











































































![Data Type Syntax Maximum Size Explanation
DATE Values range from '1000-01-01' to
'9999-12-31'.
Displayed as 'yyyy-mm-dd'.
DATETIME Values range from '1000-01-01
00:00:00' to '9999-12-31
23:59:59'.
Displayed as 'yyyy-mm-dd
hh:mm:ss'.
TIME Values range from '-838:59:59' to
'838:59:59'.
Displayed as 'HH:MM:SS'.
YEAR[(2|4)] Year value as 2 digits or 4 digits. Default is 4 digits.](https://image.slidesharecdn.com/dbmsmysql-241224180923-8c0ea133/85/DBMS_-MySql-ppsx-database-sql-file-my-sql-codes-78-320.jpg)



















![MySQL UPDATE Query
MySQL UPDATE statement is used to update data of the MySQL table within the database. It is used
when you need to modify the table.
Syntax:
Following is a generic syntax of UPDATE command to modify data into the MySQL table:
UPDATE table_name SET field1=new-value1, field2=new-value2
[WHERE Clause]
Note:
• One or more field can be updated altogether.
• Any condition can be specified by using WHERE clause.
• You can update values in a single table at a time.
• WHERE clause is used to update selected rows in a table.](https://image.slidesharecdn.com/dbmsmysql-241224180923-8c0ea133/85/DBMS_-MySql-ppsx-database-sql-file-my-sql-codes-99-320.jpg)





































































![CUSTOMER
Id(Primary key)
FirstName
LastName
City
Country
Phone
ORDER
Id
OrderDate
OrderNumber
CustomerId(ForeignKey)
TotalAmount
SQL JOIN Examples
Problem: List all orders with customer information
SELECT OrderNumber, TotalAmount, FirstName, LastName, City, Country
FROM [Order] JOIN Customer
ON [Order].CustomerId = Customer.Id](https://image.slidesharecdn.com/dbmsmysql-241224180923-8c0ea133/85/DBMS_-MySql-ppsx-database-sql-file-my-sql-codes-169-320.jpg)






























DBMS_(MySql).ppsx database sql file my sql codes
- 1. Database Management System ( DBMS)
- 2. Basic of Data and Database? • Data is nothing but facts and statistics stored or free flowing over a network, generally it's raw and unprocessed. • For example: • When visit any website, they might store IP address, that is data, in return they might add a cookie in browser, marking that we visited the website, that is data, name, age, it's data. • Data becomes information when it is processed. • What is a Database? • A Database is a collection of related data organized in a way that data can be easily accessed, managed and updated. Database can be software based or hardware based, with one sole purpose, storing data. • Larry Ellison, the co-founder of Oracle was amongst the first few, who realized the need for a software based Database Management System.
- 3. What is DBMS? • A database management system stores data in such a way that it becomes easier to retrieve, manipulate, and produce information. • Basically, DBMS is a software tool to organize (create, retrieve, update and manage) data in a database. • DBMS also provides protection and security to the databases. It also maintains data consistency in case of multiple users. • Here are some examples of popular DBMS used these days: • MySQL • Oracle • SQL Server • IBM DB2 • PostgreSQL • Amazon Simple DB (cloud based) etc.
- 4. What is DBMS? Where is DBMS being Used? Airlines: reservations, schedules etc. Telecom: calls made, customer details, network usage etc. Universities: registration, results, grades etc. Sales: products, purchases, customers etc. Banking: all transactions etc. Features of DBMS It is used to support manipulation and processing of data. It is used to provide security of data. It can view the database from different viewpoints according to the requirements of the user. It uses a digital repository established on a server to store and manage the information.
- 5. Characteristics of DBMS Data stored into Tables: Data is never directly stored into the database. Data is stored into tables, created inside the database. DBMS also allows to have relationships between tables which makes the data more meaningful and connected. Reduced Redundancy: In the modern world hard drives are very cheap, but earlier when hard drives were too expensive, unnecessary repetition of data in database was a big problem. But DBMS follows Normalization which divides the data in such a way that repetition is minimum. Data Consistency: On Live data, i.e. data that is being continuously updated and added, maintaining the consistency of data can become a challenge. But DBMS handles it all by itself. Support Multiple user and Concurrent Access: DBMS allows multiple users to work on it(update, insert, delete data) at the same time and still manages to maintain the data consistency. Query Language: DBMS provides users with a simple Query language, using which data can be easily fetched, inserted, deleted and updated in a database. Security: The DBMS also takes care of the security of data, protecting the data from un-authorized access. In a typical DBMS, we can create user accounts with different access permissions, using which we can easily secure our data by restricting user access.
- 6. Database Management System: Advantages Sharing of Data Data Security Data Consistency Reducing Data Redundancy Data Integrity Privacy Disadvantages DBMS implementation cost is high compared to the file system. Except MySQL, which is open source, licensed DBMSs are generally costly. Complexity: Database systems are complex to understand. They are large in size.
- 7. Users A typical DBMS has users with different rights and permissions who use it for different purposes. Some users retrieve data and some back it up. The users of a DBMS can be broadly categorized as in image. Administrators − Administrators maintain the DBMS and are responsible for administrating the database. They are responsible to look after its usage and by whom it should be used. They create access profiles for users and apply limitations to maintain isolation and force security. Administrators also look after DBMS resources like system license, required tools, and other software and hardware related maintenance. Designers − Designers are the group of people who actually work on the designing part of the database. They keep a close watch on what data should be kept and in what format. They identify and design the whole set of entities, relations, constraints, and views. End Users − End users are those who actually reap the benefits of having a DBMS. End users can range from simple viewers who pay attention to the logs or market rates to sophisticated users such as business analysts.
- 8. DBMS Database Models A Database model defines the logical design and structure of a database and defines how data will be stored, accessed and updated in a database management system. While the Relational Model is the most widely used database model, there are other models too: Hierarchical Model Network Model Entity-relationship Model Relational Model Hierarchical Model This database model organizes data into a tree-like- structure, with a single root, to which all the other data is linked. The hierarchy starts from the Root data, and expands like a tree, adding child nodes to the parent nodes. In this model, a child node will only have a single parent node. This model efficiently describes many real-world relationships like index of a book, recipes etc.
- 9. DBMS Database Models Network Model This is an extension of the Hierarchical model. In this model data is organised more like a graph, and are allowed to have more than one parent node. In this database model data is more related as more relationships are established in this database model. Also, as the data is more related, hence accessing the data is also easier and fast. This database model was used to map many-to-many data relationships. This was the most widely used database model, before Relational Model was introduced.
- 10. DBMS Database Models Entity-relationship Model In this database model, relationships are created by dividing object of interest into entity and its characteristics into attributes. Different entities are related using relationships. This model is good to design a database, which can then be turned into tables in relational model. Entity − An entity in an ER Model is a real-world entity having properties called attributes. Every attribute is defined by its set of values called domain. For example, in a school database, a student is considered as an entity. Student has various attributes like name, age, class, etc. Relationship − The logical association among entities is called relationship. Relationships are mapped with entities in various ways. Mapping cardinalities define the number of association between two entities.
- 11. DBMS Database Models ER Model is based on : Let's take an example : design a School Database, then Student will be an entity with attributes name, age, address etc. As Address is generally complex, it can be another entity with attributes street name, pincode, city etc., and there will be a relationship between them.
- 12. DBMS Database Models Relationship : The degree of a relationship = the number of entity sets that participate in the relationship Mapping cardinality of a relationship 1 –1 1 – many many – 1 Many-many
- 13. Attribute of A Relationship Set
- 16. DBMS Database Models Relational Model : In this model, data is organized in two-dimensional tables and the relationship is maintained by storing a common field. This model was introduced by E.F Codd in 1970, and since then it has been the most widely used database model, in fact, the only database model used around the world. The basic structure of data in the relational model is tables. All the information related to a particular type is stored in rows of that table. Hence, tables are also known as relations in relational model. Here we will see how to design tables, normalize them to reduce data redundancy and how to use Structured Query language to access data from tables. Attribute tupple
- 17. E-R Diagram of Library Management System
- 18. E-R Diagram of Student Management System
- 19. E-R Diagram of Leave Management System
- 20. E-R Diagram Do it yourself : 1. Draw an ERD for College management system 2. Draw an ERD for Online shopping system FOR Referenced : 1.Oracle – The complete reference Author : TMH /oracle press 2.Database System Concepts Author : Abraham Silberschatz, Henry F. Korth & S. Sudarshan Publisher : McGraw Hill. 3. Fundamentals of database systems(Ramez Elmsari,Shamkant B.Navathe) 4. Database System Concepts (Avi Silberschatz · Henry F.Korth · S. Sudarshan) 5. Database Systems - A Practical Approach to Design, Implementation & Management By Thomas Connolly, Carolyn Begg
- 21. Basic Relational DBMS Concepts A Relational Database management System(RDBMS) is a database management system based on the relational model introduced by E.F Codd. In relational model, data is stored in relations(tables) and is represented in form of tuples(rows). RDBMS is used to manage Relational database. Relational database is a collection of organized set of tables related to each other, and from which data can be accessed easily. Relational Database is the most commonly used database these days.
- 22. Relational DBMS What is Table ? In Relational database model, a table is a collection of data elements organized in terms of rows and columns. A table is also considered as a convenient representation of relations. But a table can have duplicate row of data while a true relation cannot have duplicate data. Table is the most simplest form of data storage. Below is an example of an Employee table. ID Name Age Salary 1 Adam 34 13000 2 Alex 28 15000 3 Stuart 20 18000 4 Ross 42 19020
- 23. Relational DBMS What is Tuple? A single entry in a table is called a Tuple or Record or Row. A tuple in a table represents a set of related data. For example, the above Employee table has 4 tuples/records/rows. Following is an example of single record or tuple. 1 Adam 34 13000 What is an Attribute? A table consists of several records(row), each record can be broken down into several smaller parts of data known as Attributes. The above Employee table consist of four attributes, ID, Name, Age and Salary.
- 24. Relational DBMS Attribute Domain When an attribute is defined in a relation(table), it is defined to hold only a certain type of values, which is known as Attribute Domain. Hence, the attribute Name will hold the name of employee for every tuple. If we save employee's address there, it will be violation of the Relational database model. Name Adam Alex Stuart - 9/401, OC Street, Amsterdam Ross What is a Relation Schema? A relation schema describes the structure of the relation, with the name of the relation(name of table), its attributes and their names and type. What is a Relation Key? A relation key is an attribute which can uniquely identify a particular tuple(row) in a relation(table).
- 25. Relational DBMS Integrity Constraints Integrity constraints are a set of rules. It is used to maintain the quality of information. Integrity constraints ensure that the data insertion, updating, and other processes have to be performed in such a way that data integrity is not affected. Thus, integrity constraint is used to guard against accidental damage to the database.
- 26. Relational DBMS Types of Integrity Constraints Integrity Constraint Domain Constraint Entity Integrity Constraint Referential Integrity Constraint Key Constraint
- 27. Relational DBMS 1. Domain constraints Domain constraints can be defined as the definition of a valid set of values for an attribute. The data type of domain includes string, character, integer, time, date, currency, etc. The value of the attribute must be available in the corresponding domain. Example: ID Name Semesters Age 1000 Tom 1 17 1001 Johnson 2 24 1002 Leonardo 5 21 1003 Kate 3 19 1004 Morgan 8 A Not allowed. Because AGE is an integer attribute
- 28. Relational DBMS 2. Entity integrity constraints The entity integrity constraint states that primary key value can't be null. This is because the primary key value is used to identify individual rows in relation and if the primary key has a null value, then we can't identify those rows. A table can contain a null value other than the primary key field. Example: EMP_ID EMP_Name Salary 1010 Tom 20000 1023 Johnson 21500 1012 Leonardo 34000 1031 Kate 27000 Morgan 42000 Not allowed as Primary key can’t contain NULL value .
- 29. Relational DBMS 3. Referential Integrity Constraints A referential integrity constraint is specified between two tables. In the Referential integrity constraints, if a foreign key in Table 1 refers to the Primary Key of Table 2, then every value of the Foreign Key in Table 1 must be null or be available in Table 2. Primary key ID Name Age D_No 1000 Tom 17 11 1001 Johnson 24 24 1002 Leonardo 21 32 1003 Kate 19 18 D_No D_Location 11 24 18 Foreign key Relationship Not allowed as D_No 32 is not defined as a Primary key of table 2 and in table 1, D_No is a foreign key defined
- 30. Relational DBMS 4. Key constraints Keys are the entity set that is used to identify an entity within its entity set uniquely. An entity set can have multiple keys, but out of which one key will be the primary key. A primary key can contain a unique and null value in the relational table. ID Name Semesters Age 1000 Tom 1 17 1001 Johnson 2 24 1002 Leonardo 5 21 1003 Kate 3 19 1002 Morgan 8 A Not allowed. Because all row must be unique
- 31. ER Diagram Representation Entity : Entities are represented by means of rectangles. Rectangles are named with the entity set they represent. Entities in a school database Attributes : Attributes are the properties of entities. Attributes are represented by means of ellipses. Every ellipse represents one attribute and is directly connected to its entity (rectangle) Student Teacher Projects Student Name BirthDate Roll_No
- 32. ER Diagram Representation If the attributes are composite, they are further divided in a tree like structure. Every node is then connected to its attribute. That is, composite attributes are represented by ellipses that are connected with an ellipse. Student Name BirthDate Roll_No First_Name Last_Name
- 33. ER Diagram Representation Multivalued attributes are depicted by double ellipse. Student Name BirthDate Roll_No First_Name Last_Name Phone_No
- 34. ER Diagram Representation Derived attributes are depicted by dashed ellipse. Student Name BirthDate Roll_No First_Name Last_Name Phone_No Age
- 35. ER Diagram Representation Cardinality : Defines the numerical attributes of the relationship between two entities or entity sets. Different types of cardinal relationships are: One-to-One Relationships One-to-Many Relationships May to One Relationships Many-to-Many Relationships
- 36. ER Diagram Representation Relationship : Relationships are represented by diamond-shaped box. Name of the relationship is written inside the diamond-box. All the entities (rectangles) participating in a relationship, are connected to it by a line. Binary Relationship and Cardinality A relationship where two entities are participating is called a binary relationship. Cardinality is the number of instance of an entity from a relation that can be associated with the relation. One-to-one − When only one instance of an entity is associated with the relationship, it is marked as '1:1'. The following image reflects that only one instance of each entity should be associated with the relationship. It depicts one-to-one relationship. Entity Entity Relationship 1 1
- 37. ER Diagram Representation One-to-many : When more than one instance of an entity is associated with a relationship, it is marked as '1:N'. The following image reflects that only one instance of entity on the left and more than one instance of an entity on the right can be associated with the relationship. It depicts one-to-many relationship. Many-to-one : When more than one instance of entity is associated with the relationship, it is marked as 'N:1'. The following image reflects that more than one instance of an entity on the left and only one instance of an entity on the right can be associated with the relationship. It depicts many-to-one relationship. Entity Entity Relationship 1 N Entity Entity Relationship N 1
- 38. ER Diagram Representation The ER Model has the power of expressing database entities in a conceptual hierarchical manner. As the hierarchy goes up, it generalizes the view of entities, and as we go deep in the hierarchy, it gives us the detail of every entity included. Going up in this structure is called generalization, where entities are clubbed together to represent a more generalized view. For example, a particular student named Mira can be generalized along with all the students. The entity shall be a student, and further, the student is a person. The reverse is called specialization where a person is a student, and that student is Mira.
- 39. ER Diagram Representation Generalization : • As mentioned above, the process of generalizing entities, where the generalized entities contain the properties of all the generalized entities, is called generalization. In generalization, a number of entities are brought together into one generalized entity based on their similar characteristics. For example, pigeon, house sparrow, crow and dove can all be generalized as Birds.
- 40. ER Diagram Representation Specialization : • Specialization is the opposite of generalization. In specialization, a group of entities is divided into sub-groups based on their characteristics. Take a group ‘Person’ for example. A person has name, date of birth, gender, etc. These properties are common in all persons, human beings. But in a company, persons can be identified as employee, employer, customer, or vendor, based on what role they play in the company. • Similarly, in a school database, persons can be specialized as teacher, student, or a staff, based on what role they play in school as entities.
- 41. ER Diagram Representation • Inheritance : • The above features of ER-Model in order to create classes of objects in object-oriented programming. The details of entities are generally hidden from the user; this process known as abstraction. • Inheritance is an important feature of Generalization and Specialization. It allows lower-level entities to inherit the attributes of higher-level entities. • For example, the attributes of a Person class such as name, age, and gender can be inherited by lower-level entities such as Student or Teacher.
- 42. ER Diagram – Internet Sales Model
- 43. Codd's Rule for Relational DBMS E.F Codd was a Computer Scientist who invented the Relational model for Database management. Based on relational model, the Relational database was created. Codd proposed 13 rules popularly known as Codd's 12 rules to test DBMS's concept against his relational model. Codd's rule actually define what quality a DBMS requires in order to become a Relational Database Management System(RDBMS). Rule zero This rule states that for a system to qualify as an RDBMS, it must be able to manage database entirely through the relational capabilities. Rule 1: Information rule All information(including metadata) is to be represented as stored data in cells of tables. The rows and columns have to be strictly unordered.
- 44. Codd's Rule for Relational DBMS Rule 2: Guaranteed Access Each unique piece of data(atomic value) should be accessible by : Table Name + Primary Key(Row) + Attribute(column). Rule 3: Systematic treatment of NULL Null has several meanings, it can mean missing data, not applicable or no value. It should be handled consistently. Also, Primary key must not be null, ever. Expression on NULL must give null. Rule 4: Active Online Catalog Database dictionary(catalog) is the structure description of the complete Database and it must be stored online. The Catalog must be governed by same rules as rest of the database. The same query language should be used on catalog as used to query database. Rule 5: Powerful and Well-Structured Language One well structured language must be there to provide all manners of access to the data stored in the database. Example: SQL, etc. If the database allows access to the data without the use of this language, then that is a violation.
- 45. Codd's Rule for Relational DBMS Rule 6: View Updation Rule All the view that are theoretically updatable should be updatable by the system as well. Rule 7: Relational Level Operation There must be Insert, Delete, Update operations at each level of relations. Set operation like Union, Intersection and minus should also be supported. Rule 8: Physical Data Independence The physical storage of data should not matter to the system. If say, some file supporting table is renamed or moved from one disk to another, it should not effect the application. Rule 9: Logical Data Independence If there is change in the logical structure(table structures) of the database the user view of data should not change. Say, if a table is split into two tables, a new view should give result as the join of the two tables. This rule is most difficult to satisfy.
- 46. Codd's Rule for Relational DBMS Rule 10: Integrity Independence The database should be able to enforce its own integrity rather than using other programs. Key and Check constraints, trigger etc., should be stored in Data Dictionary. This also make RDBMS independent of front-end. Rule 11: Distribution Independence A database should work properly regardless of its distribution across a network. Even if a database is geographically distributed, with data stored in pieces, the end user should get an impression that it is stored at the same place. This lays the foundation of distributed database. Rule 12: Non-subversion Rule If low level access is allowed to a system it should not be able to subvert or bypass integrity rules to change the data. This can be achieved by some sort of looking or encryption.
- 47. NORMALIZATION Database Normalization is a technique of organizing the data in the database. Normalization is a systematic approach of decomposing tables to eliminate data redundancy(repetition) and undesirable characteristics like Insertion, Update and Deletion. It is a multi-step process that puts data into tabular form, removing duplicated data from the relation tables. Normalization is used for mainly two purposes, • Eliminating redundant(useless) data. • Ensuring data dependencies make sense i.e. data is logically stored. Basic Concept of Database Normalization - Simple Explanation for Beginners https://www.youtube.com/watch?time_continue=476&v=xoTyrdT9SZI
- 48. NORMALIZATION Normalization Rule : Normalization rules are divided into the following normal forms: 1. First Normal Form 2. Second Normal Form 3. Third Normal Form 4. BCNF 5. Fourth Normal Form First Normal Form (1NF) : For a table to be in the First Normal Form, it should follow the following 4 rules: It should only have single(atomic) valued attributes/columns. Values stored in a column should be of the same domain All the columns in a table should have unique names. And the order in which data is stored, does not matter. https://www.youtube.com/watch?v=mUtAPbb1ECM
- 49. NORMALIZATION Rule 1: Single Valued Attributes Each column of your table should be single valued which means they should not contain multiple values. We will explain this with help of an example. Rule 2: Attribute Domain should not change This is more of a "Common Sense" rule. In each column the values stored must be of the same kind or type. For example: If you have a column dob to save date of births of a set of people, then you cannot or you must not save 'names' of some of them in that column along with 'date of birth' of others in that column. It should hold only 'date of birth' for all the records/rows. Rule 3: Unique name for Attributes/Columns This rule expects that each column in a table should have a unique name. This is to avoid confusion at the time of retrieving data or performing any other operation on the stored data. If one or more columns have same name, then the DBMS system will be left confused. Rule 4: Order doesn't matters This rule says that the order in which you store the data in your table doesn't matter.
- 50. NORMALIZATION Here is our table, with some sample data added to it. Our table already satisfies 3 rules out of the 4 rules, as all our column names are unique, we have stored data in the order we wanted to and we have not inter-mixed different type of data in columns. But out of the 3 different students in our table, 2 have opted for more than 1 subject. And we have stored the subject names in a single column. But as per the 1st Normal form each column must contain atomic value. roll_No name Subject 1001 Leonardo OS, CN 1003 Kate JAVA 1002 Morgan C, C++
- 51. NORMALIZATION How to solve this Problem? Here is our updated table and it now satisfies the First Normal Form. By doing so, although a few values are getting repeated but values for the subject column are now atomic for each record/row. Using the First Normal Form, data redundancy increases, as there will be many columns with same data in multiple rows but each row as a whole will be unique. roll_No name Subject 1001 Leonardo OS 1001 Leonardo CN 1003 Kate JAVA 1002 Morgan C 1002 Morgan C++
- 52. NORMALIZATION What is Second Normal Form? For a table to be in the Second Normal Form, it must satisfy two conditions: • The table should be in the First Normal Form. • There should be no Partial Dependency. What is Partial Dependency? First let's understand what is Dependency in a table? What is Dependency? an example of a Student table with columns student_id, name, reg_no(registration number), branch and address(student's home address). student_id name reg_no branch address
- 53. NORMALIZATION In this table, student_id is the primary key and will be unique for every row, hence we can use student_id to fetch any row of data from this table Even for a case, where student names are same, if we know the student_id we can easily fetch the correct record. Hence we can say a Primary Key for a table is the column or a group of columns(composite key) which can uniquely identify each record in the table. can ask from branch name of student with student_id 10, and I can get it. Similarly, if I ask for name of student with student_id 10 or 11, I will get it. So all I need is student_id and every other column depends on it, or can be fetched using it. This is Dependency and we also call it Functional Dependency. Student_Id name Reg_No branch address 10 Akon 07-WY CSE Kerala 11 Akon 08-WY IT Gujarat
- 54. NORMALIZATION What is Partial Dependency? For a simple table like Student, a single column like student_id can uniquely identify all the records in a table. But this is not true all the time. So now let's extend our example to see if more than 1 column together can act as a primary key. Let's create another table for Subject, which will have subject_id and subject_name fields and subject_id will be the primary key. Subject_Id Subject_name 101 C 102 Python 103 Java
- 55. NORMALIZATION Now we have a Student table with student information and another table Subject for storing subject information. Let's create another table Score, to store the marks obtained by students in the respective subjects. We will also be saving name of the teacher who teaches that subject along with marks. In the score table we are saving the student_id to know which student's marks are these and subject_id to know for which subject the marks are for. Together, student_id + subject_id forms a Candidate Key for this table, which can be the Primary key. Score_Id Student_Id Subject_Id Marks Faculty 1 10 101 72 C Faculty 2 10 102 68 Python Faculty 3 11 101 81 C Faculty
- 56. NORMALIZATION Partial Dependency? Now if you look at the Score table, we have a column names faculty which is only dependent on the subject, for C it’s C faculty and for python it’s python faculty & so on. Now as discussed that the primary key for this table is a composition of two columns which is student_id & subject_id but the teacher's name only depends on subject, hence the subject_id, and has nothing to do with student_id. This is Partial Dependency, where an attribute in a table depends on only a part of the primary key and not on the whole key.
- 57. NORMALIZATION How to remove Partial Dependency? The simplest solution is to remove columns teacher from Score table and add it to the Subject table. Hence, the Subject table will become: And our Score table is now in the second normal form, with no partial dependency. Score_Id Student_Id Subject_Id Marks 1 10 101 72 2 10 102 68 3 11 101 81 Subject_Id Subject_name Faculty 101 C C Faculty 102 Python Python Faculty 103 Java Java Faculty
- 58. NORMALIZATION Quick Recap For a table to be in the Second Normal form, it should be in the First Normal form and it should not have Partial Dependency. Partial Dependency exists, when for a composite primary key, any attribute in the table depends only on a part of the primary key and not on the complete primary key. To remove Partial dependency, we can divide the table, remove the attribute which is causing partial dependency, and move it to some other table where it fits in well. https://www.youtube.com/watch?time_continue=403&v=R7UblSu4744
- 59. NORMALIZATION Another Example : The entity should be considered already in 1NF, and all attributes within the entity should depend solely on the unique identifier of the entity. Sample Products table: Product_Id Product_Name Brand 101 Monitor Apple 102 Monitor Samsung 103 Scanner HP 104 Head phone JBL
- 60. NORMALIZATION Product table following 2NF: Products Category table: Products Brand table: Brand table: PB_Id Product_Id Brand_Id 1 101 101 2 102 102 3 103 103 4 104 104 Product_Id Product_Name 101 Monitor 102 Monitor 103 Scanner 104 Head phone Brand_Id Brand 101 Apple 102 HP 103 Samsung 104 JBL
- 61. NORMALIZATION Third Normal Form (3NF) So let's use the same example, where we have 3 tables, Student, Subject and Score. Student Table: Subject Table: Student_Id name Reg_No branch address 10 Akon 07-WY CSE Kerala 11 Akon 08-WY IT Gujarat 12 Bkon 09-WY IT Rajasthan Subject_Id Subject_name Faculty 101 C C Faculty 102 Python Python Faculty 103 Java Java Faculty
- 62. NORMALIZATION Score Table: In the Score table, we need to store some more information, which is the exam name and total marks, so let's add 2 more columns to the Score table. Score_Id Student_Id Subject_Id Marks Faculty 1 10 101 72 C Faculty 2 10 102 68 Python Faculty 3 11 101 81 C Faculty Score_Id Student_Id Subject_Id Marks Faculty Exam_Name Total_Marks
- 63. NORMALIZATION Requirements for Third Normal Form : For a table to be in the third normal form, • It should be in the Second Normal form. • And it should not have Transitive Dependency. What is Transitive Dependency? With exam_name and total_marks added to our Score table, it saves more data now. Primary key for our Score table is a composite key, which means it's made up of two attributes or columns → student_id + subject_id. Our new column exam_name depends on both student and subject. For example, a mechanical engineering student will have Workshop exam but a computer science student won't. And for some subjects you have Practical exams and for some you don't. So we can say that exam_name is dependent on both student_id and subject_id. And what about our second new column total_marks? Does it depend on our Score table's primary key? Well, the column total_marks depends on exam_name as with exam type the total score changes. For example, practical's are of less marks while theory exams are of more marks. But, exam_name is just another column in the score table. It is not a primary key or even a part of the primary key, and total_marks depends on it. This is Transitive Dependency. When a non-prime attribute depends on other non-prime attributes rather than depending upon the prime attributes or primary key.
- 64. NORMALIZATION How to remove Transitive Dependency? Again the solution is very simple. Take out the columns exam_name and total_marks from Score table and put them in an Exam table and use the exam_id wherever required. In the Score table, we need to store some more information, which is the exam name and total marks, so let's add 2 more columns to the Score table. Advantage of removing Transitive Dependency The advantage of removing transitive dependency is, • Amount of data duplication is reduced. • Data integrity achieved. https://www.youtube.com/watch?time_continue=13&v=aAx_JoEDXQA Exam_Id Exam_Name Total_Marks 1 Workshop 200 2 Mains 70 3 Practicals 30 Score_Id Student_Id Subject_Id Marks Faculty Exam_Id
- 65. NORMALIZATION Boyce-Codd Normal Form or BCNF is an extension to the third normal form, and is also known as 3.5 Normal Form. Rules for BCNF : For a table to satisfy the Boyce-Codd Normal Form, it should satisfy the following two conditions: It should be in the Third Normal Form. And, for any dependency A → B, A should be a super key. it means, that for a dependency A → B, A cannot be a non-prime attribute, if B is a prime attribute. Below we have a college enrolment table with columns student_id, subject and professor. Student_Id Subject Professor 101 C P.C 101 Java P.Java 102 Python P.Python 103 C# P.Chash 104 Java P.Java
- 66. NORMALIZATION In the table of previous slide: One student can enroll for multiple subjects. For example, student with student_id 101, has opted for subjects - C & Java For each subject, a professor is assigned to the student. And, there can be multiple professors teaching one subject like we have for Java. What should be the Primary Key? In the table above student_id, subject together form the primary key, because using student_id and subject, we can find all the columns of the table. One more important point to note here is, one professor teaches only one subject, but one subject may have two different professors. Hence, there is a dependency between subject and professor here, where subject depends on the professor name.
- 67. NORMALIZATION This table satisfies the 1st Normal form because all the values are atomic, column names are unique and all the values stored in a particular column are of same domain. This table also satisfies the 2nd Normal Form as their is no Partial Dependency. And, there is no Transitive Dependency, hence the table also satisfies the 3rd Normal Form. But this table is not in Boyce-Codd Normal Form. Why this table is not in BCNF? In the table above, student_id, subject form primary key, which means subject column is a prime attribute. But, there is one more dependency, professor → subject. And while subject is a prime attribute, professor is a non-prime attribute, which is not allowed by BCNF.
- 68. NORMALIZATION How to satisfy BCNF? To make this relation(table) satisfy BCNF, we will decompose this table into two tables, student table and professor table. Below we have the structure for both the tables. Student Table Professor Table https://www.youtube.com/watch?time_continue=6&v=NNjUhvvwOrk PId Professor Subject 1 P.C C 2 P.Java Java 3 P.Python Python And so no…. Student_Id Professor 1 2 And so no …
- 69. NORMALIZATION Fourth Normal Form (4NF) : Fourth Normal Form comes into picture when Multi-valued Dependency occur in any relation. Below is the Rules for 4th Normal Form : For a table to satisfy the Fourth Normal Form, it should satisfy the following two conditions: It should be in the Boyce-Codd Normal Form. And, the table should not have any Multi-valued Dependency. What is Multi-valued Dependency? A table is said to have multi-valued dependency, if the following conditions are true, For a dependency A → B, if for a single value of A, multiple value of B exists, then the table may have multi-valued dependency. Also, a table should have at-least 3 columns for it to have a multi-valued dependency. And, for a relation R(A,B,C), if there is a multi-valued dependency between, A and B, then B and C should be independent of each other. If all these conditions are true for any relation(table), it is said to have multi-valued dependency.
- 70. NORMALIZATION For Example: Below we have a college enrolment table with columns s_id, course and hobby. Can see in the table above, student with s_id 1 has opted for two courses, Science and Maths, and has two hobbies, Cricket and Hockey. Well the two records for student with s_id 1, will give rise to two more records, as shown below, because for one student, two hobbies exists, hence along with both the courses, these hobbies should be specified. And, in the table above, there is no relationship between the columns course and hobby. They are independent of each other. So there is multi-value dependency, which leads to un- necessary repetition of data and other anomalies as well. S_Id Course Hobby 101 Science Cricket 101 Maths Hockey 102 C# Cricket 103 Php Hockey S_Id Course Hobby 101 Science Cricket 101 Maths Hockey 101 Maths Cricket 101 Science Hockey
- 71. NORMALIZATION How to satisfy 4th Normal Form? To make the above relation satisfy the 4th normal form, we can decompose the table into 2 tables. Course Opted Table Hobbies Table Now this relation satisfies the fourth normal form. A table can also have functional dependency along with multi-valued dependency. In that case, the functionally dependent columns are moved in a separate table and the multi-valued dependent columns are moved to separate tables. S_Id Course 101 Science 101 Maths 102 C# 103 Php S_Id Hobby 101 Cricket 101 Hockey 102 Cricket 102 Hockey
- 72. Converting ER Diagrams to Tables-
- 73. NORMALIZATION Entity type becomes a table. In the given ER diagram, LECTURE, STUDENT, SUBJECT and COURSE forms individual tables. All single-valued attribute becomes a column for the table. In the STUDENT entity, STUDENT_NAME and STUDENT_ID form the column of STUDENT table. Similarly, COURSE_NAME and COURSE_ID form the column of COURSE table and so on. A key attribute of the entity type represented by the primary key. In the given ER diagram, COURSE_ID, STUDENT_ID, SUBJECT_ID, and LECTURE_ID are the key attribute of the entity. The multivalued attribute is represented by a separate table. In the student table, a hobby is a multivalued attribute. So it is not possible to represent multiple values in a single column of STUDENT table. Hence we create a table STUD_HOBBY with column name STUDENT_ID and HOBBY. Using both the column, we create a composite key. Composite attribute represented by components. In the given ER diagram, student address is a composite attribute. It contains CITY, PIN, DOOR#, STREET, and STATE. In the STUDENT table, these attributes can merge as an individual column. Derived attributes are not considered in the table. In the STUDENT table, Age is the derived attribute. It can be calculated at any point of time by calculating the difference between current date and Date of Birth.
- 74. NORMALIZATION Using these rules, can convert the ER diagram to tables and columns and assign the mapping between the tables. Table structure for the given ER diagram is as below: For more link: https://www.tutorialcup.com/dbms/er-model-into-tables.htm
- 75. History of MySQL MySQL is an open source database product that was created by MySQL AB, a company founded in 1995 in Sweden. In 2008, MySQL AB announced that it had agreed to be acquired by Sun Microsystems MySQL Features Relational Database Management System (RDBMS): MySQL is a relational database management system. Easy to use: MySQL is easy to use. You have to get only the basic knowledge of SQL. You can build and interact with MySQL with only a few simple SQL statements. It is secure: MySQL consist of a solid data security layer that protects sensitive data from intruders. Passwords are encrypted in MySQL. Client/ Server Architecture: MySQL follows a client /server architecture. There is a database server (MySQL) and arbitrarily many clients (application programs), which communicate with the server; that is, they query data, save changes, etc.
- 76. Free to download: MySQL is free to use and you can download it from MySQL official website. It is scalable: MySQL can handle almost any amount of data, up to as much as 50 million rows or more. The default file size limit is about 4 GB. However, can increase this number to a theoretical limit of 8 TB of data. Compatibale on many operating systems: MySQL is compatible to run on many operating systems, like Novell NetWare, Windows* Linux*, many varieties of UNIX* (such as Sun* Solaris*, AIX, and DEC* UNIX), OS/2, FreeBSD*, and others. MySQL also provides a facility that the clients can run on the same computer as the server or on another computer (communication via a local network or the Internet). Allows roll-back: MySQL allows transactions to be rolled back, commit and crash recovery. High Performance: MySQL is faster, more reliable and cheaper because of its unique storage engine architecture. High Flexibility: MySQL supports a large number of embedded applications which makes MySQL very flexible. High Productivity: MySQL uses Triggers, Stored procedures and views which allows the developer to give a higher productivity.
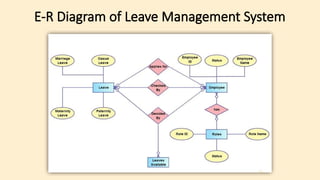
- 77. MySQL Data Types MySQL supports a lot number of SQL standard data types in various categories. It uses many different data types broken into mainly three categories: numeric, date and time, and string types. Data Type Syntax Description INT A normal-sized integer that can be signed or unsigned. If signed, the allowable range is from -2147483648 to 2147483647. If unsigned, the allowable range is from 0 to 4294967295. You can specify a width of up to 11 digits. SMALLINT A small integer that can be signed or unsigned. If signed, the allowable range is from -32768 to 32767. If unsigned, the allowable range is from 0 to 65535. You can specify a width of up to 5 digits. MEDIUMINT A medium-sized integer that can be signed or unsigned. If signed, the allowable range is from -8388608 to 8388607. If unsigned, the allowable range is from 0 to 16777215. You can specify a width of up to 9 digits. FLOAT(m,d) A floating-point number that cannot be unsigned. You can define the display length (m) and the number of decimals (d). This is not required and will default to 10,2, where 2 is the number of decimals and 10 is the total number of digits (including decimals). Decimal precision can go to 24 places for a float. DOUBLE(m,d) A double precision floating-point number that cannot be unsigned. You can define the display length (m) and the number of decimals (d). This is not required and will default to 16,4, where 4 is the number of decimals. Decimal precision can go to 53 places for a double. Real is a synonym for double. DECIMAL(m,d) An unpacked floating-point number that cannot be unsigned. In unpacked decimals, each decimal corresponds to one byte. Defining the display length (m) and the number of decimals (d) is required. Numeric is a synonym for decimal.
- 78. Data Type Syntax Maximum Size Explanation DATE Values range from '1000-01-01' to '9999-12-31'. Displayed as 'yyyy-mm-dd'. DATETIME Values range from '1000-01-01 00:00:00' to '9999-12-31 23:59:59'. Displayed as 'yyyy-mm-dd hh:mm:ss'. TIME Values range from '-838:59:59' to '838:59:59'. Displayed as 'HH:MM:SS'. YEAR[(2|4)] Year value as 2 digits or 4 digits. Default is 4 digits.
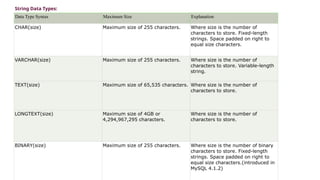
- 79. String Data Types: Data Type Syntax Maximum Size Explanation CHAR(size) Maximum size of 255 characters. Where size is the number of characters to store. Fixed-length strings. Space padded on right to equal size characters. VARCHAR(size) Maximum size of 255 characters. Where size is the number of characters to store. Variable-length string. TEXT(size) Maximum size of 65,535 characters. Where size is the number of characters to store. LONGTEXT(size) Maximum size of 4GB or 4,294,967,295 characters. Where size is the number of characters to store. BINARY(size) Maximum size of 255 characters. Where size is the number of binary characters to store. Fixed-length strings. Space padded on right to equal size characters.(introduced in MySQL 4.1.2)
- 80. MySQL Create Database Syntax- CREATE DATABASE database_name; Commands- CREATE DATABASE employees; SHOW DATABASES; SELECT Database--- USE DATABASE; MySQL Drop Database== DROP DATABASE database_name;
- 81. Introduction to SQL Structure Query Language(SQL) is a database query language used for storing and managing data in Relational DBMS. SQL was the first commercial language introduced for E.F Codd's Relational model of database. Today almost all RDBMS(MySql, Oracle, Infomix, Sybase, MS Access) use SQL as the standard database query language. SQL is used to perform all types of data operations in RDBMS. SQL Command DDL: Data Definition Language This includes changes to the structure of the table like creation of table, altering table, deleting a table etc. All DDL commands are auto-committed. That means it saves all the changes permanently in the database.
- 82. DML: Data Manipulation Language DML commands are used for manipulating the data stored in the table and not the table itself. DML commands are not auto-committed. It means changes are not permanent to database, they can be rolled back.
- 83. TCL: Transaction Control Language These commands are to keep a check on other commands and their affect on the database. These commands can annul changes made by other commands by rolling the data back to its original state. It can also make any temporary change permanent.
- 84. DCL: Data Control Language Data control language are the commands to grant and take back authority from any database user. DQL: Data Query Language Data query language is used to fetch data from tables based on conditions that we can easily apply.
- 85. Data Definition Language SQL: create command- Creating a Database To create a database in RDBMS, create command is used. Following is the syntax, CREATE DATABASE <DB_NAME>; Example for creating Database CREATE DATABASE Test; The above command will create a database named Test, which will be an empty schema without any table.
- 86. To create tables in this newly created database, we can again use the create command. Creating a Table create command can also be used to create tables. Now when we create a table, we have to specify the details of the columns of the tables too. We can specify the names and datatypes of various columns in the create command itself. Following is the syntax, CREATE TABLE <TABLE_NAME> ( column_name1 datatype1, column_name2 datatype2, column_name3 datatype3, column_name4 datatype4 ); Example for creating Table CREATE TABLE Student( student_id INT, name VARCHAR(100), age INT);
- 87. Here, NOT NULL is a field attribute and it is used because we don't want this field to be NULL. If you will try to create a record with NULL value, then MySQL will raise an error. The field attribute AUTO_INCREMENT specifies MySQL to go ahead and add the next available number to the id field.PRIMARY KEY is used to define a column as primary key.
- 88. A database with name Test and we want to create a table Student in it, then we can do so using the following query: CREATE TABLE Test.Student( student_id INT, name VARCHAR(100), age INT); Datatype Use INT used for columns which will store integer values. FLOAT used for columns which will store float values. DOUBLE used for columns which will store float values. VARCHAR used for columns which will be used to store characters and integers, basically a string. CHAR used for columns which will store char values(single character). DATE used for columns which will store date values. TEXT used for columns which will store text which is generally long in length. For example, if you create a table for storing profile information of a social networking website, then for about me section you can have a column of type TEXT. Most commonly used datatypes for Table columns .
- 89. SQL: ALTER command alter command is used for altering the table structure, such as, •to add a column to existing table •to rename any existing column •to change datatype of any column or to modify its size. •to drop a column from the table. •ALTER Command: Add a new Column ALTER TABLE table_name ADD( column_name datatype); Here is an Example for this, ALTER TABLE student ADD( address VARCHAR(200) );
- 90. ALTER Command: Add multiple new Columns Using ALTER command we can even add multiple new columns to any existing table. Following is the syntax, ALTER TABLE table_name ADD ( column_name1 datatype1, column-name2 datatype2, column-name3 datatype3); Here is an Example for this, ALTER TABLE student ADD( father_name VARCHAR(60), mother_name VARCHAR(60), dob DATE);
- 91. ALTER Command: Rename a Column Using ALTER command you can rename an existing column. Following is the syntax, ALTER TABLE table_name RENAME old_column_name TO new_column_name; Here is an example for this, ALTER TABLE student RENAME address TO location; CHANGE KEYWORD Change Keywords allows you to Change Name of Column Change Column Data Type Change Column Constraints
- 92. ALTER Command: Drop a Column ALTER command can also be used to drop or remove columns. Following is the syntax, ALTER TABLE table_name DROP( column_name); Here is an example for this, ALTER TABLE student DROP( address);
- 93. Truncate, Drop or Rename a Table the various DDL commands which are used to re-define the tables. TRUNCATE command TRUNCATE command removes all the records from a table. But this command will not destroy the table's structure. When we use TRUNCATE command on a table its (auto-increment) primary key is also initialized. Following is its syntax, TRUNCATE TABLE table_name Here is an example explaining it, TRUNCATE TABLE student; The above query will delete all the records from the table student.
- 94. DROP command DROP command completely removes a table from the database. This command will also destroy the table structure and the data stored in it. Following is its syntax, DROP TABLE table_name Here is an example explaining it DROP TABLE student; The above query will delete the Student table completely. It can also be used on Databases, to delete the complete database. For example, to drop a database, DROP DATABASE Test; The above query will drop the database with name Test from the system.
- 95. RENAME query RENAME command is used to set a new name for any existing table. Following is the syntax, RENAME TABLE old_table_name to new_table_name Here is an example explaining it. RENAME TABLE student to students_info; The above query will rename the table student to students_info
- 96. Using INSERT SQL command- INSERT INTO table_name VALUES(data1, data2, ...) Lets see an example, Consider a table student with the following fields. s_id, name, age INSERT INTO student VALUES(101, 'Adam', 15); The above command will insert a new record into student table. s_id name age 101 Adam 15
- 97. Insert value into only specific columns We can use the INSERT command to insert values for only some specific columns of a row. We can specify the column names along with the values to be inserted like this, INSERT INTO student(id, name) values(102, 'Alex'); The above SQL query will only insert id and name values in the newly inserted record. s_id name age 101 Adam 15 102 Alex
- 98. MySQL INSERT Example : for partial fields In such case, it is mandatory to specify field names. INSERT INTO emp(id,name) VALUES (7, 'Sonu'); MySQL INSERT Example 3: inserting multiple records INSERT INTO cus_tbl (cus_id, cus_firstname, cus_surname) VALUES (5, 'Ajeet', 'Maurya'), (6, 'Deepika', 'Chopra'), (7, 'Vimal', 'Jaiswal');
- 99. MySQL UPDATE Query MySQL UPDATE statement is used to update data of the MySQL table within the database. It is used when you need to modify the table. Syntax: Following is a generic syntax of UPDATE command to modify data into the MySQL table: UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE Clause] Note: • One or more field can be updated altogether. • Any condition can be specified by using WHERE clause. • You can update values in a single table at a time. • WHERE clause is used to update selected rows in a table.
- 100. Using UPDATE SQL command student_id name age 101 Adam 15 102 Alex 103 chris 14 UPDATE command UPDATE command is used to update any record of data in a table. Following is its general syntax, UPDATE table_name SET column_name = new_value WHERE some_condition; WHERE is used to add a condition to any SQL query, we will soon study about it in detail. Lets take a sample table student,
- 101. S_id S_Name age 101 Adam 15 102 Alex 18 103 chris 14 UPDATE student SET age=18 WHERE student_id=102; s_id name age 101 Adam 15 102 Alex 18 103 Abhi 17 Updating Multiple Columns We can also update values of multiple columns using a single UPDATE statement. UPDATE student SET name='Abhi', age=17 where s_id=103; The above command will update two columns of the record which has s_id 103.
- 102. MySQL DELETE Statement MySQL DELETE statement is used to delete data from the MySQL table within the database. By using delete statement, we can delete records on the basis of conditions. Syntax: DELETE FROM table_name WHERE (Condition specified); Example: DELETE FROM cus_tbl WHERE cus_id = 6;
- 103. Using DELETE SQL command DELETE command is used to delete data from a table. Following is its general syntax, DELETE FROM table_name; Delete all Records from a Table DELETE FROM student;
- 104. Delete a particular Record from a Table In our student table if we want to delete a single record, we can use the WHERE clause to provide a condition in our DELETE statement. DELETE FROM student WHERE s_id=103; Is DELETE same as TRUNCATE??? TRUNCATE command is different from DELETE command. The delete command will delete all the rows from a table whereas truncate command not only deletes all the records stored in the table, but it also re-initializes the table(like a newly created table). For eg: If you have a table with 10 rows and an auto increment primary key, and if you use DELETE command to delete all the rows, it will delete all the rows, but will not re-initialize the primary key, hence if you will insert any row after using the DELETE command, the auto increment primary key will start from 11. But in case of TRUNCATE command, primary key is re-initialized, and it will again start from 1.
- 105. SELECT SQL Query SELECT query is used to retrieve data from a table. It is the most used SQL query. We can retrieve complete table data, or partial by specifying conditions using the WHERE clause. Syntax of SELECT query SELECT query is used to retrieve records from a table. We can specify the names of the columns which we want in the result set. SELECT column_name1, column_name2, column_name3, ... column_nameN FROM table_name;
- 106. The SQL WHERE Clause The WHERE clause is used to filter records. The WHERE clause is used to extract only those records that fulfill a specified condition. WHERE Syntax SELECT column1, column2, ... FROM table_name WHERE condition;
- 107. Operators in The WHERE Clause The following operators can be used in the WHERE clause: Operator Description = Equal <> Not equal. Note: In some versions of SQL this operator may be written as != > Greater than < Less than >= Greater than or equal <= Less than or equal BETWEEN Between an inclusive range LIKE Search for a pattern IN To specify multiple possible values for a column
- 108. The SQL AND, OR and NOT Operators • The WHERE clause can be combined with AND, OR, and NOT operators. • The AND OR operators are used to filter records based on more than one condition: • The AND operator displays a record if all the conditions separated by AND is TRUE. • The OR operator displays a record if any of the conditions separated by OR is TRUE. • The NOT operator displays a record if the condition(s) is NOT TRUE.
- 109. Sample Table:
- 110. ANSWER 1. SELECT * FROM Student WHERE Age=20; 2. SELECT ROLL_NO,NAME,ADDRESS FROM Student WHERE ROLL_NO > 3; BETWEEN: operator 3. SELECT * FROM Student WHERE ROLL_NO BETWEEN 1 AND 3; 4. SELECT NAME,ADDRESS FROM Student WHERE Age BETWEEN 20 AND 30; LIKE: operator 5. SELECT * FROM Student WHERE NAME LIKE 'S%'; 6. SELECT * FROM Student WHERE NAME LIKE '%AM%'; IN operator 7. SELECT NAME,ADDRESS FROM Student WHERE Age IN (18,20); 8. SELECT * FROM Student WHERE ROLL_NO IN (1,4);
- 111. AND Syntax SELECT column1, column2, ... FROM table_name WHERE condition1 AND condition2 AND condition3 ...; OR Syntax SELECT column1, column2, ... FROM table_name WHERE condition1 OR condition2 OR condition3 ...; NOT Syntax SELECT column1, column2, ... FROM table_name WHERE NOT condition;
- 112. AND Example The following SQL statement selects all fields from "Customers" where country is "Germany" AND city is "Berlin": Example SELECT * FROM Customers WHERE Country='Germany' AND City='Berlin'; OR Example SELECT * FROM Customers WHERE City='Berlin' OR City='München'; NOT Example Example SELECT * FROM Customers WHERE NOT Country='Germany';
- 113. Combining AND, OR and NOT The following SQL statement selects all fields from "Customers" where country is "Germany" AND city must be "Berlin" OR "München" (use parenthesis to form complex expressions): Example SELECT * FROM Customers WHERE Country='Germany' AND (City='Berlin' OR City='München'); Example SELECT * FROM Customers WHERE NOT Country='Germany' AND NOT Country='USA';
- 114. SELECT Column Example SELECT s_id, name, age FROM student; The SQL SELECT DISTINCT Statement The SELECT DISTINCT statement is used to return only distinct (different) values. Inside a table, a column often contains many duplicate values; and sometimes you only want to list the different (distinct) values.
- 115. SELECT DISTINCT column1, column2, ... FROM table_name; SELECT Country FROM Customers; SELECT DISTINCT Country FROM Customers; SELECT COUNT(DISTINCT Country) FROM Customers;
- 116. ORDER BY Clause Order by clause is used with SELECT statement for arranging retrieved data in sorted order. The Order by clause by default sorts the retrieved data in ascending order. To sort the data in descending order DESC keyword is used with Order by clause. Syntax of Order By SELECT column-list|* FROM table-name ORDER BY ASC | DESC; eid name age salary 401 Anu 22 9000 402 Shane 29 8000 403 Rohan 34 6000 404 Scott 44 10000 405 Tiger 35 8000 Using default Order by Consider the following Emp table,
- 117. SELECT * FROM Emp ORDER BY salary; The above query will return the resultant data in ascending order of the salary. eid name age salary 403 Rohan 34 6000 402 Shane 29 8000 405 Tiger 35 8000 401 Anu 22 9000 404 Scott 44 10000 SELECT * FROM Emp ORDER BY salary DESC; Will return table data in descending order.
- 118. Group By Clause Group by clause is used to group the results of a SELECT query based on one or more columns. It is also used with SQL functions to group the result from one or more tables. Syntax for using Group by in a statement. SELECT column_name, function(column_name) FROM table_name WHERE condition GROUP BY column_name
- 119. eid name age salary 401 Anu 22 9000 402 Shane 29 8000 403 Rohan 34 6000 404 Scott 44 9000 405 Tiger 35 8000 Example of Group by in a Statement Consider the following Emp table. Here we want to find name and age of employees grouped by their salaries or in other words, we will be grouping employees based on their salaries, hence, as a result, we will get a data set, with unique salaries listed, along side the first employee's name and age to have that salary. group by is used to group different row of data together based on any one column. SELECT name, age FROM Emp GROUP BY salary
- 120. SELECT name, salary FROM Emp WHERE age > 25 GROUP BY salary name salary Rohan 6000 Shane 8000 Scott 9000 Result will be. must remember that Group By clause will always come at the end of the SQL query, just like the Order by clause.
- 121. EXAMPLE 1.Write a query to display the name (first_name, last_name) and department ID of all employees in departments 30 or 100 in ascending order. 2. Write a query to display the last name, job, and salary for all employees whose job is that of a Programmer or a Shipping Clerk, and salary is not equal to $4,500, $10,000, or $15,000. 3. Write a query in SQL to display all the information for all employees who have the letters D, S, or N in their first name and also arrange the result in descending order by salary. 4. Write a query in SQL to display the employee ID, first name, job id, and department number for those employees who is working except the departments 50,30 and 80. 5. Write a query in SQL to display job ID, number of employees, sum of salary, and difference between highest salary and lowest salary for a job. 6. Write a query in SQL to display job Title, the difference between minimum and maximum salaries for those jobs which max salary within the range 12000 to 18000.
- 122. Ans 1: SELECT first_name, last_name, department_id FROM employees WHERE department_id IN (30, 100) ORDER BY department_id ASC; Ans 2: SELECT last_name, job_id, salary FROM employees WHERE job_id IN ('IT_PROG', 'SH_CLERK') AND salary NOT IN (4500,10000, 15000);
- 123. Ans 3: SELECT * FROM employees WHERE first_name LIKE '%D%' OR first_name LIKE '%S%' OR first_name LIKE '%N%' ORDER BY salary DESC; Ans 4: SELECT employee_id, first_name, job_id, department_id FROM employees WHERE department_id NOT IN (50, 30, 80);
- 124. Ans 5: SELECT job_id, COUNT(*), SUM(salary), MAX(salary)-MIN(salary) AS salary_difference FROM employees GROUP BY job_id; Ans 6: SELECT job_title, max_salary-min_salary AS salary_differences FROM jobs WHERE max_salary BETWEEN 12000 AND 18000; Sample table : jobs
- 125. 1. Write a query to list the number of jobs available in the employees table. 2. Write a query to get the total salaries payable to employees 3. Write a query to get the minimum salary from employees table. 4. Write a query to get the maximum salary of an employee working as a Programmer. 5. Write a query to get the average salary and number of employees working the department 90. 6. Write a query to get the highest, lowest, sum, and average salary of all employees. 7. Write a query to get the number of employees with the same job 8. Write a query to get the department ID and the total salary payable in each department 9. Write a query to get the average salary for each job ID excluding programmer. 10.Write a query to get the total salary, maximum, minimum, average salary of employees (job ID wise), for department ID 90 only.
- 126. 1.SELECT COUNT(DISTINCT job_id) FROM employees; 2. SELECT SUM(salary) FROM employees; 3. SELECT MAX(salary) FROM employees WHERE job_id = 'IT_PROG'; 5. SELECT AVG(salary),count(*) FROM employees WHERE department_id = 90; 7. SELECT job_id, COUNT(*) FROM employees GROUP BY job_id; 8. SELECT department_id, SUM(salary) FROM employees GROUP BY department_id; 9. SELECT job_id, AVG(salary) FROM employees WHERE job_id <> 'IT_PROG' GROUP BY job_id; 10. SELECT job_id, SUM(salary), AVG(salary), MAX(salary), MIN(salary) FROM employees WHERE department_id = '90' GROUP BY job_id; 11. SELECT job_id, MAX(salary) FROM employees GROUP BY job_id HAVING MAX(salary) >=4000;
- 127. SQL - Having Clause The HAVING Clause enables specify conditions that filter which group results appear in the results. The WHERE clause places conditions on the selected columns, whereas the HAVING clause places conditions on groups created by the GROUP BY clause. Syntax The following code block shows the position of the HAVING Clause in a query. SELECT FROM WHERE GROUP BY HAVING ORDER BY The HAVING clause must follow the GROUP BY clause in a query and must also precede the ORDER BY clause if used.
- 128. How a HAVING clause works IN SQL? •The select clause specifies the columns. •The from clause supplies a set of potential rows for the result. •The where clause gives a filter for these potential rows. •The group by clause divide the rows in a table into smaller groups. •The having clause gives a filter for these group rows.
- 129. Example Consider the CUSTOMERS table having the following records. +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
- 130. SQL - TOP, LIMIT or ROWNUM Clause The SELECT TOP clause is used to specify the number of records to return. The SELECT TOP clause is useful on large tables with thousands of records. Returning a large number of records can impact on performance. Example SELECT TOP 3 * FROM Customers; Example SELECT * FROM Customers LIMIT 3; SQL Server / MS Access Syntax: SELECT TOP number|percent column_name(s) FROM table_name WHERE condition;
- 131. The following SQL statement shows the equivalent example using ROWNUM: Oracle Syntax: SELECT column_name(s) FROM table_name WHERE ROWNUM <= number; MySQL Syntax: SELECT column_name(s) FROM table_name WHERE condition LIMIT number;
- 132. SQL Aliases SQL aliases are used to give a table, or a column in a table, a temporary name. Aliases are often used to make column names more readable. An alias only exists for the duration of the query. Alias Column Syntax SELECT column_name AS alias_name FROM table_name; Example SELECT CustomerID AS ID, CustomerName AS Customer FROM Customers;
- 133. Aliases can be useful when: • There are more than one table involved in a query • Functions are used in the query • Column names are big or not very readable • Two or more columns are combined together
- 134. SQL NULL Values What is a NULL Value? A field with a NULL value is a field with no value. If a field in a table is optional, it is possible to insert a new record or update a record without adding a value to this field. Then, the field will be saved with a NULL value. Note: A NULL value is different from a zero value or a field that contains spaces. A field with a NULL value is one that has been left blank during record creation! How to Test for NULL Values? It is not possible to test for NULL values with comparison operators, such as =, <, or <>. We will have to use the IS NULL and IS NOT NULL operators instead.
- 135. IS NULL Syntax SELECT column_names FROM table_name WHERE column_name IS NULL; The IS NULL Operator The IS NULL operator is used to test for empty values (NULL values). The following SQL lists all customers with a NULL value in the "Address" field: Example SELECT CustomerName, ContactName, Address FROM Customers WHERE Address IS NULL;
- 136. IS NOT NULL Operator The IS NOT NULL operator is used to test for non-empty values (NOT NULL values). The following SQL lists all customers with a value in the "Address" field: Example SELECT CustomerName, ContactName, Address FROM Customers WHERE Address IS NOT NULL;
- 137. SQL FOREIGN KEY Constraint A FOREIGN KEY is a key used to link two tables together. A FOREIGN KEY is a field (or collection of fields) in one table that refers to the PRIMARY KEY in another table. The table containing the foreign key is called the child table, and the table containing the Primary key is called the referenced or parent table. PersonID LastName FirstName Age 1 Hansen Ola 30 2 Svendson Tove 23 3 Pettersen Kari 20 "Persons" table:
- 138. OrderID OrderNumber PersonID 1 77895 3 2 44678 3 3 22456 2 4 24562 1 "Orders" table: The "PersonID" column in the "Persons" table is the PRIMARY KEY in the "Persons" table. The "PersonID" column in the "Orders" table is a FOREIGN KEY in the "Orders" table. The FOREIGN KEY constraint is used to prevent actions that would destroy links between tables. The FOREIGN KEY constraint also prevents invalid data from being inserted into the foreign key column, because it has to be one of the values contained in the table it points to.
- 139. SQL FOREIGN KEY on CREATE TABLE CREATE TABLE Orders ( OrderID int NOT NULL, OrderNumber int NOT NULL, PersonID int, PRIMARY KEY (OrderID), FOREIGN KEY (PersonID) REFERENCES Persons(PersonID) ); SQL FOREIGN KEY on ALTER TABLE ALTER TABLE Orders ADD FOREIGN KEY (PersonID) REFERENCES Persons(PersonID); ALTER TABLE Orders ADD CONSTRAINT FK_PersonOrder FOREIGN KEY (PersonID) REFERENCES Persons(PersonID);
- 140. DROP a FOREIGN KEY Constraint To drop a FOREIGN KEY constraint, use the following SQL: ALTER TABLE Orders DROP FOREIGN KEY FK_PersonOrder;
- 141. SQL CHECK Constraint The CHECK constraint is used to limit the value range that can be placed in a column. If you define a CHECK constraint on a single column it allows only certain values for this column. If you define a CHECK constraint on a table it can limit the values in certain columns based on values in other columns in the row. SQL CHECK on CREATE TABLE The following SQL creates a CHECK constraint on the "Age" column when the "Persons" table is created. The CHECK constraint ensures that you can not have any person below 18 years CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, CHECK (Age>=18) );
- 142. SQL CHECK on ALTER TABLE To create a CHECK constraint on the "Age" column when the table is already created, use the following SQL: ALTER TABLE Persons ADD CHECK (Age>=18); To allow naming of a CHECK constraint, and for defining a CHECK constraint on multiple columns, use the following SQL syntax: ALTER TABLE Persons ADD CONSTRAINT CHK_PersonAge CHECK (Age>=18 AND City='Sandnes’); ALTER TABLE Persons DROP CHECK CHK_PersonAge;
- 143. Super key in DBMS Definition of Super Key in DBMS: A super key is a set of one or more attributes (columns), which can uniquely identify a row in a table. How candidate key is different from super key? Candidate keys are selected from the set of super keys, the only thing we take care while selecting candidate key is: It should not have any redundant attribute. That’s the reason they are also termed as minimal super key. Let’s take an example to understand this: Table: Employee Emp_SSN Emp_Number Emp_Name --------- ---------- -------- 123456789 226 Steve 999999321 227 Ajeet 888997212 228 Chaitanya 777778888 229 Robert
- 144. Super keys: The above table has following super keys. All of the following sets of super key are able to uniquely identify a row of the employee table. • {Emp_SSN} • {Emp_Number} • {Emp_SSN, Emp_Number} • {Emp_SSN, Emp_Name} • {Emp_SSN, Emp_Number, Emp_Name} • {Emp_Number, Emp_Name} Candidate Keys: a candidate key is a minimal super key with no redundant attributes. The following two set of super keys are chosen from the above sets as there are no redundant attributes in these sets. {Emp_SSN} {Emp_Number} Only these two sets are candidate keys as all other sets are having redundant attributes that are not necessary for unique identification.
- 145. Super key vs Candidate Key 1. all the candidate keys are super keys. This is because the candidate keys are chosen out of the super keys. 2. How we choose candidate keys from the set of super keys? We look for those keys from which we cannot remove any fields. In the above example, we have not chosen {Emp_SSN, Emp_Name} as candidate key because {Emp_SSN} alone can identify a unique row in the table and Emp_Name is redundant. Primary key: A Primary key is selected from a set of candidate keys. This is done by database admin or database designer. We can say that either {Emp_SSN} or {Emp_Number} can be chosen as a primary key for the table Employee.
- 146. Candidate Key in DBMS Definition of Candidate Key in DBMS: A super key with no redundant attribute is known as candidate key. Candidate keys are selected from the set of super keys, the only thing we take care while selecting candidate key is that the candidate key should not have any redundant attributes. That’s the reason they are also termed as minimal super key. Candidate Key Example Lets take an example of table “Employee”. This table has three attributes: Emp_Id, Emp_Number & Emp_Name. Here Emp_Id & Emp_Number will be having unique values and Emp_Name can have duplicate values as more than one employees can have same name. Emp_Id Emp_Number Emp_Name ------ ---------- -------- E01 2264 Steve E22 2278 Ajeet E23 2288 Chaitanya E45 2290 Robert How many super keys the above table can have? 1. {Emp_Id} 2. {Emp_Number} 3. {Emp_Id, Emp_Number} 4. {Emp_Id, Emp_Name} 5. {Emp_Id, Emp_Number, Emp_Name} 6. {Emp_Number, Emp_Name} Lets select the candidate keys from the above set of super keys.
- 147. 1. {Emp_Id} – No redundant attributes 2. {Emp_Number} – No redundant attributes 3. {Emp_Id, Emp_Number} – Redundant attribute. Either of those attributes can be a minimal super key as both of these columns have unique values. 4. {Emp_Id, Emp_Name} – Redundant attribute Emp_Name. 5. {Emp_Id, Emp_Number, Emp_Name} – Redundant attributes. Emp_Id or Emp_Number alone are sufficient enough to uniquely identify a row of Employee table. 6. {Emp_Number, Emp_Name} – Redundant attribute Emp_Name. The candidate keys we have selected are: {Emp_Id} {Emp_Number}
- 148. Composite key in DBMS Definition of Composite key: A key that has more than one attributes is known as composite key. It is also known as compound key. Composite key Example Lets consider a table Sales. This table has four columns (attributes) – cust_Id, order_Id, product_code & product_count. cust_Id order_Id product_code product_count -------- -------- ------------ ------------- C01 O001 P007 23 C02 O123 P007 19 C02 O123 P230 82 C01 O001 P890 42
- 149. None of these columns alone can play a role of key in this table. • Column cust_Id alone cannot become a key as a same customer can place multiple orders, thus the same customer can have multiple entires. • Column order_Id alone cannot be a primary key as a same order can contain the order of multiple products, thus same order_Id can be present multiple times. • Column product_code cannot be a primary key as more than one customers can place order for the same product. • Column product_count alone cannot be a primary key because two orders can be placed for the same product count. Based on this, it is safe to assume that the key should be having more than one attributes: Key in above table: {cust_id, product_code} This is a composite key as it is made up of more than one attributes.
- 150. Subqueries • A subquery is a SQL query nested inside a larger query. • A subquery may occur in: • - A SELECT clause • - A FROM clause • A WHERE clause • In MySQL subquery can be nested inside a SELECT, INSERT, UPDATE, DELETE, SET, or DO statement or inside another subquery. • A subquery is usually added within the WHERE Clause of another SQL SELECT statement. • You can use the comparison operators, such as >, <, or =. The comparison operator can also be a multiple-row operator, such as IN, ANY, SOME, or ALL. • A subquery can be treated as an inner query, which is a SQL query placed as a part of another query called as outer query. • The inner query executes first before its parent query so that the results of the inner query can be passed to the outer query
- 151. Subquery Syntax : A subquery can return a scalar (a single value), a single row, a single column, or a table (one or more rows of one or more columns). These are called scalar, column, row, and table subqueries.
- 152. Using a subquery, list the name of the employees, paid more than ‘Austin' from emp_details . FIRST_NAME LAST_NAME EMAIL PHONE_NUMBER HIRE_DATE JOB_ID SALARY Steven King SKING 515.123.4567 17-Jun-87 AD_PRES 24000 Neena Kochhar NKOCHHAR 515.123.4568 21-Sep-89 AD_VP 17000 Lex De Haan LDEHAAN 515.123.4569 13-Jan-93 AD_VP 17000 AlexanderHunold AHUNOLD 590.423.4567 3-Jan-90 IT_PROG 9000 Bruce Ernst BERNST 590.423.4568 21-May-91 IT_PROG 6000 DavidAustin DAUSTIN 590.423.4569 25-Jun-97 IT_PROG 4800 Valli Pataballa VPATABAL 590.423.4560 5-Feb-98 IT_PROG 4800 Diana Lorentz DLORENTZ 590.423.5567 7-Feb-99 IT_PROG 4200 Nancy GreenbergNGREENBE 515.124.4569 17-Aug-94 FI_MGR 12000 Daniel Faviet DFAVIET 515.124.4169 16-Aug-94 FI_ACCOUNT 9000
- 153. MySQL Subqueries: Using Comparisons A subquery can be used before or after any of the comparison operators. The subquery can return at most one value. The value can be the result of an arithmetic expression or a column function. SQL then compares the value that results from the subquery with the value on the other side of the comparison operator. You can use the following comparison operators: Operator Description = Equal to > Greater than >= Greater than or equal to < Less than <= Less than or equal to != Not equal to <> Not equal to <=> NULL-safe equal to operator
- 154. SELECT employee_id,first_name,last_name,salary FROM employees WHERE salary > (SELECT AVG(SALARY) FROM employees); +-------------+-------------+------------+----------+ | employee_id | first_name | last_name | salary | +-------------+-------------+------------+----------+ | 100 | Steven | King | 24000.00 | | 101 | Neena | Kochhar | 17000.00 | | 102 | Lex | De Haan | 17000.00 | | 103 | Alexander | Hunold | 9000.00 | | 108 | Nancy | Greenberg | 12000.00 | | 109 | Daniel | Faviet | 9000.00 | | 120 | Matthew | Weiss | 8000.00 | | 121 | Adam | Fripp | 8200.00 | | 122 | Payam | Kaufling | 7900.00 | |- - - - - - - - - - - - - - - - - - - - - - - - - -| |- - - - - - - - - - - - - - - - - - - - - - - - - -|
- 155. Subqueries: Guidelines There are some guidelines to consider when using subqueries : - A subquery must be enclosed in parentheses. - Use single-row operators with single-row subqueries, and use multiple-row operators with multiple-row subqueries. - If a subquery (inner query) returns a null value to the outer query, the outer query will not return any rows when using certain comparison operators in a WHERE clause. Types of Subqueries The Subquery as Scalar Operand Comparisons using Subqueries Subqueries with ALL, ANY, IN, or SOME Row Subqueries Subqueries with EXISTS or NOT EXISTS Correlated Subqueries Subqueries in the FROM Clause
- 156. MySQL Subquery as Scalar Operand A scalar subquery is a subquery that returns exactly one column value from one row. A scalar subquery is a simple operand, and you can use it almost anywhere a single column value or literal is legal. If the subquery returns 0 rows then the value of scalar subquery expression in NULL and if the subquery returns more than one row then MySQL returns an error. SELECT customerNumber, checkNumber, amount FROM payments WHERE amount = (SELECT MAX(amount) FROM payments);
- 157. MySQL Subqueries with ALL, ANY, IN, or SOME The ALL operator compares value to every value returned by the subquery. Therefore ALL operator (which must follow a comparison operator) returns TRUE if the comparison is TRUE for ALL of the values in the column that the subquery returns. SELECT c1 FROM t1 WHERE c1 <> ALL (SELECT c1 FROM t2); SELECT c1 FROM t1 WHERE c1 NOT IN (SELECT c1 FROM t2); The following query selects the department with the highest average salary. The subquery finds the average salary for each department, and then the main query selects the department with the highest average salary. SELECT department_id, AVG(SALARY) FROM EMPLOYEES GROUP BY department_id HAVING AVG(SALARY)>=ALL (SELECT AVG(SALARY) FROM EMPLOYEES GROUP BY department_id);
- 158. The following query selects any employee who works in the location 1800. The subquery finds the department id in the 1800 location, and then the main query selects the employees who work in any of these departments. SELECT first_name, last_name,department_id FROM employees WHERE department_id= ANY (SELECT DEPARTMENT_ID FROM departments WHERE location_id=1800); Note: We have used ANY keyword in this query because it is likely that the subquery will find more than one departments in 1800 location. If you use the ALL keyword instead of the ANY keyword, no data is selected because no employee works in all departments of 1800 location When used with a subquery, the word IN (equal to any member of the list) is an alias for = ANY. Thus, the following two statements are the same:
- 159. MySQL Row Subqueries A row subquery is a subquery that returns a single row and more than one column value. You can use = , >, <, >=, <=, <>, !=, <=> comparison operators. See the following examples: Code: SELECT * FROM table1 WHERE (col1,col2) = (SELECT col3, col4 FROM table2 WHERE id = 10); SELECT * FROM table1 WHERE ROW(col1,col2) = (SELECT col3, col4 FROM table2 WHERE id = 10); mysql>SELECT first_name FROM employees WHERE ROW(department_id, manager_id) = (SELECT department_id, manager_id FROM departments WHERE location_id = 2800);
- 160. MySQL Subqueries with EXISTS or NOT EXISTS The EXISTS operator tests for the existence of rows in the results set of the subquery. If a subquery row value is found, EXISTS subquery is TRUE and in this case NOT EXISTS subquery is FALSE. From the following tables (employees) find employees (employee_id, first_name, last_name, job_id, department_id) who have at least one person reporting to them. SELECT employee_id, first_name, last_name, job_id, department_id FROM employees E WHERE EXISTS (SELECT * FROM employees WHERE manager_id = E.employee_id);
- 161. NOT EXISTS subquery almost always contains correlations. Here is an example : From the following table (departments and employees) find all departments (department_id, department_name) that do not have any employees. mysql> SELECT department_id, department_name FROM departments d WHERE NOT EXISTS (SELECT * FROM employees WHERE department_id = d.department_id); FROM clause A subquery can also be found in the FROM clause. These are called inline views. For example: SELECT contacts.last_name, subquery1.total_size FROM contacts, (SELECT site_name, SUM(file_size) AS total_size FROM pages GROUP BY site_name) subquery1 WHERE subquery1.site_name = contacts.site_name;
- 162. MySQL Correlated Subqueries A correlated subquery is a subquery that contains a reference to a table (in the parent query) that also appears in the outer query. MySQL evaluates from inside to outside. Following query find all employees who earn more than the average salary in their department. employees table: SELECT last_name, salary, department_id FROM employees e WHERE salary > (SELECT AVG(salary) FROM employees WHERE department_id = e.department_id);
- 163. From the employees and job_history tables display details of those employees who have changed jobs at least once. employees table: job_history tables: SELECT first_name, last_name, employee_id, job_id FROM employees E WHERE 1 <= (SELECT COUNT(*) FROM Job_history WHERE employee_id = E.employee_id);
- 164. JOIN
- 165. MySQL JOINS A join enables to retrieve records from two (or more) logically related tables in a single result set. JOIN clauses are used to return the rows of two or more queries using two or more tables that shares a meaningful relationship based on a common set of values. These values are usually the same column name and datatype that appear in both the participating tables being joined. These columns, or possibly a single column from each table, are called the join key or common key. Mostly but not all of the time, the join key is the primary key of one table and a foreign key in another table. The join can be performed as long as the data in the columns are matching. It can be difficult when the join involving more than two tables. It is a good practice to think of the query as a series of two table joins when the involvement of three or more tables in joins.
- 166. Types of MySQL Joins : •INNER JOIN •LEFT JOIN •RIGHT JOIN •FULL JOIN
- 167. •(INNER) JOIN: Select records that have matching values in both tables. •LEFT (OUTER) JOIN: Select records from the first (left-most) table with matching right table records. •RIGHT (OUTER) JOIN: Select records from the second (right-most) table with matching left table records. •FULL (OUTER) JOIN: Selects all records that match either left or right table records.
- 168. The SQL JOIN syntax The general syntax is: SELECT column-names FROM table-name1 JOIN table-name2 ON column-name1 = column-name2 WHERE condition The general syntax with INNER is: SELECT column-names FROM table-name1 INNER JOIN table-name2 ON column-name1 = column-name2 WHERE condition The INNER keyword is optional: it is the default as well as the most commonly used JOIN operation.
- 169. CUSTOMER Id(Primary key) FirstName LastName City Country Phone ORDER Id OrderDate OrderNumber CustomerId(ForeignKey) TotalAmount SQL JOIN Examples Problem: List all orders with customer information SELECT OrderNumber, TotalAmount, FirstName, LastName, City, Country FROM [Order] JOIN Customer ON [Order].CustomerId = Customer.Id
- 170. supplier_id supplier_name 10000 IBM 10001 Hewlett Packard 10002 Microsoft 10003 NVIDIA order_id supplier_id order_date 500125 10000 2013/05/12 500126 10001 2013/05/13 500127 10004 2013/05/14 We have a table called suppliers with two fields (supplier_id and supplier_name). We have another table called orders with three fields (order_id, supplier_id, and order_date). It contains the following data: SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers INNER JOIN orders ON suppliers.supplier_id = orders.supplier_id; supplier_id name order_date 10000 IBM 2013/05/12 10001 Hewlett Packard 2013/05/13
- 171. supplier_id supplier_name 10000 IBM 10001 Hewlett Packard 10002 Microsoft 10003 NVIDIA order_id supplier_id order_date 500125 10000 2013/05/12 500126 10001 2013/05/13 500127 10004 2013/05/14 LEFT OUTER JOIN- This type of join returns all rows from the LEFT-hand table specified in the ON condition and only those rows from the other table where the joined fields are equal. LEFT JOIN performs a join starting with the first (left-most) table and then any matching second (right-most) table records. LEFT JOIN and LEFT OUTER JOIN are the same.
- 172. This LEFT OUTER JOIN example would return all rows from the suppliers table and only those rows from the orders table where the joined fields are equal. If a supplier_id value in the suppliers table does not exist in the orders table, all fields in the orders table will display as <null> in the result set. supplier_id supplier_name order_date 10000 IBM 2013/05/12 10001 Hewlett Packard 2013/05/13 10002 Microsoft <null> 10003 NVIDIA <null> SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers LEFT JOIN orders ON suppliers.supplier_id = orders.supplier_id; The rows for Microsoft and NVIDIA would be included because a LEFT OUTER JOIN was used. However, the order_date field for those records contains a <null> value.
- 173. RIGHT OUTER JOIN Another type of join is called a MySQL RIGHT OUTER JOIN. This type of join returns all rows from the RIGHT-hand table specified in the ON condition and only those rows from the other table where the joined fields are equal (join condition is met). This RIGHT OUTER JOIN example would return all rows from the orders table and only those rows from the suppliers table where the joined fields are equal. If a supplier_id value in the orders table does not exist in the suppliers table, all fields in the suppliers table will display as <null> in the result set. SELECT column-names FROM table-name1 RIGHT OUTER JOIN table-name2 ON column-name1 = column-name2 WHERE condition
- 174. SELECT orders.order_id, orders.order_date, suppliers.supplier_name FROM suppliers RIGHT JOIN orders ON suppliers.supplier_id = orders.supplier_id; order_id order_date supplier_name 500125 2013/08/12 Apple 500126 2013/08/13 Google 500127 2013/08/14 <null> supplier_id supplier_name 10000 Apple 10001 Google order_id supplier_id order_date 500125 10000 2013/08/12 500126 10001 2013/08/13 500127 10002 2013/08/14
- 175. The SQL FULL JOIN- FULL JOIN returns all matching records from both tables whether the other table matches or not. FULL JOIN can potentially return very large datasets. Mysql does not support FULL JOIN so you have to combine JOIN – UNION AND LEFT JOIN. MYSQL – UNION OPERATOR
- 176. If we want to display the present and previous details of jobs of all employees once the following MySQL statement can be used. Select employee_id, job_id FROM employees UNION Select employee_id,job_id FROM job_history; MySQL UNION ALL The UNION ALL operator does not eliminate duplicate selected rows and returns all rows. The UNION ALL operator returns all the rows from both the queries and no duplication elimination happens.
- 177. MySQL UNION vs UNION ALL In MySQL the UNION operator returns the combined result from multiple SELECT statements into a single result set but exclude the duplicate rows where as the UNION ALL operator avoids the elimination of duplicate selected rows and returns all rows. Example If we want to display the present and previous details of jobs of all employees, and they may appear more than once, the following MySQL statement can be used. Select employee_id, job_id,department_id FROM employees UNION ALL Select employee_id,job_id,department_id FROM job_history;
- 178. Query Processing in DBMS The main goal of creating a database is to store the related data at one place, access and manipulate them as and when it is required by the user. Accessing and manipulating the data should be done efficiently i.e.; it should be accessed easily and quickly. But a database is a system and the users are either another system or application or a person. The user can request the data in a language that he understands. But DBMS has its own language (SQL) which it understands. Hence the users are asked to query the database in its language – SQL. This SQL is a high level language created to build a bridge between user and DBMS for their communication. But the underlying systems in the DBMS will not understand SQL. There has to be some low level language which these systems can understand. Usually any query written in SQL is converted into low level language using relational algebra which system can understand. But it will be difficult for any user to directly write relational algebra kind of queries. It requires thorough knowledge of it. Hence what DBMS does is it asks its users to write query in SQL. It verifies the code written by the user and then converts them into low level languages. It then selects the best execution path and executes the query and gets the data from internal memory. All these processes are together known as query processing.
- 179. Query Processing is the step by step process of breaking the high level language into low level language which machine can understand and perform the requested action for user. Query processor in the DBMS performs this task.
- 180. Above diagram depicts how a query is processed in the database to show the result. When a query is submitted to the database, it is received by the query compiler. It then scans the query and divides it into individual tokens. Once the tokens are generated, they are verified for their correctness by the parser. Then the tokenized queries are transformed into different possible relational expressions, relational trees and relational graphs (Query Plans). Query optimizer then picks them to identify the best query plan to process. It checks in the system catalog for the constraints and indexes and decides the best query plan. It generates different execution plans for the query plan. The query execution plan then decides the best and optimized execution plan for execution. The command processor then uses this execution plan to retrieve the data from the database and returns the result. This is an overview of how a query processing works.
- 182. • There are four phases in a typical query processing. • Parsing and Translation • Query Optimization • Evaluation or query code generation • Execution in DB’s runtime processor It is done in the following steps: Step-1: Parser: During parse call, the database performs the following checks- Syntax check, Semantic check and Shared pool check, after converting the query into relational algebra. Parser performs the following checks as (refer detailed diagram): 1)Syntax check – concludes SQL syntactic validity. Example: SELECT * FORM employee Here error of wrong spelling of FROM is given by this check.
- 183. 2)Semantic check – determines whether the statement is meaningful or not. Example: query contains a tablename which does not exist is checked by this check. 3)Shared Pool check – Every query possess a hash code during its execution. So, this check determines existence of written hash code in shared pool if code exists in shared pool then database will not take additional steps for optimization and execution. Hard Parse and Soft Parse – If there is a fresh query and its hash code does not exist in shared pool then that query has to pass through from the additional steps known as hard parsing otherwise if hash code exists then query does not passes through additional steps. It just passes directly to execution engine (refer detailed diagram). This is known as soft parsing. Hard Parse includes following steps – Optimizer and Row source generation.
- 184. Step-2: Optimizer: During optimization stage, database must perform a hard parse atleast for one unique DML statement and perform optimization during this parse. This database never optimizes DDL unless it includes a DML component such as subquery that require optimization. It is a process in which multiple query execution plan for satisfying a query are examined and most efficient query plan is satisfied for execution. Database catalog stores the execution plans and then optimizer passes the lowest cost plan for execution. Row Source Generation – The Row Source Generation is a software that receives a optimal execution plan from the optimizer and produces an iterative execution plan that is usable by the rest of the database. the iterative plan is the binary program that when executes by the sql engine produces the result set. Step-3: Execution Engine: Finally runs the query and display the required result.
- 185. In query processing, we will actually understand how these queries are processed and how they are optimized. The first step is to transform the query into a standard form. A query is translated into SQL and into a relational algebraic expression. During this process, Parser checks the syntax and verifies the relations and the attributes which are used in the query. The second step is Query Optimizer. In this, it transforms the query into equivalent expressions that are more efficient to execute. The third step is Query evaluation. It executes the above query execution plan and returns the result.
- 186. Translating SQL Queries into Relational Algebra Example SELECT Ename FROM Employee WHERE Salary > 5000; Translated into Relational Algebra Expression σ Salary > 5000 (π Ename (Employee)) OR π Ename (σ Salary > 5000 (Employee)) query execution plan A sequence of primitive operations that can be used to evaluate a query is a Query Execution Plan or Query Evaluation Plan. The above diagram indicates that the query execution engine takes a query execution plan and returns the answers to the query. Query Execution Plan minimizes the cost of query evaluation.
- 187. Query Optimization Query: A query is a request for information from a database. Query Plans: A query plan (or query execution plan) is an ordered set of steps used to access data in a SQL relational database management system. Query Optimization: A single query can be executed through different algorithms or re-written in different forms and structures. Hence, the question of query optimization comes into the picture – Which of these forms or pathways is the most optimal? The query optimizer attempts to determine the most efficient way to execute a given query by considering the possible query plans. Importance: The goal of query optimization is to reduce the system resources required to fulfill a query, and ultimately provide the user with the correct result set faster.
- 188. First, it provides the user with faster results, which makes the application seem faster to the user. Secondly, it allows the system to service more queries in the same amount of time, because each request takes less time than unoptimized queries. Thirdly, query optimization ultimately reduces the amount of wear on the hardware (e.g. disk drives), and allows the server to run more efficiently (e.g. lower power consumption, less memory usage). There are two methods of query optimization. 1. Cost based Optimization (Physical) This is based on the cost of the query. The query can use different paths based on indexes, constraints, sorting methods etc. This method mainly uses the statistics like record size, number of records, number of records per block, number of blocks, table size, whether whole table fits in a block, organization of tables, uniqueness of column values, size of columns etc.
- 189. 2. Heuristic Optimization (Logical) This method is also known as rule based optimization. This is based on the equivalence rule on relational expressions; hence the number of combination of queries get reduces here. Hence the cost of the query too reduces. This method creates relational tree for the given query based on the equivalence rules. These equivalence rules by providing an alternative way of writing and evaluating the query, gives the better path to evaluate the query. This rule need not be true in all cases. It needs to be examined after applying those rules. Suppose we have a query to retrieve the students with age 18 and studying in class DESIGN_01. We can get all the student details from STUDENT table, and class details from CLASS table. We can write this query in two different ways.
- 190. Here both the queries will return same result. But when we observe them closely we can see that first query will join the two tables first and then applies the filters. That means, it traverses whole table to join, hence the number of records involved is more. But he second query, applies the filters on each table first. This reduces the number of records on each table (in class table, the number of record reduces to one in this case!). Then it joins these intermediary tables. Hence the cost in this case is comparatively less.
- 191. Measure of query cost There are multiple possible evaluation plans for a query, and it is important to be able to compare the alternatives in terms of their (estimated) cost, and choose the best plan. To do so, we must estimate the cost of individual operations, and combine them to get the cost of a query evaluation plan. The cost of query evaluation can be measured in terms of a number of different resources, including disk accesses, CPU time to execute a query, and, in a distributed or parallel database system, the cost of communication. https://www.youtube.com/watch?v=rKN60UnVsMw In large database systems, the cost to access data from disk is usually the most important cost, since disk accesses are slow compared to in-memory operations. Moreover, CPU speeds have been improving much faster than have disk speeds. Thus, it is likely that the time spent in disk activity will continue to dominate the total time to execute a query. The CPU time taken for a task is harder to estimate since it depends on low-level details of the execution code. Although real-life query optimizers do take CPU costs into account.
- 192. Evaluation of Expressions in DBMS There are two methods of evaluating the query. Materialization In this method, queries are broken into individual queries and then the results of which are used to get the final result. To be more specific, suppose there is a requirement to find the students who are studying in class ‘DESIGN_01’. SELECT * FROM STUDENT s, CLASS c WHERE s.CLASS_ID = c.CLASS_ID AND c.CLASS_NAME = ‘DESIGN_01’; Here we can observe two queries: one is to select the CLASS_ID of ‘DESIGN_01’ and another is to select the student details of the CLASS_ID retrieved in the first query. The DBMS also does the same. It breaks the query into two as mentioned above. Once it is broken, it evaluates the first query and stores it in the temporary table in the memory. This temporary table data will be then used to evaluate the second query.
- 193. This is the example of two level queries in materialization method. We can have any number of levels and so many numbers of temporary tables. Although this method looks simple, the cost of this type of evaluation is always more. It takes the time to evaluate and write into temporary table, then retrieve from this temporary table and query to get the next level of result and so on. Hence cost of evaluation in this method is: Cost = cost of individual SELECT + cost of write into temporary table
- 194. Pipelining In this method, DBMS do not store the records into temporary tables. Instead, it queries each query and result of which will be passed to next query to process and so on. It will process the query one after the other and each will use the result of previous query for its processing. In the example above, CLASS_ID of DESIGN_01 is passed to the STUDENT table to get the student details. In this method no extra cost of writing into temporary tables. It has only cost of evaluation of individual queries; hence it has better performance than materialization.
- 195. Commit, Rollback and Savepoint SQL commands Transaction Control Language(TCL) commands are used to manage transactions in the database. These are used to manage the changes made to the data in a table by DML statements. It also allows statements to be grouped together into logical transactions. COMMIT command COMMIT command is used to permanently save any transaction into the database. When we use any DML command like INSERT, UPDATE or DELETE, the changes made by these commands are not permanent, until the current session is closed, the changes made by these commands can be rolled back. To avoid that, we use the COMMIT command to mark the changes as permanent. Following is commit command's syntax, COMMIT;
- 196. ROLLBACK command This command restores the database to last commited state. It is also used with SAVEPOINT command to jump to a savepoint in an ongoing transaction. If we have used the UPDATE command to make some changes into the database, and realise that those changes were not required, then we can use the ROLLBACK command to rollback those changes, if they were not commited using the COMMIT command. Following is rollback command's syntax, ROLLBACK TO savepoint_name;
- 197. SAVEPOINT command SAVEPOINT command is used to temporarily save a transaction so that you can rollback to that point whenever required. Following is savepoint command's syntax, SAVEPOINT savepoint_name; In short, using this command we can name the different states of our data in any table and then rollback to that state using the ROLLBACK command whenever required. Using Savepoint and Rollback Following is the table class, id name 1 Abhi 2 Adam 4 Alex
- 198. INSERT INTO class VALUES(5, 'Rahul'); COMMIT; UPDATE class SET name = 'Abhijit' WHERE id = '5'; SAVEPOINT A; INSERT INTO class VALUES(6, 'Chris'); SAVEPOINT B; INSERT INTO class VALUES(7, 'Bravo'); SAVEPOINT C; SELECT * FROM class; The resultant table will look like, id name 1 Abhi 2 Adam 4 Alex 5 Abhijit 6 Chris 7 Bravo Now let's use the ROLLBACK command to roll back the state of data to the savepoint B. Now let's use the ROLLBACK command to roll back the state of data to the savepoint B. ROLLBACK TO B; SELECT * FROM class;
- 199. id name 1 Abhi 2 Adam 4 Alex 5 Abhijit 6 Chris Now let's again use the ROLLBACK command to roll back the state of data to the savepoint A ROLLBACK TO A; SELECT * FROM class; Now the table will look like, id name 1 Abhi 2 Adam 4 Alex 5 Abhijit