Lessons Learned while Implementing a Sparse Logistic Regression Algorithm in Apache Spark with Lorand Dali
3 likes1,446 views

The document discusses lessons learned from implementing a sparse logistic regression algorithm in Spark, highlighting optimization techniques and the importance of using suitable representations for distributed implementations. Key insights include the use of mini-batch gradient descent, better bias initialization, and the Adam optimizer for improved convergence speed. Final performance improvements resulted in a 40x reduction in iteration time.
1 of 42
Downloaded 67 times








![weights
Partitions
Examples
Predictions
Array[Double]
RDD[(Long, Double)]
Seq[(Int, Double)]
RDD[(Long, Seq[(Int, Double)])]
Column index
Feature value
row index
Map[Int, Double]](https://image.slidesharecdn.com/lb9loranddali-171031212752/85/Lessons-Learned-while-Implementing-a-Sparse-Logistic-Regression-Algorithm-in-Apache-Spark-with-Lorand-Dali-9-320.jpg)
![Gradient
Array[Double]
Prediction minus label
Transposed data matrix
RDD[(Long, Double)]
RDD[(Long, Seq[(Int, Double)])]](https://image.slidesharecdn.com/lb9loranddali-171031212752/85/Lessons-Learned-while-Implementing-a-Sparse-Logistic-Regression-Algorithm-in-Apache-Spark-with-Lorand-Dali-10-320.jpg)































Ad
Recommended
jQuery for beginners
jQuery for beginnersArulmurugan Rajaraman Slides for presentation C002 | jQuery for beginners in Sumofyou Technologies
JavaScript - Chapter 3 - Introduction
JavaScript - Chapter 3 - IntroductionWebStackAcademy The document provides an overview of JavaScript, including its history, advantages, and limitations. It details its evolution from a language created by Brendan Eich in 1995 to its current versions under the ECMAScript standards. Additionally, it covers implementation methods, coding conventions, and output methods for JavaScript.
07 Machine Learning - Expectation Maximization
07 Machine Learning - Expectation MaximizationAndres Mendez-Vazquez This document provides an introduction to the Expectation Maximization (EM) algorithm. EM is used to estimate parameters in statistical models when data is incomplete or has missing values. It is a two-step process: 1) Expectation step (E-step), where the expected value of the log likelihood is computed using the current estimate of parameters; 2) Maximization step (M-step), where the parameters are re-estimated to maximize the expected log likelihood found in the E-step. EM is commonly used for problems like clustering with mixture models and hidden Markov models. Applications of EM discussed include clustering data using mixture of Gaussian distributions, and training hidden Markov models for natural language processing tasks. The derivation of the EM algorithm and
Introduction to Bootstrap: Design for Developers
Introduction to Bootstrap: Design for DevelopersMelvin John The document provides an introduction to Bootstrap, one of the most popular front-end frameworks. It discusses basic design principles like proximity, alignment, repetition and contrast. It then covers key aspects of Bootstrap like the grid system, CSS components, JavaScript plugins, customization options, and how it relates to basic design principles. The benefits of Bootstrap are faster development, powerful grid system, customizable styles and responsive components, while potential drawbacks include file size overhead and templates looking similar without customization.
API Design - 3rd Edition
API Design - 3rd EditionApigee | Google Cloud This document provides an agenda for a presentation on API design. It begins with recapping the previous edition and then covers topics like API modeling, security, message design, hypermedia, transactions, URL design, versioning, errors, and client considerations. Throughout the presentation examples are given from APIs like Twitter, Foursquare, Instagram, GitHub, Netflix, and others. The goal is to discuss best practices for designing APIs.
Introduction to MSBI
Introduction to MSBIEdureka! The document provides an introduction to Microsoft Business Intelligence (MSBI). It discusses how MSBI addresses the needs of users by integrating data across networks, providing summarized and historical data to help understand organizational health, and enabling 'what-if' analysis. It describes the MSBI architecture and how it uses SQL Server Integration Services, SQL Server Analysis Services, and SQL Server Reporting Services to move data between sources and destinations, perform online analytical processing to build cubes for analysis, and deliver reports, respectively. The document also compares MSBI to other BI tools and argues it provides the most reliable solution at the lowest total cost.
NumPy.pptx
NumPy.pptxEN1036VivekSingh NumPy is a Python package that provides multidimensional array and matrix objects as well as tools to work with these objects. It was created to handle large, multi-dimensional arrays and matrices efficiently. NumPy arrays enable fast operations on large datasets and facilitate scientific computing using Python. NumPy also contains functions for Fourier transforms, random number generation and linear algebra operations.
Laravel Tutorial PPT
Laravel Tutorial PPTPiyush Aggarwal This document provides an overview of the Laravel PHP framework, including instructions for installation, directory structure, MVC concepts, and a sample "task list" application to demonstrate basic Laravel features. The summary covers creating a Laravel project, defining a database migration and Eloquent model, adding routes and views with Blade templating, performing validation and CRUD operations, and more.
Self Service Reporting & Analytics For an Enterprise
Self Service Reporting & Analytics For an EnterpriseSreejith Madhavan The document discusses self-service analytics for enterprise users, covering key concepts of business intelligence and analytics, including data mining, predictive and prescriptive analytics. It outlines the landscape of enterprise analytics, emphasizing the need for a flexible solution stack that caters to diverse user needs and types, and highlights the importance of integrating various data sources. The document also addresses performance considerations and design principles for building an effective analytics platform, aimed at supporting both technical and non-technical users.
8. sql
8. sqlkhoahuy82 This document provides an overview of SQL and database concepts. It discusses:
- The basic structure of tables, rows, columns, and data types
- The four main SQL languages: DDL, DML, TCL, and DCL and common commands like CREATE, INSERT, UPDATE, DELETE, etc.
- Database objects like tables, views, indexes, and how to query them
- Constraints like PRIMARY KEY, UNIQUE, NOT NULL and REFERENTIAL integrity
- Transactions with COMMIT, ROLLBACK, and SAVEPOINT
Html / CSS Presentation
Html / CSS PresentationShawn Calvert The document is a detailed guide on front-end and back-end coding, focusing on HTML, CSS, and JavaScript within the context of web design. It outlines the structure, style, and behavior of web pages, including the roles of static and dynamic content, as well as CSS rules and selectors. Key topics include document hierarchy, attributes, specificity in styling, and the application of styles through classes and IDs.
Vistas En Sql Y My Sql
Vistas En Sql Y My SqlZiscko Este documento describe las vistas en SQL Server y MySQL. Explica que las vistas son tablas virtuales que muestran datos de otras tablas sin almacenarlos realmente. Detalla cómo crear, modificar y eliminar vistas usando sentencias como CREATE VIEW, ALTER VIEW y DROP VIEW. Además, señala que las vistas se usan comúnmente para simplificar consultas complejas, restringir el acceso a datos sensibles y crear esquemas externos.
Le schéma directeur
Le schéma directeurSVrignaud Le schéma directeur du système d'informations (S.I.) vise à aligner l'évolution du S.I. avec l'axe stratégique de l'organisation pour garantir sa performance dans le temps. Il définit des étapes de migration et d'adaptation nécessaires pour éviter les surcoûts et les freins, tout en s'assurant que la vision stratégique est partagée. En intégrant l'infrastructure technique, l'organisation logicielle et le management, ce schéma se veut accessible à tous les acteurs de l'entreprise.
SQL Queries
SQL QueriesNilt1234 This document provides an introduction to SQL and database systems. It begins with example tables to demonstrate SQL concepts. It then covers the objectives of SQL, including allowing users to create database structures, manipulate data, and perform queries. Various SQL concepts are introduced such as data types, comparison operators, logical operators, and arithmetic operators. The document also discusses SQL statements for schema and catalog definitions, data definition, data manipulation, and other operators. Example SQL queries are provided to illustrate concepts around selecting columns, rows, sorting, aggregation, grouping, and more.
les techniques TALN
les techniques TALNetudiantemaster2 Le document présente le traitement automatique des langues (TAL) comme une discipline multidisciplinaire liant linguistique et informatique, visant à développer des logiciels capables de traiter des données linguistiques. Deux approches y sont décrites : l'approche symbolique, reposant sur des analyses syntaxiques et sémantiques, et l'approche statistique, qui utilise l'apprentissage automatique pour traiter de grandes quantités de données. Le TAL trouve de nombreuses applications dans les outils quotidiens et professionnels, bien qu'il reste des défis à relever pour intégrer ces deux approches efficacement.
Intro to HTML & CSS
Intro to HTML & CSSSyed Sami The document provides an overview of HTML and CSS, covering topics such as the structure of an HTML document, HTML tags, CSS, and how to create a basic webpage. It discusses what HTML and CSS are, why they are needed, popular HTML tags, and gives examples of adding CSS to an HTML document. It also provides a hands-on tutorial showing how to build a simple website covering HTML basics and using CSS for styling.
Modèles de langue : Ngrammes
Modèles de langue : NgrammesJaouad Dabounou Le document traite du traitement automatique du langage naturel (TALN) et présente les modèles de langue, incluant leurs applications dans la traduction, la correction d'erreur et l'analyse de sentiments. Il explique également comment ces modèles sont construits à partir de corpus textuels et l'importance des probabilités conditionnelles dans leur conception. Enfin, il aborde la notion d'espace sémantique et la manière dont les machines peuvent comprendre le langage à travers l'analyse des régularités linguistiques.
ETL VS ELT.pdf
ETL VS ELT.pdfBOSupport ETL extracts raw data from sources, transforms it on a separate server, and loads it into a target database. ELT loads raw data directly into a data warehouse, where data cleansing, enrichment, and transformations occur. While ETL has been used longer and has more supporting tools, ELT allows for faster queries, greater flexibility, and takes advantage of cloud data warehouse capabilities by performing transformations within the warehouse. However, ELT can present greater security risks and increased latency compared to ETL.
Introduction to Stream Processing
Introduction to Stream ProcessingGuido Schmutz The document is a presentation on stream processing by Guido Schmutz, covering motivation, capabilities, implementation, and applications of stream processing solutions. It discusses the differences between data at rest and data in motion, the architecture for stream analytics, and technologies involved (like Apache Kafka and Spark). Additionally, it outlines key concepts such as stream data integration, delivery guarantees, state management, and event pattern detection.
Overview SQL Server 2019
Overview SQL Server 2019Juan Fabian The document outlines the roadmap for SQL Server, including enhancements to performance, security, availability, development tools, and big data capabilities. Key updates include improved intelligent query processing, confidential computing with secure enclaves, high availability options on Kubernetes, machine learning services, and tools in Azure Data Studio. The roadmap aims to make SQL Server the most secure, high performing, and intelligent data platform across on-premises, private cloud and public cloud environments.
Intégration des données avec Talend ETL
Intégration des données avec Talend ETLLilia Sfaxi Le document présente un TP sur l'intégration de données utilisant Talend Open Studio, abordant des concepts comme l'extraction et la transformation de données à partir de différentes sources. Il détaille les étapes pour manipuler des fichiers CSV et des bases de données, incluant le tri, la jointure et la sélection des données. Le TP se conclut par un devoir à réaliser à partir des travaux pratiques, axé sur les opérations de jointure et de stockage des données.
Data Visualization With Tableau | Edureka
Data Visualization With Tableau | EdurekaEdureka! The document discusses data visualization using Tableau, highlighting its ability to connect to various data sources and facilitate data analysis. It outlines who should consider using Tableau, such as business analysts and data scientists, and provides insights into job trends and companies utilizing the software. Additionally, it covers Tableau's architecture and visualization capabilities, including real-time use cases.
CSS Font & Text style
CSS Font & Text style Yaowaluck Promdee The document outlines web design technology with a focus on CSS font properties, detailing various font sizes, units of measurement, font families, and styles. It includes examples of using different CSS properties to manipulate typography, such as font-size, font-weight, and text-decoration. Additionally, there are mentions of web-safe fonts and specific assignments related to CSS font design.
Qu'est-ce qu'un ETL ?
Qu'est-ce qu'un ETL ?Mathieu Lahaye L'ETL (Extract-Transform-Load) est un processus utilisé pour accéder à diverses sources de données, les manipuler, et les intégrer dans un entrepôt de données. Il permet de traiter des données structurées, semi-structurées et non-structurées tout en garantissant leur qualité et leur conformité. Les entreprises utilisent l'ETL pour analyser et croiser des informations afin de prendre de meilleures décisions d'affaires.
Computer Vision - Classification automatique des races de chien à partir de p...
Computer Vision - Classification automatique des races de chien à partir de p...FUMERY Michael Le document traite de la détection automatique de la race de chien à partir d'images en utilisant des algorithmes de deep learning, en se concentrant sur le dataset Stanford Dogs. Différentes méthodes de modélisation, y compris le deep learning from scratch et le transfert learning avec les modèles Xception et ResNet50, ont été explorées, aboutissant à des résultats significatifs, notamment une précision supérieure à 72% sur des données de test. Le processus inclut des étapes de prétraitement des images et d'optimisation des hyperparamètres pour améliorer la performance du modèle.
Data Quality With or Without Apache Spark and Its Ecosystem
Data Quality With or Without Apache Spark and Its EcosystemDatabricks The document discusses the importance of data quality and various methodologies for ensuring it, particularly in relation to Apache Spark and its ecosystem. It highlights the need for data profiling, ETL quality checks, and various tools like Deequ and Great Expectations for managing data integrity. The text emphasizes that effective data management requires sophistication within organizations and may necessitate continued internal development of expertise.
Data Engineering Basics
Data Engineering BasicsCatherine Kimani The document outlines the basics of data engineering, including definitions of key roles such as data engineers and data scientists, as well as core concepts like ETL (extract, transform, load) processes and data classification. It highlights the properties of big data, including volume, velocity, variety, and veracity, along with processing methods like batch and stream processing. Additionally, it mentions various data storage solutions, such as relational databases and document stores.
CSS3 Media Queries And Creating Adaptive Layouts
CSS3 Media Queries And Creating Adaptive LayoutsSvitlana Ivanytska This document discusses creating adaptive layouts using CSS3 media queries. It defines the differences between adaptive and responsive design, with adaptive using predefined layouts for different screen sizes and responsive providing an optimal experience across devices. Key concepts for adaptive design are progressive enhancement and mobile-first. The document outlines main principles like flexible grid-based layouts, flexible media, and using media queries to apply CSS styles based on features like width, height, and orientation. It provides examples of media query syntax and supported media features.
Easy, scalable, fault tolerant stream processing with structured streaming - ...
Easy, scalable, fault tolerant stream processing with structured streaming - ...Databricks The document discusses the complexities of building scalable and fault-tolerant stream processing applications using Structured Streaming with Apache Spark. It highlights key features such as handling diverse data formats and storage systems, ensuring exactly-once processing semantics, and leveraging Spark SQL for incremental execution. The presentation covers practical examples and concepts like triggers, output modes, and watermarking to efficiently manage state and late data in streaming queries.
Deduplication and Author-Disambiguation of Streaming Records via Supervised M...
Deduplication and Author-Disambiguation of Streaming Records via Supervised M...Spark Summit The document discusses advancements in deduplication and author disambiguation of scholarly records using supervised models and content encoders within the Elsevier platform, emphasizing the importance of efficient data processing techniques. It outlines the challenges and solutions for managing peer-reviewed publications in Scopus, focusing on machine learning and cloud scalability for real-time document analysis. The implementation of algorithms like word2vec for document encoding aims to improve recommendation systems and personalized user experiences across various academic entities.
More Related Content
What's hot (20)
Self Service Reporting & Analytics For an Enterprise
Self Service Reporting & Analytics For an EnterpriseSreejith Madhavan The document discusses self-service analytics for enterprise users, covering key concepts of business intelligence and analytics, including data mining, predictive and prescriptive analytics. It outlines the landscape of enterprise analytics, emphasizing the need for a flexible solution stack that caters to diverse user needs and types, and highlights the importance of integrating various data sources. The document also addresses performance considerations and design principles for building an effective analytics platform, aimed at supporting both technical and non-technical users.
8. sql
8. sqlkhoahuy82 This document provides an overview of SQL and database concepts. It discusses:
- The basic structure of tables, rows, columns, and data types
- The four main SQL languages: DDL, DML, TCL, and DCL and common commands like CREATE, INSERT, UPDATE, DELETE, etc.
- Database objects like tables, views, indexes, and how to query them
- Constraints like PRIMARY KEY, UNIQUE, NOT NULL and REFERENTIAL integrity
- Transactions with COMMIT, ROLLBACK, and SAVEPOINT
Html / CSS Presentation
Html / CSS PresentationShawn Calvert The document is a detailed guide on front-end and back-end coding, focusing on HTML, CSS, and JavaScript within the context of web design. It outlines the structure, style, and behavior of web pages, including the roles of static and dynamic content, as well as CSS rules and selectors. Key topics include document hierarchy, attributes, specificity in styling, and the application of styles through classes and IDs.
Vistas En Sql Y My Sql
Vistas En Sql Y My SqlZiscko Este documento describe las vistas en SQL Server y MySQL. Explica que las vistas son tablas virtuales que muestran datos de otras tablas sin almacenarlos realmente. Detalla cómo crear, modificar y eliminar vistas usando sentencias como CREATE VIEW, ALTER VIEW y DROP VIEW. Además, señala que las vistas se usan comúnmente para simplificar consultas complejas, restringir el acceso a datos sensibles y crear esquemas externos.
Le schéma directeur
Le schéma directeurSVrignaud Le schéma directeur du système d'informations (S.I.) vise à aligner l'évolution du S.I. avec l'axe stratégique de l'organisation pour garantir sa performance dans le temps. Il définit des étapes de migration et d'adaptation nécessaires pour éviter les surcoûts et les freins, tout en s'assurant que la vision stratégique est partagée. En intégrant l'infrastructure technique, l'organisation logicielle et le management, ce schéma se veut accessible à tous les acteurs de l'entreprise.
SQL Queries
SQL QueriesNilt1234 This document provides an introduction to SQL and database systems. It begins with example tables to demonstrate SQL concepts. It then covers the objectives of SQL, including allowing users to create database structures, manipulate data, and perform queries. Various SQL concepts are introduced such as data types, comparison operators, logical operators, and arithmetic operators. The document also discusses SQL statements for schema and catalog definitions, data definition, data manipulation, and other operators. Example SQL queries are provided to illustrate concepts around selecting columns, rows, sorting, aggregation, grouping, and more.
les techniques TALN
les techniques TALNetudiantemaster2 Le document présente le traitement automatique des langues (TAL) comme une discipline multidisciplinaire liant linguistique et informatique, visant à développer des logiciels capables de traiter des données linguistiques. Deux approches y sont décrites : l'approche symbolique, reposant sur des analyses syntaxiques et sémantiques, et l'approche statistique, qui utilise l'apprentissage automatique pour traiter de grandes quantités de données. Le TAL trouve de nombreuses applications dans les outils quotidiens et professionnels, bien qu'il reste des défis à relever pour intégrer ces deux approches efficacement.
Intro to HTML & CSS
Intro to HTML & CSSSyed Sami The document provides an overview of HTML and CSS, covering topics such as the structure of an HTML document, HTML tags, CSS, and how to create a basic webpage. It discusses what HTML and CSS are, why they are needed, popular HTML tags, and gives examples of adding CSS to an HTML document. It also provides a hands-on tutorial showing how to build a simple website covering HTML basics and using CSS for styling.
Modèles de langue : Ngrammes
Modèles de langue : NgrammesJaouad Dabounou Le document traite du traitement automatique du langage naturel (TALN) et présente les modèles de langue, incluant leurs applications dans la traduction, la correction d'erreur et l'analyse de sentiments. Il explique également comment ces modèles sont construits à partir de corpus textuels et l'importance des probabilités conditionnelles dans leur conception. Enfin, il aborde la notion d'espace sémantique et la manière dont les machines peuvent comprendre le langage à travers l'analyse des régularités linguistiques.
ETL VS ELT.pdf
ETL VS ELT.pdfBOSupport ETL extracts raw data from sources, transforms it on a separate server, and loads it into a target database. ELT loads raw data directly into a data warehouse, where data cleansing, enrichment, and transformations occur. While ETL has been used longer and has more supporting tools, ELT allows for faster queries, greater flexibility, and takes advantage of cloud data warehouse capabilities by performing transformations within the warehouse. However, ELT can present greater security risks and increased latency compared to ETL.
Introduction to Stream Processing
Introduction to Stream ProcessingGuido Schmutz The document is a presentation on stream processing by Guido Schmutz, covering motivation, capabilities, implementation, and applications of stream processing solutions. It discusses the differences between data at rest and data in motion, the architecture for stream analytics, and technologies involved (like Apache Kafka and Spark). Additionally, it outlines key concepts such as stream data integration, delivery guarantees, state management, and event pattern detection.
Overview SQL Server 2019
Overview SQL Server 2019Juan Fabian The document outlines the roadmap for SQL Server, including enhancements to performance, security, availability, development tools, and big data capabilities. Key updates include improved intelligent query processing, confidential computing with secure enclaves, high availability options on Kubernetes, machine learning services, and tools in Azure Data Studio. The roadmap aims to make SQL Server the most secure, high performing, and intelligent data platform across on-premises, private cloud and public cloud environments.
Intégration des données avec Talend ETL
Intégration des données avec Talend ETLLilia Sfaxi Le document présente un TP sur l'intégration de données utilisant Talend Open Studio, abordant des concepts comme l'extraction et la transformation de données à partir de différentes sources. Il détaille les étapes pour manipuler des fichiers CSV et des bases de données, incluant le tri, la jointure et la sélection des données. Le TP se conclut par un devoir à réaliser à partir des travaux pratiques, axé sur les opérations de jointure et de stockage des données.
Data Visualization With Tableau | Edureka
Data Visualization With Tableau | EdurekaEdureka! The document discusses data visualization using Tableau, highlighting its ability to connect to various data sources and facilitate data analysis. It outlines who should consider using Tableau, such as business analysts and data scientists, and provides insights into job trends and companies utilizing the software. Additionally, it covers Tableau's architecture and visualization capabilities, including real-time use cases.
CSS Font & Text style
CSS Font & Text style Yaowaluck Promdee The document outlines web design technology with a focus on CSS font properties, detailing various font sizes, units of measurement, font families, and styles. It includes examples of using different CSS properties to manipulate typography, such as font-size, font-weight, and text-decoration. Additionally, there are mentions of web-safe fonts and specific assignments related to CSS font design.
Qu'est-ce qu'un ETL ?
Qu'est-ce qu'un ETL ?Mathieu Lahaye L'ETL (Extract-Transform-Load) est un processus utilisé pour accéder à diverses sources de données, les manipuler, et les intégrer dans un entrepôt de données. Il permet de traiter des données structurées, semi-structurées et non-structurées tout en garantissant leur qualité et leur conformité. Les entreprises utilisent l'ETL pour analyser et croiser des informations afin de prendre de meilleures décisions d'affaires.
Computer Vision - Classification automatique des races de chien à partir de p...
Computer Vision - Classification automatique des races de chien à partir de p...FUMERY Michael Le document traite de la détection automatique de la race de chien à partir d'images en utilisant des algorithmes de deep learning, en se concentrant sur le dataset Stanford Dogs. Différentes méthodes de modélisation, y compris le deep learning from scratch et le transfert learning avec les modèles Xception et ResNet50, ont été explorées, aboutissant à des résultats significatifs, notamment une précision supérieure à 72% sur des données de test. Le processus inclut des étapes de prétraitement des images et d'optimisation des hyperparamètres pour améliorer la performance du modèle.
Data Quality With or Without Apache Spark and Its Ecosystem
Data Quality With or Without Apache Spark and Its EcosystemDatabricks The document discusses the importance of data quality and various methodologies for ensuring it, particularly in relation to Apache Spark and its ecosystem. It highlights the need for data profiling, ETL quality checks, and various tools like Deequ and Great Expectations for managing data integrity. The text emphasizes that effective data management requires sophistication within organizations and may necessitate continued internal development of expertise.
Data Engineering Basics
Data Engineering BasicsCatherine Kimani The document outlines the basics of data engineering, including definitions of key roles such as data engineers and data scientists, as well as core concepts like ETL (extract, transform, load) processes and data classification. It highlights the properties of big data, including volume, velocity, variety, and veracity, along with processing methods like batch and stream processing. Additionally, it mentions various data storage solutions, such as relational databases and document stores.
CSS3 Media Queries And Creating Adaptive Layouts
CSS3 Media Queries And Creating Adaptive LayoutsSvitlana Ivanytska This document discusses creating adaptive layouts using CSS3 media queries. It defines the differences between adaptive and responsive design, with adaptive using predefined layouts for different screen sizes and responsive providing an optimal experience across devices. Key concepts for adaptive design are progressive enhancement and mobile-first. The document outlines main principles like flexible grid-based layouts, flexible media, and using media queries to apply CSS styles based on features like width, height, and orientation. It provides examples of media query syntax and supported media features.
Viewers also liked (8)
Easy, scalable, fault tolerant stream processing with structured streaming - ...
Easy, scalable, fault tolerant stream processing with structured streaming - ...Databricks The document discusses the complexities of building scalable and fault-tolerant stream processing applications using Structured Streaming with Apache Spark. It highlights key features such as handling diverse data formats and storage systems, ensuring exactly-once processing semantics, and leveraging Spark SQL for incremental execution. The presentation covers practical examples and concepts like triggers, output modes, and watermarking to efficiently manage state and late data in streaming queries.
Deduplication and Author-Disambiguation of Streaming Records via Supervised M...
Deduplication and Author-Disambiguation of Streaming Records via Supervised M...Spark Summit The document discusses advancements in deduplication and author disambiguation of scholarly records using supervised models and content encoders within the Elsevier platform, emphasizing the importance of efficient data processing techniques. It outlines the challenges and solutions for managing peer-reviewed publications in Scopus, focusing on machine learning and cloud scalability for real-time document analysis. The implementation of algorithms like word2vec for document encoding aims to improve recommendation systems and personalized user experiences across various academic entities.
Using Pluggable Apache Spark SQL Filters to Help GridPocket Users Keep Up wit...
Using Pluggable Apache Spark SQL Filters to Help GridPocket Users Keep Up wit...Spark Summit The document discusses the use of pluggable Apache Spark SQL filters by GridPocket to enhance energy management and consumer engagement in smart grid applications. It emphasizes the importance of peer comparison in influencing energy-saving behaviors and details a dataset management solution involving object storage and metadata indexing. The proposed methods aim to improve query performance and reduce data transfer costs in Spark SQL operations, specifically for geospatial and other types of data.
Optimal Strategies for Large Scale Batch ETL Jobs with Emma Tang
Optimal Strategies for Large Scale Batch ETL Jobs with Emma TangDatabricks The document discusses optimal strategies for managing large-scale batch ETL jobs at Neustar, emphasizing efficient resource use and addressing issues such as data skew and memory management. It provides insights into handling large datasets, improving job performance, and using tools like Ganglia for monitoring. Key recommendations include increasing partitioning, filtering data, and configuring Spark settings for performance optimization.
Apache Spark and Tensorflow as a Service with Jim Dowling
Apache Spark and Tensorflow as a Service with Jim DowlingSpark Summit The document discusses advancements in deep learning, particularly the integration of TensorFlow and Spark for distributed training, highlighting the need for robust data pipelines and hardware configurations. It outlines various models and frameworks, such as Horovod and TensorFlow on Spark, to enhance efficiency in training using multiple GPUs and optimization techniques. Additionally, it presents the AI hierarchy of needs and the role of Hopsworks in supporting machine learning workflows.
Storage Engine Considerations for Your Apache Spark Applications with Mladen ...
Storage Engine Considerations for Your Apache Spark Applications with Mladen ...Spark Summit The document discusses various storage solutions for Apache Spark applications, including HDFS, HBase, Kudu, and Solr, outlining their unique capabilities and ideal use cases. It emphasizes the importance of understanding ingestion and consumption requirements, asking the right questions, and carefully choosing a storage system based on specific use-case needs. Additionally, it provides design patterns and implementation strategies for integrating these storage systems with Spark.
Building Custom ML PipelineStages for Feature Selection with Marc Kaminski
Building Custom ML PipelineStages for Feature Selection with Marc KaminskiSpark Summit The document discusses the implementation of custom machine learning pipeline stages for feature selection at BMW, focusing on the challenges of high-dimensional datasets and the necessity for data-driven car diagnostics. It outlines motivations for transitioning from manual to automated processes, highlighting the impact of feature selection on learning performance. Attendees of the Spark Summit Europe 2017 session will learn about Spark ML pipeline stages, including code examples in Scala.
Deep-Dive into Deep Learning Pipelines with Sue Ann Hong and Tim Hunter
Deep-Dive into Deep Learning Pipelines with Sue Ann Hong and Tim HunterDatabricks This document discusses the use of Apache Spark for building, scaling, and deploying deep learning pipelines, emphasizing the integration of various libraries such as TensorFlow, Keras, and others. It outlines the typical workflow of deep learning, covers the benefits of using Spark for distributed training and efficient data handling, and highlights features of Databricks' deep learning pipelines which simplify the process without sacrificing performance. Additionally, it addresses future developments and current practices in the industry for enhancing deep learning accessibility.
Ad
Similar to Lessons Learned while Implementing a Sparse Logistic Regression Algorithm in Apache Spark with Lorand Dali (20)
Scaling out logistic regression with Spark
Scaling out logistic regression with SparkBarak Gitsis This document discusses scaling out logistic regression with Apache Spark. It describes the need to classify a large number of websites using machine learning. Several approaches to logistic regression were tried, including a single machine Java implementation and moving to Spark for better scalability. Spark's L-BFGS algorithm was chosen for its out of the box distributed logistic regression solution. Challenges implementing logistic regression at large scale are discussed, such as overfitting and regularization. Methods used to address these challenges include L2 regularization, cross-validation to select the regularization parameter, and extensions made to Spark's LBFGS implementation.
Apache Sparkを用いたスケーラブルな時系列データの異常検知モデル学習ソフトウェアの開発
Apache Sparkを用いたスケーラブルな時系列データの異常検知モデル学習ソフトウェアの開発Ryo 亮 Kawahara 河原 The document outlines a method for developing software for scalable anomaly detection in time-series data using Apache Spark. It discusses the implementation of a prediction model that compares observed sensor data with predicted values to identify anomalies, and details the use of lasso regression for training the model. Performance improvements and challenges faced during the process, such as order preservation in RDD operations and the use of alternative APIs, are also highlighted.
NYAI - Scaling Machine Learning Applications by Braxton McKee
NYAI - Scaling Machine Learning Applications by Braxton McKeeRizwan Habib The document discusses Pyfora, an open-source tool designed to automatically scale Python programs for large datasets without requiring extensive rewrites. It highlights the challenges of optimizing machine learning algorithms as data sizes grow and offers solutions for parallelism and cache locality. Pyfora operates by modifying Python's behavior, allowing the runtime system to dynamically optimize executions based on data characteristics.
Braxton McKee, CEO & Founder, Ufora at MLconf NYC - 4/15/16
Braxton McKee, CEO & Founder, Ufora at MLconf NYC - 4/15/16MLconf The document discusses Pyfora, a tool designed to automate the scalability of Python programs for large-scale machine learning without requiring extensive rewrites as datasets grow. It emphasizes leveraging source code analysis for efficient execution during runtime, enabling parallel processing without complex frameworks. Pyfora aims to address common programming challenges in scaling and performance optimization through a simpler, more expressive approach to parallelism and data management.
Training Large-scale Ad Ranking Models in Spark
Training Large-scale Ad Ranking Models in SparkPatrick Pletscher This document summarizes Patrick Pletscher's presentation on training large-scale ad ranking models in Apache Spark. It discusses using Spark to implement logistic regression for click-through rate prediction on billions of daily ad impressions at Yahoo. Key points include joining impression and click data, implementing an incremental learning architecture in Spark, using feature hashing and online learning algorithms like follow-the-regularized-leader for model training, and lessons learned around Spark configurations, accumulators, and RDDs vs DataFrames.
Scalding: Twitter's New DSL for Hadoop
Scalding: Twitter's New DSL for HadoopDataWorks Summit Scalding is an open source Scala library for writing MapReduce jobs. It allows writing MapReduce logic in a functional style using Scala collections and avoids writing external UDFs. Scalding uses Cascading under the hood to handle MapReduce planning and optimization. At Twitter, over 60 Scalding jobs are used in production for tasks like ad targeting, market analysis, and recommendation algorithms implemented using Scalding's linear algebra and matrix libraries. Future work includes improving logical query planning and matrix optimizations.
Scalding: Twitter's Scala DSL for Hadoop/Cascading
Scalding: Twitter's Scala DSL for Hadoop/Cascadingjohnynek The document outlines the features and functionalities of Scalding, a Scala-based library used for map/reduce tasks at Twitter, highlighting its data flow modeling and integration with various data sources. It emphasizes the advantages of Scala for implementing domain-specific languages and the library's capabilities for complex data processing, such as parallel reductions and optimized joins. Additionally, upcoming improvements and the widespread use of Scalding within Twitter's revenue quality team are mentioned.
What`s New in Java 8
What`s New in Java 8Mohsen Zainalpour This document provides an overview and summary of new features in Java 8. It begins with the schedule and release dates for Java 8 from 2012 to 2014. The major changes covered include lambda expressions, which allow passing code as data and are enabled by default functional interfaces. The new date/time API provides a modern replacement for the legacy Date/Calendar APIs. Type annotations allow adding metadata to types. Compact profiles define modular class libraries. Overall, Java 8 aims to better support parallel programming through new language features and library APIs.
Python VS GO
Python VS GOOfir Nir Go provided a 25% performance improvement over Python for a data integration task. Further optimizations in Go, like using goroutines and minimizing memory allocations, resulted in a 3.5x faster runtime than the original Python code. While Python has many useful libraries, Go is better suited for CPU-intensive and high-throughput workloads due to its low overhead concurrency model and compiled speed. The team concluded Go would be preferable for their data ingestion needs due to its performance advantages.
Speed up R with parallel programming in the Cloud
Speed up R with parallel programming in the CloudRevolution Analytics David M. Smith discusses the use of R for data science, particularly in production environments, highlighting the need for parallel programming to enhance performance. He introduces tools like the 'foreach' package for parallel processing and 'doazureparallel' for leveraging Azure cloud resources to run R code efficiently. Additionally, the document covers integrating R with Spark for larger datasets using the 'sparklyr' package and provides practical guidance on setting up clusters and optimizing R workflows.
XGBoost: the algorithm that wins every competition
XGBoost: the algorithm that wins every competitionJaroslaw Szymczak The document discusses XGBoost, a powerful algorithm widely used in data science competitions for tasks like classification and regression. It covers various aspects such as feature handling, loss functions, model evaluation, and regularization parameters, along with setup instructions for using XGBoost in Python. The document also highlights winning solutions from competitions that leveraged the capabilities of XGBoost through feature engineering and parameter tuning.
Tom Peters, Software Engineer, Ufora at MLconf ATL 2016
Tom Peters, Software Engineer, Ufora at MLconf ATL 2016MLconf This document discusses Pyfora, a tool designed for scaling up Python programs as datasets grow, without requiring program rewrites. It emphasizes the advantages of language-based systems over API-based frameworks for performance optimization and ease of use, while providing examples of implementation challenges and solutions. The document highlights ongoing work in the area of compiler optimizations and automatic handling of data and computation across different environments.
Machine Learning with Spark
Machine Learning with Sparkelephantscale The document outlines a webinar on machine learning with Spark, focusing on essential skills for data scientists, including familiarity with programming languages and basic Linux environments. It discusses different types of machine learning, such as supervised, unsupervised, and semi-supervised learning, along with practical applications and tools like Spark and Scala. Additionally, it highlights the importance of mitigating developer productivity bottlenecks and emphasizes a balanced approach to coding and theoretical understanding.
Apache spark as a gateway drug to FP concepts taught and broken - Curry On 2018
Apache spark as a gateway drug to FP concepts taught and broken - Curry On 2018Holden Karau The document is a presentation by Holden Karau discussing Apache Spark and its role in introducing functional programming concepts to developers. It covers Spark's capabilities, advantages, and disadvantages, as well as its internals and tools for various programming languages. The talk aims to show how Spark can engage non-functional programming users in learning functional programming principles through practical examples.
Testing and validating distributed systems with Apache Spark and Apache Beam ...
Testing and validating distributed systems with Apache Spark and Apache Beam ...Holden Karau The document discusses the importance of testing and validating distributed systems using Apache Spark and Beam, covering topics like unit testing, validation rules, and testing at scale. It aims to highlight challenges associated with testing, such as data generation and the intricacies of distributed systems, while also introducing various tools and practices to enhance testing efficiency. Additionally, it features examples of unit tests and validations for Spark and Beam, along with a call to action for better testing practices.
Oct.22nd.Presentation.Final
Oct.22nd.Presentation.FinalAndrey Skripnikov This document discusses various techniques for optimizing R code performance, including profiling code to identify bottlenecks, vectorizing operations, avoiding copies, and byte code compilation. It provides examples demonstrating how to measure performance, compare alternative implementations, and apply techniques like doing less work, vectorization, and avoiding method dispatch overhead. The key message is that optimizing performance is an iterative process of measuring, testing alternatives, and applying strategies like these to eliminate bottlenecks.
Spark ml streaming
Spark ml streamingAdam Doyle The document discusses Spark streaming and machine learning concepts like logistic regression, linear regression, and clustering algorithms. It provides code examples in Scala and Python showing how to perform binary classification on streaming data using Spark MLlib. Links and documentation are referenced for setting up streaming machine learning pipelines to train models on streaming data in real-time and make predictions.
Alpine academy apache spark series #1 introduction to cluster computing wit...
Alpine academy apache spark series #1 introduction to cluster computing wit...Holden Karau The document is a presentation by Holden Karau that introduces Apache Spark, a fast and general-purpose distributed computing system, emphasizing its capabilities for data processing with Python and Scala. It covers key concepts such as Resilient Distributed Datasets (RDDs), common transformations and actions, as well as Spark SQL and DataFrames for structured data. Additional resources and exercises are provided to help users get hands-on experience with Spark programming.
Ingesting Over Four Million Rows Per Second With QuestDB Timeseries Database ...
Ingesting Over Four Million Rows Per Second With QuestDB Timeseries Database ...javier ramirez Javier Ramirez discusses the evolution and performance of various database systems, emphasizing the strengths and specialized use cases of QuestDB, particularly for time-series data. He outlines key assumptions for data ingestion and querying, highlighting the need for efficient storage and querying strategies tailored to time-series patterns. The document also covers technical considerations, trade-offs, and future enhancements aimed at improving performance and compatibility.
Explore big data at speed of thought with Spark 2.0 and Snappydata
Explore big data at speed of thought with Spark 2.0 and SnappydataData Con LA SnappyData is an open-source, hybrid database that integrates OLTP and OLAP with Spark for real-time analytics. It enhances performance by utilizing in-memory processing, improved SQL execution, and advanced sampling techniques, enabling faster and more efficient query responses. The technology supports interactive analytics with minimal resource usage and offers a unified architecture for managing disparate data sources.
Ad
More from Spark Summit (20)
FPGA-Based Acceleration Architecture for Spark SQL Qi Xie and Quanfu Wang
FPGA-Based Acceleration Architecture for Spark SQL Qi Xie and Quanfu Wang Spark Summit The document discusses an FPGA-based acceleration architecture for Spark SQL, detailing its components and advantages such as reduced execution times and CPU utilization improvements. It presents a performance comparison showing a significant speedup in query execution from 86 seconds to 44 seconds with FPGA acceleration. Additionally, it outlines future work, including expanding SQL expression support and configuring the FPGA SQL acceleration engine for more versatile application.
VEGAS: The Missing Matplotlib for Scala/Apache Spark with DB Tsai and Roger M...
VEGAS: The Missing Matplotlib for Scala/Apache Spark with DB Tsai and Roger M...Spark Summit Vegas is a visualization library for Scala, designed to fill the gap in the Scala/Spark ecosystem similar to Matplotlib in Python. It allows for declarative statistical visualizations with built-in operations like filtering and aggregation, enhancing productivity in machine learning experimentation. The library also supports various plot types, interactive selections, and is designed for seamless integration within notebooks.
Apache Spark Structured Streaming Helps Smart Manufacturing with Xiaochang Wu
Apache Spark Structured Streaming Helps Smart Manufacturing with Xiaochang WuSpark Summit The document outlines the use of Spark Structured Streaming to build a smart manufacturing IoT data platform, focusing on enhancing efficiency in PCB manufacturing through predictive fault repair and material tracking. It details architectural features, data processing capabilities, and handling of stateless and stateful operations, along with improvement proposals for more complex event processing. Key components include real-time analytics, device management, data visualization, and the support for various data types.
Improving Traffic Prediction Using Weather Data with Ramya Raghavendra
Improving Traffic Prediction Using Weather Data with Ramya RaghavendraSpark Summit The document outlines a research project by IBM to improve traffic prediction using weather data, highlighting the challenges of data collection and modeling. It details the machine learning processes used, including various algorithms like ARIMA and LSTM, to predict traffic flows based on historical traffic and weather data across multiple cities. The study demonstrates significant reductions in prediction errors, emphasizing the potential of predictive traffic systems to enhance commuting efficiency.
A Tale of Two Graph Frameworks on Spark: GraphFrames and Tinkerpop OLAP Artem...
A Tale of Two Graph Frameworks on Spark: GraphFrames and Tinkerpop OLAP Artem...Spark Summit The document compares two graph analytics frameworks, Tinkerpop and GraphFrames, used with Apache Spark, highlighting their distinct approaches. Tinkerpop is a flexible OLAP framework that operates on a node-centric model, while GraphFrames offers a relational structure and integrates closely with Spark's DataFrame API for optimization. The choice of framework depends on the complexity of traversals and the need for interoperability with external data sources.
No More Cumbersomeness: Automatic Predictive Modeling on Apache Spark Marcin ...
No More Cumbersomeness: Automatic Predictive Modeling on Apache Spark Marcin ...Spark Summit The document discusses automatic predictive modeling on Apache Spark, emphasizing the challenges and solutions associated with predictive modeling in industry. It highlights the advantages of the authors' technology that combines Spark with native machine learning engines to automate the process, providing accurate results in a fraction of the time typically required. The evaluation of their approach demonstrates competitive accuracy and efficiency across various datasets.
Apache Spark and Tensorflow as a Service with Jim Dowling
Apache Spark and Tensorflow as a Service with Jim DowlingSpark Summit The document discusses advances in distributed deep learning (DDL), highlighting the use of technologies such as TensorFlow and Spark for training large models efficiently. It details the AI hierarchy of needs, the integration of GPU resources, and various methods like allreduce for optimizing training times. Additionally, it presents the capabilities of Hopsworks, a platform for managing AI workflows and resources.
MMLSpark: Lessons from Building a SparkML-Compatible Machine Learning Library...
MMLSpark: Lessons from Building a SparkML-Compatible Machine Learning Library...Spark Summit The document discusses MMLSpark, a machine learning library designed for Apache Spark, detailing its goals, architecture, and lessons learned during development. Key aspects include enhancing the Spark ecosystem through integration, improving model management, and reducing overhead from user-defined functions while ensuring composability. An example use case highlights its application in automatic image classification for snow leopard conservation, saving time and increasing accuracy.
Next CERN Accelerator Logging Service with Jakub Wozniak
Next CERN Accelerator Logging Service with Jakub WozniakSpark Summit The document outlines the architecture and functionality of the Next CERN Accelerator Logging Service (nxcals), which improves upon the previous logging system by addressing scalability issues and enabling big data capabilities. It discusses the technologies used, such as Kafka, Hadoop, and Spark, along with the structured way to handle metadata and changing record schemas over time. Additionally, it describes various APIs for data ingestion and extraction to facilitate efficient data access and analysis.
Powering a Startup with Apache Spark with Kevin Kim
Powering a Startup with Apache Spark with Kevin KimSpark Summit The document discusses the evolution of a startup called 'Between', led by Kevin Kim, detailing its growth from 100 beta users in 2011 to 20 million downloads by 2016. It highlights the team's use of Apache Spark for big data processing, the infrastructure they have built, and their current hiring needs for data analysts and machine learning experts. The document also emphasizes the importance of data analysis for product development and marketing strategies, along with the ongoing challenges and future plans for expanding operations.
Improving Traffic Prediction Using Weather Datawith Ramya Raghavendra
Improving Traffic Prediction Using Weather Datawith Ramya RaghavendraSpark Summit The document discusses the development of a cognitive model by IBM Research that improves traffic prediction by integrating weather data, utilizing machine learning techniques like ARIMA, random forest, and LSTM. It highlights the significant impact of weather on traffic flow, emphasizes data collection challenges, and presents results from analyzing extensive traffic and weather records across multiple cities. The model aims to enhance commuter experiences by providing timely and precise traffic predictions, ultimately improving efficiency and reducing congestion.
Hiding Apache Spark Complexity for Fast Prototyping of Big Data Applications—...
Hiding Apache Spark Complexity for Fast Prototyping of Big Data Applications—...Spark Summit The document discusses the Everismoriarty platform, which simplifies the development of data analytics models using Apache Spark, facilitating collaboration between developers and data scientists. It outlines the platform's capabilities, including machine learning and data streaming, highlighting various work items and use cases such as dynamic supply networks and urban mobility. Additionally, it emphasizes the integration of Spark for efficient data processing and prototyping in developement environments.
How Nielsen Utilized Databricks for Large-Scale Research and Development with...
How Nielsen Utilized Databricks for Large-Scale Research and Development with...Spark Summit Nielsen used Databricks to test new digital advertising rating methodologies on a large scale. Databricks allowed Nielsen to run analyses on thousands of advertising campaigns using both small panel data and large production data. This identified edge cases and performance gains faster than traditional methods. Using Databricks reduced the time required to test and deploy improved rating methodologies to benefit Nielsen's clients.
Spline: Apache Spark Lineage not Only for the Banking Industry with Marek Nov...
Spline: Apache Spark Lineage not Only for the Banking Industry with Marek Nov...Spark Summit The document discusses the usage of Apache Spark lineage in Barclays Africa Group Limited to meet regulatory compliance and enhance data clarity. It introduces the Spline tool that enables visualization of Spark execution plans, emphasizing its functionality and future development plans. The presentation includes a demonstration of a use case analyzing beer consumption per capita in correlation with GDP across various countries.
Goal Based Data Production with Sim Simeonov
Goal Based Data Production with Sim SimeonovSpark Summit Simeon Simeonov discusses the concept of goal-based data production within the context of a data-powered culture, emphasizing the need for agile data production methods utilizing machine learning and AI. He highlights the complexity and inflexibility of traditional SQL abstractions and the advantages of a generative approach that enhances metadata queries and allows for real-time context resolution. The document advocates for a self-service model for data scientists and business users, aiming to improve productivity, flexibility, and collaboration through open-source solutions.
Preventing Revenue Leakage and Monitoring Distributed Systems with Machine Le...
Preventing Revenue Leakage and Monitoring Distributed Systems with Machine Le...Spark Summit Movile implemented machine learning to monitor their subscription and billing platform, utilizing data analysis to predict and prevent revenue leakage effectively. The project involved extensive data handling with millions of daily billing requests and various machine learning models, achieving significant accuracy improvements. Key outcomes include saving over $3 million and reducing recovery time from 6 hours to 1 hour, demonstrating a successful application of machine learning in operational efficiency.
Getting Ready to Use Redis with Apache Spark with Dvir Volk
Getting Ready to Use Redis with Apache Spark with Dvir VolkSpark Summit The document outlines a presentation on using Redis for real-time machine learning, focusing on Redis-ML integrated with Apache Spark. It covers the capabilities of Redis as a key-value store, the functionalities of Redis-ML for model serving, and a case study involving a recommendation system. The concluding remarks emphasize the advantages of combining Spark for training with Redis for efficient model serving, highlighting reduced resource costs and simplified machine learning lifecycle.
MatFast: In-Memory Distributed Matrix Computation Processing and Optimization...
MatFast: In-Memory Distributed Matrix Computation Processing and Optimization...Spark Summit The document presents MatFast, an in-memory distributed matrix computation platform optimized for processing queries over big matrix data, focused on applications like recommender systems and social network analysis. It discusses its implementation, optimization strategies, and comparison with existing systems in the Spark ecosystem, including data partitioning techniques for efficient execution. Future plans for MatFast include enhancing user APIs and developing additional optimization features.
Indicium: Interactive Querying at Scale Using Apache Spark, Zeppelin, and Spa...
Indicium: Interactive Querying at Scale Using Apache Spark, Zeppelin, and Spa...Spark Summit This document discusses Indicium, a system for enabling interactive querying at scale on Spark. It describes a unified data platform using Spark for storing and processing data, as well as enabling scheduled jobs, BI reports, and real-time lookups. It then discusses two parts of Indicium: (1) a managed context pool using Apache Zeppelin and Spark Job Server for multi-user SQL queries, and (2) a smart query scheduler for dynamic scheduling, load balancing, and high availability of queries. The smart scheduler aims to improve on the managed context pool by addressing issues like FIFO scheduling and lack of failure handling.
Apache Spark-Bench: Simulate, Test, Compare, Exercise, and Yes, Benchmark wit...
Apache Spark-Bench: Simulate, Test, Compare, Exercise, and Yes, Benchmark wit...Spark Summit The document presents an overview of spark-bench, a comprehensive benchmarking suite designed for the Spark data analytics platform, detailing its history, functionality, and how it facilitates performance testing using different data formats like CSV and Parquet. It highlights use cases for various user types, structural details of the project, and showcases examples of benchmarking tasks, including workload configurations and time management for performance comparisons. The content also includes insights into custom workloads and configurations to enhance benchmarking results.
Recently uploaded (20)
最新版美国威斯康星大学拉克罗斯分校毕业证(UW–L毕业证书)原版定制
最新版美国威斯康星大学拉克罗斯分校毕业证(UW–L毕业证书)原版定制Taqyea 鉴于此,定制威斯康星大学拉克罗斯分校学位证书提升履历【q薇1954292140】原版高仿威斯康星大学拉克罗斯分校毕业证(UW–L毕业证书)可先看成品样本【q薇1954292140】帮您解决在美国威斯康星大学拉克罗斯分校未毕业难题,美国毕业证购买,美国文凭购买,【q微1954292140】美国文凭购买,美国文凭定制,美国文凭补办。专业在线定制美国大学文凭,定做美国本科文凭,【q微1954292140】复制美国University of Wisconsin-La Crosse completion letter。在线快速补办美国本科毕业证、硕士文凭证书,购买美国学位证、威斯康星大学拉克罗斯分校Offer,美国大学文凭在线购买。
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
【复刻一套威斯康星大学拉克罗斯分校毕业证成绩单信封等材料最强攻略,Buy University of Wisconsin-La Crosse Transcripts】
购买日韩成绩单、英国大学成绩单、美国大学成绩单、澳洲大学成绩单、加拿大大学成绩单(q微1954292140)新加坡大学成绩单、新西兰大学成绩单、爱尔兰成绩单、西班牙成绩单、德国成绩单。成绩单的意义主要体现在证明学习能力、评估学术背景、展示综合素质、提高录取率,以及是作为留信认证申请材料的一部分。
威斯康星大学拉克罗斯分校成绩单能够体现您的的学习能力,包括威斯康星大学拉克罗斯分校课程成绩、专业能力、研究能力。(q微1954292140)具体来说,成绩报告单通常包含学生的学习技能与习惯、各科成绩以及老师评语等部分,因此,成绩单不仅是学生学术能力的证明,也是评估学生是否适合某个教育项目的重要依据!
Measurecamp Copenhagen - Consent Context
Measurecamp Copenhagen - Consent ContextHuman37 Measurecamp Copenhagen 2025 presentation by Glenn Vanderlinden, Human37
Boost Business Efficiency with Professional Data Entry Services
Boost Business Efficiency with Professional Data Entry Serviceseloiacs eloiacs Boost Business Efficiency with Professional Data Entry Services
In today’s digital-first world, businesses generate and handle massive amounts of data every day — customer records, sales data, inventory logs, survey results, and much more. But raw data has no value unless it is well-organized, accurate, and easily accessible. That’s where professional data entry services come in.
By outsourcing data entry tasks to experts, businesses can streamline operations, reduce manual errors, and improve overall efficiency — while focusing their internal resources on core activities like growth and customer engagement.
What Are Data Entry Services?
Data entry services refer to the process of converting information from various formats (handwritten, scanned, PDF, image, or audio) into structured, digital formats such as Excel sheets, CRM databases, or cloud storage systems. This work may be done online or offline, manually or using automation tools, depending on the client’s requirements.
Popular Data Entry Services Include:
Manual data entry from paper documents or scanned files
Online data entry directly into websites, forms, or portals
Offline data entry in formats like MS Word, Excel, or custom software
Product data entry for eCommerce platforms like Shopify, Amazon, and Flipkart
Document and image conversion into editable formats
Data cleansing and validation to remove duplicates and fix errors
Remote data entry support for real-time operations
CRM and ERP data management
These services are essential for organizing business data and making it usable for analysis, reporting, and decision-making.
Who Can Benefit from Data Entry Services?
Outsourcing data entry is not limited to any one industry — it's a universal need for businesses of all types and sizes. Here are some examples:
eCommerce Businesses – For managing product catalogs, inventory updates, pricing, and customer orders.
Healthcare Providers – For digitizing patient records, prescriptions, and insurance documents.
Education Institutes – To maintain student records, exam results, and staff data.
Financial Services – For processing invoices, bank statements, transaction records.
Real Estate Companies – To handle property listings, legal paperwork, client records.
Research & Marketing Firms – To compile survey data, leads, and analytics reports.
Even startups and freelancers often require virtual data entry services to stay organized and competitive.
Top Benefits of Outsourcing Data Entry Services
Outsourcing data entry work to a professional company or virtual assistant offers multiple benefits — whether you're running a small business or managing a large enterprise.
1. Reduced Costs
Maintaining an in-house data entry team means salaries, hardware, training, and software expenses. Outsourcing eliminates these costs and provides flexible, pay-as-you-go solutions.
Pause Travail 22 Hostiou Girard 12 juin 2025.pdf
Pause Travail 22 Hostiou Girard 12 juin 2025.pdfInstitut de l'Elevage - Idele Diaporama de la Pause travail 22 sur les rizières au Ghana - 12 juin 2025 - Intervenants Nathalie Hostiou et Pierre Girard
Residential Zone 4 for industrial village
Residential Zone 4 for industrial villageMdYasinArafat13 based on assumption that failure of such a weld is by shear on the
effective area whether the shear transfer is parallel to or
perpendicular to the axis of the line of fillet weld. In fact, the
strength is greater for shear transfer perpendicular to the weld axis;
however, for simplicity the situations are treated the same.
REGRESSION DIAGNOSTIC II: HETEROSCEDASTICITY
REGRESSION DIAGNOSTIC II: HETEROSCEDASTICITYAmeya Patekar REGRESSION DIAGNOSTIC II: HETEROSCEDASTICITY
最新版美国亚利桑那大学毕业证(UA毕业证书)原版定制
最新版美国亚利桑那大学毕业证(UA毕业证书)原版定制Taqyea 鉴于此,定制亚利桑那大学学位证书提升履历【q薇1954292140】原版高仿亚利桑那大学毕业证(UA毕业证书)可先看成品样本【q薇1954292140】帮您解决在美国亚利桑那大学未毕业难题,美国毕业证购买,美国文凭购买,【q微1954292140】美国文凭购买,美国文凭定制,美国文凭补办。专业在线定制美国大学文凭,定做美国本科文凭,【q微1954292140】复制美国The University of Arizona completion letter。在线快速补办美国本科毕业证、硕士文凭证书,购买美国学位证、亚利桑那大学Offer,美国大学文凭在线购买。
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
【复刻一套亚利桑那大学毕业证成绩单信封等材料最强攻略,Buy The University of Arizona Transcripts】
购买日韩成绩单、英国大学成绩单、美国大学成绩单、澳洲大学成绩单、加拿大大学成绩单(q微1954292140)新加坡大学成绩单、新西兰大学成绩单、爱尔兰成绩单、西班牙成绩单、德国成绩单。成绩单的意义主要体现在证明学习能力、评估学术背景、展示综合素质、提高录取率,以及是作为留信认证申请材料的一部分。
亚利桑那大学成绩单能够体现您的的学习能力,包括亚利桑那大学课程成绩、专业能力、研究能力。(q微1954292140)具体来说,成绩报告单通常包含学生的学习技能与习惯、各科成绩以及老师评语等部分,因此,成绩单不仅是学生学术能力的证明,也是评估学生是否适合某个教育项目的重要依据!
KLIP2Data voor de herinrichting van R4 West en Oost
KLIP2Data voor de herinrichting van R4 West en Oostjacoba18 Ontwikkeling van een centrale GIS-databank voor de periodieke import van KLIP-data, BIM- en CAD-modellen van het R4-project en bijhorende field app om de databank zowel online als offline te raadplegen en bij te werken.
Team_Mercury.pdf hai kya hai kya hai kya hai kya hai kya
Team_Mercury.pdf hai kya hai kya hai kya hai kya hai kyagenadit49 Y no me digas que no te gusta la canción de la canción de la canción de la canción de la canción de la canción de la canción de la canción
Verweven van EM Legacy en OTL-data bij AWV
Verweven van EM Legacy en OTL-data bij AWVjacoba18 Het project heeft als doel legacy- en OTL-data samen te brengen in één consistente, OTL-conforme databank. In deze sessie laten we zien hoe we data vergelijken, verschillen helder rapporteren aan de business en feedback op een geautomatiseerde manier verwerken.
Shifting Focus on AI: How it Can Make a Positive Difference
Shifting Focus on AI: How it Can Make a Positive Difference1508 A/S This morgenbooster will share how to find the positive impact of AI and how to integrate it into your own digital process.
Power BI API Connectors - Best Practices for Scalable Data Connections
Power BI API Connectors - Best Practices for Scalable Data Connections Vidicorp Ltd This document explains how API connections work in Power BI, comparing different methods like custom connectors, push datasets, database pipelines, and third-party integration tools. It also gives a clear plan on how to use APIs for flexible, scalable, and smart business reporting.
Lessons Learned while Implementing a Sparse Logistic Regression Algorithm in Apache Spark with Lorand Dali
- 1. Lessons Learned while Implementing a Sparse Logistic Regression Algorithm in Spark Lorand Dali @lorserker #EUds9
- 2. You don’t have to implement your own optimization algorithm* *unless you want to play around and learn a lot of new stuff
- 3. Use a representation that is suited for distributed implementation
- 4. Logistic regression definition weights Feature Vector Prediction Loss Weight update Derivative of loss Gradient
- 5. Logistic regression vectorized weights Predictionsfeatures examples Dot products
- 6. How to compute the gradient vector
- 7. Computing dot products and predictions
- 9. weights Partitions Examples Predictions Array[Double] RDD[(Long, Double)] Seq[(Int, Double)] RDD[(Long, Seq[(Int, Double)])] Column index Feature value row index Map[Int, Double]
- 10. Gradient Array[Double] Prediction minus label Transposed data matrix RDD[(Long, Double)] RDD[(Long, Seq[(Int, Double)])]
- 12. Experimental dataset - avazu click prediction dataset (sites) - 20 million examples - 1 million dimensions - we just want to try it out https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary.html#avazu
- 13. Learning curve
- 14. time per iteration AWS EMR Cluster 5 nodes of m4.2xlarge
- 15. Use a partitioner to avoid shuffles
- 16. We have two joins in our code
- 17. Why is the join expensive + * * * Needs shuffle No shuffle
- 18. Using a custom partitioner
- 20. Try to avoid joins altogether
- 21. Gradient descent without joins dimension
- 23. Use aggregate and treeAggregate
- 24. Gradient (part) Features Examples Tree aggregate Comb OP Seq op
- 25. Seq Op
- 26. Comb Op
- 28. If you can’t decrease the time per iteration, make the iteration smaller
- 29. Mini batch gradient descent
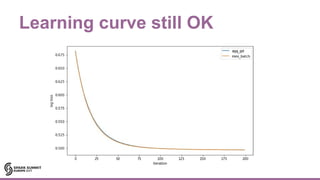
- 30. Learning curve still OK
- 33. If time per iteration is minimal, try to have fewer iterations
- 34. Find a good initialization for the bias - Usually we initialize weights randomly (or to zero) - But a careful initialization of the bias can help (especially in very unbalanced datasets) - We start the gradient descent from a better point and can save several iterations
- 35. Learning curve before bias init
- 36. Learning curve after bias init
- 37. Try a better optimization algorithm to converge faster
- 38. ADAM - converges faster - combines ideas from: gradient descent, momentum and rmsprop - basically just keeps moving averages and makes larger steps when values are consistent or gradients are small - useful for making better progress in plateaus
- 41. Conclusion - we implemented logistic regression from scratch - the first version was very slow - but we managed to improve the iteration time 40x - and also made it converge faster
- 42. Thank you! - Questions, but only simple ones please :) - Looking forward to discussing offline - Or write me an email [email protected] - Play with the code - And come work with me at http://bit.ly/slogreg