Spark Interview Questions and Answers | Apache Spark Interview Questions | Spark Tutorial | Edureka
14 likes2,197 views

The document provides an overview of Apache Spark, detailing its features, advantages over MapReduce, and its components. It discusses concepts such as RDDs (Resilient Distributed Datasets), Spark's streaming capabilities, and integration with Hadoop, along with interview questions and answers related to these topics. Key concepts highlighted include Spark's speed, real-time processing, and memory management while also addressing limitations and use cases.



























![www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING
Spark Interview Questions & Answers
How do we create RDDs in Spark?13
1
2
By parallelizing a collection in your Driver program, this makes use of
SparkContext’s ‘parallelize’
method val DataArray = Array(2,4,6,8,10)
val DataRDD = sc.parallelize (DataArray)
By loading an external dataset from external storage like HDFS,
HBase, shared file system
scala> val distFile = sc.textFile("data.txt")
distFile: org.apache.spark.rdd.RDD [String] = data.txt
MapPartitionsRDD [10] at textFile at <console>:26](https://image.slidesharecdn.com/sparkinterviewquestions-edureka-170717114457/85/Spark-Interview-Questions-and-Answers-Apache-Spark-Interview-Questions-Spark-Tutorial-Edureka-28-320.jpg)











![www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING
Spark Interview Questions & Answers
What do you understand by Pair RDD?19
Special operations can be performed on RDDs in Spark using key/value pairs and such RDDs are referred to as Pair RDDs
Pair RDDs allow users to access each key in parallel
Apache defines PairRDD functions class as:
class PairRDDFunctions[K, V] extends Logging with HadoopMapReduceUtil with Serializable](https://image.slidesharecdn.com/sparkinterviewquestions-edureka-170717114457/85/Spark-Interview-Questions-and-Answers-Apache-Spark-Interview-Questions-Spark-Tutorial-Edureka-40-320.jpg)
































































Spark Interview Questions and Answers | Apache Spark Interview Questions | Spark Tutorial | Edureka
- 2. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Agenda 1. Basic Questions 2. Spark Core Questions 3. Spark Streaming Questions 4. Spark GraphX Questions 5. Spark MLlib Questions 6. Spark SQL Questions
- 3. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is Apache Spark?1
- 4. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is Apache Spark?1 Apache Spark is an open-source cluster computing framework for real-time processing 1 Thriving open-source community & the most active Apache project currently 2 Apache Spark is an open-source cluster computing framework for real-time processing 3
- 5. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Compare MapReduce and Spark.2
- 6. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Compare MapReduce and Spark.2 Properties Spark MapReduce Difficulty Spark is simpler to program & doesn’t require any abstractions Difficult to program with abstractions Interactivity Spark provides an interactive mode No inbuilt interactive mode except for Pig & Hive Streaming Allows real-time streaming of data & processing Perform batch processing on historical data Latency Ensures lower latency computations by caching the partial results across its distributed memory MapReduce is completely disk-oriented Speed Spark is 100 times faster than Hadoop MapReduce as it stores the data in memory, by placing it in RDD MapReduce is slower than Spark
- 7. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Explain key features of Spark.3
- 8. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Explain key features of Spark.3 S p e e d & P e r f o r m a n c e P o l y g l o t M u l t i p l e F o r m a t s L a z y E v a l u a t i o n 01 02 03 04
- 9. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Explain key features of Spark.4 H a d o o p I n t e g r a t i o n R e a l T i m e C o m p u t a t i o n M a c h i n e L e a r n i n g S p a r k G r a p h X 05 06 07 08
- 10. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is YARN? Do you need to install Spark on all nodes of YARN cluster? 5
- 11. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is YARN? Do you need to install Spark on all nodes of YARN cluster? 5 Spark StreamingCSV Sequence File Avro Parquet HDFS Spark YARN MapReduce Storage Sources Input Data Resource Allocation Optional Processing Input Data Output Data • YARN provides a central resource management platform to deliver scalable operations across the cluster • YARN is a distributed container manager, whereas Spark is a data processing tool
- 12. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What file systems does Spark support?6
- 13. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What file systems does Spark support?6 The following three file systems are supported by Spark: HDFS Amazon S3 Local File System
- 14. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Illustrate some limitations of using Spark.7
- 15. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Illustrate some limitations of using Spark.7 Spark utilizes more storage space compared to Hadoop Developers need to be careful while running app in Spark Work must be distributed over multiple clusters Spark’s “in-memory” capability can become a bottleneck when it comes to cost -efficient processing of big data. Spark consumes a huge amount of data when compared to Hadoop
- 16. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers List some use cases where Spark outperforms Hadoop in processing.8
- 17. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers List some use cases where Spark outperforms Hadoop in processing.8 Real Time Processing: Spark is preferred over Hadoop for real -time querying of data. 1 Stream Processing: For processing logs and detecting frauds in live streams for alerts, Apache Spark is the best solution. 2 Big Data Processing: Spark runs upto 100 times faster than Hadoop for processing medium and large -sized datasets. 3
- 18. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How Spark uses Akka?9
- 19. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How Spark uses Akka?9 • Spark uses Akka for scheduling • All the workers request for a task to master after registering • The master just assigns the task • Then, Spark uses Akka for messaging between the workers and masters
- 20. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Name the components of Spark Ecosystem?10
- 21. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Name the components of Spark Ecosystem?10 Spark Core Engine Spark SQL Spark Streaming (Streaming) Mlib (Machine Learning) Graph X (Graph Computation) Spark R (R on Spark)
- 22. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How can Spark be used alongside Hadoop?11
- 23. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How can Spark be used alongside Hadoop?11 Using Spark and Hadoop together helps us to leverage Spark’s processing to utilize the best of Hadoop’s HDFS & YARN. Hadoop components can be used alongside Spark: ▪ HDFS ▪ MapReduce ▪ YARN ▪ Batch & Real Time Processing
- 24. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Spark Core
- 25. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Define RDD.12
- 26. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Define RDD.12 • RDD stands for Resilient Distribution Datasets • An RDD is a fault-tolerant collection of operational elements that run in parallel • Partitioned data in RDD is immutable and distributed in nature They perform functions on each file record in HDFS or other storage systems Here, the existing RDDs running parallel with one another Parallelized Collections Hadoop Datasets RDD
- 27. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How do we create RDDs in Spark?13
- 28. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How do we create RDDs in Spark?13 1 2 By parallelizing a collection in your Driver program, this makes use of SparkContext’s ‘parallelize’ method val DataArray = Array(2,4,6,8,10) val DataRDD = sc.parallelize (DataArray) By loading an external dataset from external storage like HDFS, HBase, shared file system scala> val distFile = sc.textFile("data.txt") distFile: org.apache.spark.rdd.RDD [String] = data.txt MapPartitionsRDD [10] at textFile at <console>:26
- 29. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is Executor Memory in a Spark application?14
- 30. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is Executor Memory in a Spark application?14 Spark application has fixed heap size & fixed number of cores for a Spark executor Heap size is the Spark executor memory, which is controlled with the spark.executor.memory property of the --executor-memory flag Every Spark application will have one executor on each worker node The executor memory is basically a measure on how much memory of the worker node will the application utilize
- 31. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Define Partitions in Apache Spark.15
- 32. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Define Partitions in Apache Spark.15 Partition is a smaller and logical division of a large distributed data set Partitioning is the process to derive logical units of data to speed up the processing By default, Spark tries to read data into an RDD from the nodes that are close to it Everything in Spark is a partitioned RDD Help parallelize distributed data processing with minimal network traffic file.xml 1 2 8 M B 128 MB 1 2 8 M B 128 MB
- 33. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What operations does RDD support?16
- 34. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What operations does RDD support?16 Create new RDD from existing RDD like map, reduceByKey and filter. Transformations are executed on demand Actions return final results of RDD computations. Actions triggers execution & carry out all intermediate transformations and return final results Transformations Actions RDD Operations An RDD has distributed a collection of objects RDDs are immutable (Read Only) data structure
- 35. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What do you understand by Transformations in Spark?17
- 36. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What do you understand by Transformations in Spark?17 Transformations are functions applied on RDD, resulting into another RDD Does not execute until an action occurs val rawData=sc.textFile("path to/movies.txt") val moviesData=rawData.map(x=>x.split(" t")) rawData RDD is transformed into moviesData RDD Lazily evaluated Example: map() and filter(), where the former applies the function passed to it on each element of RDD and results into another RDD. The filter() creates a new RDD by selecting elements from current RDD that pass function argument.
- 37. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Define functions of Spark Core.18
- 38. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Define functions of Spark Core.18 ▪ Spark Core is the distributed execution engine for large- scale parallel and distributed data processing ▪ The Java, Scala, and Python APIs offer a platform for distributed ETL application development ▪ Additional libraries, built atop the core allow diverse workloads for streaming, SQL, & machine learning Responsibilities Memory management and fault recovery Scheduling, distributing and monitoring jobs on a cluster Interacting with storage systems
- 39. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What do you understand by Pair RDD?19
- 40. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What do you understand by Pair RDD?19 Special operations can be performed on RDDs in Spark using key/value pairs and such RDDs are referred to as Pair RDDs Pair RDDs allow users to access each key in parallel Apache defines PairRDD functions class as: class PairRDDFunctions[K, V] extends Logging with HadoopMapReduceUtil with Serializable
- 41. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is RDD Lineage?20
- 42. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is RDD Lineage?20 Spark does not support data replication in the memory and thus, if any data is lost, it is rebuild using RDD lineage RDD lineage is a process that reconstructs lost data partitions Best is that RDD always remembers how to build from other datasets
- 43. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is Spark Driver?21
- 44. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is Spark Driver?21 Spark Driver is the program that runs on the master node and declares transformations and actions on data RDDs. Driver in Spark creates SparkContext, connected to a given Spark Master. The driver also delivers the RDD graphs to Master, where the standalone cluster manager runs.
- 45. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Name types of Cluster Managers in Spark?22
- 46. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Name types of Cluster Managers in Spark?22 1 2 3 Yarn: Responsible for resource management in Hadoop. Standalone: A basic manager to set up a cluster. Apache Mesos: Generalized/commonly-used cluster manager, also runs Hadoop MapReduce and other applications.
- 47. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What do you understand by worker node?23
- 48. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What do you understand by worker node?23 • Worker node (slave) refers to any node that can run the application code in a cluster • Master node assigns work and worker node actually performs the assigned tasks • Worker nodes process the data stored on the node and report the resources to the master • Based on the resource availability, the master schedule tasks
- 49. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is a Sparse Vector?24
- 50. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is a Sparse Vector?24 A sparse vector has two parallel arrays; one for indices and the other for values These vectors are used for storing non-zero entries to save space Vectors.sparse(7,Array(0,1,2,3,4,5,6),Array(1650d,50000d,800d,3.0,3.0,2009,95054)) The above sparse vector can be used instead of dense vectors. val myHouse = Vectors.dense(4450d,2600000d,4000d,4.0,4.0,1978.0,95070d,1.0,1.0,1.0,0.0)
- 51. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Spark Streaming
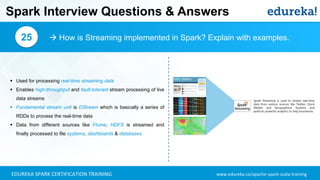
- 52. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How is Streaming implemented in Spark? Explain with examples.25
- 53. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How is Streaming implemented in Spark? Explain with examples.25 ▪ Used for processing real-time streaming data ▪ Enables high-throughput and fault-tolerant stream processing of live data streams ▪ Fundamental stream unit is DStream which is basically a series of RDDs to process the real-time data ▪ Data from different sources like Flume, HDFS is streamed and finally processed to file systems, dashboards & databases
- 54. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is the significance of Sliding Window operation?26
- 55. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is the significance of Sliding Window operation?26 • Spark Streaming also provides windowed computations which allow us to apply transformations over a sliding window of data • Controls transmission of data packets between various computer networks • RDDs are applied over a sliding window of data
- 56. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is a DStream?27
- 57. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is a DStream?27 ▪ Discretized Stream (DStream) is the basic abstraction provided by Spark Streaming ▪ It is a continuous stream of data Data From Time 0 to 1 Data From Time 1 to 2 Data From Time 2 to 3 Data From Time 3 to 4 RDD @ Time 1 RDD @ Time 2 RDD @ Time 3 RDD @ Time 4 DStream Figure: Input data stream divided into discrete chunks of data ▪ It is received from source or from a processed data stream generated by transforming the input stream ▪ Internally, a DStream is represented by a continuous series of RDDs and each RDD contains data from a certain interval
- 58. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Explain Caching in Spark Streaming.28
- 59. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Explain Caching in Spark Streaming.28 ▪ DStreams allow developers to cache/ persist the stream’s data in memory. This is useful if the data in the DStream will be computed multiple times. ▪ This can be done using the persist() method on a DStream. ▪ For input streams that receive data over the network (such as Kafka, Flume, Sockets, etc.), the default persistence level is set to replicate the data to two nodes for fault-tolerance.
- 60. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Spark GraphX
- 61. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Is there an API for implementing graphs in Spark?29
- 62. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Is there an API for implementing graphs in Spark?29 • GraphX is the Spark API for graphs and graph-parallel computation • Extends the Spark RDD with a Resilient Distributed Property Graph • Property graph is a directed multi-graph which can have multiple edges in parallel • Every edge and vertex have user defined properties associated with it • Parallel edges allow multiple relationships between the same vertices • Resilient Distributed Property Graph: a directed multigraph with properties attached to each vertex and edge
- 63. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is PageRank in GraphX?30
- 64. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is PageRank in GraphX?30 PageRank measures the importance of each vertex in a graph, assuming an edge from u to v represents an endorsement of v’s importance by u. For example, if a Twitter user is followed by many others, the user will be ranked highly. GraphX comes with static and dynamic implementations of PageRank Static PageRank runs for a fixed number of iterations While dynamic PageRank runs until the ranks converge GraphOps allows calling these algorithms directly as methods on Graph
- 65. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is lineage graph?31
- 66. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is lineage graph?31 RDDs in Spark, depend on one or more other RDDs Representation of dependencies in between RDDs is known as the lineage graph Lineage graph information is used to compute each RDD on demand If persistent RDD is lost, the lost data can be recovered using the lineage graph information
- 67. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Does Apache Spark provide checkpointing?32
- 68. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Does Apache Spark provide checkpointing?32 • They make it run 24/7 and make it resilient to failures unrelated to the application logic. • Lineage graphs are always useful to recover RDDs from a failure but this is time-consuming • Spark has an API for checkpointing i.e. a REPLICATE flag to persist. • Checkpoints are useful when the lineage graphs are long and have wide dependencies.
- 69. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Spark MLlib
- 70. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How is machine learning implemented in Spark?33
- 71. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How is machine learning implemented in Spark?33 MLlib is scalable machine learning library provided by Spark. Makes ML easy and scalable with algorithms and use cases like clustering, regression filtering, dimensional reduction, etc.
- 72. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What are categories of Machine learning?34
- 73. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What are categories of Machine learning?34 1 2 3 Reinforcement Learning Supervised Learning Unsupervised Learning
- 74. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What are Spark MLlib Tools?35
- 75. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What are Spark MLlib Tools?35 ML Algorithms Featurization Pipelines Persistence Utilities
- 76. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What are some popular algorithms and utilities in Spark MLlib?36
- 77. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What are some popular algorithms and utilities in Spark MLlib?36 The popular algorithms and utilities in Spark MLlib are: • Basic Statistics • Regression • Classification • Recommendation System • Clustering • Dimensionality Reduction • Feature Extraction • Optimization
- 78. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Spark SQL
- 79. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Is there a module to implement SQL in Spark? How does it work?37
- 80. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Is there a module to implement SQL in Spark? How does it work?37 ▪ Spark SQL integrates relational processing with Spark’s functional programming API ▪ Supports querying data either via SQL or via the HQL ▪ Provides support for various data sources and makes it possible to weave SQL queries with code transformations Four libraries of Spark SQL: ▪ Data Source API ▪ DataFrame API ▪ Interpreter & Optimizer ▪ SQL Service
- 81. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is a Parquet file?38
- 82. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What is a Parquet file?38 Parquet is a columnar format file supported by many other data processing systems Spark SQL performs both read and write operations with Parquet file One of the best big data analytics formats The advantages of having a columnar storage are as follows: Columnar storage limits IO operations1 It can fetch specific columns that you need to access 2 Columnar storage consumes less space3 It gives better-summarized data and follows type-specific encoding4
- 83. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers List the functions of Spark SQL.39
- 84. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers List the functions of Spark SQL.39 1 2 3 Providing integration between SQL and regular Python/Java/Scala code, including the ability to join RDDs and SQL tables, expose custom functions in SQL, and more. Loading data from a variety of structured sources Querying data using SQL statements, both inside a Spark program and from external tools that connect to Spark SQL(JDBC/ODBC)
- 85. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What do you understand by Lazy Evaluation?40
- 86. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What do you understand by Lazy Evaluation?40 • When you tell Spark to operate on a given dataset, it heeds the instructions and makes a note of it, • so that it does not forget – but it does nothing, unless asked for the final result • When a transformation like map() is called on an RDD, the operation is not performed immediately • Transformations in Spark are not evaluated till you perform an action • This helps optimize the overall data processing workflow
- 87. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Can you use Spark to access and analyze data stored in Cassandra databases? 41
- 88. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Can you use Spark to access and analyze data stored in Cassandra databases? 41 Yes, it is possible if you use Spark Cassandra Connector. In the setup, a Spark executor will talk to a local Cassandra node and will only query for local data. It makes queries faster by reducing the usage of the network to send data between Spark executors (to process data) and Cassandra nodes (where data lives).
- 89. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How can you minimize data transfers when working with Spark?42
- 90. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How can you minimize data transfers when working with Spark?42 Minimizing data transfers and avoiding shuffling helps write Spark programs that run in a fast and reliable manner There are two ways: Using Broadcast Variable - Broadcast variable enhances the efficiency of joins between small and large RDDs 1 Using Accumulators – Accumulators help update the values of variables in parallel while executing 2 The most common way is to avoid operations ByKey, repartition or any other operations which trigger shuffles
- 91. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What are broadcast variables?43
- 92. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What are broadcast variables?43 Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks Distribute every node a copy of a large input dataset in an efficient manner Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost
- 93. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Explain accumulators in Spark.44
- 94. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Explain accumulators in Spark.44 • Accumulators are variables that are only added through an associative and commutative operation • Used to implement counters or sums • Tracking accumulators in the UI can be useful for understanding the progress of running stages • Spark natively supports numeric accumulators. We can create named or unnamed accumulators
- 95. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Why is there a need for broadcast variables when working with Apache Spark? 45
- 96. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Why is there a need for broadcast variables when working with Apache Spark? 45 • Broadcast variables are read only variables, present in-memory cache on every machine • Eliminates the necessity to ship copies of a variable for every task, so data can be processed faster • Help in storing a lookup table inside the memory which enhances the retrieval efficiency when compared to an RDD lookup()
- 97. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How can you trigger automatic clean-ups in Spark to handle accumulated metadata? 46
- 98. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers How can you trigger automatic clean-ups in Spark to handle accumulated metadata? 46 You can trigger the clean-ups by setting the parameter ‘spark.cleaner.ttl’ or by dividing the long running jobs into different batches and writing the intermediary results to the disk
- 99. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What are the various levels of persistence in Apache Spark?47
- 100. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What are the various levels of persistence in Apache Spark?47 Apache Spark automatically persists the intermediary data from various shuffle operations Suggested that users call persist() method on the RDD in case they plan to reuse it. MEMORY-ONLY MEMORY-AND-DISK MEMORY-ONLY-SER MEMORY-AND-DISK-SER OFF-HEAPDISK-ONLY Spark has various persistence levels to store the RDDs on disk or in memory or as a combination of both with different replication levels. The various storage/persistence levels in Spark are:
- 101. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What do you understand by SchemaRDD?48
- 102. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers What do you understand by SchemaRDD?48 SchemaRDD is an RDD that consists of row objects with schema information Designed as an attempt to help developers in code debugging and unit testing on SparkSQL core module. Describing the data structures inside RDD using a formal description similar to RDB schema. SchemaRDD also provides some straightforward relational query interface that are realized through SparkSQL. Now, it is officially renamed to DataFrame API
- 103. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Explain a scenario where you will be using Spark Streaming49
- 104. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark Interview Questions & Answers Explain a scenario where you will be using Spark Streaming49 • Twitter Sentiment Analysis • Data is streamed in real-time onto our Spark program Spark Spark Streaming can be used to gather live tweets from around the world1 Stream can be filtered using Spark SQL & then we can filter tweets based on the sentiment2 Filtering logic will be implemented using MLlib & change our filtering accordingly3