Classification Algorithm in Machine Learning
Download as PPTX, PDF0 likes3 views

Classification Algorithms
1 of 43
Download to read offline










































Ad
Recommended
Unit 4 Classification of data and more info on it
Unit 4 Classification of data and more info on itrandomguy1722 The document discusses classification in machine learning, distinguishing between supervised learning (where the model is trained on labeled data) and unsupervised learning (where no class labels are known). It describes various aspects of classification, including model construction, usage, and evaluation, focusing on algorithms like decision trees and metrics such as entropy, information gain, and the Gini index. The document emphasizes the importance of data preparation and the characteristics required for effective classification models.
dataminingclassificationprediction123 .pptx
dataminingclassificationprediction123 .pptxAsrithaKorupolu This document discusses classification and prediction techniques for data analysis. Classification predicts categorical labels, while prediction models continuous values. Common algorithms include decision tree induction and Naive Bayesian classification. Decision trees use measures like information gain to build classifiers by recursively partitioning training data. Naive Bayesian classifiers apply Bayes' theorem to estimate probabilities for classification. Both approaches are popular due to their accuracy, speed and interpretability.
Presentation on supervised learning
Presentation on supervised learningTonmoy Bhagawati This document discusses computational intelligence and supervised learning techniques for classification. It provides examples of applications in medical diagnosis and credit card approval. The goal of supervised learning is to learn from labeled training data to predict the class of new unlabeled examples. Decision trees and backpropagation neural networks are introduced as common supervised learning algorithms. Evaluation methods like holdout validation, cross-validation and performance metrics beyond accuracy are also summarized.
Lect8 Classification & prediction
Lect8 Classification & predictionhktripathy Classification and prediction models are used to categorize data or predict unknown values. Classification predicts categorical class labels to classify new data based on attributes in a training set, while prediction models continuous values. Common applications include credit approval, marketing, medical diagnosis, and treatment analysis. The classification process involves building a model from a training set and then using the model to classify new data, estimating accuracy on a test set.
Data mining chapter04and5-best
Data mining chapter04and5-bestABDUmomo The document discusses the differences and similarities between classification and prediction, providing examples of how classification predicts categorical class labels by constructing a model based on training data, while prediction models continuous values to predict unknown values, though the process is similar between the two. It also covers clustering analysis, explaining that it is an unsupervised technique that groups similar data objects into clusters to discover hidden patterns in datasets.
classification in Data Analysis Data Analysis.pptx
classification in Data Analysis Data Analysis.pptxssuser71aa7e Classification is the process of categorizing data into predefined classes based on features, primarily used in machine learning as a supervised learning technique. It includes binary classification, where data is classified into two categories, and multiclass classification for multiple categories, utilizing various algorithms such as linear and non-linear classifiers. The classification process involves training a model on labeled data to predict outcomes for unseen inputs based on learned patterns.
6 classification
6 classificationVishal Dutt This document discusses classification, which involves using a training dataset to build a model that can predict the class of new data. It provides an example classification dataset on weather conditions and whether an outdoor activity was held. The document explains that classification involves a two-step process of model construction using a training set, and then model usage to classify future test data and estimate the accuracy of the predictions. An example classification process is described where attributes of employees are used to build a model to predict whether someone is tenured based on their rank and years of experience.
introducatio to ml introducatio to ml introducatio to ml
introducatio to ml introducatio to ml introducatio to mlDecentMusicians This document provides an introduction to a machine learning course, detailing its objectives, learning outcomes, and evaluation criteria. It covers various machine learning algorithms, including supervised and unsupervised approaches, along with performance evaluation metrics and methodologies. The syllabus includes modules on topics such as regression, classification, clustering, dimensionality reduction, and ensemble models.
Lecture 09(introduction to machine learning)
Lecture 09(introduction to machine learning)Jeet Das Machine learning allows computers to learn without explicit programming by analyzing data to recognize patterns and make predictions. It can be supervised, learning from labeled examples to classify new data, or unsupervised, discovering hidden patterns in unlabeled data through clustering. Key aspects include feature representation, distance metrics to compare examples, and evaluation methods like measuring error on test data to avoid overfitting to the training data.
Lecture2.ppt
Lecture2.pptsriRam132674 This document provides an overview of data mining. It defines data mining as the extraction of interesting patterns from large datasets. The document outlines different types of data mining tasks such as classification, clustering, and association rule mining. It also discusses motivations for data mining from both commercial and scientific perspectives, and provides examples of data mining applications.
3 classification
3 classificationMahmoud Alfarra The document discusses the concept of classification in machine learning, defining it as a technique for predicting group membership for data instances and detailing its applications across various fields such as medical diagnosis and fraud detection. It explains the process of data classification, including building classifiers and evaluating their accuracy through training and test sets, while contrasting classification with prediction. Techniques such as decision trees and k-nearest neighbors are presented as common methods for implementing classification models.
evaluation and credibility-Part 2
evaluation and credibility-Part 2Tilani Gunawardena PhD(UNIBAS), BSc(Pera), FHEA(UK), CEng, MIESL This document discusses various methods for evaluating machine learning models, including:
- Using train, test, and validation sets to evaluate models on large datasets. Cross-validation is recommended for smaller datasets.
- Accuracy, error, precision, recall, and other metrics to quantify a model's performance using a confusion matrix.
- Lift charts and gains charts provide a visual comparison of a model's performance compared to no model. They are useful when costs are associated with different prediction outcomes.
Classification
Classificationthamizh arasi Classification is a popular data mining technique that assigns items to target categories or classes. It builds models called classifiers to predict the class of records with unknown class labels. Some common applications of classification include fraud detection, target marketing, and medical diagnosis. Classification involves a learning step where a model is constructed by analyzing a training set with class labels, and a classification step where the model predicts labels for new data. Supervised learning uses labeled data to train machine learning algorithms to produce correct outcomes for new examples.
Machine learning and types
Machine learning and typesPadma Metta The document provides an overview of machine learning, defining it as the field that enables computers to learn from data. It covers types of machine learning such as supervised, unsupervised, and reinforcement learning, along with examples and specific datasets like the Iris dataset. It also lists tools and resources for machine learning, emphasizing the importance of data preparation and algorithm selection.
AI_06_Machine Learning.pptx
AI_06_Machine Learning.pptxYousef Aburawi Machine learning was discussed including definitions, types, and examples. The three main types are supervised, unsupervised, and reinforcement learning. Supervised learning uses labeled training data to predict target variables for new data. Unsupervised learning identifies patterns in unlabeled data through clustering and association analysis. Reinforcement learning involves an agent learning through rewards and penalties as it interacts with an environment. Examples of machine learning applications were also provided.
Machine learning Method and techniques
Machine learning Method and techniquesMarkMojumdar The document outlines various machine learning methodologies including supervised, unsupervised, semi-supervised, and reinforcement learning, detailing their definitions, examples, and classifications. Supervised learning is emphasized, explaining its process, types (classification and regression), and algorithms used, while unsupervised learning focuses on clustering and anomaly detection. Additional machine learning concepts such as dimensionality reduction, ensemble methods, neural networks, deep learning, transfer learning, and natural language processing are also described.
Supervised Learning-Unit 3.pptx
Supervised Learning-Unit 3.pptxnehashanbhag5 The document discusses supervised learning and classification using the k-nearest neighbors (kNN) algorithm. It provides examples to illustrate how kNN works and discusses key aspects like:
- kNN classifies new data based on similarity to labelled training data
- Similarity is typically measured using Euclidean distance in feature space
- The value of k determines the number of nearest neighbors considered for classification
- Choosing k involves balancing noise from small values and bias from large values
- kNN is considered a lazy learner since it does not learn patterns from training data
Machine learning session 7
Machine learning session 7NirsandhG The document provides an introduction to classification in machine learning, explaining its purpose as a means of predicting categorical outcomes from data points. It outlines the differences between lazy and eager learners, alongside examples of each, and discusses how to build classifiers in Python using the scikit-learn library. Additionally, it highlights various classification algorithms and their applications, including speech recognition and biometric identification.
Supervised learning
Supervised learningJohnson Ubah The document discusses supervised learning as a subfield of machine learning, focusing on classification and regression problems, particularly in the context of loan funding prediction at Lending Club. It explains how classifiers can be used to predict binary outcomes, such as whether a loan will be fully funded based on input features. Performance metrics like accuracy and confusion matrices are also introduced for evaluating classifier effectiveness.
ai4.ppt
ai4.pptakshatsharma823122 This document discusses machine learning and various machine learning techniques. It begins by defining learning and different types of machine learning, including supervised learning, unsupervised learning, and reinforcement learning. It then focuses on supervised learning, discussing important concepts like training and test sets. Decision trees are presented as a popular supervised learning technique, including how they are constructed using a top-down recursive approach that chooses attributes to best split the data based on measures like information gain. Overfitting is also discussed as an issue to address with techniques like pruning.
ai4.ppt
ai4.pptssuser448ad3 The document discusses machine learning and various machine learning concepts. It defines learning as improving performance through experience. Machine learning involves using data to acquire models and learn hidden concepts. The main areas covered are supervised learning (data with labels), unsupervised learning (data without labels), semi-supervised learning (some labels present), and reinforcement learning (agent takes actions and receives rewards/punishments). Decision trees are presented as a way to represent hypotheses learned through examples, with attributes used to recursively split data into partitions.
Big Data Analytics - Unit 3.pptx
Big Data Analytics - Unit 3.pptxPlacementsBCA This document provides information on clustering techniques in data mining. It discusses different types of clustering methods such as partitioning, density-based, centroid-based, hierarchical, grid-based, and model-based. It also covers hierarchical agglomerative and divisive approaches. The document notes that clustering groups similar objects without supervision to establish classes or clusters in unlabeled data. Applications mentioned include market segmentation, document classification, and outlier detection.
04-Machine-Learning-Overview pros and cons
04-Machine-Learning-Overview pros and consabzalbekulasbekov The document provides an overview of machine learning, explaining its definition, applications, and processes including supervised and unsupervised learning. It discusses various concepts such as overfitting, underfitting, model evaluation using metrics like accuracy, precision, recall, and the f1-score, as well as regression evaluation metrics. Additionally, unsupervised learning techniques such as clustering and anomaly detection are briefly mentioned.
Machine-Learning-Overview a statistical approach
Machine-Learning-Overview a statistical approachAjit Ghodke This document provides an overview of machine learning concepts including what machine learning is, common machine learning tasks like fraud detection and recommendation engines, and different machine learning techniques like supervised and unsupervised learning. It discusses neural networks and deep learning, and explains the machine learning process from data acquisition to model deployment. It also covers important concepts for evaluating machine learning models like overfitting, accuracy, recall, precision, F1 score, confusion matrices, and regression metrics like mean absolute error, mean squared error and root mean squared error.
in5490-classification (1).pptx
in5490-classification (1).pptxMonicaTimber This document provides an overview of machine learning techniques for classification with imbalanced data. It discusses challenges with imbalanced datasets like most classifiers being biased towards the majority class. It then summarizes techniques for dealing with imbalanced data, including random over/under sampling, SMOTE, cost-sensitive classification, and collecting more data. [/SUMMARY]
ai4.ppt
ai4.pptatul404633 The document discusses machine learning and various machine learning techniques. It defines machine learning as using data and experience to acquire models and modify decision mechanisms to improve performance. The document outlines different types of machine learning including supervised learning (using labeled data), unsupervised learning (using only unlabeled data), and reinforcement learning (where an agent takes actions and receives rewards or punishments). It provides examples of classification problems and discusses decision tree learning as a supervised learning method, including how decision trees are constructed and potential issues like overfitting.
Machine learning and decision trees
Machine learning and decision treesPadma Metta The document provides an overview of machine learning, defining it as the ability for computers to learn from data without explicit programming. It discusses various types of machine learning, including supervised, unsupervised, and reinforcement learning, along with examples and the importance of decision trees in classification tasks. The document also outlines how to prepare datasets, types of algorithms, and details the decision tree mechanism, including concepts of entropy and information gain to optimize classification results.
Lecture 3 ml
Lecture 3 mlKalpesh Doru This document provides an overview of machine learning concepts including:
1. The three main types of machine learning are supervised learning, unsupervised learning, and reinforcement learning. Supervised learning uses labeled training data to build predictive models for classification and regression tasks.
2. Classification predicts categorical labels while regression predicts continuous valued outputs. Examples of each are predicting tumor malignancy (classification) and real estate prices (regression).
3. Supervised learning algorithms like Naive Bayes, decision trees, and k-nearest neighbors are used to build classification models from labeled training data to classify new examples.
Logical Design Architecture in Internet of Things
Logical Design Architecture in Internet of ThingsSenthil Vit It discusses about Logical design in Internet of Things
More Related Content
Similar to Classification Algorithm in Machine Learning (20)
Lecture 09(introduction to machine learning)
Lecture 09(introduction to machine learning)Jeet Das Machine learning allows computers to learn without explicit programming by analyzing data to recognize patterns and make predictions. It can be supervised, learning from labeled examples to classify new data, or unsupervised, discovering hidden patterns in unlabeled data through clustering. Key aspects include feature representation, distance metrics to compare examples, and evaluation methods like measuring error on test data to avoid overfitting to the training data.
Lecture2.ppt
Lecture2.pptsriRam132674 This document provides an overview of data mining. It defines data mining as the extraction of interesting patterns from large datasets. The document outlines different types of data mining tasks such as classification, clustering, and association rule mining. It also discusses motivations for data mining from both commercial and scientific perspectives, and provides examples of data mining applications.
3 classification
3 classificationMahmoud Alfarra The document discusses the concept of classification in machine learning, defining it as a technique for predicting group membership for data instances and detailing its applications across various fields such as medical diagnosis and fraud detection. It explains the process of data classification, including building classifiers and evaluating their accuracy through training and test sets, while contrasting classification with prediction. Techniques such as decision trees and k-nearest neighbors are presented as common methods for implementing classification models.
evaluation and credibility-Part 2
evaluation and credibility-Part 2Tilani Gunawardena PhD(UNIBAS), BSc(Pera), FHEA(UK), CEng, MIESL This document discusses various methods for evaluating machine learning models, including:
- Using train, test, and validation sets to evaluate models on large datasets. Cross-validation is recommended for smaller datasets.
- Accuracy, error, precision, recall, and other metrics to quantify a model's performance using a confusion matrix.
- Lift charts and gains charts provide a visual comparison of a model's performance compared to no model. They are useful when costs are associated with different prediction outcomes.
Classification
Classificationthamizh arasi Classification is a popular data mining technique that assigns items to target categories or classes. It builds models called classifiers to predict the class of records with unknown class labels. Some common applications of classification include fraud detection, target marketing, and medical diagnosis. Classification involves a learning step where a model is constructed by analyzing a training set with class labels, and a classification step where the model predicts labels for new data. Supervised learning uses labeled data to train machine learning algorithms to produce correct outcomes for new examples.
Machine learning and types
Machine learning and typesPadma Metta The document provides an overview of machine learning, defining it as the field that enables computers to learn from data. It covers types of machine learning such as supervised, unsupervised, and reinforcement learning, along with examples and specific datasets like the Iris dataset. It also lists tools and resources for machine learning, emphasizing the importance of data preparation and algorithm selection.
AI_06_Machine Learning.pptx
AI_06_Machine Learning.pptxYousef Aburawi Machine learning was discussed including definitions, types, and examples. The three main types are supervised, unsupervised, and reinforcement learning. Supervised learning uses labeled training data to predict target variables for new data. Unsupervised learning identifies patterns in unlabeled data through clustering and association analysis. Reinforcement learning involves an agent learning through rewards and penalties as it interacts with an environment. Examples of machine learning applications were also provided.
Machine learning Method and techniques
Machine learning Method and techniquesMarkMojumdar The document outlines various machine learning methodologies including supervised, unsupervised, semi-supervised, and reinforcement learning, detailing their definitions, examples, and classifications. Supervised learning is emphasized, explaining its process, types (classification and regression), and algorithms used, while unsupervised learning focuses on clustering and anomaly detection. Additional machine learning concepts such as dimensionality reduction, ensemble methods, neural networks, deep learning, transfer learning, and natural language processing are also described.
Supervised Learning-Unit 3.pptx
Supervised Learning-Unit 3.pptxnehashanbhag5 The document discusses supervised learning and classification using the k-nearest neighbors (kNN) algorithm. It provides examples to illustrate how kNN works and discusses key aspects like:
- kNN classifies new data based on similarity to labelled training data
- Similarity is typically measured using Euclidean distance in feature space
- The value of k determines the number of nearest neighbors considered for classification
- Choosing k involves balancing noise from small values and bias from large values
- kNN is considered a lazy learner since it does not learn patterns from training data
Machine learning session 7
Machine learning session 7NirsandhG The document provides an introduction to classification in machine learning, explaining its purpose as a means of predicting categorical outcomes from data points. It outlines the differences between lazy and eager learners, alongside examples of each, and discusses how to build classifiers in Python using the scikit-learn library. Additionally, it highlights various classification algorithms and their applications, including speech recognition and biometric identification.
Supervised learning
Supervised learningJohnson Ubah The document discusses supervised learning as a subfield of machine learning, focusing on classification and regression problems, particularly in the context of loan funding prediction at Lending Club. It explains how classifiers can be used to predict binary outcomes, such as whether a loan will be fully funded based on input features. Performance metrics like accuracy and confusion matrices are also introduced for evaluating classifier effectiveness.
ai4.ppt
ai4.pptakshatsharma823122 This document discusses machine learning and various machine learning techniques. It begins by defining learning and different types of machine learning, including supervised learning, unsupervised learning, and reinforcement learning. It then focuses on supervised learning, discussing important concepts like training and test sets. Decision trees are presented as a popular supervised learning technique, including how they are constructed using a top-down recursive approach that chooses attributes to best split the data based on measures like information gain. Overfitting is also discussed as an issue to address with techniques like pruning.
ai4.ppt
ai4.pptssuser448ad3 The document discusses machine learning and various machine learning concepts. It defines learning as improving performance through experience. Machine learning involves using data to acquire models and learn hidden concepts. The main areas covered are supervised learning (data with labels), unsupervised learning (data without labels), semi-supervised learning (some labels present), and reinforcement learning (agent takes actions and receives rewards/punishments). Decision trees are presented as a way to represent hypotheses learned through examples, with attributes used to recursively split data into partitions.
Big Data Analytics - Unit 3.pptx
Big Data Analytics - Unit 3.pptxPlacementsBCA This document provides information on clustering techniques in data mining. It discusses different types of clustering methods such as partitioning, density-based, centroid-based, hierarchical, grid-based, and model-based. It also covers hierarchical agglomerative and divisive approaches. The document notes that clustering groups similar objects without supervision to establish classes or clusters in unlabeled data. Applications mentioned include market segmentation, document classification, and outlier detection.
04-Machine-Learning-Overview pros and cons
04-Machine-Learning-Overview pros and consabzalbekulasbekov The document provides an overview of machine learning, explaining its definition, applications, and processes including supervised and unsupervised learning. It discusses various concepts such as overfitting, underfitting, model evaluation using metrics like accuracy, precision, recall, and the f1-score, as well as regression evaluation metrics. Additionally, unsupervised learning techniques such as clustering and anomaly detection are briefly mentioned.
Machine-Learning-Overview a statistical approach
Machine-Learning-Overview a statistical approachAjit Ghodke This document provides an overview of machine learning concepts including what machine learning is, common machine learning tasks like fraud detection and recommendation engines, and different machine learning techniques like supervised and unsupervised learning. It discusses neural networks and deep learning, and explains the machine learning process from data acquisition to model deployment. It also covers important concepts for evaluating machine learning models like overfitting, accuracy, recall, precision, F1 score, confusion matrices, and regression metrics like mean absolute error, mean squared error and root mean squared error.
in5490-classification (1).pptx
in5490-classification (1).pptxMonicaTimber This document provides an overview of machine learning techniques for classification with imbalanced data. It discusses challenges with imbalanced datasets like most classifiers being biased towards the majority class. It then summarizes techniques for dealing with imbalanced data, including random over/under sampling, SMOTE, cost-sensitive classification, and collecting more data. [/SUMMARY]
ai4.ppt
ai4.pptatul404633 The document discusses machine learning and various machine learning techniques. It defines machine learning as using data and experience to acquire models and modify decision mechanisms to improve performance. The document outlines different types of machine learning including supervised learning (using labeled data), unsupervised learning (using only unlabeled data), and reinforcement learning (where an agent takes actions and receives rewards or punishments). It provides examples of classification problems and discusses decision tree learning as a supervised learning method, including how decision trees are constructed and potential issues like overfitting.
Machine learning and decision trees
Machine learning and decision treesPadma Metta The document provides an overview of machine learning, defining it as the ability for computers to learn from data without explicit programming. It discusses various types of machine learning, including supervised, unsupervised, and reinforcement learning, along with examples and the importance of decision trees in classification tasks. The document also outlines how to prepare datasets, types of algorithms, and details the decision tree mechanism, including concepts of entropy and information gain to optimize classification results.
Lecture 3 ml
Lecture 3 mlKalpesh Doru This document provides an overview of machine learning concepts including:
1. The three main types of machine learning are supervised learning, unsupervised learning, and reinforcement learning. Supervised learning uses labeled training data to build predictive models for classification and regression tasks.
2. Classification predicts categorical labels while regression predicts continuous valued outputs. Examples of each are predicting tumor malignancy (classification) and real estate prices (regression).
3. Supervised learning algorithms like Naive Bayes, decision trees, and k-nearest neighbors are used to build classification models from labeled training data to classify new examples.
More from Senthil Vit (20)
Logical Design Architecture in Internet of Things
Logical Design Architecture in Internet of ThingsSenthil Vit It discusses about Logical design in Internet of Things
Operating system Virtualization_NEW.pptx
Operating system Virtualization_NEW.pptxSenthil Vit The document provides a comprehensive overview of virtualization, defining it as the division of computer resources into multiple execution environments to enhance resource utilization. It explores the history of virtualization, the challenges associated with x86 architecture, various types of virtual machines, and key techniques in CPU and memory virtualization. The document also discusses hypervisors, emphasizing their role in enabling virtual machines to operate on physical hardware, and compares different virtualization technologies and their implications.
Synchronization Peterson’s Solution.pptx
Synchronization Peterson’s Solution.pptxSenthil Vit The document discusses the critical section problem in concurrent processes, highlighting essential requirements such as mutual exclusion, progress, and bounded waiting. It outlines various algorithms, including Peterson's algorithm, for managing access to shared resources while preventing deadlock and starvation. Additionally, it explores hardware solutions for synchronization, including interrupt disabling and atomic instructions like test-and-set and swap.
Control structures in Python programming
Control structures in Python programmingSenthil Vit Chapter 3 discusses control structures in programming, focusing on sequential, selection, and iterative control that manage the execution order of instructions in Python. It explains the significance of boolean expressions and various operators used for decision-making within programming, particularly the if statement and its associated syntax. The chapter emphasizes the importance of operator precedence and proper indentation in Python, highlighting how these elements impact the flow and logic of a program.
Data and Expressions in Python programming
Data and Expressions in Python programmingSenthil Vit Chapter 2 discusses data representation, manipulation, and input/output in computer programming using Python. It covers numeric and string literals, floating-point representation, potential arithmetic overflow and underflow issues, and the use of escape sequences in strings. The chapter also emphasizes the importance of understanding data types and representation for effective programming.
Python programming Introduction about Python
Python programming Introduction about PythonSenthil Vit Chapter 1 introduces computer science as the study of computational problem solving, emphasizing the importance of algorithms and the roles of computer hardware and software. It discusses the essence of abstraction in problem representation, illustrated with examples like the man, cabbage, goat, and wolf problem. The chapter concludes with the significance of algorithmic efficiency, particularly in complex problems like the traveling salesman problem.
Switching Problems.pdf
Switching Problems.pdfSenthil Vit The document discusses packet transmission delays for various network configurations involving satellite links and terrestrial links. It provides calculations for propagation delays, transmission delays, and total delays for sending packets of data between nodes separated by different distances over links of varying bandwidths. Examples analyze delays when transmitting messages, photos, and voice data between servers and over multi-hop networks. Calculations are shown for determining the minimum packet size needed to maintain continuous transmission over a satellite link.
Big Oh.ppt
Big Oh.pptSenthil Vit The document discusses algorithm analysis and computational complexity, specifically focusing on time complexity and big O notation. It defines key concepts like best case, average case, and worst case scenarios. Common time complexities like constant, logarithmic, linear, quadratic, and exponential functions are examined. Examples are provided to demonstrate how to calculate the time complexity of different algorithms using big O notation. The document emphasizes that worst case analysis is most useful for program design and comparing algorithms.
AsymptoticNotations.ppt
AsymptoticNotations.pptSenthil Vit This document discusses asymptotic notations and complexity classes that are used to analyze the time efficiency of algorithms. It introduces the notations of big-O, big-Omega, and big-Theta, and defines them formally using limits and inequalities. Examples are provided to demonstrate how to establish the rate of growth of functions and determine which complexity classes they belong to. Special cases involving factorial and trigonometric functions are also addressed. Properties of asymptotic notations like transitivity are covered. Exercises are presented at the end to allow students to practice determining complexity classes.
snort.ppt
snort.pptSenthil Vit Snort is an open source network intrusion prevention system capable of real-time traffic analysis and packet logging. It uses a rules-based detection engine to examine packets against defined signatures. Snort has three main operational modes: sniffer, packet logger, and network intrusion detection system. It utilizes a modular architecture with plug-ins for preprocessing, detection, and output. Rules provide flexible and configurable detection signatures.
First Best and Worst Fit.pptx
First Best and Worst Fit.pptxSenthil Vit This document discusses three algorithms for allocating memory to processes: first fit, best fit, and worst fit. First fit allocates the first block of memory large enough for the process. Best fit allocates the smallest block large enough. Worst fit allocates the largest block large enough. The document provides examples of how each algorithm would allocate memory to processes of different sizes and evaluates which algorithm makes the most efficient use of memory.
File Implementation Problem.pptx
File Implementation Problem.pptxSenthil Vit For a file consisting of 100 blocks, the number of disk I/O operations required for different allocation strategies when adding or removing a single block are:
1) Adding a block to the beginning requires 1 I/O for linked and indexed allocation, but 201 I/Os for contiguous allocation as each existing block must be shifted.
2) Adding to the middle requires 1 I/O for indexed allocation, 52 I/Os for linked to read blocks to the middle, and 101 I/Os for contiguous to shift subsequent blocks.
3) Removing from any position requires no I/Os for indexed allocation but linked and contiguous methods may require reading and writing blocks depending on the position.
Design Issues of an OS.ppt
Design Issues of an OS.pptSenthil Vit The document discusses several key design issues for operating systems including efficiency, robustness, flexibility, portability, security, and compatibility. It then focuses on robustness, explaining that robust systems can operate for prolonged periods without crashing or requiring reboots. The document also discusses failure detection and reconfiguration techniques for distributed systems, such as using heartbeat messages to check connectivity and notifying all sites when failures occur or links are restored.
Operating Systems – Structuring Methods.pptx
Operating Systems – Structuring Methods.pptxSenthil Vit This document discusses different methods for structuring operating systems, including monolithic, layered, and microkernel approaches. It provides examples of each type, such as MS-DOS as a monolithic OS and Windows NT 4.0 and XP as layered OSes. The document also outlines the key characteristics of microkernel systems, including moving most functionality out of the kernel into user space and using inter-process communication. Benefits of the microkernel approach include extensibility, reliability, portability, and support for distributed and object-oriented systems.
deadlock.ppt
deadlock.pptSenthil Vit 1) Deadlock occurs when a set of processes are blocked waiting for resources held by each other in a circular chain.
2) Four necessary conditions for deadlock are: mutual exclusion, hold and wait, no preemption, and circular wait.
3) Strategies to handle deadlock include prevention, avoidance, and detection/recovery. Prevention negates one of the necessary conditions like making resources sharable.
Virtualization.pptx
Virtualization.pptxSenthil Vit Virtualization allows for the creation of virtual machines that emulate dedicated hardware. A hypervisor software allows multiple virtual machines to run isolated operating systems like Linux and Windows on the same physical host. This improves hardware utilization and lowers costs by reducing physical servers and maintenance. There are two main types of virtual machines - process virtual machines that virtualize individual processes, and system virtual machines that provide a full virtualized environment including OS and processes. Virtualization provides benefits like better hardware usage, isolation, manageability and lower costs.
Traffic-Monitoring.ppt
Traffic-Monitoring.pptSenthil Vit This document provides an overview of using Wireshark and tcpdump to monitor network traffic. It begins with an introduction to the motivation for network monitoring. It then covers the tools tcpdump, tshark, and Wireshark. Examples are given of using tcpdump and tshark on the command line to capture traffic. The document demonstrates Wireshark's graphical user interface and features like capture filters, display filters, following TCP streams, endpoint statistics, and flow graphs. It concludes with tips for improving Wireshark performance and using grep to analyze saved packet files.
Lect_2.pptx
Lect_2.pptxSenthil Vit The document provides information on various information security devices. It discusses identity and access management (IdAM), which manages users' digital identities and privileges. It also covers networks devices like hubs, switches, routers, bridges, and gateways that connect computers. Infrastructure devices discussed include firewalls, which filter network traffic, and wireless access points, which broadcast wireless signals. The document provides diagrams and explanations of how each device works.
Ad
Recently uploaded (20)
Rigor, ethics, wellbeing and resilience in the ICT doctoral journey
Rigor, ethics, wellbeing and resilience in the ICT doctoral journeyYannis The doctoral thesis trajectory has been often characterized as a “long and windy road” or a journey to “Ithaka”, suggesting the promises and challenges of this journey of initiation to research. The doctoral candidates need to complete such journey (i) preserving and even enhancing their wellbeing, (ii) overcoming the many challenges through resilience, while keeping (iii) high standards of ethics and (iv) scientific rigor. This talk will provide a personal account of lessons learnt and recommendations from a senior researcher over his 30+ years of doctoral supervision and care for doctoral students. Specific attention will be paid on the special features of the (i) interdisciplinary doctoral research that involves Information and Communications Technologies (ICT) and other scientific traditions, and (ii) the challenges faced in the complex technological and research landscape dominated by Artificial Intelligence.
NALCO Green Anode Plant,Compositions of CPC,Pitch
NALCO Green Anode Plant,Compositions of CPC,Pitcharpitprachi123 Its a pdf about all the process involving in the green anode production
Center Enamel can Provide Aluminum Dome Roofs for diesel tank.docx
Center Enamel can Provide Aluminum Dome Roofs for diesel tank.docxCenterEnamel Center Enamel can Provide Aluminum Dome Roofs for diesel tank.docx
ElysiumPro Company Profile 2025-2026.pdf
ElysiumPro Company Profile 2025-2026.pdfinfo751436 Description
ElysiumPro | IEEE Final Year Projects | Best Internship Training | Inplant Training in Madurai
Best Final Year project training center
Address:
First Floor, A Block, 'Elysium Campus, 229, Church Rd, Vaigai Colony, Madurai, Tamil Nadu 625020
Plus Code:
W4CX+56 Madurai, Tamil Nadu
+91 9944793398
[email protected]
Elysium Group of Companies established ElysiumPro in 2001. Since its inception, it has been the most sought-after destination for final year project development and research papers among the students. Our commitment to providing quality project training & documentation to students has always been exceptional. We deliver the final year engineering projects and technical documents that provide extra edge and industry exposure to land prestigious jobs and reputed institutions for higher studies. Students from all over the country avail of our services for their final year projects. On average, we develop 5000+ projects and research papers per year on varied advanced domains. Python, JAVA, PHP, Android, Matlab, LabView, VLSI, SIMULINK, Power electronics, Power System, Antenna, Machine Learning, Deep Learning, Data Science, Artificial Intelligence, data Mining, Big Data, Cloud Computing, IoT,
Hours of Operation: -
Sunday 10am-1pm
Monday 7.30am-8pm
Tuesday 7.30am-8pm
Wednesday 7.30am-8pm
Thursday 7.30am-8pm
Friday 7.30am-8pm
Saturday 7.30am-8pm
Web Site:
https://elysiumpro.in/
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
Youtube Geotagged Video:
https://youtu.be/QULY6XfuMyo
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
Slideshow Images (Google Photos):
https://photos.app.goo.gl/hVwQJtkeptA1JZKd9
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
GBP Listing:
https://goo.gl/maps/6d6hko6TsDYyeDrz9
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
Serving Areas:
https://www.google.com/maps/d/edit?mid=1-fsZogBiEAcjGP_aDyI0UKKIcwVUWfo&usp=sharing
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
Google Site:
https://elysiumpro-project-center.business.site
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
Google Sheet: https://docs.google.com/spreadsheets/d/1uXA07zxrUx2FCnBZWH80PpBZQrrX-2q1UBBe_0k3Yeo
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
Google Document: https://docs.google.com/document/d/1BU4ZHW_41XJm2lvTq9pWYUpZILAEmF9dWEw7-DBbWoE
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
Google Slides: https://docs.google.com/presentation/d/1uF8q6ueJWcAnhKTQsZxLE0Bo9PwgRNwCeuGV_ZgbSyU
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*
Engineering Mechanics Introduction and its Application
Engineering Mechanics Introduction and its ApplicationSakthivel M Engineering Mechanics Introduction
最新版美国圣莫尼卡学院毕业证(SMC毕业证书)原版定制
最新版美国圣莫尼卡学院毕业证(SMC毕业证书)原版定制Taqyea 鉴于此,定制圣莫尼卡学院学位证书提升履历【q薇1954292140】原版高仿圣莫尼卡学院毕业证(SMC毕业证书)可先看成品样本【q薇1954292140】帮您解决在美国圣莫尼卡学院未毕业难题,美国毕业证购买,美国文凭购买,【q微1954292140】美国文凭购买,美国文凭定制,美国文凭补办。专业在线定制美国大学文凭,定做美国本科文凭,【q微1954292140】复制美国Santa Monica College completion letter。在线快速补办美国本科毕业证、硕士文凭证书,购买美国学位证、圣莫尼卡学院Offer,美国大学文凭在线购买。
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
【复刻一套圣莫尼卡学院毕业证成绩单信封等材料最强攻略,Buy Santa Monica College Transcripts】
购买日韩成绩单、英国大学成绩单、美国大学成绩单、澳洲大学成绩单、加拿大大学成绩单(q微1954292140)新加坡大学成绩单、新西兰大学成绩单、爱尔兰成绩单、西班牙成绩单、德国成绩单。成绩单的意义主要体现在证明学习能力、评估学术背景、展示综合素质、提高录取率,以及是作为留信认证申请材料的一部分。
圣莫尼卡学院成绩单能够体现您的的学习能力,包括圣莫尼卡学院课程成绩、专业能力、研究能力。(q微1954292140)具体来说,成绩报告单通常包含学生的学习技能与习惯、各科成绩以及老师评语等部分,因此,成绩单不仅是学生学术能力的证明,也是评估学生是否适合某个教育项目的重要依据!
4th International Conference on Computer Science and Information Technology (...
4th International Conference on Computer Science and Information Technology (...ijait 4th International Conference on Computer Science and Information Technology
(COMSCI 2025) will act as a major forum for the presentation of innovative ideas,
approaches, developments, and research projects in the area computer Science and
Information Technology. It will also serve to facilitate the exchange of information
between researchers and industry professionals to discuss the latest issues and
advancement in the research area.
The basics of hydrogenation of co2 reaction
The basics of hydrogenation of co2 reactionkumarrahul230759 basics of hydrogenation of CO2 where syntheis and literature review is well explained
社内勉強会資料_Chain of Thought .
社内勉強会資料_Chain of Thought .NABLAS株式会社 本資料「To CoT or not to CoT?」では、大規模言語モデルにおけるChain of Thought(CoT)プロンプトの効果について詳しく解説しています。
CoTはあらゆるタスクに効く万能な手法ではなく、特に数学的・論理的・アルゴリズム的な推論を伴う課題で高い効果を発揮することが実験から示されています。
一方で、常識や一般知識を問う問題に対しては効果が限定的であることも明らかになりました。
複雑な問題を段階的に分解・実行する「計画と実行」のプロセスにおいて、CoTの強みが活かされる点も注目ポイントです。
This presentation explores when Chain of Thought (CoT) prompting is truly effective in large language models.
The findings show that CoT significantly improves performance on tasks involving mathematical or logical reasoning, while its impact is limited on general knowledge or commonsense tasks.
Deep Learning for Natural Language Processing_FDP on 16 June 2025 MITS.pptx
Deep Learning for Natural Language Processing_FDP on 16 June 2025 MITS.pptxresming1 This gives an introduction to how NLP has evolved from the time of World War II till this date through the advances in approaches, architectures and word representations. From rule based approaches, it advanced to statistical approaches. from traditional machine learning algorithms it advanced to deep neural network architectures. Deep neural architectures include recurrent neural networks, long short term memory, gated recurrent units, seq2seq models, encoder decoder models, transformer architecture, upto large language models and vision language models which are multimodal in nature.
Development of Portable Biomass Briquetting Machine (S, A & D)-1.pptx
Development of Portable Biomass Briquetting Machine (S, A & D)-1.pptxaniket862935 Biomass briquetting Machine
3. What is the principles of Teamwork_Module_V1.0.ppt
3. What is the principles of Teamwork_Module_V1.0.pptengaash9 Demonstrate the role of teamwork in the execution of systems engineering.
Describe the principles of successful teams.
20CE601- DESIGN OF STEEL STRUCTURES ,INTRODUCTION AND ALLOWABLE STRESS DESIGN
20CE601- DESIGN OF STEEL STRUCTURES ,INTRODUCTION AND ALLOWABLE STRESS DESIGNgowthamvicky1 • Understand concepts of limit state and working stress method of design of structural steel members and various types of connections.
• Determine net area and effective sections in tension members, tension splices, lug angles and gussets.
• Execute design of compression members as per IS codal practice.
• Analyze concepts of design of flexural members.
• Design structural systems such as roof trusses, gantry girders as per provisions of IS 800 – 2007 of practice for limit state method.
OUTCOMES:
On successful completion of this course, the students will be able to,
• Analyze different types of bolted and welded connections.
• Develop skills to design tension members, splices, lug angles and gussets.
• Elaborate IS Code design practice of various compression members.
• Design laterally supported and unsupported beams, built-up beams, plate girders and stiffeners.
• Acquire knowledge about components of industrial structures, Gantry girders and roof trusses.
TEXT BOOKS:
1. Bhavikatti S S, “Design of Steel Structures”, By Limit State Method as per IS: 800 – 2007, IK International Publishing House Pvt. Ltd., 2019.
2. Subramanian N, “Design of Steel Structures”, Oxford University Press 2011.
REFERENCE BOOKS:
1. Duggal S K, “Limit State Design of Steel Structures”, Tata, McGraw Hill Education Pvt. Ltd., New Delhi, 2017.
2. Shiyekar M R, “Limit State Design in Structural Steel”, PHI Learning Private Limited, New Delhi, 2013.
3. IS: 800 – 2007, IS: 800 – 1984, General Construction in Steel – Code of Practice, BIS, New Delhi.
Structural steel types – Mechanical Properties of structural steel- Indian structural steel products- Steps involved in the Deign Process -Steel Structural systems and their Elements- -Type of Loads on Structures and Load combinations- Code of practices, Loading standards and Specifications - Concept of Allowable Stress Method, and Limit State Design Methods for Steel structures-Relative advantages and Limitations-Strengths and Serviceability Limit states.
Allowable stresses as per IS 800 section 11 -Concepts of Allowable stress design for bending and Shear –Check for Elastic deflection-Calculation of moment carrying capacity –Design of Laterally supported Solid Hot Rolled section beams-Allowable stress deign of Angle Tension and Compression Members and estimation of axial load carrying capacity.
Type of Fasteners- Bolts Pins and welds- Types of simple bolted and welded connections Relative advantages and Limitations-Modes of failure-the concept of Shear lag-efficiency of joints- Axially loaded bolted connections for Plates and Angle Members using bearing type bolts –Prying forces and Hanger connection– Design of Slip critical connections with High strength Friction Grip bolts.- Design of joints for combined shear and Tension- Eccentrically Loaded Bolted Bracket Connections- Welds-symbols and specifications- Effective area of welds-Fillet and but Welded connections-Axially Loaded connections for Plate and angle truss members and
Water demand - Types , variations and WDS
Water demand - Types , variations and WDSdhanashree78 Water demand refers to the volume of water needed or requested by users for various purposes. It encompasses the water required for domestic, industrial, agricultural, public, and other uses. Essentially, it represents the overall need or quantity of water required to meet the demands of different sectors and activities.
Cadastral Maps
Cadastral MapsGoogle Preparation of cadastral maps based by Engineer Dungo Tizazu from Dire Dawa University
Ad
Classification Algorithm in Machine Learning
- 1. Supervised vs. Unsupervised Learning Supervised learning (classification) ◦ Supervision: The training data (observations, measurements, etc.) are accompanied by labels indicating the class of the observations ◦ New data is classified based on the training set Unsupervised learning (clustering) ◦ The class labels of training data is unknown ◦ Given a set of measurements, observations, etc. with the aim of establishing the existence of classes or clusters in the data
- 4. Classification predicts categorical class labels (discrete or nominal) classifies data (constructs a model) based on the training set and the values (class labels) in a classifying attribute and uses it in classifying new data Prediction models continuous-valued functions, i.e., predicts unknown or missing values Typical applications Credit approval Target marketing Medical diagnosis Fraud detection Classification vs. Prediction
- 5. Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes, one of the attributes is the class. Find a model for class attribute as a function of the values of other attributes. Goal: previously unseen records should be assigned a class as accurately as possible. A test set is used to determine the accuracy of the model. Usually, the given data set is divided into training and test sets, with training set used to build the model and test set used to validate it.
- 6. Classification—A Two-Step Process Model construction: describing a set of predetermined classes Each tuple/sample is assumed to belong to a predefined class, as determined by the class label attribute The set of tuples used for model construction is training set The model is represented as classification rules, decision trees, or mathematical formulae
- 7. Classification—A Two-Step Process Model usage: for classifying future or unknown objects Estimate accuracy of the model The known label of test sample is compared with the classified result from the model Accuracy rate is the percentage of test set samples that are correctly classified by the model Test set is independent of training set, otherwise over-fitting will occur If the accuracy is acceptable, use the model to classify data tuples whose class labels are not known
- 8. Classification Process (1): Model Construction Training Data NAME RANK YEARS TENURED Mike Assistant Prof 3 no Mary Assistant Prof 7 yes Bill Professor 2 yes Jim Associate Prof 7 yes Dave Assistant Prof 6 no Anne Associate Prof 3 no Classification Algorithms IF rank = ‘professor’ OR years > 6 THEN tenured = ‘yes’ Classifier (Model)
- 9. Classification Process (2): Use the Model in Prediction Classifier Testing Data NAME RANK YEARS TENURED Tom Assistant Prof 2 no Merlisa Associate Prof 7 no George Professor 5 yes Joseph Assistant Prof 7 yes Unseen Data (Jeff, Professor, 4) Tenured?
- 10. The Learning Process in spam mail Example Email Server ● Number of recipients ● Size of message ● Number of attachments ● Number of "re's" in the subject line … Model Learning Model Testin g
- 11. An Example A fish-packing plant wants to automate the process of sorting incoming fish according to species As a pilot project, it is decided to try to separate sea bass from salmon using optical sensing Classification
- 12. An Example (continued) Features/attributes: Length Lightness Width Position of mouth Classification
- 13. An Example (continued) Preprocessing: Images of different fishes are isolated from one another and from background; Feature extraction: The information of a single fish is then sent to a feature extractor, that measure certain “features” or “properties”; Classification: The values of these features are passed to a classifier that evaluates the evidence presented, and build a model to discriminate between the two species Classification
- 14. An Example (continued) Classification Domain knowledge: ◦ A sea bass is generally longer than a salmon Related feature: (or attribute) ◦ Length Training the classifier: ◦ Some examples are provided to the classifier in this form: <fish_length, fish_name> ◦ These examples are called training examples ◦ The classifier learns itself from the training examples, how to distinguish Salmon from Bass based on the fish_length
- 15. An Example (continued) Classification Classification model (hypothesis): ◦ The classifier generates a model from the training data to classify future examples (test examples) ◦ An example of the model is a rule like this: ◦ If Length >= l* then sea bass otherwise salmon ◦ Here the value of l* determined by the classifier Testing the model ◦ Once we get a model out of the classifier, we may use the classifier to test future examples ◦ The test data is provided in the form <fish_length> ◦ The classifier outputs <fish_type> by checking fish_length against the model
- 16. An Example (continued) So the overall classification process goes like this Classification Preprocessing, and feature extraction Training Training Data Model Test/Unlabeled Data Testing against model/ Classification Feature vector Preprocessing, and feature extraction Feature vector Prediction/ Evaluation
- 17. An Example (continued) Classification Pre- processing, Feature extraction 12, salmon 15, sea bass 8, salmon 5, sea bass Training data Feature vector Training If len > 12, then sea bass else salmon Model Test data 15, salmon 10, salmon 18, ? 8, ? Feature vector Test/ Classify sea bass (error!) salmon (correct) sea bass salmon Evaluation/Prediction Pre- processing, Feature extraction Labeled data Unlabeled data
- 18. An Example (continued) Classification Why error? Insufficient training data Too few features Too many/irrelevant features Overfitting / specialization
- 19. An Example (continued) Classification Pre- processing, Feature extraction 12, 4, salmon 15, 8, sea bass 8, 2, salmon 5, 10, sea bass Training data Feature vector Training If ltns > 6 or len*5+ltns*2>100 then sea bass else salmon Model Test data 15, 2, salmon 10, 7, salmon 18, 7, ? 8, 5, ? Feature vector Test/ Classify salmon (correct) salmon (correct) sea bass salmon Evaluation/Prediction Pre- processing, Feature extraction
- 20. Linear, Non-linear, Multi-class and Multi-label classification
- 21. Linear Classification A linear classifier achieves this by making a classification decision based on the value of a linear combination of the characteristics. A classification algorithm (Classifier) that makes its classification based on a linear predictor function combining a set of weights with the feature vector Decision boundaries is flat ◦ Line, plane, …. May involve non-linear operations
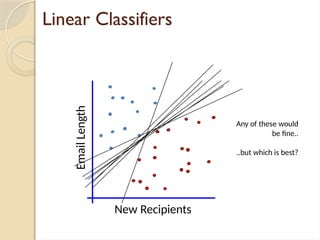
- 24. Linear Classifiers How would you classify this data? New Recipients Email Length
- 27. Linear Classifiers Any of these would be fine.. ..but which is best? New Recipients Email Length
- 28. Classifier Margin New Recipients Define the margin of a linear classifier as the width that the boundary could be increased by before hitting a datapoint. Email Length
- 34. No Linear Classifier can cover all instances How would you classify this data? New Recipients Email Length
- 35. • Ideally, the best decision boundary should be the one which provides an optimal performance such as in the following figure
- 36. No Linear Classifier can cover all instances Email Length New Recipients
- 37. What is multiclass Output ◦ In some cases, output space can be very large (i.e., K is very large) Each input belongs to exactly one class (c.f. in multilabel, input belongs to many classes)
- 38. Multi-Classes Classification Multi-class classification is simply classifying objects into any one of multiple categories. Such as classifying just into either a dog or cat from the dataset. 1.When there are more than two categories in which the images can be classified, and 2.An image does not belong to more than one class If both of the above conditions are satisfied, it is referred to as a multi- class image classification problem
- 40. Multi-label classification When we can classify an image into more than one class (as in the image beside), it is known as a multi-label image classification problem. Multi-label classification is a type of classification in which an object can be categorized into more than one class. For example, In the image dataset, we will classify a picture as the image of a dog or cat and also classify the same image based on the breed of the dog or cat . These are all labels of the given images. Each image here belongs to more than one class and hence it is a multi-label image classification problem.
- 43. Multi classVs multi label classification