Using ZFS file system with MySQL
3 likes2,437 views

The document discusses ZFS (Zettabyte File System) principles and its advantages over traditional storage systems, emphasizing pooled storage, data integrity, and self-healing capabilities. It details the setup of ZFS with MySQL, including configuration steps and performance metrics, highlighting significant improvements in efficiency and speed. Challenges such as fragmentation and tuning complexities are also acknowledged, alongside the benefits of ZFS for enterprise-grade transactional systems.
1 of 23
Downloaded 28 times





















Ad
Recommended
Container Performance Analysis
Container Performance AnalysisBrendan Gregg The document summarizes a talk on container performance analysis. It discusses identifying bottlenecks at the host, container, and kernel level using various Linux performance tools. It then provides an overview of how containers work in Linux using namespaces and control groups (cgroups). Finally, it demonstrates some example commands like docker stats, systemd-cgtop, and bcc/BPF tools that can be used to analyze containers and cgroups from the host system.
HTTP Analytics for 6M requests per second using ClickHouse, by Alexander Boc...
HTTP Analytics for 6M requests per second using ClickHouse, by Alexander Boc...Altinity Ltd This document summarizes Cloudflare's use of ClickHouse to analyze over 6 million HTTP requests per second. Some key points:
- Cloudflare previously used PostgreSQL, Citus, and Flink but these did not scale sufficiently.
- ClickHouse was chosen as it is fast, scalable, fault tolerant, and Cloudflare had existing expertise in it.
- Cloudflare designed ClickHouse schemas to aggregate HTTP data into totals, breakdowns by category, and unique counts into two tables using different engines.
- Tuning ClickHouse index granularity improved query latency by 50% and throughput by 3x.
- The new ClickHouse pipeline is more scalable, fault tolerant
DB2 TABLESPACES
DB2 TABLESPACESRahul Anand This document provides a comprehensive introduction to tablespaces in DB2 databases, explaining their role as logical views of storage that house tables and indexes. It covers the concept of containers, types of tablespaces (SMS, DMS, and automatic storage), and the various operational management aspects, including commands for creation and utilization. Additionally, it discusses configuration parameters, data categorization, and how to view and manage tablespaces effectively.
Dongwon Kim – A Comparative Performance Evaluation of Flink
Dongwon Kim – A Comparative Performance Evaluation of FlinkFlink Forward This document provides a summary and analysis of a performance evaluation comparing the big data processing engine Flink to other engines like Spark, Tez, and MapReduce. The key points are:
- Flink completes a 3.2TB TeraSort benchmark faster than Spark, Tez, and MapReduce due to its pipelined execution model which allows more overlap between stages compared to the other engines.
- While Tez and Spark attempt to overlap stages, in practice they do not due to the way tasks are scheduled and launched. MapReduce shows some overlap but is still slower.
- Flink causes fewer disk accesses during shuffling by transferring data directly from memory to memory instead of writing to disk like
Linux Performance Analysis and Tools
Linux Performance Analysis and ToolsBrendan Gregg The document discusses Linux performance analysis and tools, focusing on methodologies to identify and resolve performance bottlenecks in operating systems and applications. It emphasizes the importance of understanding system limits to optimize spend and build scalable architectures, while introducing various tools for analysis such as iostat, vmstat, and top. Brendan Gregg, a lead performance engineer, outlines his approach to performance analysis in the context of cloud infrastructure and the evolving challenges faced with operating systems.
The basics of fluentd
The basics of fluentdTreasure Data, Inc. This document discusses Fluentd, an open source log collector. It provides a pluggable architecture that allows data to be collected, filtered, and forwarded to various outputs. Fluentd uses JSON format for log messages and MessagePack internally. It is reliable, scalable, and extensible through plugins. Common use cases include log aggregation, monitoring, and analytics across multiple servers and applications.
Clickhouse Capacity Planning for OLAP Workloads, Mik Kocikowski of CloudFlare
Clickhouse Capacity Planning for OLAP Workloads, Mik Kocikowski of CloudFlareAltinity Ltd The document outlines a capacity planning methodology for ClickHouse, specifically for handling OLAP workloads at Cloudflare, which processes approximately 1 petabyte of data daily. It emphasizes the necessity of benchmarking with real queries and data to accurately gauge cluster performance and optimize configuration, especially concerning primary and partitioning keys. Additionally, it discusses the importance of limiting and quota settings to manage query loads and ensure stable performance as usage scales.
Monitoring Kubernetes with Prometheus
Monitoring Kubernetes with PrometheusGrafana Labs The document discusses monitoring Kubernetes using Prometheus, a powerful monitoring and alerting system originally developed by SoundCloud. It covers key features of Prometheus, its data model, and practical examples of building queries and generating alerts based on various metrics such as CPU utilization and container performance. The document also provides resources and links for setting up Prometheus and integrating it with Kubernetes environments.
Cloud Native ClickHouse at Scale--Using the Altinity Kubernetes Operator-2022...
Cloud Native ClickHouse at Scale--Using the Altinity Kubernetes Operator-2022...Altinity Ltd The document outlines the use of the Altinity Kubernetes Operator for deploying and managing ClickHouse clusters in Kubernetes environments, detailing the installation and configuration processes, including setting up Zookeeper and defining custom resource definitions. It emphasizes the scalability and real-time analytics capabilities of ClickHouse and provides best practices for managing resources in Kubernetes, particularly focusing on storage and node configurations. Furthermore, it includes recommendations for monitoring, security, and resources for further learning about ClickHouse and Kubernetes integration.
Linux Memory Management
Linux Memory ManagementNi Zo-Ma This document discusses Linux memory management. It outlines the buddy system, zone allocation, and slab allocator used by Linux to manage physical memory. It describes how pages are allocated and initialized at boot using the memory map. The slab allocator is used to optimize allocation of kernel objects and is implemented as caches of fixed-size slabs and objects. Per-CPU allocation improves performance by reducing locking and cache invalidations.
Apache Kafka Architecture & Fundamentals Explained
Apache Kafka Architecture & Fundamentals Explainedconfluent The document outlines the fundamentals and architecture of Apache Kafka, focusing on key elements such as topics, producers, brokers, and consumers. It explains how Kafka decouples producers and consumers, leverages Zookeeper for configuration, and manages data through partitions and segments. Additionally, it provides information on training and certification opportunities for developing and administering Apache Kafka.
Linux Network Stack
Linux Network StackAdrien Mahieux - The document discusses Linux network stack monitoring and configuration. It begins with definitions of key concepts like RSS, RPS, RFS, LRO, GRO, DCA, XDP and BPF.
- It then provides an overview of how the network stack works from the hardware interrupts and driver level up through routing, TCP/IP and to the socket level.
- Monitoring tools like ethtool, ftrace and /proc/interrupts are described for viewing hardware statistics, software stack traces and interrupt information.
YugaByte DB Internals - Storage Engine and Transactions
YugaByte DB Internals - Storage Engine and Transactions Yugabyte This document introduces YugaByte DB, a high-performance, distributed, transactional database. It is built to scale horizontally on commodity servers across data centers for mission-critical applications. YugaByte DB uses a transactional document store based on RocksDB, Raft-based replication for resilience, and automatic sharding and rebalancing. It supports ACID transactions across documents, provides APIs compatible with Cassandra and Redis, and is open source. The architecture is designed for high performance, strong consistency, and cloud-native deployment.
The evolution of Netflix's S3 data warehouse (Strata NY 2018)
The evolution of Netflix's S3 data warehouse (Strata NY 2018)Ryan Blue The document discusses Netflix’s evolution of its S3 data warehouse architecture, highlighting the use of Iceberg tables for efficient data organization, snapshot isolation, and atomic operations. It covers challenges related to S3 as a file system, performance issues, and the importance of reliable metadata tracking. The presentation concludes with insights into enhancements in data handling and the benefits of an optimized data platform for big data applications.
High Availability PostgreSQL with Zalando Patroni
High Availability PostgreSQL with Zalando PatroniZalando Technology The document discusses the high availability of PostgreSQL using Patroni, including master election, streaming replication, and failover management. It explains components like etcd for leader election and consensus, configuration parameters for Patroni, and the use of pg_rewind for recovering from master failures. Additionally, it outlines the implementation details and provides guidance on setting up the system, including HAProxy configuration and user-defined scripts.
Introduction to Kafka Cruise Control
Introduction to Kafka Cruise ControlJiangjie Qin The document provides an overview of Kafka Cruise Control, which addresses operational challenges in Kafka deployments, including dynamic workload balancing and resource utilization across brokers. It outlines the complexity of balancing workloads, the goals for success in this area, and the system architecture of Kafka Cruise Control. Additionally, it discusses key challenges such as workload modeling, optimization resolution, and failure detection.
Anatomy of a Container: Namespaces, cgroups & Some Filesystem Magic - LinuxCon
Anatomy of a Container: Namespaces, cgroups & Some Filesystem Magic - LinuxConJérôme Petazzoni The document outlines the anatomy and implementation of containers in computing, detailing components like namespaces, control groups (cgroups), and copy-on-write storage. It discusses the differences between containers and virtual machines, with insights into how containers manage resources and isolate processes. Furthermore, it explores various container runtimes such as Docker, LXC, and rkt, along with other related technologies.
Top 5 Mistakes When Writing Spark Applications
Top 5 Mistakes When Writing Spark ApplicationsSpark Summit This document discusses 5 common mistakes when writing Spark applications:
1) Improperly sizing executors by not considering cores, memory, and overhead. The optimal configuration depends on the workload and cluster resources.
2) Applications failing due to shuffle blocks exceeding 2GB size limit. Increasing the number of partitions helps address this.
3) Jobs running slowly due to data skew in joins and shuffles. Techniques like salting keys can help address skew.
4) Not properly managing the DAG to avoid shuffles and bring work to the data. Using ReduceByKey over GroupByKey and TreeReduce over Reduce when possible.
5) Classpath conflicts arising from mismatched library versions, which can be addressed using sh
Kvm performance optimization for ubuntu
Kvm performance optimization for ubuntuSim Janghoon This document discusses various techniques for optimizing KVM performance on Linux systems. It covers CPU and memory optimization through techniques like vCPU pinning, NUMA affinity, transparent huge pages, KSM, and virtio_balloon. For networking, it discusses vhost-net, interrupt handling using MSI/MSI-X, and NAPI. It also covers block device optimization through I/O scheduling, cache mode, and asynchronous I/O. The goal is to provide guidance on configuring these techniques for workloads running in KVM virtual machines.
Amazon S3 Best Practice and Tuning for Hadoop/Spark in the Cloud
Amazon S3 Best Practice and Tuning for Hadoop/Spark in the CloudNoritaka Sekiyama This document provides an overview and summary of Amazon S3 best practices and tuning for Hadoop/Spark in the cloud. It discusses the relationship between Hadoop/Spark and S3, the differences between HDFS and S3 and their use cases, details on how S3 behaves from the perspective of Hadoop/Spark, well-known pitfalls and tunings related to S3 consistency and multipart uploads, and recent community activities related to S3. The presentation aims to help users optimize their use of S3 storage with Hadoop/Spark frameworks.
Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안
Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안SANG WON PARK Apache Kafak의 빅데이터 아키텍처에서 역할이 점차 커지고, 중요한 비중을 차지하게 되면서, 성능에 대한 고민도 늘어나고 있다.
다양한 프로젝트를 진행하면서 Apache Kafka를 모니터링 하기 위해 필요한 Metrics들을 이해하고, 이를 최적화 하기 위한 Configruation 설정을 정리해 보았다.
[Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안]
Apache Kafka 성능 모니터링에 필요한 metrics에 대해 이해하고, 4가지 관점(처리량, 지연, Durability, 가용성)에서 성능을 최적화 하는 방안을 정리함. Kafka를 구성하는 3개 모듈(Producer, Broker, Consumer)별로 성능 최적화를 위한 …
[Apache Kafka 모니터링을 위한 Metrics 이해]
Apache Kafka의 상태를 모니터링 하기 위해서는 4개(System(OS), Producer, Broker, Consumer)에서 발생하는 metrics들을 살펴봐야 한다.
이번 글에서는 JVM에서 제공하는 JMX metrics를 중심으로 producer/broker/consumer의 지표를 정리하였다.
모든 지표를 정리하진 않았고, 내 관점에서 유의미한 지표들을 중심으로 이해한 내용임
[Apache Kafka 성능 Configuration 최적화]
성능목표를 4개로 구분(Throughtput, Latency, Durability, Avalibility)하고, 각 목표에 따라 어떤 Kafka configuration의 조정을 어떻게 해야하는지 정리하였다.
튜닝한 파라미터를 적용한 후, 성능테스트를 수행하면서 추출된 Metrics를 모니터링하여 현재 업무에 최적화 되도록 최적화를 수행하는 것이 필요하다.
M|18 Architectural Overview: MariaDB MaxScale
M|18 Architectural Overview: MariaDB MaxScaleMariaDB plc MaxScale uses an asynchronous and multi-threaded architecture to route client queries to backend database servers. Each thread creates its own epoll instance to monitor file descriptors for I/O events, avoiding locking between threads. Listening sockets are added to a global epoll file descriptor that notifies threads when clients connect, allowing connections to be distributed evenly across threads. This architecture improves performance over the previous single epoll instance approach.
Building flexible ETL pipelines with Apache Camel on Quarkus
Building flexible ETL pipelines with Apache Camel on QuarkusIvelin Yanev This document discusses building flexible ETL pipelines with Apache Camel on Quarkus. It begins with an overview of what ETL is and the extract, transform, load process. It then discusses what Apache Camel is and how it is an open source integration framework that allows defining routing and mediation rules. The document introduces Camel K and Camel Quarkus, noting that Camel Quarkus brings Camel's integration capabilities to the Quarkus runtime. It argues that Apache Camel and Quarkus is a good combination for efficient ETL due to Camel's easy learning curve and extensibility and Quarkus' benefits like low memory usage and fast startup times. The document concludes with a demo
Cassandra Introduction & Features
Cassandra Introduction & FeaturesDataStax Academy Apache Cassandra is an open-source, distributed, decentralized, and highly available database characterized by elastic scalability and tunable consistency, originally developed at Facebook. Key features include a column-oriented key-value store, a SQL-like query interface (CQL), and optimized high performance suitable for large-scale applications. Notable users like eBay employ Cassandra for various applications, including fraud detection and real-time insights.
Cosco: An Efficient Facebook-Scale Shuffle Service
Cosco: An Efficient Facebook-Scale Shuffle ServiceDatabricks COSCO is a shuffle service designed to enhance efficiency in large-scale data processing, particularly on spinning disks. It addresses issues related to write amplification and small input/output sizes, achieving notable improvements in disk service times for Hive and Spark workloads. The service is in production for over a year, demonstrating significant efficiency gains and plans for broader rollout.
ClickHouse Materialized Views: The Magic Continues
ClickHouse Materialized Views: The Magic ContinuesAltinity Ltd The document introduces ClickHouse, a high-performance columnar database management system, and details the use of materialized views to optimize query performance and data aggregation. It demonstrates through examples how materialized views can significantly enhance the speed of querying large datasets, such as calculating average taxi passengers in New York City and tracking CPU utilization. Additionally, it covers various techniques for creating and managing materialized views to automate data transformations and improve efficiency in real-time data scenarios.
Cgroups, namespaces, and beyond: what are containers made from? (DockerCon Eu...
Cgroups, namespaces, and beyond: what are containers made from? (DockerCon Eu...Jérôme Petazzoni Jérôme Petazzoni discusses container technology, focusing on the fundamental components such as cgroups and namespaces that enable lightweight virtualization. He outlines how containers differ from traditional virtual machines, their implementation in the Linux kernel, and the various container runtimes available. Additionally, Petazzoni highlights practical applications and configuration examples for managing resources and processes within containers.
Kafka monitoring using Prometheus and Grafana
Kafka monitoring using Prometheus and Grafanawonyong hwang Kafka Cluster를 모니터링 하기 위한 Prometheus 설정을 가이드하고, 이를 시각화하기 위해 Grafana를 연동하는 방법을 설명합니다.
Guide Prometheus settings for monitoring the Kafka Cluster and explain how to work with Grafana to visualize them.
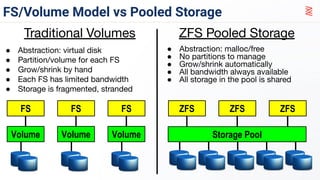
ZFS and MySQL on Linux, the Sweet Spots
ZFS and MySQL on Linux, the Sweet SpotsJervin Real The document discusses using ZFS as the storage backend for MySQL and Percona XtraDB Cluster. It finds that while ZFS can provide reliable storage, encryption, compression and backups for MySQL, direct performance is limited by disk throughput. Adding an NVMe SLOG helps improve performance for a large MySQL dataset, but is still limited by the underlying storage. ZFS snapshots provide an alternative to XtraBackup for state snapshot transfers in Percona XtraDB Cluster that keeps the donor node available. Testing backups with ZFS snapshots on MySQL shows initial steady performance, but degradation over time as reads saturate the disks.
PostgreSQL + ZFS best practices
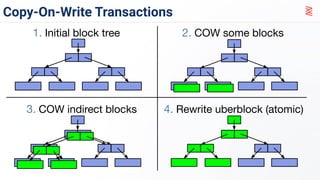
PostgreSQL + ZFS best practicesSean Chittenden ZFS provides several advantages over traditional block-based filesystems when used with PostgreSQL, including preventing bitrot, improved compression ratios, and write locality. ZFS uses copy-on-write and transactional semantics to ensure data integrity and allow for snapshots and clones. Proper configuration such as enabling compression and using ZFS features like intent logging can optimize performance when used with PostgreSQL's workloads.
More Related Content
What's hot (20)
Cloud Native ClickHouse at Scale--Using the Altinity Kubernetes Operator-2022...
Cloud Native ClickHouse at Scale--Using the Altinity Kubernetes Operator-2022...Altinity Ltd The document outlines the use of the Altinity Kubernetes Operator for deploying and managing ClickHouse clusters in Kubernetes environments, detailing the installation and configuration processes, including setting up Zookeeper and defining custom resource definitions. It emphasizes the scalability and real-time analytics capabilities of ClickHouse and provides best practices for managing resources in Kubernetes, particularly focusing on storage and node configurations. Furthermore, it includes recommendations for monitoring, security, and resources for further learning about ClickHouse and Kubernetes integration.
Linux Memory Management
Linux Memory ManagementNi Zo-Ma This document discusses Linux memory management. It outlines the buddy system, zone allocation, and slab allocator used by Linux to manage physical memory. It describes how pages are allocated and initialized at boot using the memory map. The slab allocator is used to optimize allocation of kernel objects and is implemented as caches of fixed-size slabs and objects. Per-CPU allocation improves performance by reducing locking and cache invalidations.
Apache Kafka Architecture & Fundamentals Explained
Apache Kafka Architecture & Fundamentals Explainedconfluent The document outlines the fundamentals and architecture of Apache Kafka, focusing on key elements such as topics, producers, brokers, and consumers. It explains how Kafka decouples producers and consumers, leverages Zookeeper for configuration, and manages data through partitions and segments. Additionally, it provides information on training and certification opportunities for developing and administering Apache Kafka.
Linux Network Stack
Linux Network StackAdrien Mahieux - The document discusses Linux network stack monitoring and configuration. It begins with definitions of key concepts like RSS, RPS, RFS, LRO, GRO, DCA, XDP and BPF.
- It then provides an overview of how the network stack works from the hardware interrupts and driver level up through routing, TCP/IP and to the socket level.
- Monitoring tools like ethtool, ftrace and /proc/interrupts are described for viewing hardware statistics, software stack traces and interrupt information.
YugaByte DB Internals - Storage Engine and Transactions
YugaByte DB Internals - Storage Engine and Transactions Yugabyte This document introduces YugaByte DB, a high-performance, distributed, transactional database. It is built to scale horizontally on commodity servers across data centers for mission-critical applications. YugaByte DB uses a transactional document store based on RocksDB, Raft-based replication for resilience, and automatic sharding and rebalancing. It supports ACID transactions across documents, provides APIs compatible with Cassandra and Redis, and is open source. The architecture is designed for high performance, strong consistency, and cloud-native deployment.
The evolution of Netflix's S3 data warehouse (Strata NY 2018)
The evolution of Netflix's S3 data warehouse (Strata NY 2018)Ryan Blue The document discusses Netflix’s evolution of its S3 data warehouse architecture, highlighting the use of Iceberg tables for efficient data organization, snapshot isolation, and atomic operations. It covers challenges related to S3 as a file system, performance issues, and the importance of reliable metadata tracking. The presentation concludes with insights into enhancements in data handling and the benefits of an optimized data platform for big data applications.
High Availability PostgreSQL with Zalando Patroni
High Availability PostgreSQL with Zalando PatroniZalando Technology The document discusses the high availability of PostgreSQL using Patroni, including master election, streaming replication, and failover management. It explains components like etcd for leader election and consensus, configuration parameters for Patroni, and the use of pg_rewind for recovering from master failures. Additionally, it outlines the implementation details and provides guidance on setting up the system, including HAProxy configuration and user-defined scripts.
Introduction to Kafka Cruise Control
Introduction to Kafka Cruise ControlJiangjie Qin The document provides an overview of Kafka Cruise Control, which addresses operational challenges in Kafka deployments, including dynamic workload balancing and resource utilization across brokers. It outlines the complexity of balancing workloads, the goals for success in this area, and the system architecture of Kafka Cruise Control. Additionally, it discusses key challenges such as workload modeling, optimization resolution, and failure detection.
Anatomy of a Container: Namespaces, cgroups & Some Filesystem Magic - LinuxCon
Anatomy of a Container: Namespaces, cgroups & Some Filesystem Magic - LinuxConJérôme Petazzoni The document outlines the anatomy and implementation of containers in computing, detailing components like namespaces, control groups (cgroups), and copy-on-write storage. It discusses the differences between containers and virtual machines, with insights into how containers manage resources and isolate processes. Furthermore, it explores various container runtimes such as Docker, LXC, and rkt, along with other related technologies.
Top 5 Mistakes When Writing Spark Applications
Top 5 Mistakes When Writing Spark ApplicationsSpark Summit This document discusses 5 common mistakes when writing Spark applications:
1) Improperly sizing executors by not considering cores, memory, and overhead. The optimal configuration depends on the workload and cluster resources.
2) Applications failing due to shuffle blocks exceeding 2GB size limit. Increasing the number of partitions helps address this.
3) Jobs running slowly due to data skew in joins and shuffles. Techniques like salting keys can help address skew.
4) Not properly managing the DAG to avoid shuffles and bring work to the data. Using ReduceByKey over GroupByKey and TreeReduce over Reduce when possible.
5) Classpath conflicts arising from mismatched library versions, which can be addressed using sh
Kvm performance optimization for ubuntu
Kvm performance optimization for ubuntuSim Janghoon This document discusses various techniques for optimizing KVM performance on Linux systems. It covers CPU and memory optimization through techniques like vCPU pinning, NUMA affinity, transparent huge pages, KSM, and virtio_balloon. For networking, it discusses vhost-net, interrupt handling using MSI/MSI-X, and NAPI. It also covers block device optimization through I/O scheduling, cache mode, and asynchronous I/O. The goal is to provide guidance on configuring these techniques for workloads running in KVM virtual machines.
Amazon S3 Best Practice and Tuning for Hadoop/Spark in the Cloud
Amazon S3 Best Practice and Tuning for Hadoop/Spark in the CloudNoritaka Sekiyama This document provides an overview and summary of Amazon S3 best practices and tuning for Hadoop/Spark in the cloud. It discusses the relationship between Hadoop/Spark and S3, the differences between HDFS and S3 and their use cases, details on how S3 behaves from the perspective of Hadoop/Spark, well-known pitfalls and tunings related to S3 consistency and multipart uploads, and recent community activities related to S3. The presentation aims to help users optimize their use of S3 storage with Hadoop/Spark frameworks.
Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안
Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안SANG WON PARK Apache Kafak의 빅데이터 아키텍처에서 역할이 점차 커지고, 중요한 비중을 차지하게 되면서, 성능에 대한 고민도 늘어나고 있다.
다양한 프로젝트를 진행하면서 Apache Kafka를 모니터링 하기 위해 필요한 Metrics들을 이해하고, 이를 최적화 하기 위한 Configruation 설정을 정리해 보았다.
[Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안]
Apache Kafka 성능 모니터링에 필요한 metrics에 대해 이해하고, 4가지 관점(처리량, 지연, Durability, 가용성)에서 성능을 최적화 하는 방안을 정리함. Kafka를 구성하는 3개 모듈(Producer, Broker, Consumer)별로 성능 최적화를 위한 …
[Apache Kafka 모니터링을 위한 Metrics 이해]
Apache Kafka의 상태를 모니터링 하기 위해서는 4개(System(OS), Producer, Broker, Consumer)에서 발생하는 metrics들을 살펴봐야 한다.
이번 글에서는 JVM에서 제공하는 JMX metrics를 중심으로 producer/broker/consumer의 지표를 정리하였다.
모든 지표를 정리하진 않았고, 내 관점에서 유의미한 지표들을 중심으로 이해한 내용임
[Apache Kafka 성능 Configuration 최적화]
성능목표를 4개로 구분(Throughtput, Latency, Durability, Avalibility)하고, 각 목표에 따라 어떤 Kafka configuration의 조정을 어떻게 해야하는지 정리하였다.
튜닝한 파라미터를 적용한 후, 성능테스트를 수행하면서 추출된 Metrics를 모니터링하여 현재 업무에 최적화 되도록 최적화를 수행하는 것이 필요하다.
M|18 Architectural Overview: MariaDB MaxScale
M|18 Architectural Overview: MariaDB MaxScaleMariaDB plc MaxScale uses an asynchronous and multi-threaded architecture to route client queries to backend database servers. Each thread creates its own epoll instance to monitor file descriptors for I/O events, avoiding locking between threads. Listening sockets are added to a global epoll file descriptor that notifies threads when clients connect, allowing connections to be distributed evenly across threads. This architecture improves performance over the previous single epoll instance approach.
Building flexible ETL pipelines with Apache Camel on Quarkus
Building flexible ETL pipelines with Apache Camel on QuarkusIvelin Yanev This document discusses building flexible ETL pipelines with Apache Camel on Quarkus. It begins with an overview of what ETL is and the extract, transform, load process. It then discusses what Apache Camel is and how it is an open source integration framework that allows defining routing and mediation rules. The document introduces Camel K and Camel Quarkus, noting that Camel Quarkus brings Camel's integration capabilities to the Quarkus runtime. It argues that Apache Camel and Quarkus is a good combination for efficient ETL due to Camel's easy learning curve and extensibility and Quarkus' benefits like low memory usage and fast startup times. The document concludes with a demo
Cassandra Introduction & Features
Cassandra Introduction & FeaturesDataStax Academy Apache Cassandra is an open-source, distributed, decentralized, and highly available database characterized by elastic scalability and tunable consistency, originally developed at Facebook. Key features include a column-oriented key-value store, a SQL-like query interface (CQL), and optimized high performance suitable for large-scale applications. Notable users like eBay employ Cassandra for various applications, including fraud detection and real-time insights.
Cosco: An Efficient Facebook-Scale Shuffle Service
Cosco: An Efficient Facebook-Scale Shuffle ServiceDatabricks COSCO is a shuffle service designed to enhance efficiency in large-scale data processing, particularly on spinning disks. It addresses issues related to write amplification and small input/output sizes, achieving notable improvements in disk service times for Hive and Spark workloads. The service is in production for over a year, demonstrating significant efficiency gains and plans for broader rollout.
ClickHouse Materialized Views: The Magic Continues
ClickHouse Materialized Views: The Magic ContinuesAltinity Ltd The document introduces ClickHouse, a high-performance columnar database management system, and details the use of materialized views to optimize query performance and data aggregation. It demonstrates through examples how materialized views can significantly enhance the speed of querying large datasets, such as calculating average taxi passengers in New York City and tracking CPU utilization. Additionally, it covers various techniques for creating and managing materialized views to automate data transformations and improve efficiency in real-time data scenarios.
Cgroups, namespaces, and beyond: what are containers made from? (DockerCon Eu...
Cgroups, namespaces, and beyond: what are containers made from? (DockerCon Eu...Jérôme Petazzoni Jérôme Petazzoni discusses container technology, focusing on the fundamental components such as cgroups and namespaces that enable lightweight virtualization. He outlines how containers differ from traditional virtual machines, their implementation in the Linux kernel, and the various container runtimes available. Additionally, Petazzoni highlights practical applications and configuration examples for managing resources and processes within containers.
Kafka monitoring using Prometheus and Grafana
Kafka monitoring using Prometheus and Grafanawonyong hwang Kafka Cluster를 모니터링 하기 위한 Prometheus 설정을 가이드하고, 이를 시각화하기 위해 Grafana를 연동하는 방법을 설명합니다.
Guide Prometheus settings for monitoring the Kafka Cluster and explain how to work with Grafana to visualize them.
Similar to Using ZFS file system with MySQL (20)
ZFS and MySQL on Linux, the Sweet Spots
ZFS and MySQL on Linux, the Sweet SpotsJervin Real The document discusses using ZFS as the storage backend for MySQL and Percona XtraDB Cluster. It finds that while ZFS can provide reliable storage, encryption, compression and backups for MySQL, direct performance is limited by disk throughput. Adding an NVMe SLOG helps improve performance for a large MySQL dataset, but is still limited by the underlying storage. ZFS snapshots provide an alternative to XtraBackup for state snapshot transfers in Percona XtraDB Cluster that keeps the donor node available. Testing backups with ZFS snapshots on MySQL shows initial steady performance, but degradation over time as reads saturate the disks.
PostgreSQL + ZFS best practices
PostgreSQL + ZFS best practicesSean Chittenden ZFS provides several advantages over traditional block-based filesystems when used with PostgreSQL, including preventing bitrot, improved compression ratios, and write locality. ZFS uses copy-on-write and transactional semantics to ensure data integrity and allow for snapshots and clones. Proper configuration such as enabling compression and using ZFS features like intent logging can optimize performance when used with PostgreSQL's workloads.
ZFS in 30 minutes
ZFS in 30 minutesWilliam Hathaway ZFS is a modern file system that provides data integrity through checksums and a copy-on-write design. It simplifies storage administration with a pooled model where space can be shared across file systems. ZFS supports features like snapshots, clones, compression, and deduplication. It can leverage solid state drives for caching and improve performance.
Zfs intro v2
Zfs intro v2Eric Sproul ZFS is a combined filesystem, volume manager, and RAID controller that provides immense storage capacity, simplifies administration, and ensures data integrity. It uses copy-on-write to prevent data corruption and supports features like snapshots, clones, replication, compression, and sharing data over NAS and SAN protocols. ZFS organizes storage into pools composed of virtual devices that provide fault tolerance and high performance.
MySQL on ZFS
MySQL on ZFSGordan Bobic The document discusses the benefits and configurations of using InnoDB on ZFS, outlining aspects such as disk geometry, file system options, and MySQL configurations. It highlights improvements in performance, efficient backups, and self-healing capabilities of ZFS, with specific performance metrics compared to traditional RAID setups. The recommendations include tuning parameters to optimize performance and avoid potential issues with disk sector sizes.
ZFS by PWR 2013
ZFS by PWR 2013pwrsoft ZFS is a file system developed by Sun Microsystems that provides advanced storage capabilities such as data integrity checking, snapshots and cloning. Some key features of ZFS include using copy-on-write storage, end-to-end checksumming of data to prevent silent data corruption, transactional semantics for consistency, and pooled storage that allows for thin provisioning and easy management of storage resources. ZFS aims to eliminate many of the issues with traditional file systems through its novel approach to data storage and management.
Vancouver bug enterprise storage and zfs
Vancouver bug enterprise storage and zfsRami Jebara This document provides an overview of enterprise storage needs and introduces the ZFS file system. It discusses typical enterprise storage requirements, components, tiers, and concerns. It then provides a brief history of ZFS, introduces key concepts like storage pools, datasets, snapshots, replication, and more. It offers tips for preparing ZFS for production and highlights emerging trends, resources for learning more, and examples of tools that use ZFS.
OSDC 2016 - Interesting things you can do with ZFS by Allan Jude&Benedict Reu...
OSDC 2016 - Interesting things you can do with ZFS by Allan Jude&Benedict Reu...NETWAYS The document discusses the capabilities and features of ZFS, a robust file system designed for data integrity and storage management, developed originally by Sun Microsystems. It covers key aspects such as combined volume management, self-healing properties, advanced snapshot capabilities, compression, and deduplication, along with real-world use cases and best practices for system administrators. Additionally, upcoming features of ZFS and resources for further reading are highlighted.
ZFS
ZFSMarc Seeger ZFS is a new type of file system that provides simple administration, transactional semantics, end-to-end data integrity, and immense scalability. It uses a pooled storage model that eliminates volumes and partitions, and associated problems. All operations are copy-on-write transactions to keep the on-disk state valid. ZFS provides data integrity through checksumming, self-healing capabilities, and disk scrubbing to detect and repair errors. It is highly scalable with no limits on file systems, files per directory, or other aspects. Snapshots provide space-efficient incremental backups. ZFS delivers improved performance through pipelined I/O and built-in compression.
ZFS Talk Part 1
ZFS Talk Part 1Steven Burgess The document provides an overview of ZFS, a modern file system designed for large-scale data integrity, emphasizing its capabilities such as extensive storage capacity, error overcoming through checksumming, and easy maintenance. It highlights features like snapshotting, replication, and the ability to treat disk storage more like RAM, along with various command usage for ZFS management. The document also discusses the importance of storage media reliability and includes specific commands and configurations to utilize ZFS effectively.
An Introduction to the Implementation of ZFS by Kirk McKusick
An Introduction to the Implementation of ZFS by Kirk McKusickeurobsdcon This document introduces the Zettabyte File System (ZFS), outlining its key features like consistent state management, snapshots, data compression, and storage pooling. It details the structural organization of ZFS, highlighting its object-set management and block handling mechanisms, as well as its strengths and weaknesses in terms of performance and complexity. Additionally, it references resources for further information on ZFS implementation and management.
Infrastructure review - Shining a light on the Black Box
Infrastructure review - Shining a light on the Black BoxMiklos Szel The document summarizes Miklos Szel's presentation from Percona Live Europe 2016, covering topics such as server inventory, configuration management, monitoring, backup strategies, and database schema design. It details practical tools and techniques for identifying and optimizing MySQL servers, emphasizes the importance of primary keys, and explains best practices for using EBS snapshots for backups. Additionally, it discusses performance considerations and user management in MySQL environments.
PostgreSQL on EXT4, XFS, BTRFS and ZFS
PostgreSQL on EXT4, XFS, BTRFS and ZFSTomas Vondra The document presents a comparative analysis of various file systems for PostgreSQL, particularly focusing on ext3/4, xfs, btrfs, and zfs. It discusses their stability, performance benchmarks, and suitability for production use, highlighting differences in design and features. The findings indicate that while traditional file systems are reliable, next-gen options like btrfs and zfs offer enhanced functionalities like snapshots and compression, albeit with some performance trade-offs.
ZFS on the server and the desktop: N+1 ways to better store your data
ZFS on the server and the desktop: N+1 ways to better store your dataMatthias van der Heide ZFS is an open source file system and volume manager that provides features like unlimited capacity, data integrity checking, snapshots and clones. The presentation discusses N+1 ways to better use ZFS including designing storage pools with redundancy, testing pool performance, tuning the filesystem, and maintaining the system through scrubs and resilvering. Reasons for using ZFS in DevOps environments are also provided, such as performance, scalability, replication abilities, and using snapshots for deployments and backups.
ZFS: The Last Word in Filesystems
ZFS: The Last Word in FilesystemsJarod Wang ZFS is a new file system that provides pooled storage, transactional semantics, end-to-end data integrity, and simple administration. It eliminates volumes and provides unlimited storage that grows automatically. ZFS uses copy-on-write transactions and birth time tracking for constant-time unlimited snapshots without performance penalties. Its design blows away 20 years of obsolete assumptions around file systems and storage.
Terror & Hysteria: Cost Effective Scaling of Time Series Data with Cassandra ...
Terror & Hysteria: Cost Effective Scaling of Time Series Data with Cassandra ...DataStax This document discusses Cassandra time series data challenges and Threat Stack's solutions. Typical problems include disks filling quickly and data losing value over time. Threat Stack handles 5-10TB of data daily with 80,000-150,000 transactions per second. They developed their own MTCS compaction strategy and sstablejanitor tool to better handle time series data expiration in Cassandra by unlinking expired SSTables. This allows them to analyze large volumes of real-time security event data cost effectively at scale.
PostgreSQL na EXT4, XFS, BTRFS a ZFS / FOSDEM PgDay 2016
PostgreSQL na EXT4, XFS, BTRFS a ZFS / FOSDEM PgDay 2016Tomas Vondra The document provides an overview of different file systems for PostgreSQL including EXT3/4, XFS, BTRFS and ZFS. It discusses the evolution and improvements made to EXT3/4 and XFS over time to address scalability, bugs and new storage technologies like SSDs. BTRFS and ZFS are described as designed for large data volumes and built-in features like snapshots and checksums but BTRFS is still considered experimental. Benchmark results show ZFS and optimized EXT4/XFS performing best and BTRFS performance significantly reduced due to copy-on-write. The conclusion recommends EXT4/XFS for traditional needs and ZFS for advanced features, avoiding BTRFS.
Bsdtw17: allan jude: zfs: advanced integration
Bsdtw17: allan jude: zfs: advanced integrationScott Tsai Allan Jude provides an overview of ZFS and its advanced integration capabilities. Key points include:
- ZFS is a built-in volume manager that provides checksumming, compression, snapshots, clones and tunable properties across storage pools and filesystems.
- Snapshots and clones allow instant copies of data with almost no additional space usage and no performance impact as more are taken.
- Boot environments enable upgrading operating systems without fear of failure by booting from snapshots.
- Deep boot environments integrate source and object directories into boot environments for increased development flexibility and performance.
- ZFS sends and receives allow replicating golden images of server configurations across machines quickly and efficiently.
ZFS Workshop
ZFS WorkshopAPNIC ZFS is a filesystem that provides end-to-end data integrity and reliability through the use of checksums, copy-on-write transactions, and pooled storage. Key features include detecting and correcting silent data corruption, eliminating volumes in favor of pooled storage, and providing a transactional design with consistent data. Administration is simplified with only two commands needed to manage the entire storage configuration.
Kafka on ZFS: Better Living Through Filesystems
Kafka on ZFS: Better Living Through Filesystems confluent The document discusses the benefits of using ZFS with Kafka, highlighting that ZFS improves Kafka's performance and cost-effectiveness through enhanced filesystem caching and efficient use of I/O devices. It explains how Kafka operates differently from Redis and details various I/O modes and cache management strategies. The author emphasizes key ZFS features such as automatic checksumming, compression, and advanced caching mechanisms that contribute to optimized data handling for Kafka applications.
Ad
More from Mydbops (20)
Scaling TiDB for Large-Scale Application
Scaling TiDB for Large-Scale ApplicationMydbops Mydbops MyWebinar 42: Scaling TiDB for Large-Scale Applications
Presenter: Kabilesh P.R., Founding Partner, Mydbops
Is your database slowing down as your business grows?
Scaling databases is a challenge, especially when dealing with high traffic and large workloads. TiDB is designed for scalability, but without the right approach, you may face slow queries, downtime, and migration hurdles.
Join Kabilesh P.R. as he shares real-world use cases, proven strategies, and common pitfalls in scaling TiDB for large applications. This session will help you understand how to optimize performance, improve reliability, and scale seamlessly.
What You'll Learn:
* How to scale TiDB efficiently for large applications
* Common mistakes in scaling and how to avoid them
* Real-world case studies of successful migrations
* Best practices for maintaining performance and reliability
https://www.mydbops.com/
[email protected]
AWS MySQL Showdown - RDS vs RDS Multi AZ vs Aurora vs Serverless - Mydbops...
AWS MySQL Showdown - RDS vs RDS Multi AZ vs Aurora vs Serverless - Mydbops...Mydbops AWS MySQL Showdown - RDS vs RDS Multi AZ vs Aurora vs Serverless - Mydbops Webinar 41
Key takeaways:
* Performance & Scalability – How each service handles workloads
* High Availability & Failover – Ensuring uptime and reliability
* Cost & Efficiency – Which solution gives the best value
* Architecture Deep Dive – Comparing Multi-AZ RDS and Aurora’s distributed model
Who Should Attend?
* Database Architects & Engineers
* DevOps & Cloud Professionals
* CTOs & Tech Decision-Makers
Don't miss out!
#aws #mysql #rds #aurora #serverless #cloud #database #scalability #highavailability #performance #cloudcomputing #devops #tech #engineering #webinar #automation #costoptimization #failover #replication #opensource #datamanagement #cloudarchitecture #cloudservices #datastorage #techcommunity #itprofessionals #dba #event #community #databasemanagement
Mydbops Managed Services specializes in taking the pain out of database management while optimizing performance. Since 2015, we have been providing top-notch support and assistance for the top three open-source databases: MySQL, MongoDB, and PostgreSQL.
Our team offers a wide range of services, including assistance, support, consulting, 24/7 operations, and expertise in all relevant technologies. We help organizations improve their database's performance, scalability, efficiency, and availability.
Contact us: [email protected]
Visit: https://www.mydbops.com/
Mastering Vector Search with MongoDB Atlas - Manosh Malai - Mydbops MyWebinar 39
Mastering Vector Search with MongoDB Atlas - Manosh Malai - Mydbops MyWebinar 39Mydbops Mastering Vector Search with MongoDB Atlas - Manosh Malai - Mydbops MyWebinar 39
In this session, explore how to harness MongoDB's native vector search capabilities to enhance your database and search functionality. From the basics to advanced techniques, gain insights into building intelligent solutions that drive innovation.
What You’ll Learn:
* The fundamentals of vector search in MongoDB Atlas.
* How to store vector embeddings and create efficient indexes.
* Performing similarity queries for applications like semantic search and personalized recommendations.
* Best practices for optimizing performance and scaling vector-based systems effectively.
Whether you’re a developer, data scientist, or database administrator, this webinar will equip you with practical skills to elevate your projects with MongoDB’s advanced features.
Download presentation here: https://www.mydbops.com/webinars/mastering-vector-search-with-mongodb-atlas
This webinar is ideal for database administrators, data engineers, system architects, and anyone involved in MongoDB database management.
#Webinar #mongodb #mongodbatlas #MyWebinar #Mydbops #DatabaseManagement #DevOps #TechWebinar #database #dbms #dba #vectorsearch
Migration Journey To TiDB - Kabilesh PR - Mydbops MyWebinar 38
Migration Journey To TiDB - Kabilesh PR - Mydbops MyWebinar 38Mydbops Migration Journey To TiDB - Kabilesh PR - Mydbops MyWebinar 38
Youtube video link: https://youtu.be/_WgXm1Ykj8c
What You Will Learn
* Data Migration Strategies – Understand the best approaches for transferring data to TiDB with minimal disruption.
* Seamless Replication – Learn how to maintain data consistency and minimize downtime during the migration process.
* Schema Design Adjustments – Explore the key schema design adjustments necessary for optimal TiDB performance.
* Challenges & Solutions – Gain practical insights into tackling common migration challenges to ensure a smooth transition.
This webinar is ideal for database administrators, data engineers, system architects, and anyone involved in database management and migrations. Whether you are considering TiDB as a new solution or already exploring it, this session will equip you with valuable knowledge to streamline your migration journey.
#Webinar #TiDB #MyWebinar #Mydbops #DatabaseManagement #migration #DevOps #TechWebinar #database #dbms #dba #distributedsql #sql #HTAP
Mydbops Managed Services specializes in taking the pain out of database management while optimizing performance. Since 2015, we have been providing top-notch support and assistance for the top three open-source databases: MySQL, MongoDB, PostgreSQL and TiDB.
Our team offers a wide range of services, including assistance, support, consulting, 24/7 operations, and expertise in all relevant technologies. We help organizations improve their database's performance, scalability, efficiency, and availability.
Contact us: [email protected]
Visit: https://www.mydbops.com/
AWS Blue Green Deployment for Databases - Mydbops
AWS Blue Green Deployment for Databases - MydbopsMydbops Mastering AWS Blue/Green Deployment for Databases - Mydbops MyWebinar 37
What You Will Learn
* Key Principles of Blue/Green Deployment: Understand the fundamental concepts that drive this deployment strategy.
* Step-by-Step Implementation: A detailed walkthrough of the processes involved in setting up Blue/Green deployments using AWS services.
* Best Practices: Discover industry best practices to minimize risks and avoid common pitfalls during deployments.
* Database Management with AWS: Learn how to effectively use AWS services like RDS and Aurora for safe database upgrades, including rollback options in the event of deployment issues.
This webinar is ideal for database administrators, DevOps engineers, cloud architects, and anyone interested in mastering AWS deployment strategies. Whether you are new to AWS or looking to enhance your skills, this session will provide valuable insights and practical knowledge.
Mydbops Managed Services specializes in taking the pain out of database management while optimizing performance. Since 2015, we have been providing top-notch support and assistance for the top three open-source databases: MySQL, MongoDB, and PostgreSQL.
Our team offers a wide range of services, including assistance, support, consulting, 24/7 operations, and expertise in all relevant technologies. We help organizations improve their database's performance, scalability, efficiency, and availability.
Contact us: [email protected]
Visit: https://www.mydbops.com/
What's New In MySQL 8.4 LTS Mydbops MyWebinar Edition 36
What's New In MySQL 8.4 LTS Mydbops MyWebinar Edition 36Mydbops MySQL 8.4 LTS, launching in April 2024 and supported until April 2032, includes features like in-place upgrades and downgrades, enhanced clone plugin capabilities, and tagged GTID for better transaction management. It aims to provide stability through a 2-year release cycle while supporting a wide range of components in the MySQL ecosystem and major cloud providers. Key improvements focus on better performance defaults, monitoring, and automation changes, along with the removal of outdated keywords and highlighting cloud availability.
What's New in PostgreSQL 17? - Mydbops MyWebinar Edition 35
What's New in PostgreSQL 17? - Mydbops MyWebinar Edition 35Mydbops The document details the enhancements in PostgreSQL 17, highlighting performance optimizations, developer workflow improvements, and new security features. Key improvements include more efficient vacuum mechanisms, faster tuple ID lookups, and advancements in partition management and logical replication. Additionally, the document discusses new commands and features that facilitate data management and enhance replication processes in database environments.
What's New in MongoDB 8.0 - Mydbops MyWebinar Edition 34
What's New in MongoDB 8.0 - Mydbops MyWebinar Edition 34Mydbops The document presents an overview of the new features and enhancements in MongoDB 8.0, which includes significant performance improvements in write and read operations, workload-specific optimizations, and advanced sharding capabilities. It also discusses command path optimization, improved query insights, and the introduction of persistent query settings to enhance operational efficiency. Additionally, it highlights the expected performance boosts for various workloads, including time series data management and queryable encryption improvements.
Scaling Connections in PostgreSQL Postgres Bangalore(PGBLR) Meetup-2 - Mydbops
Scaling Connections in PostgreSQL Postgres Bangalore(PGBLR) Meetup-2 - MydbopsMydbops The document discusses a PostgreSQL meetup focused on connection pooling, highlighting the benefits of using connection poolers like PgBouncer, PgPool-II, and PgCat to manage database connections efficiently. Key topics include how connection pooling reduces resource consumption, improves scalability, and the operational considerations for implementing these tools. Additionally, it emphasizes testing load balancing and ensuring optimal system settings for production environments.
Read/Write Splitting using MySQL Router - Mydbops Meetup16
Read/Write Splitting using MySQL Router - Mydbops Meetup16Mydbops Vignesh Prabhu presents a detailed overview of MySQL Router, focusing on its functionalities related to read/write splitting and routing strategies for database management. The presentation covers case studies demonstrating both static and dynamic routing scenarios for InnoDB clusters and replica sets, highlighting configurations, advantages, and limitations. It also includes a comparison of MySQL Router with other load balancers like ProxySQL and MaxScale.
TiDB - From Data to Discovery: Exploring the Intersection of Distributed Dat...
TiDB - From Data to Discovery: Exploring the Intersection of Distributed Dat...Mydbops The document discusses the challenges faced by database administrators regarding scalability and high availability in modern applications. It introduces TiDB, an advanced open-source distributed SQL database that offers features like horizontal scaling, mixed workload handling, MySQL compatibility, and robust security. TiDB Cloud allows businesses to effortlessly scale their database to accommodate traffic surges while ensuring continuous access to data through its auto-failover and self-healing capabilities.
MySQL InnoDB Storage Engine: Deep Dive - Mydbops
MySQL InnoDB Storage Engine: Deep Dive - MydbopsMydbops The document discusses improvements in MySQL's InnoDB storage engine, focusing on the dynamic configuration of redo logs and the implementation of instant add/drop column features. It highlights the ability to adjust redo log capacity without server restarts, enhancing performance and reliability, and introduces a new design for adding or dropping columns without the need for table rebuilds. These advancements address user needs for efficiency and reduce the time and resources required for database alterations.
Demystifying Real time Analytics with TiDB
Demystifying Real time Analytics with TiDBMydbops The document discusses the capabilities of TiDB, an open-source, distributed HTAP database that supports real-time analytics and integrates with Tiflash for efficient processing. It highlights the architecture, advantages of TiDB, and the functionality of Tiflash in handling real-time data insights, including scaling, query optimization, and replication management. Use cases for real-time analytics such as fraud detection and market analysis are mentioned, along with challenges related to data volume and integration.
Must Know Postgres Extension for DBA and Developer during Migration
Must Know Postgres Extension for DBA and Developer during MigrationMydbops The document provides an overview of essential PostgreSQL extensions beneficial for database administrators and developers, particularly during migration from other database systems like Oracle and MSSQL. Key highlights include the concept of extensions, specific extensions such as pg_stat_statements, pg_hint_plan, and orafce, and tools for enhancing SQL performance and managing compliance. The author, Deepak Mahto, emphasizes the versatility of PostgreSQL's extensibility and shares additional resources for further exploration.
Efficient MySQL Indexing and what's new in MySQL Explain
Efficient MySQL Indexing and what's new in MySQL ExplainMydbops The document provides an overview of efficient MySQL indexing and recent features in MySQL, including an in-depth exploration of different types of indexes and their impact on data retrieval speed. It discusses best practices for increasing indexing efficiency, presents optimization examples, and introduces new JSON output formats for the EXPLAIN functionality in MySQL. Additionally, it emphasizes the importance of regular updates and maintenance of indexes to ensure optimal performance.
Scale your database traffic with Read & Write split using MySQL Router
Scale your database traffic with Read & Write split using MySQL RouterMydbops The document discusses the utilization of MySQL Router for read/write splitting to enhance database traffic management. It outlines various configurations and use cases for static and dynamic read/write routing in environments such as InnoDB clusters and replica sets. Additionally, it evaluates the advantages and limitations of different routing strategies and provides a comparison of load balancer features.
PostgreSQL Schema Changes with pg-osc - Mydbops @ PGConf India 2024
PostgreSQL Schema Changes with pg-osc - Mydbops @ PGConf India 2024Mydbops The document discusses pg_osc, a tool for making PostgreSQL schema changes with minimal locking and zero downtime, similar to MySQL's pt_osc. It outlines the step-by-step process for implementing schema changes, including creating audit tables, shadow tables, and handling data changes, while highlighting key features and considerations. The presentation was part of PGConf India on February 29, 2024.
Choosing the Right Database: Exploring MySQL Alternatives for Modern Applicat...
Choosing the Right Database: Exploring MySQL Alternatives for Modern Applicat...Mydbops The document explores modern alternatives to MySQL for managing transactional data in applications, highlighting challenges in scalability, performance, and infrastructure complexity. It proposes distributed SQL databases like TiDB as solutions, which offer horizontal scalability, high availability, and support for real-time analytics, eliminating many limitations of traditional MySQL setups. Case studies illustrate successful migrations to TiDB, showcasing substantial improvements in performance, cost efficiency, and data management for various companies.
Mastering Aurora PostgreSQL Clusters for Disaster Recovery
Mastering Aurora PostgreSQL Clusters for Disaster RecoveryMydbops The document outlines a presentation on mastering Aurora PostgreSQL clusters for disaster recovery, discussing features like decoupled storage and compute layers, global databases, and various replication strategies. It highlights the importance of managed failover for both controlled and unforeseen outages, along with real-world experiences and challenges such as the 'global_db_rpo' parameter. Additionally, it touches on TLS certificate management and VPC peering issues related to DNS resolution and security configurations.
Navigating Transactions: ACID Complexity in Modern Databases- Mydbops Open So...
Navigating Transactions: ACID Complexity in Modern Databases- Mydbops Open So...Mydbops The document discusses the complexities of implementing transactions in modern databases while considering ACID properties, scalability, and performance trade-offs. It explores historical perspectives on transaction systems, details on distributed transactions, and various implementation challenges, including two-phase commit and its alternatives. Additionally, it highlights specific database solutions such as Amazon Aurora, DynamoDB, and Google Spanner, focusing on their transaction handling and coordination methods.
Ad
Recently uploaded (20)
2025_06_18 - OpenMetadata Community Meeting.pdf
2025_06_18 - OpenMetadata Community Meeting.pdfOpenMetadata The community meetup was held Wednesday June 18, 2025 @ 9:00 AM PST.
Catch the next OpenMetadata Community Meetup @ https://www.meetup.com/openmetadata-meetup-group/
In this month's OpenMetadata Community Meetup, "Enforcing Quality & SLAs with OpenMetadata Data Contracts," we covered data contracts, why they matter, and how to implement them in OpenMetadata to increase the quality of your data assets!
Agenda Highlights:
👋 Introducing Data Contracts: An agreement between data producers and consumers
📝 Data Contracts key components: Understanding a contract and its purpose
🧑🎨 Writing your first contract: How to create your own contracts in OpenMetadata
🦾 An OpenMetadata MCP Server update!
➕ And More!
Raman Bhaumik - Passionate Tech Enthusiast
Raman Bhaumik - Passionate Tech EnthusiastRaman Bhaumik A Junior Software Developer with a flair for innovation, Raman Bhaumik excels in delivering scalable web solutions. With three years of experience and a solid foundation in Java, Python, JavaScript, and SQL, she has streamlined task tracking by 20% and improved application stability.
“MPU+: A Transformative Solution for Next-Gen AI at the Edge,” a Presentation...
“MPU+: A Transformative Solution for Next-Gen AI at the Edge,” a Presentation...Edge AI and Vision Alliance For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/06/mpu-a-transformative-solution-for-next-gen-ai-at-the-edge-a-presentation-from-fotonation/
Petronel Bigioi, CEO of FotoNation, presents the “MPU+: A Transformative Solution for Next-Gen AI at the Edge” tutorial at the May 2025 Embedded Vision Summit.
In this talk, Bigioi introduces MPU+, a novel programmable, customizable low-power platform for real-time, localized intelligence at the edge. The platform includes an AI-augmented image signal processor that enables leading image and video quality.
In addition, it integrates ultra-low-power object and motion detection capabilities to enable always-on computer vision. A programmable neural processor provides flexibility to efficiently implement new neural networks. And additional specialized engines facilitate image stabilization and audio enhancements.
Using the SQLExecutor for Data Quality Management: aka One man's love for the...
Using the SQLExecutor for Data Quality Management: aka One man's love for the...Safe Software The SQLExecutor is one of FME’s most powerful and flexible transformers. Pivvot maintains a robust internal metadata hierarchy used to support ingestion and curation of thousands of external data sources that must be managed for quality before entering our platform. By using the SQLExecutor, Pivvot can efficiently detect problems and perform analysis before data is extracted from our staging environment, removing the need for rollbacks or cycles waisted on a failed job. This presentation will walk through three distinct examples of how Pivvot uses the SQLExecutor to engage its metadata hierarchy and integrate with its Data Quality Management workflows efficiently and within the source postgres database. Spatial Validation –Validating spatial prerequisites before entering a production environment. Reference Data Validation - Dynamically validate domain-ed columns across any table and multiple columns per table. Practical De-duplication - Removing identical or near-identical well point locations from two distinct source datasets in the same table.
Hyderabad MuleSoft In-Person Meetup (June 21, 2025) Slides
Hyderabad MuleSoft In-Person Meetup (June 21, 2025) SlidesRavi Tamada Hyderabad MuleSoft In-Person Meetup (June 21, 2025) Slides
Coordinated Disclosure for ML - What's Different and What's the Same.pdf
Coordinated Disclosure for ML - What's Different and What's the Same.pdfPriyanka Aash Coordinated Disclosure for ML - What's Different and What's the Same
From Manual to Auto Searching- FME in the Driver's Seat
From Manual to Auto Searching- FME in the Driver's SeatSafe Software Finding a specific car online can be a time-consuming task, especially when checking multiple dealer websites. A few years ago, I faced this exact problem while searching for a particular vehicle in New Zealand. The local classified platform, Trade Me (similar to eBay), wasn’t yielding any results, so I expanded my search to second-hand dealer sites—only to realise that periodically checking each one was going to be tedious. That’s when I noticed something interesting: many of these websites used the same platform to manage their inventories. Recognising this, I reverse-engineered the platform’s structure and built an FME workspace that automated the search process for me. By integrating API calls and setting up periodic checks, I received real-time email alerts when matching cars were listed. In this presentation, I’ll walk through how I used FME to save hours of manual searching by creating a custom car-finding automation system. While FME can’t buy a car for you—yet—it can certainly help you find the one you’re after!
You are not excused! How to avoid security blind spots on the way to production
You are not excused! How to avoid security blind spots on the way to productionMichele Leroux Bustamante We live in an ever evolving landscape for cyber threats creating security risk for your production systems. Mitigating these risks requires participation throughout all stages from development through production delivery - and by every role including architects, developers QA and DevOps engineers, product owners and leadership. No one is excused! This session will cover examples of common mistakes or missed opportunities that can lead to vulnerabilities in production - and ways to do better throughout the development lifecycle.
Agentic AI for Developers and Data Scientists Build an AI Agent in 10 Lines o...
Agentic AI for Developers and Data Scientists Build an AI Agent in 10 Lines o...All Things Open Presented at All Things Open RTP Meetup
Presented by William Hill - Developer Advocate, NVIDIA
Title: Agentic AI for Developers and Data Scientists
Build an AI Agent in 10 Lines of Code and the Concepts Behind the Code
Abstract: In this talk we will demonstrate building a working data science AI agent in 10 lines of basic Python code in a Colab notebook. Our AI Agent will perform LLM prompt-driven visual analysis using open-source libraries. In this session we will show how to develop an AI Agent using GPUs through NVIDIA’s developer program and Google Colab notebooks. After coding our AI Agent, we will break down the 10 lines of code. We will show the key components and open source library integrations that enable the agent's functionality, focusing on practical implementation details and then the theoretical concepts. The presentation concludes with a survey of current LLM technologies and the latest trends in developing AI applications for enthusiasts and enterprises
Curietech AI in action - Accelerate MuleSoft development
Curietech AI in action - Accelerate MuleSoft developmentshyamraj55 CurieTech AI in Action – Accelerate MuleSoft Development
Overview:
This presentation demonstrates how CurieTech AI’s purpose-built agents empower MuleSoft developers to create integration workflows faster, more accurately, and with less manual effort
linkedin.com
+12
curietech.ai
+12
meetups.mulesoft.com
+12
.
Key Highlights:
Dedicated AI agents for every stage: Coding, Testing (MUnit), Documentation, Code Review, and Migration
curietech.ai
+7
curietech.ai
+7
medium.com
+7
DataWeave automation: Generate mappings from tables or samples—95%+ complete within minutes
linkedin.com
+7
curietech.ai
+7
medium.com
+7
Integration flow generation: Auto-create Mule flows based on specifications—speeds up boilerplate development
curietech.ai
+1
medium.com
+1
Efficient code reviews: Gain intelligent feedback on flows, patterns, and error handling
youtube.com
+8
curietech.ai
+8
curietech.ai
+8
Test & documentation automation: Auto-generate MUnit test cases, sample data, and detailed docs from code
curietech.ai
+5
curietech.ai
+5
medium.com
+5
Why Now?
Achieve 10× productivity gains, slashing development time from hours to minutes
curietech.ai
+3
curietech.ai
+3
medium.com
+3
Maintain high accuracy with code quality matching or exceeding manual efforts
curietech.ai
+2
curietech.ai
+2
curietech.ai
+2
Ideal for developers, architects, and teams wanting to scale MuleSoft projects with AI efficiency
Conclusion:
CurieTech AI transforms MuleSoft development into an AI-accelerated workflow—letting you focus on innovation, not repetition.
"How to survive Black Friday: preparing e-commerce for a peak season", Yurii ...
"How to survive Black Friday: preparing e-commerce for a peak season", Yurii ...Fwdays We will explore how e-commerce projects prepare for the busiest time of the year, which key aspects to focus on, and what to expect. We’ll share our experience in setting up auto-scaling, load balancing, and discuss the loads that Silpo handles, as well as the solutions that help us navigate this season without failures.
Cracking the Code - Unveiling Synergies Between Open Source Security and AI.pdf
Cracking the Code - Unveiling Synergies Between Open Source Security and AI.pdfPriyanka Aash Cracking the Code - Unveiling Synergies Between Open Source Security and AI
CapCut Pro Crack For PC Latest Version {Fully Unlocked} 2025
CapCut Pro Crack For PC Latest Version {Fully Unlocked} 2025pcprocore 👉𝗡𝗼𝘁𝗲:𝗖𝗼𝗽𝘆 𝗹𝗶𝗻𝗸 & 𝗽𝗮𝘀𝘁𝗲 𝗶𝗻𝘁𝗼 𝗚𝗼𝗼𝗴𝗹𝗲 𝗻𝗲𝘄 𝘁𝗮𝗯> https://pcprocore.com/ 👈◀
CapCut Pro Crack is a powerful tool that has taken the digital world by storm, offering users a fully unlocked experience that unleashes their creativity. With its user-friendly interface and advanced features, it’s no wonder why aspiring videographers are turning to this software for their projects.
The Future of Product Management in AI ERA.pdf
The Future of Product Management in AI ERA.pdfAlyona Owens Hi, I’m Aly Owens, I have a special pleasure to stand here as over a decade ago I graduated from CityU as an international student with an MBA program. I enjoyed the diversity of the school, ability to work and study, the network that came with being here, and of course the price tag for students here has always been more affordable than most around.
Since then I have worked for major corporations like T-Mobile and Microsoft and many more, and I have founded a startup. I've also been teaching product management to ensure my students save time and money to get to the same level as me faster avoiding popular mistakes. Today as I’ve transitioned to teaching and focusing on the startup, I hear everybody being concerned about Ai stealing their jobs… We’ll talk about it shortly.
But before that, I want to take you back to 1997. One of my favorite movies is “Fifth Element”. It wowed me with futuristic predictions when I was a kid and I’m impressed by the number of these predictions that have already come true. Self-driving cars, video calls and smart TV, personalized ads and identity scanning. Sci-fi movies and books gave us many ideas and some are being implemented as we speak. But we often get ahead of ourselves:
Flying cars,Colonized planets, Human-like AI: not yet, Time travel, Mind-machine neural interfaces for everyone: Only in experimental stages (e.g. Neuralink).
Cyberpunk dystopias: Some vibes (neon signs + inequality + surveillance), but not total dystopia (thankfully).
On the bright side, we predict that the working hours should drop as Ai becomes our helper and there shouldn’t be a need to work 8 hours/day. Nobody knows for sure but we can require that from legislation. Instead of waiting to see what the government and billionaires come up with, I say we should design our own future.
So, we as humans, when we don’t know something - fear takes over. The same thing happened during the industrial revolution. In the Industrial Era, machines didn’t steal jobs—they transformed them but people were scared about their jobs. The AI era is making similar changes except it feels like robots will take the center stage instead of a human. First off, even when it comes to the hottest space in the military - drones, Ai does a fraction of work. AI algorithms enable real-time decision-making, obstacle avoidance, and mission optimization making drones far more autonomous and capable than traditional remote-controlled aircraft. Key technologies include computer vision for object detection, GPS-enhanced navigation, and neural networks for learning and adaptation. But guess what? There are only 2 companies right now that utilize Ai in drones to make autonomous decisions - Skydio and DJI.
UserCon Belgium: Honey, VMware increased my bill
UserCon Belgium: Honey, VMware increased my billstijn40 VMware’s pricing changes have forced organizations to rethink their datacenter cost management strategies. While FinOps is commonly associated with cloud environments, the FinOps Foundation has recently expanded its framework to include Scopes—and Datacenter is now officially part of the equation. In this session, we’ll map the FinOps Framework to a VMware-based datacenter, focusing on cost visibility, optimization, and automation. You’ll learn how to track costs more effectively, rightsize workloads, optimize licensing, and drive efficiency—all without migrating to the cloud. We’ll also explore how to align IT teams, finance, and leadership around cost-aware decision-making for on-prem environments. If your VMware bill keeps increasing and you need a new approach to cost management, this session is for you!
GenAI Opportunities and Challenges - Where 370 Enterprises Are Focusing Now.pdf
GenAI Opportunities and Challenges - Where 370 Enterprises Are Focusing Now.pdfPriyanka Aash GenAI Opportunities and Challenges - Where 370 Enterprises Are Focusing Now
9-1-1 Addressing: End-to-End Automation Using FME
9-1-1 Addressing: End-to-End Automation Using FMESafe Software This session will cover a common use case for local and state/provincial governments who create and/or maintain their 9-1-1 addressing data, particularly address points and road centerlines. In this session, you'll learn how FME has helped Shelby County 9-1-1 (TN) automate the 9-1-1 addressing process; including automatically assigning attributes from disparate sources, on-the-fly QAQC of said data, and reporting. The FME logic that this presentation will cover includes: Table joins using attributes and geometry, Looping in custom transformers, Working with lists and Change detection.
PyCon SG 25 - Firecracker Made Easy with Python.pdf
PyCon SG 25 - Firecracker Made Easy with Python.pdfMuhammad Yuga Nugraha Explore the ease of managing Firecracker microVM with the firecracker-python. In this session, I will introduce the basics of Firecracker microVM and demonstrate how this custom SDK facilitates microVM operations easily. We will delve into the design and development process behind the SDK, providing a behind-the-scenes look at its creation and features. While traditional Firecracker SDKs were primarily available in Go, this module brings a simplicity of Python to the table.
OpenACC and Open Hackathons Monthly Highlights June 2025
OpenACC and Open Hackathons Monthly Highlights June 2025OpenACC The OpenACC organization focuses on enhancing parallel computing skills and advancing interoperability in scientific applications through hackathons and training. The upcoming 2025 Open Accelerated Computing Summit (OACS) aims to explore the convergence of AI and HPC in scientific computing and foster knowledge sharing. This year's OACS welcomes talk submissions from a variety of topics, from Using Standard Language Parallelism to Computer Vision Applications. The document also highlights several open hackathons, a call to apply for NVIDIA Academic Grant Program and resources for optimizing scientific applications using OpenACC directives.
“MPU+: A Transformative Solution for Next-Gen AI at the Edge,” a Presentation...
“MPU+: A Transformative Solution for Next-Gen AI at the Edge,” a Presentation...Edge AI and Vision Alliance
You are not excused! How to avoid security blind spots on the way to production
You are not excused! How to avoid security blind spots on the way to productionMichele Leroux Bustamante
Using ZFS file system with MySQL
- 1. MySQL on ZFS Bajrang Panigrahi August, 2019
- 2. ZFS Principles ● Pooled storage ● Completely eliminates the antique notion of volumes ● Does for storage what VM did for memory ● Transactional object system ● Always consistent on disk – no fsck, ever ● Provable end-to-end data integrity ● Detects and corrects silent data corruption ● Simple administration ● Concisely express your intent
- 3. FS/Volume Model vs Pooled Storage Traditional Volumes ● Abstraction: virtual disk ● Partition/volume for each FS ● Grow/shrink by hand ● Each FS has limited bandwidth ● Storage is fragmented, stranded ZFS Pooled Storage ● Abstraction: malloc/free ● No partitions to manage ● Grow/shrink automatically ● All bandwidth always available ● All storage in the pool is shared Storage PoolVolume FS Volume FS Volume FS ZFS ZFS ZFS
- 4. NFS SMB Local files VFS Filesystem (e.g. UFS, ext3) Volume Manager (e.g. LVM, SVM) NFS SMB Local files VFS DMU (Data Management Unit) SPA (Storage Pool Allocator) iSCSI FC SCSI target ZPL (ZFS POSIX Layer) ZVOL (ZFS Volume) Block interface ZFS Block allocate+write, read, free Atomic transactions on objects File interface
- 5. Benefits of ZFS ● Copy-on-Write (CoW) File System. ● Throttles writes. ● Data integrity and resiliency. ● Self Healing of Data on ZFS. ● Block size matching.(Allows Variable Block size) ● Snapshots & Clones ● Active development community
- 6. Copy-On-Write Transactions 1. Initial block tree 2. COW some blocks 4. Rewrite uberblock (atomic)3. COW indirect blocks
- 7. Block Pointer Structure in ZFS First copy of data When the block was written Checksum of data this block points to padding physical birth txg logical birth txg fill count 256-bit checksum BDX lvl type PSIZEcomp LSIZE offset1 offset2 offset3 vdev1 vdev2 vdev3 ASIZE ASIZE ASIZE cksum Second copy of data (for metadata) Third copy of data (pool-wide metadata)
- 8. END-to-END Data Integrity in ZFS ZFS validates the entire I/O path ✓ Bit rot ✓ Phantom writes ✓ Misdirected reads and writes ✓ DMA parity errors ✓ Driver bugs ✓ Accidental overwrite Disk checksum only validates media ✓ Bit rot ✓ Phantom writes ✓ Misdirected reads and writes ✓ DMA parity errors ✓ Driver bugs ✓ Accidental overwrite Disk Block Checksums ● Checksum stored with data block ● Any self-consistent block will pass ● Can't detect stray writes ● Inherent FS/volume interface limitation Data Data Data Checksum Data Checksum ZFS Data Authentication ● Checksum stored in parent block pointer ● Fault isolation between data and checksum ● Checksum hierarchy forms self-validating Merkle tree Address Checksum Checksum Address • • • Address Checksum Checksum Address
- 9. Self Healing of Data in ZFS Application ZFS mirror Application ZFS mirror Application ZFS mirror 1. Application issues a read. Checksum reveals that the block is corrupt on disk. 2. ZFS tries the next disk. Checksum indicates that the block is good. 3. ZFS returns good data to the application and repairs the damaged block.
- 10. Initial Use case at Zenefits We use AWS snapshot to rebuild a new DB for dev/ops; the first access to the data is slow because “New volumes created from existing EBS snapshots load lazily in the background” Multiple DB clusters data needed for generating the DB for dev/ops -- We use Multi-Source Replication.
- 11. Alternatives Multiple EBS Volume attached as Slave MySQL, and rotate on fresh snapshot request Con: Additional EBS volumes, will still have the problem of initial load of queries (Taking snap at every 15 mins) Use Percona Xtrabackup as an Incremental Data Copy to the Spoof Instance. Con: Requires an additional EBS volume and MySQL Service needs to be shutdown during the entire period the backup is restored. Use ZFS file system as a mechanism of taking a snapshot at the file system level
- 12. Setting up ZFS on MySQL ● Create a pool name “ZP1” zpool create -O compression=gzip -f -o autoexpand=on "zp1" mirror "/dev/xvdm" "/dev/xvdn" -o ashift=12 ● Create a new filesystem named “data2” in POOL “ZP1” #Create the ZFS Filesystems - name: Create a new file system called data2 in pool zp1 zfs: name: zp1/mysql state: present extra_zfs_properties: setuid: off compression: gzip recordsize: 128k atime: off primarycache: metadata
- 13. Setting up ZFS on MySQL ● Create the required datasets to run MySQL zp1/mysql 1.19T 4.92T 100K /zp1/mysql zp1/mysql/data 1.18T 4.92T 1.17T /data2/data zp1/mysql/logs 9.97G 4.92T 8.84G /data2/logs zp1/mysql/tmp 216K 4.92T 152K /data2/tmp ● Configurations on MySQL Innodb_doublewrite = 0 Innodb_checksum_algorithm = none Innodb_use_native_aio = 0
- 14. ZPOOL Status ● ZPOOL status zpool status pool: zp1 state: ONLINE scan: none requested config: NAME STATE READ WRITE CKSUM zp1 ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 xvdm ONLINE 0 0 0 xvdn ONLINE 0 0 0 errors: No known data errors
- 15. ZFS List NAME USED AVAIL REFER MOUNTPOINT zp1 1.20T 4.92T 104K /zp1 zp1/mslave03 1.11G 4.92T 100K /zp1/mslave03 zp1/mslave03/data 1.11G 4.92T 1.17T /data3/data zp1/mslave03/logs 308K 4.92T 340K /data3/logs zp1/mslave03/tmp 96K 4.92T 128K /data3/tmp zp1/mslave04 686M 4.92T 100K /zp1/mslave04 zp1/mslave04/data 686M 4.92T 1.17T /data4/data zp1/mslave04/logs 300K 4.92T 332K /data4/logs zp1/mslave04/tmp 96K 4.92T 128K /data4/tmp zp1/mysql 1.19T 4.92T 100K /zp1/mysql zp1/mysql/data 1.18T 4.92T 1.17T /data2/data zp1/mysql/logs 10.2G 4.92T 8.78G /data2/logs zp1/mysql/tmp 216K 4.92T 152K /data2/tmp
- 16. Incremental Send and Receive zfs send zp1/mysql/data@monday | ssh host zfs receive zp1/recvd/fs zfs send -i @monday zp1/mysql/data@tuesday | ssh .. “FromSnap” “ToSnap”
- 17. ZFS - Design - Local Clones
- 18. ZFS - Design - Remote Clones
- 19. ZFS - usage metrics KEY Old_ENV New_ENV Performance - Page Load 2-3 minutes ~15 secs Faster Data Snapshots 15 minutes ~2 - 4 secs Cloning / EBS attachment > 20 minutes ~ 3 - 5 secs Costs: Higher* Lower Monitoring / Alerting only Slack messages Jenkins + PagerDuty
- 20. ZFS - Performance Benchmarking
- 21. ZFS - Challenges ● Fragmentation. ● Complex to tweak and tune. ● Requires extra free space or pool performance can suffer.
- 22. Further ... ● High Read throughput (>= 83.88 million) ● MySQL / sec upto 76.2 K ● InnoDB file I/O write upto 150K ● Enterprise-grade transactional file system. ● Automatically reconstructs data after detecting an error. ● Multiple physical media devices into one logical volume using ZPOOL. ● Snapshot and Mirroring capabilities, and can quickly compress data. (LZ4) Enjoy a user-friendly, high-volume storage system.
- 23. Thank you.