EuroPython 2022 - Automated Refactoring Large Python Codebases

Like many companies with multi-million-line Python codebases, Carta has struggled to adopt best practices like Black formatting and type annotation. The extra work needed to do the right thing competes with the almost overwhelming need for new development, and unclear code ownership and lack of insight into the size and scope of type problems add to the burden. We’ve greatly mitigated these problems by building an automated refactoring pipeline that applies Black formatting and backfills missing types via incremental Github pull requests. Our refactor applications use LibCST and MonkeyType to modify the Python syntax tree and use GitPython/PyGithub to create and manage pull requests. It divides changes into small, easily reviewed pull requests and assigns appropriate code owners to review them. After creating and merging more than 3,000 pull requests, we have fully converted our large codebase to Black format and have added type annotations to more than 50,000 functions. In this talk, you’ll learn to use LibCST to build automated refactoring tools that fix general Python code quality issues at scale and how to use GitPython/PyGithub to automate the code review process.







![Common Python Errors
Mypy can catch the errors by doing type checking
9
TypeError: f() got multiple values for keyword argument 'a'
AttributeError: 'str' object has no attribute 'args'
ValueError: not enough values to unpack (expected 4, got 3)
Error: "str" has no attribute "args"
Error: Attribute function "f" with type "Callable[[C], Any]" does not accept self argument
Error: Need more than 3 values to unpack (4 expected)](https://image.slidesharecdn.com/automatedrefactoringlargepythoncodebases-220715141336-a16263e7/95/EuroPython-2022-Automated-Refactoring-Large-Python-Codebases-9-638.jpg)









![Number of Pending PRs
21
Tradeoffs:
● Too many concurrent pending PRs introduce too much code review work for developers
● Too few PRs results in slow progress
# gh CLI tool allow searching pending PRs based on label
# gh pr list --label automated-refactoring --json number,headRefName
from subprocess import check_output
from json import loads
pending_prs = loads(check_output(["gh", "pr", "list", "--label",
"automated-refactoring", "--json", "number,headRefName"]).decode())
if len(pending_prs) < PENDING_PR_THRESHOLD:
... # create more PRs](https://image.slidesharecdn.com/automatedrefactoringlargepythoncodebases-220715141336-a16263e7/95/EuroPython-2022-Automated-Refactoring-Large-Python-Codebases-21-638.jpg)




![Automated Refactoring Application API
26
from abc import ABC
from subprocess import check_output
class RefactoringApplication(ABC):
...
class BlackFormattingApplication(RefactoringApplication):
pr_title: str = "Automated Black formatting on path %{target_path}"
pr_labels: List[str] = ["automated-refactoring", "black-formatting"]
pr_body: Path: Path("Black_formatting_body.md")
commit_message: "Automated Black formatting on path %{target_path}"
def skip_a_path(path: Path) -> bool:
# lookup black_enrollment.txt to verify if the path exists or is covered by another path
return path_is_enrolled_in_black(path)
def refactor(path: Path):
# 1. Apply Black on the target path
check_output(["black", str("path")])
# 2. Add the path to the enrollment file black_enrollment.txt
enroll_a_path_to_black_formatting(path)](https://image.slidesharecdn.com/automatedrefactoringlargepythoncodebases-220715141336-a16263e7/95/EuroPython-2022-Automated-Refactoring-Large-Python-Codebases-26-638.jpg)
![Periodical Jobs
27
27
Using Github workflows to run a Python script every 30 minutes during weekdays
on:
schedule:
- cron: '30 * * * 1,2,3,4,5'
jobs:
runs-on: ubuntu-latest
steps:
name: Apply code change and create a pull request
shell: python
run: |
from subprocess import check_output
check_output([...])
.github/workflows/create_pull_requests.yml](https://image.slidesharecdn.com/automatedrefactoringlargepythoncodebases-220715141336-a16263e7/95/EuroPython-2022-Automated-Refactoring-Large-Python-Codebases-27-638.jpg)
![Job: Apply code change and create a pull request
from github import Github # use PyGithub library
github = Github("${{ github.token }}")
repo = github.get_repo("${{ github.repository }}")
for Application in RefactoringApplication.__subclasses__():
app = Application()
while len(app.get_pending_prs()) < PENDING_PR_THRESHOLD:
path = app.get_next_path()
app.refactor(path)
check_output(["git", "add", str(path)])
check_output(["git", "commit", "-m", app.get_commit_message()])
repo.create_pull(title=app.get_pr_title(),
body=app.get_pr_body(), head=app.get_branch(), base=MAIN_BRANCH)](https://image.slidesharecdn.com/automatedrefactoringlargepythoncodebases-220715141336-a16263e7/95/EuroPython-2022-Automated-Refactoring-Large-Python-Codebases-28-638.jpg)










EuroPython 2022 - Automated Refactoring Large Python Codebases
- 1. Automated Refactoring in Large Python Codebases Jimmy Lai, Staff Software Engineer at Carta July 15, 2022
- 2. Problems in Large Codebases Code Formatting Type Checking 2
- 3. 3 Startup Founder Employee Stock Option Investor Stock Money Compensation Valuation Tax Fund Admin.
- 4. Large Codebase 4 Python code Developed for 10 years 200 active developers 2 million lines 30,000 files 20,000 file changes 🚩Challenge: Impossible to merge due to conflicts
- 6. Flexible Python Code Style 6 Python Code Formatting Tool
- 7. Break up changes as small pieces incrementally 7 20,000 file changes 🚩 Challenge: Impossible to merge due to conflicts 🚩Challenge: Extra work: need to manage each change to create/review/merge them and avoid overlaps 1 ~20 files changes 2 ~20 files changes 3 ~20 files changes 🚩Challenge: Avoid regression during incremental adoption
- 9. Common Python Errors Mypy can catch the errors by doing type checking 9 TypeError: f() got multiple values for keyword argument 'a' AttributeError: 'str' object has no attribute 'args' ValueError: not enough values to unpack (expected 4, got 3) Error: "str" has no attribute "args" Error: Attribute function "f" with type "Callable[[C], Any]" does not accept self argument Error: Need more than 3 values to unpack (4 expected)
- 10. Type Annotations 10 def add(a, b): … def add(a: int, b: int) -> int: … add(1.2, 2) Error: Argument 1 to "add" has incompatible type "float"; expected "int" 🚩 Challenge: Too many functions (100k) without type annotations
- 12. “ What if we can automate incremental code changes?
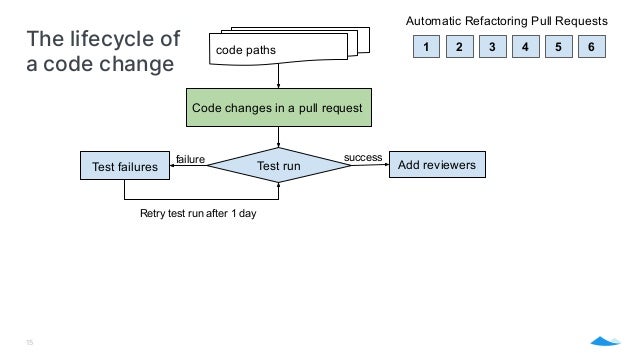
- 13. The lifecycle of a code change code paths 1 2 3 4 5 6 Automatic Refactoring Pull Requests
- 14. The lifecycle of a code change code paths Code changes in a pull request 1 2 3 4 5 6 Automatic Refactoring Pull Requests 14 Test run
- 15. The lifecycle of a code change 15 code paths Add reviewers success Test run Test failures failure Retry test run after 1 day Code changes in a pull request 1 2 3 4 5 6 Automatic Refactoring Pull Requests
- 16. The lifecycle of a code change 16 code paths Add reviewers success Test run Test failures failure Retry test run after 1 day Code changes in a pull request 1 2 3 4 5 6 Automatic Refactoring Pull Requests Wait for review Approvals 2 Merge Add more reviewers 1 + pending for 3 days Post in reviewer’s team Slack channel 0
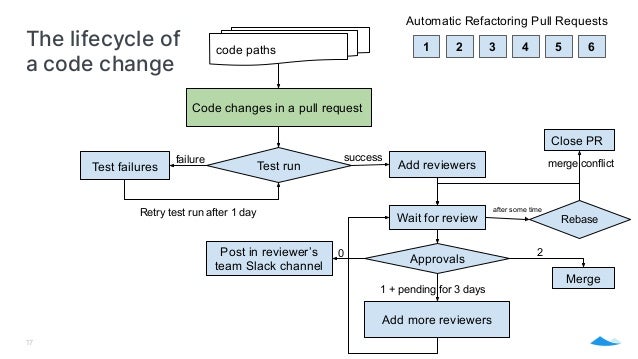
- 17. The lifecycle of a code change 17 code paths Add reviewers success Test run Test failures failure Retry test run after 1 day Code changes in a pull request 1 2 3 4 5 6 Automatic Refactoring Pull Requests Wait for review Approvals 2 Merge Add more reviewers 1 + pending for 3 days Post in reviewer’s team Slack channel 0 after some time Rebase Close PR merge conflict
- 18. The lifecycle of a code change 18 code paths Add reviewers success Test run Test failures failure Retry test run after 1 day Apply Code Changes 1 2 3 4 5 6 Automatic Refactoring Pull Requests Wait for review Approvals 2 Merge Add more reviewers 1 + pending for 3 days Post in reviewer’s team Slack channel 0 after some time Rebase Close PR merge conflict Automation Actions performed by pipeline jobs
- 20. Size of Code Change 20 Tradeoffs: ● Too Big: not easy to review ● Too Small: too many pull requests from os import walk from pathlib import Path for dirpath, _, _ in walk("."): num_files = len(path for path in Path(dirpath).glob("**/*.py")) if num_files < THRESHOLD: ... # use the dirpath
- 21. Number of Pending PRs 21 Tradeoffs: ● Too many concurrent pending PRs introduce too much code review work for developers ● Too few PRs results in slow progress # gh CLI tool allow searching pending PRs based on label # gh pr list --label automated-refactoring --json number,headRefName from subprocess import check_output from json import loads pending_prs = loads(check_output(["gh", "pr", "list", "--label", "automated-refactoring", "--json", "number,headRefName"]).decode()) if len(pending_prs) < PENDING_PR_THRESHOLD: ... # create more PRs
- 22. Avoid Duplications 22 Pull request paths should not have overlaps. Encode the path info as part of the pull request for lookup Using Git branch name "black_formatting@dir_a/dir_b" "black_formatting@dir_a/dir_c"
- 23. Incremental Adoption 23 Protect automated refactored files from regression using an enrollment process. 1. When a file is Black formatted, add the file path to an enrollment list. 2. A CI job runs Black format check on all enrolled files to ensure they follow Black formats. Once we enrolled the entire codebase, we can run Black on the entire codebase and remove the enrollment list. The same approach applies to type annotation adoption.
- 24. State Machine Transitions with Periodical Jobs 24 code paths Add reviewers success Test run Test failures failure Retry test run after 1 day Apply Code Changes Wait for review Approvals 2 Merge Add more reviewers 1 + pending for 3 days Post in reviewer’s team Slack channel 0 after some time Rebase Close PR merge conflict Automation Actions performed by pipeline jobs
- 25. Jobs 25 1. Apply code change and create a pull request 2. Check test status and add reviewers 3. Check review status and add more reviewers 4. Send Slack notifications for old PRs 5. Merge approved PRs 6. Close Pull Request when conflicts
- 26. Automated Refactoring Application API 26 from abc import ABC from subprocess import check_output class RefactoringApplication(ABC): ... class BlackFormattingApplication(RefactoringApplication): pr_title: str = "Automated Black formatting on path %{target_path}" pr_labels: List[str] = ["automated-refactoring", "black-formatting"] pr_body: Path: Path("Black_formatting_body.md") commit_message: "Automated Black formatting on path %{target_path}" def skip_a_path(path: Path) -> bool: # lookup black_enrollment.txt to verify if the path exists or is covered by another path return path_is_enrolled_in_black(path) def refactor(path: Path): # 1. Apply Black on the target path check_output(["black", str("path")]) # 2. Add the path to the enrollment file black_enrollment.txt enroll_a_path_to_black_formatting(path)
- 27. Periodical Jobs 27 27 Using Github workflows to run a Python script every 30 minutes during weekdays on: schedule: - cron: '30 * * * 1,2,3,4,5' jobs: runs-on: ubuntu-latest steps: name: Apply code change and create a pull request shell: python run: | from subprocess import check_output check_output([...]) .github/workflows/create_pull_requests.yml
- 28. Job: Apply code change and create a pull request from github import Github # use PyGithub library github = Github("${{ github.token }}") repo = github.get_repo("${{ github.repository }}") for Application in RefactoringApplication.__subclasses__(): app = Application() while len(app.get_pending_prs()) < PENDING_PR_THRESHOLD: path = app.get_next_path() app.refactor(path) check_output(["git", "add", str(path)]) check_output(["git", "commit", "-m", app.get_commit_message()]) repo.create_pull(title=app.get_pr_title(), body=app.get_pr_body(), head=app.get_branch(), base=MAIN_BRANCH)
- 29. Job: Merge approved PRs 29 from github import Github # use PyGithub library github = Github("${{ github.token }}") repo = github.get_repo("${{ github.repository }}") for issue in repo.legacy_search_issues("open", "label:automated-refactoring is:pull-request review:approved"): pull = repo.get_pull(issue.number) pull.merge()
- 30. Refactor Python code to add missing types 30 Add missing types based on simple inferences
- 31. from pathlib import Path from libcst import CSTTransformer, FunctionDef, Return, Yield, Annotation, Name, parse_module class AddMissingNoneReturn(CSTTransformer): def __init__(self): self.return_count = 0 def visit_FunctionDef(self, node: FunctionDef) -> None: self.return_count = 0 def visit_Return(self, node: Return) -> None: self.return_count += 1 def leave_FunctionDef(self, original_node: FunctionDef, updated_node: FunctionDef) -> FunctionDef: if updated_node.returns is None and self.return_count == 0: return updated_node.with_changes(returns=Annotation(annotations=Name("None"))) return updated_node def refactor(python_file_path: Path): module = parse_module(python_file_path.read_text()) modified_module = module.visit(AddMissingNoneReturn()) python_file_path.write_text(modified_module.code) 31 Add missing None return using LibCST
- 32. Add missing complex types by collecting types at runtime 32 Using MonkeyType: 1. Run your program with MonkeyType enabled 2. MonkeyType collects types of each function call trace 3. Run MonkeyType command to apply the collected types
- 33. Results
- 34. 34 Black format coverage in our monolith codebase Black tool was added on 2020-10-30 Manual Adoption Automated Refactoring 100% coverage on 2021-10-22
- 35. Type annotation coverage in our monolith codebase 35 Automated Refactoring
- 36. Production type error improvement 36
- 37. Summary 37 Automated Refactoring is useful if you have a large codebase and many tech debt to resolve. Automated Refactoring framework enables: ● Saving tons of development time ● Fixing tech debt incrementally and continuously ● Refactor any programming language
- 38. Thank you for your attentions! Carta Engineering Blog https://medium.com/building-carta Carta Jobs https://boards.greenhouse.io/carta Tools: ● Black Formatting ● Mypy ● PyGithub ● LibCST ● MonkeyType