












database application using SQL DML statements: Insert, Select, Update, Delete with operators, functions, and set operator.
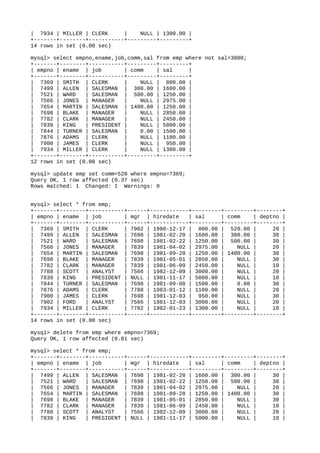
- 1. Practical No: 3 Problem Statement: Design at least 10 SQL queries for suitable database application using SQL DML statements: Insert, Select, Update, Delete with operators, functions, and set operator. mysql> use prac3; Database changed mysql> DROP TABLE IF EXISTS emp; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> mysql> CREATE TABLE emp ( -> empno decimal(4,0) NOT NULL, -> ename varchar(10) default NULL, -> job varchar(9) default NULL, -> mgr decimal(4,0) default NULL, -> hiredate date default NULL, -> sal decimal(7,2) default NULL, -> comm decimal(7,2) default NULL, -> deptno decimal(2,0) default NULL -> ); Query OK, 0 rows affected (0.06 sec) mysql> mysql> DROP TABLE IF EXISTS dept; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> mysql> CREATE TABLE dept ( -> deptno decimal(2,0) default NULL, -> dname varchar(14) default NULL, -> loc varchar(13) default NULL -> ); Query OK, 0 rows affected (0.01 sec) mysql> mysql> INSERT INTO emp VALUES ('7369','SMITH','CLERK','7902','1980-12- 17','800.00',NULL,'20'); Query OK, 1 row affected (0.02 sec) mysql> INSERT INTO emp VALUES ('7499','ALLEN','SALESMAN','7698','1981-02- 20','1600.00','300.00','30'); Query OK, 1 row affected (0.04 sec) mysql> INSERT INTO emp VALUES ('7521','WARD','SALESMAN','7698','1981-02- 22','1250.00','500.00','30'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO emp VALUES ('7566','JONES','MANAGER','7839','1981-04- 02','2975.00',NULL,'20'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO emp VALUES ('7654','MARTIN','SALESMAN','7698','1981-09- 28','1250.00','1400.00','30'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO emp VALUES ('7698','BLAKE','MANAGER','7839','1981-05- 01','2850.00',NULL,'30'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO emp VALUES ('7782','CLARK','MANAGER','7839','1981-06- 09','2450.00',NULL,'10'); Query OK, 1 row affected (0.01 sec)
- 2. mysql> INSERT INTO emp VALUES ('7788','SCOTT','ANALYST','7566','1982-12- 09','3000.00',NULL,'20'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO emp VALUES ('7839','KING','PRESIDENT',NULL,'1981-11- 17','5000.00',NULL,'10'); Query OK, 1 row affected (0.00 sec) mysql> select ename, sal frommysql> select ename, sal from emp where sal between 1000 and 5000; +--------+---------+ | ename | sal | +--------+---------+ | ALLEN | 1600.00 | | WARD | 1250.00 | | JONES | 2975.00 | | MARTIN | 1250.00 | | BLAKE | 2850.00 | | CLARK | 2450.00 | | SCOTT | 3000.00 | | KING | 5000.00 | | TURNER | 1500.00 | | ADAMS | 1100.00 | | FORD | 3000.00 | | MILLER | 1300.00 | +--------+---------+ 12 rows in set (0.00 sec) emp where sal between 1000 and 5000; +--------+---------+ | ename | sal | +--------+---------+ | ALLEN | 1600.00 | | WARD | 1250.00 | | JONES | 2975.00 | | MARTIN | 1250.00 | | BLAKE | 2850.00 | | CLARK | 2450.00 | | SCOTT | 3000.00 | | KING | 5000.00 | | TURNER | 1500.00 | | ADAMS | 1100.00 | | FORD | 3000.00 | | MILLER | 1300.00 | +--------+---------+ 12 rows in set (0.00 sec) mysql> INSERT INTO emp VALUES ('7844','TURNER','SALESMAN','7698','1981-09- 08','1500.00','0.00','30'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO emp VALUES ('7876','ADAMS','CLERK','7788','1983-01- 12','1100.00',NULL,'20'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO emp VALUES ('7900','JAMES','CLERK','7698','1981-12- 03','950.00',NULL,'30'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO emp VALUES ('7902','FORD','ANALYST','7566','1981-12- 03','3000.00',NULL,'20'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO emp VALUES ('7934','MILLER','CLERK','7782','1982-01- 23','1300.00',NULL,'10');
- 3. Query OK, 1 row affected (0.01 sec) mysql> mysql> INSERT INTO dept VALUES ('10','ACCOUNTING','NEW YORK'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO dept VALUES ('20','RESEARCH','DALLAS'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO dept VALUES ('30','SALES','CHICAGO'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO dept VALUES ('40','OPERATIONS','BOSTON'); Query OK, 1 row affected (0.00 sec) mysql> desc emp; +----------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------+--------------+------+-----+---------+-------+ | empno | decimal(4,0) | NO | | NULL | | | ename | varchar(10) | YES | | NULL | | | job | varchar(9) | YES | | NULL | | | mgr | decimal(4,0) | YES | | NULL | | | hiredate | date | YES | | NULL | | | sal | decimal(7,2) | YES | | NULL | | | comm | decimal(7,2) | YES | | NULL | | | deptno | decimal(2,0) | YES | | NULL | | +----------+--------------+------+-----+---------+-------+ 8 rows in set (0.00 sec) mysql> select * from emp; +-------+--------+-----------+------+------------+---------+---------+--------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +-------+--------+-----------+------+------------+---------+---------+--------+ | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 1982-12-09 | 3000.00 | NULL | 20 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 | | 7876 | ADAMS | CLERK | 7788 | 1983-01-12 | 1100.00 | NULL | 20 | | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | +-------+--------+-----------+------+------------+---------+---------+--------+ 14 rows in set (0.00 sec) mysql> select distinct(job) from emp; +-----------+ | job | +-----------+mysql> select ename, sal from emp where sal between 1000 and 5000; +--------+---------+ | ename | sal | +--------+---------+ | ALLEN | 1600.00 | | WARD | 1250.00 | | JONES | 2975.00 | | MARTIN | 1250.00 | | BLAKE | 2850.00 | | CLARK | 2450.00 |
- 4. | SCOTT | 3000.00 | | KING | 5000.00 | | TURNER | 1500.00 | | ADAMS | 1100.00 | | FORD | 3000.00 | | MILLER | 1300.00 | +--------+---------+ 12 rows in set (0.00 sec) | CLERK | | SALESMAN | | MANAGER | | ANALYST | | PRESIDENT | +-----------+ 5 rows in set (0.00 sec) mysql> select empno,ename,sal from emp where deptno=20 ; +-------+-------+---------+ | empno | ename | sal | +-------+-------+---------+ | 7369 | SMITH | 800.00 | | 7566 | JONES | 2975.00 | | 7788 | SCOTT | 3000.00 | | 7876 | ADAMS | 1100.00 | | 7902 | FORD | 3000.00 | +-------+-------+---------+ 5 rows in set (0.00 sec) mysql> select empno,ename,sal from emp where deptno like 20 ; +-------+-------+---------+ | empno | ename | sal | +-------+-------+---------+ | 7369 | SMITH | 800.00 | | 7566 | JONES | 2975.00 | | 7788 | SCOTT | 3000.00 | | 7876 | ADAMS | 1100.00 | | 7902 | FORD | 3000.00 | +-------+-------+---------+ 5 rows in set (0.00 sec) mysql> select empno,ename,sal from emp where ename like 'a%' ; +-------+-------+---------+ | empno | ename | sal | +-------+-------+---------+ | 7499 | ALLEN | 1600.00 | | 7876 | ADAMS | 1100.00 | +-------+-------+---------+ 2 rows in set (0.00 sec) mysql> select * from emp where ename like '__N%'; +-------+-------+-----------+------+------------+---------+------+--------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +-------+-------+-----------+------+------------+---------+------+--------+ | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | +-------+-------+-----------+------+------------+---------+------+--------+ 2 rows in set (0.00 sec) mysql> select deptno as DEPTNO, MAX(sal) as "MAXIMUM SALARY" from emp group by (deptno); +--------+----------------+ | DEPTNO | MAXIMUM SALARY |
- 5. +--------+----------------+ | 10 | 5000.00 | | 20 | 3000.00 | | 30 | 2850.00 | +--------+----------------+ 3 rows in set (0.00 sec) mysql> select count(sal) from emp where sal=3000; +------------+ | count(sal) | +------------+ | 2 | +------------+ 1 row in set (0.00 sec) mysql> select MAX(sal) from emp; +----------+ | MAX(sal) | +----------+ | 5000.00 | +----------+ 1 row in set (0.00 sec) mysql> select MIN(sal) from emp; +----------+ | MIN(sal) | +----------+ | 800.00 | +----------+ 1 row in set (0.00 sec) mysql> select MIN(sal) least, MAX(sal) max from emp; +--------+---------+ | least | max | +--------+---------+ | 800.00 | 5000.00 | +--------+---------+ 1 row in set (0.00 sec) mysql> select deptno , MIN(sal) "MINIMUM SALARY" from emp group by (deptno); +--------+----------------+ | deptno | MINIMUM SALARY | +--------+----------------+ | 10 | 1300.00 | | 20 | 800.00 | | 30 | 950.00 | +--------+----------------+ 3 rows in set (0.00 sec) mysql> select SUM(sal) totalsal from emp; +----------+ | totalsal | +----------+ | 29025.00 | +----------+ 1 row in set (0.00 sec) mysql> select deptno , SUM(sal) "sal sum" from emp group by (deptno); +--------+----------+ | deptno | sal sum | +--------+----------+ | 10 | 8750.00mysql> select * from t1; +-----+-------+
- 6. | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t2; +-----+-------+ | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) | | 20 | 10875.00 | | 30 | 9400.00 | +--------+----------+ 3 rows in set (0.00 sec) mysql> select deptno , avg(sal) "sal avg" from emp group by (deptno); +--------+-------------+ | deptno | sal avg | +--------+-------------+ | 10 | 2916.666667 | | 20 | 2175.000000 | | 30 | 1566.666667 | +--------+-------------+ 3 rows in set (0.00 sec) mysql> select * from emp where job in('CLERK','PRESIDENT'); +-------+--------+-----------+------+------------+---------+------+--------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +-------+--------+-----------+------+------------+---------+------+--------+ | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | | 7876 | ADAMS | CLERK | 7788 | 1983-01-12 | 1100.00 | NULL | 20 | | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | +-------+--------+-----------+------+------------+---------+------+--------+ 5 rows in set (0.00 sec) mysql> select * from emp where job not in('CLERK','PRESIDENT'); +-------+--------+----------+------+------------+---------+---------+--------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +-------+--------+----------+------+------------+---------+---------+--------+ | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 1982-12-09 | 3000.00 | NULL | 20 | | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 | | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | +-------+--------+----------+------+------------+---------+---------+--------+
- 7. 9 rows in set (0.00 sec) mysql> select * fromysql> select * from t1; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t2; +-----+-------+ | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) m emp order by comm; +-------+--------+-----------+------+------------+---------+---------+--------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +-------+--------+-----------+------+------------+---------+---------+--------+ | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | | 7876 | ADAMS | CLERK | 7788 | 1983-01-12 | 1100.00 | NULL | 20 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 1982-12-09 | 3000.00 | NULL | 20 | | 7782 | CLARK | mysql> select * from t1; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t2; +-----+-------+ | Rno | Name | +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t2;
- 8. +-----+-------+ | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | +-------+--------+- mysql> select * from t1; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | mysql> select * from t1; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t2; +-----+-------+ | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) | 5 | pati | +-----+-------+
- 9. 5 rows in set (0.00 sec) mysql> select * from t2; +-----+-------+mysql> select * from t1; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t2; +-----+-------+ | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) ----------+------+------------+---------+---------+--------+ 14 rows in set (0.00 sec) mysql> select * from emp where comm <> 'NULL'; +-------+--------+----------+------+------------+---------+---------+--------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +-------+--------+----------+------+------------+---------+---------+--------+ | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | +-------+--------+----------+------+------------+---------+---------+--------+ 3 rows in set, 1 warning (0.00 sec) mysql> select * from emp where comm <> 'NULL' order by comm desc; +-------+--------+----------+------+------------+---------+---------+--------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +-------+--------+----------+------+------------+---------+---------+--------+ | 7654 | MARTIN | mysql> select * from t1; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec)
- 10. mysql> select * from t2; +-----+-------+ | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00mysql> select * from t1; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t2; +-----+-------+ | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) sec) SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | +-------+--------+----------+------+------------+---------+---------+--------+ 3 rows in set, 1 warning (0.00 sec) mysql> select ename, sal from emp where sal between 1000 and 5000; +--------+---------+mysql> select ename, sal from emp where sal between 1000 and 5000; +--------+---------+ | ename | sal | +--------+---------+ | ALLEN | 1600.00 | | WARD | 1250.00 mysql> select * from t1; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t2; +-----+-------+
- 11. | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) | | JONES | 2975.00 | | MARTIN | 1250.00 mysql> select * from t1; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t2; +-----+-------+ | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | mysql> select * from t1; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t2; +-----+-------+ | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) | | BLAKE | 2850.00 | | CLARK | 2450.00 | | SCOTT | 3000.00 | | KING | 5000.00 |
- 12. | TURNER | 1500.00 | | ADAMS | 1100.00 | | FORD | 3000.00 | | MILLER | 1300.00 | +--------+---------+ 12 rows in set (0.00 sec) | ename | sal | +--------+---------+ | ALLEN | 1600.00 | | WARD | 1250.00 | | JONES | 2975.00 | | MARTIN | 1250.00 | | BLAKE | 2850.00 | | CLARK | 2450.00 | | SCOTT | 3000.00 | | KING | 5000.00 | | TURNER | 1500.00 | | ADAMS | 1100.00 | | FORD | 3000.00 | | MILLER | 1300.00 | +--------+---------+ 12 rows in set (0.00 sec) mysql> select empno,ename,job,comm,sal from emp where sal>=1000 and sal<=3000; +-------+--------+----------+---------+---------+ | empno | ename | job | comm | sal | +-------+--------+----------+---------+---------+ | 7499 | ALLEN | SALESMAN | 300.00 | 1600.00 | | 7521 | WARD | SALESMAN | 500.00 | 1250.00 | | 7566 | JONES | MANAGER | NULL | 2975.00 | | 7654 | MARTIN | SALESMAN | 1400.00 | 1250.00 | | 7698 | BLAKE | MANAGER | NULL | 2850.00 | | 7782 | CLARK | MANAGER | NULL | 2450.00 | | 7788 | SCOTT | ANALYST | NULL | 3000.00 | | 7844 | TURNER | SALESMAN | 0.00 | 1500.00 | | 7876 | ADAMS | CLERK | NULL | 1100.00 | | 7902 | FORD | ANALYST | NULL | 3000.00 | | 7934 | MILLER | CLERK | NULL | 1300.00 | +-------+--------+----------+---------+---------+ 11 rows in set (0.00 sec) mysql> select empno,ename,job,comm,sal from emp where sal>=1000 or sal<=3000; +-------+--------+-----------+---------+---------+ | empno | ename | job | comm | sal | +-------+--------+-----------+---------+---------+ | 7369 | SMITH | CLERK | NULL | 800.00 | | 7499 | ALLEN | SALESMAN | 300.00 | 1600.00 | | 7521 | WARD | SALESMAN | 500.00 | 1250.00 | | 7566 | JONES | MANAGER | NULL | 2975.00 | | 7654 | MARTIN | SALESMAN | 1400.00 | 1250.00 | | 7698 | BLAKE | MANAGER | NULL | 2850.00 | | 7782 | CLARK | MANAGER | NULL | 2450.00 | | 7788 | SCOTT | ANALYST | NULL | 3000.00 | | 7839 | KING | PRESIDENT | NULL | 5000.00 | | 7844 | TURNER | SALESMAN | 0.00 | 1500.00 | | 7876 | ADAMS | CLERK | NULL | 1100.00 | | 7900 | JAMES | CLERK | NULL | 950.00 | | 7902 | FORD | ANALYST | NULL | 3000.00 |
- 13. | 7934 | MILLER | CLERK | NULL | 1300.00 | +-------+--------+-----------+---------+---------+ 14 rows in set (0.00 sec) mysql> select empno,ename,job,comm,sal from emp where not sal=3000; +-------+--------+-----------+---------+---------+ | empno | ename | job | comm | sal | +-------+--------+-----------+---------+---------+ | 7369 | SMITH | CLERK | NULL | 800.00 | | 7499 | ALLEN | SALESMAN | 300.00 | 1600.00 | | 7521 | WARD | SALESMAN | 500.00 | 1250.00 | | 7566 | JONES | MANAGER | NULL | 2975.00 | | 7654 | MARTIN | SALESMAN | 1400.00 | 1250.00 | | 7698 | BLAKE | MANAGER | NULL | 2850.00 | | 7782 | CLARK | MANAGER | NULL | 2450.00 | | 7839 | KING | PRESIDENT | NULL | 5000.00 | | 7844 | TURNER | SALESMAN | 0.00 | 1500.00 | | 7876 | ADAMS | CLERK | NULL | 1100.00 | | 7900 | JAMES | CLERK | NULL | 950.00 | | 7934 | MILLER | CLERK | NULL | 1300.00 | +-------+--------+-----------+---------+---------+ 12 rows in set (0.00 sec) mysql> update emp set comm=520 where empno=7369; Query OK, 1 row affected (0.37 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from emp; +-------+--------+-----------+------+------------+---------+---------+--------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +-------+--------+-----------+------+------------+---------+---------+--------+ | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | 520.00 | 20 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 1982-12-09 | 3000.00 | NULL | 20 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 | | 7876 | ADAMS | CLERK | 7788 | 1983-01-12 | 1100.00 | NULL | 20 | | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | +-------+--------+-----------+------+------------+---------+---------+--------+ 14 rows in set (0.00 sec) mysql> delete from emp where empno=7369; Query OK, 1 row affected (0.01 sec) mysql> select * from emp; +-------+--------+-----------+------+------------+---------+---------+--------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +-------+--------+-----------+------+------------+---------+---------+--------+ | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 1982-12-09 | 3000.00 | NULL | 20 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
- 14. | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 | | 7876 | ADAMS | CLERK | 7788 | 1983-01-12 | 1100.00 | NULL | 20 | | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | +-------+--------+-----------+------+------------+---------+---------+--------+ 13 rows in set (0.00 sec) ________________________________________________________________________________ _______ mysql> select * from t1; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t2; +-----+-------+ | Rno | Name | +-----+-------+ | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 5 rows in set (0.00 sec) mysql> select * from t1 union select * from t2; +-----+-------+ | Rno | Name | +-----+-------+ | 1 | amit | | 2 | rohan | | 3 | rahul | | 4 | Nayan | | 5 | pati | | 6 | xyz | | 7 | pqr | +-----+-------+ 7 rows in set (0.00 sec) mysql> select distinct(Rno) as "Common RollNo" from t1 inner join t2 using(Rno); +---------------+ | Common RollNo | +---------------+ | 3 | | 4 | | 5 | +---------------+ 3 rows in set (0.00 sec)