications for the DIMP and TIMP software solutions.
Smarter Aviation Data Management: Lessons from Swedavia Airports and Sweco
Smarter Aviation Data Management: Lessons from Swedavia Airports and SwecoSafe Software Managing airport and airspace data is no small task, especially when you’re expected to deliver it in AIXM format without spending a fortune on specialized tools. But what if there was a smarter, more affordable way?
Join us for a behind-the-scenes look at how Sweco partnered with Swedavia, the Swedish airport operator, to solve this challenge using FME and Esri.
Learn how they built automated workflows to manage periodic updates, merge airspace data, and support data extracts – all while meeting strict government reporting requirements to the Civil Aviation Administration of Sweden.
Even better? Swedavia built custom services and applications that use the FME Flow REST API to trigger jobs and retrieve results – streamlining tasks like securing the quality of new surveyor data, creating permdelta and baseline representations in the AIS schema, and generating AIXM extracts from their AIS data.
To conclude, FME expert Dean Hintz will walk through a GeoBorders reading workflow and highlight recent enhancements to FME’s AIXM (Aeronautical Information Exchange Model) processing and interpretation capabilities.
Discover how airports like Swedavia are harnessing the power of FME to simplify aviation data management, and how you can too.
From Manual to Auto Searching- FME in the Driver's Seat
From Manual to Auto Searching- FME in the Driver's SeatSafe Software Finding a specific car online can be a time-consuming task, especially when checking multiple dealer websites. A few years ago, I faced this exact problem while searching for a particular vehicle in New Zealand. The local classified platform, Trade Me (similar to eBay), wasn’t yielding any results, so I expanded my search to second-hand dealer sites—only to realise that periodically checking each one was going to be tedious. That’s when I noticed something interesting: many of these websites used the same platform to manage their inventories. Recognising this, I reverse-engineered the platform’s structure and built an FME workspace that automated the search process for me. By integrating API calls and setting up periodic checks, I received real-time email alerts when matching cars were listed. In this presentation, I’ll walk through how I used FME to save hours of manual searching by creating a custom car-finding automation system. While FME can’t buy a car for you—yet—it can certainly help you find the one you’re after!
FIDO Seminar: Targeting Trust: The Future of Identity in the Workforce.pptx
FIDO Seminar: Targeting Trust: The Future of Identity in the Workforce.pptxFIDO Alliance FIDO Seminar: Targeting Trust: The Future of Identity in the Workforce
Improving Data Integrity: Synchronization between EAM and ArcGIS Utility Netw...
Improving Data Integrity: Synchronization between EAM and ArcGIS Utility Netw...Safe Software Utilities and water companies play a key role in the creation of clean drinking water. The creation and maintenance of clean drinking water is becoming a critical problem due to pollution and pressure on the environment. A lot of data is necessary to create clean drinking water. For fieldworkers, two types of data are key: Asset data in an asset management system (EAM for example) and Geographic data in a GIS (ArcGIS Utility Network ). Keeping this type of data up to date and in sync is a challenge for many organizations, leading to duplicating data and creating a bulk of extra attributes and data to keep everything in sync. Using FME, it is possible to synchronize Enterprise Asset Management (EAM) data with the ArcGIS Utility Network in real time. Changes (creation, modification, deletion) in ArcGIS Pro are relayed to EAM via FME, and vice versa. This ensures continuous synchronization of both systems without daily bulk updates, minimizes risks, and seamlessly integrates with ArcGIS Utility Network services. This presentation focuses on the use of FME at a Dutch water company, to create a sync between the asset management and GIS.
Information Security Response Team Nepal_npCERT_Vice_President_Sudan_Jha.pdf
Information Security Response Team Nepal_npCERT_Vice_President_Sudan_Jha.pdfICT Frame Magazine Pvt. Ltd. Artificial Intelligence (AI) is rapidly changing the face of cybersecurity across the globe. In Nepal, the shift is already underway. Vice President of the Information Security Response Team Nepal (npCERT) and Information Security Consultant at One Cover Pvt. Ltd., Sudan Jha, recently presented an in-depth workshop on how AI can strengthen national security and digital defenses.
Viral>Wondershare Filmora 14.5.18.12900 Crack Free Download
Viral>Wondershare Filmora 14.5.18.12900 Crack Free DownloadPuppy jhon ➡ 🌍📱👉COPY & PASTE LINK👉👉👉 ➤ ➤➤ https://drfiles.net/
Wondershare Filmora Crack is a user-friendly video editing software designed for both beginners and experienced users.
Security Tips for Enterprise Azure Solutions
Security Tips for Enterprise Azure SolutionsMichele Leroux Bustamante Delivering solutions to Azure may involve a variety of architecture patterns involving your applications, APIs data and associated Azure resources that comprise the solution. This session will use reference architectures to illustrate the security considerations to protect your Azure resources and data, how to achieve Zero Trust, and why it matters. Topics covered will include specific security recommendations for types Azure resources and related network security practices. The goal is to give you a breadth of understanding as to typical security requirements to meet compliance and security controls in an enterprise solution.
The Future of Data, AI, and AR: Innovation Inspired by You.pdf
The Future of Data, AI, and AR: Innovation Inspired by You.pdfSafe Software The future of FME is inspired by you. We can't wait to show you what's ahead for FME and Safe Software.
Securing Account Lifecycles in the Age of Deepfakes.pptx
Securing Account Lifecycles in the Age of Deepfakes.pptxFIDO Alliance Securing Account Lifecycles in the Age of Deepfakes
You are not excused! How to avoid security blind spots on the way to production
You are not excused! How to avoid security blind spots on the way to productionMichele Leroux Bustamante
“Key Requirements to Successfully Implement Generative AI in Edge Devices—Opt...
“Key Requirements to Successfully Implement Generative AI in Edge Devices—Opt...Edge AI and Vision Alliance
Information Security Response Team Nepal_npCERT_Vice_President_Sudan_Jha.pdf
Information Security Response Team Nepal_npCERT_Vice_President_Sudan_Jha.pdfICT Frame Magazine Pvt. Ltd.
Build, Scale, and Deploy Deep Learning Pipelines Using Apache Spark
- 1. Build, Scale, and Deploy Deep Learning Pipelines Using Apache Spark Tim Hunter, Databricks Spark Meetup London, March 2018
- 2. About Me Tim Hunter • Software engineer @ Databricks • Ph.D. from UC Berkeley in Machine Learning • Very early Spark user (Spark 0.0.2) • Co-creator of GraphFrames, TensorFrames, Joint work with Sue Ann Hong
- 3. TEAM About Databricks Started Spark project (now Apache Spark) at UC Berkeley in 2009 PRODUCT Unified Analytics Platform MISSION Making Big Data Simple Try for free today. databricks.com
- 4. This talk • Deep Learning at scale: current state • Deep Learning Pipelines: the vision • End-to-end workflow with DL Pipelines • Future
- 5. Deep Learning at Scale : current state 5put your #assignedhashtag here by setting the
- 6. What is Deep Learning? • A set of machine learning techniques that use layers that transform numerical inputs • Classification • Regression • Arbitrary mapping • Popular in the 80’s as Neural Networks • Recently came back thanks to advances in data collection, computation techniques, and hardware. t
- 7. Success of Deep Learning Tremendous success for applications with complex data • AlphaGo • Image interpretation • Automatic translation • Speech recognition
- 8. But requires a lot of effort • No exact science around deep learning • Success requires many engineer-hours • Low level APIs with steep learning curve • Not well integrated with other enterprise tools • Tedious to distribute computations
- 9. What does Spark offer? Very little in Apache Spark MLlib itself (multilayer perceptron) Many Spark packages Integrations with existing DL libraries • Deep Learning Pipelines (from Databricks) • Caffe (CaffeOnSpark) • Keras (Elephas) • mxnet • Paddle • TensorFlow (TensorFlow on Spark, TensorFrames) • CNTK (mmlspark) Implementations of DL on Spark • BigDL • DeepDist • DeepLearning4J • MLlib • SparkCL • SparkNet
- 10. Deep Learning in industry • Currently limited adoption • Huge potential beyond the industrial giants • How do we accelerate the road to massive availability?
- 12. Deep Learning Pipelines: Deep Learning with Simplicity • Open-source Databricks library • Focuses on ease of use and integration • without sacrificing performance • Primary language: Python • Uses Apache Spark for scaling out common tasks • Integrates with MLlib Pipelines to capture the ML workflow concisely s
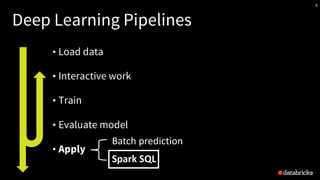
- 13. A typical Deep Learning workflow • Load data (images, text, time series, …) • Interactive work • Train • Select an architecture for a neural network • Optimize the weights of the NN • Evaluate results, potentially re-train • Apply: • Pass the data through the NN to produce new features or output Load data Interactive work Train Evaluate Apply
- 14. A typical Deep Learning workflow Load data Interactive work Train Evaluate Apply • Image loading in Spark • Distributed batch prediction • Deploying models in SQL • Transfer learning • Distributed tuning • Pre-trained models
- 15. End-to-End Workflow with Deep Learning Pipelines 15put your #assignedhashtag here by setting the
- 16. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply t
- 17. Built-in support in Spark • In Spark 2.3 • Collaboration with Microsoft • ImageSchema, reader, conversion functions to/from numpy arrays • Most of the tools we’ll describe work on ImageSchema columns images = spark.readImages(img_dir, recursive = True, sampleRatio = 0.1)
- 18. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply
- 19. Applying popular models • Popular pre-trained models accessible through MLlib Transformers predictor = DeepImagePredictor(inputCol="image", outputCol="predicted_labels", modelName="InceptionV3") predictions_df = predictor.transform(image_df)
- 20. Applying popular models predictor = DeepImagePredictor(inputCol="image", outputCol="predicted_labels", modelName="InceptionV3") predictions_df = predictor.transform(image_df)
- 21. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply Hyperparameter tuning Transfer learning s
- 22. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply Hyperparameter tuning Transfer learning
- 23. Transfer learning • Pre-trained models may not be directly applicable • New domain, e.g. shoes • Training from scratch requires • Enormous amounts of data • A lot of compute resources & time • Idea: intermediate representations learned for one task may be useful for other related tasks
- 24. Transfer Learning SoftMax GIANT PANDA 0.9 RACCOON 0.05 RED PANDA 0.01 …
- 28. MLlib Pipelines primer • MLlib: the machine learning library included with Spark • Transformer • Takes in a Spark dataframe • Returns a Spark dataframe with new column(s) containing “transformed” data • e.g. a Model is a Transformer • Estimator • A learning algorithm, e.g. lr = LogisticRegression() • Produces a Model via lr.fit() • Pipeline: a sequence of Transformers and Estimators
- 29. Transfer Learning as a Pipeline ClassifierDeepImageFeaturizer Rose / Daisy
- 30. Transfer Learning as a Pipeline DeepImageFeaturizer Image Loading Preprocessing Logistic Regression MLlib Pipeline
- 31. Transfer Learning as a Pipeline 31put your #assignedhashtag here by setting the featurizer = DeepImageFeaturizer(inputCol="image", outputCol="features", modelName="InceptionV3") lr = LogisticRegression(labelCol="label") p = Pipeline(stages=[featurizer, lr]) p_model = p.fit(train_df)
- 32. Transfer Learning • Usually for classification tasks • Similar task, new domain • But other forms of learning leveraging learned representations can be loosely considered transfer learning
- 34. Featurization for similarity-based ML DeepImageFeaturizer Image Loading Preprocessing Logistic Regression
- 35. Featurization for similarity-based ML DeepImageFeaturizer Image Loading Preprocessing Clustering KMeans GaussianMixture Nearest Neighbor KNN LSH Distance computation
- 36. Featurization for similarity-based ML DeepImageFeaturizer Image Loading Preprocessing Clustering KMeans GaussianMixture Nearest Neighbor KNN LSH Distance computation Duplicate Detection Recommendation Anomaly Detection Search result diversification
- 37. Keras 37 model = Sequential() model.add(Dense(32, input_dim=784)) model.add(Activation('relu')) • A popular, declarative interface to build DL models • High level, expressive API in python • Executes on TensorFlow, Theano, CNTK
- 38. model = Sequential() model.add(...) model.save(model_filename) estimator = KerasImageFileEstimator( kerasOptimizer=“adam“, kerasLoss=“categorical_crossentropy“, kerasFitParams={“batch_size“:100}, modelFile=model_filename) model = model.fit(dataframe) 38 Keras Estimator
- 39. 39 Keras Estimator in Model Selection estimator = KerasImageFileEstimator( kerasOptimizer=“adam“, kerasLoss=“categorical_crossentropy“) paramGrid = ( ParamGridBuilder() .addGrid(kerasFitParams=[{“batch_size“:100}, {“batch_size“:200}]) .addGrid(modelFile=[model1, model2]) ) cv = CrossValidator(estimator=estimator, estimatorParamMaps=paramGrid, evaluator=BinaryClassificationEvaluator(), numFolds=3) best_model = cv.fit(train_df)
- 40. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply
- 41. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply Spark SQL Batch prediction s
- 42. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply Spark SQL Batch prediction
- 43. Batch prediction as an MLlib Transformer • Recall a model is a Transformer in MLlib predictor = XXTransformer(inputCol="image", outputCol=”predictions", modelSpecification={…}) predictions = predictor.transform(test_df)
- 44. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply Spark SQL Batch prediction s
- 45. Shipping predictors in SQL Take a trained model / Pipeline, register a SQL UDF usable by anyone in the organization In Spark SQL: registerKerasUDF(”my_object_recognition_function", keras_model_file="/mymodels/007model.h5") select image, my_object_recognition_function(image) as objects from traffic_imgs This means you can apply deep learning models in streaming!
- 46. Deep Learning Pipelines : Future In progress • Scala API for DeepImageFeaturizer • Text featurization (embeddings) • TFTransformer for arbitrary vectors Future • Distributed training • Support for more backends, e.g. MXNet, PyTorch, BigDL
- 47. Deep Learning without Deep Pockets • Simple API for Deep Learning, integrated with MLlib • Scales common tasks with transformers and estimators • Embeds Deep Learning models in MLlib and SparkSQL • Check out https://github.com/databricks/spark-deep- learning !
- 48. Resources Blog posts & webinars (http://databricks.com/blog) • Deep Learning Pipelines • GPU acceleration in Databricks • BigDL on Databricks • Deep Learning and Apache Spark Docs for Deep Learning on Databricks (http://docs.databricks.com) • Getting started • Deep Learning Pipelines Example • Spark integration
- 49. 49 WWW.DATABRICKS.COM/SPARKAISUMMIT DATE: June 4-6, 2018 LOCATION: San Francisco - Moscone TRACKS: Artificial Intelligence, Spark Use Cases, Enterprise, Productionizing ML, Deep Learning, Hardware in the Cloud ATTENDEES: 4000+ Data Scientists, Data Engineers, Analysts, & VP/CxOs
- 51. Thank You! Questions? Happy Sparking & Deep Learning!