Using MongoDB with Kafka - Use Cases and Best Practices
0 likes239 views

The document discusses the integration of MongoDB with Apache Kafka, highlighting use cases, such as using MongoDB as a source and sink. It details configuration options, throttling mechanisms, and real-world applications, including a case study from TransferWise. The presentation emphasizes the benefits of selective replication and Kafka's scalability in managing workloads effectively.
1 of 33
Download to read offline









![Debezium
Supports both Replica-set and Sharded clusters
Uses the oplog to capture and create events
Selective Replication: [database|collection].[include|exclude].list
EL: field.exclude.list & field.renames
snapshot.mode = initial | never
tasks.max
initial.sync.max.threads](https://image.slidesharecdn.com/usingmongodbwithkafkausecasesandbestpractices-201021101522/85/Using-MongoDB-with-Kafka-Use-Cases-and-Best-Practices-10-320.jpg)


















![MongoDB Kafka Sink
connector: Configuration
## Document manipulation settings
[key|value].projection.type=AllowList
[key|value].projection.list=name,age,address.post_code
## Id Strategy
document.id.strategy=com.mongodb.kafka.connect.sink.processor.id.strategy.BsonOidStrategy
post.processor.chain=com.mongodb.kafka.connect.sink.processor.DocumentIdAdder](https://image.slidesharecdn.com/usingmongodbwithkafkausecasesandbestpractices-201021101522/85/Using-MongoDB-with-Kafka-Use-Cases-and-Best-Practices-30-320.jpg)



Ad
Recommended
How to upgrade to MongoDB 4.0 - Percona Europe 2018
How to upgrade to MongoDB 4.0 - Percona Europe 2018Antonios Giannopoulos This document outlines the upgrade process to MongoDB 4.0, detailing necessary steps in the upgrade procedure for various components, including replica sets, sharded clusters, and dependent applications. It highlights compatibility requirements for drivers, the importance of feature compatibility versions, and the deprecation of certain features. Key improvements in MongoDB 4.0 include support for multi-document transactions, enhanced security with SCRAM-SHA-256, and changes to secondary reads for improved performance.
Sharded cluster tutorial
Sharded cluster tutorialAntonios Giannopoulos This document provides guidance on deploying and upgrading a MongoDB sharded cluster. It discusses the components of a sharded cluster including config servers, shards, and mongos processes. It recommends a production deployment have at least 3 config servers, 3 nodes per shard replica set, and multiple mongos instances. The document outlines steps for deploying each component, including initializing replica sets and adding shards. It also provides a checklist for upgrading between minor and major versions, such as changes to configuration options, deprecated operations, and connectivity changes.
Sharding in MongoDB 4.2 #what_is_new
Sharding in MongoDB 4.2 #what_is_newAntonios Giannopoulos The document discusses key features and improvements in MongoDB 4.2, focusing on sharding, distributed transactions, and shard key management. It highlights the immutability of shard keys, the introduction of distributed transactions across sharded clusters, and performance implications. Additionally, the presentation includes considerations for chunk migrations, transaction handling, and balancer functionality within sharded environments.
Upgrading to MongoDB 4.0 from older versions
Upgrading to MongoDB 4.0 from older versionsAntonios Giannopoulos Upgrading to MongoDB 4.0 involves several steps:
1. Upgrade config servers to replica sets following procedures for upgrading replica sets.
2. Upgrade shards by upgrading each replica set member individually.
3. Upgrade mongos processes one at a time by replacing binaries and restarting.
4. Set the featureCompatibilityVersion to enable backwards incompatible 4.0 features.
5. Consider application impacts such as upgrading drivers, frameworks, and inspecting code for removed/deprecated features.
6. Test upgrades in non-production environments before upgrading production systems.
Triggers in MongoDB
Triggers in MongoDBAntonios Giannopoulos The document provides an overview of triggers in MongoDB, detailing their definitions, types, and practical applications. It discusses the implementation of application triggers, oplog tailing, and change streams, as well as their advantages and considerations in various use cases. Additionally, it highlights challenges such as shard key analysis and the complexities involved in managing replication and event handling.
New Indexing and Aggregation Pipeline Capabilities in MongoDB 4.2
New Indexing and Aggregation Pipeline Capabilities in MongoDB 4.2Antonios Giannopoulos The document discusses new features in MongoDB 4.2, focusing on indexing, aggregation, and materialized views. Key improvements include hybrid indexing methods, the removal of index key limits, and the introduction of new aggregation operators such as trigonometric functions and regex processing. It also highlights the ability to use the aggregation framework for update operations, emphasizing the power and potential complexity of these enhancements.
Elastic 101 tutorial - Percona Europe 2018
Elastic 101 tutorial - Percona Europe 2018 Antonios Giannopoulos Elasticsearch allows users to group related data into logical units called indices. An index can be defined using the create index API and documents are indexed to an index. Indices are partitioned into shards which can be distributed across multiple nodes for scaling. Each shard is a standalone Lucene index. Documents must be in JSON format with a unique ID and can contain any text or numeric data to be searched or analyzed.
Managing data and operation distribution in MongoDB
Managing data and operation distribution in MongoDBAntonios Giannopoulos This document provides an overview of managing data and operations distribution in MongoDB sharded clusters. It discusses shard key selection, applying and reverting shard keys, automatic and manual chunk splitting and merging, balancing data distribution across shards, and cleaning up orphaned documents. The goal is to optimally distribute data and load across shards in the cluster.
MongoDB - Sharded Cluster Tutorial
MongoDB - Sharded Cluster TutorialJason Terpko This document provides an overview and instructions for deploying, upgrading, and troubleshooting a MongoDB sharded cluster. It describes the components of a sharded cluster including shards, config servers, and mongos processes. It provides recommendations for initial deployment including using replica sets for shards and config servers, DNS names instead of IPs, and proper user authorization. The document also outlines best practices for upgrading between minor and major versions, including stopping the balancer, upgrading processes in rolling fashion, and handling incompatible changes when downgrading major versions.
MongoDB - External Authentication
MongoDB - External AuthenticationJason Terpko The document provides an overview of external authentication options for Percona Server for MongoDB and MongoDB Enterprise, highlighting configurations for LDAP, SASL, and Kerberos. It includes detailed setup instructions, security configurations, and examples of how to authenticate users within these systems. Additionally, it emphasizes operational management through tools like Ops Manager and offers career opportunities at ObjectRocket.
Triggers In MongoDB
Triggers In MongoDBJason Terpko Triggers in MongoDB can be implemented through application-based or oplog/change stream-based approaches. Application-based triggers are self-implemented and offer more flexibility but require additional development. Oplog/change stream-based triggers allow monitoring database operations by tailing the oplog or using change streams. Considerations for oplog/change stream triggers include handling rollbacks, maintaining operation order, and filtering migration/orphan events in sharded clusters. An example use case is analyzing shard keys by monitoring operations on a collection to identify access patterns before defining the shard key.
MongoDB: Comparing WiredTiger In-Memory Engine to Redis
MongoDB: Comparing WiredTiger In-Memory Engine to RedisJason Terpko The document compares MongoDB and Redis, discussing their architectures, storage engines, and operational features. It details the WiredTiger engine and its configurations, including in-memory and replication options, and highlights key differences in data storage, scaling, and persistence. The document also touches on sharding, monitoring, and data expiration management in both databases.
MongoDB Chunks - Distribution, Splitting, and Merging
MongoDB Chunks - Distribution, Splitting, and MergingJason Terpko The document discusses MongoDB chunk management including distribution, splitting, and merging in sharded clusters. It covers use cases for splitting and merging, conditions for chunk size and shard key considerations, and performance profiling examples. Additionally, it highlights specific utilities provided by ObjectRocket for managing chunks in MongoDB databases.
MongoDB – Sharded cluster tutorial - Percona Europe 2017
MongoDB – Sharded cluster tutorial - Percona Europe 2017Antonios Giannopoulos This document provides guidance on deploying and upgrading a MongoDB sharded cluster. It discusses the components of a sharded cluster including config servers, shards, and mongos processes. It recommends a production deployment has at least 3 config servers, 3 nodes per shard replica set, and multiple mongos instances. The document outlines steps for deploying each component, including initializing replica sets and adding shards. It also provides a checklist for upgrading between minor and major versions, such as changes to configuration options, deprecated operations, and connectivity changes.
Unqlite
UnqlitePaul Myeongchan Kim UnQLite is an embeddable, serverless, zero-configuration NoSQL database that uses a single database file with no external dependencies. It provides ACID transactions with key-value and document storage and supports efficient O(1) lookups. The database can be accessed from C code using a simple API to open and close the database, store, retrieve, append, and delete key-value pairs, and iterate over records with a cursor. It also supports loading and storing files and scripting functionality through Jx9 scripts.
Managing Data and Operation Distribution In MongoDB
Managing Data and Operation Distribution In MongoDBJason Terpko The document provides a comprehensive overview of managing data and operation distribution in MongoDB, focusing on aspects like sharded clusters, shard key selection, chunk management, and data distribution. It discusses technical details regarding cluster setup, shard key operations, and balancing chunk sizes across shards. Additionally, it addresses challenges related to orphaned documents and their cleanup, while also emphasizing the importance of profiling for optimal shard key selection.
Like loggly using open source
Like loggly using open sourceThomas Alrin This document discusses options for streaming logs and metrics from cloud VMs in real-time. It evaluates log shipping tools like Logstash, Fluentd, Beaver, Logstash-Forwarder, RSYSLOG and Heka, and recommends Heka and Beaver for shipping logs from VMs to a central queue due to their lightweight footprint. The document also provides configuration examples for using Heka and Beaver to collect logs from VMs and stream them to RabbitMQ in real-time for further processing. Chef recipes are used to dynamically configure log shipping tools on VMs.
Fluentd meetup
Fluentd meetupSadayuki Furuhashi This document provides an overview of Fluentd, an open source data collector for structured logging. Fluentd uses a pluggable architecture and JSON format for log messages, allowing logs to be filtered, buffered, and reliably forwarded to storage. It provides client libraries for integrating with applications in languages like Ruby, Perl, PHP, Python and Java. Fluentd is positioned as an alternative to other log collection systems like Scribe and Flume, with advantages of being easier to install, configure, extend with plugins, and smaller footprint.
Fluentd vs. Logstash for OpenStack Log Management
Fluentd vs. Logstash for OpenStack Log ManagementNTT Communications Technology Development The document compares two popular log collectors, Fluentd and Logstash, focusing on their features, configurations, performance, and transport protocols. Fluentd, written in cruby, uses tagged logs for routing, while Logstash, written in jruby, aggregates logs without tagging. The document also discusses integration with OpenStack, log handling, and some unique features of each log collector such as Fluentd's support for active-active load balancing.
Redis modules 101
Redis modules 101Dvir Volk The document summarizes Redis Modules and provides an overview of how to build and use Redis Modules. Some key points:
- Redis Modules allow developers to extend Redis with new commands by dynamically loading libraries written in C/C++. This provides new functionality and integrates with existing Redis data types and commands.
- The Modules API provides both high-level and low-level interfaces. The high-level API is similar to Lua but slower, while the low-level API exposes specific Redis commands and data types for better performance.
- Building a simple module involves writing a command handler, validating arguments, making Redis calls, and returning a reply. Modules are initialized via an OnLoad function and new commands can
ELK stack at weibo.com
ELK stack at weibo.com琛琳 饶 - The document discusses using the ELK stack (Elasticsearch, Logstash, Kibana) to perform real-time log search, analysis, and monitoring. It provides examples of using Logstash and Elasticsearch for parsing and indexing application logs, and using Kibana for visualization and analysis.
- The document identifies several performance and stability issues with Logstash and Elasticsearch including high CPU usage from grok filtering, GeoIP filtering performance, and Elasticsearch relocation and recovery times. It proposes solutions like custom filtering plugins, tuning Elasticsearch configuration, and optimizing mappings.
- Rsyslog is presented as an alternative to Logstash for log collection with better performance. Examples are given of using Rsyslog plugins and Rainerscript for efficient
Sessionization with Spark streaming
Sessionization with Spark streamingRamūnas Urbonas The document discusses sessionization with Spark streaming to analyze user sessions from a constant stream of page visit data. Key points include:
- Streaming page visit data presents challenges like joining new visits to ongoing sessions and handling variable data volumes and long user sessions.
- The proposed solution uses Spark streaming to join a checkpoint of incomplete sessions with new visit data to calculate session metrics in real-time.
- Important aspects are controlling data ingress size and partitioning to optimize performance of operations like joins and using custom formats to handle output to multiple sinks.
MongoDB Scalability Best Practices
MongoDB Scalability Best PracticesJason Terpko This document presents best practices for scaling MongoDB, covering key topics such as schema design, sharding, and locking mechanisms. It details vertical and horizontal scaling options, including replica sets and sharding, along with implications for performance and resource utilization. The document emphasizes the importance of selecting the right tool for specific data use cases to optimize database performance.
Tuning Elasticsearch Indexing Pipeline for Logs
Tuning Elasticsearch Indexing Pipeline for LogsSematext Group, Inc. This document summarizes techniques for optimizing Logstash and Rsyslog for high volume log ingestion into Elasticsearch. It discusses using Logstash and Rsyslog to ingest logs via TCP and JSON parsing, applying filters like grok and mutate, and outputting to Elasticsearch. It also covers Elasticsearch tuning including refresh rate, doc values, indexing performance, and using time-based indices on hot and cold nodes. Benchmark results show Logstash and Rsyslog can handle thousands of events per second with appropriate configuration.
Collect distributed application logging using fluentd (EFK stack)
Collect distributed application logging using fluentd (EFK stack)Marco Pas This document discusses using Fluentd to collect distributed application logging in a containerized environment. It provides an overview of Fluentd, including its pluggable architecture and configuration. It then demonstrates capturing logging from Docker containers and HTTP services and storing the logs in MongoDB and Elasticsearch as part of the ELK stack. It shows filtering and parsing logs from a Spring Boot application. Finally, it discusses setting up Fluentd for high availability.
Building Scalable, Distributed Job Queues with Redis and Redis::Client
Building Scalable, Distributed Job Queues with Redis and Redis::ClientMike Friedman This document discusses using Redis and the Redis::Client Perl module to build scalable distributed job queues. It provides an overview of Redis, describing it as a key-value store that is simple, fast, and open-source. It then covers the various Redis data types like strings, lists, hashes, sets and sorted sets. Examples are given of how to work with these types using Redis::Client. The document discusses using Redis lists to implement job queues, with jobs added via RPUSH and popped via BLPOP. Benchmark results show the Redis-based job queue approach significantly outperforms using a MySQL jobs table with polling. Some caveats are provided about the benchmarks.
Attack monitoring using ElasticSearch Logstash and Kibana
Attack monitoring using ElasticSearch Logstash and KibanaPrajal Kulkarni This document discusses using the ELK stack (Elasticsearch, Logstash, Kibana) for attack monitoring. It provides an overview of each component, describes how to set up ELK and configure Logstash for log collection and parsing. It also demonstrates log forwarding using Logstash Forwarder, and shows how to configure alerts and dashboards in Kibana for attack monitoring. Examples are given for parsing Apache logs and syslog using Grok filters in Logstash.
Using Apache Spark to Solve Sessionization Problem in Batch and Streaming
Using Apache Spark to Solve Sessionization Problem in Batch and StreamingDatabricks This document discusses sessionization techniques using Apache Spark batch and streaming processing. It describes using Spark to join previous session data with new log data to generate user sessions in batch mode. For streaming, it covers using watermarks and stateful processing to continuously generate sessions from streaming data. Key aspects covered include checkpointing to provide fault tolerance, configuring the state store, and techniques for reprocessing data in batch and streaming contexts.
Kafka syed academy_v1_introduction
Kafka syed academy_v1_introductionSyed Hadoop This document provides an introduction to Apache Kafka. It discusses why Kafka is needed for real-time streaming data processing and real-time analytics. It also outlines some of Kafka's key features like scalability, reliability, replication, and fault tolerance. The document summarizes common use cases for Kafka and examples of large companies that use it. Finally, it describes Kafka's core architecture including topics, partitions, producers, consumers, and how it integrates with Zookeeper.
Introduction to apache kafka
Introduction to apache kafkaSamuel Kerrien The document provides an introduction to Apache Kafka, detailing its architecture, use cases, and features such as messaging, log aggregation, and real-time processing. It highlights Kafka's scalability, durability, and performance benchmarks, along with the role of Zookeeper in managing Kafka clusters. Key recommendations for starting with Kafka, including configuration and monitoring, are also discussed.
More Related Content
What's hot (20)
MongoDB - Sharded Cluster Tutorial
MongoDB - Sharded Cluster TutorialJason Terpko This document provides an overview and instructions for deploying, upgrading, and troubleshooting a MongoDB sharded cluster. It describes the components of a sharded cluster including shards, config servers, and mongos processes. It provides recommendations for initial deployment including using replica sets for shards and config servers, DNS names instead of IPs, and proper user authorization. The document also outlines best practices for upgrading between minor and major versions, including stopping the balancer, upgrading processes in rolling fashion, and handling incompatible changes when downgrading major versions.
MongoDB - External Authentication
MongoDB - External AuthenticationJason Terpko The document provides an overview of external authentication options for Percona Server for MongoDB and MongoDB Enterprise, highlighting configurations for LDAP, SASL, and Kerberos. It includes detailed setup instructions, security configurations, and examples of how to authenticate users within these systems. Additionally, it emphasizes operational management through tools like Ops Manager and offers career opportunities at ObjectRocket.
Triggers In MongoDB
Triggers In MongoDBJason Terpko Triggers in MongoDB can be implemented through application-based or oplog/change stream-based approaches. Application-based triggers are self-implemented and offer more flexibility but require additional development. Oplog/change stream-based triggers allow monitoring database operations by tailing the oplog or using change streams. Considerations for oplog/change stream triggers include handling rollbacks, maintaining operation order, and filtering migration/orphan events in sharded clusters. An example use case is analyzing shard keys by monitoring operations on a collection to identify access patterns before defining the shard key.
MongoDB: Comparing WiredTiger In-Memory Engine to Redis
MongoDB: Comparing WiredTiger In-Memory Engine to RedisJason Terpko The document compares MongoDB and Redis, discussing their architectures, storage engines, and operational features. It details the WiredTiger engine and its configurations, including in-memory and replication options, and highlights key differences in data storage, scaling, and persistence. The document also touches on sharding, monitoring, and data expiration management in both databases.
MongoDB Chunks - Distribution, Splitting, and Merging
MongoDB Chunks - Distribution, Splitting, and MergingJason Terpko The document discusses MongoDB chunk management including distribution, splitting, and merging in sharded clusters. It covers use cases for splitting and merging, conditions for chunk size and shard key considerations, and performance profiling examples. Additionally, it highlights specific utilities provided by ObjectRocket for managing chunks in MongoDB databases.
MongoDB – Sharded cluster tutorial - Percona Europe 2017
MongoDB – Sharded cluster tutorial - Percona Europe 2017Antonios Giannopoulos This document provides guidance on deploying and upgrading a MongoDB sharded cluster. It discusses the components of a sharded cluster including config servers, shards, and mongos processes. It recommends a production deployment has at least 3 config servers, 3 nodes per shard replica set, and multiple mongos instances. The document outlines steps for deploying each component, including initializing replica sets and adding shards. It also provides a checklist for upgrading between minor and major versions, such as changes to configuration options, deprecated operations, and connectivity changes.
Unqlite
UnqlitePaul Myeongchan Kim UnQLite is an embeddable, serverless, zero-configuration NoSQL database that uses a single database file with no external dependencies. It provides ACID transactions with key-value and document storage and supports efficient O(1) lookups. The database can be accessed from C code using a simple API to open and close the database, store, retrieve, append, and delete key-value pairs, and iterate over records with a cursor. It also supports loading and storing files and scripting functionality through Jx9 scripts.
Managing Data and Operation Distribution In MongoDB
Managing Data and Operation Distribution In MongoDBJason Terpko The document provides a comprehensive overview of managing data and operation distribution in MongoDB, focusing on aspects like sharded clusters, shard key selection, chunk management, and data distribution. It discusses technical details regarding cluster setup, shard key operations, and balancing chunk sizes across shards. Additionally, it addresses challenges related to orphaned documents and their cleanup, while also emphasizing the importance of profiling for optimal shard key selection.
Like loggly using open source
Like loggly using open sourceThomas Alrin This document discusses options for streaming logs and metrics from cloud VMs in real-time. It evaluates log shipping tools like Logstash, Fluentd, Beaver, Logstash-Forwarder, RSYSLOG and Heka, and recommends Heka and Beaver for shipping logs from VMs to a central queue due to their lightweight footprint. The document also provides configuration examples for using Heka and Beaver to collect logs from VMs and stream them to RabbitMQ in real-time for further processing. Chef recipes are used to dynamically configure log shipping tools on VMs.
Fluentd meetup
Fluentd meetupSadayuki Furuhashi This document provides an overview of Fluentd, an open source data collector for structured logging. Fluentd uses a pluggable architecture and JSON format for log messages, allowing logs to be filtered, buffered, and reliably forwarded to storage. It provides client libraries for integrating with applications in languages like Ruby, Perl, PHP, Python and Java. Fluentd is positioned as an alternative to other log collection systems like Scribe and Flume, with advantages of being easier to install, configure, extend with plugins, and smaller footprint.
Fluentd vs. Logstash for OpenStack Log Management
Fluentd vs. Logstash for OpenStack Log ManagementNTT Communications Technology Development The document compares two popular log collectors, Fluentd and Logstash, focusing on their features, configurations, performance, and transport protocols. Fluentd, written in cruby, uses tagged logs for routing, while Logstash, written in jruby, aggregates logs without tagging. The document also discusses integration with OpenStack, log handling, and some unique features of each log collector such as Fluentd's support for active-active load balancing.
Redis modules 101
Redis modules 101Dvir Volk The document summarizes Redis Modules and provides an overview of how to build and use Redis Modules. Some key points:
- Redis Modules allow developers to extend Redis with new commands by dynamically loading libraries written in C/C++. This provides new functionality and integrates with existing Redis data types and commands.
- The Modules API provides both high-level and low-level interfaces. The high-level API is similar to Lua but slower, while the low-level API exposes specific Redis commands and data types for better performance.
- Building a simple module involves writing a command handler, validating arguments, making Redis calls, and returning a reply. Modules are initialized via an OnLoad function and new commands can
ELK stack at weibo.com
ELK stack at weibo.com琛琳 饶 - The document discusses using the ELK stack (Elasticsearch, Logstash, Kibana) to perform real-time log search, analysis, and monitoring. It provides examples of using Logstash and Elasticsearch for parsing and indexing application logs, and using Kibana for visualization and analysis.
- The document identifies several performance and stability issues with Logstash and Elasticsearch including high CPU usage from grok filtering, GeoIP filtering performance, and Elasticsearch relocation and recovery times. It proposes solutions like custom filtering plugins, tuning Elasticsearch configuration, and optimizing mappings.
- Rsyslog is presented as an alternative to Logstash for log collection with better performance. Examples are given of using Rsyslog plugins and Rainerscript for efficient
Sessionization with Spark streaming
Sessionization with Spark streamingRamūnas Urbonas The document discusses sessionization with Spark streaming to analyze user sessions from a constant stream of page visit data. Key points include:
- Streaming page visit data presents challenges like joining new visits to ongoing sessions and handling variable data volumes and long user sessions.
- The proposed solution uses Spark streaming to join a checkpoint of incomplete sessions with new visit data to calculate session metrics in real-time.
- Important aspects are controlling data ingress size and partitioning to optimize performance of operations like joins and using custom formats to handle output to multiple sinks.
MongoDB Scalability Best Practices
MongoDB Scalability Best PracticesJason Terpko This document presents best practices for scaling MongoDB, covering key topics such as schema design, sharding, and locking mechanisms. It details vertical and horizontal scaling options, including replica sets and sharding, along with implications for performance and resource utilization. The document emphasizes the importance of selecting the right tool for specific data use cases to optimize database performance.
Tuning Elasticsearch Indexing Pipeline for Logs
Tuning Elasticsearch Indexing Pipeline for LogsSematext Group, Inc. This document summarizes techniques for optimizing Logstash and Rsyslog for high volume log ingestion into Elasticsearch. It discusses using Logstash and Rsyslog to ingest logs via TCP and JSON parsing, applying filters like grok and mutate, and outputting to Elasticsearch. It also covers Elasticsearch tuning including refresh rate, doc values, indexing performance, and using time-based indices on hot and cold nodes. Benchmark results show Logstash and Rsyslog can handle thousands of events per second with appropriate configuration.
Collect distributed application logging using fluentd (EFK stack)
Collect distributed application logging using fluentd (EFK stack)Marco Pas This document discusses using Fluentd to collect distributed application logging in a containerized environment. It provides an overview of Fluentd, including its pluggable architecture and configuration. It then demonstrates capturing logging from Docker containers and HTTP services and storing the logs in MongoDB and Elasticsearch as part of the ELK stack. It shows filtering and parsing logs from a Spring Boot application. Finally, it discusses setting up Fluentd for high availability.
Building Scalable, Distributed Job Queues with Redis and Redis::Client
Building Scalable, Distributed Job Queues with Redis and Redis::ClientMike Friedman This document discusses using Redis and the Redis::Client Perl module to build scalable distributed job queues. It provides an overview of Redis, describing it as a key-value store that is simple, fast, and open-source. It then covers the various Redis data types like strings, lists, hashes, sets and sorted sets. Examples are given of how to work with these types using Redis::Client. The document discusses using Redis lists to implement job queues, with jobs added via RPUSH and popped via BLPOP. Benchmark results show the Redis-based job queue approach significantly outperforms using a MySQL jobs table with polling. Some caveats are provided about the benchmarks.
Attack monitoring using ElasticSearch Logstash and Kibana
Attack monitoring using ElasticSearch Logstash and KibanaPrajal Kulkarni This document discusses using the ELK stack (Elasticsearch, Logstash, Kibana) for attack monitoring. It provides an overview of each component, describes how to set up ELK and configure Logstash for log collection and parsing. It also demonstrates log forwarding using Logstash Forwarder, and shows how to configure alerts and dashboards in Kibana for attack monitoring. Examples are given for parsing Apache logs and syslog using Grok filters in Logstash.
Using Apache Spark to Solve Sessionization Problem in Batch and Streaming
Using Apache Spark to Solve Sessionization Problem in Batch and StreamingDatabricks This document discusses sessionization techniques using Apache Spark batch and streaming processing. It describes using Spark to join previous session data with new log data to generate user sessions in batch mode. For streaming, it covers using watermarks and stateful processing to continuously generate sessions from streaming data. Key aspects covered include checkpointing to provide fault tolerance, configuring the state store, and techniques for reprocessing data in batch and streaming contexts.
Similar to Using MongoDB with Kafka - Use Cases and Best Practices (20)
Kafka syed academy_v1_introduction
Kafka syed academy_v1_introductionSyed Hadoop This document provides an introduction to Apache Kafka. It discusses why Kafka is needed for real-time streaming data processing and real-time analytics. It also outlines some of Kafka's key features like scalability, reliability, replication, and fault tolerance. The document summarizes common use cases for Kafka and examples of large companies that use it. Finally, it describes Kafka's core architecture including topics, partitions, producers, consumers, and how it integrates with Zookeeper.
Introduction to apache kafka
Introduction to apache kafkaSamuel Kerrien The document provides an introduction to Apache Kafka, detailing its architecture, use cases, and features such as messaging, log aggregation, and real-time processing. It highlights Kafka's scalability, durability, and performance benchmarks, along with the role of Zookeeper in managing Kafka clusters. Key recommendations for starting with Kafka, including configuration and monitoring, are also discussed.
Introduction to Apache Kafka
Introduction to Apache KafkaShiao-An Yuan This document provides an introduction to Apache Kafka. It describes Kafka as a distributed messaging system with features like durability, scalability, publish-subscribe capabilities, and ordering. It discusses key Kafka concepts like producers, consumers, topics, partitions and brokers. It also summarizes use cases for Kafka and how to implement producers and consumers in code. Finally, it briefly outlines related tools like Kafka Connect and Kafka Streams that build upon the Kafka platform.
14th Athens Big Data Meetup - Landoop Workshop - Apache Kafka Entering The St...
14th Athens Big Data Meetup - Landoop Workshop - Apache Kafka Entering The St...Athens Big Data The document provides a comprehensive overview of Kafka, a distributed pub-sub system used for real-time data pipelines and streaming applications. It details Kafka's architecture, components, and functionalities such as message production/consumption, data connectors, and integration strategies with other systems like Elasticsearch. Additionally, it offers practical setup instructions, examples, and best practices for implementation and administration within a complex infrastructure.
Apache Kafka - From zero to hero
Apache Kafka - From zero to heroApache Kafka TLV This document provides an introduction and overview of Apache Kafka. It discusses Kafka's core concepts including producers, consumers, topics, partitions and brokers. It also covers how to install and run Kafka, producer and consumer configuration settings, and how data is distributed in a Kafka cluster. Examples of creating topics, producing and consuming messages are also included.
Kafka zero to hero
Kafka zero to heroAvi Levi The document provides an introduction to Apache Kafka, a high-throughput distributed messaging system, covering core concepts such as producers, consumers, brokers, and clusters. It discusses the scaling and fault tolerance strategies like data partitioning and replication, as well as configuration settings for setting up a Kafka cluster. Additionally, it details consumer groups, message sending approaches, and configurations for both producers and consumers.
Streaming in Practice - Putting Apache Kafka in Production
Streaming in Practice - Putting Apache Kafka in Productionconfluent The document outlines a series of online talks by Roger Hoover on implementing Apache Kafka in production, covering key topics such as Kafka basics, tuning, data balancing, and multi-datacenter configurations. It discusses operational strategies, use cases, and technical considerations for deploying Kafka, including partitioning, replication, retention settings, and data balancing. The document also highlights the importance of configuring Kafka for specific application needs and provides resources for further learning.
Apache Kafka - Event Sourcing, Monitoring, Librdkafka, Scaling & Partitioning
Apache Kafka - Event Sourcing, Monitoring, Librdkafka, Scaling & PartitioningGuido Schmutz Apache Kafka is a distributed streaming platform. It provides a high-throughput distributed messaging system with publish-subscribe capabilities. The document discusses Kafka producers and consumers, Kafka clients in different programming languages, and important configuration settings for Kafka brokers and topics. It also demonstrates sending messages to Kafka topics from a Java producer and consuming messages from the console consumer.
Kafka RealTime Streaming
Kafka RealTime StreamingViyaan Jhiingade Kafka is a distributed publish-subscribe messaging system that provides high throughput and low latency for processing streaming data. It is used to handle large volumes of data in real-time by partitioning topics across multiple servers or brokers. Kafka maintains ordered and immutable logs of messages that can be consumed by subscribers. It provides features like replication, fault tolerance and scalability. Some key Kafka concepts include producers that publish messages, consumers that subscribe to topics, brokers that handle data streams, topics to categorize related messages, and partitions to distribute data loads across clusters.
Devoxx university - Kafka de haut en bas
Devoxx university - Kafka de haut en basFlorent Ramiere Kafka can be used to build real-time streaming applications and process large amounts of data. It provides a simple publish-subscribe messaging model with streams of records. Kafka Connect allows connecting Kafka with other data systems and formats through reusable connectors. Kafka Streams provides a streaming library to allow building streaming applications and processing data in Kafka streams through operators like map, filter and windowing.
Kafka internals
Kafka internalsDavid Groozman The document discusses Kafka as a high-performance data streaming and storage technology, emphasizing its architecture and the roles of brokers, controllers, and Zookeeper in managing data flow and state. It highlights key features like ordered partitioning, efficient read/write mechanisms, and the ability to handle large volumes of data with minimal latency, while comparing Kafka to traditional databases and data processing frameworks. The document concludes by describing use cases and lessons learned from implementing Kafka in real-time data processing environments.
Dissolving the Problem (Making an ACID-Compliant Database Out of Apache Kafka®)
Dissolving the Problem (Making an ACID-Compliant Database Out of Apache Kafka®)confluent The document discusses creating an acid-compliant database using Apache Kafka, explaining key concepts such as ACID properties, which include atomicity, consistency, isolation, and durability. It details Kafka's architecture, including topics, partitions, and producers/consumers, and touches on Kafka Connect and stream processing capabilities. Ultimately, it emphasizes that using Kafka involves building a database-like framework with transactional properties.
Building zero data loss pipelines with apache kafka
Building zero data loss pipelines with apache kafkaAvinash Ramineni The document discusses building zero data loss pipelines using Apache Kafka, highlighting its features like high throughput, scalability, and fault tolerance. It emphasizes the importance of monitoring, managing offsets, and implementing idempotency logic to prevent data loss during production and consumption processes. Collaboration between operations and development teams is crucial to anticipate failures and ensure seamless performance of Kafka clusters.
Kafka.pptx (uploaded from MyFiles SomnathDeb_PC)
Kafka.pptx (uploaded from MyFiles SomnathDeb_PC)somnathdeb0212 The document provides an overview of Apache Kafka, describing it as a distributed streaming platform used for building real-time data pipelines and applications. It outlines key components such as brokers, producers, consumers, topics, and partitions, as well as Kafka's APIs and replication mechanisms. Additionally, it includes installation instructions and examples of real-world applications like website activity tracking.
Kafka 0.9, Things you should know
Kafka 0.9, Things you should knowRatish Ravindran The document outlines key features and improvements in Apache Kafka 0.9, including security enhancements such as Kerberos and TLS, the introduction of Kafka Connect for importing/exporting data, and user-defined quotas for performance management. It discusses the motivation behind new consumer functionalities like group management and failure detection, as well as notable improvements such as automated replica lag tuning and no data loss in the mirror maker. Additionally, it specifies upgrade instructions from Kafka 0.8 and highlights features in Kafka 0.10.
Kafka Summit NYC 2017 Introduction to Kafka Streams with a Real-life Example
Kafka Summit NYC 2017 Introduction to Kafka Streams with a Real-life Exampleconfluent This document introduces Kafka Streams and provides an example of using it to process streaming data from Apache Kafka. It summarizes some key limitations of using Apache Spark for streaming use cases with Kafka before demonstrating how to build a simple text processing pipeline with Kafka Streams. The document also discusses parallelism, state stores, aggregations, joins and deployment considerations when using Kafka Streams. It provides an example of how Kafka Streams was used to aggregate metrics from multiple instances of an application into a single stream.
Kafka used at scale to deliver real-time notifications
Kafka used at scale to deliver real-time notificationsSérgio Nunes This document discusses using Apache Kafka at scale to deliver real-time notifications. It describes using Kafka to listen to database events, process them into transactions, translate transactions into notifications, and push notifications to mobile devices in real-time. It outlines the system architecture, challenges faced around partitioning, scaling consumers, and upgrading Kafka clients. Monitoring metrics and consumer lag is also discussed using tools like Burrow and Datadog.
Data pipeline with kafka
Data pipeline with kafkaMole Wong The document discusses the role of Apache Kafka in building data pipelines, highlighting its capabilities such as data ingestion, processing, and providing insights. It addresses various aspects of data flow, including Kafka's producer-consumer model, Kafka Connect API, and its application in handling real-time data. Additionally, it explores practical use cases of Kafka in data-driven product development and the benefits and challenges associated with its integration.
DevOps Fest 2020. Сергій Калінець. Building Data Streaming Platform with Apac...
DevOps Fest 2020. Сергій Калінець. Building Data Streaming Platform with Apac...DevOps_Fest The document discusses building a data streaming platform using Apache Kafka, which is optimized for message brokering and log-aggregation. It covers Kafka's architecture, including topics, partitions, producers, consumers, and transaction management, as well as tools like Kafka Streams and ksqlDB for stream processing and querying. The emphasis is on Kafka's configuration, data retention, and the use of connectors to integrate with external systems.
Set your Data in Motion with Confluent & Apache Kafka Tech Talk Series LME
Set your Data in Motion with Confluent & Apache Kafka Tech Talk Series LMEconfluent The Confluent Platform is an enterprise event streaming platform built around Apache Kafka, designed for dynamic performance and elasticity. It features components like brokers, Zookeeper, a schema registry, and tools for stream processing, data compatibility, and security to ensure efficient operations at scale. The platform also supports multi-region clusters and provides features for seamless integration, monitoring, and management via a comprehensive user interface.
Ad
More from Antonios Giannopoulos (6)
Comparing Geospatial Implementation in MongoDB, Postgres, and Elastic
Comparing Geospatial Implementation in MongoDB, Postgres, and ElasticAntonios Giannopoulos The document discusses the geospatial capabilities of MongoDB, PostgreSQL/PostGIS, and Elasticsearch, highlighting their differences in features like proximity searches, indexing, and best practices for implementation. MongoDB supports GeoJSON and has specific query functionalities, while PostgreSQL offers advanced spatial types and functions through PostGIS, and Elasticsearch utilizes geo field types and efficient query processes with caching. The closing remarks suggest that for heavy geospatial workloads, PostgreSQL and Elasticsearch may be more suitable than MongoDB, with PostgreSQL having the richest command set.
Percona Live 2017 - Sharded cluster tutorial
Percona Live 2017 - Sharded cluster tutorialAntonios Giannopoulos This document provides an overview of how to set up and manage a MongoDB sharded cluster. It describes the key components of a sharded cluster including shards, config servers, and mongos query routers. It then provides step-by-step instructions for deploying, upgrading, and troubleshooting a sharded cluster. The document explains how to configure shards, config servers, and mongos processes. It also outlines best practices for upgrading between minor and major versions of MongoDB.
How sitecore depends on mongo db for scalability and performance, and what it...
How sitecore depends on mongo db for scalability and performance, and what it...Antonios Giannopoulos The document discusses how Sitecore leverages MongoDB for scalability and performance, detailing best practices for integrating MongoDB with Sitecore. It emphasizes the importance of optimal configurations, such as replica sets and sharded clusters, and offers guidelines on choosing effective shard keys to enhance workload distribution. Additionally, the authors share insights from performance benchmarks comparing different MongoDB storage engines and highlight considerations for multi-region deployments.
Antonios Giannopoulos Percona 2016 WiredTiger Configuration Variables
Antonios Giannopoulos Percona 2016 WiredTiger Configuration VariablesAntonios Giannopoulos The document discusses various WiredTiger configuration variables that can be used to tune MongoDB's performance. It provides details on variables like journalCompressor, blockCompressor, prefixCompression, concurrent transactions, eviction triggers and targets, dirty triggers and targets, and eviction threads. Benchmarks are presented comparing the default settings to alternative configurations, showing impacts on load time and transactions per second.
Introduction to Polyglot Persistence
Introduction to Polyglot Persistence Antonios Giannopoulos This document discusses polyglot persistence, which refers to applications that use multiple database technologies suited to different data and access needs. It provides examples of using a relational database for transactions alongside a NoSQL key-value store for session data. The challenges of such architectures include defining the data model across databases and maintaining consistency. The document advocates choosing databases based on data structure, access patterns, and other organizational needs rather than conforming to stereotypes.
MongoDB Sharding Fundamentals
MongoDB Sharding Fundamentals Antonios Giannopoulos The document provides an overview of MongoDB sharding, including:
- Sharding allows horizontal scaling of data by partitioning a database across multiple servers or shards.
- The MongoDB sharding architecture consists of shards to hold data, config servers to store metadata, and mongos processes to route requests.
- Data is partitioned into chunks based on a shard key and chunks can move between shards as the data distribution changes.
How sitecore depends on mongo db for scalability and performance, and what it...
How sitecore depends on mongo db for scalability and performance, and what it...Antonios Giannopoulos
Ad
Recently uploaded (20)
Best Software Development at Best Prices
Best Software Development at Best Pricessoftechies7 Welcome to Softechies Solutions—your ultimate resource for all technology and software needs. We specialize in delivering expert solutions and guidance to help you tackle everyday tech challenges. We’ve got you covered, from software troubleshooting and website development to digital marketing. Whether you need technology upgrades, mobile app development, cloud-managed services, or IT consulting, Softechies Solutions is here to enhance your digital experience. https://softechies.net/
AI for PV: Development and Governance for a Regulated Industry
AI for PV: Development and Governance for a Regulated IndustryBiologit AI for pharmacovigilance: Development and Governance for a Regulated Industry.
A survey of regulatory guidance for the use of artificial intelligence in pharmacovigilance and best practices for its safe implementation with the Biologit literature platform as case study.
A Guide to Telemedicine Software Development.pdf
A Guide to Telemedicine Software Development.pdfOlivero Bozzelli Learn how telemedicine software is built from the ground up—starting with idea validation, followed by tech selection, feature integration, and deployment.
Know more about this: https://www.yesitlabs.com/a-guide-to-telemedicine-software-development/
Which Hiring Management Tools Offer the Best ROI?
Which Hiring Management Tools Offer the Best ROI?HireME In today's cost-focused world, companies must assess not just how they hire, but which hiring management tools deliver the best value for money. Learn more in PDF!
IDM Crack with Internet Download Manager 6.42 Build 41 [Latest 2025]
IDM Crack with Internet Download Manager 6.42 Build 41 [Latest 2025]pcprocore 👉Copy link &paste Google new tab > https://pcprocore.com/ 👈✅
IDM Crack with Internet Download Manager (IDM) is a tool to increase download speeds, resume, and schedule downloads.Comprehensive error recovery and resume capability will restart broken or interrupted downloads due to lost connections, network problems, computer shutdowns, or unexpected power outages. The simple graphic user interface makes IDM user-friendly and easy to use. Internet Download Manager has a smart download logic accelerator with intelligent dynamic file segmentation and safe multipart downloading technology to accelerate your downloads. Unlike other download managers and accelerators, Internet Download Manager segments downloaded files dynamically during the download process and reuses available connections without additional connect and login stages to achieve the best acceleration performance for IDM users.
System Requirements of IDM:
Operating System: Windows XP, NT, 2000, Vista, 7, 8, 8.1, 10 & 11 (32bit and 64bit)
Memory (RAM): 512 MB of RAM required
Hard Disk Space: 25 MB of free space required for full installation
Processor: Intel Pentium 4 Dual Core GHz or higher. Ensure your system meets these requirements for the IDM Crack to function properly.
How to Install and Crack:
Temporarily disable the antivirus until the IDM Crack process
Install “idman642build41.exe”
Extract “IDM 6.42.41 Patch.rar” (Password is: 123)
Install “IDM 6.42.41 Patch.exe”
Done!!! Enjoy!!!
Simplify Insurance Regulations with Compliance Management Software
Simplify Insurance Regulations with Compliance Management SoftwareInsurance Tech Services Streamline your compliance processes and stay up-to-date with changing regulations effortlessly. Our Compliance Management Software helps insurers reduce risk, avoid penalties, and maintain full compliance — all from a unified platform. Explore More - https://www.damcogroup.com/insurance/compliance-management-software
Introduction to Agile Frameworks for Product Managers.pdf
Introduction to Agile Frameworks for Product Managers.pdfAli Vahed As a Product Manager, having a solid understanding of Agile frameworks is essential, whether you are joining an established team or helping shape a new one.
Agile is not just a delivery method; it is a mind set that directly impacts how products are built, iterated, and brought to market. Knowing the strengths and trade-offs of each framework enables you to collaborate more effectively with teams, foster alignment, and drive meaningful outcomes.
Simply put, Agile fluency helps you lead with clarity in fast-paced, ever-changing environments.
The next few slides are simple ‘STUDY CARDS’ to help you learn or refresh your understanding of a few popular Agile frameworks.
Why Every Growing Business Needs a Staff Augmentation Company IN USA.pdf
Why Every Growing Business Needs a Staff Augmentation Company IN USA.pdfmary rojas U.S. staff augmentation companies excel at providing IT professionals with expertise in development, cybersecurity, AI, and more. Whether you need to fill a short-term gap or enhance your team’s capabilities long-term, these firms deliver pre-vetted talent tailored to your tech stack and industry. With an understanding of both global technologies and local compliance, U.S.-based IT staff augmentation bridges the gap between talent shortage and project demand efficiently.
Building Geospatial Data Warehouse for GIS by GIS with FME
Building Geospatial Data Warehouse for GIS by GIS with FMESafe Software Data warehouses are often considered the backbone of data-driven decision-making. However, traditional implementations can struggle to meet the iterative and dynamic demands of GIS operations, particularly for Iterative Cross-Division Data Integration (ICDI) processes. At WVDOT, we faced this challenge head-on by designing a Geospatial Data Warehouse (GDW) tailored to the needs of GIS. In this talk, we’ll share how WVDOT developed a metadata-driven, SESSI-based (Simplicity, Expandability, Spatiotemporality, Scalability, Inclusivity) GDW that transforms how we manage and leverage spatial data. Key highlights include: - Simplifying data management with a lean schema structure. - Supporting ad hoc source data variations using JSON for flexibility. - Scaling for performance with RDBMS partitioning and materialized views. - Empowering users with FME Flow-based self-service metadata tools.We’ll showcase real-world use cases, such as pavement condition data and LRS-based reporting, and discuss how this approach is elevating GIS as an integrative framework across divisions. Attendees will walk away with actionable insights on designing GIS-centric data systems that combine the best of GIS and data warehouse methodologies.
Best AI-Powered Wearable Tech for Remote Health Monitoring in 2025
Best AI-Powered Wearable Tech for Remote Health Monitoring in 2025SEOLIFT - SEO Company London Introduction In 2025, the fusion of artificial intelligence (AI) with wearable technology is redefining how we monitor health remotely. With the rise in chronic illnesses and the need for proactive health tracking, AI-powered wearables have emerged as essential tools. These devices offer real-time health insights, predictive alerts, and seamless integration with telehealth services.
Digital Transformation: Automating the Placement of Medical Interns
Digital Transformation: Automating the Placement of Medical InternsSafe Software Discover how the Health Service Executive (HSE) in Ireland has leveraged FME to implement an automated solution for its “Order of Merit” process, which assigns medical interns to their preferred placements based on applications and academic performance. This presentation will showcase how FME validates applicant data, including placement preferences and academic results, ensuring both accuracy and eligibility. It will also explore how FME automates the matching process, efficiently assigning placements to interns and distributing offer letters. Beyond this, FME actively monitors responses and dynamically reallocates placements in line with the order of merit when offers are accepted or declined. The solution also features a self-service portal (FME Flow Gallery App), enabling administrators to manage the entire process seamlessly, make adjustments, generate reports, and maintain audit logs. Additionally, the system upholds strict data security and governance, utilising FME to encrypt data both at rest and in transit.
IDM Crack with Internet Download Manager 6.42 [Latest 2025]
IDM Crack with Internet Download Manager 6.42 [Latest 2025]HyperPc soft 🌍📱👉COPY LINK & PASTE ON GOOGLEhttps://hyperpcsoft.com/ after-verification-click-go-to-download-page
The user-friendly interface makes IDM Crack 2025 easy to use. IDM Crack has a smart download logic accelerator with dynamic file segmentation and safe multipart downloading to speed up your downloads. Unlike other download managers, IDM Patch dynamically segments files during download and reuses available connections, avoiding additional connect and login stages for the best acceleration performance.
From Code to Commerce, a Backend Java Developer's Galactic Journey into Ecomm...
From Code to Commerce, a Backend Java Developer's Galactic Journey into Ecomm...Jamie Coleman In a galaxy not so far away, a Java developer advocate embarks on an epic quest into the vast universe of e-commerce. Armed with backend languages and the wisdom of microservice architectures, set out with us to learn the ways of the Force. Navigate the asteroid fields of available tools and platforms; tackle the challenge of integrating location-based technologies into open-source projects; placate the Sith Lords by enabling great customer experiences.
Follow me on this journey from humble Java coder to digital marketplace expert. Through tales of triumph and tribulation, gain valuable insights into conquering the e-commerce frontier - such as the different open-source solutions available - and learn how technology can bring balance to the business Force, large or small. May the code be with you.
Enable Your Cloud Journey With Microsoft Trusted Partner | IFI Tech
Enable Your Cloud Journey With Microsoft Trusted Partner | IFI TechIFI Techsolutions Start your cloud journey with IFI Tech—Microsoft’s trusted partner delivering secure, scalable Azure solutions tailored for your business.
OpenChain Webinar - AboutCode - Practical Compliance in One Stack – Licensing...
OpenChain Webinar - AboutCode - Practical Compliance in One Stack – Licensing...Shane Coughlan OpenChain Webinar - AboutCode - Practical Compliance in One Stack – Licensing, Vulnerabilities, and More
CodeCleaner: Mitigating Data Contamination for LLM Benchmarking
CodeCleaner: Mitigating Data Contamination for LLM Benchmarkingarabelatso The pdf-version of "CodeCleaner: Mitigating Data Contamination for LLM Benchmarking" presented in Internetware 2025.
Best Practice for LLM Serving in the Cloud
Best Practice for LLM Serving in the CloudAlluxio, Inc. Alluxio Webinar
June 17, 2025
For more Alluxio Events: https://www.alluxio.io/events/
Speaker:
Nilesh Agarwal (Co-founder & CTO @ Inferless)
Nilesh Agarwal, co-founder & CTO at Inferless, shares insights on accelerating LLM inference in the cloud using Alluxio, tackling key bottlenecks like slow model weight loading from S3 and lengthy container startup time. Inferless uses Alluxio as a three-tier cache system that dramatically cuts model load time by 10x.
Azure AI Foundry: The AI app and agent factory
Azure AI Foundry: The AI app and agent factoryMaxim Salnikov Discover how Azure AI Foundry is transforming the way organizations innovate and operate. This session explores the pivotal role of AI in reshaping business processes, enhancing employee experiences, and redefining customer engagement. Attendees will gain insights into the strategic value of AI investments, including the measurable returns and the growing momentum behind generative AI experimentation.
The talk introduces the emerging paradigm of agentic AI - intelligent agents that are revolutionizing how we build, manage, and interact with software. Through real-world examples, the session demonstrates how Azure AI Foundry empowers teams to design, customize, and scale AI applications and agents, unlocking new levels of efficiency and creativity across industries.
IObit Driver Booster Pro 12 Crack Latest Version Download
IObit Driver Booster Pro 12 Crack Latest Version Downloadpcprocore 👉𝗡𝗼𝘁𝗲:𝗖𝗼𝗽𝘆 𝗹𝗶𝗻𝗸 & 𝗽𝗮𝘀𝘁𝗲 𝗶𝗻𝘁𝗼 𝗚𝗼𝗼𝗴𝗹𝗲 𝗻𝗲𝘄 𝘁𝗮𝗯🔴▶ https://pcprocore.com/ ◀✅
IObit Driver Booster Pro is the solution. It automatically downloads and updates drivers with just one click, avoiding hardware failures, system instability, and security vulnerabilities.
ERP Systems in the UAE: Driving Business Transformation with Smart Solutions
ERP Systems in the UAE: Driving Business Transformation with Smart Solutionsdheeodoo ERP solutions are driving innovative change for businesses across the UAE through improved efficiency, reduced operational costs, and provide real-time visibility of operational data. By offering native Arabic language support, VAT compliance, and some level of cloud readiness, ERP solutions also supports and are consistent with the initiative for Smart Dubai 2030. Odoo is an example of a flexible & scalable solution. If you're looking for expert support with implementation contact Banibro. www.banibro.com
Using MongoDB with Kafka - Use Cases and Best Practices
- 1. Using MongoDB with Kafka Percona Live Online 20-21 October 2020
- 2. Antonios Giannopoulos Senior Database Administrator Pedro Albuquerque Principal Database Engineer
- 3. Agenda ● Definitions ● Use cases ● Using MongoDB as a source ● Using MongoDB as a sink ● Real world use case: Transferwise ● MongoDB to Kafka Connectors ● Takeaways
- 4. What is MongoDB? ● Document-oriented Database ● Flexible JSON-style schema Use-Cases: ● Pretty much any workload ● After version 4.0/4.2 supports ACID transactions ● Frequent schema changes
- 5. What is Apache Kafka? ● Distributed event streaming platform Use-Cases: ● Publish and subscribe to stream of events ● Async RPC-style calls between services ● Log replay ● CQRS and Event Sourcing ● Real-time analytics
- 6. How can they work together?
- 7. Use cases - Topologies MongoDB as a sink MongoDB as a source MongoDB as a source/sink
- 8. MongoDB as a Source
- 9. Selective Replication/EL/ETL MongoDB doesn’t support selective Replication Oplog or Change Streams (prefered method) Kafka cluster, with one topic per collection MongoDB to Kafka connectors
- 10. Debezium Supports both Replica-set and Sharded clusters Uses the oplog to capture and create events Selective Replication: [database|collection].[include|exclude].list EL: field.exclude.list & field.renames snapshot.mode = initial | never tasks.max initial.sync.max.threads
- 11. MongoDB Kafka Source Connector - Supports both Replica-set and Sharded clusters - Uses MongoDB Change Streams to create events - Selective Replication: - mongodb db.collection -> db.collection kafka topic - Multi-source replication: - multiple collections to single kafka topic - EL: Filter or modify change events with MongoDB aggregation pipeline - Sync historical data (copy.existing=true) - copy.existing.max.threads
- 12. MongoDB as a Sink
- 13. Throttling Throttling* (is a forbidden word but) is extremely useful: - During MongoDB scaling - Planned or unplanned maintenances - Unexpected growth events - Provides workload priorities The need for throttling: MongoDB 4.2 Flow control You can configure Flow Control on the Replica-Set level (Config settings: enableFlowControl, flowControlTargetLagSeconds) Kafka provides a more flexible “flow control” that you can easily manage * Throttling may not be suitable for every workloads
- 14. Throttling The aim is to rate limit write operations Kafka supports higher write throughput & scales faster Kafka scales: - Adding partitions - Add brokers - Add clusters - Minimal application changes MongoDB scales as well: - Adding shards - Balancing takes time - Balancing affects performance
- 15. Throttling Quotas can be applied to (user, client-id), user or client-id groups producer_byte_rate : The total rate limit for the user’s producers without a client-id quota override consumer_byte_rate : The total rate limit for the user’s consumers without a client-id quota override Static changes: /config/users/ & /config/clients (watch out the override order) Dynamic changes: > bin/kafka-configs.sh --bootstrap-server <host>:<port> --describe --entity-type users|clients --entity-name user|client-id > bin/kafka-configs.sh --bootstrap-server <host>:<port> --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048' --entity-type users|clients --entity-name user|client-id
- 16. Throttling Evaluate a MongoDB metric - Read/Write Queues , Latency etc > db.serverStatus().globalLock.currentQueue.writers 0 Prometheus Alert Manager - Tons of integrations - Groups alerts - Notify on resolution Consumer Producer kafka-configs.sh PROD or your favorite integration... Prometheus monitors Production
- 17. Workload isolation Kafka handles specific workloads better An successful event website (for example: Percona Live 2020) - Contains a stream of social media interactions - Kafka serves the raw stream - all interactions - MongoDB serves aggregated data - for example top tags Raw steam is native for Kafka as its a commit-log MongoDB rich aggregation framework provides aggregated data
- 19. Continuous aggregations Useful for use-cases that raw data are useless (or not very useful) Kafka streams is your friend - Windowing Examples: Meteo stations sending metrics every second MongoDB serves the min(),max() for every hour Website statistics - counters MongoDB gets updated every N seconds with hits summary MongoDB gets updated with hits per minute/hour
- 20. Journal Data recovery is a usual request in the databases world Human error, application bugs, hardware failures are some reasons Kafka can help on partial recovery or point in time recovery A partial data recovery may require restore of a full backup Restore changes from a full backup, Replay the changes from Kafka
- 21. Journal
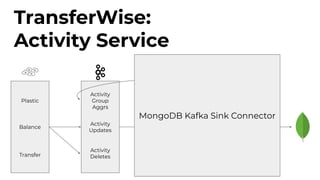
- 22. TransferWise: Activity Service ● Customer action ● Many types ● Different status ● Variety of categories ● Repository of all activities ● List of customer’s actions ● Activity list ● Ability to search and filter
- 24. spring-kafka Producer configuration private ProducerFactory<Object, Object> producerFactory(KafkaProperties kafkaProperties) { return new DefaultKafkaProducerFactory<>( Map.of( ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getServers(), ProducerConfig.CLIENT_ID_CONFIG, kafkaProperties.getClientId(), ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, JsonSerializer.class, ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class ) ); } public KafkaTemplate<Object, Object> kafkaTemplate(KafkaProperties kafkaProperties) { return new KafkaTemplate<>(producerFactory(kafkaProperties)); }
- 25. spring-kafka Send message public void send(String key, Object value, Runnable successCallback) { String jsonBody = value.getClass() == String.class ? (String) value : JSON_SERIALIZER.writeAsJson(value); kafkaTemplate.send(topic, key, jsonBody) .addCallback(new ListenableFutureCallback<>() { @Override public void onFailure(Throwable ex) { log.error("Failed sending message with key {} to {}", key, topic); } @Override public void onSuccess(SendResult<String, String> result) { successCallback.run(); } }); }
- 26. spring-kafka Consumer configuration @EnableKafka private ConsumerFactory<String, String> consumerFactory(KafkaProperties kafkaProperties) { return new DefaultKafkaConsumerFactory<>( Map.of( ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getServers(), ConsumerConfig.CLIENT_ID_CONFIG, kafkaProperties.getClientId(), ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class, ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class ));} ConcurrentKafkaListenerContainerFactory<String, String> factory = buildListenerContainerFactory(objectMapper, kafkaProperties); KafkaRetryConfig retryConfig = new KafkaRetryConfig(KafkaProducerFactory.kafkaTemplate(kafkaProperties)); @KafkaListener(topics = "${activity-service.kafka.topics.activityUpdates}", containerFactory = ActivityUpdatesKafkaListenersConfig.ACTIVITY_UPDATES_KAFKA_LISTENER_FACTORY)
- 28. name=mongodb-sink-example topics=topicA,topicB connector.class=com.mongodb.kafka.connect.MongoSinkConnector tasks.max=1 # Specific global MongoDB Sink Connector configuration connection.uri=mongodb://mongod1:27017,mongod2:27017,mongod3:27017 database=perconalive collection=slides MongoDB Kafka Sink connector: Configuration
- 29. MongoDB Kafka Sink connector: Configuration # Message types key.converter=io.confluent.connect.avro.AvroConverter key.converter.schema.registry.url=http://localhost:8081 value.converter=io.confluent.connect.avro.AvroConverter value.converter.schema.registry.url=http://localhost:8081
- 30. MongoDB Kafka Sink connector: Configuration ## Document manipulation settings [key|value].projection.type=AllowList [key|value].projection.list=name,age,address.post_code ## Id Strategy document.id.strategy=com.mongodb.kafka.connect.sink.processor.id.strategy.BsonOidStrategy post.processor.chain=com.mongodb.kafka.connect.sink.processor.DocumentIdAdder
- 31. MongoDB Kafka Sink connector: Configuration ## Dead letter queue errors.tolerance=all errors.log.enable=true errors.log.include.messages=true errors.deadletterqueue.topic.name=perconalive.deadletterqueue errors.deadletterqueue.context.headers.enable=true
- 32. Recap/Takeaways There are tons of use-cases for MongoDB & Kafka We described couple of use-cases ● Selective replication/ETL ● Throttling/Journaling/Workload Isolation Kafka has a rich ecosystem that can expand the use-cases Connectors is your friend, but you can build your own connector Large orgs like TransferWise use MongoDB & Kafka for complex projects
- 33. - Thank you!!! - - Q&A - Big thanks to: John Moore, Principal Engineer @Eventador Diego Furtado, Senior Software Engineer @TransferWise for their guidance