DevOps for Data Engineers - Automate Your Data Science Pipeline with Ansible, Python and Kubernetes
0 likes394 views

- The document discusses automating data science pipelines with DevOps tools like Ansible, Packer, and Kubernetes. - It covers obtaining data, exploring and modeling data, and how to automate infrastructure setup and deployment with tools like Packer to build machine images and Ansible for configuration management. - The rise of DevOps and its cultural aspects are discussed as well as how tools like Packer, Ansible, Kubernetes can help automate infrastructure and deploy machine learning models at scale in production environments.











































![Hashicorp Packer: Image Build Automation
packer build rhel8.json
"builders": [ {
"type": "virtualbox-iso",
"boot_command": [
"<up><wait><tab>",
" text inst.ks=http://{{ .HTTPIP }}:{{ .HTTPPort }}/{{user `vm_name`}}.cfg",
"<enter><wait>"
]}],
"provisioners": [
{
"type": "ansible",
"playbook_file": "{{user `playbook_file`}}"
}]
43](https://image.slidesharecdn.com/05-mihaicriveti-devopsfordataengineers-automateyourdatasciencepipelinewithansiblepythonandkubernetes-211023131814/85/DevOps-for-Data-Engineers-Automate-Your-Data-Science-Pipeline-with-Ansible-Python-and-Kubernetes-52-320.jpg)


DevOps for Data Engineers - Automate Your Data Science Pipeline with Ansible, Python and Kubernetes
- 1. DevOps for Data Engineers Automate your Data Science pipeline with Ansible, Python and Kubernetes Mihai Criveti 2nd September 2019 1
- 2. 1 Introduction 2 Data Science Landscape 3 Process and Flow 4 The Data 5 Data Science Toolkit 6 The Big Data Challange 7 Cloud Computing Solutions 8 The rise of DevOps 10 Automate Your Infrastructure with Packer and Ansible 2
- 4. 3
- 5. Speaker Bio Mihai Criveti, IBM • Designs and builds multi-cloud customer solutions for Cloud Native applications, big data analytics and machine learning workloads. • Pursuing a MSc in Data Science at UCD. • Leads the Cloud Native competency for IBM Cloud Solutioning. 4
- 6. 2 Data Science Landscape
- 7. What is Data Science Data Science Multi-disciplinary field that brings together Computer Science, Statistics/Machine Learning, and Data Analysis to understand and extract insights from ever-increasing amounts of data. Machine Learning The science of getting computers to act without being explicitly programmed. Deep Learning Family of machine learning methods based on learning data representations, as opposed to task-specific algorithms. Learning can be supervised, semi-supervised or unsupervised. AI Intelligent machines that work and react like humans. 5
- 8. Moving Towards Big Data Figure 1: Powerful models and big data support Machine Learning 6
- 9. Data Scientist Domain Data Engineering: • Linux, Cloud, Big Data Platforms. • Streaming, big data pipelines. Software Development • Coding skills, such as Python, R, SQL. • Development practices: Agile, DevOps, CI/CD and using GitOps effectively. Figure 2: Data Scientist Venn Diagram “While data scientists are recognised for their brilliant algorithms, up to 80% of their time could be spent collecting, cleaning and organising data.” 1 1 forbes.com/sites/forbestechcouncil/2019/03/01/radical-change-is-coming-to-data-science-jobs 7
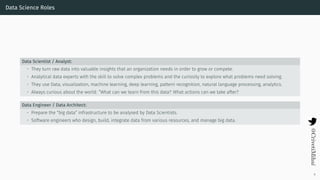
- 10. Data Science Roles Data Scientist / Analyst: • They turn raw data into valuable insights that an organization needs in order to grow or compete. • Analytical data experts with the skill to solve complex problems and the curiosity to explore what problems need solving. • They use Data, visualization, machine learning, deep learning, pattern recognition, natural language processing, analytics. • Always curious about the world: ”What can we learn from this data? What actions can we take after? Data Engineer / Data Architect: • Prepare the “big data” infrastructure to be analysed by Data Scientists. • Software engineers who design, build, integrate data from various resources, and manage big data. 8
- 11. 3 Process and Flow
- 12. Example ML Flow Stage Description 01. Business Understanding Ask relevant questions, define objectives 02. Data Mining Gather the necessary data 03. Data Cleaning Scrub and fix data inconsistencies 04. Data Exploration Form hyphothesis about the data 05. Feature Engineering Select / construct important features 06. Predictive Modeling Train Machine Learning Models 07. Data Visualization Communicate findings with key stakeholder 08. Data Automation Automate and deploy ml models in production 9
- 13. Often, it’s a manual process Figure 3: Pen and paper - planning 10
- 14. Data Science is awesome Data Science is OSEMN (pronounced AWESOME!)2 - an interactive process that consists, largely, of the following steps: 1. Inquire: ask a meaningful question. 2. Obtain: get the required data. 3. Scrub: clean the data. 4. Explore: learn about your data, try stuff. 5. Model: create a couple of models and test them. 6. iNterpret: gain insight from data, present it in a usable form (reports, dashboards, applications, etc). 2 O’Reilly - “Data Science at the Command Line, Facing the Future with Time-Tested Tools, Jeroen Janssens” 11
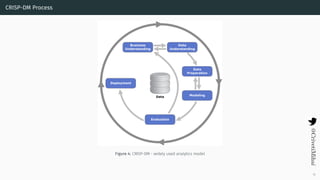
- 15. CRISP-DM Process Figure 4: CRISP-DM - widely used analytics model 12
- 16. Design Thinking Figure 5: Design Thinking 13
- 17. Data Development Lifecycle Figure 6: Development, Data and Analytics Lifecycle 14
- 18. 4 The Data
- 19. Data is fundamental Figure 7: Data and the AI Ladder 15
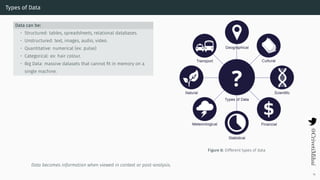
- 20. Types of Data Data can be: • Structured: tables, spreadsheets, relational databases. • Unstructured: text, images, audio, video. • Quantitative: numerical (ex: pulse) • Categorical: ex: hair colour. • Big Data: massive datasets that cannot fit in memory on a single machine. Figure 8: Different types of data Data becomes information when viewed in context or post-analysis. 16
- 21. Obtaining Data Private / Enterprise Data • Private data can often be found in: Data warehouse, SQL Database. • NoSQL store, Data Lakes or HDFS, document repositories. • Private wiks, ERP and CRM platforms, object storage and more often then not, spreadsheets. Public Data • Weather, social media, location / geographical data, stock data, public internet data (scraping), wikis, Eurostat, kaggle, government data portal - are all sources of external data. Data compliance, governance and security are key to a successful data strategy. 17
- 22. Data Portal Figure 9: Open Data portals such as data.gov.ie 18
- 23. Common Data Formats • XML, JSON, YAML • CSV, TSV, Parquet, XLSX • Markdown, HTML, DOCX • TXT, PDF • Audio, Video • Data APIs that return JSON or XML • Streaming data • SQL and other database formats • HDFS and other big data stores or encapsulated data on object storage 19
- 24. Big Data Figure 10: The 4 Vs of Big Data 20
- 25. 5 Data Science Toolkit
- 26. 5 Data Science Toolkit Figure 11: Big Data Landscape by Firstmark 21
- 27. Tools Data Scientists use • Mathematics - Linear Algebra, Statistics, Combinatorics • Some of them use R - focusing on statistics • A lot of them use Python - usually with Jupyter notebook as a front-end • Libraries such as Pandas and Numpy are very handy! • Natural Language Processing with NLTK • or Machine Learning libraries - Scikit-Learn, Tensorflow or PyTorch • SQL and databases tend to be quite popular. After all, where does data live? • NoSQL databases such as MongoDB are quite useful too… • And a whole bunch of Big Data tools: Hadoop, Spark, Kafka, etc. • They write papers too, so Markdown and LaTeX come in handy! • Lots of code, so typical software development tools (git, IDEs, CI/CD, etc.) • Processes (SCRUM, Agile, Lean, CRISP-DM, Design Thinking) 22
- 28. Tools to IOSEMN process +-----------------+ Project Management / Lifecycle | INQUIRE | Git, Github, Gitlab (Project documentation) +-----------------+ Documentation systems v +------------------+ Requests, APIs, sensors, surveys | OBTAIN | SQL, CSV, JSON, XLS, NoSQL, Hadoop, Spark +------------------+ Store / Cache data locally (SQLite, PostgreSQL) v (Gather internal and external data) +-----------------+ Jupyter Notebook | SCRUB | Regular Expression (re), BeautifulSoup +-----------------+ SQLite, ETL, Glue 23
- 29. Tools (continued) +-----------------+ Jupyter Notebook | EXPLORE | Pandas, Orange +-----------------+ Matplotlib ^ v (Explore and understand the data) +-----------------+ SciKit-Learn, Tensorflow | MODEL | PyTorch, NumPy +-----------------+ Machine Learning RE-INQUIRE | (Model: predict, check accuracy, evaluate model) ^ +-----------------+ Jupyter Notebook, MatplotLib +--------- | INTERPRET | Bokeh, D3.JS, XLSXWriter +-----------------+ Dashboards, Reports, etc. (Choose a good representation, interpret the results) 24
- 30. Jupyter Lab / Notebook Figure 12: Jupyter Notebook 25
- 31. Graphing and Dashboards Figure 13: Grafana: dashboard for time series analytics 26
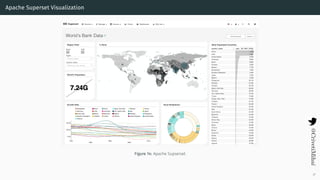
- 32. Apache Superset Visualization Figure 14: Apache Supserset 27
- 33. Geospacial Data Visualization Figure 15: Visualize geospatial data with deck.gl 28
- 34. Local Cloud - Docker Compose version: '3' services: jupyter: image: cmihai/genealgo-dev:v1 container_name: genealgo-dev volumes: - './notebooks:/notebooks' ports: - '9000:9000' 29
- 35. Composable Environments +-----------------+ | Jupyter | PYTHON | ports:9000 +---------------------------------+ | vol: /notebooks | | | (Anaconda 3) +-----------------+ | +---------|-------+ | | | | | +---------v-------+ +-----v------+ +-----v-----+ | PostgreSQL | NOSQL: | REDIS | | MONGODB | SQL | | | | | | | | | | | | | | | | | | +-----------------+ +------------+ +-----------+ 30
- 36. Machine Learning Frameworks Figure 16: Architecture: Jupyter Notebook using Keras with Tensorflow 31
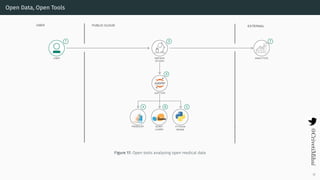
- 37. Open Data, Open Tools Figure 17: Open tools analysing open medical data 32
- 38. 6 The Big Data Challange
- 39. 6 The Big Data Challange Making sense of ever growing datasets through automation, machine learning and Big Data pipelines. 33
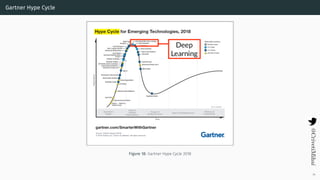
- 40. Gartner Hype Cycle Figure 18: Gartner Hype Cycle 2018 34
- 41. 7 Cloud Computing Solutions
- 42. Cloud Computing Cloud Computing is a model for enabling convenient, on-demand network access to a shared pool of configurable computing resources that can be rapidly provisioned and released with minimal management effort or service provider interaction. 35
- 43. Why Cloud in Data Science 1. Setting up environments with ease. 2. Access to virtually unlimited resources, GPU computing, etc. 3. Free access to lite tiers from most providers. 4. You’re likely already using it. Github? Kaggle notebooks? Google Docs? Dropbox? AWS Free Tier? JupyterHub? 36
- 44. Cloud Native Architectures • Take advantage of modern techiques, PaaS, multi-cloud, microservice design, agile development, containers, CI/CD, DevOps. • Quickly scale-out to thousands of CPU or GPU cores. • Store limitless ammounts of data. • Process events in real time. • Pay only for what you consume. 37
- 45. Machine Learning as a Service Figure 19: IBM Watson Machine Learning Services 38
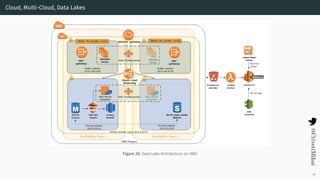
- 46. Cloud, Multi-Cloud, Data Lakes Figure 20: Data Lake Architecture on AWS 39
- 47. 8 The rise of DevOps
- 48. 8 The rise of DevOps DevOps: People, Processes and Tools working together to bring continuous delivery of value to clients. 40
- 49. Collaborate to continuously deliver Figure 21: Practices to implement DevOps 41
- 50. Cultural Transformation • Culture: Build trust and align your team with better communication and transparency. • Discover: Understand the problem domain and align on common goals. • Think: Know your audience and meet its needs faster than the competition. • Develop: Collaborate to build, continuously integrate and deliver high-quality code. • Reason: Apply AI techniques so that you can make better decisions. • Operate: Harness the power of the cloud to quickly get your minimum viable product (MVP) into production, and monitor and manage your applications to a high degree of quality and meet your service level agreements. Grow or shrink your resources based on demand. • Learn: Gain insights from your users as they interact with your application. 42
- 51. 10 Automate Your Infrastructure with Packer and Ansible
- 52. Hashicorp Packer: Image Build Automation packer build rhel8.json "builders": [ { "type": "virtualbox-iso", "boot_command": [ "<up><wait><tab>", " text inst.ks=http://{{ .HTTPIP }}:{{ .HTTPPort }}/{{user `vm_name`}}.cfg", "<enter><wait>" ]}], "provisioners": [ { "type": "ansible", "playbook_file": "{{user `playbook_file`}}" }] 43
- 53. Packer building a VirtualBox image for RHEL 8 using Kickstart Automated Install Figure 22: Image Build with Packer 44
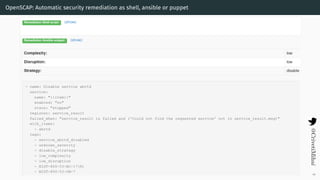
- 54. OpenSCAP: Automatic security remediation as shell, ansible or puppet 45
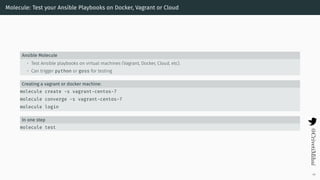
- 55. Molecule: Test your Ansible Playbooks on Docker, Vagrant or Cloud Ansible Molecule • Test Ansible playbooks on virtual machines (Vagrant, Docker, Cloud, etc). • Can trigger python or goss for testing Creating a vagrant or docker machine: molecule create -s vagrant-centos-7 molecule converge -s vagrant-centos-7 molecule login In one step molecule test 46
- 56. Kubernetes: Container Orchestration at Scale Figure 24: Kubernetes is Desired State Management 47