










































































JavaEdge09 : Java Indexing and Searching
- 1. Java Indexing and SearchingBy : Shay Sofer & EvgenyBorisov
- 3. MotivationWhat is Full Text Search and why do I need it?
- 4. MotivationUse case“Book” tableGood practices for Gava
- 5. We’d like to : Index the information efficientlyanswer queries using that indexMore common than you thinkFull Text SearchMotivation
- 6. Integrated full text search engine in the database e.g. DBSight, Recent versions of MySQL, MS SQL Server, Oracle Text, etc Out of the box Search Appliances e.g. Google Search ApplianceThird party librariesFull Text Search SolutionsMotivation
- 7. Lucene Intro
- 8. The most popular full text search libraryScalable and high performanceAround for about 9 yearsOpen source Supported by the Apache Software FoundationApache LuceneLucene Intro
- 9. Lucene Intro
- 10. “Word-oriented” searchPowerful query syntaxWildcards, typos, proximity search.Sorting by relevance (Lucene’s scoring algorithm) or any other fieldFast searching, fast indexingInverted index.Lucene’s FeaturesLucene Intro
- 11. Lucene IntroInverted Index DBHead First Java0Best of the best of the best1Chuck Norris in action2JBoss in action3
- 12. A Field is a key+value. Value is always represented as a String (Textual)A Document can contain as many Fields as we’d likeLucene’sindex is a collection of DocumentsBasic DefinitionsLucene Intro
- 13. Lucene IntroUsing Lucene API…IndexSearcher is = newIndexSearcher(“BookIndex");QueryParserparser = newQueryParser("title", analyzer);Query query = parser.parse(“Good practices for Gava”);return is.search(query);
- 14. OO domain model Vs. Lucene’s Index structureLucene Intro
- 15. The Structural MismatchConverting objects to string and vice versaNo representation of relation between DocumentsThe Synchronization MismatchDB must by sync’ed with the indexThe Retrieval MismatchRetrieving documents ( =pairs of key + value) and not objects Object vs Flat text mismatchesLucene Intro
- 17. Leverages ORM and Lucene together to solve those mismatchesComplements Hibernate Core by providing FTS on persistent domain models.It’s actually a bridge that hides the sometimes complex Lucene API usage.Open source.Hibernate Search
- 18. Document = Class (Mapped POJO)Hibernate Search metadata can be described by Annotations onlyRegardless, you can still use Hibernate Core with XML descriptors (hbm files)Let’s create our first mapping – BookMappingHibernate Search
- 19. @Entity @Indexedpublicclass Book implementsSerializable {@Idprivate Long id;@Boost(2.0f) @Field private String title;@Field privateStringdescription; privateStringimageURL;@Field (index=Index.UN_TOKENIZED) privateStringisbn; … }Hibernate Search
- 20. Types will be converted via “Field Bridge”.It is a bridge between the Java type and its representation in Lucene (aka String)Hibernate Search comes with a set for most standard types (Numbers – primitives and wrappers, Date, Class etc)They are extendable, of courseBridgesHibernate Search
- 21. We can use a field bridge…@FieldBridge(impl = MyPaddedFieldBridge.class,params = {@Parameter(name="padding", value=“5")} )public Double getPrice(){return price;}Or a class bridge - incase the data we want to index is more than just the field itselfe.g. concatenation of 2 fieldsCustom BridgesHibernate Search
- 22. In order to create a custom bridge we need to implement the interface StringBridgeParameterizedBridge – to inject paramsCustom BridgesHibernate Search
- 23. Directory is where Lucene stores its index structure.Filesystem Directory ProviderIn-memory Directory ProviderClusteringDirectory ProvidersHibernate Search
- 24. DefaultMost efficientLimited only by the disk’s free spaceCan be easily replicatedLuke supportFilesystem Directory ProviderHibernate Search
- 25. Index dies as soon as SessionFactory is closed.Very useful when unit testing. (along side with in-memory DBs)Data can be made persistent at any moment, if needed.Obviously, be aware of OutOfMemoryExceptionIn-memory Directory Provider Hibernate Search
- 26. <!-- Hibernate Search Config --><propertyname="hibernate.search.default.directory_provider">org.hibernate.search.store.FSDirectoryProvider</property><propertyname="hibernate.search.com.alphacsp.Book.directory_provider">org.hibernate.search.store.RAMDirectoryProvider</property>Directory Providers Config ExampleHibernate Search
- 27. Correlated queries - How do we navigate from one entity to another?Lucene doesn’t support relationships between documentsHibernate Search to the rescue - DenormalizationRelationshipsHibernate Search
- 28. Hibernate Search
- 29. @Entity@Indexedpublicclass Book{ @ManyToOne @IndexEmbedded private Author author;}@Entity @Indexedpublicclass Author{private String firstName;}Object navigation is easy (author.firstName)RelationshipsHibernate Search
- 30. Entities can be referenced by other entities.Relationships – Denormalization PitfallHibernate Search
- 31. Entities can be referenced by other entities.Relationships – Denormalization PitfallHibernate Search
- 32. Entities can be referenced by other entities.Relationships – Denormalization PitfallHibernate Search
- 33. The solution: The association pointing back to the parent will be marked with @ContainedIn@Entity @Indexedpublicclass Book{ @ManyToOne @IndexEmbeddedprivate Author author;}@Entity @Indexedpublicclass Author{@OneToMany(mappedBy=“author”) @ContainedIn private Set<Book> books;}Relationships – SolutionHibernate Search
- 34. Responsible for tokenizing and filtering words Tokenizing – not a trivial as it seemsFiltering – Clearing the noise (case, stop words etc) and applying “other” operationsCreating a custom analyzer is easyThe default analyzer is Standard AnalyzerAnalyzersHibernate Search
- 35. StandardTokenizer : Splits words and removes punctuations.StandardFilter : Removes apostrophes and dots from acronyms.LowerCaseFilter : Decapitalizes words.StopFilter : Eliminates common words.Standard AnalyzerHibernate Search
- 36. Other cool Filters….Hibernate Search
- 37. N-Gram algorithm – Indexing a sequence of n consecutive characters. Usually when a typo occurs, part of the word is still correctEncyclopedia in 3-grams =Enc | ncy | cyc | ycl | clo | lop | ope | ped | edi | diaApproximative SearchHibernate Search
- 38. Algorithms for indexing of words by their pronunciation The most widely known algorithm is SoundexOther Algorithms that are available : RefinedSoundex, Metaphone, DoubleMetaphonePhonetic ApproximationHibernate Search
- 39. SynonymsYou can expand your synonym dictionary with your own rules (e.g. Business oriented words)StemmingStemming is the process of reducing words to their stem, base or root form.“Fishing”, “Fisher”, “Fish” and “Fished” FishSnowball stemming language – supports over 15 languagesSynonyms & StemmingHibernate Search
- 40. Lucene is bundled with the basic analyzers, tokenizers and filters. More can be found at Lucene’s contribution part and at Apache-SolrAdditional AnalyzersHibernate Search
- 41. No free Hebrew analyzer for LuceneItamarSyn-HershkoInvolved in the creation of CLucene (The C++ port of Lucene)Creating a Hebrew analyzer as a side projectLooking to join [email protected]?Hibernate Search
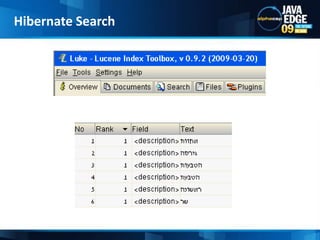
- 42. Hibernate Searchשר הטבעות, גירסה ראשונה:אחוות הטבעת
- 44. When data has changed?Which data has changed?When to index the changing data?How to do it all efficiently? Hibernate Search will do it for you!Transparent indexingIndexing
- 45. Indexing – On Rollback ApplicationQueueDBStart TransactionSession (Entity Manager)Insert/updatedeleteLucene Index
- 46. Indexing – On Rollback Transaction failedApplicationQueueDBRollbackStart TransactionSession (Entity Manager)Insert/updatedeleteLucene Index
- 47. Indexing – On Commit Transaction CommittedApplicationQueueDBSession (Entity Manager)Insert/updatedelete√Lucene Index
- 48. <property name="org.hibernate.worker.execution“>async</property><property name="org.hibernate.worker.thread_pool.size“>2 </property><property name="org.hibernate.worker.buffer_queue.max“>10</property> hibernate.cfg.xmlIndexing
- 49. IndexingIt’s too late! I already have a database without Lucene!
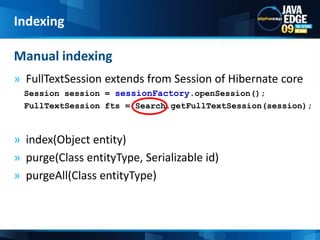
- 50. FullTextSession extends from Session of Hibernate core Session session = sessionFactory.openSession();FullTextSessionfts = Search.getFullTextSession(session);index(Object entity)purge(Class entityType, Serializable id)purgeAll(Class entityType)Manual indexingIndexing
- 51. tx = fullTextSession.beginTransaction();//read the data from the database Query query = fullTextSession.createCriteria(Book.class); List<Book> books = query.list();for (Book book: books ) {fullTextSession.index( book);}tx.commit();Manual indexingIndexing
- 52. tx = fullTextSession.beginTransaction();List<Integer> ids = getIds();for (Integer id : ids) {if(…){fullTextSession.purge(Book.class, id ); } }tx.commit();fullTextSession.purgeAll(Book.class);Removing objects from the Lucene indexIndexing
- 53. IndexingRrrr!!! I got an OutOfMemoryException!
- 54. session.setFlushMode(FlushMode.MANUAL);session.setCacheMode(CacheMode.IGNORE);Transactiontx=session.beginTransaction();ScrollableResultsresults = session.createCriteria(Item.class) .scroll(ScrollMode.FORWARD_ONLY);intindex = 0;while(results.next()) {index++;session.index(results.get(0));if (index % BATCH_SIZE == 0){session.flushToIndexes();session.clear(); } }tx.commit();Indexing10054
- 55. Searching
- 56. title : lord title: rings+title : lord +title: rings title : lord –author: Tolkien title: r?ngs title: r*gs title: “Lord of the Rings” title: “Lord Rings”~5 title: rengs~0.8 title: lord author: Tolkien^2And more…Lucene’s Query SyntaxSearching
- 57. To build FTS queries we need to:Create a Lucene queryCreate a Hibernate Search query that wraps the Lucene queryWhy?No need to build framework around LuceneConverting document to object happens transparently.Seamless integration with Hibernate Core APIQueryingSearching
- 58. String stringToSearch = “rings";Term term = new Term(“title",stringToSearch);TermQuery query = newTermQuery(term);FullTextQueryhibQuery = session.createFullTextQuery(query,Book.class); List<Book> results = hibQuery.list(); Hibernate Queries ExamplesSearching
- 59. String stringToSearch = "r??gs";Term term = new Term(“title",stringToSearch);WildCardQuery query = newWildCardQuery (term);...List<Book> results = hibQuery.list(); WildCardQuery ExampleSearching
- 60. MotivationUse caseBook tableGood practices for Gava
- 61. HS Query FlowchartSearching Hibernate SearchQueryQuery the indexLuceneIndexClientReceive matching idsLoads objects from the Persistence ContextDBDB access (if needed)Persistence Context
- 62. You can use list(), uniqueResult(), iterate(), scroll() – just like in Hibernate Core !Multistage search engineSortingExplanation objectQuerying tipsSearching
- 63. Score
- 64. Most based on Vector Space Model of SaltonScore
- 65. Most based on Vector Space Model of SaltonScore
- 66. Term RatingScoreLogarithmnumber of documents in the indexterm weighttotal number of documents containing term “I”best java in action books
- 68. Head First JavaBest of the best of the bestBest examples from Hibernate in actionThe best action of Chuck NorrisScoring exampleScoreSearch for: “best java in action books”0.602060.124940.30103
- 69. Conventional Boolean retrievalCalculating score for only matching documentsCustomizing similarity algorithmQuery boostingCustom scoring algorithmsLucene’s scoring approachScore
- 70. Alternatives
- 72. AlternativesDistributedSpring supportSimpleLucene basedIntegrates with popular ORM frameworksConfigurable via XML or annotationsLocal & External TX Manager
- 73. Alternatives
- 74. Enterprise Search ServerSupports multiple protocols (xml, json, ruby, etc...)Runs as a standalone Full Text Search server within a servlete.g. TomcatHeavily based on LuceneJSA – Java Search API (based on JPA)ODM (Object/Document Mapping) Spring integration (Transactions)Apache SolrAlternatives
- 75. Powerful Web Administration InterfaceCan be tailored without any Java coding!Extensive plugin architectureServer statistics exposed over JMXScalability – easily replicatedApache SolrAlternatives
- 76. ResourcesLuceneLucenecontrib partHibernate SearchHibernate Search in Action / Emmanuel Bernard, John GriffinCompassApache Solr
- 77. Thank you!Q & A