From Query Plan to Query Performance: Supercharging your Apache Spark Queries using the Spark UI SQL Tab
1 like811 views

The document discusses optimizing query performance in Apache Spark using the Spark UI SQL tab, which provides insights into query execution and planning through the catalyst optimizer. It outlines the structure of physical plans, common transformation types, and various join strategies to improve query execution efficiency. Several scenarios are provided to illustrate common pitfalls and optimization techniques, such as handling filters, using case statements, and adjusting aggregation strategies.






![A simple example (2)
# dfSalesSample is some cached dataframe
dfItemSales = (dfSalesSample
.filter(f.col("item_id") >= 600000)
.groupBy("item_id")
.agg(f.sum(f.col("sales")).alias("itemSales")))
# Trigger the query
dfItemSales.write.format("noop").mode("overwrite").save()
== Physical Plan ==
OverwriteByExpression org.apache.spark.sql.execution.datasources.noop.NoopTable$@dc93aa9, [AlwaysTrue()], org.apache.spark.sql.util.CaseInsensitiveStringMap@1f
+- *(2) HashAggregate(keys=[item_id#232L], functions=[finalmerge_sum(merge sum#1247L) AS sum(cast(sales#233 as bigint))#1210L], output=[item_id#232L, itemSales#1211L])
+- Exchange hashpartitioning(item_id#232L, 8), true, [id=#1268]
+- *(1) HashAggregate(keys=[item_id#232L], functions=[partial_sum(cast(sales#233 as bigint)) AS sum#1247L], output=[item_id#232L, sum#1247L])
+- *(1) Filter (isnotnull(item_id#232L) AND (item_id#232L >= 600000))
+- InMemoryTableScan [item_id#232L, sales#233], [isnotnull(item_id#232L), (item_id#232L >= 600000)]](https://image.slidesharecdn.com/15vanwouwthone-201124190155/85/From-Query-Plan-to-Query-Performance-Supercharging-your-Apache-Spark-Queries-using-the-Spark-UI-SQL-Tab-8-320.jpg)
![A simple example (3)
== Physical Plan ==
OverwriteByExpression org.apache.spark.sql.execution.datasources.noop.NoopTable$@dc93aa9, [AlwaysTrue()], org.apache.spark.sql.util.CaseInsensitiveStringMap@1f
+- *(2) HashAggregate(keys=[item_id#232L], functions=[finalmerge_sum(merge sum#1247L) AS sum(cast(sales#233 as bigint))#1210L], output=[item_id#232L, itemSales#1211L])
+- Exchange hashpartitioning(item_id#232L, 8), true, [id=#1268]
+- *(1) HashAggregate(keys=[item_id#232L], functions=[partial_sum(cast(sales#233 as bigint)) AS sum#1247L], output=[item_id#232L, sum#1247L])
+- *(1) Filter (isnotnull(item_id#232L) AND (item_id#232L >= 600000))
+- InMemoryTableScan [item_id#232L, sales#233], [isnotnull(item_id#232L), (item_id#232L >= 600000)]
▪ What more possible operators exist in Physical plan?
▪ How should we interpret the “details” in the SQL plan?
▪ How can we use above knowledge to optimise our Query?](https://image.slidesharecdn.com/15vanwouwthone-201124190155/85/From-Query-Plan-to-Query-Performance-Supercharging-your-Apache-Spark-Queries-using-the-Spark-UI-SQL-Tab-9-320.jpg)





























![Join Implementations & Requirements
Different joins have different complexities
Join Type Required Child Distribution Required
Child
Ordering
Description Complexity
(ballpark)
BroadcastHashJoinExec One Side:
BroadcastDistribution
Other: UnspecifiedDistribution
None Performs local hash join between
broadcast side and other side.
O(n)
SortMergeJoinExec Both Sides:
HashClusteredDistribution
Both Sides:
Ordered (asc)
by join keys
Compare keys of sorted data
sets and merges if match.
O(nlogn)
BroadcastNestedLoopJoinExec One Side:
BroadcastDistribution
Other: UnspecifiedDistribution
None For each row of [Left/Right]
dataset, compare all rows of
[Left/Right] data set.
O(n * m), small
m
CartesianProductExec None None Cartesian product/”cross join” +
filter
O(n* m), bigger
m](https://image.slidesharecdn.com/15vanwouwthone-201124190155/85/From-Query-Plan-to-Query-Performance-Supercharging-your-Apache-Spark-Queries-using-the-Spark-UI-SQL-Tab-39-320.jpg)

![Ordering requirements
Example for SortMergeJoinExec
SortMergeJoin
(left.id=right.id
, Inner)
outputOrdering =
[left.id, right.id] ASC
Sort ([left.id],
ASC)
SortMergeJoin
(left.id=right.id
, Inner)
requiredChildOrdering =
[left.id, right.id] (ASC)
outputOrdering = depends on
join type
Ensure the requirements
Sort ([right.id],
ASC)](https://image.slidesharecdn.com/15vanwouwthone-201124190155/85/From-Query-Plan-to-Query-Performance-Supercharging-your-Apache-Spark-Queries-using-the-Spark-UI-SQL-Tab-41-320.jpg)

![Scenario 1: Filter + Union anti-pattern
E.g. apply different logic based on a category the data belongs to.
final_df = functools.reduce(DataFrame.union,
[
logic_cat_0(df.filter(F.col("category") == 0)),
logic_cat_1(df.filter(F.col("category") == 1)),
logic_cat_2(df.filter(F.col("category") == 2)),
logic_cat_3(df.filter(F.col("category") == 3))
]
)
…
def logic_cat_0(df: DataFrame) -> DataFrame:
return df.withColumn("output", F.col("sales") * 2)
…
Repeated
ReadsofData!](https://image.slidesharecdn.com/15vanwouwthone-201124190155/85/From-Query-Plan-to-Query-Performance-Supercharging-your-Apache-Spark-Queries-using-the-Spark-UI-SQL-Tab-44-320.jpg)








From Query Plan to Query Performance: Supercharging your Apache Spark Queries using the Spark UI SQL Tab
- 1. From Query Plan to Query Performance: Supercharging your Spark Queries using the Spark UI SQL Tab Max Thone - Resident Solutions Architect Stefan van Wouw - Sr. Resident Solutions Architect
- 2. Agenda Introduction to Spark SQL Tab The Most Common Components of the Query Plan Supercharge your spark queries
- 3. Introduction to Spark SQL Tab
- 4. Why should you know about the SQL Tab? ▪ Shows how the Spark query is executed ▪ Can be used to reason about query execution time.
- 5. What is a Query Plan? ▪ A Spark SQL/Dataframe/Dataset query goes through Spark Catalyst Optimizer before being executed by the JVM ▪ With “Query plan” we mean the “Selected Physical Plan”, it is the output of Catalyst Catalyst Optimizer From the Databricks glossary (https://databricks.com/glossary/catalyst-optimizer)
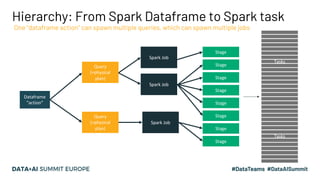
- 6. Dataframe “action” Query (=physical plan) Spark Job Spark Job Spark Job Stage Stage Stage Stage Stage Stage Stage Stage Tasks Tasks Hierarchy: From Spark Dataframe to Spark task One “dataframe action” can spawn multiple queries, which can spawn multiple jobs Query (=physical plan)
- 7. A simple example (1) # dfSalesSample is some cached dataframe dfItemSales = (dfSalesSample .filter(f.col("item_id") >= 600000) .groupBy("item_id") .agg(f.sum(f.col("sales")).alias("itemSales"))) # Trigger the query dfItemSales.write.format("noop").mode("overwrite").save() (1) dataframe “action” (2) Query (physical plan) (3) Job (4) Two Stages (5) Nine tasks
- 8. A simple example (2) # dfSalesSample is some cached dataframe dfItemSales = (dfSalesSample .filter(f.col("item_id") >= 600000) .groupBy("item_id") .agg(f.sum(f.col("sales")).alias("itemSales"))) # Trigger the query dfItemSales.write.format("noop").mode("overwrite").save() == Physical Plan == OverwriteByExpression org.apache.spark.sql.execution.datasources.noop.NoopTable$@dc93aa9, [AlwaysTrue()], org.apache.spark.sql.util.CaseInsensitiveStringMap@1f +- *(2) HashAggregate(keys=[item_id#232L], functions=[finalmerge_sum(merge sum#1247L) AS sum(cast(sales#233 as bigint))#1210L], output=[item_id#232L, itemSales#1211L]) +- Exchange hashpartitioning(item_id#232L, 8), true, [id=#1268] +- *(1) HashAggregate(keys=[item_id#232L], functions=[partial_sum(cast(sales#233 as bigint)) AS sum#1247L], output=[item_id#232L, sum#1247L]) +- *(1) Filter (isnotnull(item_id#232L) AND (item_id#232L >= 600000)) +- InMemoryTableScan [item_id#232L, sales#233], [isnotnull(item_id#232L), (item_id#232L >= 600000)]
- 9. A simple example (3) == Physical Plan == OverwriteByExpression org.apache.spark.sql.execution.datasources.noop.NoopTable$@dc93aa9, [AlwaysTrue()], org.apache.spark.sql.util.CaseInsensitiveStringMap@1f +- *(2) HashAggregate(keys=[item_id#232L], functions=[finalmerge_sum(merge sum#1247L) AS sum(cast(sales#233 as bigint))#1210L], output=[item_id#232L, itemSales#1211L]) +- Exchange hashpartitioning(item_id#232L, 8), true, [id=#1268] +- *(1) HashAggregate(keys=[item_id#232L], functions=[partial_sum(cast(sales#233 as bigint)) AS sum#1247L], output=[item_id#232L, sum#1247L]) +- *(1) Filter (isnotnull(item_id#232L) AND (item_id#232L >= 600000)) +- InMemoryTableScan [item_id#232L, sales#233], [isnotnull(item_id#232L), (item_id#232L >= 600000)] ▪ What more possible operators exist in Physical plan? ▪ How should we interpret the “details” in the SQL plan? ▪ How can we use above knowledge to optimise our Query?
- 10. An Overview of Common Components of the Physical Plan
- 11. The physical plan under the hood What is the physical plan represented by in the Spark Code? ▪ The physical plan is represented by SparkPlan class ▪ SparkPlan is a recursive data structure: ▪ It represents a physical operator in the physical plan, AND the whole plan itself (1) ▪ SparkPlan is the base class, or “blueprint” for these physical operators ▪ These physical operators are “chained” together (1) From Jacek Laskowski’s Mastering Spark SQL (https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/spark-sql-SparkPlan.html#contract
- 12. Physical operators of SparkPlan Extending SparkPlan Query Input (LeafExecNode) Output (UnaryExecNode) Binary Transformation (BinaryExecNode) Query Input (LeafExecNode) Unary Transformation (UnaryExecNode)
- 13. Physical operators of SparkPlan Extending SparkPlan (152 subclasses) Query Input (LeafExecNode) Output (UnaryExecNode) Binary Transformation (BinaryExecNode) Query Input (LeafExecNode) Unary Transformation (UnaryExecNode) ▪ LeafExecNode (27 subclasses) ▪ All file sources, cache read, construction of dataframes from RDDs, range generator, and reused exchanges & subqueries. ▪ BinaryExecNode (8 subclasses) ▪ Operations with 2 dataframes as input (joins, unions, etc.) ▪ UnaryExecNode (82 subclasses) ▪ Operations with one dataframe as input. E.g. sort, aggregates, exchanges, filters, projects, limits ▪ Other (32 traits/abstract/misc classes)
- 14. The Most Common Components of the Physical Plan ▪ Common Narrow Transformations ▪ Distribution Requirements (Exchange) ▪ Common Wide Transformations ▪ Aggregates ▪ Joins ▪ Ordering Requirements (Sort) ▪ Adaptive Query Execution ▪ Streaming ▪ Datasource V2 specifics ▪ Command specifics (Hive metastore related) ▪ Dataset API specifics ▪ Caching / Reuse ▪ UDFs Parts we will NOT cover.Parts we will cover.
- 15. Let’s start with the basics: Read/Write
- 16. Row-based Scan CSV and Write to Delta Lake No dataframe transformations apart from read/write spark .read .format("csv") .option("header", True) .load("/databricks-datasets/airlines") .write .format("delta") .save("/tmp/airlines_delta") Q1 Q2 1 2 3 4
- 17. Columnar Scan Delta Lake and Write to Delta Lake High level spark .read .format("delta") .load("...path...") .write .format("delta") .save("/tmp/..._delta") Q1 Q2 Parquet is Columnar, while Spark is row-based Anything in this box supports codegen
- 18. Columnar Scan Delta Lake and Write to Delta Lake Statistics on Columnar Parquet Scan spark .read .format("delta") .load("...path...") .write .format("delta") .save("/tmp/..._delta") Q2 1
- 19. Columnar Scan Delta Lake and Write to Delta Lake Statistics on WSCG + ColumnarToRow spark .read .format("delta") .load("...path...") .write .format("delta") .save("/tmp/..._delta") Q2 1 2 3
- 21. Common Narrow Transformations Filter / Project spark .read .format("delta") .load("...path...") .filter(col("item_id") < 1000) .withColumn("doubled_item_id", col("item_id")*2) .write .format("delta") .save("/tmp/..._delta") Filter → Filter withColumn/select → Project
- 22. Common Narrow Transformations Range / Sample / Union / Coalesce df1 = spark.range(1000000) df2 = spark.range(1000000) df1 .sample(0.1) .union(df2) .coalesce(1) .write .format("delta") .save("/tmp/..._delta") spark.range → Range sample → Sample union → Union coalesce → Coalesce
- 23. Special Case! Local Sorting sortWithinPartitions df.sortWithinPartitions("item_id") sortWithinPartitions / partitionBy → Sort (global=False) 1 Input (item_id) Result of Sort Global result (unsorted! ) Partition X 33 33 33 Partition Y 34 4 4 66 8 8 4 34 34 8 66 66
- 24. Special Case! Global Sorting orderBy df.orderBy("item_id") Input (item_id) Result of Exchange (example) Result of Sort Global result (sorted!) Partition X New Partition X 8 4 4 33 4 8 8 Partition Y New Partition Y 34 66 66 33 33 4 33 34 34 8 34 66 66 orderBy → Sort (global=True)
- 26. What are wide transformations? ▪ Transformations for which re-distribution of data is required ▪ e.g: joins, global sorting, and aggregations ▪ These above requirements are captured through “distribution” requirements
- 27. Distribution requirements Each node in the physical plan can specify how it expects data to be distributed over the Spark cluster SparkPlan Operator (e.g. Filter) requiredChildDistribution (Default: UnspecifiedDistribution) outputPartitioning (Default: UnknownPartitioning) Required Distribution Satisfied by (roughly) this Partitioning of child Example operator UnspecifiedDistributio n All Scan AllTuples All with 1 partition only Flatmap in Pandas OrderedDistribution RangePartitioning Sort (global) (Hash)ClusteredDistrib ution HashPartitioning HashAggregate / SortMergeJoin BroadcastDistribution BroadcastPartitioning BroadcastHashJoin
- 28. Distribution requirements Example for Local Sort (global=False) Sort (global=False) requiredChildDistribution = UnspecifiedDistribution outputPartitioning = retain child’s Ensure the requirements Sort (global=False) outputPartitioning = retain child’s
- 29. Distribution requirements Example for Global Sort (global=True) Sort (global=True) outputPartitioning = RangePartitioning Exchange (rangepartition ing) Sort (global=True) requiredChildDistribution = OrderedDistribution (ASC/DESC) outputPartitioning = retain child’s Ensure the requirements
- 30. Shuffle Exchange What are the metrics in the Shuffle exchange? Size of shuffle bytes written Size of serialised data read from “local” executor Serialised size of data read from “remote” executors When is it used? Before any operation that requires the same keys on same partitions (e.g. groupBy + aggregation, and for joins (sortMergeJoin)
- 31. Broadcast Exchange Only output rows are a metric with broadcasts Size of broadcasted data (in memory) # of rows in broadcasted data time to build the broadcast table time to build the broadcast table time to collect all the data When is it used? Before any operation in which copying the same data to all nodes is required. Usually: BroadcastHashJoin, BroadcastNestedLoopJoin
- 32. Zooming in on Aggregates
- 33. Aggregates groupBy/agg → HashAggregate Distribution requirement Input (item_id, sales) Result of Exchange Result of HashAggregate 2 Partition X New Partition X (A, 10) (A,10) (A, 13) (B, 5) (A,3) Partition Y New Partition Y (A, 3) (B,1) (B, 9) (B, 1) (B, 1) (B, 1) (B, 1) (B, 2) (B, 2) df .groupBy("item_id") .agg(F.sum("sales"))
- 34. Aggregate implementations df .groupBy("item_id") .agg(F.sum("sales")) HashAggregateExec (Dataframe API) - Based on HashTable structure. - Supports codegen - When hitting memory limits, spill to disk and start new HashTable - Merge all HashTables using sort based aggregation method. ObjectHashAggregateExec (Dataset API) - Same as HashAggregateExec, but for JVM objects - Does not support codegen - Immediately falls back to sort based aggregation method when hitting memory limits SortAggregateExec - sort based aggregation
- 35. Aggregates Metrics Only in case of fallback to sorting (too many distinct keys to keep in memory)
- 36. Partial Aggregation Extra HashAggregate Input (item_id, sales) Result of HashAggregate 1 Result of Exchange Result of HashAggregate 2 Partition X New Partition X (A, 10) (A, 10) (A,10) (A, 13) (B, 5) (B, 5) (A,3) Partition Y New Partition Y (A, 3) (A, 3) (B,5) (B, 9) (B, 1) (B, 4) (B, 4) (B, 1) (B, 2)
- 37. Zooming in on Joins
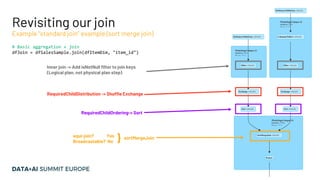
- 38. Joins # Basic aggregation + join dfJoin = dfSalesSample.join(dfItemDim, "item_id") Example “standard join” example (sort merge join) ▪ What kind of join algorithms exist? ▪ How does Spark choose what join algorithm to use? ▪ Where are the sorts and filters coming from? ▪ (We already know Exchanges come from requiredChildDistribution)
- 39. Join Implementations & Requirements Different joins have different complexities Join Type Required Child Distribution Required Child Ordering Description Complexity (ballpark) BroadcastHashJoinExec One Side: BroadcastDistribution Other: UnspecifiedDistribution None Performs local hash join between broadcast side and other side. O(n) SortMergeJoinExec Both Sides: HashClusteredDistribution Both Sides: Ordered (asc) by join keys Compare keys of sorted data sets and merges if match. O(nlogn) BroadcastNestedLoopJoinExec One Side: BroadcastDistribution Other: UnspecifiedDistribution None For each row of [Left/Right] dataset, compare all rows of [Left/Right] data set. O(n * m), small m CartesianProductExec None None Cartesian product/”cross join” + filter O(n* m), bigger m
- 40. Join Strategy How does Catalyst choose what join? equiJoin? One side small enough? One side small enough? inner join? BroadcastHashJoinExec SortMergeJoinExec BroadcastNestedLoopJoinExec CartesianProductExec BroadcastNested LoopJoinExec Danger Zone (OOM) No Yes Yes Yes Yes No No No
- 41. Ordering requirements Example for SortMergeJoinExec SortMergeJoin (left.id=right.id , Inner) outputOrdering = [left.id, right.id] ASC Sort ([left.id], ASC) SortMergeJoin (left.id=right.id , Inner) requiredChildOrdering = [left.id, right.id] (ASC) outputOrdering = depends on join type Ensure the requirements Sort ([right.id], ASC)
- 42. Revisiting our join # Basic aggregation + join dfJoin = dfSalesSample.join(dfItemDim, "item_id") Example “standard join” example (sort merge join) equi-join? Yes Broadcastable? No RequiredChildDistribution -> Shuffle Exchange RequiredChildOrdering-> Sort } sortMergeJoin Inner join -> Add isNotNull filter to join keys (Logical plan, not physical plan step)
- 43. Supercharge your Spark Queries
- 44. Scenario 1: Filter + Union anti-pattern E.g. apply different logic based on a category the data belongs to. final_df = functools.reduce(DataFrame.union, [ logic_cat_0(df.filter(F.col("category") == 0)), logic_cat_1(df.filter(F.col("category") == 1)), logic_cat_2(df.filter(F.col("category") == 2)), logic_cat_3(df.filter(F.col("category") == 3)) ] ) … def logic_cat_0(df: DataFrame) -> DataFrame: return df.withColumn("output", F.col("sales") * 2) … Repeated ReadsofData!
- 45. Scenario 1: Filter + Union anti-pattern FIXED Rewrite code with CASE WHEN :) final_df = ( df .filter((F.col("category") >= 0) & (F.col("category") <= 3)) .withColumn("output", F.when(F.col("category") == 0, logic_cat_0()) .when(F.col("category") == 1, logic_cat_1()) .when(F.col("category") == 2, logic_cat_2()) .otherwise(logic_cat_3()) ) ) def logic_cat_0() -> Column: return F.col("sales") * 2 One read!
- 46. Scenario 2: Partial Aggregations Partial aggregations do not help with high-cardinality grouping keys transaction_dim = 100000000 # 100 million transactions item_dim = 90000000 # 90 million itemIDs itemDF.groupBy("itemID").agg(sum(col("sales")).alias("sales")) Query duration: 23 seconds This doesn’t help!
- 47. Scenario 2: Partial Aggregations FIXED Partial aggregations do not help with high-cardinality grouping keys transaction_dim = 100000000 # 100 million transactions item_dim = 90000000 # 90 million itemIDs spark.conf.set("spark.sql.aggregate.partialaggregate.skip.enabled", True) itemDF.groupBy("itemID").agg(sum(col("sales")).alias("sales")) Query duration: 18 seconds (22% reduction) PR for enabling partial aggregation skipping
- 48. Scenario 3: Join Strategy ship_ports = dfPorts.alias("p").join( dfShips.alias("s"), (col("s.lat") >= col("p.min_lat")) & (col("s.lat") <= col("p.max_lat")) & (col("s.lon") >= col("p.min_lon")) & (col("s.lon") <= col("p.max_lon"))) Query duration: 3.5 minutes Compare coordinates to check if a ship is in a port slow!
- 49. Scenario 3: Join Strategy FIXED Use a geohash to convert to equi-join ship_ports = dfPorts.alias("p").join( dfShips.alias("s"), (col("s.lat") >= col("p.min_lat")) & (col("s.lat") <= col("p.max_lat")) & (col("s.lon") >= col("p.min_lon")) & (col("s.lon") <= col("p.max_lon")) & (substring(col("s.geohash"),1,2) == substring(col("p.geohash"),1,2))) Query duration: 6 seconds Fast!
- 50. In Summary
- 51. What we covered The SQL Tab provides insights into how the Spark query is executed We can use the SQL Tab to reason about query execution time. We can answer important questions: What part of my Spark query takes the most time? Is my Spark query choosing the most efficient Spark operators for the task? Want to practice / know more? Mentally visualize what a physical plan might look like for a spark query, and then check the SQL tab if you are correct. Check out the source code of SparkPlan
- 52. Feedback Your feedback is important to us. Don’t forget to rate and review the sessions.