




































![17
parallel loops
Parallel loops have many variations. There are 12 overloaded
methods for Parallel.For and 20 overloaded methods for Parallel.
ForEach. PLINQ has close to 200 extension methods. Although there
are many overloaded versions of For and ForEach, you can think of
the overloads as providing optional configuration options. Two ex-
amples are a maximum degree of parallelism and hooks for external
cancellation. These options allow the loop body to monitor the prog-
ress of other steps (for example, to see if exceptions are pending) and
to manage task-local state. They are sometimes needed in advanced
scenarios. To learn about the most important cases, see the section,
“Variations,” later in this chapter.
If you convert a sequential loop to a parallel loop and then find
that your program does not behave as expected, the mostly likely
problem is that the loop’s steps are not independent. Here are some
common examples of dependent loop bodies:
• Writing to shared variables. If the body of a loop writes to
a shared variable, there is a loop body dependency. This is a
common case that occurs when you are aggregating values.
Here is an example, where total is shared across iterations.
for(int i = 1; i < n; i++)
total += data[i];
If you encounter this situation, see Chapter 4, “Parallel Aggregation.”
Shared variables come in many flavors. Any variable that is
declared outside of the scope of the loop body is a shared
variable. Shared references to types such as classes or arrays
will implicitly allow all fields or array elements to be shared.
Parameters that are declared using the keyword ref result in
shared variables. Even reading and writing files can have the
same effect as shared variables.
• Using properties of an object model. If the object being
processed by a loop body exposes properties, you need to
know whether those properties refer to shared state or state
that’s local to the object itself. For example, a property named
Parent is likely to refer to global state. Here’s an example.
for(int i = 0; i < n; i++)
SomeObject[i].Parent.Update();
In this example, it’s likely that the loop iterations are not independent.
For all values of i, SomeObject[i].Parent is a reference to a single
shared object.
Robust exception handling
is an important aspect of
parallel loop processing.
Check carefully for dependen-
cies between loop iterations!
Not noticing dependencies
between steps is by far the
most common mistake you’ll
make with parallel loops.](https://image.slidesharecdn.com/1244148-250518070723-3ddca070/85/Parallel-Programming-With-Microsoft-Net-Design-Patterns-For-Decomposition-And-Coordination-On-Multicore-Architectures-Patterns-Practices-1st-Edition-Colin-Campbell-39-320.jpg)
![18 chapter two
• Referencing data types that are not thread safe. If the body of
the parallel loop uses a data type that is not thread safe, the
loop body is not independent (there is an implicit dependency
on the thread context). An example of this case, along with a
solution, is shown in “Using Task-Local State in a Loop Body” in
the section, “Variations,” later in this chapter.
• Loop-carried dependence. If the body of a parallel for loop
performs arithmetic on the loop index, there is likely to be a
dependency that is known as loop-carried dependence. This is
shown in the following code example. The loop body references
data[i] and data[i – 1]. If Parallel.For is used here, there’s no
guarantee that the loop body that updates data[i – 1] has
executed before the loop for data[i].
for(int i = 1; i < N; i++)
data[i] = data[i] + data[i - 1];
Sometimes, it’s possible to use a parallel algorithm in cases of
loop-carried dependence, but this is outside the scope of this
book. Your best bet is to look elsewhere in your program for
opportunities for parallelism or to analyze your algorithm and
see if it matches some of the advanced parallel patterns that
occur in scientific computing. Parallel scan and parallel dynamic
programming are examples of these patterns.
When you look for opportunities for parallelism, profiling your ap-
plication is a way to deepen your understanding of where your
application spends its time; however, profiling is not a substitute for
understanding your application’s structure and algorithms. For exam-
ple, profiling doesn’t tell you whether loop bodies are independent.
An Example
Here’s an example of when to use a parallel loop. Fabrikam Shipping
extends credit to its commercial accounts. It uses customer credit
trends to identify accounts that might pose a credit risk. Each cus-
tomer account includes a history of past balance-due amounts. Fabri-
kam has noticed that customers who don’t pay their bills often have
histories of steadily increasing balances over a period of several
months before they default.
To identify at-risk accounts, Fabrikam uses statistical trend analy-
sis to calculate a projected credit balance for each account. If the
analysis predicts that a customer account will exceed its credit limit
within three months, the account is flagged for manual review by one
of Fabrikam’s credit analysts.
Arithmetic on loop index
variables, especially addition or
subtraction, usually indicates
loop-carried dependence.
Don’t expect miracles from
profiling—it can’t analyze your
algorithms for you. Only you
can do that.
You must be extremely
cautious when getting data
from properties and methods.
Large object models are known
for sharing mutable state in
unbelievably devious ways.](https://image.slidesharecdn.com/1244148-250518070723-3ddca070/85/Parallel-Programming-With-Microsoft-Net-Design-Patterns-For-Decomposition-And-Coordination-On-Multicore-Architectures-Patterns-Practices-1st-Edition-Colin-Campbell-40-320.jpg)




![23
parallel loops
ties. If the IsCompleted property is false and the LowestBreak
Iteration property returns an object whose HasValue property is
true, you know that the loop terminated by a call to the Break
method. You can query for the specific index with the loop result’s
LowestBreakIteration property. Here’s an example.
int n = ...
var result = new double[n];
var loopResult = Parallel.For(0, n, (i, loopState) =>
{
if (/* break condition is true */)
{
loopState.Break();
return;
}
result[i] = DoWork(i);
});
if (!loopResult.IsCompleted &&
loopResult.LowestBreakIteration.HasValue)
{
Console.WriteLine(“Loop encountered a break at {0}”,
loopResult.LowestBreakIteration.Value);
}
The Break method ensures that data up to a particular iteration index
value will be processed. Depending on how the iterations are sched-
uled, it may be possible that some steps with a higher index value than
the one that called the Break method may have been started before
the call to Break occurs.
The Parallel.ForEach method also supports the loop state Break
method. The parallel loop assigns items a sequence number, starting
from zero, as it pulls them from the enumerable input. This sequence
number is used as the iteration index for the LowestBreakIteration
property.
Parallel Stop
There are also situations, such as unordered searches, where you want
the loop to stop as quickly as possible after the stopping condition is
met. The difference between “break” and “stop” is that, with stop, no
attempt is made to execute loop iterations less than the stopping in-
dex if they have not already run. To stop a loop in this way, call the
ParallelLoopState class’s Stop method instead of the Break method.
Here is an example of parallel stop.
Be aware that some steps with
index values higher than the
step that called the Break
method might be run. There’s
no way of predicting when or
if this might happen.
The Parallel.ForEach
method also supports the
loop state Break method.
Use Stop to exit a loop early
when you don’t need all
lower-indexed iterations
to run before terminating
the loop.](https://image.slidesharecdn.com/1244148-250518070723-3ddca070/85/Parallel-Programming-With-Microsoft-Net-Design-Patterns-For-Decomposition-And-Coordination-On-Multicore-Architectures-Patterns-Practices-1st-Edition-Colin-Campbell-45-320.jpg)
![24 chapter two
var n = ...
var loopResult = Parallel.For(0, n, (i, loopState) =>
{
if (/* stopping condition is true */)
{
loopState.Stop();
return;
}
result[i] = DoWork(i);
});
if (!loopResult.IsCompleted &&
!loopResult.LowestBreakIteration.HasValue)
{
Console.WriteLine(“Loop was stopped”);
}
When the Stop method is called, the index value of the iteration
that caused the stop isn’t available.
You cannot call both Break and Stop during the same parallel
loop. You have to choose which of the two loop exit behaviors you
want to use. If you call both Break and Stop in the same parallel loop,
an exception will be thrown.
Parallel programs use Stop more often than Break. Processing all
iterations with indices less than the stopping iteration is usually not
necessary when the loop bodies are independent of each other. It’s
also true that Stop shuts down a loop more quickly than Break.
There’s no Stop method for a PLINQ query, but you can use the
WithCancellation extension method and then use cancellation as a
way to stop PLINQ execution. For more information, see the next
section, “External Loop Cancellation.”
external loop cancellation
In some scenarios, you may want to cancel a parallel loop because of
an external request. For example, you may need to respond to a re-
quest from a user interface to stop what you’re doing.
In .NET, you use the CancellationTokenSource class to signal
cancellation and the CancellationToken structure to detect and re-
spond to a cancellation request. The structure allows you to find out
if there is a pending cancellation request. The class lets you signal that
cancellation should occur.
The Parallel.For and Parallel.ForEach methods include over-
loaded versions that accept parallel loop options as one of the argu-
ments. You can specify a cancellation token as one of these options.
You’ll probably use Stop
more often than Break.](https://image.slidesharecdn.com/1244148-250518070723-3ddca070/85/Parallel-Programming-With-Microsoft-Net-Design-Patterns-For-Decomposition-And-Coordination-On-Multicore-Architectures-Patterns-Practices-1st-Edition-Colin-Campbell-46-320.jpg)


![27
parallel loops
By grouping iterations into ranges, you can avoid some of the over-
head of a normal parallel loop. Here’s an example.
int n = ...
double[] result = new double[n];
Parallel.ForEach(Partitioner.Create(0, n),
(range) =>
{
for (int i = range.Item1; i < range.Item2; i++)
{
// very small, equally sized blocks of work
result[i] = (double)(i * i);
}
});
Here’s the signature of the Parallel.For method that was used in the
example.
Parallel.ForEach<TSource>(
Partitioner<TSource> source,
Action<TSource> body);
In this example, you can think of the result of the Partitioner.Create
method as an object that acts like an instance of IEnumerable
<Tuple<int, int>> (the actual type is Partitioner<Tuple<int, int>>).
In other words, Create gives you access to a collection of tuples
(unnamed records) with two integer field values. Each tuple represents
a range of index values that should be processed in a single iteration
of the parallel loop. Each iteration of the parallel loop contains a
nested sequential for loop that processes each index in the range.
The partition-based syntax for parallel loops is more complicated
than the syntax for other parallel loops in .NET, and when the amount
of work in each iteration is large (or of uneven size across iterations),
it may not result in better performance. Generally, you would only use
the more complicated syntax after profiling or in the case where loop
bodies are extremely small and the number of iterations large.
The number of ranges that will be created by a Partitioner object
depends on the number of cores in your computer. The default num-
ber of ranges is approximately three times the number of those cores.
If you know how big you want your ranges to be, you can use an
overloaded version of the Partitioner.Create method that allows you
to specify the size of each range. Here’s an example.
double[] result = new double[1000000];
Parallel.ForEach(Partitioner.Create(0, 1000000, 50000),
(range) =>](https://image.slidesharecdn.com/1244148-250518070723-3ddca070/85/Parallel-Programming-With-Microsoft-Net-Design-Patterns-For-Decomposition-And-Coordination-On-Multicore-Architectures-Patterns-Practices-1st-Edition-Colin-Campbell-49-320.jpg)
![28 chapter two
{
for (int i = range.Item1; i < range.Item2; i++)
{
// small, equally sized blocks of work
result[i] = (double)(i * i);
}
});
In this example, each range will span 50,000 index values. In other
words, for a million iterations, the system will use twenty parallel
iterations (1,000,000 / 50,000). These iterations will be spread out
among all the available cores.
Custom partitioning is an extension point in the API for parallel
loops. You can implement your own partitioning strategies. For more
information about this topic, see the section, “Further Reading,” at the
end of this chapter.
controlling the degree of parallelism
Although you usually let the system manage how iterations of a paral-
lel loop are mapped to your computer’s cores, in some cases, you may
want additional control.
You’ll see this variation of the Parallel Loop pattern in a variety of
circumstances. Reducing the degree of parallelism is often used in
performance testing to simulate less capable hardware. Increasing the
degree of parallelism to a number larger than the number of cores can
be appropriate when iterations of your loop spend a lot of time wait-
ing for I/O operations to complete.
The term degree of parallelism can be used in two senses. In the
simplest case, it refers to the number of cores that are used to process
iterations simultaneously. However, .NET also uses this term to refer
to the number of tasks that can be used simultaneously by the parallel
loop. For example, the MaxDegreeOfParallelism property of the
ParallelOptions object refers to the maximum number of worker
tasks that will be scheduled at any one time by a parallel loop.
For efficient use of hardware resources, the number of tasks is
often greater than the number of available cores. For example, parallel
loops may use additional tasks in cases where there are blocking I/O
operations that do not require processor resources to run. The degree
of parallelism is automatically managed by the underlying components
of the system; the implementation of the Parallel class, the default
task scheduler, and the .NET thread pool all play a role in optimizing
throughput under a wide range of conditions.
You can limit the maximum number of tasks used concurrently
by specifying the MaxDegreeOfParallelism property of a Parallel
Options object. Here is an example.
You can control the
maximum number of
threads used concurrently
by a parallel loop.](https://image.slidesharecdn.com/1244148-250518070723-3ddca070/85/Parallel-Programming-With-Microsoft-Net-Design-Patterns-For-Decomposition-And-Coordination-On-Multicore-Architectures-Patterns-Practices-1st-Edition-Colin-Campbell-50-320.jpg)






![This ebook is for the use of anyone anywhere in the United States
and most other parts of the world at no cost and with almost no
restrictions whatsoever. You may copy it, give it away or re-use it
under the terms of the Project Gutenberg License included with this
ebook or online at www.gutenberg.org. If you are not located in the
United States, you will have to check the laws of the country where
you are located before using this eBook.
Title: The Art of Logical Thinking; Or, The Laws of Reasoning
Author: William Walker Atkinson
Release date: January 13, 2013 [eBook #41838]
Most recently updated: October 23, 2024
Language: English
Credits: Produced by sp1nd, CM, and the Online Distributed
Proofreading Team at http://www.pgdp.net (This file was
produced from images generously made available by The
Internet Archive)
*** START OF THE PROJECT GUTENBERG EBOOK THE ART OF
LOGICAL THINKING; OR, THE LAWS OF REASONING ***](https://image.slidesharecdn.com/1244148-250518070723-3ddca070/85/Parallel-Programming-With-Microsoft-Net-Design-Patterns-For-Decomposition-And-Coordination-On-Multicore-Architectures-Patterns-Practices-1st-Edition-Colin-Campbell-57-320.jpg)
















Parallel Programming With Microsoft Net Design Patterns For Decomposition And Coordination On Multicore Architectures Patterns Practices 1st Edition Colin Campbell
- 1. Parallel Programming With Microsoft Net Design Patterns For Decomposition And Coordination On Multicore Architectures Patterns Practices 1st Edition Colin Campbell download https://ebookbell.com/product/parallel-programming-with- microsoft-net-design-patterns-for-decomposition-and-coordination- on-multicore-architectures-patterns-practices-1st-edition-colin- campbell-2488296 Explore and download more ebooks at ebookbell.com
- 2. 001 • • • • • • • • • • • • • • • • • • • • • • • • • • PA R A L L E L P R O G R A M M I N G M I C R O S O F T ® .N ET Design Patterns for Decomposition and Coordination on Multicore Architectures Colin Campbell Ralph Johnson Ade Miller Stephen Toub Foreword by Tony Hey WITH
- 3. a guide to parallel programming
- 5. Parallel Programming with Microsoft® .NET Design Patterns for Decomposition and Coordination on Multicore Architectures Colin Campbell Ralph Johnson Ade Miller Stephen Toub
- 6. ISBN 9780735640603 This document is provided “as-is.” Information and views expressed in this document, including URL and other Internet website references, may change without notice. You bear the risk of using it. Unless otherwise noted, the companies, organizations, products, domain names, email addresses, logos, people, places, and events depicted in examples herein are fictitious. No association with any real company, organization, product, domain name, email address, logo, person, place, or event is intended or should be inferred. Complying with all applicable copyright laws is the responsibility of the user. Without limiting the rights under copyright, no part of this document may be reproduced, stored in or introduced into a retrieval system, or transmitted in any form or by any means (electronic, mechanical, photocopying, recording, or otherwise), or for any purpose, without the express written permission of Microsoft Corporation. Microsoft may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document. Except as expressly provided in any written license agreement from Microsoft, the furnishing of this document does not give you any license to these patents, trademarks, copyrights, or other intellectual property. © 2010 Microsoft Corporation. All rights reserved. Microsoft, MSDN, Visual Basic, Visual C#, Visual Studio, Windows, Windows Live, Windows Server, and Windows Vista are trademarks of the Microsoft group of companies. All other trademarks are property of their respective owners.
- 7. Contents Foreword xi Tony Hey Preface xiii Who This Book Is For xiii Why This Book Is Pertinent Now xiv What You Need to Use the Code xiv How to Use This Book xv Introduction xvi Parallelism with Control Dependencies Only xvi Parallelism with Control and Data Dependencies xvi Dynamic Task Parallelism and Pipelines xvi Supporting Material xvii What Is Not Covered xviii Goals xviii Acknowledgments xix 1 Introduction 1 The Importance of Potential Parallelism 2 Decomposition, Coordination, and Scalable Sharing 3 Understanding Tasks 3 Coordinating Tasks 4 Scalable Sharing of Data 5 Design Approaches 6 Selecting the Right Pattern 7 A Word About Terminology 7 The Limits of Parallelism 8 A Few Tips 10 Exercises 11 For More Information 11
- 8. vi 2 Parallel Loops 13 The Basics 14 Parallel for Loops 14 Parallel for Each 15 Parallel Linq (PLINQ) 16 What to Expect 16 An Example 18 Sequential Credit Review Example 19 Credit Review Example Using Parallel.For Each 19 Credit Review Example with PLINQ 20 Performance Comparison 21 Variations 21 Breaking Out of Loops Early 21 Parallel Break 21 Parallel Stop 23 External Loop Cancellation 24 Exception Handling 26 Special Handling of Small Loop Bodies 26 Controlling the Degree of Parallelism 28 Using Task-Local State in a Loop Body 29 Using a Custom Task Scheduler For a Parallel Loop 31 Anti-Patterns 32 Step Size Other than One 32 Hidden Loop Body Dependencies 32 Small Loop Bodies with Few Iterations 32 Processor Oversubscription And Undersubscription 33 Mixing the Parallel Class and PLINQ 33 Duplicates in the Input Enumeration 34 Design Notes 34 Adaptive Partitioning 34 Adaptive Concurrency 34 Support for Nested Loops and Server Applications 35 Related Patterns 35 Exercises 35 Further Reading 37 3 Parallel Tasks 39 The Basics 40 An Example 41
- 9. vii Variations 43 Canceling a Task 43 Handling Exceptions 44 Ways to Observe an Unhandled Task Exception 45 Aggregate Exceptions 45 The Handle Method 46 The Flatten Method 47 Waiting for the First Task to Complete 48 Speculative Execution 49 Creating Tasks with Custom Scheduling 50 Anti-Patterns 51 Variables Captured by Closures 51 Disposing a Resource Needed by a Task 52 Avoid Thread Abort 53 Design Notes 53 Tasks and Threads 53 Task Life Cycle 53 Writing a Custom Task Scheduler 54 Unobserved Task Exceptions 55 Relationship Between Data Parallelism and Task Parallelism 56 The Default Task Scheduler 56 The Thread Pool 57 Decentralized Scheduling Techniques 58 Work Stealing 59 Top-Level Tasks in the Global Queue 60 Subtasks in a Local Queue 60 Inlined Execution of Subtasks 60 Thread Injection 61 Bypassing the Thread Pool 63 Exercises 64 Further Reading 65 4 Parallel Aggregation 67 The Basics 68 An Example 69 Variations 73 Using Parallel Loops for Aggregation 73 Using A Range Partitioner for Aggregation 76 Using Plinq Aggregation with Range Selection 77 Design Notes 80 Related Patterns 82 Exercises 82 Further Reading 83
- 10. viii 5 Futures 85 The Basics 86 Futures 86 Continuation Tasks 88 Example: The Adatum Financial Dashboard 89 The Business Objects 91 The Analysis Engine 92 Loading External Data 95 Merging 95 Normalizing 96 Analysis and Model Creation 96 Processing Historical Data 96 Comparing Models 96 View And View Model 97 Variations 97 Canceling Futures and Continuation Tasks 97 Continue When “At Least One” Antecedent Completes 97 Using .Net Asynchronous Calls with Futures 97 Removing Bottlenecks 98 Modifying the Graph at Run Time 98 Design Notes 99 Decomposition into Futures And Continuation Tasks 99 Functional Style 99 Related Patterns 100 Pipeline Pattern 100 Master/Worker Pattern 100 Dynamic Task Parallelism Pattern 100 Discrete Event Pattern 100 Exercises 101 Further Reading 101 6 Dynamic Task Parallelism 103 The Basics 103 An Example 105 Variations 107 Parallel While-Not-Empty 107 Task Chaining with Parent/Child Tasks 108 Design Notes 109 Exercises 110 Further Reading 110
- 11. ix 7 Pipelines 113 The Basics 113 An Example 117 Sequential Image Processing 117 The Image Pipeline 119 Performance Characteristics 120 Variations 122 Canceling a Pipeline 122 Handling Pipeline Exceptions 124 Load Balancing Using Multiple Producers 126 Pipelines and Streams 129 Asynchronous Pipelines 129 Anti-Patterns 129 Thread Starvation 129 Infinite Blocking Collection Waits 130 Forgetting GetConsumingEnumerable() 130 Using Other Producer/Consumer Collections 130 Design Notes 131 Related Patterns 131 Exercises 132 Further Reading 132 Appendices a Adapting Object-Oriented Patterns 133 Structural Patterns 133 Façade 134 Example 134 Guidelines 134 Decorators 134 Example 135 Guidelines 136 Adapters 136 Example 137 Guidelines 138 Repositories And Parallel Data Access 138 Example 139 Guidelines 139 Singletons and Service Locators 139 Implementing a Singleton with the Lazy<T> Class 140 Notes 141 Guidelines 141
- 12. x Model-View-ViewModel 142 Example 143 The Dashboard’s User Interface 144 Guidelines 147 Immutable Types 148 Example 149 Immutable Types as Value Types 150 Compound Values 152 Guidelines 152 Shared Data Classes 153 Guidelines 153 Iterators 154 Example 154 Lists and Enumerables 155 Further Reading 156 Structural Patterns 156 Singleton 156 Model-View-ViewModel 157 Immutable Types 158 b Debugging and Profiling Parallel Applications 159 The Parallel Tasks and Parallel Stacks Windows 159 The Concurrency Visualizer 162 Visual Patterns 167 Oversubscription 167 Lock Contention and Serialization 168 Load Imbalance 169 Further Reading 172 c Technology Overview 173 Further Reading 175 Glossary 177 References 187 Other Online Sources 189 Index 191
- 13. xi Foreword At its inception some 40 or so years ago, parallel computing was the province of experts who applied it to exotic fields, such as high en- ergy physics, and to engineering applications, such as computational fluid dynamics. We’ve come a long way since those early days. This change is being driven by hardware trends. The days of per- petually increasing processor clock speeds are now at an end. Instead, the increased chip densities that Moore’s Law predicts are being used to create multicore processors, or single chips with multiple processor cores. Quad-core processors are now common, and this trend will continue, with 10’s of cores available on the hardware in the not-too- distant future. In the last five years, Microsoft has taken advantage of this tech- nological shift to create a variety of parallel implementations. These include the Windows High Performance Cluster (HPC) technology for message-passing interface (MPI) programs, Dryad, which offers a Map-Reduce style of parallel data processing, the Windows Azure platform, which can supply compute cores on demand, the Parallel Patterns Library (PPL) for native code, and the parallel extensions of the .NET Framework 4. Multicore computation affects the whole spectrum of applica- tions, from complex scientific and design problems to consumer applications and new human/computer interfaces. We used to joke that “parallel computing is the future, and always will be,” but the pessimists have been proven wrong. Parallel computing has at last moved from being a niche technology to being center stage for both application developers and the IT industry. But, there is a catch. To obtain any speed-up of an application, programmers now have to divide the computational work to make efficient use of the power of multicore processors, a skill that still belongs to experts. Parallel programming presents a massive challenge for the majority of developers, many of whom are encountering it for the first time. There is an urgent need to educate them in practical
- 14. xii ways so that they can incorporate parallelism into their applications. Two possible approaches are popular with some of my computer science colleagues: either design a new parallel programming language or develop a “heroic” parallelizing compiler. While both are certainly interesting academically, neither has had much success in popularizing and simplifying the task of parallel programming for non-experts. In contrast, a more pragmatic approach is to provide programmers with a library that hides much of parallel programming’s complexity and to teach programmers how to use it. To that end, the Microsoft .NET Framework parallel extensions present a higher-level programming model than earlier APIs. Program- mers can, for example, think in terms of tasks rather than threads and can avoid the complexities of managing threads. Parallel Programming with Microsoft .NET teaches programmers how to use these libraries by putting them in the context of design patterns. As a result, applica- tion developers can quickly learn to write parallel programs and gain immediate performance benefits. I believe that this book, with its emphasis on parallel design pat- terns and an up-to-date programming model, represents an important first step in moving parallel programming into the mainstream. Tony Hey Corporate Vice President, Microsoft Research foreword
- 15. xiii Preface This book describes patterns for parallel programming, with code examples, that use the new parallel programming support in the Microsoft® .NET Framework 4. This support is commonly referred to as the Parallel Extensions. You can use the patterns described in this book to improve your application’s performance on multicore com- puters. Adopting the patterns in your code makes your application run faster today and also helps prepare for future hardware environments, which are expected to have an increasingly parallel computing architecture. Who This Book Is For The book is intended for programmers who write managed code for the .NET Framework on the Microsoft Windows® operating system. This includes programmers who write in Microsoft Visual C#® development tool, Microsoft Visual Basic® development system, and Microsoft Visual F#. No prior knowledge of parallel programming techniques is assumed. However, readers need to be familiar with features of C# such as delegates, lambda expressions, generic types, and Language Integrated Query (LINQ) expressions. Readers should also have at least a basic familiarity with the concepts of processes and threads of execution. Note: The examples in this book are written in C# and use the features of the .NET Framework 4, including the Task Parallel Library (TPL) and Parallel LINQ (PLINQ). However, you can use the concepts presented here with other frameworks and libraries and with other languages. Complete code solutions are posted on CodePlex. See http://parallelpatterns.codeplex.com/. There is a C# version for every example. In addition to the C# example code, there are also versions of the examples in Visual Basic and F#.
- 16. xiv Why This Book Is Pertinent Now The advanced parallel programming features that are delivered with Visual Studio® 2010 development system make it easier than ever to get started with parallel programming. The Task Parallel Library (TPL) is for .NET programmers who want to write parallel programs. It simplifies the process of adding parallelism and concurrency to applications. The TPL dynamically scales the degree of parallelism to most efficiently use all the proces- sors that are available. In addition, the TPL assists in the partitioning of work and the scheduling of tasks in the .NET thread pool. The library provides cancellation support, state management, and other services. Parallel LINQ (PLINQ) is a parallel implementation of LINQ to Objects. PLINQ implements the full set of LINQ standard query operators as extension methods for the System.Linq namespace and has additional operators for parallel operations. PLINQ is a declara- tive, high-level interface with query capabilities for operations such as filtering, projection, and aggregation. Visual Studio 2010 includes tools for debugging parallel applica- tions. The Parallel Stacks window shows call stack information for all the threads in your application. It lets you navigate between threads and stack frames on those threads. The Parallel Tasks window resembles the Threads window, except that it shows information about each task instead of each thread. The Concurrency Visualizer views in the Visual Studio profiler enable you to see how your applica- tion interacts with the hardware, the operating system, and other processes on the computer. You can use the Concurrency Visualizer to locate performance bottlenecks, processor underutilization, thread contention, cross-core thread migration, synchronization delays, areas of overlapped I/O, and other information. For a complete overview of the parallel technologies available from Microsoft, see Appendix C, “Technology Overview.” What You Need to Use the Code The code that is used as examples in this book is at http://parallel patterns.codeplex.com/. These are the system requirements: • Microsoft Windows Vista® SP1, Windows 7, Microsoft Windows Server® 2008, or Windows XP SP3 (32-bit or 64-bit) operating system • Microsoft Visual Studio 2010 (Ultimate or Premium edition is required for the Concurrency Visualizer, which allows you to analyze the performance of your application); this includes the .NET Framework 4, which is required to run the samples preface
- 17. xv How to Use This Book This book presents parallel programming techniques in terms of particular patterns. Figure 1 shows the different patterns and their relationships to each other. The numbers refer to the chapters in this book where the patterns are described. figure 1 Parallel programming patterns After the introduction, the book has one branch that discusses data parallelism and another that discusses task parallelism. Both parallel loops and parallel tasks use only the program’s control flow as the means to coordinate and order tasks. The other patterns use both control flow and data flow for coordination. Control flow refers to the steps of an algorithm. Data flow refers to the availability of inputs and outputs. Data Parallelism Task Parallelism Coordinated by control flow only Coordinated by control flow and data flow 5 Futures 7 Pipelines 6 Dynamic Task Parallelism 4 Parallel Aggregation 2 Parallel Loops 3 Parallel Tasks 1 Introduction
- 18. xvi introduction Chapter 1 introduces the common problems faced by developers who want to use parallelism to make their applications run faster. It explains basic concepts and prepares you for the remaining chapters. There is a table in the “Design Approaches” section of Chapter 1 that can help you select the right patterns for your application. parallelism with control dependencies only Chapters 2 and 3 deal with cases where asynchronous operations are ordered only by control flow constraints: • Chapter 2, “Parallel Loops.” Use parallel loops when you want to perform the same calculation on each member of a collection or for a range of indices, and where there are no dependencies between the members of the collection. For loops with depen- dencies, see Chapter 4, “Parallel Aggregation.” • Chapter 3, “Parallel Tasks.” Use parallel tasks when you have several distinct asynchronous operations to perform. This chap- ter explains why tasks and threads serve two distinct purposes. parallelism with control and data dependencies Chapters 4 and 5 show patterns for concurrent operations that are constrained by both control flow and data flow: • Chapter 4, “Parallel Aggregation.” Patterns for parallel aggre- gation are appropriate when the body of a parallel loop includes data dependencies, such as when calculating a sum or searching a collection for a maximum value. • Chapter 5, “Futures.” The Futures pattern occurs when opera- tions produce some outputs that are needed as inputs to other operations. The order of operations is constrained by a directed graph of data dependencies. Some operations are performed in parallel and some serially, depending on when inputs become available. dynamic task parallelism and pipelines Chapters 6 and 7 discuss some more advanced scenarios: • Chapter 6, “Dynamic Task Parallelism.” In some cases, operations are dynamically added to the backlog of work as the computation proceeds. This pattern applies to several domains, including graph algorithms and sorting. • Chapter 7, “Pipelines.” Use pipelines to feed successive outputs of one component to the input queue of another component, in the style of an assembly line. Parallelism results when the pipeline fills, and when more than one component is simultaneously active. preface
- 19. xvii supporting material In addition to the patterns, there are several appendices: • Appendix A, “Adapting Object-Oriented Patterns.” This appendix gives tips for adapting some of the common object-oriented patterns, such as facades, decorators, and repositories, to multicore architectures. • Appendix B, “Debugging and Profiling Parallel Applications.” This appendix gives you an overview of how to debug and profile parallel applications in Visual Studio 2010. • Appendix C, “Technology Roadmap.” This appendix describes the various Microsoft technologies and frameworks for parallel programming. • Glossary. The glossary contains definitions of the terms used in this book. • References. The references cite the works mentioned in this book. Everyone should read Chapters 1, 2, and 3 for an introduction and overview of the basic principles. Although the succeeding material is presented in a logical order, each chapter, from Chapter 4 on, can be read independently. Callouts in a distinctive style, such as the one shown in the margin, alert you to things you should watch out for. It’s very tempting to take a new tool or technology and try and use it to solve whatever problem is confronting you, regardless of the tool’s applicability. As the saying goes, “when all you have is a hammer, everything looks like a nail.” The “everything’s a nail” mentality can lead to very unfortunate results, which one hopes the bunny in Figure 2 will be able to avoid. You also want to avoid unfortunate results in your parallel pro- grams. Adding parallelism to your application costs time and adds complexity. For good results, you should only parallelize the parts of your application where the benefits outweigh the costs. figure 2 “When all you have is a hammer, everything looks like a nail.” Don’t apply the patterns in this book blindly to your applications.
- 20. xviii What Is Not Covered This book focuses more on processor-bound workloads than on I/O-bound workloads. The goal is to make computationally intensive applications run faster by making better use of the computer’s avail- able cores. As a result, the book does not focus as much on the issue of I/O latency. Nonetheless, there is some discussion of balanced workloads that are both processor intensive and have large amounts of I/O (see Chapter 7, “Pipelines”). There is also an important example for user interfaces in Chapter 5, “Futures,” that illustrates concurrency for tasks with I/O. The book describes parallelism within a single multicore node with shared memory instead of the cluster, High Performance Computing (HPC) Server approach that uses networked nodes with distributed memory. However, cluster programmers who want to take advantage of parallelism within a node may find the examples in this book helpful, because each node of a cluster can have multiple processing units. Goals After reading this book, you should be able to: • Answer the questions at the end of each chapter. • Figure out if your application fits one of the book’s patterns and, if it does, know if there’s a good chance of implementing a straightforward parallel implementation. • Understand when your application doesn’t fit one of these patterns. At that point, you either have to do more reading and research, or enlist the help of an expert. • Have an idea of the likely causes, such as conflicting dependencies or erroneously sharing data between tasks, if your implementation of a pattern doesn’t work. • Use the “Further Reading” sections to find more material. preface
- 21. xix Acknowledgments Writing a technical book is a communal effort. The patterns & prac- tices group always involves both experts and the broader community in its projects. Although this makes the writing process lengthier and more complex, the end result is always more relevant. The authors drove this book’s direction and developed its content, but they want to acknowledge the other people who contributed in various ways. The following subject matter experts were key contributors: Nicholas Chen, Daniel Dig, Munawar Hafiz, Fredrik Berg Kjolstad and Samira Tasharofi, (University of Illinois at Urbana Champaign), Reed Copsey, Jr. (C Tech Development Corporation), and Daan Leijen (Microsoft Research). Judith Bishop (Microsoft Research) reviewed the text and also gave us her valuable perspective as an author. Our schedule was aggressive, but the reviewers worked extra hard to help us meet it. Thank you. Jon Jacky (Modeled Computation LLC) created many of the programming samples and contributed to the text. Rick Carr (DCB Software Testing, Inc) tested the samples and content. Many other people reviewed sections of the book or gave us feedback on early outlines and drafts. They include Chris Tavares, Niklas Gustafson, Dana Groff, Wenming Ye, and David Callahan (Microsoft), Justin Bozonier (MG-ALFA / Milliman, Inc.), Tim Mattson (Intel), Kurt Keutzer (UC Berkeley), Joe Hummel, Ian Griffiths and Mike Woodring (Pluralsight, LLC). There were a great many people who spoke to us about the book and provided feedback. They include the attendees at the ParaPLoP 2010 workshop and TechEd 2010 conference, as well as contributors to discussions on the book’s CodePlex site. The work at UC Berkeley and University of Illinois at Urbana Champaign was supported in part by the Universal Parallel Computing Research Center initiative. Tiberiu Covaci (Many-core.se) also deserves special mention for generating interest in the book during his numerous speaking engage- ments on “Patterns for Parallel Programming” in the U.S. and Europe.
- 22. xx A team of technical writers and editors worked to make the prose readable and interesting. They include Roberta Leibovitz (Modeled Computation LLC), Tina Burden (TinaTech Inc.), and RoAnn Corbisier (Microsoft). The innovative visual design concept used for this guide was developed by Roberta Leibovitz and Colin Campbell (Modeled Computation LLC) who worked with a group of talented designers and illustrators. The book design was created by John Hubbard (Eson). The cartoons that face the chapters were drawn by the award-winning Seattle-based cartoonist Ellen Forney. The technical illustrations were done by Katie Niemer (TinaTech Inc.). acknowledgments
- 23. 1 Introduction Parallel programming uses multiple cores at the same time to improve your application’s speed. Writing parallel programs has the reputation of being hard, but help has arrived. The CPU meter shows the problem. One core is running at 100 per- cent, but all the other cores are idle. Your application is CPU-bound, but you are using only a fraction of the computing power of your multicore system. What next? The answer, in a nutshell, is parallel programming. Where you once would have written the kind of sequential code that is familiar to all programmers, you now find that this no longer meets your perfor- mance goals. To use your system’s CPU resources efficiently, you need to split your application into pieces that can run at the same time. This is easier said than done. Parallel programming has a reputation for being the domain of experts and a minefield of subtle, hard-to-reproduce software defects. Everyone seems to have a favor- ite story about a parallel program that did not behave as expected because of a mysterious bug. These stories should inspire a healthy respect for the difficulty of the problems you face in writing your own parallel programs. Fortunately, help has arrived. The Microsoft® .NET Framework 4 in- troduces a new programming model for parallelism that significantly simplifies the job. Behind the scenes are supporting libraries with sophisticated algorithms that dynamically distribute computations on multicore architectures. In addition, Microsoft Visual Studio® 2010 development system includes debugging and analysis tools to support the new parallel programming model. Proven design patterns are another source of help. This guide introduces you to the most important and frequently used patterns of parallel programming and gives executable code samples for them, using the Task Parallel Library (TPL) and Parallel LINQ (PLINQ). When thinking about where to begin, a good place to start is to review the patterns in this book. See if your problem has any attributes that match the six patterns presented in the following chapters. If it does, delve more deeply into the relevant pattern or patterns and study the sample code. 1
- 24. 2 chapter one Most parallel programs conform to these patterns, and it’s very likely you’ll be successful in finding a match to your particular problem. If you can’t use these patterns, you’ve probably encountered one of the more difficult cases, and you’ll need to hire an expert or consult the academic literature. The code examples for this guide are online at http://parallel patterns.codeplex.com. The Importance of Potential Parallelism The patterns in this book are ways to express potential parallelism. This means that your program is written so that it runs faster when parallel hardware is available and roughly the same as an equivalent sequential program when it’s not. If you correctly structure your code, the run-time environment can automatically adapt to the workload on a particular computer. This is why the patterns in this book only express potential parallelism. They do not guarantee parallel execution in every situation. Expressing potential parallelism is a central organizing principle behind the programming model of .NET. It deserves some explanation. Some parallel applications can be written for specific hardware. For example, creators of programs for a console gaming platform have detailed knowledge about the hardware resources that will be available at run time. They know the number of cores and the details of the memory architecture in advance. The game can be written to exploit the exact level of parallelism provided by the platform. Com- plete knowledge of the hardware environment is also a characteristic of some embedded applications, such as industrial control. The life cycle of such programs matches the life cycle of the specific hardware they were designed to use. In contrast, when you write programs that run on general-purpose computing platforms, such as desktop workstations and servers, there is less predictability about the hardware features. You may not always know how many cores will be available. You also may be unable to predict what other software could be running at the same time as your application. Even if you initially know your application’s environment, it can change over time. In the past, programmers assumed that their applications would automatically run faster on later generations of hardware. You could rely on this assumption because processor clock speeds kept increasing. With multicore processors, clock speeds are not increasing with newer hardware as much as in the past. Instead, the trend in processor design is toward more cores. If you want your application to benefit from hardware advances in the multicore world, you need to adapt your programming model. You should expect that Declaring the potential parallelism of your program allows the execution environ- ment to run it on all available cores, whether one or many. Don’t hard code the degree of parallelism in an application. You can’t always predict how many cores will be available at run time.
- 25. 3 introduction the programs you write today will run on computers with many more cores within a few years. Focusing on potential parallelism helps to “future proof” your program. Finally, you must plan for these contingencies in a way that does not penalize users who might not have access to the latest hardware. You want your parallel application to run as fast on a single-core com- puter as an application that was written using only sequential code. In other words, you want scalable performance from one to many cores. Allowing your application to adapt to varying hardware capabilities, both now and in the future, is the motivation for potential parallelism. An example of potential parallelism is the parallel loop pattern described in Chapter 2, “Parallel Loops.” If you have a for loop that performs a million independent iterations, it makes sense to divide those iterations among the available cores and do the work in parallel. It’s easy to see that how you divide the work should depend on the number of cores. For many common scenarios, the speed of the loop will be approximately proportional to the number of cores. Decomposition, Coordination, and Scalable Sharing The patterns in this book contain some common themes. You’ll see that the process of designing and implementing a parallel application involves three aspects: methods for decomposing the work into dis- crete units known as tasks, ways of coordinating these tasks as they run in parallel, and scalable techniques for sharing the data needed to perform the tasks. The patterns described in this guide are design patterns. You can apply them when you design and implement your algorithms and when you think about the overall structure of your application. Although the example applications are small, the principles they dem- onstrate apply equally well to the architectures of large applications. understanding tasks Tasks are sequential operations that work together to perform a larger operation. When you think about how to structure a parallel program, it’s important to identify tasks at a level of granularity that results in efficient use of hardware resources. If the chosen granular- ity is too fine, the overhead of managing tasks will dominate. If it’s too coarse, opportunities for parallelism may be lost because cores that could otherwise be used remain idle. In general, tasks should be as large as possible, but they should remain independent of each other, and there should be enough tasks to keep the cores busy. You may also need to consider the heuristics that will be used for task Hardware trends predict more cores instead of faster clock speeds. A well-written parallel program runs at approxi- mately the same speed as a sequential program when there is only one core available. Tasks are sequential units of work. Tasks should be large, independent, and numerous enough to keep all cores busy.
- 26. 4 chapter one scheduling. Meeting all these goals sometimes involves design tradeoffs. Decomposing a problem into tasks requires a good under- standing of the algorithmic and structural aspects of your application. An example of these guidelines is a parallel ray tracing application. A ray tracer constructs a synthetic image by simulating the path of each ray of light in a scene. The individual ray simulations are a good level of granularity for parallelism. Breaking the tasks into smaller units, for example, by trying to decompose the ray simulation itself into independent tasks, only adds overhead, because the number of ray simulations is already large enough to keep all cores occupied. If your tasks vary greatly in size, you generally want more of them in order to fill in the gaps. Another advantage to grouping work into larger and fewer tasks is that such tasks are often more independent of each other than smaller but more numerous tasks. Larger tasks are less likely than smaller tasks to share local variables or fields. Unfortunately, in applications that rely on large mutable object graphs, such as applica- tions that expose a large object model with many public classes, methods, and properties, the opposite may be true. In these cases, the larger the task, the more chance there is for unexpected sharing of data or other side effects. The overall goal is to decompose the problem into independent tasks that do not share data, while providing sufficient tasks to occupy the number of cores available. When considering the number of cores, you should take into account that future generations of hardware will have more cores. coordinating tasks It’s often possible that more than one task can run at the same time. Tasks that are independent of one another can run in parallel, while some tasks can begin only after other tasks complete. The order of execution and the degree of parallelism are constrained by the appli- cation’s underlying algorithms. Constraints can arise from control flow (the steps of the algorithm) or data flow (the availability of inputs and outputs). Various mechanisms for coordinating tasks are possible. The way tasks are coordinated depends on which parallel pattern you use. For example, the pipeline pattern described in Chapter 7, “Pipelines,” is distinguished by its use of concurrent queues to coordinate tasks. Regardless of the mechanism you choose for coordinating tasks, in order to have a successful design, you must understand the dependen- cies between tasks. Keep in mind that tasks are not threads. Tasks and threads take very different approaches to scheduling. Tasks are much more compat- ible with the concept of potential parallelism than threads are. While a new thread immediately introduces additional concurrency to your application, a new task introduces only the potential for additional concurrency. A task’s potential for additional concurrency will be realized only when there are enough available cores.
- 27. 5 introduction scalable sharing of data Tasks often need to share data. The problem is that when a program is running in parallel, different parts of the program may be racing against each other to perform updates on the same location of memory. The result of such unintended data races can be catastroph- ic. The solution to the problem of data races includes techniques for synchronizing threads. You may already be familiar with techniques that synchronize concurrent threads by blocking their execution in certain circum- stances. Examples include locks, atomic compare-and-swap opera- tions, and semaphores. All of these techniques have the effect of serializing access to shared resources. Although your first impulse for data sharing might be to add locks or other kinds of synchronization, adding synchronization reduces the parallelism of your application. Every form of synchronization is a form of serialization. Your tasks can end up contending over the locks instead of doing the work you want them to do. Programming with locks is also error-prone. Fortunately, there are a number of techniques that allow data to be shared that don’t degrade performance or make your program prone to error. These techniques include the use of immutable, read- only data, limiting your program’s reliance on shared variables, and introducing new steps in your algorithm that merge local versions of mutable state at appropriate checkpoints. Techniques for scalable sharing may involve changes to an existing algorithm. Conventional object-oriented designs can have complex and highly interconnected in-memory graphs of object references. As a result, traditional object-oriented programming styles can be very difficult to adapt to scalable parallel execution. Your first impulse might be to consider all fields of a large, interconnected object graph as mutable shared state, and to wrap access to these fields in serial- izing locks whenever there is the possibility that they may be shared by multiple tasks. Unfortunately, this is not a scalable approach to sharing. Locks can often negatively affect the performance of all cores. Locks force cores to pause and communicate, which takes time, and they introduce serial regions in the code, which reduces the potential for parallelism. As the number of cores gets larger, the cost of lock contention can increase. As more and more tasks are added that share the same data, the overhead associated with locks can dominate the computation. In addition to performance problems, programs that rely on com- plex synchronization are prone to a variety of problems, including deadlock. This occurs when two or more tasks are waiting for each other to release a lock. Most of the horror stories about parallel programming are actually about the incorrect use of shared mutable state or locking protocols. For more about the impor- tance of immutable types in parallel programs, see the section, “Immutable Types,” in Appendix A. Scalable sharing may involve changes to your algorithm. Adding synchronization (locks) can reduce the scalability of your application.
- 28. 6 chapter one Nonetheless, synchronizing elements in an object graph plays a legitimate, if limited, role in scalable parallel programs. This book uses synchronization sparingly. You should, too. Locks can be thought of as the goto statements of parallel programming: they are error prone but necessary in certain situations, and they are best left, when possible, to compilers and libraries. No one is advocating the removal, in the name of performance, of synchronization that’s necessary for correctness. First and foremost, the code still needs to be correct. However, it’s important to incorpo- rate design principles into the design process that limit the need for synchronization. Don’t add synchronization to your application as an afterthought. design approaches It’s common for developers to identify one problem area, parallelize the code to improve performance, and then repeat the process for the next bottleneck. This is a particularly tempting approach when you parallelize an existing sequential application. Although this may give you some initial improvements in performance, it has many pitfalls, and it may not produce the best results. A far better approach is to understand your problem or application and look for potential parallelism across the entire application as a whole. What you dis- cover may lead you to adopt a different architecture or algorithm that better exposes the areas of potential parallelism in your application. Don’t simply identify bottlenecks and parallelize them. Instead, pre- pare your program for parallel execution by making structural changes. Techniques for decomposition, coordination, and scalable sharing are interrelated. There’s a circular dependency. You need to consider all of these aspects together when choosing your approach for a particular application. After reading the preceding description, you might complain that it all seems vague. How specifically do you divide your problem into tasks? Exactly what kinds of coordination techniques should you use? Questions like these are best answered by the patterns described in this book. Patterns are a true shortcut to understanding. As you begin to see the design motivations behind the patterns, you will also develop your intuition about how the patterns and their variations can be applied to your own applications. The following section gives more details about how to select the right pattern. Think in terms of data structures and algorithms; don’t just identify bottlenecks. Use patterns.
- 29. 7 introduction Selecting the Right Pattern To select the relevant pattern, use the following table. Application characteristic Relevant pattern Do you have sequential loops where there’s no communication among the steps of each iteration? The Parallel Loop pattern (Chapter 2). Parallel loops apply an independent operation to multiple inputs simultaneously. Do you have distinct operations with well-defined control dependencies? Are these operations largely free of serializing dependencies? The Parallel Task pattern (Chapter 3) Parallel tasks allow you to establish parallel control flow in the style of fork and join. Do you need to summarize data by applying some kind of combination operator? Do you have loops with steps that are not fully independent? The Parallel Aggregation pattern (Chapter 4) Parallel aggregation introduces special steps in the algorithm for merging partial results. This pattern expresses a reduction operation and includes map/reduce as one of its variations. Does the ordering of steps in your algorithm depend on data flow constraints? The Futures pattern (Chapter 5) Futures make the data flow dependencies between tasks explicit. This pattern is also referred to as the Task Graph pattern. Does your algorithm divide the problem domain dynamically during the run? Do you operate on recursive data structures such as graphs? The Dynamic Task Parallelism pattern (Chapter 6) This pattern takes a divide-and-conquer approach and spawns new tasks on demand. Does your application perform a sequence of operations repetitively? Does the input data have streaming characteristics? Does the order of processing matter? The Pipelines pattern (Chapter 7) Pipelines consist of components that are connected by queues, in the style of producers and consumers. All the components run in parallel even though the order of inputs is respected. One way to become familiar with the possibilities of the six patterns is to read the first page or two of each chapter. This gives you an overview of approaches that have been proven to work in a wide va- riety of applications. Then go back and more deeply explore patterns that may apply in your situation. A Word About Terminology You’ll often hear the words parallelism and concurrency used as syn- onyms. This book makes a distinction between the two terms. Concurrency is a concept related to multitasking and asynchro- nous input-output (I/O). It usually refers to the existence of multiple threads of execution that may each get a slice of time to execute before being preempted by another thread, which also gets a slice of time. Concurrency is necessary in order for a program to react to external stimuli such as user input, devices, and sensors. Operating systems and games, by their very nature, are concurrent, even on one core.
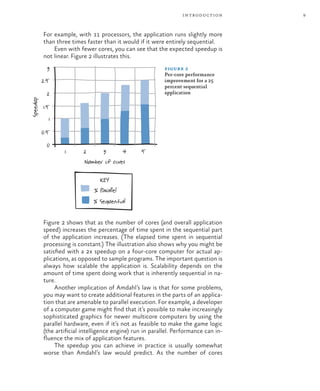
- 30. 8 chapter one With parallelism, concurrent threads execute at the same time on multiple cores. Parallel programming focuses on improving the perfor- mance of applications that use a lot of processor power and are not constantly interrupted when multiple cores are available. The goals of concurrency and parallelism are distinct. The main goal of concurrency is to reduce latency by never allowing long peri- ods of time to go by without at least some computation being performed by each unblocked thread. In other words, the goal of concurrency is to prevent thread starvation. Concurrency is required operationally. For example, an operating system with a graphical user interface must support concurrency if more than one window at a time can update its display area on a sin- gle-core computer. Parallelism, on the other hand, is only about throughput. It’s an optimization, not a functional requirement. Its goal is to maximize processor usage across all available cores; to do this, it uses scheduling algorithms that are not preemptive, such as algorithms that process queues or stacks of work to be done. The Limits of Parallelism A theoretical result known as Amdahl’s law says that the amount of performance improvement that parallelism provides is limited by the amount of sequential processing in your application. This may, at first, seem counterintuitive. Amdahl’s law says that no matter how many cores you have, the maximum speedup you can ever achieve is (1 / percent of time spent in sequential processing). Figure 1 illustrates this. figure 1 Amdahl’s law for an application with 25 percent sequential processing Execution Speed 4 3.5 3 2.5 2 1.5 1 0.5 0 0 6 11 16 Number of processors
- 31. 9 introduction For example, with 11 processors, the application runs slightly more than three times faster than it would if it were entirely sequential. Even with fewer cores, you can see that the expected speedup is not linear. Figure 2 illustrates this. figure 2 Per-core performance improvement for a 25 percent sequential application Figure 2 shows that as the number of cores (and overall application speed) increases the percentage of time spent in the sequential part of the application increases. (The elapsed time spent in sequential processing is constant.) The illustration also shows why you might be satisfied with a 2x speedup on a four-core computer for actual ap- plications, as opposed to sample programs. The important question is always how scalable the application is. Scalability depends on the amount of time spent doing work that is inherently sequential in na- ture. Another implication of Amdahl’s law is that for some problems, you may want to create additional features in the parts of an applica- tion that are amenable to parallel execution. For example, a developer of a computer game might find that it’s possible to make increasingly sophisticated graphics for newer multicore computers by using the parallel hardware, even if it’s not as feasible to make the game logic (the artificial intelligence engine) run in parallel. Performance can in- fluence the mix of application features. The speedup you can achieve in practice is usually somewhat worse than Amdahl’s law would predict. As the number of cores % P arallel % Sequential KEY 0 0.5 1 1.5 2 2.5 3 1 2 3 4 5 Number of cores Speedup
- 32. 10 chapter one increases, the overhead incurred by accessing shared memory also increases. Also, parallel algorithms may include overhead for coordina- tion that would not be necessary for the sequential case. Profiling tools, such as the Visual Studio Concurrency Visualizer, can help you understand how effective your use of parallelism is. In summary, because an application consists of parts that must run sequentially as well as parts that can run in parallel, the application overall will rarely see a linear increase in performance with a linear increase in the number of cores, even if certain parts of the applica- tion see a near linear speedup. Understanding the structure of your application, and its algorithms—that is, which parts of your applica- tion are suitable for parallel execution—is a step that can’t be skipped when analyzing performance. A Few Tips Always try for the simplest approach. Here are some basic precepts: • Whenever possible, stay at the highest possible level of abstrac- tion and use constructs or a library that does the parallel work for you. • Use your application server’s inherent parallelism; for example, use the parallelism that is incorporated into a web server or database. • Use an API to encapsulate parallelism, such as Microsoft Parallel Extensions for .NET (TPL and PLINQ). These libraries were written by experts and have been thoroughly tested; they help you to avoid many of the common problems that arise in parallel programming. • Consider the overall architecture of your application when thinking about how to parallelize it. It’s tempting to simply look for the performance hotspots and focus on improving them. While this may improve things, it does not necessarily give you the best results. • Use patterns, such as the ones described in this book. • Often, restructuring your algorithm (for example, to eliminate the need for shared data) is better than making low-level improvements to code that was originally designed to run serially. • Don’t share data among concurrent tasks unless absolutely necessary. If you do share data, use one of the containers provided by the API you are using, such as a shared queue. • Use low-level primitives, such as threads and locks, only as a last resort. Raise the level of abstraction from threads to tasks in your applications.
- 33. 11 introduction Exercises 1. What are some of the tradeoffs between decomposing a problem into many small tasks versus decomposing it into larger tasks? 2. What is the maximum potential speedup of a program that spends 10 percent of its time in sequential processing when you move it from one to four cores? 3. What is the difference between parallelism and concurrency? For More Information If you are interested in better understanding the terminology used in the text, refer to the glossary at the end of this book. The design patterns presented in this book are consistent with classifications of parallel patterns developed by groups in both indus- try and academia. In the terminology of these groups, the patterns in this book would be considered to be algorithm or implementation patterns. Classification approaches for parallel patterns can be found in the book by Mattson, et al. and at the Our Pattern Language (OPL) web site. This book attempts to be consistent with the terminology of these sources. In cases where this is not possible, an explanation appears in the text. For a detailed discussion of parallelism on the Windows platform, see the book by Duffy. An overview of threading and synchronization in .NET can be found in Albahari. J. Albahari and B. Albahari. C# 4 in a Nutshell. O’Reilly, fourth edition, 2010. J. Duffy. Concurrent Programming on Windows. Addison-Wesley, 2008. T. G. Mattson, B. A. Sanders, and B. L. Massingill. Patterns for Parallel Programming. Addison-Wesley, 2004. “Our Pattern Language for Parallel Programming Ver 2.0.” http://parlab.eecs.berkeley.edu/wiki/patterns
- 35. 13 Parallel Loops 2 The Parallel Loop pattern independently applies an operation to multiple data elements. It’s an example of data parallelism. Use the Parallel Loop pattern when you need to perform the same independent operation for each element of a collection or for a fixed number of iterations. The steps of a loop are independent if they don’t write to memory locations or files that are read by other steps. The syntax of a parallel loop is very similar to the for and foreach loops you already know, but the parallel loop runs faster on a com- puter that has available cores. Another difference is that, unlike a se- quential loop, the order of execution isn’t defined for a parallel loop. Steps often take place at the same time, in parallel. Sometimes, two steps take place in the opposite order than they would if the loop were sequential. The only guarantee is that all of the loop’s iterations will have run by the time the loop finishes. It’s easy to change a sequential loop into a parallel loop. However, it’s also easy to use a parallel loop when you shouldn’t. This is because it can be hard to tell if the steps are actually independent of each other. It takes practice to learn how to recognize when one step is dependent on another step. Sometimes, using this pattern on a loop with dependent steps causes the program to behave in a completely unexpected way, and perhaps to stop responding. Other times, it in- troduces a subtle bug that only appears once in a million runs. In other words, the word “independent” is a key part of the definition of this pattern, and one that this chapter explains in detail. For parallel loops, the degree of parallelism doesn’t need to be specified by your code. Instead, the run-time environment executes the steps of the loop at the same time on as many cores as it can. The loop works correctly no matter how many cores are available. If there is only one core, the performance is close to (perhaps within a few percentage points of) the sequential equivalent. If there are multiple cores, performance improves; in many cases, performance improves proportionately with the number of cores.
- 36. 14 chapter two The Basics The .NET Framework includes both parallel For and parallel ForEach loops and is also implemented in the Parallel LINQ (PLINQ) query language. Use the Parallel.For method to iterate over a range of inte- ger indices and the Parallel.ForEach method to iterate over user- provided values. Use PLINQ if you prefer a high-level, declarative style for describing loops or if you want to take advantage of PLINQ’s convenience and flexibility. parallel for loops Here’s an example of a sequential for loop in C#. int n = ... for (int i = 0; i < n; i++) { // ... } To take advantage of multiple cores, replace the for keyword with a call to the Parallel.For method and convert the body of the loop into a lambda expression. int n = ... Parallel.For(0, n, i => { // ... }); Parallel.For is a static method with overloaded versions. Here’s the signature of the version of Parallel.For that’s used in the example. Parallel.For(int fromInclusive, int toExclusive, Action<int> body); In the example, the first two arguments specify the iteration limits. The first argument is the lowest index of the loop. The second argu- ment is the exclusive upper bound, or the largest index plus one. The third argument is an action that’s invoked once per iteration. The ac- tion takes the iteration’s index as its argument and executes the loop body once for each index. The Parallel.For method has additional overloaded versions. These are covered in the section, “Variations,” later in this chapter and in Chapter 4, “Parallel Aggregation.” The example includes a lambda expression in the form args => body as the third argument to the Parallel.For invocation. Lambda expressions are unnamed methods that can capture variables from To make for and foreach loops with independent iterations run faster on multicore computers, use their parallel counterparts. Don’t forget that the steps of the loop body must be independent of one another if you want to use a parallel loop. The steps must not communicate by writing to shared variables. Parallel.For uses multiple cores to operate over an index range. The Parallel.For method does not guarantee any particular order of execution. Unlike a sequential loop, some higher-valued indices may be processed before some lower-valued indices.
- 37. 15 parallel loops their enclosing scope. Of course, the body parameter could also be an instance of a delegate type, an anonymous method (using the delegate keyword) or an ordinary named method. In other words, you don’t have to use lambda expressions if you don’t want to. Examples in this book use lambda expressions because they keep the code within the body of the loop, and they are easier to read when the number of lines of code is small. parallel for each Here’s an example of a sequential foreach loop in C#. IEnumerable<MyObject> myEnumerable = ... foreach (var obj in myEnumerable) { // ... } To take advantage of multiple cores, replace the foreach keyword with a call to the Parallel.ForEach method. IEnumerable<MyObject> myEnumerable = ... Parallel.ForEach(myEnumerable, obj => { // ... }); Parallel.ForEach is a static method with overloaded versions. Here’s the signature of the version of Parallel.ForEach that was used in the example. ForEach<TSource>(IEnumerable<TSource> source, Action<TSource> body); In the example, the first argument is an object that implements the IEnumerable<MyObject> interface. The second argument is a method that’s invoked for each element of the input collection. The Parallel.ForEach method does not guarantee the order of execution. Unlike a sequential ForEach loop, the incoming values aren’t always processed in order. The Parallel.ForEach method has additional overloaded versions. These are covered in the section, “Variations,” later in this chapter and in Chapter 4, “Parallel Aggregation.” If you’re unfamiliar with the syntax for lambda expressions, see “Further Reading” at the end of this chapter. After you use lambda expressions, you’ll wonder how you ever lived without them. Parallel.ForEach runs the loop body for each element in a collection. Don’t forget that iterations need to be independent. The loop body must only make updates to fields of the particular instance that’s passed to it.
- 38. 16 chapter two parallel linq (plinq) The Language Integrated Query (LINQ) feature of the .NET Frame- work includes a parallel version named PLINQ (Parallel LINQ). There are many options and variations for expressing PLINQ queries but al- most all LINQ-to-Objects expressions can easily be converted to their parallel counterpart by adding a call to the AsParallel extension method. Here’s an example that shows both the LINQ and PLINQ versions. IEnumerable<MyObject> source = ... // LINQ var query1 = from i in source select Normalize(i); // PLINQ var query2 = from i in source.AsParallel() select Normalize(i); This code example creates two queries that transform values of the enumerable object source. The PLINQ version uses multiple cores if they’re available. You can also use PLINQ’s ForAll extension method in cases where you want to iterate over the input values but you don’t want to select output values to return. This is shown in the following code. IEnumerable<MyObject> myEnumerable = ... myEnumerable.AsParallel().ForAll(obj => DoWork(obj)); The ForAll extension method is the PLINQ equivalent of Parallel. ForEach. what to expect By default, the degree of parallelism (that is, how many iterations run at the same time in hardware) depends on the number of available cores. In typical scenarios, the more cores you have, the faster your loop executes, until you reach the point of diminishing returns that Amdahl’s Law predicts. How much faster depends on the kind of work your loop does. The .NET implementation of the Parallel Loop pattern ensures that exceptions that are thrown during the execution of a loop body are not lost. For both the Parallel.For and Parallel.ForEach methods as well as for PLINQ, exceptions are collected into an AggregateEx- ception object and rethrown in the context of the calling thread. All exceptions are propagated back to you. To learn more about excep- tion handling for parallel loops, see the section, “Variations,” later in this chapter. You can convert LINQ expressions to parallel code with the AsParallel extension method. It’s important to use PLINQ’s ForAll extension method instead of giving a PLINQ query as an argument to the Parallel.ForEach method. For more information, see the section, “Mixing the Parallel Class and PLINQ,” later in this chapter. Adding cores makes your loop run faster; however, there’s always an upper limit. You must choose the correct granularity. Too many small parallel loops can reach a point of over-decomposition where the multicore speedup is more than offset by the parallel loop’s overhead.
- 39. 17 parallel loops Parallel loops have many variations. There are 12 overloaded methods for Parallel.For and 20 overloaded methods for Parallel. ForEach. PLINQ has close to 200 extension methods. Although there are many overloaded versions of For and ForEach, you can think of the overloads as providing optional configuration options. Two ex- amples are a maximum degree of parallelism and hooks for external cancellation. These options allow the loop body to monitor the prog- ress of other steps (for example, to see if exceptions are pending) and to manage task-local state. They are sometimes needed in advanced scenarios. To learn about the most important cases, see the section, “Variations,” later in this chapter. If you convert a sequential loop to a parallel loop and then find that your program does not behave as expected, the mostly likely problem is that the loop’s steps are not independent. Here are some common examples of dependent loop bodies: • Writing to shared variables. If the body of a loop writes to a shared variable, there is a loop body dependency. This is a common case that occurs when you are aggregating values. Here is an example, where total is shared across iterations. for(int i = 1; i < n; i++) total += data[i]; If you encounter this situation, see Chapter 4, “Parallel Aggregation.” Shared variables come in many flavors. Any variable that is declared outside of the scope of the loop body is a shared variable. Shared references to types such as classes or arrays will implicitly allow all fields or array elements to be shared. Parameters that are declared using the keyword ref result in shared variables. Even reading and writing files can have the same effect as shared variables. • Using properties of an object model. If the object being processed by a loop body exposes properties, you need to know whether those properties refer to shared state or state that’s local to the object itself. For example, a property named Parent is likely to refer to global state. Here’s an example. for(int i = 0; i < n; i++) SomeObject[i].Parent.Update(); In this example, it’s likely that the loop iterations are not independent. For all values of i, SomeObject[i].Parent is a reference to a single shared object. Robust exception handling is an important aspect of parallel loop processing. Check carefully for dependen- cies between loop iterations! Not noticing dependencies between steps is by far the most common mistake you’ll make with parallel loops.
- 40. 18 chapter two • Referencing data types that are not thread safe. If the body of the parallel loop uses a data type that is not thread safe, the loop body is not independent (there is an implicit dependency on the thread context). An example of this case, along with a solution, is shown in “Using Task-Local State in a Loop Body” in the section, “Variations,” later in this chapter. • Loop-carried dependence. If the body of a parallel for loop performs arithmetic on the loop index, there is likely to be a dependency that is known as loop-carried dependence. This is shown in the following code example. The loop body references data[i] and data[i – 1]. If Parallel.For is used here, there’s no guarantee that the loop body that updates data[i – 1] has executed before the loop for data[i]. for(int i = 1; i < N; i++) data[i] = data[i] + data[i - 1]; Sometimes, it’s possible to use a parallel algorithm in cases of loop-carried dependence, but this is outside the scope of this book. Your best bet is to look elsewhere in your program for opportunities for parallelism or to analyze your algorithm and see if it matches some of the advanced parallel patterns that occur in scientific computing. Parallel scan and parallel dynamic programming are examples of these patterns. When you look for opportunities for parallelism, profiling your ap- plication is a way to deepen your understanding of where your application spends its time; however, profiling is not a substitute for understanding your application’s structure and algorithms. For exam- ple, profiling doesn’t tell you whether loop bodies are independent. An Example Here’s an example of when to use a parallel loop. Fabrikam Shipping extends credit to its commercial accounts. It uses customer credit trends to identify accounts that might pose a credit risk. Each cus- tomer account includes a history of past balance-due amounts. Fabri- kam has noticed that customers who don’t pay their bills often have histories of steadily increasing balances over a period of several months before they default. To identify at-risk accounts, Fabrikam uses statistical trend analy- sis to calculate a projected credit balance for each account. If the analysis predicts that a customer account will exceed its credit limit within three months, the account is flagged for manual review by one of Fabrikam’s credit analysts. Arithmetic on loop index variables, especially addition or subtraction, usually indicates loop-carried dependence. Don’t expect miracles from profiling—it can’t analyze your algorithms for you. Only you can do that. You must be extremely cautious when getting data from properties and methods. Large object models are known for sharing mutable state in unbelievably devious ways.
- 41. 19 parallel loops In the application, a top-level loop iterates over customers in the account repository. The body of the loop fits a trend line to the bal- ance history, extrapolates the projected balance, compares it to the credit limit, and assigns the warning flag if necessary. An important aspect of this application is that each customer’s credit status can be independently calculated. The credit status of one customer doesn’t depend on the credit status of any other customer. Because the operations are independent, making the credit analysis application run faster is simply a matter of replacing a sequential foreach loop with a parallel loop. The complete source code for this example is online at http:// parallelpatterns.codeplex.com in the Chapter2CreditReview project. sequential credit review example Here’s the sequential version of the credit analysis operation. static void UpdatePredictionsSequential( AccountRepository accounts) { foreach (Account account in accounts.AllAccounts) { Trend trend = SampleUtilities.Fit(account.Balance); double prediction = trend.Predict( account.Balance.Length + NumberOfMonths); account.SeqPrediction = prediction; account.SeqWarning = prediction < account.Overdraft; } } The UpdatePredictionsSequential method processes each account from the application’s account repository. The Fit method is a utility function that uses the statistical least squares method to create a trend line from an array of numbers. The Fit method is a pure func- tion. This means that it doesn’t modify any state. The prediction is a three-month projection based on the trend. If a prediction is more negative than the overdraft limit (credit balances are negative numbers in the accounting system), the account is flagged for review. credit review example using parallel.for each The parallel version of the credit scoring analysis is very similar to the sequential version.
- 42. 20 chapter two static void UpdatePredictionsParallel(AccountRepository accounts) { Parallel.ForEach(accounts.AllAccounts, account => { Trend trend = SampleUtilities.Fit(account.Balance); double prediction = trend.Predict( account.Balance.Length + NumberOfMonths); account.ParPrediction = prediction; account.ParWarning = prediction < account.Overdraft; }); } The UpdatePredictionsParallel method is identical to the Up- datePredictionsSequential method, except that the Parallel.ForEach method replaces the foreach operator. credit review example with plinq You can also use PLINQ to express a parallel loop. Here’s an example. static void UpdatePredictionsPlinq(AccountRepository accounts) { accounts.AllAccounts .AsParallel() .ForAll(account => { Trend trend = SampleUtilities.Fit(account.Balance); double prediction = trend.Predict( account.Balance.Length + NumberOfMonths); account.PlinqPrediction = prediction; account.PlinqWarning = prediction < account.Overdraft; }); } Using PLINQ is almost exactly like using LINQ-to-Objects. PLINQ provides a ParallelEnumerable class that defines extension methods for various types in a manner very similar to LINQ’s Enumerable class. One of the methods of ParallelEnumerable is the AsParallel exten- sion method. The AsParallel extension method allows you to convert a se- quential collection of type IEnumerable<T> into a ParallelQuery<T> object. Applying AsParallel to the accounts.AllAccounts collection returns an object of type ParallelQuery<AccountRecord>. PLINQ’s ParallelEnumerable class has close to 200 extension methods that provide parallel queries for ParallelQuery<T> objects. In addition to parallel implementations of LINQ methods, such as
- 43. 21 parallel loops Use Break to exit a loop early while ensuring that lower-indexed steps complete. Select and Where, PLINQ provides a ForAll extension method that invokes a delegate method in parallel for every element. In the PLINQ prediction example, the argument to ForAll is a lambda expression that performs the credit analysis for a specified account. The body is the same as in the sequential version. performance comparison Running the credit review example on a quad-core computer shows that the Parallel.ForEach and PLINQ versions run slightly less than four times as fast as the sequential version. Timing numbers vary; you may want to run the online samples on your own computer. Variations The credit analysis example shows a typical way to use parallel loops, but there can be variations. This section introduces some of the most important ones. You won’t always need to use these variations, but you should be aware that they are available. breaking out of loops early Breaking out of loops is a familiar part of sequential iteration. It’s less common in parallel loops, but you’ll sometimes need to do it. Here’s an example of the sequential case. int n = ... for (int i = 0; i < n; i++) { // ... if (/* stopping condition is true */) break; } The situation is more complicated with parallel loops because more than one step may be active at the same time, and steps of a parallel loop are not necessarily executed in any predetermined order. Conse- quently, parallel loops have two ways to break or stop a loop instead of just one. Parallel break allows all steps with indices lower than the break index to run before terminating the loop. Parallel stop termi- nates the loop without allowing any new steps to begin. Parallel Break The Parallel.For method has an overload that provides a Parallel LoopState object as a second argument to the loop body. You can ask the loop to break by calling the Break method of the ParallelLoop State object. Here’s an example.
- 44. 22 chapter two int n = ... Parallel.For(0, n, (i, loopState) => { // ... if (/* stopping condition is true */) { loopState.Break(); return; } }); This example uses an overloaded version of Parallel.For that passes a “loop state” object to each step. Here’s the signature of the version of the Parallel.For method that was used in the example. Parallel.For(int fromInclusive, int toExclusive, Action<int, ParallelLoopState> body); The object that’s passed to the loopState argument is an instance of the ParallelLoopState class that was created by the parallel loop for use within the loop body. Calling the Break method of the ParallelLoopState object begins an orderly shutdown of the loop processing. Any steps that are run- ning as of the call to Break will run to completion. You may want to check for a break condition in long-running loop bodies and exit that step immediately if a break was requested. If you don’t do this, the step will continue to run until it finishes. To see if another step running in parallel has requested a break, retrieve the value of the parallel loop state’s LowestBreakIteration property. If this returns a nullable long integer whose HasValue property is true, you know that a break has been requested. You can also read the ShouldExitCurrentIteration property of the loop state object, which checks for breaks as well as other stopping conditions. During the processing of a call to the Break method, iterations with an index value less than the current index will be allowed to start (if they have not already started), but iterations with an index value greater than the current index will not be started. This ensures that all iterations below the break point will complete. Because of parallel execution, it’s possible that more than one step may call Break. In that case, the lowest index will be used to determine which steps will be allowed to start after the break occurred. The Parallel.For and Parallel.ForEach methods return an object of type ParallelLoopResult. You can find out if a loop terminated with a break by examining the values of two of the loop result proper- Calling Break doesn’t stop other steps that might have already started running. Don’t forget that all steps with an index value less than the step that invoked the Break method will be allowed to run normally, even after you call Break.
- 45. 23 parallel loops ties. If the IsCompleted property is false and the LowestBreak Iteration property returns an object whose HasValue property is true, you know that the loop terminated by a call to the Break method. You can query for the specific index with the loop result’s LowestBreakIteration property. Here’s an example. int n = ... var result = new double[n]; var loopResult = Parallel.For(0, n, (i, loopState) => { if (/* break condition is true */) { loopState.Break(); return; } result[i] = DoWork(i); }); if (!loopResult.IsCompleted && loopResult.LowestBreakIteration.HasValue) { Console.WriteLine(“Loop encountered a break at {0}”, loopResult.LowestBreakIteration.Value); } The Break method ensures that data up to a particular iteration index value will be processed. Depending on how the iterations are sched- uled, it may be possible that some steps with a higher index value than the one that called the Break method may have been started before the call to Break occurs. The Parallel.ForEach method also supports the loop state Break method. The parallel loop assigns items a sequence number, starting from zero, as it pulls them from the enumerable input. This sequence number is used as the iteration index for the LowestBreakIteration property. Parallel Stop There are also situations, such as unordered searches, where you want the loop to stop as quickly as possible after the stopping condition is met. The difference between “break” and “stop” is that, with stop, no attempt is made to execute loop iterations less than the stopping in- dex if they have not already run. To stop a loop in this way, call the ParallelLoopState class’s Stop method instead of the Break method. Here is an example of parallel stop. Be aware that some steps with index values higher than the step that called the Break method might be run. There’s no way of predicting when or if this might happen. The Parallel.ForEach method also supports the loop state Break method. Use Stop to exit a loop early when you don’t need all lower-indexed iterations to run before terminating the loop.
- 46. 24 chapter two var n = ... var loopResult = Parallel.For(0, n, (i, loopState) => { if (/* stopping condition is true */) { loopState.Stop(); return; } result[i] = DoWork(i); }); if (!loopResult.IsCompleted && !loopResult.LowestBreakIteration.HasValue) { Console.WriteLine(“Loop was stopped”); } When the Stop method is called, the index value of the iteration that caused the stop isn’t available. You cannot call both Break and Stop during the same parallel loop. You have to choose which of the two loop exit behaviors you want to use. If you call both Break and Stop in the same parallel loop, an exception will be thrown. Parallel programs use Stop more often than Break. Processing all iterations with indices less than the stopping iteration is usually not necessary when the loop bodies are independent of each other. It’s also true that Stop shuts down a loop more quickly than Break. There’s no Stop method for a PLINQ query, but you can use the WithCancellation extension method and then use cancellation as a way to stop PLINQ execution. For more information, see the next section, “External Loop Cancellation.” external loop cancellation In some scenarios, you may want to cancel a parallel loop because of an external request. For example, you may need to respond to a re- quest from a user interface to stop what you’re doing. In .NET, you use the CancellationTokenSource class to signal cancellation and the CancellationToken structure to detect and re- spond to a cancellation request. The structure allows you to find out if there is a pending cancellation request. The class lets you signal that cancellation should occur. The Parallel.For and Parallel.ForEach methods include over- loaded versions that accept parallel loop options as one of the argu- ments. You can specify a cancellation token as one of these options. You’ll probably use Stop more often than Break.
- 47. 25 parallel loops If you provide a cancellation token as an option to a parallel loop, the loop will use that token to look for a cancellation request. Here’s an example. void DoLoop(CancellationTokenSource cts) { int n = ... CancellationToken token = cts.Token; var options = new ParallelOptions { CancellationToken = token }; try { Parallel.For(0, n, options, (i) => { // ... // ... optionally check to see if cancellation happened if (token.IsCancellationRequested) { // ... optionally exit this iteration early return; } }); } catch (OperationCanceledException ex) { // ... handle the loop cancellation } } Here is the signature of the Parallel.For method that was used in the example. Parallel.For(int fromInclusive, int toExclusive, ParallelOptions parallelOptions, Action<int> body); When the caller of the DoLoop method is ready to cancel, it invokes the Cancel method of the CancellationTokenSource class that was provided as an argument to the DoLoop method. The parallel loop will allow currently running iterations to complete and then throw an OperationCanceledException. No new iterations will start after cancellation begins. External cancellation requires a cancellation token source object.
- 48. 26 chapter two If external cancellation has been signaled and your loop has called either the Break or the Stop method of the ParallelLoopState object, a race occurs to see which will be recognized first. The parallel loop will either throw an OperationCanceledException or it will termi- nate using the mechanism for Break and Stop that is described in the section, “Breaking Out of Loops Early,” earlier in this chapter. You can use the WithCancellation extension method to add external cancellation capabilities to a PLINQ query. exception handling If the body of a parallel loop throws an unhandled exception, the parallel loop no longer begins any new steps. By default, iterations that are executing at the time of the exception, other than the itera- tion that threw the exception, will complete. After they finish, the parallel loop will throw an exception in the context of the thread that invoked it. Long-running iterations may want to test to see whether an exception is pending in another iteration. They can do this with the ParallelLoopState class’s IsExceptional property. This property returns true if an exception is pending. Because more than one exception may occur during parallel exe- cution, exceptions are grouped using an exception type known as an aggregate exception. The AggregateException class has an Inner Exceptions property that contains a collection of all the exceptions that occurred during the execution of the parallel loop. Because the loop runs in parallel, there may be more than one exception. Exceptions take priority over external cancellations and termina- tions of a loop initiated by calling the Break or Stop methods of the ParallelLoopState object. For a code example and more information about handling aggre- gate exceptions, see the section, “Exception Handling,” in Chapter 3, “Parallel Tasks.” special handling of small loop bodies If the body of the loop performs only a small amount of work, you may find that you achieve better performance by partitioning the it- erations into larger units of work. The reason for this is that there are two types of overhead that are introduced when processing a loop: the cost of managing worker threads and the cost of invoking a del- egate method. In most situations, these costs are negligible, but with very small loop bodies they can be significant. The parallel extensions of .NET Framework 4 include support for custom partitioning. A Partitioner object divides the indices into non-overlapping intervals named ranges. With partitioners, each par- allel loop step handles a range of indices instead of individual indices. Throwing an unhandled exception prevents new iterations from starting. Consider using a Partitioner object when you have many iterations that each perform a small amount of work.
- 49. 27 parallel loops By grouping iterations into ranges, you can avoid some of the over- head of a normal parallel loop. Here’s an example. int n = ... double[] result = new double[n]; Parallel.ForEach(Partitioner.Create(0, n), (range) => { for (int i = range.Item1; i < range.Item2; i++) { // very small, equally sized blocks of work result[i] = (double)(i * i); } }); Here’s the signature of the Parallel.For method that was used in the example. Parallel.ForEach<TSource>( Partitioner<TSource> source, Action<TSource> body); In this example, you can think of the result of the Partitioner.Create method as an object that acts like an instance of IEnumerable <Tuple<int, int>> (the actual type is Partitioner<Tuple<int, int>>). In other words, Create gives you access to a collection of tuples (unnamed records) with two integer field values. Each tuple represents a range of index values that should be processed in a single iteration of the parallel loop. Each iteration of the parallel loop contains a nested sequential for loop that processes each index in the range. The partition-based syntax for parallel loops is more complicated than the syntax for other parallel loops in .NET, and when the amount of work in each iteration is large (or of uneven size across iterations), it may not result in better performance. Generally, you would only use the more complicated syntax after profiling or in the case where loop bodies are extremely small and the number of iterations large. The number of ranges that will be created by a Partitioner object depends on the number of cores in your computer. The default num- ber of ranges is approximately three times the number of those cores. If you know how big you want your ranges to be, you can use an overloaded version of the Partitioner.Create method that allows you to specify the size of each range. Here’s an example. double[] result = new double[1000000]; Parallel.ForEach(Partitioner.Create(0, 1000000, 50000), (range) =>
- 50. 28 chapter two { for (int i = range.Item1; i < range.Item2; i++) { // small, equally sized blocks of work result[i] = (double)(i * i); } }); In this example, each range will span 50,000 index values. In other words, for a million iterations, the system will use twenty parallel iterations (1,000,000 / 50,000). These iterations will be spread out among all the available cores. Custom partitioning is an extension point in the API for parallel loops. You can implement your own partitioning strategies. For more information about this topic, see the section, “Further Reading,” at the end of this chapter. controlling the degree of parallelism Although you usually let the system manage how iterations of a paral- lel loop are mapped to your computer’s cores, in some cases, you may want additional control. You’ll see this variation of the Parallel Loop pattern in a variety of circumstances. Reducing the degree of parallelism is often used in performance testing to simulate less capable hardware. Increasing the degree of parallelism to a number larger than the number of cores can be appropriate when iterations of your loop spend a lot of time wait- ing for I/O operations to complete. The term degree of parallelism can be used in two senses. In the simplest case, it refers to the number of cores that are used to process iterations simultaneously. However, .NET also uses this term to refer to the number of tasks that can be used simultaneously by the parallel loop. For example, the MaxDegreeOfParallelism property of the ParallelOptions object refers to the maximum number of worker tasks that will be scheduled at any one time by a parallel loop. For efficient use of hardware resources, the number of tasks is often greater than the number of available cores. For example, parallel loops may use additional tasks in cases where there are blocking I/O operations that do not require processor resources to run. The degree of parallelism is automatically managed by the underlying components of the system; the implementation of the Parallel class, the default task scheduler, and the .NET thread pool all play a role in optimizing throughput under a wide range of conditions. You can limit the maximum number of tasks used concurrently by specifying the MaxDegreeOfParallelism property of a Parallel Options object. Here is an example. You can control the maximum number of threads used concurrently by a parallel loop.
- 51. 29 parallel loops var n = ... var options = new ParallelOptions() { MaxDegreeOfParallelism = 2}; Parallel.For(0, n, options, i => { // ... }); In the preceding code example, the parallel loop will run using at most two tasks at any one time. Here’s the signature of the Parallel.For method that was used in the example. Parallel.For(int fromInclusive, int toExclusive, ParallelOptions parallelOptions, Action<int> body); You can also configure the maximum number of worker threads for PLINQ queries by setting the WithDegreeOfParallelism property of a ParallelQuery<T> object. Here’s an example. IEnumerable<T> myCollection = // ... myCollection.AsParallel() .WithDegreeOfParallelism(8) .ForAll(obj => /* ... */); The query in the code example will run with a maximum of eight tasks at any one time. If you specify a larger degree of parallelism, you may also want to use the ThreadPool class’s SetMinThreads method so that these threads are created without delay. If you don’t do this, the thread pool’s thread injection algorithm may limit how quickly threads can be added to the pool of worker threads that is used by the parallel loop. It may take more time than you want to create the required number of threads. using task-local state in a loop body Occasionally, you’ll need to maintain thread-local state during the execution of a parallel loop. For example, you might want to use a parallel loop to initialize each element of a large array with random values. The .NET Framework Random class does not support multi- threaded access. Therefore, you need a separate instance of the random number generator for each thread. Here’s an example that uses one of the overloads of the Parallel. ForEach method. The example uses a Partitioner object to decom- You must use task-local state for loop bodies that make calls to methods that are not thread safe.
- 52. Other documents randomly have different content
- 56. The Project Gutenberg eBook of The Art of Logical Thinking; Or, The Laws of Reasoning
- 57. This ebook is for the use of anyone anywhere in the United States and most other parts of the world at no cost and with almost no restrictions whatsoever. You may copy it, give it away or re-use it under the terms of the Project Gutenberg License included with this ebook or online at www.gutenberg.org. If you are not located in the United States, you will have to check the laws of the country where you are located before using this eBook. Title: The Art of Logical Thinking; Or, The Laws of Reasoning Author: William Walker Atkinson Release date: January 13, 2013 [eBook #41838] Most recently updated: October 23, 2024 Language: English Credits: Produced by sp1nd, CM, and the Online Distributed Proofreading Team at http://www.pgdp.net (This file was produced from images generously made available by The Internet Archive) *** START OF THE PROJECT GUTENBERG EBOOK THE ART OF LOGICAL THINKING; OR, THE LAWS OF REASONING ***
- 58. THE ART OF LOGICAL THINKING OR THE LAWS OF REASONING By WILLIAM WALKER ATKINSON L.N. FOWLER & COMPANY 7, Imperial Arcade, Ludgate Circus London, E.C., England 1909 THE PROGRESS COMPANY CHICAGO, ILL. Copyright 1909 By THE PROGRESS COMPANY Chicago, Ill., U.S.A.
- 59. CONTENTS I. Reasoning 9 II. The Process of Reasoning 17 III. The Concept 25 IV. The Use of Concepts 37 V. Concepts and Images 48 VI. Terms 56 VII. The Meaning of Terms 73 VIII. Judgments 82 IX. Propositions 90 X. Immediate Reasoning 99 XI. Inductive Reasoning 107 XII. Reasoning by Induction 116 XIII. Theory and Hypotheses 125 XIV. Making and Testing Hypotheses 132 XV. Deductive Reasoning 144 XVI. The Syllogism 156 XVII. Varieties of Syllogisms 167 XVIII. Reasoning by Analogy 179 XIX. Fallacies 186
- 60. CHAPTER I. REASONING "Reasoning" is defined as: "The act, process or art of exercising the faculty of reason; the act or faculty of employing reason in argument; argumentation, ratiocination; reasoning power; disputation, discussion, argumentation." Stewart says: "The word reason itself is far from being precise in its meaning. In common and popular discourse it denotes that power by which we distinguish truth from falsehood, and right from wrong, and by which we are enabled to combine means for the attainment of particular ends." By the employment of the reasoning faculties of the mind we compare objects presented to the mind as percepts or concepts, taking up the "raw materials" of thought and weaving them into more complex and elaborate mental fabrics which we call abstract and general ideas of truth. Brooks says: "It is the thinking power of the mind; the faculty which gives us what has been called thought- knowledge, in distinction from sense-knowledge. It may be regarded as the mental architect among the faculties; it transforms the material furnished by the senses ... into new products, and thus builds up the temples of science and philosophy." The last- mentioned authority adds: "Its products are twofold, ideas and thoughts. An idea is a mental product which when expressed in words does not give a proposition; a thought is a mental product which embraces the relation of two or more ideas. The ideas of the understanding are of two general classes; abstract ideas and general ideas. The thoughts are also of two general classes; those pertaining to contingent truth and those pertaining to necessary truth. In contingent truth, we have facts, or immediate judgments, and general truths including laws and causes, derived from particular facts; in necessary truth we have axioms, or self-evident truths, and the truths derived from them by reasoning, called theorems."
- 61. In inviting you to consider the processes of reasoning, we are irresistibly reminded of the old story of one of Moliere's plays in which one of the characters expresses surprise on learning that he "had been talking prose for forty years without knowing it." As Jevons says in mentioning this: "Ninety-nine people out of a hundred might be equally surprised on hearing that they had been converting propositions, syllogizing, falling into paralogisms, framing hypotheses and making classifications with genera and species. If asked whether they were logicians, they would probably answer, No! They would be partly right; for I believe that a large number even of educated persons have no clear idea of what logic is. Yet, in a certain way, every one must have been a logician since he began to speak." So, in asking you to consider the processes of reasoning we are not assuming that you never have reasoned—on the contrary we are fully aware that you in connection with every other person, have reasoned all your mature life. That is not the question. While everyone reasons, the fact is equally true that the majority of persons reason incorrectly. Many persons reason along lines far from correct and scientific, and suffer therefor and thereby. Some writers have claimed that the majority of persons are incapable of even fairly correct reasoning, pointing to the absurd ideas entertained by the masses of people as a proof of the statement. These writers are probably a little radical in their views and statements, but one is often struck with wonder at the evidences of incapacity for interpreting facts and impressions on the part of the general public. The masses of people accept the most absurd ideas as truth, providing they are gravely asserted by some one claiming authority. The most illogical ideas are accepted without dispute or examination, providing they are stated solemnly and authoritatively. Particularly in the respective fields of religion and politics do we find this blind acceptance of illogical ideas by the multitude. Mere assertion by the leaders seems sufficient for the multitude of followers to acquiesce. In order to reason correctly it is not merely necessary to have a good intellect. An athlete may have the proper proportions, good
- 62. framework, and symmetrical muscles, but he cannot expect to cope with others of his kind unless he has learned to develop those muscles and to use them to the best advantage. And, in the same way, the man who wishes to reason correctly must develop his intellectual faculties and must also learn the art of using them to the best advantage. Otherwise he will waste his mental energy and will be placed at a disadvantage when confronted with a trained logician in argument or debate. One who has witnessed a debate or argument between two men equally strong intellectually, one of whom is a trained logician and the other lacking this advantage, will never forget the impression produced upon him by the unequal struggle. The conflict is like that of a powerful wrestler, untrained in the little tricks and turns of the science, in the various principles of applying force in a certain way at a certain time, at a certain place, with a trained and experienced wrestler. Or of a conflict between a muscular giant untrained in the art of boxing, when confronted with a trained and experienced exponent of "the manly art." The result of any such conflict is assured in advance. Therefore, everyone should refuse to rest content without a knowledge of the art of reasoning correctly, for otherwise he places himself under a heavy handicap in the race for success, and allows others, perhaps less well-equipped mentally, to have a decided advantage over him. Jevons says in this connection: "To be a good logician is, however, far more valuable than to be a good athlete; because logic teaches us to reason well, and reasoning gives us knowledge, and knowledge, as Lord Bacon said, is power. As athletes, men cannot for a moment compare with horses or tigers or monkeys. Yet, with the power of knowledge, men tame horses and shoot tigers and despise monkeys. The weakest framework with the most logical mind will conquer in the end, because it is easy to foresee the future, to calculate the result of actions, to avoid mistakes which might be fatal, and to discover the means of doing things which seemed impossible. If such little creatures as ants had better brains than men, they would either destroy men or make them into slaves. It is true that we cannot use our eyes and ears without getting some
- 63. kind of knowledge, and the brute animals can do the same. But what gives power is the deeper knowledge called Science. People may see, and hear, and feel all their lives without really learning the nature of things they see. But reason is the mind's eye, and enables us to see why things are, and when and how events may be made to happen or not to happen. The logician endeavors to learn exactly what this reason is which makes the power of men. We all, as I have said, must reason well or ill, but logic is the science of reasoning and enables us to distinguish between the good reasoning which leads to truth, and the bad reasoning which every day betrays people into error and misfortune." In this volume we hope to be able to point out the methods and principles of correctly using the reasoning faculties of the mind, in a plain, simple manner, devoid of useless technicalities and academic discussion. We shall adhere, in the main, to the principles established by the best of the authorities of the old school of psychology, blending the same with those advanced by the best authorities of the New Psychology. No attempt to make of this book a school text-book shall be made, for our sole object and aim is to bring this important subject before the general public composed of people who have neither the time nor inclination to indulge in technical discussion nor academic hair-splitting, but who desire to understand the underlying working principles of the Laws of Reasoning.
- 64. CHAPTER II. THE PROCESS OF REASONING The processes of Reasoning may be said to comprise four general stages or steps, as follows: I. Abstraction, by which is meant the process of drawing off and setting aside from an object, person or thing, a quality or attribute, and making of it a distinct object of thought. For instance, if I perceive in a lion the quality of strength, and am able to think of this quality abstractly and independently of the animal—if the term strength has an actual mental meaning to me, independent of the lion—then I have abstracted that quality; the thinking thereof is an act of abstraction; and the thought-idea itself is an abstract idea. Some writers hold that these abstract ideas are realities, and "not mere figments of fancy." As Brooks says: "The rose dies, but my idea of its color and fragrance remains." Other authorities regard Abstraction as but an act of attention concentrated upon but the particular quality to the exclusion of others, and that the abstract idea has no existence apart from the general idea of the object in which it is included. Sir William Hamilton says: "We can rivet our attention on some particular mode of a thing, as its smell, its color, its figure, its size, etc., and abstract it from the others. This may be called Modal Abstraction. The abstraction we have now been considering is performed on individual objects, and is consequently particular. There is nothing necessarily connected with generalization in abstraction; generalization is indeed dependent on abstraction, which it supposes; but abstraction does not involve generalization." II. Generalization, by which is meant the process of forming Concepts or General Ideas. It acts in the direction of apprehending the common qualities of objects, persons and things, and combining and uniting them into a single notion or conception which will
- 65. comprehend and include them all. A General Idea or Concept differs from a particular idea in that it includes within itself the qualities of the particular and other particulars, and accordingly may be applied to any one of these particulars as well as to the general class. For instance, one may have a particular idea of some particular horse, which applies only to that particular horse. He may also have a General Idea of horse, in the generic or class sense, which idea applies not only to the general class of horse but also to each and every horse which is included in that class. The expression of Generalization or Conception is called a Concept. III. Judgment, by which is meant the process of comparing two objects, persons or things, one with another, and thus perceiving their agreement or disagreement. Thus we may compare the two concepts horse and animal, and perceiving a certain agreement between them we form the judgment that: "A horse is an animal;" or comparing horse and cow, and perceiving their disagreement, we form the judgment: "A horse is not a cow." The expression of a judgment is called a Proposition. IV. Reasoning, by which is meant the process of comparing two objects, persons or things, through their relation to a third object, person or thing. Thus we may reason (a) that all mammals are animals; (b) that a horse is a mammal; (c) that, therefore, a horse is an animal; the result of the reasoning being the statement that: "A horse is an animal." The most fundamental principle of reasoning, therefore, consists in the comparing of two objects of thought through and by means of their relation to a third object. The natural form of expression of this process of Reasoning is called a Syllogism. It will be seen that these four processes of reasoning necessitate the employment of the processes of Analysis and Synthesis, respectively. Analysis means a separating of an object of thought into its constituent parts, qualities or relations. Synthesis means the combining of the qualities, parts or relations of an object of thought into a composite whole. These two processes are found in all processes of Reasoning. Abstraction is principally analytic;
- 66. Generalization or Conception chiefly synthetic; Judgment is either or both analytic or synthetic; Reasoning is either a synthesis of particulars in Induction, or an evolution of the particular from the general in Deduction. There are two great classes of Reasoning; viz., (1) Inductive Reasoning, or the inference of general truths from particular truths; and (2) Deductive Reasoning, or the inference of particular truths from general truths. Inductive Reasoning proceeds by discovering a general truth from particular truths. For instance, from the particular truths that individual men die we discover the general truth that "All men must die;" or from observing that in all observed instances ice melts at a certain temperature, we may infer that "All ice melts at a certain temperature." Inductive Reasoning proceeds from the known to the unknown. It is essentially a synthetic process. It seeks to discover general laws from particular facts. Deductive Reasoning proceeds by discovering particular truths from general truths. Thus we reason that as all men die, John Smith, being a man, must die; or, that as all ice melts at a certain temperature, it follows that the particular piece of ice under consideration will melt at that certain temperature. Deductive Reasoning is therefore seen to be essentially an analytical process. Mills says of Inductive Reasoning: "The inductive method of the ancients consisted in ascribing the character of general truths to all propositions which are true in all the instances of which we have knowledge. Bacon exposed the insufficiency of this method, and physical investigation has now far outgrown the Baconian conception.... Induction, then, is that operation by which we infer that what we know to be true in a particular case or cases, will be true in all cases which resemble the former in certain assignable respects. In other words, induction is the process by which we conclude that what is true of certain individuals of a class is true of the whole class, or that what is true at certain times will be true in similar circumstances at all times."
- 67. Regarding Deductive Reasoning, a writer says: "Deductive Reasoning is that process of reasoning by which we arrive at the necessary consequences, starting from admitted or established premises." Brooks says: "The general truths from which we reason to particulars are derived from several distinct sources. Some are intuitive, as the axioms of mathematics or logic. Some of them are derived from induction.... Some of them are merely hypothetical, as in the investigation of the physical sciences. Many of the hypotheses and theories of the physical sciences are used as general truth for deductive reasoning; as the theory of gravitation, the theory of light; etc. Reasoning from the theory of universal gravitation, Leverrier discovered the position of a new planet in the heavens before it had been discovered by human eyes." Halleck points out the interdependence of Inductive and Deductive Reasoning in the following words: "Man has to find out through his own experience, or that of others, the major premises from which he argues or draws his conclusions. By induction we examine what seems to us a sufficient number of individual cases. We then conclude that the rest of these cases, which we have not examined, will obey the same general laws.... The premise, 'All cows chew the cud,' was laid down after a certain number of cows had been examined. If we were to see a cow twenty years hence, we should expect that she chewed her cud.... After Induction has classified certain phenomena and thus given us a major premise, we proceed deductively to apply the inference to any new specimen that can be shown to belong to that class." The several steps of Deductive Reasoning shall now be considered in turn as we proceed.
- 68. CHAPTER III. THE CONCEPT In considering the process of thinking, we must classify the several steps or stages of thought that we may examine each in detail for the purpose of comprehending them combined as a whole. In actual thinking these several steps or stages are not clearly separated in consciousness, so that each stands out clear and distinct from the preceding and succeeding steps or stages, but, on the contrary, they blend and shade into each other so that it is often difficult to draw a clear dividing line. The first step or stage in the process of thinking is that which is called a concept. A concept is a mental representation of anything. Prof. Wm. James says: "The function by which we mark off, discriminate, draw a line around, and identify a numerically distinct subject of discourse is called conception." There are five stages or steps in each concept, as follows: I. Presentation. Before a concept may be formed there must first be a presentation of the material from which the concept is to be formed. If we wish to form the concept, animal, we must first have perceived an animal, probably several kinds of animals—horses, dogs, cats, cows, pigs, lions, tigers, etc. We must also have received impressions from the sight of these animals which may be reproduced by the memory—represented to the mind. In order that we may have a full concept of animal we should have perceived every kind of animal, for otherwise there would be some elements of the full concept lacking. Accordingly it is practically impossible to have a full concept of anything. The greater the opportunities for perception the greater will be the opportunity for conception. In other books of this series we have spoken of the value and importance of the attention and of clear and full perception. Without
- 69. an active employment of the attention, it is impossible to receive a clear perception of anything; and unless the perception has been clear, it is impossible for the mind to form a clear concept of the thing perceived. As Sir Wm. Hamilton has said: "An act of attention, that is an act of concentration, seems thus necessary to every exertion of consciousness, as a certain contraction of the pupil is requisite to every exertion of vision.... Attention, then, is to consciousness what the contraction of the pupil is to sight, or to the eye of the mind what the microscope or telescope is to the bodily eye.... It constitutes the half of all intellectual power." And Sir B. Brodie said: "It is attention, much more than in the abstract power of reasoning, which constitutes the vast difference which exists between minds of different individuals." And as Dr. Beattie says: "The force with which anything strikes the mind is generally in proportion to the degree of attention bestowed upon it." II. Comparison. Following the stage of Presentation is the stage of Comparison. We separate our general concept of animal into a number of sub-concepts, or concepts of various kinds of animals. We compare the pig with the goat, the cow with the horse, in fact each animal with all other animals known to us. By this process we distinguish the points of resemblance and the points of difference. We perceive that the wolf resembles the dog to a considerable degree; that it has some points of resemblance to the fox; and a still less distinct resemblance to the bear; also that it differs materially from the horse, the cow or the elephant. We also learn that there are various kinds of wolves, all bearing a great resemblance to each other, and yet having marked points of difference. The closer we observe the various individuals among the wolves, the more points of difference do we find. The faculty of Comparison evidences itself in inductive reasoning; ability and disposition to analyze, classify, compare, etc. Fowler says that those in whom it is largely developed "Reason clearly and correctly from conclusions and scientific facts up to the laws which govern them; discern the known from the unknown; detect error by its incongruity with facts; have an excellent talent for comparing, explaining, expounding, criticising,
- 70. exposing, etc." Prof. William James says: "Any personal or practical interest in the results to be obtained by distinguishing, makes one's wits amazingly sharp to detect differences. And long training and practice in distinguishing has the same effect as personal interest. Both of these agencies give to small amounts of objective difference the same effectiveness upon the mind that, under other circumstances, only large ones would make." III. Abstraction. Following the stage of Comparison is that of Abstraction. The term "Abstraction" as used in psychology means: "The act or process of separating from the numerous qualities inherent in any object, the particular one which we wish to make the subject of observation and reflection. Or, the act of withdrawing the consciousness from a number of objects with a view to concentrate it on some particular one. The negative act of which Attention is the positive." To abstract is "to separate or set apart." In the process of Abstraction in our consideration of animals, after having recognized the various points of difference and resemblance between the various species and individuals, we proceed to consider some special quality of animals, and, in doing so, we abstract, set aside, or separate the particular quality which we wish to consider. If we wish to consider the size of animals, we abstract the quality of size from the other qualities, and consider animals with reference to size alone. Thus we consider the various degrees of size of the various animals, classifying them accordingly. In the same way we may abstract the quality of shape, color or habits, respectively, setting aside this quality for special observation and classification. If we wish to study, examine or consider certain qualities in a thing we abstract that particular quality from the other qualities of the thing; or we abstract the other qualities until nothing is left but the particular quality under consideration. In examining or considering a class or number of things, we first abstract the qualities possessed in common by the class or number of things; and also abstract or set aside the qualities not common to them. For instance; in considering classes of animals, we abstract the combined quality of milk-giving and pouch-possessing which is
- 71. possessed in common by a number of animals; then we group these several animals in a class which we name the Marsupialia, of which the opossum and kangaroo are members. In these animals the young are brought forth in an imperfect condition, undeveloped in size and condition, and are then kept in the pouch and nourished until they are able to care for themselves. Likewise, we may abstract the idea of the placenta, the appendage which connects the young unborn animal with the mother, and by means of which the fœtus is nourished. The animals distinguished by this quality are grouped together as the Placental Mammals. The Placental Mammals are divided into various groups, by an Abstraction of qualities or class resemblance or difference, as follows: The Edentata, or toothless creatures, such as the sloths, ant-eaters, armadillos, etc.; the Sirenia, so-named from their fancied resemblance to the fabled "sirens," among which class are the sea-cows, manatees, dugongs, etc.; the Cetacea, or whale family, which although fish-like in appearance, are really mammals, giving birth to living young which they nourish with breast-milk, among which are the whales, porpoises, dolphins, etc.; the Ungulata, or hoofed animals, such as the horse, the tapir, the rhinoceros, the swine, the hippopotamus, the camel, the deer, the sheep, the cow, etc.; the Hyracoidea, having teeth resembling both the hoofed animals and the gnawing animals, of which the coney or rock-rabbit is the principal example; the Proboscidea, or trunked animals, which family is represented by the various families of elephants; the Carnivora, or flesh-eaters, represented by various sub-families and species; the Rodentia, or gnawers; the Insectivora, or insect feeders; the Cheiroptera, or finger-winged; the Lemuroidea, or lemurs, having the general appearance of the monkey, but also the long bushy tail of the fox; the Primates, including the monkeys, baboons, man-apes, gibbons, gorillas, chimpanzees, orang-outangs and Man. In all of these cases you will see that each class or general family possesses a certain common quality which gives it its classification, and which quality is the subject of the Abstraction in considering the particular group of animals. Further and closer Abstraction divides
- 72. these classes into sub-classes; for instance, the family or class of the Carnivora, or flesh-eaters, may be divided by further Abstraction into the classes of seals, bears, weasels, wolves, dogs, lions, tigers, leopards, etc. In this process, we must first make the more general Abstraction of the wolf and similar animals into the dog-family; and the lion, tiger and similar forms into the cat-family. Halleck says of Abstraction: "In the process of Abstraction, we draw our attention away from a mass of confusing details, unimportant at the time, and attend only to qualities common to the class. Abstraction is little else than centering the power of attention on some qualities to the exclusion of others." IV. Generalization. Arising from the stage of Abstraction is the stage of Generalization. Generalization is: "The act or process of generalizing or making general; bringing several objects agreeing in some point under a common or general name, head or class; an extending from particulars to generals; reducing or arranging in a genus; bringing a particular fact or series of facts into a relation with a wider circle of facts." As Bolingbroke says: "The mind, therefore, makes its utmost endeavors to generalize its ideas, beginning early with such as are most familiar and coming in time to those which are less so." Under the head of Abstraction we have seen that through Abstraction we may Generalize the various species into the various families, and thus, in turn, into the various sub-families. Following the same process we may narrow down the sub-families into species composed of various individuals; or into greater and still greater families or groups. Generalization is really the act of Classification, or forming into classes all things having certain qualities or properties in common. The corollary is that all things in a certain generalized class must possess the particular quality or property common to the class. Thus we know that all animals in the class of the Carnivora must eat flesh; and that all Mammals possess breasts from which they feed their young. As Halleck says: "We put all objects having like qualities into a certain genus, or class. When the objects are in that class, we know that certain qualities will have a general application to them all."
- 73. Welcome to our website – the perfect destination for book lovers and knowledge seekers. We believe that every book holds a new world, offering opportunities for learning, discovery, and personal growth. That’s why we are dedicated to bringing you a diverse collection of books, ranging from classic literature and specialized publications to self-development guides and children's books. More than just a book-buying platform, we strive to be a bridge connecting you with timeless cultural and intellectual values. With an elegant, user-friendly interface and a smart search system, you can quickly find the books that best suit your interests. Additionally, our special promotions and home delivery services help you save time and fully enjoy the joy of reading. Join us on a journey of knowledge exploration, passion nurturing, and personal growth every day! ebookbell.com