Efficient frequent pattern mining in distributed system
Download as PPTX, PDF1 like1,191 views

The document discusses efficient frequent pattern mining within distributed systems, focusing on association rule mining as a method for extracting actionable knowledge from large data sets. It outlines the importance of data mining in managing the challenges of massive databases and reviews existing literature in the field, highlighting significant research and algorithms developed over the years. Additionally, it identifies future work that could enhance system efficiency through improvements in the distributed setup and processing of large data inputs.




![The association rule mining algorithm is given as below:
» Input: D, ,
» Output: R(D, , )
» 1: Compute F(D, )
» 2: R := {}
» 3: for all I 2 F do
» 4: R := R [ I ) {}
» 5: C1 := {{i} | i 2 I};
» 6: k := 1;
» 7: while Ck 6= {} do
» 8: // Extract all heads of confident association rules
» 9: Hk := {X 2 Ck | confidence(I X ) X,D) }
» 10: // Generate new candidate heads
» 11: for all X, Y 2 Hk,X[i] = Y [i] for 1 i k−1, and X[k] < Y [k] do
» 12: I = X [ {Y [k]}
» 13: if 8J I, |J| = k : J 2 Hk then
» 14: Ck+1 := Ck+1 [ I
» 15: end if
» 16: end for
» 17: k++
» 18: end while
» 19: // Cumulate all association rules
» 20: R := R [ {I X ) X | X 2 H1 [ · · · [ Hk}
» 21: end](https://image.slidesharecdn.com/efficientfrequentpatternminingindistributedsystem-130918043234-phpapp02/85/Efficient-frequent-pattern-mining-in-distributed-system-5-320.jpg)








Efficient frequent pattern mining in distributed system
- 1. Efficient Frequent Pattern Mining In Distributed Systems
- 2. Content 1. Abstract 2. Introduction 3. Literature Survey 4. Work Done Till Now 5. Block Diagram 6. Scope Of The Project 7. References
- 3. Abstract Data Mining the domain of our project , is a newly developed sub- field of computer science engineering , it is the analysis step of Knowledge discovery in databases(KDD ) process and is used for extraction of data from a huge data set and make it understandable for further use. Among the Six classes of data mining our choice of interest and our project area is the Association Rule Mining. We will be applying this class of data mining in an efficient and frequent pattern for the mining of knowledge or data from Distributed System , which can be explained as a collection of set of computers that act , work and appear as one large computer.
- 4. Introduction Progress in digital data acquisition, distribution, retrieval and storage technology has resulted in the growth of massive databases. One of the greatest challenges facing organizations and individuals is how to turn their rapidly expanding data collections into accessible, and actionable knowledge. Distributed Systems are collections of computers that act and work together and appear as a large super system with a huge processing speed. The association rule mining , which is one of the six classes of Data mining, is our area of project and is a solution to the above problem. The general form of Association Rule Mining is : X1,X2,X3,…..,Xn->Y Which implies that all attributes X1,X2,..,Xn predict Y.
- 5. The association rule mining algorithm is given as below: » Input: D, , » Output: R(D, , ) » 1: Compute F(D, ) » 2: R := {} » 3: for all I 2 F do » 4: R := R [ I ) {} » 5: C1 := {{i} | i 2 I}; » 6: k := 1; » 7: while Ck 6= {} do » 8: // Extract all heads of confident association rules » 9: Hk := {X 2 Ck | confidence(I X ) X,D) } » 10: // Generate new candidate heads » 11: for all X, Y 2 Hk,X[i] = Y [i] for 1 i k−1, and X[k] < Y [k] do » 12: I = X [ {Y [k]} » 13: if 8J I, |J| = k : J 2 Hk then » 14: Ck+1 := Ck+1 [ I » 15: end if » 16: end for » 17: k++ » 18: end while » 19: // Cumulate all association rules » 20: R := R [ {I X ) X | X 2 H1 [ · · · [ Hk} » 21: end
- 6. LITERATURE SURVEY » Frequent pattern mining has been a focused theme in data mining research for over a decade. » Abundant literature has been dedicated to this research and tremendous progress has been made till now. » It ranges from efficient and scalable algorithms for frequent itemset mining in transaction databases to numerous research frontiers, such as sequential pattern mining, structured pattern mining , correlation mining, associative classification, and frequent pattern- based clustering, as well as their broad applications.
- 7. » Till date there had been a huge literature present for this research topic, some of the IEEE papers which we have gone through , we are naming a few of those paper’s below : 1. Efficient and scalable methods for mining frequent patterns. 2.Mining interesting frequent patterns. 3. Impact to data analysis and mining applications. 4.Applications of frequent patterns and Research Directions.
- 8. Work Done Till Now In this part of the presentation , we will put a light on the various research works that have been done till now on the entitled project and will be naming a few of them in our presentation. 1 . A Fast Algorithm for Mining Association Rules Title of paper: A Fast Algorithm for Mining Association Rules Author : Rakesh agarwal and Ramakrishna Srikant Year of Publication: 1997 2. Mining Frequent Patterns without Candidate Generation Title of paper: Mining Frequent Patterns without Candidate Generation Author : Jiwei Han, Jian Pei, Yiwen Yin Year of Publication: 1997
- 9. 3. Improved Association Rule Mining Algorithim for large dataset. Title of the project: Improved association rule mining for large dataset . Author: Tanu Arora , Rahul Yadav Year of Publication : 2011
- 10. Block Diagram 1. General working of Data Mining.
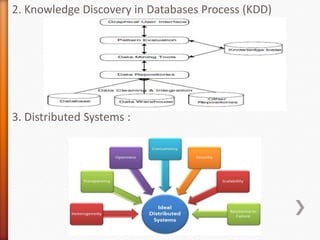
- 11. 2. Knowledge Discovery in Databases Process (KDD) 3. Distributed Systems :
- 12. Future Work The prescribed work is implemented in a local area network, which can be extended to WAN as a future work. An improvement could be made in the efficiency of the system when number of computers are increased in the distributed system. We can also improve the efficiency of the algorithm when large Data Sets are given as input files to the tool.
- 13. References 1. R. Agarwal, C.Faloutsos, and A.Swami, “Efficient Similarity Search in Sequence Databases, “Proc. Fourth Int’l Conf. foundations of data organization and Algorithm, Oct 1993 2. Data Mining and concepts, Morgan Kaufmann publishers,2006,2nd edition By-Han and Kamber 3. Data mining techniques, University press, 2011,2nd edition By-Arun K.Pujari 4. R.Agrawal, T.Imielinski, and A.Swami, “ Database Mining: A performance perspective “IEEE Trans. Knowledge nnd Dada Engineering, vol.5 ,pp. 914. 5. Software Engineering, Pearson Education, 2007