Streaming Machine Learning with Python, Jupyter, TensorFlow, Apache Kafka and KSQL
4 likes1,954 views

The document discusses the integration of Apache Kafka and machine learning, highlighting its role in data engineering and scalable model deployment. Key takeaways include the use of Jupyter for prototyping, streaming model training with Kafka and TensorFlow, and real-world applications like supply chain optimization. The agenda covers challenges, ecosystems, and various tools for streaming data processing and model deployment.













![16Apache Kafka and Machine Learning – Kai Waehner
Confluent - Business Value per Use Case
Improve
Customer
Experience
(CX)
Increase
Revenue
(make money)
Business
Value
Decrease
Costs
(save
money)
Core Business
Platform
Increase
Operational
Efficiency
Migrate to
Cloud
Mitigate Risk
(protect money)
Key Drivers
Strategic Objectives
(sample)
Fraud
Detection
IoT sensor
ingestion
Digital
replatforming/
Mainframe Offload
Connected Car: Navigation & improved
in-car experience: Audi
Customer 360
Simplifying Omni-channel Retail at
Scale: Target
Faster transactional
processing / analysis
incl. Machine Learning / AI
Mainframe Offload: RBC
Microservices
Architecture
Online Fraud Detection
Online Security
(syslog, log
aggregation, Splunk
replacement)
Middleware
replacement
Regulatory
Digital
Transformation
Application Modernization: Multiple
Examples
Website / Core
Operations
(Central Nervous System)
The [Silicon Valley] Digital Natives;
LinkedIn, Netflix, Uber, Yelp...
Predictive Maintenance: Audi
Streaming Platform in a regulated
environment (e.g. Electronic Medical
Records): Celmatix
Real-time app
updates
Real Time Streaming Platform for
Communications and Beyond: Capital One
Developer Velocity - Building Stateful
Financial Applications with Kafka
Streams: Funding Circle
Detect Fraud & Prevent Fraud in Real
Time: PayPal
Kafka as a Service - A Tale of Security
and Multi-Tenancy: Apple
Example Use Cases
$↑
$↓
$
Example Case Studies
(of many)](https://image.slidesharecdn.com/201909oraclecodeonestreamingmlpythonkafkaksqltensorflowkaiwaehner-190917013808/85/Streaming-Machine-Learning-with-Python-Jupyter-TensorFlow-Apache-Kafka-and-KSQL-16-320.jpg)





































Streaming Machine Learning with Python, Jupyter, TensorFlow, Apache Kafka and KSQL
- 1. 1Apache Kafka and Machine Learning – Kai Waehner Streaming Machine Learning with Python, Jupyter, TensorFlow, Apache Kafka, and KSQL Kai Waehner Technology Evangelist [email protected] LinkedIn @KaiWaehner www.confluent.io www.kai-waehner.de
- 2. 2 3 Talks at Oracle Code One 2019 in San Francisco
- 3. 3Apache Kafka and Machine Learning – Kai Waehner Key Takeaways • The Apache Kafka ecosystem helps to do data engineering and production deployment at scale • Jupyter allows debugging, prototyping and scalable, reliable data processing by combining tool sets • Kafka and TensorFlow I/O enable streaming model training without extra data store
- 4. 4Apache Kafka and Machine Learning – Kai Waehner Agenda • Challenges of Machine Learning • Apache Kafka Ecosystem for Machine Learning • TensorFlow Ecosystem • Prototyping and Data Engineering with Python, Jupyter and KSQL • Streaming Model Training with Kafka and TensorFlow I/O • Production Deployment Alternatives and Trade-Offs • Real World Example - Supply Chain Optimization
- 5. 5Apache Kafka and Machine Learning – Kai Waehner Agenda • Challenges of Machine Learning • Apache Kafka Ecosystem for Machine Learning • TensorFlow Ecosystem • Prototyping and Data Engineering with Python, Jupyter and KSQL • Streaming Model Training with Kafka and TensorFlow I/O • Production Deployment Alternatives and Trade-Offs • Real World Example - Supply Chain Optimization
- 6. 6Apache Kafka and Machine Learning – Kai Waehner Analyze and act on critical business moments Seconds Minutes Hours Real Time Tracking Predictive Maintenance Fraud Detection Cross Selling Transportation Rerouting Customer Service Inventory Management Windows of Opportunity
- 7. 7Apache Kafka and Machine Learning – Kai Waehner Machine Learning (ML) ...allows computers to find hidden insights without being explicitly programmed where to look. Machine Learning • Decision Trees • Naïve Bayes • Clustering • Neural Networks • Etc. Deep Learning • CNN • RNN • Autoencoder • Etc.
- 8. 8Apache Kafka and Machine Learning – Kai Waehner Python == De Facto Standard for Machine Learning
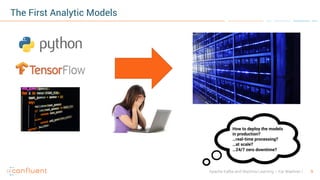
- 9. 9Apache Kafka and Machine Learning – Kai Waehner The First Analytic Models How to deploy the models in production? …real-time processing? …at scale? …24/7 zero downtime?
- 10. 10Apache Kafka and Machine Learning – Kai Waehner Hidden Technical Debt in Machine Learning Systems https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
- 11. 11Apache Kafka and Machine Learning – Kai Waehner Impedance mismatch between model development and model deployment https://www.slideshare.net/NickPentreath/productionizing-spark-ml-pipelines-with-the-portable-format-for-analytics-100788521
- 12. 12Apache Kafka and Machine Learning – Kai Waehner Scalable, Technology-Agnostic Machine Learning Infrastructures https://www.infoq.com/presentations/netflix-ml-meson https://eng.uber.com/michelangelo https://www.infoq.com/presentations/paypal-data-service-fraud What is this thing used everywhere?
- 13. 13Apache Kafka and Machine Learning – Kai Waehner Agenda • Challenges of Machine Learning • Apache Kafka Ecosystem for Machine Learning • TensorFlow Ecosystem • Prototyping and Data Engineering with Python, Jupyter and KSQL • Streaming Model Training with Kafka and TensorFlow I/O • Production Deployment Alternatives and Trade-Offs • Real World Example - Supply Chain Optimization
- 14. 14Apache Kafka and Machine Learning – Kai Waehner The Log ConnectorsConnectors Producer Consumer Streaming Engine Apache Kafka—The Rise of an Event Streaming Platform
- 15. 15Apache Kafka and Machine Learning – Kai Waehner Apache Kafka at Scale at Tech Giants > 4.5 trillion messages / day > 6 Petabytes / day “You name it” * Kafka Is not just used by tech giants ** Kafka is not just used for big data
- 16. 16Apache Kafka and Machine Learning – Kai Waehner Confluent - Business Value per Use Case Improve Customer Experience (CX) Increase Revenue (make money) Business Value Decrease Costs (save money) Core Business Platform Increase Operational Efficiency Migrate to Cloud Mitigate Risk (protect money) Key Drivers Strategic Objectives (sample) Fraud Detection IoT sensor ingestion Digital replatforming/ Mainframe Offload Connected Car: Navigation & improved in-car experience: Audi Customer 360 Simplifying Omni-channel Retail at Scale: Target Faster transactional processing / analysis incl. Machine Learning / AI Mainframe Offload: RBC Microservices Architecture Online Fraud Detection Online Security (syslog, log aggregation, Splunk replacement) Middleware replacement Regulatory Digital Transformation Application Modernization: Multiple Examples Website / Core Operations (Central Nervous System) The [Silicon Valley] Digital Natives; LinkedIn, Netflix, Uber, Yelp... Predictive Maintenance: Audi Streaming Platform in a regulated environment (e.g. Electronic Medical Records): Celmatix Real-time app updates Real Time Streaming Platform for Communications and Beyond: Capital One Developer Velocity - Building Stateful Financial Applications with Kafka Streams: Funding Circle Detect Fraud & Prevent Fraud in Real Time: PayPal Kafka as a Service - A Tale of Security and Multi-Tenancy: Apple Example Use Cases $↑ $↓ $ Example Case Studies (of many)
- 17. 17Apache Kafka and Machine Learning – Kai Waehner Apache Kafka’s Open Source Ecosystem as Infrastructure for ML
- 18. 18Apache Kafka and Machine Learning – Kai Waehner Apache Kafka’s Open Ecosystem as Infrastructure for ML Kafka Streams Kafka Connect Rest Proxy Schema Registry Go/.NET /Python Kafka Producer KSQL Kafka Streams
- 19. 19Apache Kafka and Machine Learning – Kai Waehner Want to learn more about Apache Kafka + Machine Learning? Overview à www.kai-waehner.de • Blog Post: How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka https://www.confluent.io/blog/build-deploy-scalable-machine-learning-production-apache-kafka/ • Slide Deck: Apache Kafka + Machine Learning => Intelligent Real Time Applications https://www.slideshare.net/KaiWaehner/apache-kafka-streams-machine-learning-deep-learning • Slide Deck: Deep Learning at Extreme Scale (in the Cloud) with the Apache Kafka Open Source Ecosystem https://www.slideshare.net/KaiWaehner/deep-learning-at-extreme-scale-in-the-cloud-with-the-apache-kafka-open-source-ecosystem • Video Recording: Deep Learning in Mission Critical and Scalable Real Time Applications with Open Source Frameworks https://vimeo.com/jaxtv/review/256406763/7fbf4213be • Blog Post: Using Apache Kafka to Drive Cutting-Edge Machine Learning - Hybrid ML Architectures, AutoML, and more... https://www.confluent.io/blog/using-apache-kafka-drive-cutting-edge-machine-learning • Blog Post: Machine Learning with Python, Jupyter, KSQL and TensorFlow https://www.confluent.io/blog/machine-learning-with-python-jupyter-ksql-tensorflow
- 20. 20Apache Kafka and Machine Learning – Kai Waehner Agenda • Challenges of Machine Learning • Apache Kafka Ecosystem for Machine Learning • TensorFlow Ecosystem • Prototyping and Data Engineering with Python, Jupyter and KSQL • Streaming Model Training with Kafka and TensorFlow I/O • Production Deployment Alternatives and Trade-Offs • Real World Example - Supply Chain Optimization
- 21. 21Apache Kafka and Machine Learning – Kai Waehner TensorFlow TensorFlow is an open source software library for high performance numerical computation. Its flexible architecture allows easy deployment of computation across a variety of platforms (CPUs, GPUs, TPUs), and from desktops to clusters of servers to mobile and edge devices. Originally developed by researchers and engineers from the Google Brain team within Google’s AI organization, it comes with strong support for machine learning and deep learning and the flexible numerical computation core is used across many other scientific domains. https://www.tensorflow.org/
- 22. 22Apache Kafka and Machine Learning – Kai Waehner TensorFlow Ecosystem + large community + integration with most 3rd party ML tools + support by all major cloud providers
- 23. 23Apache Kafka and Machine Learning – Kai Waehner TensorFlow Model • Serialization: Protocol Buffers (protobufs) • Generated classes in C, Python, Java, etc. that can load, save, and access the data • File Format: Human readable TextFormat (.pbtxt) vs. compressed Binary (.pb) • Graph object: Foundation of computation in TensorFlow • Weights: Held in separate checkpoint files • Standards: Support for ONNX, PMML Autoencoder for Anomaly Detection
- 24. 24Apache Kafka and Machine Learning – Kai Waehner Agenda • Challenges of Machine Learning • Apache Kafka Ecosystem for Machine Learning • TensorFlow Ecosystem • Prototyping and Data Engineering with Python, Jupyter and KSQL • Streaming Model Training with Kafka and TensorFlow I/O • Production Deployment Alternatives and Trade-Offs • Real World Example - Supply Chain Optimization
- 25. 25Apache Kafka and Machine Learning – Kai Waehner Jupyter https://jupyter.org/
- 26. 26Apache Kafka and Machine Learning – Kai Waehner Prototyping with TensorFlow in a Jupyter Notebook
- 27. 27Apache Kafka and Machine Learning – Kai Waehner Data Preprocessing at Scale and Reliable Preprocessing Filter, transform, anonymize, extract features Data needs to be preprocessed at scale and reusable! Streams • Use KSQL to preprocess data at scale without coding • Use SQL statements for interactive analysis + deployment to production at scale • Leverage e.g. Python with KSQL REST interface Data Ready for Model Training
- 28. 28Apache Kafka and Machine Learning – Kai Waehner KSQL – A Streaming SQL Engine for Apache Kafka
- 29. 29Apache Kafka and Machine Learning – Kai Waehner Preprocessing with KSQL SELECT car_id, event_id, car_model_id, sensor_input FROM car_sensor c LEFT JOIN car_models m ON c.car_model_id = m.car_model_id WHERE m.car_model_type ='Audi_A8';
- 30. 30Apache Kafka and Machine Learning – Kai Waehner Excursus: KSQL compared to Kafka Streams https://www.slideshare.net/KaiWaehner/kafka-streams-vs-ksql-for-stream-processing-on-top-of-apache-kafka-142127337
- 31. 31Apache Kafka and Machine Learning – Kai Waehner Data Engineering with Python, KSQL, TensorFlow and Keras https://github.com/kaiwaehner/python-jupyter-apache-kafka-ksql-tensorflow-keras https://github.com/kaiwaehner/python-jupyter-apache-kafka-ksql-tensorflow-keras/blob/master/python- jupyter-apache-kafka-ksql-tensorflow-keras.ipynb Pick and combine the tools you need and want to use! Some libraries used in this example: • Numpy • Pandas • TensorFlow • Keras • KSQL • ksql-python • sklearn • matplotlib
- 32. 32Apache Kafka and Machine Learning – Kai Waehner Live Demo Rapid Prototyping and Data Preprocessing at Scale with Python, Jupyter and KSQL
- 33. 33Apache Kafka and Machine Learning – Kai Waehner Data Engineering and Interactive Queries with Jupyter, Python and KSQL https://github.com/jupyter/jupyter/wiki/Jupyter-kernels https://github.com/takluyver/bash_kernel You can also use just the bash kernel and KSQL CLI:
- 34. 34Apache Kafka and Machine Learning – Kai Waehner ksql> SELECT customer_id, location_id FROM orders WHERE customer_id = 32235; +-------------+-------------+ | customer_id | location_id | +-------------+-------------+ | 32235 | 90 | +-------------+-------------+ 1 row in 0.003s ksql> ksql> ksql> ksql> SELECT count FROM orders WHERE customer_id = 1980; +-----------+ | count | +-----------+ | 12 | +-----------+ 1 row in 0.002s ksql> CREATE TABLE orders AS SELECT customer_id, location_id, count(*) FROM orders_stream GROUP BY customer_id, location_id; Query runs until completion and returns the final result as quickly as possible KSQL: Interactive Queries (aka Point-in-Time Queries) https://github.com/confluentinc/ksql/blob/master/design-proposals/klip-8-interactive-queries.md
- 35. 35Apache Kafka and Machine Learning – Kai Waehner Agenda • Challenges of Machine Learning • Apache Kafka Ecosystem for Machine Learning • TensorFlow Ecosystem • Prototyping and Data Engineering with Python, Jupyter and KSQL • Streaming Model Training with Kafka and TensorFlow I/O • Production Deployment Alternatives and Trade-Offs • Real World Example - Supply Chain Optimization
- 36. 36Apache Kafka and Machine Learning – Kai Waehner Data Ingestion into a Data Store Connect Preprocessed Data There isn’t just one ML solution. We need to be flexible!
- 37. 37Apache Kafka and Machine Learning – Kai Waehner Kafka Connect • “Kafka Benefits Under the Hood” • Out-of-the-box connectivity • Data format conversion • Single message transformation (including error-handling) KafkaConnect KafkaConnect Data Source Data Sink REST API
- 38. 38Apache Kafka and Machine Learning – Kai Waehner CREATE SOURCE CONNECTOR reader WITH (source = ‘confluent.jdbc.postgres’, table = ‘customers’, …); CREATE SINK CONNECTOR writer WITH (sink = ‘confluent.s3’, bucket = ‘vip_customers’, …); CREATE STREAM postgres_customers (id integer, purchases integer) WITH (source = ‘reader’, ...); CREATE STREAM vip_customers WITH (sink = ‘writer’, ...) AS SELECT * FROM postgres_customers WHERE purchases > 10; KSQL: Embedded Kafka Connect https://github.com/confluentinc/ksql/blob/master/design-proposals/klip-7-connect-integration.md Continuous streaming integration and pre-processing at scale and reliable – just with SQL commands!
- 39. 39Apache Kafka and Machine Learning – Kai Waehner Model Training using a Data Store Let’s build some models at extreme scale using TensorFlow and TPUs! Analytic Model
- 40. 40Apache Kafka and Machine Learning – Kai Waehner Streaming Model Training without additional Data Store https://github.com/tensorflow/io/tree/master/tensorflow_io/kafka TensorFlow I/O Kafka Plugin • Native integration between Kafka and TensorFlow • KafkaDataSet and KafkaOutputSequence for TensorFlow • Written in C++ (linked with librdkafka) • Part of the graph in TensorFlow • Direct training and inference from streaming data • No data storage like S3 or HDFS needed
- 41. 41Apache Kafka and Machine Learning – Kai Waehner Streaming Model Training with Kafka and TensorFlow I/O https://github.com/kaiwaehner/hivemq-mqtt-tensorflow-kafka-realtime-iot-machine-learning-training-inference Python Kafka Producer Python Kafka Consumer + Streaming Ingestion + Model Training
- 42. 42Apache Kafka and Machine Learning – Kai Waehner Time Model BModel A Producer Distributed Commit Log Streaming Model Training with Kafka and TensorFlow I/O Another Real Time Consumer Another Batch Consumer
- 43. 43Apache Kafka and Machine Learning – Kai Waehner Model Example: Autoencoder for Anomaly Detection
- 44. 44Apache Kafka and Machine Learning – Kai Waehner Agenda • Challenges of Machine Learning • Apache Kafka Ecosystem for Machine Learning • TensorFlow Ecosystem • Prototyping and Data Engineering with Python, Jupyter and KSQL • Streaming Model Training with Kafka and TensorFlow I/O • Production Deployment Alternatives and Trade-Offs • Real World Example - Supply Chain Optimization
- 45. 45Apache Kafka and Machine Learning – Kai Waehner RPC communication to do model inference Streams Input Event Prediction Request Response Model Serving TensorFlow Serving gRPC / HTTP Application
- 46. 47Apache Kafka and Machine Learning – Kai Waehner Model interference natively embedded into the App Application Input Event Prediction
- 47. 48Apache Kafka and Machine Learning – Kai Waehner Model interference in a Stream Processing App Streams Input Event Prediction Stream Processing Model doPrediction() return value
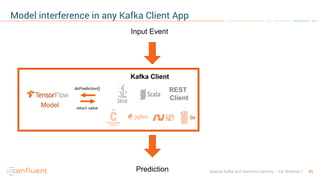
- 48. 49Apache Kafka and Machine Learning – Kai Waehner Model interference in any Kafka Client App Input Event Prediction Kafka Client REST Client Model doPrediction() return value
- 49. 52Apache Kafka and Machine Learning – Kai Waehner RPC vs. Stream Processing for Model Serving Why a Model Server and RPC • Simple integration with existing technologies and organizational processes • Easier to understand if you come from non- streaming world • Later migration to real streaming is also possible • Model management built-in for different models, versioning and A/B testing • Monitoring built-in Why embedded into Streaming App • Better latency as remote call instead of local inference • Offline inference (devices, edge processing, etc.) • No coupling of the availability, scalability, and latency/throughput of your Kafka Streams application with the SLAs of the RPC interface • No side-effects (e.g., in case of failure), all covered by Kafka processing (e.g., exactly once) Application Input Event Prediction
- 50. 54Apache Kafka and Machine Learning – Kai Waehner Model Deployment with Apache Kafka, KSQL and TensorFlow “CREATE STREAM AnomalyDetection AS SELECT sensor_id, detectAnomaly(sensor_values) FROM machine_engine;“ User Defined Function (UDF)
- 51. 55Apache Kafka and Machine Learning – Kai Waehner Live Demo Real Time Model Scoring with KSQL and TensorFlow
- 52. 56Apache Kafka and Machine Learning – Kai Waehner Agenda • Challenges of Machine Learning • Apache Kafka Ecosystem for Machine Learning • TensorFlow Ecosystem • Prototyping and Data Engineering with Python, Jupyter and KSQL • Streaming Model Training with Kafka and TensorFlow I/O • Production Deployment Alternatives and Trade-Offs • Real World Example - Supply Chain Optimization
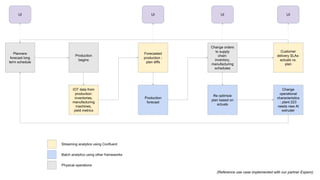
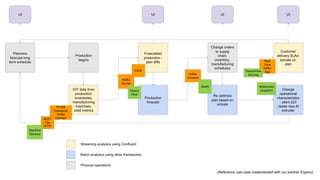
- 53. Planners forecast long term schedule Production begins IOT data from production: inventories, manufacturing machines, yield metrics Production forecast Forecasted production - plan diffs Re optimize plan based on actuals Change orders to supply chain: inventory, manufacturing schedules Change operational characteristics : plant 223 needs new Al extruder Customer delivery SLAs: actuals vs. plan Streaming analytics using Confluent Batch analytics using other frameworks Physical operations UI UI UIUI (Reference use case implemented with our partner Expero)
- 54. Planners forecast long term schedule Production begins IOT data from production: inventories, manufacturing machines, yield metrics Production forecast Forecasted production - plan diffs Re optimize plan based on actuals Change orders to supply chain: inventory, manufacturing schedules Change operational characteristics : plant 223 needs new Al extruder Customer delivery SLAs: actuals vs. plan UI UI UIUI PLC4X Connector Kafka ConnectMQTT File HTTP Machine Sensors Kafka Cluster KSQL Tensor Flow Kafka Connect Notebooks (Jupyter) Spark Real Time Kafka App Streaming analytics using Confluent Batch analytics using other frameworks Physical operations TensorFlow Serving (Reference use case implemented with our partner Expero)
- 55. 62Apache Kafka and Machine Learning – Kai Waehner Code and Demos for Kafka and Machine Learning https://github.com/kaiwaehner
- 56. 63Apache Kafka and Machine Learning – Kai Waehner Key Takeaways • The Apache Kafka ecosystem helps to do data engineering and production deployment at scale • Jupyter allows debugging, prototyping and scalable, reliable data processing by combining tool sets • Kafka and TensorFlow I/O enable streaming model training without extra data store
- 57. 64Apache Kafka and Machine Learning – Kai Waehner Kai Waehner Technology Evangelist [email protected] @KaiWaehner www.kai-waehner.de www.confluent.io LinkedIn Questions? Feedback? Let’s connect!