Spark SQL Tutorial | Spark SQL Using Scala | Apache Spark Tutorial For Beginners | Simplilearn

This presentation about Spark SQL will help you understand what is Spark SQL, Spark SQL features, architecture, data frame API, data source API, catalyst optimizer, running SQL queries and a demo on Spark SQL. Spark SQL is an Apache Spark's module for working with structured and semi-structured data. It is originated to overcome the limitations of Apache Hive. Now, let us get started and understand Spark SQL in detail. Below topics are explained in this Spark SQL presentation: 1. What is Spark SQL? 2. Spark SQL features 3. Spark SQL architecture 4. Spark SQL - Dataframe API 5. Spark SQL - Data source API 6. Spark SQL - Catalyst optimizer 7. Running SQL queries 8. Spark SQL demo This Apache Spark and Scala certification training is designed to advance your expertise working with the Big Data Hadoop Ecosystem. You will master essential skills of the Apache Spark open source framework and the Scala programming language, including Spark Streaming, Spark SQL, machine learning programming, GraphX programming, and Shell Scripting Spark. This Scala Certification course will give you vital skillsets and a competitive advantage for an exciting career as a Hadoop Developer. What is this Big Data Hadoop training course about? The Big Data Hadoop and Spark developer course have been designed to impart an in-depth knowledge of Big Data processing using Hadoop and Spark. The course is packed with real-life projects and case studies to be executed in the CloudLab. What are the course objectives? Simplilearn’s Apache Spark and Scala certification training are designed to: 1. Advance your expertise in the Big Data Hadoop Ecosystem 2. Help you master essential Apache and Spark skills, such as Spark Streaming, Spark SQL, machine learning programming, GraphX programming and Shell Scripting Spark 3. Help you land a Hadoop developer job requiring Apache Spark expertise by giving you a real-life industry project coupled with 30 demos What skills will you learn? By completing this Apache Spark and Scala course you will be able to: 1. Understand the limitations of MapReduce and the role of Spark in overcoming these limitations 2. Understand the fundamentals of the Scala programming language and its features 3. Explain and master the process of installing Spark as a standalone cluster 4. Develop expertise in using Resilient Distributed Datasets (RDD) for creating applications in Spark 5. Master Structured Query Language (SQL) using SparkSQL 6. Gain a thorough understanding of Spark streaming features 7. Master and describe the features of Spark ML programming and GraphX programming Learn more at https://www.simplilearn.com/big-data-and-analytics/apache-spark-scala-certification-training













































































More Related Content
What's hot (20)
Similar to Spark SQL Tutorial | Spark SQL Using Scala | Apache Spark Tutorial For Beginners | Simplilearn (20)


















More from Simplilearn (20)




















Recently uploaded (20)




















Spark SQL Tutorial | Spark SQL Using Scala | Apache Spark Tutorial For Beginners | Simplilearn
- 2. What is Spark SQL? Spark SQL Features Spark SQL Architecture Spark SQL – DataFrame API Spark SQL – Data Source API Spark SQL – Catalyst Optimizer Running SQL Queries Spark SQL Demo What’s in it for you? SQL
- 3. What is Spark SQL? SQL Spark SQL is Apache Spark’s module for working with structured and semi-structured data
- 4. Click here to watch the video
- 5. SQL Spark SQL is Apache Spark’s module for working with structured and semi-structured data It originated to overcome the limitations of Apache Hive What is Spark SQL?
- 6. SQL Spark SQL is Apache Spark’s module for working with structured and semi-structured data It originated to overcome the limitations of Apache Hive Hive lags in performance as it uses MapReduce jobs for executing ad-hoc queries Hive does not allow you to resume a job processing if it fails in the middle Limitations What is Spark SQL?
- 7. SQL Spark performs better than Hive in most scenarios Source: https://engineering.fb.com/ Hive ~ Spark
- 9. SQL Integrated High Compatibility You can integrate Spark SQL and query structured data inside Spark programs You can run unmodified Hive queries on existing warehouses in Spark SQL. With existing Hive data, queries and UDFs, Spark SQL offers full compatibility Below are some essential features of Spark SQL that makes it a compelling framework for data processing and analyzing Spark SQL Features Spark SQL Spark programs SQLQueries
- 10. SQL Scalability Standard Connectivity Spark SQL leverages RDD model as it supports large jobs and mid- query fault tolerance. For interactive and long queries, it uses the same engine You can easily connect Spark SQL with JDBC or ODBC. For connectivity for business intelligence tools, both turned as industry norms Spark SQL Features SQL SQL RDD Below are some essential features of Spark SQL that makes it a compelling framework for data processing and analyzing
- 12. SQL DataFrame DSLDataframe DSL DataFrame API Data Source API CSV JSON JDBC DataFrame DSLSpark SQL and HQL Spark SQL Architecture
- 13. Spark SQL has three main layers Spark SQL is Apache Spark’s module for working with structured data Language API SchemaRDD Data Sources Spark is very compatible as it supports languages like Python, HiveQL, Scala, and Java As Spark SQL works on schema, tables, and records, you can use SchemaRDD or DataFrame as a temporary table SQL Spark SQL supports multiple data sources like JSON, Cassandra database, Hive tables Spark SQL Architecture
- 14. Spark SQL – DataFrame API
- 15. A DataFrame is a domain-specific language (DSL) for working with structured and semi-structured data, i.e., datasets with a schema Spark SQL – Data Frame API
- 16. DataFrame API in Spark was designed taking inspiration from DataFrame in R programming and Pandas in Python Spark SQL – Data Frame API A DataFrame is a domain-specific language (DSL) for working with structured and semi-structured data, i.e., datasets with a schema
- 17. Has can process the data in the size of Kilobytes to Petabytes on a single node cluster Can be easily integrated with all Big Data tools and frameworks via Spark-Core Provides API for Python, Java, Scala, and R Programming DataFrame features Spark SQL – Data Frame API DataFrame API in Spark was designed taking inspiration from DataFrame in R programming and Pandas in Python A DataFrame is a domain-specific language (DSL) for working with structured and semi-structured data, i.e., datasets with a schema
- 18. Spark SQL – Data Source API
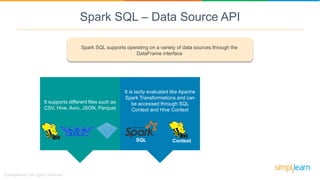
- 19. Spark SQL supports operating on a variety of data sources through the DataFrame interface Spark SQL – Data Source API
- 20. Spark SQL supports operating on a variety of data sources through the DataFrame interface It supports different files such as CSV, Hive, Avro, JSON, Parquet Spark SQL – Data Source API
- 21. It supports different files such as CSV, Hive, Avro, JSON, Parquet It is lazily evaluated like Apache Spark Transformations and can be accessed through SQL Context and Hive Context ContextSQL Spark SQL – Data Source API Spark SQL supports operating on a variety of data sources through the DataFrame interface
- 22. It can be easily integrated with all Big Data tools and frameworks via Spark-Core ContextSQL Spark SQL – Data Source API It supports different files such as CSV, Hive, Avro, JSON, Parquet It is lazily evaluated like Apache Spark Transformations and can be accessed through SQL Context and Hive Context Spark SQL supports operating on a variety of data sources through the DataFrame interface
- 24. Catalyst optimizer leverages advanced programming language features (such as Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer Spark SQL – Catalyst Optimizer
- 25. It works in 4 phases: 1 Analyzing a logical plan to resolve references 2 Logical plan optimization 3 Physical planning 4 Code generation to compile parts of the query to Java bytecode Spark SQL – Catalyst Optimizer Catalyst optimizer leverages advanced programming language features (such as Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer
- 26. SQL Query SQL Query Spark SQL – Catalyst Optimizer Catalyst optimizer leverages advanced programming language features (such as Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer
- 27. SQL Query SQL Query Unresolved Logical plan Spark SQL – Catalyst Optimizer Catalyst optimizer leverages advanced programming language features (such as Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer
- 28. SQL Query SQL Query Unresolved Logical plan Logical plan Catalog Analysis Spark SQL – Catalyst Optimizer Catalyst optimizer leverages advanced programming language features (such as Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer
- 29. SQL Query SQL Query Unresolved Logical plan Logical plan Optimized Logical plan Catalog Analysis Logical Optimization Spark SQL – Catalyst Optimizer Catalyst optimizer leverages advanced programming language features (such as Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer
- 30. SQL Query SQL Query Unresolved Logical plan Logical plan Optimized Logical plan Physical plans Catalog Analysis Logical Optimization Physical Planning Spark SQL – Catalyst Optimizer Catalyst optimizer leverages advanced programming language features (such as Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer
- 31. SQL Query SQL Query Unresolved Logical plan Logical plan Optimized Logical plan Physical plans Cost Model Catalog Analysis Logical Optimization Physical Planning Spark SQL – Catalyst Optimizer Catalyst optimizer leverages advanced programming language features (such as Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer
- 32. SQL Query SQL Query Unresolved Logical plan Logical plan Optimized Logical plan Physical plans Cost Model Selected Physical Plan Catalog Analysis Logical Optimization Physical Planning Spark SQL – Catalyst Optimizer Catalyst optimizer leverages advanced programming language features (such as Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer
- 33. SQL Query SQL Query Unresolved Logical plan Logical plan Optimized Logical plan Physical plans Cost Model Selected Physical Plan RDDs Catalog Analysis Logical Optimization Physical Planning Code Generation Spark SQL – Catalyst Optimizer Catalyst optimizer leverages advanced programming language features (such as Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer
- 34. Spark SQLContext
- 35. Spark SQLContext SQLContext is a class used for initializing the functionalities of Spark SQL
- 36. SparkContext class object (sc) is required for initializing SQLContext class object The following command initializes SparkContext through spark-shell $ spark-shell Spark SQLContext SQLContext is a class used for initializing the functionalities of Spark SQL
- 37. The following command creates a SQLContext scala> val sqlcontext = new org.apache.sql.SQLContext(sc) Spark SQLContext SparkContext class object (sc) is required for initializing SQLContext class object SQLContext is a class used for initializing the functionalities of Spark SQL The following command initializes SparkContext through spark-shell $ spark-shell
- 38. SparkSession
- 39. It is the entry point to any functionality in Spark. To create a basic SparkSession, use SparkSession.builder() Source: https://spark.apache.org/ SparkSession
- 40. Applications can create DataFrames with the help of an existing RDD using a Hive table, or from Spark data sources The following creates a DataFrame based on the content of a JSON file: https://spark.apache.org/Source: Creating DataFrames
- 42. Structured data can be manipulated using domain-specific language provided by DataFrames https://spark.apache.org/Source: DataFrame Operations Below are some examples of structured data processing:
- 43. https://spark.apache.org/Source: DataFrame Operations Structured data can be manipulated using domain-specific language provided by DataFrames Below are some examples of structured data processing:
- 44. https://spark.apache.org/Source: DataFrame Operations Structured data can be manipulated using domain-specific language provided by DataFrames Below are some examples of structured data processing:
- 46. The sql function on a SparkSession allows applications to run SQL queries programmatically and returns the result in the form of a DataFrame https://spark.apache.org/Source: Running SQL Queries