Commit2015 kharchenko - python generators - ext
Download as pptx, pdf3 likes665 views

The document discusses using Python generators and pipelines to efficiently process streaming data. It provides examples of parsing Oracle listener logs to extract client IP addresses using generators. Generators allow data to be yielded incrementally to reduce memory usage and enable non-blocking operations compared to collecting all results at once. The document advocates defining simple generator functions that can be pipelined together to iteratively process large datasets.
1 of 26
Downloaded 23 times



![Streaming in Python
# Lists
db_list = ['db1', 'db2', 'db3']
for db in db_list:
print db
# Dictionaries
host_cpu = {'avg': 2.34, 'p99': 98.78, 'min': 0.01}
for stat in host_cpu:
print "%s = %s" % (stat, host_cpu[stat])
# Files, strings
file = open("/etc/oratab")
for line in file:
for word in line.split(" "):
print word
# Whatever is coming out of get_things()
for thing in get_things():
print thing](https://image.slidesharecdn.com/commit2015-kharchenko-pythongenerators-ext-151014181026-lva1-app6892/85/Commit2015-kharchenko-python-generators-ext-4-320.jpg)
![Quick example: Reading records from a file
def print_databases():
""" Read /etc/oratab and print database names """
file = open("/etc/oratab", 'r')
while True:
line = file.readline() # Get next line
# Check for empty lines
if len(line) == 0 and not line.endswith('n'):
break
# Parsing oratab line into components
db_line = line.strip()
db_info_array = db_line.split(':')
db_name = db_info_array[0]
print db_name
file.close()](https://image.slidesharecdn.com/commit2015-kharchenko-pythongenerators-ext-151014181026-lva1-app6892/85/Commit2015-kharchenko-python-generators-ext-5-320.jpg)
![Reading records from a file: with “streaming”
def print_databases():
""" Read /etc/oratab and print database names """
with open("/etc/oratab") as file:
for line in file:
print line.strip().split(':')[0]](https://image.slidesharecdn.com/commit2015-kharchenko-pythongenerators-ext-151014181026-lva1-app6892/85/Commit2015-kharchenko-python-generators-ext-6-320.jpg)


![First attempt at listener log parser
def parse_listener_log(log_name):
""" Parse listener log and return clients
"""
client_hosts = []
with open(log_name) as listener_log:
for line in listener_log:
host_match = <regex magic>
if host_match:
host = <regex magic>
client_hosts.append(host)
return client_hosts](https://image.slidesharecdn.com/commit2015-kharchenko-pythongenerators-ext-151014181026-lva1-app6892/85/Commit2015-kharchenko-python-generators-ext-9-320.jpg)
![First attempt at listener log parser
def parse_listener_log(log_name):
""" Parse listener log and return clients
"""
client_hosts = []
with open(log_name) as listener_log:
for line in listener_log:
host_match = <regex magic>
if host_match:
host = <regex magic>
client_hosts.append(host)
return client_hosts
MEMORY
WASTE!
Stores all
results until
return
BLOCKING!
Does NOT
return until
the entire log
is processed](https://image.slidesharecdn.com/commit2015-kharchenko-pythongenerators-ext-151014181026-lva1-app6892/85/Commit2015-kharchenko-python-generators-ext-10-320.jpg)
![Generators for efficiency
def parse_listener_log(log_name):
""" Parse listener log and return clients
"""
client_hosts = []
with open(log_name) as listener_log:
for line in listener_log:
host_match = <regex magic>
if host_match:
host = <regex magic>
client_hosts.append(host)
return client_hosts](https://image.slidesharecdn.com/commit2015-kharchenko-pythongenerators-ext-151014181026-lva1-app6892/85/Commit2015-kharchenko-python-generators-ext-11-320.jpg)
![Generators for efficiency
def parse_listener_log(log_name):
""" Parse listener log and return clients
"""
client_hosts = []
with open(log_name) as listener_log:
for line in listener_log:
host_match = <regex magic>
if host_match:
host = <regex magic>
client_hosts.append(host)
return client_hosts](https://image.slidesharecdn.com/commit2015-kharchenko-pythongenerators-ext-151014181026-lva1-app6892/85/Commit2015-kharchenko-python-generators-ext-12-320.jpg)


![Nongenerators in a nutshell
def test_nongenerator():
""" Test no generator """
result = []
print "ENTER()"
for i in range(5):
print "add i=%d" % i
result.append(i)
print "EXIT()"
return result
# MAIN
for i in test_nongenerator():
print "RET=%d" % i
ENTER()
add i=0
add i=1
add i=2
add i=3
add i=4
EXIT()
RET=0
RET=1
RET=2
RET=3
RET=4](https://image.slidesharecdn.com/commit2015-kharchenko-pythongenerators-ext-151014181026-lva1-app6892/85/Commit2015-kharchenko-python-generators-ext-15-320.jpg)



![Generators for simplicity
def extract_client_ips(lines):
""" GENERATOR: Extract client host
"""
host_regex = re.compile('(HOST=(S+))(PORT=')
for line in lines:
line_match = host_regex.search(line)
if line_match:
yield line_match.groups(0)[0]](https://image.slidesharecdn.com/commit2015-kharchenko-pythongenerators-ext-151014181026-lva1-app6892/85/Commit2015-kharchenko-python-generators-ext-20-320.jpg)






Ad
Recommended
2015 555 kharchenko_ppt
2015 555 kharchenko_pptMaxym Kharchenko Maxym Kharchenko presented ways to manage Oracle databases with Python. He demonstrated a Python tool to ping multiple Oracle databases concurrently and time the execution. The tool reports the status and timing for each database pinged. Python enforces good coding practices and interfaces well with databases, APIs, and other systems. Learning Python helps develop a more Pythonic way of thinking that can improve code quality and productivity.
Visualizing ORACLE performance data with R @ #C16LV
Visualizing ORACLE performance data with R @ #C16LVMaxym Kharchenko The document presents a discussion on visualizing Oracle database performance using R, highlighting its advantages over traditional methods. It details the steps to prepare, transform, and visualize data using R, along with examples of different visualization techniques. Key takeaways include R's ability to serve as a powerful, graphic-enhanced alternative to traditional SQLPlus for database administrators.
Shell Script to Extract IP Address, MAC Address Information
Shell Script to Extract IP Address, MAC Address InformationVCP Muthukrishna This script collects the active MAC addresses, IP addresses, and associated hardware vendor information on a system. It uses the arp command to gather this network information and outputs it to an HTML file. The HTML file displays the IP address, MAC address, and includes a hyperlink to lookup the IEEE vendor information based on the first three octets of the MAC address. It also includes an option to email the results in an HTML formatted email.
File Space Usage Information and EMail Report - Shell Script
File Space Usage Information and EMail Report - Shell ScriptVCP Muthukrishna This script generates an HTML report of the top 10 largest files and directories on a server by size and emails the report. It uses the du command to get disk usage information, sorts the results in descending order of size, and outputs the top 10 to a HTML table. The table is written to a file and emailed using sendmail to notify of disk space usage.
Bash Script Disk Space Utilization Report and EMail
Bash Script Disk Space Utilization Report and EMailVCP Muthukrishna This bash script generates an HTML disk usage report and emails it. It collects disk usage information using df, formats it into an HTML table, and emails the report. If disk usage exceeds 90%, the row is highlighted red and a critical alert is shown. Usage between 70-80% is highlighted orange. The report is generated daily and emailed to a recipient.
Realtime Analytics Using MongoDB, Python, Gevent, and ZeroMQ
Realtime Analytics Using MongoDB, Python, Gevent, and ZeroMQRick Copeland Zarkov is a real-time analytics platform that uses MongoDB, Python, Gevent, and ZeroMQ to aggregate and analyze event data. It handles high volumes of event ingestion and uses a lightweight map/reduce framework to incrementally calculate statistics. The system was developed at SourceForge.net to monitor user and project activity in real-time and has proven capable of replacing other analytics solutions.
PuppetDB, Puppet Explorer and puppetdbquery
PuppetDB, Puppet Explorer and puppetdbqueryPuppet This document summarizes PuppetDB, Puppet Explorer, and puppetdbquery. PuppetDB is a Clojure service that stores Puppet data like facts, catalogs, and reports in a PostgreSQL backend. It allows exporting and collecting resources. PuppetDB has a rich query API to search nodes, environments, facts, catalogs, resources, and more. Puppet Explorer is a web UI that visualizes PuppetDB data using CoffeeScript and AngularJS. Puppetdbquery is a Puppet module and CLI tool for querying PuppetDB with functions, a Puppetface, hiera backend, and Ruby API. It allows querying nodes and resources with comparison, logical, and date expressions.
Redis as a message queue
Redis as a message queueBrandon Lamb Redis is being used as a message queue to asynchronously process image uploads on a website for gaming screenshots. When a user uploads images, the application server adds a message to the Redis queue containing metadata about the upload. A separate process polls the queue and processes each upload by resizing images, creating database entries, and more. This allows upload processing to happen in the background without blocking the user.
Impala: A Modern, Open-Source SQL Engine for Hadoop
Impala: A Modern, Open-Source SQL Engine for HadoopAll Things Open The document discusses a query execution framework involving components such as query planners, coordinators, and executors, which handle SQL requests and manage data across distributed systems like HDFS and HBase. It describes the process of transforming requests into executable plan fragments and handling intermediate results, with a focus on efficient data serialization. Additionally, it touches on various SQL functions and performance optimization techniques in data management.
working with files
working with filesSangeethaSasi1 This document discusses working with files in C++. It covers opening and closing files using constructors and the open() function. It describes using input and output streams to read from and write to files. It also discusses the different file stream classes like ifstream, ofstream, and fstream and their functions. Finally, it mentions the different file opening modes that can be used with the open() function.
Using Logstash, elasticsearch & kibana
Using Logstash, elasticsearch & kibanaAlejandro E Brito Monedero The document discusses using Logstash, Elasticsearch, and Kibana as tools for log collection, parsing, storage, and search. It provides configuration examples for processing logs from HTTPd and Tomcat servers and outlines various best practices for logging implementations. Additionally, it includes resources for further learning and emphasizes the importance of security and flexibility in logging applications.
Ansible for Beginners
Ansible for BeginnersArie Bregman The document is an Ansible workshop presentation led by Arie Bregman, aiming to introduce participants to Ansible as an IT automation tool that emphasizes simplicity and ease of use. It covers installation, basic commands, inventory management, writing playbooks, using modules, and executing tasks, culminating in hands-on exercises to reinforce learning. Additionally, it highlights features such as conditionals, loops, ad-hoc commands, and encourages further exploration of advanced topics like Ansible roles and error handling.
CouchDB Day NYC 2017: Full Text Search
CouchDB Day NYC 2017: Full Text SearchIBM Cloud Data Services This document provides instructions for performing full-text search using Cloudant. It includes steps to create a Cloudant account, set up an index, add documents, perform searches, handle pagination and sorting, and configure tokenization for text fields. Users are shown examples of searching by field values, getting the next page of results, sorting, and using different analyzers.
RestMQ - HTTP/Redis based Message Queue
RestMQ - HTTP/Redis based Message QueueGleicon Moraes RestMQ is a message queue system based on Redis that allows storing and retrieving messages through HTTP requests. It uses Redis' data structures like lists, sets, and hashes to maintain queues and messages. Messages can be added to and received from queues using RESTful endpoints. Additional features include status monitoring, queue control, and support for protocols like JSON, Comet, and WebSockets. The core functionality is language-agnostic but implementations exist in Python and Ruby.
MySQL Slow Query log Monitoring using Beats & ELK
MySQL Slow Query log Monitoring using Beats & ELKYoungHeon (Roy) Kim This document provides instructions for using Filebeat, Logstash, Elasticsearch, and Kibana to monitor and visualize MySQL slow query logs. It describes installing and configuring each component on appropriate servers to ship MySQL slow logs from database servers to Logstash for processing, indexing to Elasticsearch for search and analysis, and visualization of slow query trends and details in Kibana dashboards and graphs.
Parse, scale to millions
Parse, scale to millionsFlorent Vilmart The document provides an overview of scaling applications using Parse, including setup instructions, configuration details, and methods for managing various APIs such as file storage and push notifications. It covers essential topics like cloud code functions, database controller interactions, and strategies for optimizing performance and cost. There are specific implementation examples and recommendations for handling live queries and caching solutions.
Database Homework Help
Database Homework HelpDatabase Homework Help The document provides an overview of SimpleDB, a basic database system highlighting its components such as heapfiles, operators, and transaction management. It details the implementation of iterators, table schema creation, and database operations using code examples. Additionally, it explains how to manage heapfiles, conversion of CSV files to heapfiles, and testing procedures using the Ant tool.
serverstats
serverstatsBen De Koster This Bash script collects and displays server performance statistics on an Apache/MySQL server. It uses commands like ps, netstat, iostat, and mysqladmin to gather data on CPU usage, memory usage, disk space, Apache and MySQL processes and configurations, Exim queue status, and more. The results are output with color-coded headings to make the report easy to read. The user can specify which set of statistics to display.
How to admin
How to adminyalegko This document provides instructions for various tasks related to networking and system administration on Linux systems, including:
1) Configuring network interfaces using dhclient or manually assigning an IP address and route.
2) Installing and configuring OpenSSH for remote access and using SSH, SCP for secure file transfers.
3) Using common Linux commands like tcpdump, tshark, ps, kill, service to monitor network traffic, view processes, kill processes, and control services.
4) Additional instructions are provided for using shell commands like head, tail, awk, sed, grep to view logs and parse output from other commands. Guidance is given for capturing network traffic to PCAP files using tcp
Value protocols and codables
Value protocols and codablesFlorent Vilmart This document discusses using protocols and Codables to build REST APIs in Swift. It introduces Encodable and Decodable protocols which allow objects to be encoded to and decoded from data. This enables sending objects over REST without serialization code. Commands define API requests and responses. ObjectType is a protocol for objects that can be saved and fetched. Extensions add saving and fetching methods. The SDK handles encoding/decoding and executing requests on a background queue for asynchronous access to APIs.
CouchDB Day NYC 2017: Introduction to CouchDB 2.0
CouchDB Day NYC 2017: Introduction to CouchDB 2.0IBM Cloud Data Services Bradley Holt gave a presentation on Apache CouchDB 2.0, which introduced new features such as clustering, shards and replicas, Mango querying, and per-user databases. The presentation demonstrated how to connect to and interact with CouchDB through the HTTP API using the http-console tool, including creating databases and documents, retrieving documents, adding attachments, conditional requests, and deleting documents.
Nginx-lua
Nginx-luaДэв Тим Афс This document discusses using NGINX with embedded Lua scripting via OpenResty. Lua is a lightweight scripting language used in many applications and games. OpenResty bundles NGINX with LuaJIT and modules to allow full control over every stage of request processing with non-blocking Lua scripts. Examples show how to build a REST API for user scores with Redis using Lua scripts to handle data retrieval, modification and aggregation directly from NGINX.
CouchDB Day NYC 2017: MapReduce Views
CouchDB Day NYC 2017: MapReduce ViewsIBM Cloud Data Services The document outlines a lab session on map/reduce views using CouchDB, presenting key concepts such as design documents and views. It includes step-by-step examples of creating design documents, querying views, and adding reduce functions, with specific commands for setting up and interacting with the database. Additionally, the document encourages participants to try creating their own views and queries based on the provided instructions.
Overloading Perl OPs using XS
Overloading Perl OPs using XSℕicolas ℝ. The document discusses a presentation on overloading Perl operations using XS at The Perl Conference 2019, presented by Nicolas R. It covers topics such as the printing of optrees, the implementation of Perl opcodes, and practical examples of file checks and mocking in Perl. The session aims to deepen the understanding of Perl operations, enhance filesystem testing, and provide insights into Perl's functionality.
Perl Memory Use - LPW2013
Perl Memory Use - LPW2013Tim Bunce Tim Bunce's talk at the London Perl Workshop 2013 discusses Perl memory usage, profiling, and the management of memory allocation through malloc and arenas. The presentation covers various commands to inspect memory usage, highlights the challenges of tracking memory over time, and introduces tools like devel::size and devel::sizeme for analyzing memory consumption in Perl applications. Key recommendations include storing data in databases for scalability and flexibility while exploring future enhancements in memory profiling tools.
CouchDB Day NYC 2017: Replication
CouchDB Day NYC 2017: ReplicationIBM Cloud Data Services The document outlines a lab session on replication conducted by Bradley Holt during CouchDB Developer Day. It includes instructions for using the http-console to connect to CouchDB and perform replication tasks, such as creating databases and ensuring continuous replication. The session illustrates practical hands-on exercises to replicate data between two databases.
Lies, Damn Lies, and Benchmarks
Lies, Damn Lies, and BenchmarksWorkhorse Computing The document discusses benchmarking Perl in comparison to shell commands, highlighting misconceptions about Perl's speed. It emphasizes the importance of proper benchmarking techniques, including using the 'time' command and running multiple tests to account for background noise. The author illustrates various examples of performance comparisons between Perl and shell commands, showcasing that single-purpose programs tend to be faster while reminding readers that additional overhead comes with chaining commands.
Workshop on command line tools - day 2
Workshop on command line tools - day 2Leandro Lima The document is a workshop transcript covering command-line tools including the use of 'awk' for data filtering, comparing files with 'diff', and process management with 'top' and 'screen'. It provides examples and exercises for data manipulation, script execution, and changing file permissions using bash commands. Additionally, it introduces tools like 'datamash' for command-line calculations and demonstrates advanced command usage for genetic data analysis.
Teasing talk for Flow-based programming made easy with PyF 2.0
Teasing talk for Flow-based programming made easy with PyF 2.0Jonathan Schemoul The document discusses PyF, a Python dataflow processing framework. It describes dataflow programming as a paradigm where data items pass through a network of processing blocks from one to the next. With PyF, these blocks can be defined as Python generators, allowing lazy execution and low memory usage. The document outlines PyF's architecture, plugins system, and visual programming interface. It promotes an upcoming training session on PyF to be held the next day.
Kafka Summit SF 2017 - Streaming Processing in Python – 10 ways to avoid summ...
Kafka Summit SF 2017 - Streaming Processing in Python – 10 ways to avoid summ...confluent The document discusses stream processing with Python and options to avoid summoning Cuthulu when doing so. It summarizes Apache Spark's capabilities for stream processing with Python, current limitations, and potential future improvements. It also discusses alternative approaches like using pure Python or Spark Structured Streaming. The document recommends Spark Streaming for Python stream processing needs today while noting potential performance improvements in the future.
More Related Content
What's hot (20)
Impala: A Modern, Open-Source SQL Engine for Hadoop
Impala: A Modern, Open-Source SQL Engine for HadoopAll Things Open The document discusses a query execution framework involving components such as query planners, coordinators, and executors, which handle SQL requests and manage data across distributed systems like HDFS and HBase. It describes the process of transforming requests into executable plan fragments and handling intermediate results, with a focus on efficient data serialization. Additionally, it touches on various SQL functions and performance optimization techniques in data management.
working with files
working with filesSangeethaSasi1 This document discusses working with files in C++. It covers opening and closing files using constructors and the open() function. It describes using input and output streams to read from and write to files. It also discusses the different file stream classes like ifstream, ofstream, and fstream and their functions. Finally, it mentions the different file opening modes that can be used with the open() function.
Using Logstash, elasticsearch & kibana
Using Logstash, elasticsearch & kibanaAlejandro E Brito Monedero The document discusses using Logstash, Elasticsearch, and Kibana as tools for log collection, parsing, storage, and search. It provides configuration examples for processing logs from HTTPd and Tomcat servers and outlines various best practices for logging implementations. Additionally, it includes resources for further learning and emphasizes the importance of security and flexibility in logging applications.
Ansible for Beginners
Ansible for BeginnersArie Bregman The document is an Ansible workshop presentation led by Arie Bregman, aiming to introduce participants to Ansible as an IT automation tool that emphasizes simplicity and ease of use. It covers installation, basic commands, inventory management, writing playbooks, using modules, and executing tasks, culminating in hands-on exercises to reinforce learning. Additionally, it highlights features such as conditionals, loops, ad-hoc commands, and encourages further exploration of advanced topics like Ansible roles and error handling.
CouchDB Day NYC 2017: Full Text Search
CouchDB Day NYC 2017: Full Text SearchIBM Cloud Data Services This document provides instructions for performing full-text search using Cloudant. It includes steps to create a Cloudant account, set up an index, add documents, perform searches, handle pagination and sorting, and configure tokenization for text fields. Users are shown examples of searching by field values, getting the next page of results, sorting, and using different analyzers.
RestMQ - HTTP/Redis based Message Queue
RestMQ - HTTP/Redis based Message QueueGleicon Moraes RestMQ is a message queue system based on Redis that allows storing and retrieving messages through HTTP requests. It uses Redis' data structures like lists, sets, and hashes to maintain queues and messages. Messages can be added to and received from queues using RESTful endpoints. Additional features include status monitoring, queue control, and support for protocols like JSON, Comet, and WebSockets. The core functionality is language-agnostic but implementations exist in Python and Ruby.
MySQL Slow Query log Monitoring using Beats & ELK
MySQL Slow Query log Monitoring using Beats & ELKYoungHeon (Roy) Kim This document provides instructions for using Filebeat, Logstash, Elasticsearch, and Kibana to monitor and visualize MySQL slow query logs. It describes installing and configuring each component on appropriate servers to ship MySQL slow logs from database servers to Logstash for processing, indexing to Elasticsearch for search and analysis, and visualization of slow query trends and details in Kibana dashboards and graphs.
Parse, scale to millions
Parse, scale to millionsFlorent Vilmart The document provides an overview of scaling applications using Parse, including setup instructions, configuration details, and methods for managing various APIs such as file storage and push notifications. It covers essential topics like cloud code functions, database controller interactions, and strategies for optimizing performance and cost. There are specific implementation examples and recommendations for handling live queries and caching solutions.
Database Homework Help
Database Homework HelpDatabase Homework Help The document provides an overview of SimpleDB, a basic database system highlighting its components such as heapfiles, operators, and transaction management. It details the implementation of iterators, table schema creation, and database operations using code examples. Additionally, it explains how to manage heapfiles, conversion of CSV files to heapfiles, and testing procedures using the Ant tool.
serverstats
serverstatsBen De Koster This Bash script collects and displays server performance statistics on an Apache/MySQL server. It uses commands like ps, netstat, iostat, and mysqladmin to gather data on CPU usage, memory usage, disk space, Apache and MySQL processes and configurations, Exim queue status, and more. The results are output with color-coded headings to make the report easy to read. The user can specify which set of statistics to display.
How to admin
How to adminyalegko This document provides instructions for various tasks related to networking and system administration on Linux systems, including:
1) Configuring network interfaces using dhclient or manually assigning an IP address and route.
2) Installing and configuring OpenSSH for remote access and using SSH, SCP for secure file transfers.
3) Using common Linux commands like tcpdump, tshark, ps, kill, service to monitor network traffic, view processes, kill processes, and control services.
4) Additional instructions are provided for using shell commands like head, tail, awk, sed, grep to view logs and parse output from other commands. Guidance is given for capturing network traffic to PCAP files using tcp
Value protocols and codables
Value protocols and codablesFlorent Vilmart This document discusses using protocols and Codables to build REST APIs in Swift. It introduces Encodable and Decodable protocols which allow objects to be encoded to and decoded from data. This enables sending objects over REST without serialization code. Commands define API requests and responses. ObjectType is a protocol for objects that can be saved and fetched. Extensions add saving and fetching methods. The SDK handles encoding/decoding and executing requests on a background queue for asynchronous access to APIs.
CouchDB Day NYC 2017: Introduction to CouchDB 2.0
CouchDB Day NYC 2017: Introduction to CouchDB 2.0IBM Cloud Data Services Bradley Holt gave a presentation on Apache CouchDB 2.0, which introduced new features such as clustering, shards and replicas, Mango querying, and per-user databases. The presentation demonstrated how to connect to and interact with CouchDB through the HTTP API using the http-console tool, including creating databases and documents, retrieving documents, adding attachments, conditional requests, and deleting documents.
Nginx-lua
Nginx-luaДэв Тим Афс This document discusses using NGINX with embedded Lua scripting via OpenResty. Lua is a lightweight scripting language used in many applications and games. OpenResty bundles NGINX with LuaJIT and modules to allow full control over every stage of request processing with non-blocking Lua scripts. Examples show how to build a REST API for user scores with Redis using Lua scripts to handle data retrieval, modification and aggregation directly from NGINX.
CouchDB Day NYC 2017: MapReduce Views
CouchDB Day NYC 2017: MapReduce ViewsIBM Cloud Data Services The document outlines a lab session on map/reduce views using CouchDB, presenting key concepts such as design documents and views. It includes step-by-step examples of creating design documents, querying views, and adding reduce functions, with specific commands for setting up and interacting with the database. Additionally, the document encourages participants to try creating their own views and queries based on the provided instructions.
Overloading Perl OPs using XS
Overloading Perl OPs using XSℕicolas ℝ. The document discusses a presentation on overloading Perl operations using XS at The Perl Conference 2019, presented by Nicolas R. It covers topics such as the printing of optrees, the implementation of Perl opcodes, and practical examples of file checks and mocking in Perl. The session aims to deepen the understanding of Perl operations, enhance filesystem testing, and provide insights into Perl's functionality.
Perl Memory Use - LPW2013
Perl Memory Use - LPW2013Tim Bunce Tim Bunce's talk at the London Perl Workshop 2013 discusses Perl memory usage, profiling, and the management of memory allocation through malloc and arenas. The presentation covers various commands to inspect memory usage, highlights the challenges of tracking memory over time, and introduces tools like devel::size and devel::sizeme for analyzing memory consumption in Perl applications. Key recommendations include storing data in databases for scalability and flexibility while exploring future enhancements in memory profiling tools.
CouchDB Day NYC 2017: Replication
CouchDB Day NYC 2017: ReplicationIBM Cloud Data Services The document outlines a lab session on replication conducted by Bradley Holt during CouchDB Developer Day. It includes instructions for using the http-console to connect to CouchDB and perform replication tasks, such as creating databases and ensuring continuous replication. The session illustrates practical hands-on exercises to replicate data between two databases.
Lies, Damn Lies, and Benchmarks
Lies, Damn Lies, and BenchmarksWorkhorse Computing The document discusses benchmarking Perl in comparison to shell commands, highlighting misconceptions about Perl's speed. It emphasizes the importance of proper benchmarking techniques, including using the 'time' command and running multiple tests to account for background noise. The author illustrates various examples of performance comparisons between Perl and shell commands, showcasing that single-purpose programs tend to be faster while reminding readers that additional overhead comes with chaining commands.
Workshop on command line tools - day 2
Workshop on command line tools - day 2Leandro Lima The document is a workshop transcript covering command-line tools including the use of 'awk' for data filtering, comparing files with 'diff', and process management with 'top' and 'screen'. It provides examples and exercises for data manipulation, script execution, and changing file permissions using bash commands. Additionally, it introduces tools like 'datamash' for command-line calculations and demonstrates advanced command usage for genetic data analysis.
Similar to Commit2015 kharchenko - python generators - ext (20)
Teasing talk for Flow-based programming made easy with PyF 2.0
Teasing talk for Flow-based programming made easy with PyF 2.0Jonathan Schemoul The document discusses PyF, a Python dataflow processing framework. It describes dataflow programming as a paradigm where data items pass through a network of processing blocks from one to the next. With PyF, these blocks can be defined as Python generators, allowing lazy execution and low memory usage. The document outlines PyF's architecture, plugins system, and visual programming interface. It promotes an upcoming training session on PyF to be held the next day.
Kafka Summit SF 2017 - Streaming Processing in Python – 10 ways to avoid summ...
Kafka Summit SF 2017 - Streaming Processing in Python – 10 ways to avoid summ...confluent The document discusses stream processing with Python and options to avoid summoning Cuthulu when doing so. It summarizes Apache Spark's capabilities for stream processing with Python, current limitations, and potential future improvements. It also discusses alternative approaches like using pure Python or Spark Structured Streaming. The document recommends Spark Streaming for Python stream processing needs today while noting potential performance improvements in the future.
Monitoring and Debugging your Live Applications
Monitoring and Debugging your Live ApplicationsRobert Coup The document discusses techniques for monitoring and debugging live applications, emphasizing the importance of logging, configuration, and various logging tools. It covers examples of logging setups, the use of debuggers like pdb, and remote consoles for accessing applications. Additionally, it highlights the benefits of interaction between applications and users through bots and messaging services.
Apache Spark Structured Streaming for Machine Learning - StrataConf 2016
Apache Spark Structured Streaming for Machine Learning - StrataConf 2016Holden Karau The document discusses the integration of structured streaming with machine learning within Apache Spark, outlining the capabilities and experimental APIs being developed. It covers topics such as the use of datasets and continuous tables in structured streaming, as well as potential methods for building machine learning pipelines. Additionally, it highlights challenges and considerations for implementing streaming ML, alongside resources for further reading and community engagement.
Interop 2015: Hardly Enough Theory, Barley Enough Code
Interop 2015: Hardly Enough Theory, Barley Enough CodeJeremy Schulman The document discusses intermediate Python techniques for automation, focusing on empowering teams and improving productivity through automation. Key concepts include iterators, generators, data loading with JSON/YAML/CSV, and templating with Jinja2, along with best practices in programming and data validation. It emphasizes the importance of decomposing problems and utilizing Pythonic techniques to enhance efficiency and maintainability in coding.
A look ahead at spark 2.0
A look ahead at spark 2.0 Databricks This document summarizes the upcoming features in Spark 2.0, including major performance improvements from Tungsten optimizations, unifying DataFrames and Datasets into a single API, and new capabilities for streaming data with Structured Streaming. Spark 2.0 aims to further simplify programming models while delivering up to 10x speedups for queries through compiler techniques that generate efficient low-level execution plans.
PySaprk
PySaprkGiivee The PySpark is a next generation cloud computing engine that uses Python. It allows users to write Spark applications in Python. PySpark applications can access data via the Spark API and process it using Python. The PySpark architecture involves Python code running on worker nodes communicating with Java Virtual Machines on those nodes via sockets. This allows leveraging Python libraries like scikit-learn with Spark. The presentation demonstrated recommender systems and interactive shell usage with PySpark.
Hack Like It's 2013 (The Workshop)
Hack Like It's 2013 (The Workshop)Itzik Kotler This document introduces Pythonect, a dataflow programming language based on Python, highlighting its installation, syntax, and applications in developing domain-specific languages (DSLs) and security tools. Additionally, it presents Hackersh, a shell designed for security tasks integration with Pythonect, featuring built-in security components and multi-threading capabilities. The content emphasizes ease of use, flexibility, and the potential for creating efficient workflows within the realms of programming and cybersecurity.
Writing Continuous Applications with Structured Streaming Python APIs in Apac...
Writing Continuous Applications with Structured Streaming Python APIs in Apac...Databricks The document discusses the use of Apache Spark for building continuous streaming applications using structured streaming in PySpark, highlighting its benefits, challenges, and integration capabilities. It explains how Spark unifies various data processing needs and provides a detailed overview of constructing a streaming application with example code snippets. The session also covers topics such as data ingestion from sources like Kafka, processing data transformations, and writing results to output sinks while ensuring fault tolerance and efficient querying.
Python vs JLizard.... a python logging experience
Python vs JLizard.... a python logging experiencePython Ireland The document discusses log management as a service, emphasizing the exponential growth of log data and its challenges for organizations. It compares Python and Jlizard in the context of log management solutions, highlighting features of the Logentries agent and its capabilities. The need for effective logging is underscored by compliance requirements and the consequences of inadequate log management.
Build your own discovery index of scholary e-resources
Build your own discovery index of scholary e-resourcesMartin Czygan The document outlines a workshop presented at the 40th ELAG conference on building a custom index for scholarly e-resources using a virtual machine setup. The presentation details a step-by-step approach to create an aggregated index using Vufind 3, focusing on batch processing, data normalization, and licensing considerations. Participants are guided through coding tasks to process various data sources, culminating in the indexing of data into Solr for use in research libraries.
Getting The Best Performance With PySpark
Getting The Best Performance With PySparkSpark Summit This document provides an overview of techniques for getting the best performance with PySpark. It discusses RDD reuse through caching and checkpointing. It explains how to avoid issues with groupByKey by using reduceByKey or aggregateByKey instead. Spark SQL and DataFrames are presented as alternatives that can improve performance by avoiding serialization costs for Python users. The document also covers mixing Python and Scala code by exposing Scala functions to be callable from Python.
Python with data Sciences
Python with data SciencesKrishna Mohan Mishra The document provides an overview of Python, highlighting its features, types, and applications in data science. It covers Python's object-oriented nature, data structures like lists, sets, tuples, and dictionaries, along with functions, file handling, exception handling, and regular expressions. Additionally, it describes web scraping techniques using Python's package manager and libraries such as urllib.request and BeautifulSoup.
Making the big data ecosystem work together with python apache arrow, spark,...
Making the big data ecosystem work together with python apache arrow, spark,...Holden Karau The document discusses the current state of the big data ecosystem and how tools interact across different programming languages and environments. It focuses on Python tools like Dask, Spark, Beam, and Kafka and how they can communicate with systems built on the Java Virtual Machine like Spark. It notes that there is often unnecessary data copying between systems due to differences in languages and environments. Emerging technologies like Apache Arrow aim to allow more direct data sharing to improve performance. The document advocates for continued work to better integrate Python tools into the larger big data ecosystem.
Making the big data ecosystem work together with Python & Apache Arrow, Apach...
Making the big data ecosystem work together with Python & Apache Arrow, Apach...Holden Karau The document details a presentation by Holden Karau about integrating big data tools using Python and various technologies like Apache Arrow, Spark, Beam, and Dask. It discusses the challenges and current state of PySpark, including integration hurdles with non-JVM tools, serialization issues, and the future potential of multi-language pipelines. The importance of efficient data processing and the need for improved collaboration within the big data ecosystem are emphasized throughout the talk.
A fast introduction to PySpark with a quick look at Arrow based UDFs
A fast introduction to PySpark with a quick look at Arrow based UDFsHolden Karau The document serves as an introductory guide to Apache Spark, highlighting its distributed computing capabilities, setup instructions, and core abstractions like RDDs and DataFrames. It covers topics such as data processing, transformations, actions, and the performance advantages of Spark over traditional systems like Hadoop. Additionally, it discusses new features in Spark 2.3, including vectorized UDFs, and touches on future developments in the Spark ecosystem.
Log Analysis Engine with Integration of Hadoop and Spark
Log Analysis Engine with Integration of Hadoop and SparkIRJET Journal The document proposes a log analysis system that integrates Hadoop, Spark, Hive, and Shark to analyze large volumes of log data efficiently. The system would extract, transform, and load log data into Hadoop and Hive for batch processing using MapReduce. It would also use Spark and Shark for faster interactive querying and iterative algorithms. This combination of tools is meant to provide a scalable, high-performance platform for log analysis that can handle both large-scale batch processing and real-time queries.
Writing Continuous Applications with Structured Streaming in PySpark
Writing Continuous Applications with Structured Streaming in PySparkDatabricks The document discusses the use of Apache Spark for building continuous applications with structured streaming, emphasizing the challenges of stream processing and advantages of using Spark. It covers various components such as data integration, transformation, and real-time analytics, showcasing the power of structured streaming in dealing with complex data. The talk includes a demonstration of continuous applications and resources for further exploration of Spark's capabilities.
Rapid Prototyping in PySpark Streaming: The Thermodynamics of Docker Containe...
Rapid Prototyping in PySpark Streaming: The Thermodynamics of Docker Containe...Richard Seymour The document discusses the use of PySpark Streaming and Docker for rapid prototyping, highlighting their capabilities in managing resources and processing data streams. It explains concepts like Resilient Distributed Datasets (RDDs) in Spark and offers methods for processing data in microbatches. Additionally, it delves into the thermodynamics of Docker containers and the challenges of using PySpark for specific tasks.
Python Powered Data Science at Pivotal (PyData 2013)
Python Powered Data Science at Pivotal (PyData 2013)Srivatsan Ramanujam The document discusses how Pivotal uses the Python data science stack in real engagements. It provides an overview of Pivotal's data science toolkit, including PL/Python for running Python code directly in the database and MADlib for parallel in-database machine learning. The document then demonstrates how Pivotal works with large enterprise customers who have large amounts of structured and unstructured data and want to perform interactive data analysis and become more data-driven.
Ad
Recently uploaded (20)
FME as an Orchestration Tool - Peak of Data & AI 2025
FME as an Orchestration Tool - Peak of Data & AI 2025Safe Software Processing huge amounts of data through FME can have performance consequences, but as an orchestration tool, FME is brilliant! We'll take a look at the principles of data gravity, best practices, pros, cons, tips and tricks. And of course all spiced up with relevant examples!
Transmission Media. (Computer Networks)
Transmission Media. (Computer Networks)S Pranav (Deepu) INTRODUCTION:TRANSMISSION MEDIA
• A transmission media in data communication is a physical path between the sender and
the receiver and it is the channel through which data can be sent from one location to
another. Data can be represented through signals by computers and other sorts of
telecommunication devices. These are transmitted from one device to another in the
form of electromagnetic signals. These Electromagnetic signals can move from one
sender to another receiver through a vacuum, air, or other transmission media.
Electromagnetic energy mainly includes radio waves, visible light, UV light, and gamma
ra
Open Source Software Development Methods
Open Source Software Development MethodsVICTOR MAESTRE RAMIREZ Open Source Software Development Methods
MOVIE RECOMMENDATION SYSTEM, UDUMULA GOPI REDDY, Y24MC13085.pptx
MOVIE RECOMMENDATION SYSTEM, UDUMULA GOPI REDDY, Y24MC13085.pptxMaharshi Mallela Movie recommendation system is a software application or algorithm designed to suggest movies to users based on their preferences, viewing history, or other relevant factors. The primary goal of such a system is to enhance user experience by providing personalized and relevant movie suggestions.
GDG Douglas - Google AI Agents: Your Next Intern?
GDG Douglas - Google AI Agents: Your Next Intern?felipeceotto Presentation done at the GDG Douglas event for June 2025.
A first look at Google's new Agent Development Kit.
Agent Development Kit is a new open-source framework from Google designed to simplify the full stack end-to-end development of agents and multi-agent systems.
Code and No-Code Journeys: The Coverage Overlook
Code and No-Code Journeys: The Coverage OverlookApplitools Explore practical ways to expand visual and functional UI coverage without deep coding or heavy maintenance in this session. Session recording and more info at applitools.com
Looking for a BIRT Report Alternative Here’s Why Helical Insight Stands Out.pdf
Looking for a BIRT Report Alternative Here’s Why Helical Insight Stands Out.pdfVarsha Nayak The search for an Alternative to BIRT Reports has intensified as companies face challenges with BIRT's steep learning curve, limited visualization capabilities, and complex deployment requirements. Organizations need reporting solutions that offer intuitive design interfaces, comprehensive analytics features, and seamless integration capabilities – all while maintaining the reliability and performance that enterprise environments demand.
Smart Financial Solutions: Money Lender Software, Daily Pigmy & Personal Loan...
Smart Financial Solutions: Money Lender Software, Daily Pigmy & Personal Loan...Intelli grow Explore innovative tools tailored for modern finance with our Money Lender Software Development, efficient Daily Pigmy Collection Software, and streamlined Personal Loan Software. This presentation showcases how these solutions simplify loan management, boost collection efficiency, and enhance customer experience for NBFCs, microfinance firms, and individual lenders.
Artificial Intelligence Applications Across Industries
Artificial Intelligence Applications Across IndustriesSandeepKS52 Artificial Intelligence is a rapidly growing field that influences many aspects of modern life, including transportation, healthcare, and finance. Understanding the basics of AI provides insight into how machines can learn and make decisions, which is essential for grasping its applications in various industries. In the automotive sector, AI enhances vehicle safety and efficiency through advanced technologies like self-driving systems and predictive maintenance. Similarly, in healthcare, AI plays a crucial role in diagnosing diseases and personalizing treatment plans, while in financial services, it helps in fraud detection and risk management. By exploring these themes, a clearer picture of AI's transformative impact on society emerges, highlighting both its potential benefits and challenges.
How Insurance Policy Management Software Streamlines Operations
How Insurance Policy Management Software Streamlines OperationsInsurance Tech Services Insurance policy management software transforms complex, manual insurance operations into streamlined, efficient digital workflows, enhancing productivity, accuracy, customer service, and profitability for insurers. Visit https://www.damcogroup.com/insurance/policy-management-software for more details!
Agentic Techniques in Retrieval-Augmented Generation with Azure AI Search
Agentic Techniques in Retrieval-Augmented Generation with Azure AI SearchMaxim Salnikov Discover how Agentic Retrieval in Azure AI Search takes Retrieval-Augmented Generation (RAG) to the next level by intelligently breaking down complex queries, leveraging full conversation history, and executing parallel searches through a new LLM-powered query planner. This session introduces a cutting-edge approach that delivers significantly more accurate, relevant, and grounded answers—unlocking new capabilities for building smarter, more responsive generative AI applications.
Traditional Retrieval-Augmented Generation (RAG) pipelines work well for simple queries—but when users ask complex, multi-part questions or refer to previous conversation history, they often fall short. That’s where Agentic Retrieval comes in: a game-changing advancement in Azure AI Search that brings LLM-powered reasoning directly into the retrieval layer.
This session unveils how agentic techniques elevate your RAG-based applications by introducing intelligent query planning, subquery decomposition, parallel execution, and result merging—all orchestrated by a new Knowledge Agent. You’ll learn how this approach significantly boosts relevance, groundedness, and answer quality, especially for sophisticated enterprise use cases.
Key takeaways:
- Understand the evolution from keyword and vector search to agentic query orchestration
- See how full conversation context improves retrieval accuracy
- Explore measurable improvements in answer relevance and completeness (up to 40% gains!)
- Get hands-on guidance on integrating Agentic Retrieval with Azure AI Foundry and SDKs
- Discover how to build scalable, AI-first applications powered by this new paradigm
Whether you're building intelligent copilots, enterprise Q&A bots, or AI-driven search solutions, this session will equip you with the tools and patterns to push beyond traditional RAG.
IBM Rational Unified Process For Software Engineering - Introduction
IBM Rational Unified Process For Software Engineering - IntroductionGaurav Sharma IBM Rational Unified Process For Software Engineering
Advanced Token Development - Decentralized Innovation
Advanced Token Development - Decentralized Innovationarohisinghas720 The world of blockchain is evolving at a fast pace, and at the heart of this transformation lies advanced token development. No longer limited to simple digital assets, today’s tokens are programmable, dynamic, and play a crucial role in driving decentralized applications across finance, governance, gaming, and beyond.
Who will create the languages of the future?
Who will create the languages of the future?Jordi Cabot Will future languages be created by language engineers?
Can you "vibe" a DSL?
In this talk, we will explore the changing landscape of language engineering and discuss how Artificial Intelligence and low-code/no-code techniques can play a role in this future by helping in the definition, use, execution, and testing of new languages. Even empowering non-tech users to create their own language infrastructure. Maybe without them even realizing.
Migrating to Azure Cosmos DB the Right Way
Migrating to Azure Cosmos DB the Right WayAlexander (Alex) Komyagin In this session we cover the benefits of a migration to Cosmos DB, migration paths, common pain points and best practices. We share our firsthand experiences and customer stories. Adiom is the trusted partner for migration solutions that enable seamless online database migrations from MongoDB to Cosmos DB vCore, and DynamoDB to Cosmos DB for NoSQL.
Software Engineering Process, Notation & Tools Introduction - Part 3
Software Engineering Process, Notation & Tools Introduction - Part 3Gaurav Sharma Software Engineering Process, Notation & Tools Introduction
Women in Tech: Marketo Engage User Group - June 2025 - AJO with AWS
Women in Tech: Marketo Engage User Group - June 2025 - AJO with AWSBradBedford3 Creating meaningful, real-time engagement across channels is essential to building lasting business relationships. Discover how AWS, in collaboration with Deloitte, set up one of Adobe's first instances of Journey Optimizer B2B Edition to revolutionize customer journeys for B2B audiences.
This session will share the use cases the AWS team has the implemented leveraging Adobe's Journey Optimizer B2B alongside Marketo Engage and Real-Time CDP B2B to deliver unified, personalized experiences and drive impactful engagement.
They will discuss how they are positioning AJO B2B in their marketing strategy and how AWS is imagining AJO B2B and Marketo will continue to work together in the future.
Whether you’re looking to enhance customer journeys or scale your B2B marketing efforts, you’ll leave with a clear view of what can be achieved to help transform your own approach.
Speakers:
Britney Young Senior Technical Product Manager, AWS
Erine de Leeuw Technical Product Manager, AWS
Plooma is a writing platform to plan, write, and shape books your way
Plooma is a writing platform to plan, write, and shape books your wayPlooma Plooma is your all in one writing companion, designed to support authors at every twist and turn of the book creation journey. Whether you're sketching out your story's blueprint, breathing life into characters, or crafting chapters, Plooma provides a seamless space to organize all your ideas and materials without the overwhelm. Its intuitive interface makes building rich narratives and immersive worlds feel effortless.
Packed with powerful story and character organization tools, Plooma lets you track character development and manage world building details with ease. When it’s time to write, the distraction-free mode offers a clean, minimal environment to help you dive deep and write consistently. Plus, built-in editing tools catch grammar slips and style quirks in real-time, polishing your story so you don’t have to juggle multiple apps.
What really sets Plooma apart is its smart AI assistant - analyzing chapters for continuity, helping you generate character portraits, and flagging inconsistencies to keep your story tight and cohesive. This clever support saves you time and builds confidence, especially during those complex, detail packed projects.
Getting started is simple: outline your story’s structure and key characters with Plooma’s user-friendly planning tools, then write your chapters in the focused editor, using analytics to shape your words. Throughout your journey, Plooma’s AI offers helpful feedback and suggestions, guiding you toward a polished, well-crafted book ready to share with the world.
With Plooma by your side, you get a powerful toolkit that simplifies the creative process, boosts your productivity, and elevates your writing - making the path from idea to finished book smoother, more fun, and totally doable.
Get Started here: https://www.plooma.ink/
Ad
Commit2015 kharchenko - python generators - ext
- 1. Maxym Kharchenko & m@ team Writing efficient Python code with pipelines and generators
- 2. Agenda
- 3. Python is all about streaming (a.k.a. iteration)
- 4. Streaming in Python # Lists db_list = ['db1', 'db2', 'db3'] for db in db_list: print db # Dictionaries host_cpu = {'avg': 2.34, 'p99': 98.78, 'min': 0.01} for stat in host_cpu: print "%s = %s" % (stat, host_cpu[stat]) # Files, strings file = open("/etc/oratab") for line in file: for word in line.split(" "): print word # Whatever is coming out of get_things() for thing in get_things(): print thing
- 5. Quick example: Reading records from a file def print_databases(): """ Read /etc/oratab and print database names """ file = open("/etc/oratab", 'r') while True: line = file.readline() # Get next line # Check for empty lines if len(line) == 0 and not line.endswith('n'): break # Parsing oratab line into components db_line = line.strip() db_info_array = db_line.split(':') db_name = db_info_array[0] print db_name file.close()
- 6. Reading records from a file: with “streaming” def print_databases(): """ Read /etc/oratab and print database names """ with open("/etc/oratab") as file: for line in file: print line.strip().split(':')[0]
- 8. Ok, let’s do something useful with streaming We have a bunch of ORACLE listener logs Let’s parse them for “client IPs” 21-AUG-2015 21:29:56 * (CONNECT_DATA=(SID=orcl)(CID=(PROGRAM=)(HOST=_ _jdbc__)(USER=))) * (ADDRESS=(PROTOCOL=tcp)(HOST=10.107.137.91)(PO RT=43105)) * establish * orcl * 0 And find where the clients are coming from
- 9. First attempt at listener log parser def parse_listener_log(log_name): """ Parse listener log and return clients """ client_hosts = [] with open(log_name) as listener_log: for line in listener_log: host_match = <regex magic> if host_match: host = <regex magic> client_hosts.append(host) return client_hosts
- 10. First attempt at listener log parser def parse_listener_log(log_name): """ Parse listener log and return clients """ client_hosts = [] with open(log_name) as listener_log: for line in listener_log: host_match = <regex magic> if host_match: host = <regex magic> client_hosts.append(host) return client_hosts MEMORY WASTE! Stores all results until return BLOCKING! Does NOT return until the entire log is processed
- 11. Generators for efficiency def parse_listener_log(log_name): """ Parse listener log and return clients """ client_hosts = [] with open(log_name) as listener_log: for line in listener_log: host_match = <regex magic> if host_match: host = <regex magic> client_hosts.append(host) return client_hosts
- 12. Generators for efficiency def parse_listener_log(log_name): """ Parse listener log and return clients """ client_hosts = [] with open(log_name) as listener_log: for line in listener_log: host_match = <regex magic> if host_match: host = <regex magic> client_hosts.append(host) return client_hosts
- 13. Generators for efficiency def parse_listener_log(log_name): """ Parse listener log and return clients """ with open(log_name) as listener_log: for line in listener_log: host_match = <regex magic> if host_match: host = <regex magic> yield hostAdd this !
- 14. Generators in a nutshell def test_generator(): """ Test generator """ print "ENTER()" for i in range(5): print "yield i=%d" % i yield i print "EXIT()" # MAIN for i in test_generator(): print "RET=%d" % i ENTER() yield i=0 RET=0 yield i=1 RET=1 yield i=2 RET=2 yield i=3 RET=3 yield i=4 RET=4 EXIT()
- 15. Nongenerators in a nutshell def test_nongenerator(): """ Test no generator """ result = [] print "ENTER()" for i in range(5): print "add i=%d" % i result.append(i) print "EXIT()" return result # MAIN for i in test_nongenerator(): print "RET=%d" % i ENTER() add i=0 add i=1 add i=2 add i=3 add i=4 EXIT() RET=0 RET=1 RET=2 RET=3 RET=4
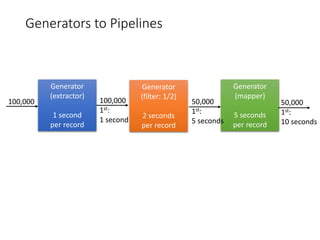
- 16. Generators to Pipelines Generator (extractor) 1 second per record 100,000 1st: 1 second 100,000 Generator (filter: 1/2) 2 seconds per record Generator (mapper) 5 seconds per record 50,000 1st: 5 seconds 50,000 1st: 10 seconds
- 17. Generator pipelining in Python file_handles = open_files(LISTENER_LOGS) log_lines = extract_lines(file_handles) client_hosts = extract_client_ips(log_lines) for host in client_hosts: print host Open files Extract lines Extract IPs File names File handles File lines Client IPs
- 18. Generators for simplicity def open_files(file_names): """ GENERATOR: file name -> file handle """ for file in file_names: yield open(file)
- 19. Generators for simplicity def extract_lines(file_handles): """ GENERATOR: File handles -> file lines Similar to UNIX: cat file1, file2, … """ for file in file_handles: for line in file: yield line
- 20. Generators for simplicity def extract_client_ips(lines): """ GENERATOR: Extract client host """ host_regex = re.compile('(HOST=(S+))(PORT=') for line in lines: line_match = host_regex.search(line) if line_match: yield line_match.groups(0)[0]
- 21. Developer’s bliss: simple input, simple output, trivial function body
- 22. Then, pipeline the results
- 23. But, really … Open files Extract lines IP -> host name File names File handles File lines Client hosts Locate files Filter db=orcl Filter proto= TCP db=orcl lines db=orcl lines db=orcl & prot=TCP Extract clients Client IPs Client hosts Db writer Client hosts Text writer
- 24. Why generators ? Simple functions that are easy to write and understand Non blocking operations: TOTAL execution time: faster FIRST RESULTS: much faster Efficient use of memory Potential for parallelization and ASYNC processing
- 25. Special thanks to David Beazley … For this: http://www.dabeaz.com/generators-uk/GeneratorsUK.pdf
- 26. Thank you!