Machine learning with Apache Spark MLlib | Big Data Hadoop Spark Tutorial | CloudxLab
1 like590 views

The document provides an overview of machine learning, focusing on the Spark MLlib framework. It covers types of machine learning such as supervised, unsupervised, and reinforcement learning, along with various applications and algorithms including classification, regression, and clustering. Additionally, it discusses the MLlib library's capabilities, usage, and examples like collaborative filtering and k-means clustering.





























![Spark - MLlib
spark.mllib - DataTypes
Local vector
integer-typed and 0-based indices and double-typed values
dv2 = [1.0, 0.0, 3.0]
Labeled point
a local vector, either dense or sparse, associated with a label/response
pos = LabeledPoint(1.0, [1.0, 0.0, 3.0])
Matrices:
Local matrix
Distributed matrix
RowMatrix
IndexedRowMatrix
CoordinateMatrix
BlockMatrix](https://image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/85/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-32-320.jpg)















![Spark - MLlib
import org.apache.spark.mllib.recommendation._
var raw = sc.textFile("/data/ml-1m/ratings.dat")
var mydata = [(2, 0.01), ....]
var mydatardd = mydata.parallelize().map(x => Ratings(0, x._1, x._2))
def parseRating(str: String): Rating = {
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat)
}
val ratings = raw.map(parseRating)
totalratings = ratings.union(mydatardd)
val model = ALS.train(totalratings, 8, 5, 1)
var products = model.recommendProducts(1, 10)
//load data from movies , join it and display the names ordered by ratings
Example - Movie Lens Reco (ver 2.0)](https://image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/85/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-48-320.jpg)




![Spark - MLlib
MLlib - k-means Example
from pyspark.mllib.clustering import KMeans, KMeansModel
from numpy import array
from math import sqrt
# Load and parse the data
data = sc.textFile("/data/spark/mllib/kmeans_data.txt")
parsedData = data.map(lambda line: array([float(x) for x in line.split(' ')]))
# Build the model (cluster the data)
clusters = KMeans.train(parsedData, 2, maxIterations=10, runs=10,
initializationMode="random")](https://image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/85/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-53-320.jpg)
![Spark - MLlib
MLlib - k-means Example
# Evaluate clustering by computing Within Set Sum of Squared Errors
def error(point):
center = clusters.centers[clusters.predict(point)]
return sqrt(sum([x**2 for x in (point - center)]))
WSSSE = parsedData.map(lambda point: error(point)).reduce(lambda x, y: x +
y)
print("Within Set Sum of Squared Error = " + str(WSSSE))
# Save and load model
clusters.save(sc, "myModelPath")
sameModel = KMeansModel.load(sc, "myModelPath")](https://image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/85/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-54-320.jpg)

Machine learning with Apache Spark MLlib | Big Data Hadoop Spark Tutorial | CloudxLab
- 1. Machine Learning with MLlib
- 2. Spark - MLlib MACHINE LEARNING “Programming Computers to optimize performance using Example Data or Past Experience”
- 3. Spark - MLlib MACHINE LEARNING? Field of study that gives "computers the ability to learn without being explicitly programmed." -- Arthur Samuel, 1959
- 4. Spark - MLlib HAVE YOU PLAYED MARIO? How much time did it take you to learn & win the princess?
- 5. Spark - MLlib How about automating it?
- 6. Spark - MLlib • Program Learns to Play Mario Observes the game & presses keys Maximises Score How about automating it?
- 8. Spark - MLlib • Program Learnt to play Mario and other games Without any need of programming So?
- 9. Spark - MLlib 1. Write new rules as per the game 2. Just hook it to new game and let it play for a while Question: To make this program learn any other games such as PacMan we will have to …
- 10. Spark - MLlib 1. Write new rules as per the game 2. Just hook it to new game and let it play for a while Question: To make this program learn any other games such as PacMan we will have to …
- 11. Spark - MLlib MACHINE LEARNING • Branch of Artificial Intelligence • Design and Development of Algorithms • Computers Evolve Behaviour based on Empirical Data
- 12. Spark - MLlib Recommend Friends, Dates, Products to end-user. MACHINE LEARNING - APPLICATIONS
- 13. Spark - MLlib Classify content into predefined groups. MACHINE LEARNING - APPLICATIONS
- 14. Spark - MLlib Identify key topics in large Collections of Text. MACHINE LEARNING - APPLICATIONS
- 15. Spark - MLlib Computer Vision - Identifying Objects MACHINE LEARNING - APPLICATIONS
- 16. Spark - MLlib Natural Language Processing MACHINE LEARNING - APPLICATIONS
- 17. Spark - MLlib MACHINE LEARNING - APPLICATIONS • Find Similar content based on Object Properties. • Detect Anomalies within given data. • Ranking Search Results with User Feedback Learning. • Classifying DNA sequences. • Sentiment Analysis/ Opinion Mining • BioInformatics. • Speech and HandWriting Recognition.
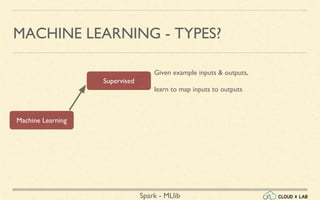
- 18. Spark - MLlib MACHINE LEARNING - TYPES? Machine Learning Supervised Given example inputs & outputs, learn to map inputs to outputs
- 19. Spark - MLlib MACHINE LEARNING - TYPES? Machine Learning Supervised Unsupervised Given example inputs & outputs, learn to map inputs to outputs No labels given, find structure
- 20. Spark - MLlib MACHINE LEARNING - TYPES? Machine Learning Supervised Unsupervised Reinforcement Given example inputs & outputs, learn to map inputs to outputs No labels given, find structure Dynamic environment, perform a certain goal
- 21. Spark - MLlib MACHINE LEARNING - TYPES? Machine Learning Supervised Unsupervised Reinforcement Classification Regression Clustering
- 22. Spark - MLlib MACHINE LEARNING - CLASSIFICATION? Spam? Ye s No Check Email We Use Logistic Regression
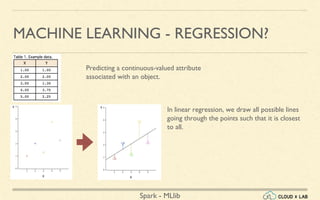
- 23. Spark - MLlib MACHINE LEARNING - REGRESSION? Predicting a continuous-valued attribute associated with an object. In linear regression, we draw all possible lines going through the points such that it is closest to all.
- 24. Spark - MLlib MACHINE LEARNING - CLUSTERING? • To form a cluster • based on some definition of nearness
- 25. Spark - MLlib MACHINE LEARNING - TOOLS DATA SIZE CLASSFICATION TOOLS Lines Sample Data Analysis and Visualization Whiteboard,… KBs - low MBs Prototype Data Analysis and Visualization Matlab, Octave, R, Processing, MBs - low GBs Online Data Analysis NumPy, SciPy, Weka, Visualization Flare, AmCharts, Raphael, Protovis GBs - TBs - PBs Big Data Analysis MLlib, SparkR, GraphX, Mahout, Giraph
- 26. Spark - MLlib Machine Learning Library (MLlib) Goal is to make practical machine learning scalable and easy Consists of common learning algorithms and utilities, including: ● Classification ● Regression ● Clustering ● Collaborative filtering ● Dimensionality reduction ● Lower-level optimization primitives ● Higher-level pipeline APIs
- 27. Spark - MLlib MlLib Structure ML Algorithms Common learning algorithms e.g. classification, regression, clustering, and collaborative filtering Featurization Feature extraction, Transformation, Dimensionality reduction, and Selection Pipelines Tools for constructing, evaluating, and tuning ML Pipelines Persistence Saving and load algorithms, models, and Pipelines Utilities Linear algebra, statistics, data handling, etc.
- 28. Spark - MLlib MLlib - Collaborative Filtering ● Commonly used for recommender systems ● Techniques aim to fill in the missing entries of a user-item association matrix ● Supports model-based collaborative filtering, ● Users and products are described by a small set of latent factors ○ that can be used to predict missing entries. ● MLlib uses the alternating least squares (ALS) algorithm to learn these latent factors.
- 29. Spark - MLlib Example - Movie Lens Recommendation (1)
- 30. Spark - MLlib Example - Movie Lens Recommendation https://github.com/cloudxlab/bigdata/blob/master/spark/examples/mllib/ml-recommender.scala Demo
- 31. Spark - MLlib Exercise - Movies suggestions for you! 1. Find the maximum user id 2. Create the next user id denoting yourselves 3. Put your ratings of various movies 4. Generate your movies recommendations 5. Write down the steps in your Google Doc and share with [email protected].
- 32. Spark - MLlib spark.mllib - DataTypes Local vector integer-typed and 0-based indices and double-typed values dv2 = [1.0, 0.0, 3.0] Labeled point a local vector, either dense or sparse, associated with a label/response pos = LabeledPoint(1.0, [1.0, 0.0, 3.0]) Matrices: Local matrix Distributed matrix RowMatrix IndexedRowMatrix CoordinateMatrix BlockMatrix
- 33. Spark - MLlib Pipe Lines DataFrame:This ML API uses DataFrame from Spark SQL as an ML dataset, which can hold a variety of data types. E.g., a DataFrame could have different columns storing text, feature vectors, true labels, and predictions. Transformer: A Transformer is an algorithm which can transform one DataFrame into another DataFrame. E.g., an ML model is a Transformer which transforms a DataFrame with features into a DataFrame with predictions. Estimator: An Estimator is an algorithm which can be fit on a DataFrame to produce a Transformer. E.g., a learning algorithm is an Estimator which trains on a DataFrame and produces a model. Pipeline: A Pipeline chains multiple Transformers and Estimators together to specify an ML workflow. Parameter: All Transformers and Estimators now share a common API for specifying parameters.
- 34. Spark - MLlib Pipe Lines
- 35. Spark - MLlib spark.mllib - Basic Statistics Summary statistics Correlations Stratified sampling Hypothesis testing Random data generation Kernel density estimation See https://spark.apache.org/docs/latest/mllib-statistics.html
- 36. Spark - MLlib MLlib - Classification and Regression MLlib supports various methods: Binary Classification linear SVMs, logistic regression, decision trees, random forests, gradient-boosted trees, naive Bayes Multiclass Classification logistic regression, decision trees, random forests, naive Bayes Regression linear least squares, Lasso, ridge regression, decision trees, random forests, gradient-boosted trees, isotonic regression More Details>>
- 37. Spark - MLlib MlLib - Other Classes of Algorithms Dimensionality reduction: https://spark.apache.org/docs/latest/mllib-dimensionality-reduction.html Feature extraction and transformation: https://spark.apache.org/docs/latest/mllib-feature-extraction.html Frequent pattern mining: https://spark.apache.org/docs/latest/mllib-frequent-pattern-mining.html Evaluation metrics: https://spark.apache.org/docs/latest/mllib-evaluation-metrics.html PMML model export: https://spark.apache.org/docs/latest/mllib-pmml-model-export.html Optimization (developer): https://spark.apache.org/docs/latest/mllib-optimization.html
- 39. Spark - MLlib MACHINE LEARNING - TYPES Supervised Unsupervised Semi-Supervised Reinforcement
- 40. Spark - MLlib MACHINE LEARNING - TYPES Using Labeled training data, to create a Classifier that can predict output for unseen inputs. Supervised Unsupervised Semi-Supervised Reinforcement
- 41. Spark - MLlib MACHINE LEARNING - TYPES Example1: Spam Filter Supervised Unsupervised Semi-Supervised Reinforcement
- 42. Spark - MLlib MACHINE LEARNING - TYPES Example1: Spam Filter Supervised Unsupervised Semi-Supervised Reinforcement
- 43. Spark - MLlib MACHINE LEARNING - TYPES Supervised Using unlabeled training data to create a function that can predict output. Unsupervised Semi-Supervised Reinforcement
- 44. Spark - MLlib MACHINE LEARNING - TYPES Make use of unlabeled data for training - typically a small amount of labeled data with a large amount of unlabeled data. Supervised Unsupervised Semi-Supervised Reinforcement
- 45. Spark - MLlib MACHINE LEARNING - TYPES A computer program interacts with a dynamic environment for goal gets feedback as it navigates its problem space. Supervised Unsupervised Semi-Supervised Reinforcement
- 46. Spark - MLlib MACHINE LEARNING - TYPES
- 47. Spark - MLlib MACHINE LEARNING - GRADIENT DESCENT • Instead of trying all lines, go into the direction yielding better results. Imagine yourself blindfolded on the mountainous terrain. And you have to find the best lowest point. If your last step went higher, you will go in opposite direction. Other, you will keep going just faster
- 48. Spark - MLlib import org.apache.spark.mllib.recommendation._ var raw = sc.textFile("/data/ml-1m/ratings.dat") var mydata = [(2, 0.01), ....] var mydatardd = mydata.parallelize().map(x => Ratings(0, x._1, x._2)) def parseRating(str: String): Rating = { val fields = str.split("::") assert(fields.size == 4) Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat) } val ratings = raw.map(parseRating) totalratings = ratings.union(mydatardd) val model = ALS.train(totalratings, 8, 5, 1) var products = model.recommendProducts(1, 10) //load data from movies , join it and display the names ordered by ratings Example - Movie Lens Reco (ver 2.0)
- 49. Spark - MLlib spark.mllib - Basic Statistics - Summary from pyspark.mllib.stat import Statistics sc = ... # SparkContext mat = ... # an RDD of Vectors # Compute column summary statistics. summary = Statistics.colStats(mat) print(summary.mean()) print(summary.variance()) print(summary.numNonzeros())
- 50. Spark - MLlib MLlib - Clustering ● Clustering is an unsupervised learning problem ● Group subsets of entities with one another based on some notion of similarity. ● Often used for exploratory analysis
- 51. Spark - MLlib MLlib supports the following models: K-means Clusters the data points into a predefined number of clusters Gaussian mixture Subgroups within overall population Power iteration clustering (PIC) Clustering vertices of a graph given pairwise similarities as edge properties Latent Dirichlet allocation (LDA) Infers topics from a collection of text documents Streaming k-means
- 52. Spark - MLlib MLlib - k-means Example import org.apache.spark.mllib.clustering.{KMeans, KMeansModel} import org.apache.spark.mllib.linalg.Vectors // Load and parse the data val data = sc.textFile("/data/spark/kmeans_data.txt") val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache() // Cluster the data into two classes using KMeans val numClusters = 2 val numIterations = 20 val clusters = KMeans.train(parsedData, numClusters, numIterations) // Evaluate clustering by computing Within Set Sum of Squared Errors val WSSSE = clusters.computeCost(parsedData) println("Within Set Sum of Squared Errors = " + WSSSE) // Save and load model clusters.save(sc, "KMeansModel1") val sameModel = KMeansModel.load(sc, "KMeansModel1")
- 53. Spark - MLlib MLlib - k-means Example from pyspark.mllib.clustering import KMeans, KMeansModel from numpy import array from math import sqrt # Load and parse the data data = sc.textFile("/data/spark/mllib/kmeans_data.txt") parsedData = data.map(lambda line: array([float(x) for x in line.split(' ')])) # Build the model (cluster the data) clusters = KMeans.train(parsedData, 2, maxIterations=10, runs=10, initializationMode="random")
- 54. Spark - MLlib MLlib - k-means Example # Evaluate clustering by computing Within Set Sum of Squared Errors def error(point): center = clusters.centers[clusters.predict(point)] return sqrt(sum([x**2 for x in (point - center)])) WSSSE = parsedData.map(lambda point: error(point)).reduce(lambda x, y: x + y) print("Within Set Sum of Squared Error = " + str(WSSSE)) # Save and load model clusters.save(sc, "myModelPath") sameModel = KMeansModel.load(sc, "myModelPath")
- 55. Spark - MLlib Example - Movie Lens Recommendation https://github.com/cloudxlab/bigdata/blob/master/spark/examples/mllib/ml-recommender.scala Movie Lens - Movies Training Set (80%) Test Set (20%) Model MLLib Recommendations Remove ratings & Apply Model