Build, Scale, and Deploy Deep Learning Pipelines with Ease Using Apache Spark
6 likes2,504 views

The document presents a talk on building, scaling, and deploying deep learning pipelines using Apache Spark, highlighting its advantages over traditional methods. It covers topics such as the workflow of deep learning, the integration of Spark with deep learning libraries, and examples of applying pre-trained models. The presentation emphasizes the simplicity and efficiency of Spark for deep learning tasks, along with future developments in this area.
1 of 39
Downloaded 49 times






































Ad
Recommended
Build, Scale, and Deploy Deep Learning Pipelines Using Apache Spark
Build, Scale, and Deploy Deep Learning Pipelines Using Apache SparkDatabricks The document discusses the development and deployment of deep learning pipelines using Apache Spark, highlighting the current state of deep learning and its challenges in industry. It emphasizes the use of Databricks' open-source library to simplify deep learning workflows, integrate with common model architectures, and leverage pre-trained models. It also outlines the typical deep learning workflow and future directions, including non-image data domains and enhanced model support.
Deep Learning on Apache® Spark™ : Workflows and Best Practices
Deep Learning on Apache® Spark™ : Workflows and Best PracticesJen Aman The document presents an overview of deep learning workflows and best practices using Apache Spark, highlighting its integration with various deep learning frameworks such as TensorFlow and Caffe. It discusses the architecture of Databricks, which simplifies data processing and machine learning for users, as well as monitoring techniques and solutions for managing distributed deep learning tasks. The presentation emphasizes the importance of experimentation and provides resources for further learning.
Build, Scale, and Deploy Deep Learning Pipelines with Ease
Build, Scale, and Deploy Deep Learning Pipelines with EaseDatabricks The document discusses the process of building, scaling, and deploying deep learning pipelines using Databricks and Apache Spark, emphasizing ease of integration and performance. It covers topics such as the definition of deep learning, successful applications, and a typical workflow, while highlighting the advantages of using Spark for distributed computation. Additionally, it provides insights into the development of deep learning models with transfer learning and model deployment in SQL.
Build, Scale, and Deploy Deep Learning Pipelines Using Apache Spark
Build, Scale, and Deploy Deep Learning Pipelines Using Apache SparkDatabricks The presentation by Tim Hunter at the Databricks Spark Meetup discusses deep learning at scale using Apache Spark, highlighting its potential and current limitations in industry adoption. It introduces Deep Learning Pipelines, an open-source library designed for ease of use and integration with Spark, catering primarily to Python users while aiming to simplify the deep learning workflow from data loading to model evaluation. Future developments include support for more backends and improved functionalities such as distributed training and text featurization.
Jump Start with Apache Spark 2.0 on Databricks
Jump Start with Apache Spark 2.0 on DatabricksAnyscale This document provides an agenda for a 3+ hour workshop on Apache Spark 2.x on Databricks. It includes introductions to Databricks, Spark fundamentals and architecture, new features in Spark 2.0 like unified APIs, and workshops on DataFrames/Datasets, Spark SQL, and structured streaming concepts. The agenda covers lunch and breaks and is divided into hour and half hour segments.
What's New in Apache Spark 2.3 & Why Should You Care
What's New in Apache Spark 2.3 & Why Should You CareDatabricks The document discusses the major features and enhancements in Apache Spark 2.3, including improvements in continuous processing, stream-stream joins, and PySpark performance. Key elements include the new structured streaming execution mode that offers low latency, support for various data formats, and integration with Kubernetes. The emphasis is placed on building robust streaming applications and the advantages of using Spark's unified analytics platform.
A Tale of Three Deep Learning Frameworks: TensorFlow, Keras, & Deep Learning ...
A Tale of Three Deep Learning Frameworks: TensorFlow, Keras, & Deep Learning ...Databricks The document discusses three deep learning frameworks: TensorFlow, Keras, and Deep Learning Pipelines, highlighting their unique features, advantages, and use cases. It emphasizes the challenges posed by big data to machine learning systems and the importance of frameworks like Apache Spark for data processing. Additionally, the content provides insights on transfer learning, ease of integration, and the potential for deploying deep learning applications.
Extending Apache Spark SQL Data Source APIs with Join Push Down with Ioana De...
Extending Apache Spark SQL Data Source APIs with Join Push Down with Ioana De...Databricks This document summarizes a presentation on extending Spark SQL Data Sources APIs with join push down. The presentation discusses how join push down can significantly improve query performance by reducing data transfer and exploiting data source capabilities like indexes. It provides examples of join push down in enterprise data pipelines and SQL acceleration use cases. The presentation also outlines the challenges of network speeds and exploiting data source capabilities, and how join push down addresses these challenges. Future work discussed includes building a cost model for global optimization across data sources.
Composable Parallel Processing in Apache Spark and Weld
Composable Parallel Processing in Apache Spark and WeldDatabricks The document discusses composable parallel processing in Apache Spark and introduces the Weld runtime, emphasizing the need for efficient composition of libraries in big data processing. It highlights Spark's goals to provide a unified engine and API for batch, interactive, and streaming applications, as well as the benefits of structured APIs in Spark 2.0 for performance and programmability. Additionally, it addresses challenges regarding data representation and the inefficiencies of traditional library composition, proposing new composition interfaces like Weld to optimize data movement and execution across various workloads.
Integrating Deep Learning Libraries with Apache Spark
Integrating Deep Learning Libraries with Apache SparkDatabricks The document discusses integrating deep learning libraries with Apache Spark, highlighting various frameworks such as TensorFlow, Keras, and MXNet that can be utilized within the Spark environment. It emphasizes the development of a deep learning pipeline API to streamline processes like featurization and model training, aiming for easier integration and scalability. The talk outlines challenges pertaining to communication patterns, flexible cluster deployments, and the importance of proper resource management in deep learning applications.
Spark Summit EU talk by Kent Buenaventura and Willaim Lau
Spark Summit EU talk by Kent Buenaventura and Willaim LauSpark Summit This document summarizes Unity Technologies' journey migrating their data pipeline from a legacy Hive-based system to using Spark. Some key points:
- They moved to Spark for its scaling, performance, and ability to handle both batch and streaming workloads from a single stack.
- The new Spark-based pipeline uses Airflow for workflow management and saves processed data to Parquet files stored in S3 for backup.
- Taking a test-driven development approach with unit and integration tests helped ensure a smooth migration. Staging the pipeline in an environment similar to production also helped address issues early.
- The new Spark pipeline completed analysis stages up to 2x faster than the previous Hive-based system and
A Tale of Three Tools: Kubernetes, Jsonnet, and Bazel
A Tale of Three Tools: Kubernetes, Jsonnet, and BazelDatabricks The document discusses the use of Kubernetes, Jsonnet, and Bazel at Databricks, highlighting the challenges of managing multiple Kubernetes clusters and deployments. It emphasizes the benefits of using Jsonnet to simplify configuration management and improve deployment processes, as well as Bazel for customizable builds. The presentation concludes with an invitation for potential hires to join the team.
Getting Ready to Use Redis with Apache Spark with Dvir Volk
Getting Ready to Use Redis with Apache Spark with Dvir VolkSpark Summit The document outlines a presentation on using Redis for real-time machine learning, focusing on Redis-ML integrated with Apache Spark. It covers the capabilities of Redis as a key-value store, the functionalities of Redis-ML for model serving, and a case study involving a recommendation system. The concluding remarks emphasize the advantages of combining Spark for training with Redis for efficient model serving, highlighting reduced resource costs and simplified machine learning lifecycle.
Spark r under the hood with Hossein Falaki
Spark r under the hood with Hossein FalakiDatabricks The document is a presentation by Hossein Falaki on debugging SparkR code, covering the architecture, implementation, limitations, and common errors associated with the SparkR API. It highlights the communication between R and Spark, including serialization and deserialization issues, as well as practical debugging tips for common problems encountered when using User Defined Functions (UDFs). The document also emphasizes utilizing Java stack traces for error resolution and provides guidance on avoiding typical pitfalls in SparkR coding.
Operational Tips For Deploying Apache Spark
Operational Tips For Deploying Apache SparkDatabricks Operational Tips for Deploying Apache Spark provides an overview of Apache Spark configuration, pipeline design best practices, and debugging techniques. It discusses how to configure Spark through command line options, programmatically, and Hadoop configs. It also covers topics like file formats, compression codecs, partitioning, and monitoring Spark jobs. The document provides tips on common issues like OutOfMemoryErrors, debugging SQL queries, and tuning shuffle partitions.
Large-Scale Data Science in Apache Spark 2.0
Large-Scale Data Science in Apache Spark 2.0Databricks This document discusses the enhancements in Apache Spark 2.0, focusing on its scalability for large-scale data science and AI through improved hardware and user scalability. It emphasizes the use of structured APIs for efficient data manipulation and introduces new features for deep learning and integration with existing Python and R libraries. The content highlights Spark's capabilities in parallelizing computations and the ease of building complex data science models with high-level APIs.
Apache Spark Usage in the Open Source Ecosystem
Apache Spark Usage in the Open Source EcosystemDatabricks The document discusses the usage statistics and library integration of Apache Spark among users of Databricks, highlighting user demographics and language preferences. Users have extensively adopted external libraries for ETL, visualization, and advanced analytics across Python, Scala, and R. The summary indicates a strong trend towards mixing languages and packages, showcasing the flexibility of Apache Spark in an open-source ecosystem.
Apache Spark MLlib's Past Trajectory and New Directions with Joseph Bradley
Apache Spark MLlib's Past Trajectory and New Directions with Joseph BradleyDatabricks - MLlib has rapidly developed over the past 5 years, growing from a few algorithms to over 50 algorithms and featurizers for classification, regression, clustering, recommendation, and more.
- This growth has shifted from just adding algorithms to improving algorithms, infrastructure, and integrating ML workflows with Spark's broader capabilities like SQL, DataFrames, and streaming.
- Going forward, areas of focus include continued scalability improvements, enhancing core algorithms, extensible APIs, and making MLlib a more comprehensive standard library.
Spark Summit 2016: Connecting Python to the Spark Ecosystem
Spark Summit 2016: Connecting Python to the Spark EcosystemDaniel Rodriguez This document discusses connecting Python to the Spark ecosystem. It covers the PyData and Spark ecosystems, package management for Python libraries in a cluster, leveraging Spark with tools like Sparkonda and Conda, and using Python with Spark including with NLTK, scikit-learn, TensorFlow, and Dask. Future directions include Apache Arrow for efficient data structures and leveraging alternative computing frameworks like TensorFlow.
Spark Summit EU talk by Tim Hunter
Spark Summit EU talk by Tim HunterSpark Summit This document summarizes Timothée Hunter's presentation on TensorFrames, which allows running Google TensorFlow models on Apache Spark. Some key points:
- TensorFrames embeds TensorFlow into Spark to enable distributed numerical computing on big data. This leverages GPUs to speed up computationally intensive machine learning algorithms.
- An example demonstrates speedups from using TensorFrames and GPUs for kernel density estimation, a non-parametric statistical technique.
- Future improvements include better integration with Tungsten in Spark for direct memory copying and columnar storage to reduce communication costs.
What's New in Upcoming Apache Spark 2.3
What's New in Upcoming Apache Spark 2.3Databricks Apache Spark 2.3 introduces several major features including continuous processing capabilities, enhancements to the data source API, improved PySpark performance, and robust machine learning operations over streaming data. It emphasizes the use of Databricks Delta for reliable data management and transactions, tackling issues of data corruption and complexity in data pipelines. The updates also include advanced SQL functionalities, support for Kubernetes, and improved stability for user-defined functions.
Apache Spark-Bench: Simulate, Test, Compare, Exercise, and Yes, Benchmark wit...
Apache Spark-Bench: Simulate, Test, Compare, Exercise, and Yes, Benchmark wit...Spark Summit The document presents an overview of spark-bench, a comprehensive benchmarking suite designed for the Spark data analytics platform, detailing its history, functionality, and how it facilitates performance testing using different data formats like CSV and Parquet. It highlights use cases for various user types, structural details of the project, and showcases examples of benchmarking tasks, including workload configurations and time management for performance comparisons. The content also includes insights into custom workloads and configurations to enhance benchmarking results.
From Pipelines to Refineries: scaling big data applications with Tim Hunter
From Pipelines to Refineries: scaling big data applications with Tim HunterDatabricks The document discusses the future challenges and foundations for scaling big data applications using Apache Spark, emphasizing the need for a robust theoretical framework. It outlines the current state of Spark, the potential complexities in data flows, and the importance of lazy evaluation and declarative APIs to manage those complexities. The presentation also highlights trends in data processing and proposals for enhancing Spark's capabilities, such as a more complete Python interface.
Simplifying Big Data Applications with Apache Spark 2.0
Simplifying Big Data Applications with Apache Spark 2.0Spark Summit Apache Spark 2.0 is a major new release that simplifies the Spark API and improves performance. Some key points:
1) It remains highly compatible with Spark 1.x while building on lessons learned to simplify the API with over 2000 patches from 280 contributors.
2) It introduces structured APIs like DataFrames that allow Spark to optimize queries via whole-stage code generation, providing up to 10x performance gains.
3) It launches a new higher-level streaming API called Structured Streaming that allows developers to write streaming jobs that behave like batch jobs and integrate easily with static data and batch jobs.
Dynamic DDL: Adding Structure to Streaming Data on the Fly with David Winters...
Dynamic DDL: Adding Structure to Streaming Data on the Fly with David Winters...Databricks The document outlines GoPro's transition from a file-based data pipeline architecture to a dynamic DDL architecture for real-time streaming data processing. Key aspects include handling diverse data formats, the implementation of a centralized Hive metastore, and the use of Amazon S3 for storage, highlighting the importance of dynamic DDL for rapid schema adaptation and efficient data ingestion. It also discusses challenges faced with the old system and improvements achieved with the new architecture, including reduced operational overhead and enhanced elasticity.
Resource-Efficient Deep Learning Model Selection on Apache Spark
Resource-Efficient Deep Learning Model Selection on Apache SparkDatabricks The document discusses resource-efficient deep learning model selection using Apache Spark, focusing on the challenges of training deep networks with various hyperparameters and architectures. It introduces Model Hopper Parallelism (MOP) as a method to improve efficiency through task parallelism and data parallelism while minimizing resource wastage. Additionally, it details the implementation of MOP on Spark, testing results, and comparisons with other tuning algorithms.
Extending the R API for Spark with sparklyr and Microsoft R Server with Ali Z...
Extending the R API for Spark with sparklyr and Microsoft R Server with Ali Z...Databricks The document outlines the integration of R with Microsoft R Server and Spark, highlighting key talks and features related to big data analytics and machine learning. It discusses R's growing popularity as a programming language, its ecosystem, and capabilities in handling data through parallel processing and remote compute contexts. Additionally, it covers specifics about Microsoft R functions, shared Spark sessions, and distributed machine learning frameworks available in the Microsoft R environment.
Building a Business Logic Translation Engine with Spark Streaming for Communi...
Building a Business Logic Translation Engine with Spark Streaming for Communi...Spark Summit Patrick Bamba presents on building a translation engine with Spark Streaming to enable communication between legacy code and microservices. The translation engine acts as an anti-corruption layer, translating data and requests between the different systems. Spark is well-suited for this purpose due to its streaming capabilities and built-in connectors for various data sources and sinks. The presentation provides an example implementation using structured streaming to interface legacy systems with microservices through sources, transformations, and sinks.
Deep-Dive into Deep Learning Pipelines with Sue Ann Hong and Tim Hunter
Deep-Dive into Deep Learning Pipelines with Sue Ann Hong and Tim HunterDatabricks This document discusses the use of Apache Spark for building, scaling, and deploying deep learning pipelines, emphasizing the integration of various libraries such as TensorFlow, Keras, and others. It outlines the typical workflow of deep learning, covers the benefits of using Spark for distributed training and efficient data handling, and highlights features of Databricks' deep learning pipelines which simplify the process without sacrificing performance. Additionally, it addresses future developments and current practices in the industry for enhancing deep learning accessibility.
Combining Machine Learning frameworks with Apache Spark
Combining Machine Learning frameworks with Apache SparkDataWorks Summit/Hadoop Summit This document discusses combining machine learning frameworks like TensorFlow with Apache Spark. It describes how Spark can be used to schedule and distribute machine learning tasks across a cluster in order to speed up model training. Specific examples are provided of using TensorFlow for neural network training on image data and distributing those computations using Spark. The document also outlines Apache Spark MLlib and its DataFrame-based APIs for building machine learning pipelines that can be trained and deployed at scale.
More Related Content
What's hot (20)
Composable Parallel Processing in Apache Spark and Weld
Composable Parallel Processing in Apache Spark and WeldDatabricks The document discusses composable parallel processing in Apache Spark and introduces the Weld runtime, emphasizing the need for efficient composition of libraries in big data processing. It highlights Spark's goals to provide a unified engine and API for batch, interactive, and streaming applications, as well as the benefits of structured APIs in Spark 2.0 for performance and programmability. Additionally, it addresses challenges regarding data representation and the inefficiencies of traditional library composition, proposing new composition interfaces like Weld to optimize data movement and execution across various workloads.
Integrating Deep Learning Libraries with Apache Spark
Integrating Deep Learning Libraries with Apache SparkDatabricks The document discusses integrating deep learning libraries with Apache Spark, highlighting various frameworks such as TensorFlow, Keras, and MXNet that can be utilized within the Spark environment. It emphasizes the development of a deep learning pipeline API to streamline processes like featurization and model training, aiming for easier integration and scalability. The talk outlines challenges pertaining to communication patterns, flexible cluster deployments, and the importance of proper resource management in deep learning applications.
Spark Summit EU talk by Kent Buenaventura and Willaim Lau
Spark Summit EU talk by Kent Buenaventura and Willaim LauSpark Summit This document summarizes Unity Technologies' journey migrating their data pipeline from a legacy Hive-based system to using Spark. Some key points:
- They moved to Spark for its scaling, performance, and ability to handle both batch and streaming workloads from a single stack.
- The new Spark-based pipeline uses Airflow for workflow management and saves processed data to Parquet files stored in S3 for backup.
- Taking a test-driven development approach with unit and integration tests helped ensure a smooth migration. Staging the pipeline in an environment similar to production also helped address issues early.
- The new Spark pipeline completed analysis stages up to 2x faster than the previous Hive-based system and
A Tale of Three Tools: Kubernetes, Jsonnet, and Bazel
A Tale of Three Tools: Kubernetes, Jsonnet, and BazelDatabricks The document discusses the use of Kubernetes, Jsonnet, and Bazel at Databricks, highlighting the challenges of managing multiple Kubernetes clusters and deployments. It emphasizes the benefits of using Jsonnet to simplify configuration management and improve deployment processes, as well as Bazel for customizable builds. The presentation concludes with an invitation for potential hires to join the team.
Getting Ready to Use Redis with Apache Spark with Dvir Volk
Getting Ready to Use Redis with Apache Spark with Dvir VolkSpark Summit The document outlines a presentation on using Redis for real-time machine learning, focusing on Redis-ML integrated with Apache Spark. It covers the capabilities of Redis as a key-value store, the functionalities of Redis-ML for model serving, and a case study involving a recommendation system. The concluding remarks emphasize the advantages of combining Spark for training with Redis for efficient model serving, highlighting reduced resource costs and simplified machine learning lifecycle.
Spark r under the hood with Hossein Falaki
Spark r under the hood with Hossein FalakiDatabricks The document is a presentation by Hossein Falaki on debugging SparkR code, covering the architecture, implementation, limitations, and common errors associated with the SparkR API. It highlights the communication between R and Spark, including serialization and deserialization issues, as well as practical debugging tips for common problems encountered when using User Defined Functions (UDFs). The document also emphasizes utilizing Java stack traces for error resolution and provides guidance on avoiding typical pitfalls in SparkR coding.
Operational Tips For Deploying Apache Spark
Operational Tips For Deploying Apache SparkDatabricks Operational Tips for Deploying Apache Spark provides an overview of Apache Spark configuration, pipeline design best practices, and debugging techniques. It discusses how to configure Spark through command line options, programmatically, and Hadoop configs. It also covers topics like file formats, compression codecs, partitioning, and monitoring Spark jobs. The document provides tips on common issues like OutOfMemoryErrors, debugging SQL queries, and tuning shuffle partitions.
Large-Scale Data Science in Apache Spark 2.0
Large-Scale Data Science in Apache Spark 2.0Databricks This document discusses the enhancements in Apache Spark 2.0, focusing on its scalability for large-scale data science and AI through improved hardware and user scalability. It emphasizes the use of structured APIs for efficient data manipulation and introduces new features for deep learning and integration with existing Python and R libraries. The content highlights Spark's capabilities in parallelizing computations and the ease of building complex data science models with high-level APIs.
Apache Spark Usage in the Open Source Ecosystem
Apache Spark Usage in the Open Source EcosystemDatabricks The document discusses the usage statistics and library integration of Apache Spark among users of Databricks, highlighting user demographics and language preferences. Users have extensively adopted external libraries for ETL, visualization, and advanced analytics across Python, Scala, and R. The summary indicates a strong trend towards mixing languages and packages, showcasing the flexibility of Apache Spark in an open-source ecosystem.
Apache Spark MLlib's Past Trajectory and New Directions with Joseph Bradley
Apache Spark MLlib's Past Trajectory and New Directions with Joseph BradleyDatabricks - MLlib has rapidly developed over the past 5 years, growing from a few algorithms to over 50 algorithms and featurizers for classification, regression, clustering, recommendation, and more.
- This growth has shifted from just adding algorithms to improving algorithms, infrastructure, and integrating ML workflows with Spark's broader capabilities like SQL, DataFrames, and streaming.
- Going forward, areas of focus include continued scalability improvements, enhancing core algorithms, extensible APIs, and making MLlib a more comprehensive standard library.
Spark Summit 2016: Connecting Python to the Spark Ecosystem
Spark Summit 2016: Connecting Python to the Spark EcosystemDaniel Rodriguez This document discusses connecting Python to the Spark ecosystem. It covers the PyData and Spark ecosystems, package management for Python libraries in a cluster, leveraging Spark with tools like Sparkonda and Conda, and using Python with Spark including with NLTK, scikit-learn, TensorFlow, and Dask. Future directions include Apache Arrow for efficient data structures and leveraging alternative computing frameworks like TensorFlow.
Spark Summit EU talk by Tim Hunter
Spark Summit EU talk by Tim HunterSpark Summit This document summarizes Timothée Hunter's presentation on TensorFrames, which allows running Google TensorFlow models on Apache Spark. Some key points:
- TensorFrames embeds TensorFlow into Spark to enable distributed numerical computing on big data. This leverages GPUs to speed up computationally intensive machine learning algorithms.
- An example demonstrates speedups from using TensorFrames and GPUs for kernel density estimation, a non-parametric statistical technique.
- Future improvements include better integration with Tungsten in Spark for direct memory copying and columnar storage to reduce communication costs.
What's New in Upcoming Apache Spark 2.3
What's New in Upcoming Apache Spark 2.3Databricks Apache Spark 2.3 introduces several major features including continuous processing capabilities, enhancements to the data source API, improved PySpark performance, and robust machine learning operations over streaming data. It emphasizes the use of Databricks Delta for reliable data management and transactions, tackling issues of data corruption and complexity in data pipelines. The updates also include advanced SQL functionalities, support for Kubernetes, and improved stability for user-defined functions.
Apache Spark-Bench: Simulate, Test, Compare, Exercise, and Yes, Benchmark wit...
Apache Spark-Bench: Simulate, Test, Compare, Exercise, and Yes, Benchmark wit...Spark Summit The document presents an overview of spark-bench, a comprehensive benchmarking suite designed for the Spark data analytics platform, detailing its history, functionality, and how it facilitates performance testing using different data formats like CSV and Parquet. It highlights use cases for various user types, structural details of the project, and showcases examples of benchmarking tasks, including workload configurations and time management for performance comparisons. The content also includes insights into custom workloads and configurations to enhance benchmarking results.
From Pipelines to Refineries: scaling big data applications with Tim Hunter
From Pipelines to Refineries: scaling big data applications with Tim HunterDatabricks The document discusses the future challenges and foundations for scaling big data applications using Apache Spark, emphasizing the need for a robust theoretical framework. It outlines the current state of Spark, the potential complexities in data flows, and the importance of lazy evaluation and declarative APIs to manage those complexities. The presentation also highlights trends in data processing and proposals for enhancing Spark's capabilities, such as a more complete Python interface.
Simplifying Big Data Applications with Apache Spark 2.0
Simplifying Big Data Applications with Apache Spark 2.0Spark Summit Apache Spark 2.0 is a major new release that simplifies the Spark API and improves performance. Some key points:
1) It remains highly compatible with Spark 1.x while building on lessons learned to simplify the API with over 2000 patches from 280 contributors.
2) It introduces structured APIs like DataFrames that allow Spark to optimize queries via whole-stage code generation, providing up to 10x performance gains.
3) It launches a new higher-level streaming API called Structured Streaming that allows developers to write streaming jobs that behave like batch jobs and integrate easily with static data and batch jobs.
Dynamic DDL: Adding Structure to Streaming Data on the Fly with David Winters...
Dynamic DDL: Adding Structure to Streaming Data on the Fly with David Winters...Databricks The document outlines GoPro's transition from a file-based data pipeline architecture to a dynamic DDL architecture for real-time streaming data processing. Key aspects include handling diverse data formats, the implementation of a centralized Hive metastore, and the use of Amazon S3 for storage, highlighting the importance of dynamic DDL for rapid schema adaptation and efficient data ingestion. It also discusses challenges faced with the old system and improvements achieved with the new architecture, including reduced operational overhead and enhanced elasticity.
Resource-Efficient Deep Learning Model Selection on Apache Spark
Resource-Efficient Deep Learning Model Selection on Apache SparkDatabricks The document discusses resource-efficient deep learning model selection using Apache Spark, focusing on the challenges of training deep networks with various hyperparameters and architectures. It introduces Model Hopper Parallelism (MOP) as a method to improve efficiency through task parallelism and data parallelism while minimizing resource wastage. Additionally, it details the implementation of MOP on Spark, testing results, and comparisons with other tuning algorithms.
Extending the R API for Spark with sparklyr and Microsoft R Server with Ali Z...
Extending the R API for Spark with sparklyr and Microsoft R Server with Ali Z...Databricks The document outlines the integration of R with Microsoft R Server and Spark, highlighting key talks and features related to big data analytics and machine learning. It discusses R's growing popularity as a programming language, its ecosystem, and capabilities in handling data through parallel processing and remote compute contexts. Additionally, it covers specifics about Microsoft R functions, shared Spark sessions, and distributed machine learning frameworks available in the Microsoft R environment.
Building a Business Logic Translation Engine with Spark Streaming for Communi...
Building a Business Logic Translation Engine with Spark Streaming for Communi...Spark Summit Patrick Bamba presents on building a translation engine with Spark Streaming to enable communication between legacy code and microservices. The translation engine acts as an anti-corruption layer, translating data and requests between the different systems. Spark is well-suited for this purpose due to its streaming capabilities and built-in connectors for various data sources and sinks. The presentation provides an example implementation using structured streaming to interface legacy systems with microservices through sources, transformations, and sinks.
Similar to Build, Scale, and Deploy Deep Learning Pipelines with Ease Using Apache Spark (20)
Deep-Dive into Deep Learning Pipelines with Sue Ann Hong and Tim Hunter
Deep-Dive into Deep Learning Pipelines with Sue Ann Hong and Tim HunterDatabricks This document discusses the use of Apache Spark for building, scaling, and deploying deep learning pipelines, emphasizing the integration of various libraries such as TensorFlow, Keras, and others. It outlines the typical workflow of deep learning, covers the benefits of using Spark for distributed training and efficient data handling, and highlights features of Databricks' deep learning pipelines which simplify the process without sacrificing performance. Additionally, it addresses future developments and current practices in the industry for enhancing deep learning accessibility.
Combining Machine Learning frameworks with Apache Spark
Combining Machine Learning frameworks with Apache SparkDataWorks Summit/Hadoop Summit This document discusses combining machine learning frameworks like TensorFlow with Apache Spark. It describes how Spark can be used to schedule and distribute machine learning tasks across a cluster in order to speed up model training. Specific examples are provided of using TensorFlow for neural network training on image data and distributing those computations using Spark. The document also outlines Apache Spark MLlib and its DataFrame-based APIs for building machine learning pipelines that can be trained and deployed at scale.
Combining Machine Learning Frameworks with Apache Spark
Combining Machine Learning Frameworks with Apache SparkDatabricks This document discusses combining machine learning frameworks with Apache Spark. It provides an overview of Apache Spark and MLlib, describes how to distribute TensorFlow computations using Spark, and discusses managing machine learning workflows with Spark through features like cross validation, persistence, and distributed data sources. The goal is to make machine learning easy, scalable, and integrate with existing workflows.
Deep learning with DL4J - Hadoop Summit 2015
Deep learning with DL4J - Hadoop Summit 2015Josh Patterson This document discusses deep learning and DL4J. It begins with an overview of deep learning, describing it as automated feature engineering through chained techniques like restricted Boltzmann machines. It then introduces DL4J, describing it as an enterprise-grade Java implementation of deep learning that supports parallelization on Hadoop, Spark, and GPUs. The rest of the document discusses building deep learning workflows with DL4J and related tools like Canova and Arbiter, providing an example of vectorizing and modeling iris data from a CSV file on the command line.
Deep learning and Apache Spark
Deep learning and Apache SparkQuantUniversity The document is a presentation about a QuantUniversity meetup on deep learning and Apache Spark, featuring Sri Krishnamurthy, who discusses various deep learning frameworks and their integration with Spark for efficient data processing. It highlights the use of technologies like TensorFlow, BigDL, and DeepLearning4J for distributed deep learning, showcasing benefits such as reduced training time and resource efficiency. Upcoming workshops and events related to deep learning are also announced, along with resources for further learning.
AI and Spark - IBM Community AI Day
AI and Spark - IBM Community AI DayNick Pentreath The document provides an overview of @mlnick, a principal engineer at IBM's CODAIT, focusing on making AI solutions easier for enterprises. It discusses machine learning, deep learning frameworks, and tools, as well as the evolution of these technologies, their applications, and integration with platforms like Apache Spark. Key frameworks mentioned include deeplearning4j, bigdl, and mmlspark, along with challenges in integration and data management.
Applied Deep Learning with Spark and Deeplearning4j
Applied Deep Learning with Spark and Deeplearning4jDataWorks Summit This document discusses deep learning and DL4J. It begins with an overview of deep learning, describing it as automated feature engineering through chained techniques like restricted Boltzmann machines. It then introduces DL4J, describing it as an enterprise-grade deep learning library for Java, Scala, and Python that supports parallelization on YARN and Spark as well as GPUs. The rest of the document discusses using DL4J with Spark for deep learning workflows on large datasets and provides an example of using the DL4J tool suite to perform vectorization, training, and evaluation on the Iris dataset.
Deep Learning on Apache® Spark™: Workflows and Best Practices
Deep Learning on Apache® Spark™: Workflows and Best PracticesDatabricks The document discusses deep learning integration with Apache Spark, emphasizing workflows and best practices. It highlights the various deep learning frameworks supported by Spark, including TensorFlow and Keras, and provides insights into data pipeline patterns, monitoring, and the use of GPUs. The talk aims to guide users in optimizing their deep learning applications within the Spark ecosystem.
Deep Learning on Apache® Spark™: Workflows and Best Practices
Deep Learning on Apache® Spark™: Workflows and Best PracticesJen Aman This document summarizes a presentation about deep learning workflows and best practices on Apache Spark. It discusses how deep learning fits within broader data pipelines for tasks like training and transformation. It also outlines recurring patterns for integrating Spark and deep learning frameworks, including using Spark for data parallelism and embedding deep learning transforms. The presentation provides tips for developers on topics like using GPUs with PySpark and monitoring deep learning jobs. It concludes by discussing challenges in the areas of distributed deep learning and Spark integration.
How to Build Deep Learning Models
How to Build Deep Learning ModelsJosh Patterson Josh Patterson's presentation at the Smart Data Conference 2015 outlines deep learning concepts, specifically focusing on the Deep Learning for Java (DL4J) framework. He discusses various deep learning architectures such as deep belief networks and CNNs, along with tools for data processing and training models, particularly emphasizing the importance of workflows and integration in machine learning. Patterson also highlights the suite of tools available within DL4J, including Canova for data vectorization and Arbiter for model evaluation.
Using SparkML to Power a DSaaS (Data Science as a Service): Spark Summit East...
Using SparkML to Power a DSaaS (Data Science as a Service): Spark Summit East...Spark Summit The document discusses Sparkle, a solution built by Comcast to address challenges in processing massive amounts of data and enabling data science workflows at scale. Sparkle is a centralized processing system with SQL and machine learning capabilities that is highly scalable and accessible via a REST API. It is used by Comcast to power various use cases including churn modeling, price elasticity analysis, and direct mail campaign optimization.
Fighting Fraud with Apache Spark
Fighting Fraud with Apache SparkMiklos Christine Miklos Christine is a solutions architect at Databricks who helps customers build big data platforms using Apache Spark. Databricks is the main contributor to the Apache Spark project. Spark is an open source engine for large-scale data processing that can be used for machine learning. Spark ML provides machine learning algorithms and pipelines to make machine learning scalable and easier to use at an enterprise level. Spark 2.0 includes improvements to Spark ML such as new algorithms and better support for Python.
Data Engineering Course Syllabus - WeCloudData
Data Engineering Course Syllabus - WeCloudDataWeCloudData This document provides information about the Programming for Data Engineers course offered by WeCloudData. The course teaches essential programming skills for data engineering such as Scala, Spark, Linux, and Docker over 10 sessions. Students will learn key topics like Scala programming, Spark fundamentals, and how to build data pipelines. They will also complete hands-on projects and get interview preparation support to help find jobs as a data engineer.
Apache Spark's MLlib's Past Trajectory and new Directions
Apache Spark's MLlib's Past Trajectory and new DirectionsDatabricks - MLlib has rapidly developed over the past 5 years, growing from a few initial algorithms to over 50 algorithms and featurizers today.
- It has shifted focus from just adding algorithms to improving existing algorithms and infrastructure like DataFrame integration.
- This allows for scalable machine learning workflows on big data from small laptop datasets to large clusters, with seamless integration between SQL, DataFrames, streaming, and other Spark components.
- Going forward, areas of focus include continued improvements to scalability, enhancing core algorithms, extending APIs to support custom algorithms, and building out a standard library of machine learning components.
Apache® Spark™ MLlib: From Quick Start to Scikit-Learn
Apache® Spark™ MLlib: From Quick Start to Scikit-LearnDatabricks The document provides an overview of Apache Spark's MLlib, highlighting its capabilities for machine learning at scale, emphasizing its design advantages like simplicity and scalability. It features insights from Joseph K. Bradley and Denny Lee, discussing the integration of MLlib with tools like scikit-learn, and the advantages of automating decision-making for large datasets. The document also includes examples and workflows for using MLlib effectively in data analysis scenarios.
Enterprise Deep Learning with DL4J
Enterprise Deep Learning with DL4JJosh Patterson Josh Patterson presented on deep learning and DL4J. He began with an overview of deep learning, explaining it as automated feature engineering where machines learn representations of the world. He then discussed DL4J, describing it as the "Hadoop of deep learning" - an open source deep learning library with Java, Scala, and Python APIs that supports parallelization on Hadoop, Spark, and GPUs. He demonstrated building deep learning workflows with DL4J and Canova, using the Iris dataset as an example to show how data can be vectorized with Canova and then a model trained on it using DL4J from the command line. He concluded by describing Skymind as a distribution of DL4J with enterprise
Build Deep Learning Applications for Big Data Platforms (CVPR 2018 tutorial)
Build Deep Learning Applications for Big Data Platforms (CVPR 2018 tutorial)Jason Dai This document outlines an agenda for a talk on building deep learning applications on big data platforms using Analytics Zoo. The agenda covers motivations around trends in big data, deep learning frameworks on Apache Spark like BigDL and TensorFlowOnSpark, an introduction to Analytics Zoo and its high-level pipeline APIs, built-in models, and reference use cases. It also covers distributed training in BigDL, advanced applications, and real-world use cases of deep learning on big data at companies like JD.com and World Bank. The talk concludes with a question and answer session.
A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and ...
A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and ...Jose Quesada (hiring) The document compares machine learning pipelines in scikit-learn and Scala-Spark, discussing the advantages of Spark for distributed machine learning workloads. It emphasizes Spark's capacity for real-time processing, ease of programming, and its unified DataFrame-based API in Spark 2.0, while also pointing out the potential challenges within Spark ML, such as feature indexing and the maximum depth limit for trees. Overall, it highlights Spark's evolution and its significant improvements over Hadoop in the context of machine learning.
Apache Spark MLlib
Apache Spark MLlib Zahra Eskandari This document provides an overview and agenda for a course on Spark MLlib. The course covers Spark fundamentals, SQL, streaming and MLlib. The MLlib section includes an overview of MLlib, a quick review of machine learning concepts, and why MLlib is useful. It describes the main concepts in MLlib like DataFrames, transformers, estimators and pipelines. It provides examples of classification using logistic regression on text data, regression to predict tweet impressions, and topic modeling on tweets. Finally, it lists some of the algorithms in MLlib, including classification, regression, clustering and tree ensemble methods.
Big Data Introduction - Solix empower
Big Data Introduction - Solix empowerDurga Gadiraju This document provides an overview of big data and the Spark framework. It discusses the big data ecosystem, including file systems, data ingestion tools, batch and real-time data processing frameworks, visualization tools, and support technologies. It outlines common big data job roles and their associated skills. The document then focuses on Spark, describing its core functionality, modules like DataFrames and MLlib, and execution modes. It provides guidance on learning Spark, emphasizing programming skills and Spark APIs. A demo of Spark fundamentals on a big data lab is also proposed.
A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and ...
A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and ...Jose Quesada (hiring)
Ad
More from Databricks (20)
DW Migration Webinar-March 2022.pptx
DW Migration Webinar-March 2022.pptxDatabricks The document discusses migrating a data warehouse to the Databricks Lakehouse Platform. It outlines why legacy data warehouses are struggling, how the Databricks Platform addresses these issues, and key considerations for modern analytics and data warehousing. The document then provides an overview of the migration methodology, approach, strategies, and key takeaways for moving to a lakehouse on Databricks.
Data Lakehouse Symposium | Day 1 | Part 1
Data Lakehouse Symposium | Day 1 | Part 1Databricks The document discusses the concept of a data lakehouse, highlighting the integration of structured, textual, and analog/IOT data. It emphasizes the importance of common identifiers and universal connectors for meaningful analytics across different data types, ultimately aiming to improve healthcare and manufacturing outcomes through effective data analysis. The presentation outlines the challenges of managing diverse data formats and the potential for data-driven insights to enhance quality of life.
Data Lakehouse Symposium | Day 1 | Part 2
Data Lakehouse Symposium | Day 1 | Part 2Databricks The document compares data lakehouses and data warehouses, outlining their similarities and differences. Both serve analytical processing and contain vetted, historical data, but the data lakehouse handles a much larger volume of machine-generated data and features fundamentally different structures from transaction-based data warehouses. Ultimately, they are presented as related yet distinct entities in the realm of data management.
Data Lakehouse Symposium | Day 2
Data Lakehouse Symposium | Day 2Databricks The Data Lakehouse Symposium held in February 2022 discussed the evolution of data management from data warehouses to lakehouses, emphasizing the integration of governance and metadata. It highlighted the challenges companies face in utilizing various types of data, particularly unstructured textual data, and the importance of adding context for effective analysis. The presentation also examined strategies for transforming unstructured data into structured formats to enable better decision-making and analytical processes.
Data Lakehouse Symposium | Day 4
Data Lakehouse Symposium | Day 4Databricks The document discusses the challenges of modern data, analytics, and AI workloads. Most enterprises struggle with siloed data systems that make integration and productivity difficult. The future of data lies with a data lakehouse platform that can unify data engineering, analytics, data warehousing, and machine learning workloads on a single open platform. The Databricks Lakehouse platform aims to address these challenges with its open data lake approach and capabilities for data engineering, SQL analytics, governance, and machine learning.
5 Critical Steps to Clean Your Data Swamp When Migrating Off of Hadoop
5 Critical Steps to Clean Your Data Swamp When Migrating Off of HadoopDatabricks The document outlines the challenges and considerations for migrating from Hadoop to Databricks, emphasizing the complexities of the Hadoop ecosystem and the advantages of a modern cloud-based data architecture. It provides a comprehensive migration plan that includes internal assessments, technical planning, and execution while addressing key topics such as data migration, security, and SQL integration. Specific tools and methodologies for effective transition and enhanced performance in data analytics are also discussed.
Democratizing Data Quality Through a Centralized Platform
Democratizing Data Quality Through a Centralized PlatformDatabricks Zillow's Data Governance Platform team addresses data quality challenges by creating a centralized platform that enhances visibility and standardizes data quality rules. The platform includes self-service capabilities and integrates with data lineage, allowing for built-in alerting and scalable onboarding. Key takeaways emphasize the importance of early alerting, collaboration, and the shared responsibility for maintaining high-quality data to improve decision-making.
Learn to Use Databricks for Data Science
Learn to Use Databricks for Data ScienceDatabricks The document outlines the challenges and workflows involved in data science, emphasizing the need for proper setup and resource management. It highlights the importance of sharing results with stakeholders and describes how Databricks' lakehouse platform simplifies these processes by integrating data sources and providing essential tools for data analysis. Overall, the goal is to help data scientists focus on their core analytical work rather than dealing with setup complexities.
Why APM Is Not the Same As ML Monitoring
Why APM Is Not the Same As ML MonitoringDatabricks The document discusses the distinctions between application performance monitoring (APM) and machine learning (ML) monitoring, emphasizing the unique challenges of ML monitoring, such as the need for intelligent detection and alerting. It outlines the essential components of ML monitoring, including statistical summarization, distribution comparison, and actionable alerts based on model performance. Additionally, it introduces Verta's end-to-end MLOps platform designed to meet the specialized needs of ML monitoring throughout the entire model lifecycle.
The Function, the Context, and the Data—Enabling ML Ops at Stitch Fix
The Function, the Context, and the Data—Enabling ML Ops at Stitch FixDatabricks Elijah Ben Izzy, a Data Platform Engineer at Stitch Fix, discusses building abstractions for machine learning operations to optimize workflows and enhance the separation of concerns between data science and platform engineering. The presentation highlights the importance of a custom-built model envelope for seamless integration and management of ML models, as well as advancements in deployment and inference processes. Future directions include enhanced production monitoring and sophisticated feature integration to further streamline data science workflows.
Stage Level Scheduling Improving Big Data and AI Integration
Stage Level Scheduling Improving Big Data and AI IntegrationDatabricks The document discusses stage-level scheduling and resource allocation in Apache Spark to enhance big data and AI integration. It outlines various resource requirements such as executors, memory, and accelerators, while presenting benefits like improved hardware utilization and simplified application pipelines. Additionally, it introduces the RAPIDS Accelerator for Spark and distributed deep learning with Horovod, emphasizing performance optimizations and future enhancements.
Simplify Data Conversion from Spark to TensorFlow and PyTorch
Simplify Data Conversion from Spark to TensorFlow and PyTorchDatabricks The document discusses the importance of data conversion between Spark and deep learning frameworks like TensorFlow and PyTorch. It highlights key pain points, such as challenges in migrating from single-node to distributed training and the complexity of saving and loading data. Additionally, it introduces the Spark Dataset Converter, which simplifies data handling while training deep learning models and offers best practices for efficient usage.
Scaling your Data Pipelines with Apache Spark on Kubernetes
Scaling your Data Pipelines with Apache Spark on KubernetesDatabricks This document discusses the integration of Apache Spark with Kubernetes on Google Cloud, highlighting its advantages for running data engineering and machine learning workloads within existing infrastructure. It outlines benefits such as improved cost optimization, faster scaling, and enhanced resource management through Google Kubernetes Engine (GKE) and Dataproc, while detailing implementation steps and monitoring options. Additionally, it covers the compatibility with big data ecosystem tools, job execution, and enterprise security features.
Scaling and Unifying SciKit Learn and Apache Spark Pipelines
Scaling and Unifying SciKit Learn and Apache Spark PipelinesDatabricks The document discusses the integration and scaling of AI/ML pipelines using Ray, aiming to unify Scikit-learn and Spark pipelines. Key features include Python functions as computation units, data exchange capabilities, and support for advanced execution strategies. It concludes with contact information for collaboration and emphasizes the importance of feedback from the community.
Sawtooth Windows for Feature Aggregations
Sawtooth Windows for Feature AggregationsDatabricks The document discusses the Sawtooth Windows Zipline, a feature engineering framework focusing on machine learning with structured data. It emphasizes the importance of real-time, stable, and consistent features for model training and serving, while highlighting the challenges of data sources and the intricacies of aggregations. Key topics include model complexity, data quality, and various types of windowed aggregations for efficient data processing.
Redis + Apache Spark = Swiss Army Knife Meets Kitchen Sink
Redis + Apache Spark = Swiss Army Knife Meets Kitchen SinkDatabricks The document discusses the integration of Redis with Apache Spark for managing long-running batch jobs and distributed counters. It outlines the challenges faced in submitting queries and the inefficiencies of existing solutions, proposing a system that utilizes Redis for queuing and job status communication. Key workflows and code views are provided to demonstrate the proposed solutions for efficient query handling and data processing.
Re-imagine Data Monitoring with whylogs and Spark
Re-imagine Data Monitoring with whylogs and SparkDatabricks The document discusses the challenges of monitoring machine learning data, emphasizing how traditional data analysis techniques fall short in addressing issues in ML data pipelines. It introduces the open-source library Whylogs for data logging, highlighting its lightweight profiling methods suitable for large datasets and integration with Apache Spark. Key topics include data quality problems, the need for scalable monitoring, and approaches for logging and analyzing ML data effectively.
Raven: End-to-end Optimization of ML Prediction Queries
Raven: End-to-end Optimization of ML Prediction QueriesDatabricks The document discusses Raven, an optimizer for machine learning prediction queries at Microsoft, focusing on its ability to improve the performance of SQL-based ML operations. It details how Raven integrates with Azure data engines, utilizing techniques like model projection pushdown and model-to-SQL translation to enhance query efficiency. Performance evaluations indicate that Raven significantly outperforms existing ML runtimes in various scenarios, achieving speed increases of up to 44 times compared to traditional approaches.
Processing Large Datasets for ADAS Applications using Apache Spark
Processing Large Datasets for ADAS Applications using Apache SparkDatabricks The document outlines the use of Spark for processing large datasets in automated driving applications, focusing on semantic segmentation and the challenges of moving from prototype to production. It presents the architecture of the system, covering ETL processes, model training, and inference, while addressing design considerations like scaling, security, and governance. Key takeaways emphasize the importance of leveraging cloud-based solutions and effective workflow management to enhance the development of perception software for autonomous vehicles.
Massive Data Processing in Adobe Using Delta Lake
Massive Data Processing in Adobe Using Delta LakeDatabricks The document discusses massive data processing at Adobe using Delta Lake, highlighting various aspects such as data representation, schema evolution, and challenges in data ingestion. It emphasizes the performance benefits of utilizing Delta Lake for handling large-scale data efficiently, while considering issues like schema management and replication lag. Key features like ACID transactions and lazy schema on-read approaches are also outlined to address the complexities of multi-tenant data architecture.
Ad
Recently uploaded (20)
About Certivo | Intelligent Compliance Solutions for Global Regulatory Needs
About Certivo | Intelligent Compliance Solutions for Global Regulatory Needscertivoai Certivo delivers intelligent compliance solutions designed to simplify and automate regulatory management for modern businesses in the USA, UK, and EU. Our AI-driven compliance platform helps enterprises navigate complex requirements with ease, offering real-time automated compliance monitoring and powerful product compliance software. At Certivo, we’re driven by a mission to transform how companies handle compliance, reducing risk and boosting operational efficiency. Discover our core values, vision, and innovation behind our trusted compliance management solutions. Whether you're in life sciences, automotive, or tech, Certivo helps you simplify regulatory compliance and scale faster with confidence.
Software Testing & it’s types (DevOps)
Software Testing & it’s types (DevOps)S Pranav (Deepu) NTRODUCTION TO SOFTWARE TESTING
• Definition:
• Software testing is the process of evaluating and
verifying that a software application or system meets
specified requirements and functions correctly.
• Purpose:
• Identify defects and bugs in the software.
• Ensure the software meets quality standards.
• Validate that the software performs as intended in
various scenarios.
• Importance:
• Reduces risks associated with software failures.
• Improves user satisfaction and trust in the product.
• Enhances the overall reliability and performance of
the software
Decipher SEO Solutions for your startup needs.
Decipher SEO Solutions for your startup needs.mathai2 A solution deck that gives you an idea of how you can use Decipher SEO to target keywords, build authority and generate high ranking content.
With features like images to product you can create a E-commerce pipeline that is optimized to help your store rank.
With integrations with shopify, woocommerce and wordpress theres a seamless way get your content to your website or storefront.
View more at decipherseo.com
Step by step guide to install Flutter and Dart
Step by step guide to install Flutter and DartS Pranav (Deepu) Flutter is basically Google’s portable user
interface (UI) toolkit, used to build and
develop eye-catching, natively-built
applications for mobile, desktop, and web,
from a single codebase. Flutter is free, open-
sourced, and compatible with existing code. It
is utilized by companies and developers
around the world, due to its user-friendly
interface and fairly simple, yet to-the-point
commands.
What is data visualization and how data visualization tool can help.pdf
What is data visualization and how data visualization tool can help.pdfVarsha Nayak An open source data visualization tool enhances this process by providing flexible, cost-effective solutions that allow users to customize and scale their visualizations according to their needs. These tools enable organizations to make data-driven decisions with complete freedom from proprietary software limitations. Whether you're a data scientist, marketer, or business leader, understanding how to utilize an open source data visualization tool can significantly improve your ability to communicate insights effectively.
wAIred_RabobankIgniteSession_12062025.pptx
wAIred_RabobankIgniteSession_12062025.pptxSimonedeGijt In today's world, artificial intelligence (AI) is transforming the way we learn.
This talk will explore how we can use AI tools to enhance our learning experiences, by looking at some (recent) research that has been done on the matter.
But as we embrace these new technologies, we must also ask ourselves:
Are we becoming less capable of thinking for ourselves?
Do these tools make us smarter, or do they risk dulling our critical thinking skills?
This talk will encourage us to think critically about the role of AI in our education. Together, we will discover how to use AI to support our learning journey while still developing our ability to think critically.
On-Device AI: Is It Time to Go All-In, or Do We Still Need the Cloud?
On-Device AI: Is It Time to Go All-In, or Do We Still Need the Cloud?Hassan Abid As mobile hardware becomes more powerful, the promise of running advanced AI directly on-device is closer than ever. With Google’s latest on-device model Gemini Nano, accessible through the new ML Kit GenAI APIs and AI Edge SDK, alongside the open-source Gemma-3n models, developers can now integrate lightweight, multimodal intelligence that works even without an internet connection. But does this mean we no longer need cloud-based AI? This session explores the practical trade-offs between on-device and cloud AI for mobile apps.
Shell Skill Tree - LabEx Certification (LabEx)
Shell Skill Tree - LabEx Certification (LabEx)VICTOR MAESTRE RAMIREZ Shell Skill Tree - LabEx Certification (LabEx)
Open Source Software Development Methods
Open Source Software Development MethodsVICTOR MAESTRE RAMIREZ Open Source Software Development Methods
Meet You in the Middle: 1000x Performance for Parquet Queries on PB-Scale Dat...
Meet You in the Middle: 1000x Performance for Parquet Queries on PB-Scale Dat...Alluxio, Inc. Alluxio Webinar
June 10, 2025
For more Alluxio Events: https://www.alluxio.io/events/
Speaker:
David Zhu (Engineering Manager @ Alluxio)
Storing data as Parquet files on cloud object storage, such as AWS S3, has become prevalent not only for large-scale data lakes but also as lightweight feature stores for training and inference, or as document stores for Retrieval-Augmented Generation (RAG). However, querying petabyte-to-exabyte-scale data lakes directly from S3 remains notoriously slow, with latencies typically ranging from hundreds of milliseconds to several seconds.
In this webinar, David Zhu, Software Engineering Manager at Alluxio, will present the results of a joint collaboration between Alluxio and a leading SaaS and data infrastructure enterprise that explored leveraging Alluxio as a high-performance caching and acceleration layer atop AWS S3 for ultra-fast querying of Parquet files at PB scale.
David will share:
- How Alluxio delivers sub-millisecond Time-to-First-Byte (TTFB) for Parquet queries, comparable to S3 Express One Zone, without requiring specialized hardware, data format changes, or data migration from your existing data lake.
- The architecture that enables Alluxio’s throughput to scale linearly with cluster size, achieving one million queries per second on a modest 50-node deployment, surpassing S3 Express single-account throughput by 50x without latency degradation.
- Specifics on how Alluxio offloads partial Parquet read operations and reduces overhead, enabling direct, ultra-low-latency point queries in hundreds of microseconds and achieving a 1,000x performance gain over traditional S3 querying methods.
Smadav Pro 2025 Rev 15.4 Crack Full Version With Registration Key
Smadav Pro 2025 Rev 15.4 Crack Full Version With Registration Keyjoybepari360 ➡️ 🌍📱👉COPY & PASTE LINK👉👉👉
https://crackpurely.site/smadav-pro-crack-full-version-registration-key/
Enable Your Cloud Journey With Microsoft Trusted Partner | IFI Tech
Enable Your Cloud Journey With Microsoft Trusted Partner | IFI TechIFI Techsolutions Start your cloud journey with IFI Tech—Microsoft’s trusted partner delivering secure, scalable Azure solutions tailored for your business.
Milwaukee Marketo User Group June 2025 - Optimize and Enhance Efficiency - Sm...
Milwaukee Marketo User Group June 2025 - Optimize and Enhance Efficiency - Sm...BradBedford3 Inspired by the Adobe Summit hands-on lab, Optimize Your Marketo Instance Performance, review the recording from June 5th to learn best practices that can optimize your smart campaign and smart list processing time, inefficient practices to try to avoid, and tips and tricks for keeping your instance running smooth!
You will learn:
How smart campaign queueing works, how flow steps are prioritized, and configurations that slow down smart campaign processing.
Best practices for smart list and smart campaign configurations that yield greater reliability and processing efficiencies.
Generally recommended timelines for reviewing instance performance: walk away from this session with a guideline of what to review in Marketo and how often to review it.
This session will be helpful for any Marketo administrator looking for opportunities to improve and streamline their instance performance. Be sure to watch to learn best practices and connect with your local Marketo peers!
Making significant Software Architecture decisions
Making significant Software Architecture decisionsBert Jan Schrijver Presented at the iSAQB Software Architecture Community NL meetup on 12-6-2025
Folding Cheat Sheet # 9 - List Unfolding 𝑢𝑛𝑓𝑜𝑙𝑑 as the Computational Dual of ...
Folding Cheat Sheet # 9 - List Unfolding 𝑢𝑛𝑓𝑜𝑙𝑑 as the Computational Dual of ...Philip Schwarz For most up-to-date version see https://fpilluminated.org/deck/264
In this deck we look at the following:
* How unfolding lists is the computational dual of folding lists
* Different variants of the function for unfolding lists
* How they relate to the iterate function
Artificial Intelligence Workloads and Data Center Management
Artificial Intelligence Workloads and Data Center ManagementSandeepKS52 Data centers play a crucial role in the modern digital landscape, serving as the backbone for data storage, processing, and management. Understanding the structure and function of these facilities is essential, as they house the technology that supports various applications and services. The use of Kubernetes and container orchestration has transformed how software is deployed and managed, allowing for greater efficiency and scalability in handling applications. Additionally, the management of AI workloads presents unique challenges and opportunities, as organizations seek to optimize resources and performance for complex algorithms and data processing tasks. Together, these topics provide a comprehensive overview of the technologies and strategies that drive today’s information systems.
Zoneranker’s Digital marketing solutions
Zoneranker’s Digital marketing solutionsreenashriee Zoneranker offers expert digital marketing services tailored for businesses in Theni. From SEO and PPC to social media and content marketing, we help you grow online. Partner with us to boost visibility, leads, and sales.
Porting Qt 5 QML Modules to Qt 6 Webinar
Porting Qt 5 QML Modules to Qt 6 WebinarICS Have you upgraded your application from Qt 5 to Qt 6? If so, your QML modules might still be stuck in the old Qt 5 style—technically compatible, but far from optimal. Qt 6 introduces a modernized approach to QML modules that offers better integration with CMake, enhanced maintainability, and significant productivity gains.
In this webinar, we’ll walk you through the benefits of adopting Qt 6 style QML modules and show you how to make the transition. You'll learn how to leverage the new module system to reduce boilerplate, simplify builds, and modernize your application architecture. Whether you're planning a full migration or just exploring what's new, this session will help you get the most out of your move to Qt 6.
Build, Scale, and Deploy Deep Learning Pipelines with Ease Using Apache Spark
- 1. Build, Scale, and Deploy Deep Learning Pipelines with Ease Using Apache Spark Tim Hunter (Software Engineer) Sue Ann Hong (Software Engineer) Spark Meetup - August 22nd, 2017
- 2. About Us • Sue Ann Hong • Software engineer @ Databricks • Ph.D. from CMU in Machine Learning • Tim Hunter • Software engineer @ Databricks • Ph.D. from UC Berkeley in Machine Learning • Very early Spark user
- 3. Today • Deep Learning at scale made easy: the vision • Processing images with DL Pipelines • Building simple Deep Learning models with transfer learning • Model deployment via SQL More advanced topics will be covered during the Q&A and other meetups.
- 4. Deep Learning with ease
- 5. What is Deep Learning? • A set of machine learning techniques that use layers that transform numerical inputs • Classification • Regression • Arbitrary mapping • Popular in the 80’s as Neural Networks • Recently came back thanks to advances in data collection, computation techniques, and hardware.
- 6. Success of Deep Learning • Tremendous success for applications with complex data • AlphaGo • Image interpretation • Automatictranslation • Speech recognition
- 7. But still requires a lot of effort • Low level APIs with steep learning curve • Tedious to distribute computations • Not well integrated with other enterprise tools • No exact science around deep learning • Success requires many engineer-hours
- 8. Deep Learning in industry • Currently limited adoption • Huge potential beyond the industrial giants • How do we accelerate the road to massive availability?
- 9. A typical Deep Learning workflow • Load data (images, text, time series, …) • Interactive work • Train • Select an architecture for a neural network • Optimize the weights of the NN • Evaluateresults, potentially re-train • Apply: • Pass the data through the NN to produce new features or output
- 10. How can Spark help? • A lot of libraries available for Deep Learning in Spark • TensorFlowOnSpark, BigDL, … • Goes from simple to very advanced • See our previous meetuptalks for more detail • Spark is great at scaling out computations • Distribute the transforms • Manage the trainingcomputation • Spark MLlib Pipelines • Simple, concise APIto capture the ML workflow
- 11. Deep Learning Pipelines: Deep Learning with Simplicity • Open-source Databricks library: https://github.com/databricks/spark-deep-learning • Focuses on easeof useand integration,without sacrificing performance • Scales out common tasks • Integrates with Spark APIs • Primary language: Python
- 12. Deep Learning Pipelines • Load data • Interactive work • Train • Evaluate model • Apply • Image loading in Spark • Deploying models in SQL • Transfer learning • Distributed tuning • Distributed prediction • Pre-trained models This talk: ✓ ✓ ✓ ✓
- 13. Image processing with DL Pipelines and Databricks
- 14. Adds support for images in Spark • ImageSchema, reader, conversion functions to/from numpy arrays • Most of the tools we’ll describe work on ImageSchema columns from sparkdl import readImages image_df = readImages(sample_img_dir)
- 15. Applying popular models • Popular pre-trained models accessible through MLlib Transformers predictor = DeepImagePredictor(inputCol="image", outputCol="predicted_labels", modelName="InceptionV3") predictions_df = predictor.transform(image_df)
- 16. Applying popular models predictor = DeepImagePredictor(inputCol="image", outputCol="predicted_labels", modelName="InceptionV3") predictions_df = predictor.transform(image_df)
- 17. Fast model training via transfer learning
- 18. Example: Identify the James Bond cars
- 19. DEMO
- 25. SoftMax GIANT PANDA 0.9 RED PANDA 0.05 RACCOON 0.01 … Classifier Transfer Learning DeepImageFeaturizer
- 26. MLlib primer • MLlib: the machine learning library included with Spark • Transformer • Transforms the data: takes a Spark dataframe and appends a new column • Estimator • Produces a model (fit) • Pipeline: sequence of transformers and estimators
- 27. Transfer Learning as a Pipeline MLlib Pipeline Image Loading Preprocessing Logistic Regression DeepImageFeaturizer
- 28. DEMO
- 29. Sharing and exporting Deep Learning models
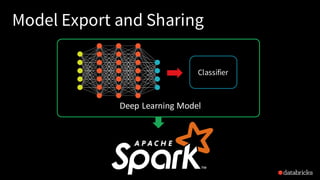
- 30. Classifier Deep Learning Model Model Export and Sharing
- 31. Shipping predictors in SQL Take a trained model / Pipeline, register a SQL UDF usable by anyone in the organization In Spark SQL: registerKerasUDF(”my_object_recognition_function", keras_model_file="/mymodels/007model.h5") select image, my_object_recognition_function(image) as objects from traffic_imgs
- 32. DEMO
- 33. Conclusion
- 34. Deep Learning without Deep Pockets • Simple API for Deep Learning, integrated with MLlib • Scales common tasks with transformers and estimators • Embeds Deep Learning models in MLlib and SparkSQL • Early release of Deep Learning Pipelines https://github.com/databricks/spark-deep-learning
- 35. Deep Learning Pipelines - future In progress • Hyper-parameter tuning for Keras models • Official image support in Spark • Scala API (Potential) future work • Text models • Support for more backends, e.g. MXNet, PyTorch, BigDL
- 36. Resources Blog posts & webinars — http://databricks.com/blog • Deep Learning Pipelines • GPU acceleration in Databricks • BigDL on Databricks • Deep Learning and Apache Spark Docs for Deep Learning on Databricks — http://docs.databricks.com • Getting started • Deep Learning Pipelines Example • Spark integration
- 39. Thank You! Questions? Happy Sparking & Deep Learning!