Machine Learning with Apache Flink at Stockholm Machine Learning Group
15 likes10,276 views

The document discusses Apache Flink, a large-scale data processing engine with capabilities for batch and real-time streaming analysis, utilizing a cost-based optimizer and custom memory management. It covers the implementation of machine learning pipelines using Flink, highlighting features like stateful iterations and delta iterations, as well as various algorithms and applications in streaming machine learning. Additionally, it mentions ongoing developments in Flink-ML and its integration with other frameworks for advanced machine learning functionalities.


![Technology inside Flink
§ Technology inspired by compilers +
MPP databases + distributed systems
§ For ease of use, reliable performance,
and scalability
case
class
Path
(from:
Long,
to:
Long)
val
tc
=
edges.iterate(10)
{
paths:
DataSet[Path]
=>
val
next
=
paths
.join(edges)
.where("to")
.equalTo("from")
{
(path,
edge)
=>
Path(path.from,
edge.to)
}
.union(paths)
.distinct()
next
}
Cost-based
optimizer
Type extraction
stack
Memory
manager
Out-of-core
algos
real-time
streaming
Task
scheduling
Recovery
metadata
Data
serialization
stack
Streaming
network
stack
...
Pre-flight
(client) Master
Workers](https://image.slidesharecdn.com/flinkstockholm-150324090049-conversion-gate01/85/Machine-Learning-with-Apache-Flink-at-Stockholm-Machine-Learning-Group-3-320.jpg)










![Example: Gaussian non-negative matrix
factorization
§ Given input matrix V, find W and H such
that
§ Iterative approximation
14
Ht+1 = Ht ∗ Wt
T
V /Wt
T
Wt Ht( )
Wt+1 = Wt ∗ VHt+1
T
/Wt Ht+1Ht+1
T
( )
V ≈ WH
var
i
=
0
var
H:
CheckpointedDrm[Int]
=
randomMatrix(k,
V.numCols)
var
W:
CheckpointedDrm[Int]
=
randomMatrix(V.numRows,
k)
while(i
<
maxIterations)
{
H
=
H
*
(W.t
%*%
V
/
W.t
%*%
W
%*%
H)
W
=
W
*
(V
%*%
H.t
/
W
%*%
H
%*%
H.t)
i
+=
1
}](https://image.slidesharecdn.com/flinkstockholm-150324090049-conversion-gate01/85/Machine-Learning-with-Apache-Flink-at-Stockholm-Machine-Learning-Group-14-320.jpg)











![Naïve ALS
case
class
Rating(userID:
Int,
itemID:
Int,
rating:
Double)
case
class
ColumnVector(columnIndex:
Int,
vector:
Array[Double])
val
items:
DataSet[ColumnVector]
=
_
val
ratings:
DataSet[Rating]
=
_
//
Generate
tuples
of
items
with
their
ratings
val
uVA
=
items.join(ratings).where(0).equalTo(1)
{
(item,
ratingEntry)
=>
{
val
Rating(uID,
_,
rating)
=
ratingEntry
(uID,
rating,
item.vector)
}
}
27](https://image.slidesharecdn.com/flinkstockholm-150324090049-conversion-gate01/85/Machine-Learning-with-Apache-Flink-at-Stockholm-Machine-Learning-Group-27-320.jpg)












Machine Learning with Apache Flink at Stockholm Machine Learning Group
- 1. Till Rohrmann Flink committer [email protected] @stsffap Machine Learning with Apache Flink
- 2. What is Flink § Large-scale data processing engine § Easy and powerful APIs for batch and real-time streaming analysis (Java / Scala) § Backed by a very robust execution backend • with true streaming capabilities, • custom memory manager, • native iteration execution, • and a cost-based optimizer. 2
- 3. Technology inside Flink § Technology inspired by compilers + MPP databases + distributed systems § For ease of use, reliable performance, and scalability case class Path (from: Long, to: Long) val tc = edges.iterate(10) { paths: DataSet[Path] => val next = paths .join(edges) .where("to") .equalTo("from") { (path, edge) => Path(path.from, edge.to) } .union(paths) .distinct() next } Cost-based optimizer Type extraction stack Memory manager Out-of-core algos real-time streaming Task scheduling Recovery metadata Data serialization stack Streaming network stack ... Pre-flight (client) Master Workers
- 4. How do you use Flink? 4
- 5. Example: WordCount 5 case class Word (word: String, frequency: Int) val env = ExecutionEnvironment.getExecutionEnvironment() val lines = env.readTextFile(...) lines .flatMap {line => line.split(" ").map(word => Word(word,1))} .groupBy("word").sum("frequency”) .print() env.execute() Flink has mirrored Java and Scala APIs that offer the same functionality, including by-name addressing.
- 6. Flink API in a Nutshell § map, flatMap, filter, groupBy, reduce, reduceGroup, aggregate, join, coGroup, cross, project, distinct, union, iterate, iterateDelta, ... § All Hadoop input formats are supported § API similar for data sets and data streams with slightly different operator semantics § Window functions for data streams § Counters, accumulators, and broadcast variables 6
- 7. Machine learning with Flink 7
- 8. Does ML work like that? 8
- 10. Machine learning pipelines § Pipelining inspired by scikit-learn § Transformer: Modify data § Learner: Train a model § Reusable components § Let’s you quickly build ML pipelines § Model inherits pipeline of learner 10
- 11. Linear regression in polynomial space val polynomialBase = PolynomialBase() val learner = MultipleLinearRegression() val pipeline = polynomialBase.chain(learner) val trainingDS = env.fromCollection(trainingData) val parameters = ParameterMap() .add(PolynomialBase.Degree, 3) .add(MultipleLinearRegression.Stepsize, 0.002) .add(MultipleLinearRegression.Iterations, 100) val model = pipeline.fit(trainingDS, parameters) 11 Input Data Polynomial Base Mapper Mul4ple Linear Regression Linear Model
- 12. Current state of Flink-ML § Existing learners • Multiple linear regression • Alternating least squares • Communication efficient distributed dual coordinate ascent (PR pending) § Feature transformer • Polynomial base feature mapper § Tooling 12
- 13. Distributed linear algebra § Linear algebra universal language for data analysis § High-level abstraction § Fast prototyping § Pre- and post-processing step 13
- 14. Example: Gaussian non-negative matrix factorization § Given input matrix V, find W and H such that § Iterative approximation 14 Ht+1 = Ht ∗ Wt T V /Wt T Wt Ht( ) Wt+1 = Wt ∗ VHt+1 T /Wt Ht+1Ht+1 T ( ) V ≈ WH var i = 0 var H: CheckpointedDrm[Int] = randomMatrix(k, V.numCols) var W: CheckpointedDrm[Int] = randomMatrix(V.numRows, k) while(i < maxIterations) { H = H * (W.t %*% V / W.t %*% W %*% H) W = W * (V %*% H.t / W %*% H %*% H.t) i += 1 }
- 15. Why is Flink a good fit for ML? 15
- 16. Flink’s features § Stateful iterations • Keep state across iterations § Delta iterations • Limit computation to elements which matter § Pipelining • Avoiding materialization of large intermediate state 16
- 17. CoCoA 17 minw∈Rd P(w):= λ 2 w 2 + 1 n ℓi wT xi( ) i=1 n ∑ # $ % & ' (
- 19. Delta iterations 19 partial solution delta setX other datasets Y initial solution iteration result workset A B workset Merge deltas Replace initial workset
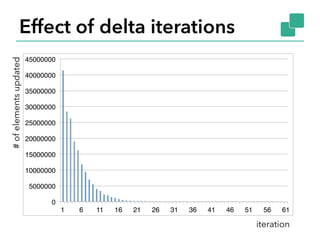
- 20. Effect of delta iterations 0 5000000 10000000 15000000 20000000 25000000 30000000 35000000 40000000 45000000 1 6 11 16 21 26 31 36 41 46 51 56 61 #ofelementsupdated iteration
- 21. Iteration performance 21 0 10 20 30 40 50 60 Hadoop Flink bulk Flink delta Time(minutes) 61 iterations and 30 iterations of PageRank on a Twitter follower graph with Hadoop MapReduce and Flink using bulk and delta iterations 30 iterations 61 iterations MapReduce
- 22. How to factorize really large matrices? 22
- 23. Collaborative Filtering § Recommend items based on users with similar preferences § Latent factor models capture underlying characteristics of items and preferences of user § Predicted preference: 23 ˆru,i = xu T yi
- 24. Matrix factorization 24 minX,Y ru,i − xu T yi( ) 2 + λ nu xu 2 + ni yi 2 i ∑ u ∑ # $ % & ' ( ru,i≠0 ∑ R ≈ XT Y R X Y
- 25. Alternating least squares § Fixing one matrix gives a quadratic form § Solution guarantees to decrease overall cost function § To calculate , all rated item vectors and ratings are needed 25 xu = YSu YT + λnuΙ( ) −1 Yru T Sii u = 1 if ru,i ≠ 0 0 else " # $ %$ xu
- 27. Naïve ALS case class Rating(userID: Int, itemID: Int, rating: Double) case class ColumnVector(columnIndex: Int, vector: Array[Double]) val items: DataSet[ColumnVector] = _ val ratings: DataSet[Rating] = _ // Generate tuples of items with their ratings val uVA = items.join(ratings).where(0).equalTo(1) { (item, ratingEntry) => { val Rating(uID, _, rating) = ratingEntry (uID, rating, item.vector) } } 27
- 28. Naïve ALS contd. uVA.groupBy(0).reduceGroup { vectors => { var uID = -‐1 val matrix = FloatMatrix.zeros(factors, factors) val vector = FloatMatrix.zeros(factors) var n = 0 for((id, rating, v) <-‐ vectors) { uID = id vector += rating * v matrix += outerProduct(v , v) n += 1 } for(idx <-‐ 0 until factors) { matrix(idx, idx) += lambda * n } new ColumnVector(uID, Solve(matrix, vector)) } } 28
- 29. Problems of naïve ALS § Problem: • Item vectors are sent redundantly à High network load § Solution: • Blocking of user and item vectors to share common data • Avoids blown up intermediate state 29
- 31. Performance comparison 31 • 40 node GCE cluster, highmem-‐8 • 10 ALS itera4on with 50 latent factors Runtimeinminutes 0 225 450 675 900 Number of non-zero entries (billion) 0 7.5 15 22.5 30 Blocked ALS Blocked ALS highmem-16 Naive ALS 5.5h 14h 2.5h 1h Table 2 Entries in billion Naive Join Naive Join Broadcast Broadcast 80 0.08 201.326 3.35543333333333 190.723 3.17871666666667
- 33. Why is streaming ML important? § Spam detection in mails § Patterns might change over time § Retraining of model necessary § Best solution: Online models 33
- 34. Applications § Spam detection § Recommendation § News feed personalization § Credit card fraud detection 34
- 35. Apache SAMOA § Scalable Advanced Massive Online Analysis § Distributed streaming machine learning framework § Incubation at the Apache Software Foundation § Runs on multiple streaming processing engines (S4, Storm, Samza) § Support for Flink is pending pull request 35
- 36. Supported algorithms § Classification: Vertical Hoeffding Tree § Clustering: CluStream § Regression: Adaptive Model Rules § Frequent pattern mining: PARMA 36
- 37. Closing 37
- 38. Flink-ML Outlook § Support more algorithms § Support for distributed linear algebra § Integration with streaming machine learning § Interactive programs and Zeppelin 38