Spark Based Distributed Deep Learning Framework For Big Data Applications
4 likes756 views

The document outlines a proposed spark-based distributed deep learning framework aimed at big data applications, detailing the challenges in distributed computing and the advantages of using Apache Spark for machine learning tasks. It highlights the importance of deep learning in big data for semantic indexing and efficient information retrieval, and describes the implementation of the system utilizing distributed stochastic gradient descent. Results indicate satisfactory performance in time and accuracy, with potential for future enhancements.




















![Traditional methods for representing word vectors
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 … ]
[0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 … ]
[government debt problems turning into banking crisis as has happened]
[saying that Europe needs unified banking regulation to replace the old]
Motel Say Good Cat Main
Snake Award Business Cola Twitter
Google Save Money Florida Post
Great Success Today Amazon Hotel
…. …. …. …. ….
Keep word by its context](https://image.slidesharecdn.com/mymastersthesis-170110033545/85/Spark-Based-Distributed-Deep-Learning-Framework-For-Big-Data-Applications-21-320.jpg)




















![Traditional methods for representing word vectors
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 … ]
[0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 … ]
[government debt problems turning into banking crisis as has happened]
[saying that Europe needs unified banking regulation to replace the old]
Motel Say Good Cat Main
Snake Award Business Cola Twitter
Google Save Money Florida Post
Great Success Today Amazon Hotel
…. …. …. …. ….
Keep word by its context](https://image.slidesharecdn.com/mymastersthesis-170110033545/85/Spark-Based-Distributed-Deep-Learning-Framework-For-Big-Data-Applications-43-320.jpg)












Spark Based Distributed Deep Learning Framework For Big Data Applications
- 1. Thesis Topic: Spark based Distributed Deep Learning Framework for Big Data Applications SMCC Lab Social Media Cloud Computing Research Center Prof Lee Han-Ku
- 2. III Challenges in Distributed Computing IV Apache Spark V Deep Learning in Big Data VI Proposed System I Motivation II Introduction VII Experiments and Results Conclusion Outline
- 3. Motivation
- 4. Problem
- 6. Wait a minute!? D << N D (dimension/number of features) = 1,300 N (size of training data) = 5,000,000
- 7. What if : Feature size is almost as huge as dataset D ~ N D = 1,134,000 N = 5,000,000
- 8. Further solution Model Parallelism CPU 1 CPU 2 CPU 3 CPU 4
- 9. Computer Vision: Face Recognition Finance: Fraud Detection … Medicine: Medical Diagnosis … Data Mining: Prediction, Classification … Industry: Process Control … Operational Analysis: Cash Flow Forecasting … Sales and Marketing: Sales Forecasting … Science: Pattern Recognition … … Introduction Applications of Deep Learning
- 10. Map ping Mountain River City Sun Blue Cloud Input Layer Output LayerHidden Layers Some Examples
- 11. Map ping Input Layer Output Layer The Face Successfully Recognized Hidden Layers Some Examples
- 12. Map ping Hidden Layers Input Layer Output Layer love Romeo kiss hugs ………… Happy End Romance Detective Historical Scientific Technical Some Examples
- 14. Challenges Distributed Computing Complexities Heterogeneity Openness Security Scalability Fault Handling Concurrency Transparency
- 15. Apache Spark Most Machine Learning algorithms are inherently iterative because each iteration can improve the results With disk based approach each iteration’s output is written to disk which makes reading back slow In Spark, the output can be cached in memory which makes reading very fast (distributed cache) Hadoop execution flow Spark execution flow
- 16. Initially started at UC Berkeley in 2009 Fast and general purpose cluster computing system 10x (on disk) – 100x (in-memory) faster than Hadoop Most popular for running Iterative Machine Learning Algorithms Provides high level API in Java Scala Python R Combine SQL, streaming, and complex analytics. Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3. Apache Spark
- 17. Spark Stack Spark SQL For SQL and unstructured data processing Spark Streaming Stream processing of live data streams MLLib Machine Learning Algorithms GraphX Graph Processing Apache Spark
- 18. "Deep learning" is the new big trend in Machine Learning. It promises general, powerful, and fast machine learning, moving us one step closer to AI. An algorithm is deep if the input is passed through several non-linear functions before being output. Most modern learning algorithms (including Decision Trees and SVMs and Naive Bayes) are "shallow". Deep Learning is about learning multiple levels of representation and abstraction that help to make sense of data such as images, sound, and text. Deep Learning in Big Data
- 19. A key task associated with Big Data Analytics is information retrieval Instead of using raw input for data indexing, Deep Learning can be utilized to generate high-level abstract data representations which will be used for semantic indexing. These representations can reveal complex associations and factors (especially if raw input is Big Data), leading to semantic knowledge and understanding, for example by making search engines work more quickly and efficiently. Deep Learning aids in providing a semantic and relational understanding of the data. Deep Learning in Big Data Semantic Indexing
- 20. The learnt complex data representations contain semantic and relational information instead of just raw bit data, they can directly be used for semantic indexing when each data point is presented by a vector representation, allowing for a vector-based comparison which is more efficient than comparing instances based directly on raw data. The data instances that have similar vector representations are likely to have similar semantic meaning. Thus, using vector representations of complex high-level data abstractions for indexing the data makes semantic indexing feasible Deep Learning in Big Data
- 21. Traditional methods for representing word vectors [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 … ] [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 … ] [government debt problems turning into banking crisis as has happened] [saying that Europe needs unified banking regulation to replace the old] Motel Say Good Cat Main Snake Award Business Cola Twitter Google Save Money Florida Post Great Success Today Amazon Hotel …. …. …. …. …. Keep word by its context
- 22. Word2Vec (distributed representation of words) Deep Learning in Big Data •The cake was just good (trained tweet) Training data •The cake was just great (new unseen tweet)Test data
- 23. Deep Learning in Big Data Great ( 0.938401) Awesome ( 0.8912334 ) Well ( 0.8242320 ) Fine ( 0.7943241 ) Outstanding ( 0.71239 ) Normal ( 0.640323 ) …. ( ….. ) Good ( 1.0 ) They are close in vector space Word2Vec (distributed representation of words) •The cake was just good (trained tweet) Training data •The cake was just great (new unseen tweet)Test data
- 24. Proposed System should deal with: Concurrency Asynchrony Distributed Computing Parallelism model parallelism data parallelism Proposed System
- 25. 1 2 3 4 5 6 Data Shard 1 Data Shard 1 Data Shard 1 Model Replicas Parameter Servers Master Spark Driver HDFS data nodes Architecture
- 26. Domain Entities Master Start Done JobDone DataShard ReadyToProcess FetchParameters ParameterShard ParameterRequest LatestParameters NeuralNetworkLayer DoneFetchingParameters Gradient ForwardPass BackwardPass ChildLayer
- 27. Backward Pass Child Layer Gradient Fetching Parameters Forward Pass Ready To Process MASTER Deep Layer Worker Parameter Shard Worker Job Done Start Data Shard Worker Fetch Parameters Parameter Request Latest Parameters Output Proposed System Class Hierarchy Class Hierarchy
- 28. Data Shards (HDFS) X1 𝑊11 𝑊12 𝑊12 𝑊14 𝑊15 𝑊16 … X2 𝑊21 𝑊22 … … 𝑊26 … X3 𝑊31 𝑊32 … … 𝑊36 … … … … … … … … … h1 𝑊11 𝑊12 𝑊12 𝑊14 𝑊15 𝑊16 … h2 𝑊21 𝑊22 … … 𝑊26 … h3 𝑊31 𝑊32 … … 𝑊36 … … … … … … … … … Corresponding Model Replica Input-to-hidden parameters Hidden-to-output parameters Data Shards
- 29. W W W W W W W W W W W W W W W W W W W W W W W W W W W W W . . . W W X X X X X X X X X X X X X X X X X . . . X X Parameter Server
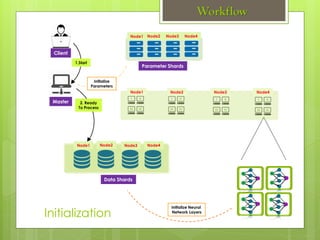
- 30. 1.Start Master Client Data Shards (HDFS) Parameter Shards (HDFS) Initialize Parameters Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 Initialization Workflow
- 31. Master Client Data Shards Parameter Shards 2. Ready To Process Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 Initialization Initialize Neural Network Layers Initialize Parameters 1.Start Workflow
- 32. Master Client Data Shards Parameter Shards 2.Ready To Process Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 5.Parameter Request 4.FetchParams 1.Start Workflow
- 33. Master Client Data Shards Parameter Shards 2.Ready To Process Initial Parameters Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 5.Parameter Request 4.FetchParams 6.Latest Parameters 1.Start Workflow
- 34. Master Client Data Shards Parameter Shards 2.Ready To Process 7.DoneFetchingParams Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 5.Parameter Request 6.Latest Parameters 1.Start Workflow
- 35. Master Client Data Shards Parameter Shards 2.Ready To Process 7.DoneFetchingParams Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 8.Forward 5.Parameter Request 6.Latest Parameters Training Data Examples One by one 1.Start Workflow
- 36. 1.Start Master Client Data Shards Parameter Shards 2.Ready To Process Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 9.Gradient 10.Latest Parameters 8.Forward 7.DoneFetchingParams 7.Backward 7.Backward Logging 11. Output Workflow
- 37. Master Client Data Shards Parameter Shards Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 2.Gradient 5.Backward 5.Backward Training(Learning) Phase 1.Forward 4.DoneFetchingParams 3.Latest Parameters Logging 6. Output Workflow
- 38. 7.JobDone Master Client Data Shards Parameter Shards 6.Done Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 Node1 Node2 Node3 Node4 3.Backward 3.Backward Training is Done 1.Gradient 2.Latest Parameters 5.DoneFetchingParams Workflow Logging 4. Output
- 39. Model Replica 1 Model Replica 2 Model Replica 3 Model Replica 4 Model Replica 5 Model Replica 6 Corresponding Parameter Shard 𝑥0 𝑥1 𝑥2 𝑥3 𝑥4 𝑥0𝑥1𝑥2𝑥3 𝑥4 Learning Process
- 40. Cluster Nodes Single Node 3D view of the Model (Convergence point is the global minimum) Global minimum is the target
- 41. procedure STARTASYNCHRONOUSLYFETCHINGPARAMETERS(parameters) parameters ← GETPARAMETERSFROMPARAMSERVER() procedure STARTASYNCHRONOUSLYPUSHINGGRADIENTS(accruedgradients) SENDGRADIENTSTOPARAMSERVER(accruedgradients) accruedgradients ← 0 main global parameters, accruedgradients step ← 0 accruedgradients ← 0 while true do if (step mod 𝑁𝑓𝑒𝑡𝑐ℎ) == 0 then STARTASYNCHRONOUSLYFETCHINGPARAMETERS(parameters) data ← GETNEXTMINIBATCH() gradient ← COMPUTEGRADIENT(parameters, data) accruedgradients ← accruedgradients + gradient parameters ← parameters − α ∗ gradient if (step mod npush) == 0 then STARTASYNCHRONOUSLYPUSHINGGRADIENTS(accruedgradients) step ← step + 1 SGD Algorithm
- 43. Traditional methods for representing word vectors [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 … ] [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 … ] [government debt problems turning into banking crisis as has happened] [saying that Europe needs unified banking regulation to replace the old] Motel Say Good Cat Main Snake Award Business Cola Twitter Google Save Money Florida Post Great Success Today Amazon Hotel …. …. …. …. …. Keep word by its context
- 44. Deep Learning in Big Data Great ( 0.938401) Awesome ( 0.8912334 ) Well ( 0.8242320 ) Fine ( 0.7943241 ) Outstanding ( 0.71239 ) Normal ( 0.640323 ) …. ( ….. ) Good ( 1.0 ) They are close in vector space Word2Vec (distributed representation of words) •The cake was just good (trained tweet) Training data •The cake was just great (new unseen tweet)Test data
- 45. •Training Data Tokenizer •Tokenized Data Count Vector •Word2Vec (distributed represent) Output •Nonlinear classifier Deep Net Word2Vec - Deep Net
- 48. Assessment Cluster Specification (10 nodes) CPU Intel Xeon 4 Core DP E5506 2.13GHz *2E RAM 4GB Registered ECC DDR * 4EA HDD 1TB SATA-2 7,200 RPM OS Ubuntu 12.04 LTS 64bit Spark Spark-1.6.0 Hadoop(HDFS) Hadoop 2.6.0 Java Oracle JDK 1.8.0_61 64 bit Scala Scala-12.9.1 Python Python-2.7.9 Cluster Specs
- 49. 0 5 10 15 20 25 30 2 nodes 4 nodes 6 nodes 8 nodes 10 nodes Time Performance vs. Number of nodes RunTime(mins) Number of Nodes in Cluster Performance
- 51. N p/n Sample from positive and negative tweets corpus 1 0 Very sad about Iran. 2 0 where is my picture i feel naked 3 1 the cake was just great! 4 1 had a WONDERFUL day G_D is GREAT!!!!! 5 1 I have passed 70-542 exam today 6 0 #3turnoffwords this shit sucks 7 1 @alexrauchman I am happy you are staying around here. 8 1 praise God for this beautiful day!!! 9 0 probably guna get off soon since no one is talkin no more 10 0 i still Feel like a Douchebag 11 1 Just another day in paradise. ;) 12 1 No no no. Tonight goes on the books as the worst SYTYCD results show. 13 0 i couldnt even have one fairytale night 14 0 AFI are not at reading till sunday this sucks !! Samples
- 52. Spark Metrics
- 53. Tweet Statistics
- 54. The main goal of this work was to build Distributed Deep Learning Framework which is targeted for Big Data applications. We managed to implement the proposed system on top of Apache Spark, well- known general purpose data processing engine. Deep network training of proposed system depends on well-known distributed Stochastic Gradient Descent method, namely Downpour SGD. The system can be used in building Big Data application or can be integrated to Big Data analytics pipeline as it showed satisfactory performance in terms of both time and accuracy. However, there are a lot of room for further enhancement and new features. Conclusion
- 55. Thank You For Your Attention