





































Engineering patterns for implementing data science models on big data platforms
- 1. Data Science Models on Big Data Platforms Engineering Patterns for Implementing Hisham Arafat Digital Transformation Lead Consultant Solutions Architect, Technology Strategist & Researcher Riyadh, KSA – 31 January 2017
- 2. http://www.visualcapitalist.com/what-happens-internet-minute-2016/ Big Data…Practical Definition! • Big Data is the challenge not the solution • Big Data technologies address that challenge • Practically: • Massive Streams • Unstructured • Complex Processing
- 3. Let’s Have a Use Case…Social Marketing
- 4. Social Marketing…Looks Simple! Ingest Social Feeds Build Corpus Metrics Design Text Mining Model Deploy All to a Big Data Platform Application for Marketing Users What people are saying about our new brand “LemaTea”?
- 5. Ingest Social Feeds Build Corpus Metrics Design Text Mining Model Deploy All to a Big Data Platform Application for Marketing Users
- 6. It’s NOT as Easy as it’s Looks Like!
- 7. Not Only Building Appropriate Model, but More Into Designing a Solution…Engineering Factors
- 8. • Interfacing with sources: REST APIs, source HTML,… (text is assumed) • Parsing to extract: queries, Regular Expressions,… • Crawling frequency: every 1 minute, 1 hour, on event,… • Document structure: post, post + comments, #, Reach, Retweets,… • Metadata: time, date, source, tags, authoritativeness,… • Transformations: canonicalization, weights, tokenization,… - Size: average size of 2 KB / doc - Initial load: 1.5B doc - Frequency: every 5 minutes - Throughput: 2 KB * 60,000 doc = 120 MB / load - Grows per day ~ 34 GB Engineering Factors
- 9. • Input format: text, encoded text,… • Document representation: bag of words, ontology… • Corpus structures: indexes, reverse indexes,… • Corpus metrics: doc frequency, inverse doc frequency,… • Preprocessing: annotation, tagging,… • Files structure: tables, text files, files-day,… - No of docs: 1.5B + 17M / day - Processing window: 60K per 3 mins - Processing rate: 20K doc per min - Final doc size = 2KB * 5 ~ 10KB - Scan rate: 20k * 10KB min ~ 200MB/min - Many overheads need to be added Engineering Factors
- 10. • Dimensionality reduction: stemming, lemmatization, noisy words… • Type of applications: search/retrieval, sentiment analysis… • Modeling methods: classifiers, topic modeling, relevance… • Model efficiency: confusion metrics, precision, recall… • Overheads: intermediate processing, pre-aggregation,… • Files structure: tables, text files, files-day,… - No of docs: 1.5B + 17M / day - Search for “LemaTea sweet taste” - No of tf to calculate ~ 1.5B * 3 ~ 4.5B - No of idf to calculate ~ 1.5B - Total calculations for 1 search ~ 6 B - Consider daily growth Engineering Factors
- 11. • Files structure: tables, text files, files-day,… • Files formats: HDFS, parquet, avro… • Platform technology: Hadoop/YARN, Spark, Greenplum, Flink,… • Model deployment: Java/Scala, Mahoot, Mllib, MADlib, PL/R, FlinkML… • Data ingestion: Spring XD, Flume, Sqoop, G. Data Flow, Kafka/Streaming… • Ingestion pattern: real-time, micro batches,… - Overall Storage - Processing capacity per node - No of nodes - Tables Hive, Hbase, Greenplum - Individual files Spark, Flink - Files-day Hadoop HDFS Engineering Factors
- 12. • Workload: no of requests, request size,… • Application performance: response time, concurrent requests… • Applications interfacing: RESET APIs, native, messaging,… • Application implementation: integration, model scoring,… • Security model: application level, platform level,… - For 3 search terms ~ 6B calculations - For 5 search terms ~ 9B calculations - For 10 concurrent requests ~ 75B - Resource queuing / prioritization - Search options like date range - Access control model Engineering Factors
- 13. Ongoing Process…Growing Requirements What if? • New sources are included • Wider parsing Criteria • Advanced modeling: POS, Word Co- occurrence, Co-referencing, Named Entity, Relationship Extraction,… • Better response time is needed • More frequent ingestion Dynamic Platform Ingestion Corpus Processing Model Processing Requests Processing • Larger number of docs • Increased processing requirements • Platform expansion • Overall architecture reconsidered
- 15. What is a Data Science Model? • Type & format of inputs date • Data ingestion • Transformations and feature engineering • Modeling methods and algorithms • Model evaluation and scoring • Applications implantations considerations • In-Memory vs. In-Database
- 16. Key Challenges for Data Science Models Volume Stationary Batches Structured Insights Growth Streams Real-time Unstructured Responsive Scale out Performance Data Flow Engines Event Processing Complex Formats Perspective / Deep Models
- 17. Traditional Data Management Systems • Shared I/O • Shared Processing • Limited Scalability • Service Bottlenecks • High Cost Factor SharedBuffers Data Files Database Cluster I/O I/O I/O Network DatabaseService
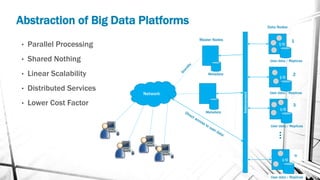
- 18. Abstraction of Big Data Platforms Data Nodes Master Nodes I/O Network Interconnect • Parallel Processing • Shared Nothing • Linear Scalability • Distributed Services • Lower Cost Factor I/O I/O I/O … Metadata 1 2 3 n Metadata User data / Replicas User data / Replicas User data / Replicas User data / Replicas
- 19. In a Nutshell Source: http://dataconomy.com /2014/06/understandi ng-big-data-ecosystem/ • Very huge. • Overlaps. • Overloading. • You need to start with a use case to be able to get your solutions well engineered.
- 20. Engineered Systems • Packaged: Hortonworks – Pivotal – Cloudera • Appliances: EMC DCA – Dell DSSD – Dell VxRack • Cloud offerings: Azure – AWS – IBM – Google Cloud
- 22. Lambda Architecture…Social Marketing • Generic, scalable and fault-tolerant data processing architecture. • Keeps a master immutable dataset while serving low latency requests. • Aims at providing linear scalability. Source: http://lambda-architecture.net/
- 23. Social Marketing…Revisted Ingest Social Feeds Build Corpus Metrics Design Text Mining Model Deploy All to a Big Data Platform Application for Marketing Users What people are saying about our new brand “LemaTea”?
- 24. Lambda Architecture (cont.) Source: https://speakerdeck.com/mhausenblas/lambda-architecture-with-apache-spark
- 25. Lambda Architecture (cont.) Source: https://speakerdeck.com/mhausenblas/lambda-architecture-with-apache-spark
- 26. Lambda Architecture (cont.) Source: https://speakerdeck.com/mhausenblas/lambda-architecture-with-apache-spark Sequence Files
- 27. Apache Spark / MLlib • In memory distributed Processing • Scala, Python, Java and R • Resilient Distributed Dataset (RDD) • Mllib – Machine Learning Algorithms • SQL and Data Frames / Pipelines • Streaming • Big Graph analytics Spark Cluster Mesos HDFS/YARN
- 28. Apache Spark • Supports different types of Cluster Managers • HDFS / YARN, Mesos, Amazon S3, Stand Alone, Hbase, Casandra… • Interactive vs Application Mode • Memory Optimization Source: https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/spark-architecture.html
- 29. Apache Spark
- 31. Apache Spark…The Big Picture Source” https://www.datanami.com/2015/11/30/spark-streaming-what-is-it-and-whos-using-it/
- 32. Greenplum / MADLib • Massively Parallel Processing • Shared Nothing • Table distribution • By Key • By Round Robin • Massively Parallel Data Loading • Integration with Hadoop • Native MapReduce
- 33. Apache MADLib
- 34. Image Processing…Unusual Way Massively Parallel, In-Database Image Processing Source: https://content.pivotal.io/blog/data-science-how-to- massively-parallel-in-database-image-processing-part-1
- 35. Image Processing…Unusual Way Massively Parallel, In-Database Image Processing Source: https://content.pivotal.io/blog/data-science-how-to-massively-parallel-in-database-image-processing-part-1
- 36. Image Processing…Unusual Way Massively Parallel, In-Database Image Processing Source: https://content.pivotal.io/blog/data-science-how-to-massively-parallel-in-database-image-processing-part-1
- 37. Take Aways • A Data Science is not just the algorithms but it includes and end-to-end solution. • The implementation should consider engineering factors and quantify them so appropriate components can be selected. • The Big Data technology land scape is really huge and growing – start with a solid use case to identify potential components. • Abstraction of specific technology will enable you to put your hands on the pros and cons. • Creativity in solutions design and technology selection case by case. • Lambda Architecture, Spark, Spark MLlib, Spark Streaming, Spark SQL Kafka, Hadoop / Yarn, Greenplum, MADLib.
- 38. Q & A
- 39. Email: [email protected] Skype: hichawy LinkedIn: https://eg.linkedin.com/in/hisham-arafat-a7a69230 Thank You