



























![Categorizing by Composition
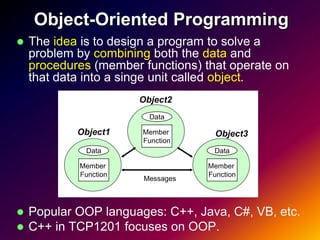
Sample code for the composition involving faculty
and student.
class Student { // Student is a class.
...
}; // End of class
class Faculty { // Faculty is a class.
string name;
vector<Student> students1; // Composition, attribute is
// a class by itself.
//vector<Student*> students2; // Also composition.
//Student students3[10]; // Also composition.
//Student* students3; // Also composition.
...
};](https://image.slidesharecdn.com/lecture01-objectorientedprogramming-130120010815-phpapp01/85/Lecture01-object-oriented-programming-31-320.jpg)

![Class Diagram
Must have 3 sections.
Class name is placed at the top Student
section.
-id:int
Attributes are placed at the middle -subjects:string[*]
section.
+getId():int
Behaviors are placed at the bottom +setId(id:int):void
section. +show_subjects():void
+register_subject():void
'-' denotes private access privilege. +withdraw_subject():void
'+' denotes public access privilege.
'[*]' denotes "many" (array, vector).](https://image.slidesharecdn.com/lecture01-objectorientedprogramming-130120010815-phpapp01/85/Lecture01-object-oriented-programming-33-320.jpg)
![Class Diagram
Faculty Student
Association
-name:string -id: int
-students:Student[*] -subjects:string[*]
1 1..n
+getId():int
+setId(id:int):void
+intake()
'n' means many +show_subjects():void
+register_subject():void
+withdraw_subject():void
Associations shows the relationship between
instances of classes, e.g. a faculty has one or more
students, a student belongs to exactly one faculty
only.](https://image.slidesharecdn.com/lecture01-objectorientedprogramming-130120010815-phpapp01/85/Lecture01-object-oriented-programming-34-320.jpg)






Lecture01 object oriented-programming
- 1. Tip to Save Printer Ink If you prefer to save your printer ink, follow the steps below to print the lectures in black text on white background. 1. In PowerPoint, select File > Print. 2. In the Settings section, locate an item with value "Color", change it to "Pure Black and While".
- 2. Introduction to Object-Oriented Programming Lecture 1 TCP1201 OOPDS
- 3. Learning Objectives To understand object & class To understand abstraction in C++ To understand encapsulation in C++ To categorize similar objects To categorize objects by Composition To understand object behaviors To construct UML Class Diagram To differentiate between Procedural Programming and Object-Oriented Programming
- 4. What is an “object”? An object is a computer representation of real-world person, place, event or anything in the problem that we are solving.
- 5. What is an “object”? An object consists of: – attributes/data/states/fields/variables (typically noun), e.g. name, date, balance, size, mark, etc. – behaviors/procedures/methods/operations/functions (typically verb), e.g. eat, drive, set, get, push, etc. We refer to a group of similar objects with the same attributes and behaviors as a class. Same attribute does not mean same value for the attribute, e.g. 2 students have attribute 'name', but the name of each student can be different.
- 6. Object and Class Class: Student. Attributes: name, student_ID. Behavior/method: do_homeworks(). Objects of Student class: steve, victor.
- 7. Object and Class Steve and victor share the same attributes (name & student_id), but each object has its own value for the attributes.
- 8. Object and Class We refer to a group of similar objects with the same attributes and behaviors as a class. Thus, we can define a class as: – “a set of objects comprised of the same attributes and behaviors”. Thus, we can define object as “a particular instance of a class”.
- 9. Object-Oriented Programming The idea is to design a program to solve a problem by combining both the data and procedures (member functions) that operate on that data into a singe unit called object. Object2 Data Object1 Member Object3 Function Data Data Member Member Function Function Messages Popular OOP languages: C++, Java, C#, VB, etc. C++ in TCP1201 focuses on OOP.
- 10. Steps to Use OOP 1. Identify the objects in the problem. 2. Identify the data/attributes and operations/methods in each object. 3. Determine how the objects interact with one another (messaging). Object2 Data Object1 Member Object3 Function Data Data Member Member Function Function Messages
- 11. 4 Principles of OOP 1. Abstraction – identify the properties that are important to the user in the problem, and create representations that are similar to its original meaning. 2. Encapsulation – combine data and its operations in a single unit, and hide the implementation from user. 3. Inheritance – create new classes from existing classes (Lecture 3). 4. Polymorphism – use the same expression to denote different operations (Lecture 4).
- 12. OOP Principle – Abstraction Abstraction is the process of identifying important logical properties (object, attributes, methods) that simplifies the modeling and working of the problem. If you are designing a mobile phone, example properties that are important to the user are the screen, keypad, UI, cover, etc., but not the internal working of the processor, how the screen is actually rendered, etc.
- 13. OOP in Practice – Abstraction Assume that we are developing simple system to keep track of subjects registered by student. It won't be difficult to identify the following Student class, its attributes and behaviors/methods. – We keep the class simple for the purpose of discussion. Class Student Attributes id subjects Methods show_subjects register_subject withdraw_subject
- 14. OOP in Practice – Abstraction Based on what we collected and consider appropriate data type, the following class definition can be declared: class Student { int id; vector<string> subjects; void show_subjects(); void register_subject(); void withdraw_subject(); }; The next step is to consider encapsulation – the 2nd OOP principle.
- 15. OOP Principle – Encapsulation Encapsulation is the idea that the internal workings of an object can be hidden from the outside world. Encapsulation is performed in 2 ways: 1. We encapsulate how attributes are accessed via access privileges (private, public, protected, friend). 2. We encapsulate how methods are implemented by separating interface and implementation into different files.
- 16. Access Privileges in C++ Access privileges allow us to restrict the access to an object’s members. 4 types of access privileges in C++: 1. private 2. public 3. protected (Lecture 3 Inheritance) 4. friend (Lecture 5 Operator Overloading)
- 17. private and public Access Privileges private members public members Not accessible from Accessible from anywhere except for the anywhere including object itself. outside the class. We generally declare We generally declare attributes as private. methods as public. By default, all members By default, all members of a C++ class are of a C++ struct are declared as private if declared as public if unspecified. unspecified.
- 18. OOP Principle – Encapsulation To maintain data integrity, attribute is usually set hidden/private inside a class to prevent direct modification from outside the class. To access or modify an object' attribute from outside the class, we provide public get or set methods. Get method – a method that returns the value of an attribute but does not modify it. Set method – a method that modifies the value of an attribute.
- 19. OOP in Practice – Encapsulation Since all our methods are meant to be used from outside the class, we should declare them as public. class Student { // private by default int id; vector<string> subjects; public: // public from now on int getId(); // get method for id void setId (int id); // set method for id void show_subjects(); void register_subject(); void withdraw_subject(); }; The next step is to consider where to place the implementation.
- 20. Placing Implementation There are 2 ways to place the implementation (method body) in C++. Inside of class declaration Outside of class declaration class Student { class Student { int id; int id; ... ... int getId() { int getId(); //prototype return id; void setId (int id); //prototype } ... void setId (int id) { }; // End of class this->id = id; } int Student::getId() { ... return id; }; // End of class } void Student::setId (int id) { this->id = id; }
- 21. Placing Implementation Outside of Class Declaration "::" is a scope resolution operator. "Student::" indicates that the function is a method of Student class, not a global function. class Student { int id; ... int getId(); //prototype void setId (int id); //prototype ... }; // End of class int Student::getId() { return id; } void Student::setId (int id) { this->id = id; }
- 22. The this Pointer We use this pointer to refer to a member of a class. class Student { int id; ... void setId (int id); //prototype ... }; // End of class ... void Student::setId (int id) { this->id = id; } id here is attribute id here is function parameter, not attribute
- 23. The this Pointer We use this pointer to refer to a member of a class. class Student { int id; ... void setId (int id); //prototype ... }; // End of class ... void Student::setId (int id) { id = id; // Wrong, "parameter = parameter". // Attribute id is not updated. this->id = id; // Correct, "attribute = parameter". Student::id = id; // Correct, "attribute = parameter". }
- 24. Maintaining Data Integrity with Encapsulation By declaring attributes as private and providing public set methods, we can prevent erroneous data being entered into the object. ... // Ensure id entered is within range. void Student::setId (int id) { if (id < 1000000000 || id > 9999999999) { cout << "Error: Id out of range.n"; this->id = 0; } else this->id = id; }
- 25. Placing Interface and Implementation in Separate Files To bring encapsulation to the next level, we separate the interfaces and its implementations into different files. For every class: – Place its interface in a .hpp file – called header file, e.g. Student.hpp. – Place its implementation in a .cpp file – called source file, e.g. Student.cpp. – In every cpp that needs to refer to the class, "#include" the hpp.
- 26. HPP Header File The use of #ifndef, #define & #endif is to prevent multiple inclusion. // Student.hpp header file #ifndef STUDENT_HPP // Prevent multiple inclusion. #define STUDENT_HPP #include <iostream> #include <string> using namespace std; class Student { int id; vector<string> subjects; public: int getId(); void setId (int id); void show_subjects(); void register_subject(); void withdraw_subject(); }; // End of class #endif
- 27. CPP Source File Every cpp source file that needs to refer to the class should "#include" the hpp. // Student.cpp source file #include "Student.hpp" // Use "", not <>. int Student::getId() { return id; } void Student::setId (int id) { this->id = id; } void Student::show_subjects() { ... } void Student::register_subject() { ... } void Student::withdraw_subject() { ... } // main.cpp source file #include "Student.hpp" // Use "", not <>. int main() { Student s; s.register_subject(); ... }
- 28. Why Encapsulation? 1. To maintain data integrity – By limiting direct access to attributes, we prevent class users from providing invalid data to the object. 2. To reduce the need for class users to worry about the implementation – By separating the interface from the implementation (shorter class declaration), class users can focus on using the class instead of being bothered by the implementation of the class. 3. To improve program maintenance – Separating the interface from the implementation enables us to change the implementation without the class users ever being aware (provided that the interface remains the same).
- 29. Categorizing Objects There might be many objects. 2 common ways to categorize objects are: 1. Categorize similar objects that have the same attributes and behaviors, e.g. the student example. – We have covered this one up until now. 2. Categorize objects by composition, that is when an attribute of a class is a class by itself, e.g. a faculty has many students.
- 30. Categorizing by Composition When categorizing objects by composition, an attribute of a class is a class by itself. Is also referred to as a “has-a” relationship. Example 1: A faculty has many students (both faculty and student are classes). Example 2: Typical corporate organization: – 3 classes can be identified: Dept, Staff, Data. – A Dept has Staff and Data. Personnel Data Personnel Dept. Sales Dept. Personnel Finance Dept. Staff Sales Data Finance Data Sales Messages Finance Staff Staff
- 31. Categorizing by Composition Sample code for the composition involving faculty and student. class Student { // Student is a class. ... }; // End of class class Faculty { // Faculty is a class. string name; vector<Student> students1; // Composition, attribute is // a class by itself. //vector<Student*> students2; // Also composition. //Student students3[10]; // Also composition. //Student* students3; // Also composition. ... };
- 32. UML Class Diagram UML is a formal notation to describe models (representations of things/objects) in sofware development. Class Diagram is one type of many diagrams in UML. Class Diagram contains 2 elements: – Classes represent objects with common attributes, operations, and associations. – Associations represent relationships that relate two or more classes. 32
- 33. Class Diagram Must have 3 sections. Class name is placed at the top Student section. -id:int Attributes are placed at the middle -subjects:string[*] section. +getId():int Behaviors are placed at the bottom +setId(id:int):void section. +show_subjects():void +register_subject():void '-' denotes private access privilege. +withdraw_subject():void '+' denotes public access privilege. '[*]' denotes "many" (array, vector).
- 34. Class Diagram Faculty Student Association -name:string -id: int -students:Student[*] -subjects:string[*] 1 1..n +getId():int +setId(id:int):void +intake() 'n' means many +show_subjects():void +register_subject():void +withdraw_subject():void Associations shows the relationship between instances of classes, e.g. a faculty has one or more students, a student belongs to exactly one faculty only.
- 35. Revisiting Procedural Programming C++ in TCP1101 is taught as a procedural programming language. In procedural programming, the idea is to design a program to solve a problem by concentrating on the procedures first and data second. This approach is known as top-down design. Procedures and data are 2 separate units that relate primarily via function parameter. Main Program Data Function1 Function2 Function3
- 36. Problems with Procedural Programming Unrestricted access to global data struct Student { and procedures. int id; vector<string> subjects; Poor modeling of the real world }; (data and procedures are void register_subject separated). (Student& a) Not the way that humans naturally { ... } think about a situation. void withdraw_subject Poor code reusability. (Student& s) { ... } int main() { Student s; register_subject (s); withdraw_subject (s); }
- 37. Why Object-Oriented Programming? Solve the problems of procedural programming. Restrict access to data and procedures (via encapsulation). Better modeling of real world objects (via abstraction). – Data and procedures are combined in a single unit. – Easier to understand, correct, and modify. Better code reusability – existing objects can be reused to create new objects via inheritance (Lecture 3). More useful for development of large and complex systems.
- 38. Converting Procedural Program to OOP 1. Identify the variables and the global functions that use the variables as parameters, create a class and include the variables and the global functions as class members. 2. Make all attributes private. Const attributes can opt for public. 3. For methods that use the class as parameter(s), remove ONE such parameter. Then update the method body to refer to the member instead of the removed parameter.
- 39. // Procedural version Point readPoint() { #include <iostream> Point p; #include <string> cout << "Enter point x y : "; #include <cmath> cin >> p.x >> p.y; using namespace std; return p; struct Point { } int x, y; // public by default }; void printPoint (Point p) { cout << "(x = " << p.x Point readPoint(); << ", y = "<< p.y void printPoint (Point); << ")" << endl; double distPoint (Point, Point); } int main() { double distPoint (Point p, Point q) Point p1 = readPoint(); { cout << "p1 = "; double dx = p.x - q.x; printPoint (p1); double dy = p.y - q.y; cout << endl; double dsquared = dx*dx + dy*dy; Point p2 = readPoint(); return sqrt (dsquared); cout << "p2 = "; } printPoint (p2); cout << endl << endl; double d = distPoint (p1, p2); cout << "Distance p1 to p2 = " << d << endl; }
- 40. // OOP version double Point::distPoint (Point q) { #include <iostream> double dx = x - q.x; #include <string> double dy = y - q.y; #include <cmath> double dsquared = dx*dx + dy*dy; using namespace std; return sqrt(dsquared); } class Point { int x, y; // private by default int main() { public: Point p1, p2; void readPoint(); void printPoint(); p1.readPoint(); double distPoint (Point q); cout << "p1 = "; }; p1.printPoint(); cout << endl; void Point::readPoint() { p2.readPoint(); cout << "Enter point x y : "; cout << "p2 = "; cin >> x >> y; p2.printPoint(); } cout << endl; void Point::printPoint() { cout << "(x = " << x double d = p1.distPoint (p2); << ", y = " << y cout << "Distance p1 to p2 = " << ")" << endl; << d << endl; } }