Lecture 1 introduction to parallel and distributed computing
5 likes4,661 views

The course on parallel and distributed computing aims to equip students with skills in parallel algorithms, performance analysis, task decomposition, and parallel programming. It covers a wide range of topics including the history of computing, Flynn's taxonomy, various parallel architectures, and the principles of distributed systems. Assessment includes lab assignments and exams, while optional references provide additional resources for deeper understanding.
1 of 36
Downloaded 86 times



































Ad
Recommended
Introduction to Parallel and Distributed Computing
Introduction to Parallel and Distributed ComputingSayed Chhattan Shah The document provides an introduction to parallel computing, describing its significance, architecture, and programming models. It emphasizes the advantages of using parallel computing in various fields including science, engineering, and commercial applications, while addressing the limitations and complexities associated with parallel programming. Moreover, it discusses memory architectures such as shared, distributed, and hybrid models, along with key concepts like scalability and communication.
Introduction to Parallel Computing
Introduction to Parallel ComputingAkhila Prabhakaran This document provides an introduction to parallel computing. It discusses serial versus parallel computing and how parallel computing involves simultaneously using multiple compute resources to solve problems. Common parallel computer architectures involve multiple processors on a single computer or connecting multiple standalone computers together in a cluster. Parallel computers can use shared memory, distributed memory, or hybrid memory architectures. The document outlines some of the key considerations and challenges in moving from serial to parallel code such as decomposing problems, identifying dependencies, mapping tasks to resources, and handling dependencies.
Distributed & parallel system
Distributed & parallel systemManish Singh The document defines distributed and parallel systems. A distributed system consists of independent computers that communicate over a network to collaborate on tasks. It has features like no common clock and increased reliability. Examples include telephone networks and the internet. Advantages are information sharing and scalability, while disadvantages include difficulty developing software and security issues. A parallel system uses multiple processors with shared memory to solve problems. Examples are supercomputers and server clusters. Advantages are concurrency and saving time, while the main disadvantage is lack of scalability between memory and CPUs.
Underlying principles of parallel and distributed computing
Underlying principles of parallel and distributed computingGOVERNMENT COLLEGE OF ENGINEERING,TIRUNELVELI Parallel and distributed computing allows problems to be broken into discrete parts that can be solved simultaneously. This approach utilizes multiple processors that work concurrently on different parts of the problem. There are several types of parallel architectures depending on how instructions and data are distributed across processors. Shared memory systems give all processors access to a common memory space while distributed memory assigns private memory to each processor requiring explicit data transfer. Large-scale systems may combine these approaches into hybrid designs. Distributed systems extend parallelism across a network and provide users with a single, integrated view of geographically dispersed resources and computers. Key challenges for distributed systems include transparency, scalability, fault tolerance and concurrency.
parallel Questions & answers
parallel Questions & answersMd. Mashiur Rahman Parallelism involves executing multiple processes simultaneously using two or more processors. There are different types of parallelism including instruction level, job level, and program level. Parallelism is used in supercomputing to solve complex problems more quickly in fields like weather forecasting, climate modeling, engineering, and material science. Parallel computers can be classified based on whether they have a single or multiple instruction and data streams, including SISD, MISD, SIMD, and MIMD architectures. Shared memory parallel computers allow processors to access a global address space but can have conflicts when simultaneous writes occur, while message passing computers communicate via messages to avoid conflicts. Factors like software overhead and load balancing can limit the speedup achieved by parallel algorithms
Parallel Processing Concepts
Parallel Processing Concepts Dr Shashikant Athawale This document discusses parallel processing concepts including:
1. Parallel computing involves simultaneously using multiple processing elements to solve problems faster than a single processor. Common parallel platforms include shared-memory and message-passing architectures.
2. Key considerations for parallel platforms include the control structure for specifying parallel tasks, communication models, and physical organization including interconnection networks.
3. Scalable design principles for parallel systems include avoiding single points of failure, pushing work away from the core, and designing for maintenance and automation. Common parallel architectures include N-wide superscalar, which can dispatch N instructions per cycle, and multi-core which places multiple cores on a single processor socket.
multiprocessors and multicomputers
multiprocessors and multicomputersPankaj Kumar Jain The document outlines the architecture of parallel computers, categorizing them into shared-memory multiprocessors and distributed-memory multicomputers. It describes various models such as UMA, NUMA, and COMA, detailing their characteristics, performance calculations, and the efficiency of parallel processing. Additionally, it touches on multicomputer generations and the operational models of vector and SIMD supercomputers.
Parallel computing and its applications
Parallel computing and its applicationsBurhan Ahmed Parallel computing involves performing multiple calculations simultaneously to solve large problems more efficiently. It can be categorized into three types: bit-level, instruction-level, and task parallelism, with various applications such as data mining and medical imaging. The future of parallel computing is geared towards integrating more processors into chips and developing new programming languages to optimize processing capabilities.
OS - Process Concepts
OS - Process ConceptsMukesh Chinta The document provides an extensive overview of process concepts in operating systems, defining processes as instances of computer programs that execute various states such as new, ready, running, waiting, and terminated. It details the organization of process memory, the roles of process control blocks, and the mechanics of process scheduling, creation, and termination, with emphasis on how modern systems support multiple threads to enhance multitasking. Additionally, it covers interprocess communication methods, including message passing and shared memory, as well as the producer-consumer problem as a case study of cooperating processes.
Distributed file system
Distributed file systemAnamika Singh The document discusses key concepts related to distributed file systems including:
1. Files are accessed using location transparency where the physical location is hidden from users. File names do not reveal storage locations and names do not change when locations change.
2. Remote files can be mounted to local directories, making them appear local while maintaining location independence. Caching is used to reduce network traffic by storing recently accessed data locally.
3. Fault tolerance is improved through techniques like stateless server designs, file replication across failure independent machines, and read-only replication for consistency. Scalability is achieved by adding new nodes and using decentralized control through clustering.
System models in distributed system
System models in distributed systemishapadhy The document discusses different models for distributed systems including physical, architectural and fundamental models. It describes the physical model which captures the hardware composition and different generations of distributed systems. The architectural model specifies the components and relationships in a system. Key architectural elements discussed include communicating entities like processes and objects, communication paradigms like remote invocation and indirect communication, roles and responsibilities of entities, and their physical placement. Common architectures like client-server, layered and tiered are also summarized.
Distributed Systems Architecture in Software Engineering SE11
Distributed Systems Architecture in Software Engineering SE11koolkampus Distributed systems architectures allow software to execute across multiple processors. Key approaches include client-server systems and distributed object architectures. Client-server divides an application into client and server components, while distributed object architectures treat all entities as objects that provide and consume services. Middleware like CORBA supports object communication and common services.
distributed shared memory
distributed shared memoryAshish Kumar Distributed shared memory (DSM) provides processes with a shared address space across distributed memory systems. DSM exists only virtually through primitives like read and write operations. It gives the illusion of physically shared memory while allowing loosely coupled distributed systems to share memory. DSM refers to applying this shared memory paradigm using distributed memory systems connected by a communication network. Each node has CPUs, memory, and blocks of shared memory can be cached locally but migrated on demand between nodes to maintain consistency.
Memory Management in OS
Memory Management in OSvampugani This document discusses different memory management techniques used in operating systems. It begins by describing the basic components and functions of memory. It then explains various memory management algorithms like overlays, swapping, paging and segmentation. Overlays divide a program into instruction sets that are loaded and unloaded as needed. Swapping loads entire processes into memory for execution then writes them back to disk. Paging and segmentation are used to map logical addresses to physical addresses through page tables and segment tables respectively. The document compares advantages and limitations of these approaches.
Parallel Algorithms
Parallel AlgorithmsDr Sandeep Kumar Poonia The document discusses parallel algorithms and parallel computing. It begins by defining parallelism in computers as performing more than one task at the same time. Examples of parallelism include I/O chips and pipelining of instructions. Common terms for parallelism are defined, including concurrent processing, distributed processing, and parallel processing. Issues in parallel programming such as task decomposition and synchronization are outlined. Performance issues like scalability and load balancing are also discussed. Different types of parallel machines and their classification are described.
Replication in Distributed Systems
Replication in Distributed SystemsKavya Barnadhya Hazarika The document discusses replication in distributed systems, highlighting its definition, benefits, and necessity for maintaining consistency among redundant resources. It describes various replication techniques such as active and passive replication, different replication models including master-slave and peer-to-peer, and the challenges of ensuring consistency during updates. Additionally, it covers consistency models, including strict and causal consistency, and their implications for performance in distributed systems.
Cloud Resource Management
Cloud Resource ManagementNASIRSAYYED4 The document discusses cloud resource management and cloud computing architecture. It covers the following key points in 3 sentences:
Cloud architecture can be broadly divided into the front end, which consists of interfaces and applications for accessing cloud platforms, and the back end, which comprises resources for providing cloud services like storage, virtual machines, and security mechanisms. Common cloud service models include infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS). Virtualization techniques allow for the sharing of physical resources among multiple organizations by assigning logical names to physical resources and providing pointers to access them.
Parallel algorithms
Parallel algorithmsDanish Javed The document discusses parallel algorithms, which are designed for execution on multi-processor computers while also being applicable to single processors. It covers their benefits, such as improved throughput and reduced latency, as well as challenges like data dependency, resource requirements, and scalability issues. Key examples include odd-even transposition sort and parallel merge sort, highlighting their methodologies and complexities.
Trends in distributed systems
Trends in distributed systemsJayanthi Radhakrishnan Trends in distributed systems include the emergence of pervasive technology, ubiquitous and mobile computing, increasing demand for multimedia, and viewing distributed systems as a utility. These trends have led to modern networks consisting of interconnected wired and wireless devices that can connect from any location. Mobile and ubiquitous computing allow small portable devices to connect to distributed systems from different places. Distributed multimedia systems enable accessing content like live broadcasts from desktops and mobile devices. Distributed systems are also seen as a utility with physical and logical resources rented rather than owned, such as with cloud computing which provides internet-based applications and services on demand.
Kernel (OS)
Kernel (OS)عطاءالمنعم اثیل شیخ The kernel is the core component of operating systems, acting as a bridge between applications and hardware for resource management. It comes in various types, including microkernels, monolithic kernels, and hybrid kernels, each with distinct advantages and disadvantages related to performance, maintenance, and system calls. Key responsibilities of the kernel include managing CPU allocation, memory resources, input/output devices, and facilitating system calls for user applications.
Free Space Management, Efficiency & Performance, Recovery and NFS
Free Space Management, Efficiency & Performance, Recovery and NFSUnited International University The document discusses various methods for managing free disk space, including implementations such as bit vectors, linked lists, grouping, and counting techniques. It also highlights the efficiency and performance factors affecting disk allocation, along with recovery techniques for data consistency and backup. Additionally, it mentions the Network File System (NFS) as an implementation for accessing remote files over LANs and WANs.
Introduction to Distributed System
Introduction to Distributed SystemSunita Sahu The document provides an introduction to distributed systems, defining them as a collection of independent computers that communicate over a network to act as a single coherent system. It discusses the motivation for and characteristics of distributed systems, including concurrency, lack of a global clock, and independence of failures. Architectural categories of distributed systems include tightly coupled and loosely coupled, with examples given of different types of distributed systems such as database management systems, ATM networks, and the internet.
Message passing in Distributed Computing Systems
Message passing in Distributed Computing SystemsAlagappa Govt Arts College, Karaikudi This document discusses interprocess communication (IPC) and message passing in distributed systems. It covers key topics such as:
- The two main approaches to IPC - shared memory and message passing
- Desirable features of message passing systems like simplicity, uniform semantics, efficiency, reliability, correctness, flexibility, security, and portability
- Issues in message passing IPC like message format, synchronization methods (blocking vs. non-blocking), and buffering strategies
Parallel Programming
Parallel ProgrammingUday Sharma This document discusses parallel programming concepts including threads, synchronization, and barriers. It defines parallel programming as carrying out many calculations simultaneously. Advantages include increased computational power and speed up. Key issues in parallel programming are sharing resources between threads, and ensuring synchronization through locks and barriers. Data parallel programming is discussed where the same operation is performed on different data elements simultaneously.
program partitioning and scheduling IN Advanced Computer Architecture
program partitioning and scheduling IN Advanced Computer ArchitecturePankaj Kumar Jain The document discusses program partitioning and scheduling in advanced computer architecture, emphasizing the transformation of sequential programs into parallel forms. It details granularity levels (fine, medium, coarse) in parallel execution and the associated latencies, communication demands, and techniques like grain packing to optimize execution time and resource allocation. Furthermore, it illustrates the trade-offs between parallelism, scheduling overhead, and communication latency in the design of parallel computing systems.
Code optimization in compiler design
Code optimization in compiler designKuppusamy P The document discusses code optimization techniques in compilers. It covers the following key points:
1. Code optimization aims to improve code performance by replacing high-level constructs with more efficient low-level code while preserving program semantics. It occurs at various compiler phases like source code, intermediate code, and target code.
2. Common optimization techniques include constant folding, propagation, algebraic simplification, strength reduction, copy propagation, and dead code elimination. Control and data flow analysis are required to perform many optimizations.
3. Optimizations can be local within basic blocks, global across blocks, or inter-procedural across procedures. Representations like flow graphs, basic blocks, and DAGs are used to apply optimizations at
Implementation levels of virtualization
Implementation levels of virtualizationGokulnath S Virtualization allows multiple virtual machines to run on the same physical machine. It improves resource sharing and utilization. Traditional computers run a single operating system tailored to the hardware, while virtualization allows different guest operating systems to run independently on the same hardware. Virtualization software creates an abstraction layer at different levels - instruction set architecture, hardware, operating system, library, and application levels. Virtual machines at the operating system level have low startup costs and can easily synchronize with the environment, but all virtual machines must use the same or similar guest operating system.
Query trees
Query treesShefa Idrees The document discusses query trees in the context of distributed query optimization, explaining their structure and the conversion from parse trees to logical query trees. It outlines various approaches to query optimization, including dynamic, static, semijoin-based, and hybrid methods, emphasizing the trade-offs between communication time and response time. Additionally, it covers the challenges presented by nested queries and the complexities involved in processing correlated subqueries.
intro, definitions, basic laws+.pptx
intro, definitions, basic laws+.pptxssuser413a98 The document discusses the importance and applications of high performance computing (HPC). It provides examples of when HPC is needed, such as to perform time-consuming operations more quickly or handle high volumes of data/transactions. It also outlines what HPC studies, including hardware components like computer architecture and networks, as well as software elements like programming paradigms and languages. Additionally, it notes the international competition around developing exascale supercomputers and some of the research areas that utilize HPC, such as finance, weather forecasting, and health care applications involving large datasets.
Chapter 1 - introduction - parallel computing
Chapter 1 - introduction - parallel computingHeman Pathak The document discusses advancements in high-speed computing and the evolution of parallel computers, highlighting the limitations of traditional physical experiments and the increasing reliance on numerical simulations. It outlines the critical role of parallel computing in solving complex scientific problems and describes various architectures and classifications of parallel computers. Additionally, it explores the benefits of data and control parallelism, scalability of algorithms, and provides insight into Flynn's taxonomy for classifying parallel computer architectures.
More Related Content
What's hot (20)
OS - Process Concepts
OS - Process ConceptsMukesh Chinta The document provides an extensive overview of process concepts in operating systems, defining processes as instances of computer programs that execute various states such as new, ready, running, waiting, and terminated. It details the organization of process memory, the roles of process control blocks, and the mechanics of process scheduling, creation, and termination, with emphasis on how modern systems support multiple threads to enhance multitasking. Additionally, it covers interprocess communication methods, including message passing and shared memory, as well as the producer-consumer problem as a case study of cooperating processes.
Distributed file system
Distributed file systemAnamika Singh The document discusses key concepts related to distributed file systems including:
1. Files are accessed using location transparency where the physical location is hidden from users. File names do not reveal storage locations and names do not change when locations change.
2. Remote files can be mounted to local directories, making them appear local while maintaining location independence. Caching is used to reduce network traffic by storing recently accessed data locally.
3. Fault tolerance is improved through techniques like stateless server designs, file replication across failure independent machines, and read-only replication for consistency. Scalability is achieved by adding new nodes and using decentralized control through clustering.
System models in distributed system
System models in distributed systemishapadhy The document discusses different models for distributed systems including physical, architectural and fundamental models. It describes the physical model which captures the hardware composition and different generations of distributed systems. The architectural model specifies the components and relationships in a system. Key architectural elements discussed include communicating entities like processes and objects, communication paradigms like remote invocation and indirect communication, roles and responsibilities of entities, and their physical placement. Common architectures like client-server, layered and tiered are also summarized.
Distributed Systems Architecture in Software Engineering SE11
Distributed Systems Architecture in Software Engineering SE11koolkampus Distributed systems architectures allow software to execute across multiple processors. Key approaches include client-server systems and distributed object architectures. Client-server divides an application into client and server components, while distributed object architectures treat all entities as objects that provide and consume services. Middleware like CORBA supports object communication and common services.
distributed shared memory
distributed shared memoryAshish Kumar Distributed shared memory (DSM) provides processes with a shared address space across distributed memory systems. DSM exists only virtually through primitives like read and write operations. It gives the illusion of physically shared memory while allowing loosely coupled distributed systems to share memory. DSM refers to applying this shared memory paradigm using distributed memory systems connected by a communication network. Each node has CPUs, memory, and blocks of shared memory can be cached locally but migrated on demand between nodes to maintain consistency.
Memory Management in OS
Memory Management in OSvampugani This document discusses different memory management techniques used in operating systems. It begins by describing the basic components and functions of memory. It then explains various memory management algorithms like overlays, swapping, paging and segmentation. Overlays divide a program into instruction sets that are loaded and unloaded as needed. Swapping loads entire processes into memory for execution then writes them back to disk. Paging and segmentation are used to map logical addresses to physical addresses through page tables and segment tables respectively. The document compares advantages and limitations of these approaches.
Parallel Algorithms
Parallel AlgorithmsDr Sandeep Kumar Poonia The document discusses parallel algorithms and parallel computing. It begins by defining parallelism in computers as performing more than one task at the same time. Examples of parallelism include I/O chips and pipelining of instructions. Common terms for parallelism are defined, including concurrent processing, distributed processing, and parallel processing. Issues in parallel programming such as task decomposition and synchronization are outlined. Performance issues like scalability and load balancing are also discussed. Different types of parallel machines and their classification are described.
Replication in Distributed Systems
Replication in Distributed SystemsKavya Barnadhya Hazarika The document discusses replication in distributed systems, highlighting its definition, benefits, and necessity for maintaining consistency among redundant resources. It describes various replication techniques such as active and passive replication, different replication models including master-slave and peer-to-peer, and the challenges of ensuring consistency during updates. Additionally, it covers consistency models, including strict and causal consistency, and their implications for performance in distributed systems.
Cloud Resource Management
Cloud Resource ManagementNASIRSAYYED4 The document discusses cloud resource management and cloud computing architecture. It covers the following key points in 3 sentences:
Cloud architecture can be broadly divided into the front end, which consists of interfaces and applications for accessing cloud platforms, and the back end, which comprises resources for providing cloud services like storage, virtual machines, and security mechanisms. Common cloud service models include infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS). Virtualization techniques allow for the sharing of physical resources among multiple organizations by assigning logical names to physical resources and providing pointers to access them.
Parallel algorithms
Parallel algorithmsDanish Javed The document discusses parallel algorithms, which are designed for execution on multi-processor computers while also being applicable to single processors. It covers their benefits, such as improved throughput and reduced latency, as well as challenges like data dependency, resource requirements, and scalability issues. Key examples include odd-even transposition sort and parallel merge sort, highlighting their methodologies and complexities.
Trends in distributed systems
Trends in distributed systemsJayanthi Radhakrishnan Trends in distributed systems include the emergence of pervasive technology, ubiquitous and mobile computing, increasing demand for multimedia, and viewing distributed systems as a utility. These trends have led to modern networks consisting of interconnected wired and wireless devices that can connect from any location. Mobile and ubiquitous computing allow small portable devices to connect to distributed systems from different places. Distributed multimedia systems enable accessing content like live broadcasts from desktops and mobile devices. Distributed systems are also seen as a utility with physical and logical resources rented rather than owned, such as with cloud computing which provides internet-based applications and services on demand.
Kernel (OS)
Kernel (OS)عطاءالمنعم اثیل شیخ The kernel is the core component of operating systems, acting as a bridge between applications and hardware for resource management. It comes in various types, including microkernels, monolithic kernels, and hybrid kernels, each with distinct advantages and disadvantages related to performance, maintenance, and system calls. Key responsibilities of the kernel include managing CPU allocation, memory resources, input/output devices, and facilitating system calls for user applications.
Free Space Management, Efficiency & Performance, Recovery and NFS
Free Space Management, Efficiency & Performance, Recovery and NFSUnited International University The document discusses various methods for managing free disk space, including implementations such as bit vectors, linked lists, grouping, and counting techniques. It also highlights the efficiency and performance factors affecting disk allocation, along with recovery techniques for data consistency and backup. Additionally, it mentions the Network File System (NFS) as an implementation for accessing remote files over LANs and WANs.
Introduction to Distributed System
Introduction to Distributed SystemSunita Sahu The document provides an introduction to distributed systems, defining them as a collection of independent computers that communicate over a network to act as a single coherent system. It discusses the motivation for and characteristics of distributed systems, including concurrency, lack of a global clock, and independence of failures. Architectural categories of distributed systems include tightly coupled and loosely coupled, with examples given of different types of distributed systems such as database management systems, ATM networks, and the internet.
Message passing in Distributed Computing Systems
Message passing in Distributed Computing SystemsAlagappa Govt Arts College, Karaikudi This document discusses interprocess communication (IPC) and message passing in distributed systems. It covers key topics such as:
- The two main approaches to IPC - shared memory and message passing
- Desirable features of message passing systems like simplicity, uniform semantics, efficiency, reliability, correctness, flexibility, security, and portability
- Issues in message passing IPC like message format, synchronization methods (blocking vs. non-blocking), and buffering strategies
Parallel Programming
Parallel ProgrammingUday Sharma This document discusses parallel programming concepts including threads, synchronization, and barriers. It defines parallel programming as carrying out many calculations simultaneously. Advantages include increased computational power and speed up. Key issues in parallel programming are sharing resources between threads, and ensuring synchronization through locks and barriers. Data parallel programming is discussed where the same operation is performed on different data elements simultaneously.
program partitioning and scheduling IN Advanced Computer Architecture
program partitioning and scheduling IN Advanced Computer ArchitecturePankaj Kumar Jain The document discusses program partitioning and scheduling in advanced computer architecture, emphasizing the transformation of sequential programs into parallel forms. It details granularity levels (fine, medium, coarse) in parallel execution and the associated latencies, communication demands, and techniques like grain packing to optimize execution time and resource allocation. Furthermore, it illustrates the trade-offs between parallelism, scheduling overhead, and communication latency in the design of parallel computing systems.
Code optimization in compiler design
Code optimization in compiler designKuppusamy P The document discusses code optimization techniques in compilers. It covers the following key points:
1. Code optimization aims to improve code performance by replacing high-level constructs with more efficient low-level code while preserving program semantics. It occurs at various compiler phases like source code, intermediate code, and target code.
2. Common optimization techniques include constant folding, propagation, algebraic simplification, strength reduction, copy propagation, and dead code elimination. Control and data flow analysis are required to perform many optimizations.
3. Optimizations can be local within basic blocks, global across blocks, or inter-procedural across procedures. Representations like flow graphs, basic blocks, and DAGs are used to apply optimizations at
Implementation levels of virtualization
Implementation levels of virtualizationGokulnath S Virtualization allows multiple virtual machines to run on the same physical machine. It improves resource sharing and utilization. Traditional computers run a single operating system tailored to the hardware, while virtualization allows different guest operating systems to run independently on the same hardware. Virtualization software creates an abstraction layer at different levels - instruction set architecture, hardware, operating system, library, and application levels. Virtual machines at the operating system level have low startup costs and can easily synchronize with the environment, but all virtual machines must use the same or similar guest operating system.
Query trees
Query treesShefa Idrees The document discusses query trees in the context of distributed query optimization, explaining their structure and the conversion from parse trees to logical query trees. It outlines various approaches to query optimization, including dynamic, static, semijoin-based, and hybrid methods, emphasizing the trade-offs between communication time and response time. Additionally, it covers the challenges presented by nested queries and the complexities involved in processing correlated subqueries.
Similar to Lecture 1 introduction to parallel and distributed computing (20)
intro, definitions, basic laws+.pptx
intro, definitions, basic laws+.pptxssuser413a98 The document discusses the importance and applications of high performance computing (HPC). It provides examples of when HPC is needed, such as to perform time-consuming operations more quickly or handle high volumes of data/transactions. It also outlines what HPC studies, including hardware components like computer architecture and networks, as well as software elements like programming paradigms and languages. Additionally, it notes the international competition around developing exascale supercomputers and some of the research areas that utilize HPC, such as finance, weather forecasting, and health care applications involving large datasets.
Chapter 1 - introduction - parallel computing
Chapter 1 - introduction - parallel computingHeman Pathak The document discusses advancements in high-speed computing and the evolution of parallel computers, highlighting the limitations of traditional physical experiments and the increasing reliance on numerical simulations. It outlines the critical role of parallel computing in solving complex scientific problems and describes various architectures and classifications of parallel computers. Additionally, it explores the benefits of data and control parallelism, scalability of algorithms, and provides insight into Flynn's taxonomy for classifying parallel computer architectures.
Parallel computing
Parallel computingVinay Gupta Parallel computing involves solving computational problems simultaneously using multiple processors. It can save time and money compared to serial computing and allow larger problems to be solved. Parallel programs break problems into discrete parts that can be solved concurrently on different CPUs. Shared memory parallel computers allow all processors to access a global address space, while distributed memory systems require communication between separate processor memories. Hybrid systems combine shared and distributed memory architectures.
Par com
Par comtttoracle Parallel processing architectures allow for simultaneous computation across multiple processing elements. There are four main types of parallel architectures: single instruction single data (SISD), single instruction multiple data (SIMD), multiple instruction single data (MISD), and multiple instruction multiple data (MIMD). MIMD systems are the most common and can have either shared or distributed memory. Effective parallel programming requires approaches like message passing or shared memory models to facilitate communication between processing elements.
unit_1.pdf
unit_1.pdfJyotiChoudhary469897 The document outlines essential elements of modern computer architecture, including computing problems, algorithms, hardware resources, and operating systems. It discusses the evolution of computer architecture, performance factors affecting system attributes, and classifications of parallel computing systems. Key concepts such as multi-processors, memory architecture models, PRAM models, and VLSI complexity are also reviewed.
Distributed Computing
Distributed ComputingSudarsun Santhiappan The document discusses various models of parallel and distributed computing including symmetric multiprocessing (SMP), cluster computing, distributed computing, grid computing, and cloud computing. It provides definitions and examples of each model. It also covers parallel processing techniques like vector processing and pipelined processing, and differences between shared memory and distributed memory MIMD (multiple instruction multiple data) architectures.
Parallel computing persentation
Parallel computing persentationVIKAS SINGH BHADOURIA The document provides an overview of parallel computing, contrasting it with traditional serial computing and highlighting its benefits, such as time and cost savings, ability to tackle larger problems, and concurrency. It discusses various parallel computing architectures, programming models, and the significance of collaborative and efficient computational practices like Flynn's taxonomy. The future of computing is positioned around increasing performance through parallel architectures, reflecting a shift from serial to more concurrent processing capabilities.
Parallel Computing-Part-1.pptx
Parallel Computing-Part-1.pptxkrnaween This document provides an overview of parallel and distributed computing. It begins by outlining the key learning outcomes of studying this topic, which include defining parallel algorithms, analyzing parallel performance, applying task decomposition techniques, and performing parallel programming. It then reviews the history of computing from the batch era to today's network era. The rest of the document discusses parallel computing concepts like Flynn's taxonomy, shared vs distributed memory systems, limits of parallelism based on Amdahl's law, and different types of parallelism including bit-level, instruction-level, data, and task parallelism. It concludes by covering parallel implementation in both software through parallel programming and in hardware through parallel processing.
distributed system lab materials about ad
distributed system lab materials about admilkesa13 The document discusses various topics related to distributed systems including:
1. An agenda covering evolution of computational technology, parallel computing, cluster computing, grid computing, utility computing, virtualization, service-oriented architecture, cloud computing, and internet of things.
2. Definitions of distributed systems and reasons why typical definitions are unsatisfactory.
3. A proposed working definition of distributed systems.
4. Computing paradigms including centralized, parallel, and distributed computing.
5. Challenges of distributed systems such as failure recovery, scalability, asynchrony, and security.
ceg4131_models.ppthjjjjjjjhhjhjhjhjhjhjhj
ceg4131_models.ppthjjjjjjjhhjhjhjhjhjhjhj431m2rn14g vyiyiiiiiiivyyyyyyyyyyyyyyyyyyyyyyyyyyyyyiiiiiiiiiiiiiiiyyyyyyyyyyyyyyyyyiiiiiiiiiiii
Chap2 GGKK.ppt
Chap2 GGKK.pptaminnezarat This document discusses different types of parallel computing platforms and architectures. It describes single instruction multiple data (SIMD) and multiple instruction multiple data (MIMD) models. Shared memory and message passing platforms are covered, as well as different interconnection network topologies like buses, crossbars, and multistage networks. Idealized parallel random access machines (PRAMs) are introduced along with the challenges of building a real PRAM system.
Lec 2 (parallel design and programming)
Lec 2 (parallel design and programming)Sudarshan Mondal This document discusses parallel computing architectures and concepts. It begins by describing Von Neumann architecture and how parallel computers follow the same basic design but with multiple units. It then covers Flynn's taxonomy which classifies computers based on their instruction and data streams as Single Instruction Single Data (SISD), Single Instruction Multiple Data (SIMD), Multiple Instruction Single Data (MISD), or Multiple Instruction Multiple Data (MIMD). Each classification is defined. The document also discusses parallel terminology, synchronization, scalability, and Amdahl's law on the costs and limits of parallel programming.
introduction to advanced distributed system
introduction to advanced distributed systemmilkesa13 This document provides an overview of distributed systems and computing paradigms. It begins with an agenda that covers topics like parallel computing, cluster computing, grid computing, utility computing, and cloud computing. Examples of distributed systems are provided. Definitions of distributed systems emphasize that they are collections of independent computers that appear as a single system to users. Computing paradigms like centralized, parallel, and distributed computing are described. Challenges of distributed systems like failures, scalability, and asynchrony are listed. The operational layers of distributed systems from the application to network layers are outlined. Models and enabling technologies are mentioned.
Asynchronous and Parallel Programming in .NET
Asynchronous and Parallel Programming in .NETssusere19c741 This document provides an overview of asynchronous and parallel programming concepts including:
- Mono-processor and multiprocessor systems
- Flynn's taxonomy for classifying computer architectures
- Serial and parallel computing approaches
- .NET frameworks for parallel programming like the Task Parallel Library and Parallel LINQ
It includes demonstrations of using tasks and PLINQ for parallel programming in .NET.
parallel computing.ppt
parallel computing.pptssuser413a98 This document provides an introduction to parallel and distributed computing. It discusses traditional sequential programming and von Neumann architecture. It then introduces parallel computing as a way to solve larger problems faster by breaking them into discrete parts that can be solved simultaneously. The document outlines different parallel computing architectures including shared memory, distributed memory, and hybrid models. It provides examples of applications that benefit from parallel computing such as physics simulations, artificial intelligence, and medical imaging. Key challenges of parallel programming are also discussed.
2 parallel processing presentation ph d 1st semester
2 parallel processing presentation ph d 1st semesterRafi Ullah This document discusses parallel processing. It begins by defining parallel processing as a form of processing where many instructions are carried out simultaneously by multiple processors. It then discusses why parallel processing is needed due to increasing computational demands and the limitations of increasing processor speeds alone. It classifies different types of parallel processor architectures including single instruction single data (SISD), single instruction multiple data (SIMD), multiple instruction single data (MISD), and multiple instruction multiple data (MIMD). The document concludes by outlining some advantages of parallel processing such as saving time and cost and solving larger problems, and provides examples of applications that benefit from parallel processing.
20090720 smith
20090720 smithMichael Karpov The document discusses parallel and high performance computing. It begins with definitions of key terms like parallel computing, high performance computing, asymptotic notation, speedup, work and time optimality, latency, bandwidth and concurrency. It then covers parallel architecture and programming models including SIMD, MIMD, shared and distributed memory, data and task parallelism, and synchronization methods. Examples of parallel sorting and prefix sums are provided. Programming models like OpenMP, PPL and work stealing are also summarized.
Parallel Programming Models: Shared variable model, Message passing model, Da...
Parallel Programming Models: Shared variable model, Message passing model, Da...SHASHIKANT346021 Hardware Components of the Instruction Set Architecture, ARC - A RISC Computer , Pseudo Operations, Synthetic Instructions, Examples of Assembly Language Programs, Accessing Data in Memory-Addressing Modes, The Memory Hierarchy, Cache Memory
Floating Point Operations , Memory Chip Organization , Serial Bus Architectur...
Floating Point Operations , Memory Chip Organization , Serial Bus Architectur...VAISHNAVI MADHAN This document discusses parallel computer architecture, focusing on the importance of resource allocation, performance, and scalability in parallel processing. It elaborates on different models of parallel computing, including shared memory multiprocessors and message-passing multicomputers, while highlighting trends in scientific computing and technological advancements. Key aspects such as programming models, algorithm design, and hardware architecture are examined to emphasize the evolution and effectiveness of parallel computing systems.
Floating Point Operations , Memory Chip Organization , Serial Bus Architectur...
Floating Point Operations , Memory Chip Organization , Serial Bus Architectur...KRamasamy2 This document discusses parallel computer architecture and challenges. It covers topics such as resource allocation, data access, communication, synchronization, performance and scalability for parallel processing. It also discusses different levels of parallelism that can be exploited in programs as well as the need for and feasibility of parallel computing given technology and application demands.
Ad
More from Vajira Thambawita (20)
Lecture 4 principles of parallel algorithm design updated
Lecture 4 principles of parallel algorithm design updatedVajira Thambawita The document discusses principles of parallel algorithm design, emphasizing the importance of parallel algorithms in problem-solving using multiple processors. It covers key concepts like decomposition into tasks, dependency graphs, granularity, concurrency, task interaction, and mapping of tasks onto processes for efficiency. Additionally, it describes various decomposition techniques, including recursive, data, exploratory, and speculative decomposition, along with their impact on task planning and execution.
Lecture 3 parallel programming platforms
Lecture 3 parallel programming platformsVajira Thambawita Parallel platforms can be organized in various ways, from an ideal parallel random access machine (PRAM) to more conventional architectures. PRAMs allow concurrent access to shared memory and can be divided into subclasses based on how simultaneous memory accesses are handled. Physical parallel computers use interconnection networks to provide communication between processing elements and memory. These networks include bus-based, crossbar, multistage, and various topologies like meshes and hypercubes. Maintaining cache coherence across multiple processors is important and can be achieved using invalidate protocols, directories, and snooping.
Lecture 2 more about parallel computing
Lecture 2 more about parallel computingVajira Thambawita The document discusses parallel computing and memory architectures, specifically distinguishing between shared memory, distributed memory, and hybrid systems. It also covers various parallel programming models such as shared memory without threads, distributed memory/message passing, and hybrid approaches, along with key design considerations like partitioning, granularity, and I/O efficiency. Additionally, it highlights debugging and performance analysis tools used in parallel program development.
Lecture 12 localization and navigation
Lecture 12 localization and navigationVajira Thambawita Localization and navigation are important tasks for mobile robots. Localization involves determining a robot's position and orientation, which can be done using global positioning systems outdoors or local sensor networks indoors. Navigation involves planning a path to reach a goal destination. Common navigation algorithms include Dijkstra's algorithm, A* algorithm, potential field method, wandering standpoint algorithm, and DistBug algorithm. Each algorithm has different requirements and approaches to planning paths between a starting point and goal.
Lecture 11 neural network principles
Lecture 11 neural network principlesVajira Thambawita The document explains artificial neural networks (ANNs), highlighting their ability to learn input-output mappings through training without explicit programming. It focuses on three-layer neural networks, detailing their structure, neuron connections, and weight determination methods, including backpropagation and evolutionary algorithms. An example illustrates how an ANN can be applied to navigate a mobile robot through a maze using sensor inputs and motor outputs.
Lecture 10 mobile robot design
Lecture 10 mobile robot designVajira Thambawita The document discusses various designs for mobile robots, including single wheel drive, differential drive, tracked robots, and omni-directional robots. It highlights the differences between holonomic and non-holonomic movement capabilities, particularly focusing on the mecanum wheel design for omni-directional mobility. Additionally, it briefly mentions the steering mechanisms used in these designs, such as Ackermann steering.
Lecture 09 control
Lecture 09 controlVajira Thambawita On-off control is the simplest method of feedback control where the motor power is either switched fully on or off depending on whether the actual speed is higher or lower than the desired speed. A PID controller is a more advanced control method that uses proportional, integral and derivative terms to provide smoother control compared to on-off control and help reduce steady-state error. PID control is almost an industry standard approach for feedback-based motor speed regulation.
Lecture 08 robots and controllers
Lecture 08 robots and controllersVajira Thambawita Sensors and actuators are important components for robots. Sensors can be analog or digital and include sensors for position, orientation, distance, light, and more. The right sensor must match the application needs. Actuators allow robots to move and interact with their environment. Common actuators include DC motors, stepper motors, and servos, which can be controlled through techniques like pulse-width modulation. Together, sensors and actuators enable robots to perceive and interact with the world.
Lecture 07 more about pic
Lecture 07 more about picVajira Thambawita The PIC 18 microcontroller has two to five timers that can be used as timers to generate time delays or counters to count external events. The document discusses Timer 0 and Timer 1, how they work in C code, and interrupt programming which allows writing interrupt service routines to handle interrupts in a round-robin fashion through the interrupt vector table and INTCON register.
Lecture 06 pic programming in c
Lecture 06 pic programming in cVajira Thambawita The document discusses programming the PIC18 microcontroller in C, highlighting its advantages such as ease of writing, modification, and portability. It covers essential C data types for PIC18 and methods for implementing time delays, including loop structures and the use of timers. It also mentions the impact of crystal frequency and compiler differences on timing accuracy and includes examples of I/O programming and logic operations in C.
Lecture 05 pic io port programming
Lecture 05 pic io port programmingVajira Thambawita The document covers I/O port programming for the PIC18F458 microcontroller, detailing the alternative functions of ports including ADC, timers, and serial communication. It explains the significance of the TRIS register for designating ports as inputs or outputs and describes methods of data transfer between ports. Additionally, it addresses the concept of bit addressability for managing port operations.
Lecture 04 branch call and time delay
Lecture 04 branch call and time delayVajira Thambawita The document discusses various types of looping and branching instructions in the PIC microcontroller, specifically focusing on methods for implementing loops such as the 'decfsz' and 'bnz' instructions. It details unconditional branch instructions like 'goto' and 'bra', and describes the call and return mechanisms including stack usage. Additionally, it addresses factors affecting time delays in execution and the importance of instruction cycle time in the PIC 18 architecture.
Lecture 03 basics of pic
Lecture 03 basics of picVajira Thambawita The document provides an overview of the PIC18 microcontroller features, including its RISC architecture, memory types (ROM, RAM, EEPROM), and assembly language programming concepts. It details the use of registers like the WREG and the file register, instruction types, and assembler directives. Additionally, it discusses the program counter and performance enhancement methods for microprocessor design.
Lecture 02 mechatronics systems
Lecture 02 mechatronics systemsVajira Thambawita Mechatronics is the synergistic combination of mechanical, electrical, and computer engineering with an emphasis on integrated design. It has applications across many scales, from micro-electromechanical systems to large transportation systems like high-speed trains. Some key applications discussed in the document include CNC machining, automobiles using technologies like brake-by-wire, smart home appliances, prosthetics, pacemakers and defibrillators, unmanned aerial vehicles, and robots for space exploration, military, sanitation, and other uses. Mechatronics allows the development of advanced, integrated systems for improved performance, safety, efficiency and user experience.
Lecture 1 - Introduction to embedded system and Robotics
Lecture 1 - Introduction to embedded system and RoboticsVajira Thambawita The document outlines the PST 41203 Robotics course, detailing its content, credit hours, and evaluation methods, focusing on topics such as analog and digital circuits, microcontrollers, mechatronics, and automation. It explains embedded systems and programming, highlighting the significance and components of microcontrollers, particularly PIC microcontrollers. The course emphasizes the integration of mechanics, electronics, and software in mechatronics, offering hands-on experience with practical applications.
Lec 09 - Registers and Counters
Lec 09 - Registers and CountersVajira Thambawita Registers are groups of flip-flops that store binary information, while counters are a special type of register that sequences through a set of states. A register consists of flip-flops and gates, and can store multiple bits. Counters increment or decrement their state in response to clock pulses. There are two main types: ripple counters where flip-flops trigger each other, and synchronous counters where all flip-flops change on a clock pulse.
Lec 08 - DESIGN PROCEDURE
Lec 08 - DESIGN PROCEDUREVajira Thambawita The document outlines the design procedures for clocked sequential circuits, starting from specifications to creating logic diagrams. It emphasizes the importance of deriving state tables or diagrams and covers step-by-step processes including state reduction, binary assignment, and obtaining flip-flop input equations. Additionally, it provides examples and discusses excitation tables for different types of flip-flops used in circuit design.
Lec 07 - ANALYSIS OF CLOCKED SEQUENTIAL CIRCUITS
Lec 07 - ANALYSIS OF CLOCKED SEQUENTIAL CIRCUITSVajira Thambawita The document analyzes clocked sequential circuits, detailing their behavior through state equations, state tables, and state diagrams. It elucidates the processing of input equations for different types of flip-flops (D, JK, T) and outlines the Mealy and Moore models of finite state machines. Additionally, it discusses state reduction techniques to optimize circuit design by minimizing the number of flip-flops and states while maintaining output functionality.
Lec 06 - Synchronous Sequential Logic
Lec 06 - Synchronous Sequential LogicVajira Thambawita This document discusses synchronous and asynchronous sequential logic circuits, highlighting their importance in electronic devices for storing and processing binary information. It describes the architecture of synchronous sequential circuits, which use clock signals for synchronization, and explains the function and types of storage elements like flip-flops and latches. The document also emphasizes the distinction between these storage elements based on their sensitivity to signal transitions and levels.
Lec 05 - Combinational Logic
Lec 05 - Combinational LogicVajira Thambawita The document provides an overview of combinational logic circuits, explaining their characteristics, analysis, and design procedures. It discusses key concepts such as boolean functions, truth tables, and various components like binary adders, decoders, encoders, and multiplexers. Additionally, it emphasizes the importance of certain design considerations like carry propagation in adders and methods for code conversion.
Ad
Recently uploaded (20)
How to Configure Vendor Management in Lunch App of Odoo 18
How to Configure Vendor Management in Lunch App of Odoo 18Celine George The Vendor management in the Lunch app of Odoo 18 is the central hub for managing all aspects of the restaurants or caterers that provide food for your employees.
Analysis of Quantitative Data Parametric and non-parametric tests.pptx
Analysis of Quantitative Data Parametric and non-parametric tests.pptxShrutidhara2 This presentation covers the following points--
Parametric Tests
• Testing the Significance of the Difference between Means
• Analysis of Variance (ANOVA) - One way and Two way
• Analysis of Co-variance (One-way)
Non-Parametric Tests:
• Chi-Square test
• Sign test
• Median test
• Sum of Rank test
• Mann-Whitney U-test
Moreover, it includes a comparison of parametric and non-parametric tests, a comparison of one-way ANOVA, two-way ANOVA, and one-way ANCOVA.
LDMMIA GRAD Student Check-in Orientation Sampler
LDMMIA GRAD Student Check-in Orientation SamplerLDM & Mia eStudios Completed Tuesday June 10th.
An Orientation Sampler of 8 pages.
It helps to understand the text behind anything. This improves our performance and confidence.
Your training will be mixed media. Includes Rehab Intro and Meditation vods, all sold separately.
Editing our Vods & New Shop.
Retail under $30 per item. Store Fees will apply. Digital Should be low cost.
I am still editing the package. I wont be done until probably July? However; Orientation and Lecture 1 (Videos) will be available soon. Media will vary between PDF and Instruction Videos.
Thank you for attending our free workshops. Those can be used with any Reiki Yoga training package. Traditional Reiki does host rules and ethics. Its silent and within the JP Culture/Area/Training/Word of Mouth. It allows remote healing but there’s limits for practitioners and masters. We are not allowed to share certain secrets/tools. Some content is designed only for “Masters”. Some yoga are similar like the Kriya Yoga-Church (Vowed Lessons). We will review both Reiki and Yoga (Master symbols) later on. Sounds Simple but these things host Energy Power/Protection.
Imagine This package will be a supplement or upgrade for professional Reiki. You can create any style you need.
♥♥♥
•* ́ ̈ ̧.•
(Job) Tech for students: In short, high speed is essential. (Space, External Drives, virtual clouds)
Fast devices and desktops are important. Please upgrade your technology and office as needed and timely. - MIA J. Tech Dept (Timeless)
♥♥♥
•* ́ ̈ ̧.•
Copyright Disclaimer 2007-2025+: These lessons are not to be copied or revised without the
Author’s permission. These Lessons are designed Rev. Moore to instruct and guide students on the path to holistic health and wellness.
It’s about expanding your Nature Talents, gifts, even Favorite Hobbies.
♥♥♥
•* ́ ̈ ̧.•
First, Society is still stuck in the matrix. Many of the spiritual collective, say the matrix crashed. Its now collapsing. This means anything lower, darker realms, astral, and matrix are below 5D. 5D is thee trend. It’s our New Dimensional plane. However; this plane takes work ethic,
integration, and self discovery. ♥♥♥
•* ́ ̈ ̧.•
We don’t need to slave, mule, or work double shifts to fuse Reiki lol. It should blend naturally within our lifestyles. Same with Yoga. There’s no
need to use all the poses/asanas. For under a decade, my fav exercises are not asanas but Pilates. It’s all about Yoga-meditation when using Reiki. (Breaking old myths.)
Thank You for reading our Orientation Sampler. The Workshop is 14 pages on introduction. These are a joy and effortless to produce/make.
Sustainable Innovation with Immersive Learning
Sustainable Innovation with Immersive LearningLeonel Morgado Prof. Leonel and Prof. Dennis approached educational uses, practices, and strategies of using immersion as a lens to interpret, design, and planning educational activities in a sustainable way. Rather than one-off gimmicks, the intent is to enable instructors (and institutions) to be able to include them in their regular activities, including the ability to evaluate and redesign them.
Immersion as a phenomenon enables interpreting pedagogical activities in a learning-agnostic way: you take a stance on the learning theory to follow, and leverage immersion to envision and guide your practice.
Battle of Bookworms 2025 - U25 Literature Quiz by Pragya
Battle of Bookworms 2025 - U25 Literature Quiz by Pragya Pragya - UEM Kolkata Quiz Club Battle of Bookworms is a literature quiz organized by Pragya, UEM Kolkata, as part of their cultural fest Ecstasia. Curated by quizmasters Drisana Bhattacharyya, Argha Saha, and Aniket Adhikari, the quiz was a dynamic mix of classical literature, modern writing, mythology, regional texts, and experimental literary forms. It began with a 20-question prelim round where ‘star questions’ played a key tie-breaking role. The top 8 teams moved into advanced rounds, where they faced audio-visual challenges, pounce/bounce formats, immunity tokens, and theme-based risk-reward questions. From Orwell and Hemingway to Tagore and Sarala Das, the quiz traversed a global and Indian literary landscape. Unique rounds explored slipstream fiction, constrained writing, adaptations, and true crime literature. It included signature IDs, character identifications, and open-pounce selections. Questions were crafted to test contextual understanding, narrative knowledge, and authorial intent, making the quiz both intellectually rewarding and culturally rich. Battle of Bookworms proved literature quizzes can be insightful, creative, and deeply enjoyable for all.
GEOGRAPHY-Study Material [ Class 10th] .pdf
GEOGRAPHY-Study Material [ Class 10th] .pdfSHERAZ AHMAD LONE "Geography Study Material for Class 10th" provides a comprehensive and easy-to-understand resource for key topics like Resources & Development, Water Resources, Agriculture, Minerals & Energy, Manufacturing Industries, and Lifelines of the National Economy. Designed as per the latest NCERT/JKBOSE syllabus, it includes notes, maps, diagrams, and MODEL question Paper to help students excel in exams. Whether revising for exams or strengthening conceptual clarity, this material ensures effective learning and high scores. Perfect for last-minute revisions and structured study sessions.
Revista digital preescolar en transformación
Revista digital preescolar en transformaciónguerragallardo26 EVOLUCIÓN DEL CONTENIDO DE LA EVALUACIÓN DE LOS RECURSOS Y DE LA FORMACIÓN DE LOS DOCENTES
Vikas Bansal Himachal Pradesh: A Visionary Transforming Himachal’s Educationa...
Vikas Bansal Himachal Pradesh: A Visionary Transforming Himachal’s Educationa...Himalayan Group of Professional Institutions (HGPI) Himachal Pradesh’s beautiful hills have long faced a challenge: limited access to quality education and career opportunities for students in remote towns and villages. Many young people had to leave their homes in search of better learning and growth, creating a gap between talent and opportunity.
Vikas Bansal, a visionary leader, decided to change this by bringing education directly to the heart of the Himalayas. He founded the Himalayan Group of Professional Institutions, offering courses in engineering, management, pharmacy, law, and more. These institutions are more than just schools—they are centers of hope and transformation.
By introducing digital classrooms, smart labs, and practical workshops, Vikas ensures that students receive modern, high-quality education without needing to leave their hometowns. His skill development programs prepare youth for real-world careers by teaching technical and leadership skills, with strong industry partnerships and hands-on training.
Vikas also focuses on inclusivity, providing scholarships, career counseling, and support to underprivileged and first-generation learners. His quiet but impactful leadership is turning Himachal Pradesh into a knowledge hub, empowering a new generation to build a brighter future right in their own hills.
THERAPEUTIC COMMUNICATION included definition, characteristics, nurse patient...
THERAPEUTIC COMMUNICATION included definition, characteristics, nurse patient...parmarjuli1412 The document provides an overview of therapeutic communication, emphasizing its importance in nursing to address patient needs and establish effective relationships. THERAPEUTIC COMMUNICATION included some topics like introduction of COMMUNICATION, definition, types, process of communication, definition therapeutic communication, goal, techniques of therapeutic communication, non-therapeutic communication, few ways to improved therapeutic communication, characteristics of therapeutic communication, barrier of THERAPEUTIC RELATIONSHIP, introduction of interpersonal relationship, types of IPR, elements/ dynamics of IPR, introduction of therapeutic nurse patient relationship, definition, purpose, elements/characteristics , and phases of therapeutic communication, definition of Johari window, uses, what actually model represent and its areas, THERAPEUTIC IMPASSES and its management in 5th semester Bsc. nursing and 2nd GNM students
Capitol Doctoral Presentation -June 2025.pptx
Capitol Doctoral Presentation -June 2025.pptxCapitolTechU Slides from a Capitol Technology University presentation covering doctoral programs offered by the university. All programs are online, and regionally accredited. The presentation covers degree program details, tuition, financial aid and the application process.
Overview of Employee in Odoo 18 - Odoo Slides
Overview of Employee in Odoo 18 - Odoo SlidesCeline George The employee module is a core component of the HR workspace that helps the business to get the employee activities and details. This would also allow you to get the employee details by acting as a centralized system and accessing, updating, and managing all the other employee data.
Exploring Ocean Floor Features for Middle School
Exploring Ocean Floor Features for Middle SchoolMarie This 16 slide science reader is all about ocean floor features. It was made to use with middle school students.
You can download the PDF at thehomeschooldaily.com
Thanks! Marie
How to Manage Inventory Movement in Odoo 18 POS
How to Manage Inventory Movement in Odoo 18 POSCeline George Inventory management in the Odoo 18 Point of Sale system is tightly integrated with the inventory module, offering a solution to businesses to manage sales and stock in one united system.
LDMMIA Free Reiki Yoga S9 Grad Level Intuition II
LDMMIA Free Reiki Yoga S9 Grad Level Intuition IILDM & Mia eStudios Completed Sunday 6/8. For Weekend 6/14 & 15th. (Fathers Day Weekend US.) These workshops are also timeless for future students TY. No admissions needed.
A 9th FREE WORKSHOP
Reiki - Yoga
“Intuition-II, The Chakras”
Your Attendance is valued.
We hit over 5k views for Spring Workshops and Updates-TY.
Thank you for attending our workshops.
If you are new, do welcome.
Grad Students: I am planning a Reiki-Yoga Master Course (As a package). I’m Fusing both together.
This will include the foundation of each practice. Our Free Workshops can be used with any Reiki Yoga training package. Traditional Reiki does host rules and ethics. Its silent and within the JP Culture/Area/Training/Word of Mouth. It allows remote healing but there’s limits As practitioners and masters, we are not allowed to share certain secrets/tools. Some content is designed only for “Masters”. Some yoga are similar like the Kriya Yoga-Church (Vowed Lessons). We will review both Reiki and Yoga (Master tools) in the Course upcoming.
S9/This Week’s Focus:
* A continuation of Intuition-2 Development. We will review the Chakra System - Our temple. A misguided, misused situation lol. This will also serve Attunement later.
Thx for tuning in. Your time investment is valued. I do select topics related to our timeline and community. For those seeking upgrades or Reiki Levels. Stay tuned for our June packages. It’s for self employed/Practitioners/Coaches…
Review & Topics:
* Reiki Is Japanese Energy Healing used Globally.
* Yoga is over 5k years old from India. It hosts many styles, teacher versions, and it’s Mainstream now vs decades ago.
* Anything of the Holistic, Wellness Department can be fused together. My origins are Alternative, Complementary Medicine. In short, I call this ND. I am also a metaphysician. I learnt during the 90s New Age Era. I forget we just hit another wavy. It’s GenZ word of Mouth, their New Age Era. WHOA, History Repeats lol. We are fusing together.
* So, most of you have experienced your Spiritual Awakening. However; The journey wont be perfect. There will be some roller coaster events. The perks are: We are in a faster Spiritual Zone than the 90s. There’s more support and information available.
(See Presentation for all sections, THX AGAIN.)
Final Sketch Designs for poster production.pptx
Final Sketch Designs for poster production.pptxbobby205207 Final Sketch Designs for poster production.
BUSINESS QUIZ PRELIMS | QUIZ CLUB OF PSGCAS | 9 SEPTEMBER 2024
BUSINESS QUIZ PRELIMS | QUIZ CLUB OF PSGCAS | 9 SEPTEMBER 2024Quiz Club of PSG College of Arts & Science THE QUIZ CLUB OF PSGCAS BRINGS T0 YOU A FUN-FILLED, SEAT EDGE BUSINESS QUIZ
DIVE INTO THE PRELIMS OF BIZCOM 2024
QM: GOWTHAM S
BCom (2022-25)
THE QUIZ CLUB OF PSGCAS
How to Manage Multi Language for Invoice in Odoo 18
How to Manage Multi Language for Invoice in Odoo 18Celine George Odoo supports multi-language functionality for invoices, allowing you to generate invoices in your customers’ preferred languages. Multi-language support for invoices is crucial for businesses operating in global markets or dealing with customers from different linguistic backgrounds.
Webcrawler_Mule_AIChain_MuleSoft_Meetup_Hyderabad
Webcrawler_Mule_AIChain_MuleSoft_Meetup_HyderabadVeera Pallapu 1. MuleSoft AI Chain Concept Introduction
2. Demo on Mule AI Chain Connector
3. Q/A
4. Wrap up
Vikas Bansal Himachal Pradesh: A Visionary Transforming Himachal’s Educationa...
Vikas Bansal Himachal Pradesh: A Visionary Transforming Himachal’s Educationa...Himalayan Group of Professional Institutions (HGPI)
BUSINESS QUIZ PRELIMS | QUIZ CLUB OF PSGCAS | 9 SEPTEMBER 2024
BUSINESS QUIZ PRELIMS | QUIZ CLUB OF PSGCAS | 9 SEPTEMBER 2024Quiz Club of PSG College of Arts & Science
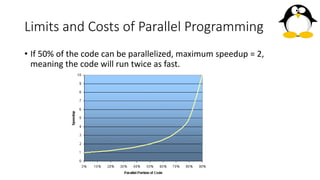
Lecture 1 introduction to parallel and distributed computing
- 1. Parallel and Distributed Computing CST342-3 Vajira Thambawita
- 2. Learning Outcomes At the end of the course, the students will be able to • - define Parallel Algorithms • - recognize parallel speedup and performance analysis • - identify task decomposition techniques • - perform Parallel Programming • - apply acceleration strategies for algorithms
- 3. Contents • Sequential Computing, History of Parallel Computation, Flynn’s Taxonomy, Process, threads, Pipeline, parallel models, Shared Memory UMA,NUMA, CCUMA, Ring ,Mesh , Hypercube topologies, Cost and Complexity analysis of the interconnection networks, Task Partition , Data Decomposition, Task Mapping, Tasks and Decomposition , Processes and Mapping ,Processes Versus Processors, Granularity, processing, elements, Speedup , Efficiency , overhead, Practical ,Introduction to Pthered library, CUDA program , MPICH, Introduction to Distributed Computing, Centralized System , Comparison , mini Computer ,Workstation models, Process pool , analysis, Distributed OS, Remote procedure call ,RPC, Sun RPC, Distributed Resource Management, Fault Tolerance
- 4. References • Ananth,G, Anshul,G, Karypis,G and Kumar,V, 2003, Introduction to Parallel Computing , 2nd Edition , Addison Wesley Optional References: • CUDA Toolkit Documentation • Introduction to Parallel Computing, Second Edition By Ananth Grama, Anshul Gupta, George Karypis, Vipin Kumar • Programming on Parallel Machines, Norm Matloff • Introduction to High Performance Computing for Scientists and Engineers, Georg Hager, Gerhard Wellein
- 5. Evaluation • Continuous Assessment: • 60% - Lab assignments, Tutorials, Quizzes, • End Semester Examination: • 40% - 2hrs or 3hrs paper
- 6. Knowledge • Data structures and algorithms • C programming
- 8. Four decades of computing • Batch Era • Time sharing Era • Desktop Era • Network Era
- 9. Batch era • Batch processing • Is execution of a series of programs on a computer without manual intervention • The term originated in the days when users entered programs on punch cards
- 10. Time-sharing Era • time-sharing is the sharing of a computing resource among many users by means of multiprogramming and multi-tasking • Developing a system that supported multiple users at the same time
- 11. Desktop Era • Personal Computers (PCs) • With WAN
- 12. Network Era • Systems with: • Shared memory • Distributed memory • Example for parallel computers: Intel iPSC, nCUBE
- 13. FLYNN's taxonomy of computer architecture Two types of information flow into processor: Instructions Data what are instructions and data?
- 14. FLYNN's taxonomy of computer architecture 1. single-instruction single-data streams (SISD) 2. single-instruction multiple-data streams (SIMD) 3. multiple-instruction single-data streams (MISD) 4. multiple-instruction multiple-data streams (MIMD)
- 17. Parallel Computers • all stand-alone computers today are parallel from a hardware perspective
- 18. Parallel Computers • Networks connect multiple stand-alone computers (nodes) to make larger parallel computer clusters.
- 19. Why Use Parallel Computing? • SAVE TIME AND/OR MONEY:
- 20. Why Use Parallel Computing? • SOLVE LARGER / MORE COMPLEX PROBLEMS Grand Challenge Problems ?
- 21. Why Use Parallel Computing? • PROVIDE CONCURRENCY
- 22. Why Use Parallel Computing? • TAKE ADVANTAGE OF NON-LOCAL RESOURCES:
- 23. Why Use Parallel Computing? • MAKE BETTER USE OF UNDERLYING PARALLEL HARDWARE • Modern computers, even laptops, are parallel in architecture with multiple processors/cores
- 24. BACK to Flynn's Classical Taxonomy
- 25. Single Instruction Single Data (SISD) • A serial (non-parallel) computer • This is the oldest type of computer UNIVAC1 IBM 360 CRAY1 CDC 7600 PDP1
- 26. Single Instruction Multiple Data (SIMD) ILLIAC IV MasPar Cray X-MP Cray Y-MP Cell Processor (GPU)
- 27. Multiple Instruction Single Data The Space Shuttle flight control computers
- 28. Multiple Instruction Multiple Data (MIMD) IBM POWER5 HP/Compaq Alphaserver Intel IA32 AMD Opteron
- 29. What are we going to learn?
- 30. Shared Memory System • A shared memory system typically accomplishes interprocessor coordination through a global memory shared by all processors. • Ex: Server systems, GPGPU
- 31. Message Passing System (Distributed Memory) • This kind of systems typically combine the local memory and processor at each node of the interconnection network • There is no global memory • Use message passing technique to move data from one local memory to another
- 32. Limits and Costs of Parallel Programming • Amdahl's Law: Amdahl's Law states that potential program speedup is defined by the fraction of code (P) that can be parallelized: 𝑆𝑝𝑒𝑒𝑑𝑢𝑝 = 1 1 − 𝑝 • If none of the code can be parallelized, P = 0 and the speedup = 1 (no speedup). • If all of the code is parallelized, P = 1 and the speedup is infinite (in theory).
- 33. Limits and Costs of Parallel Programming • If 50% of the code can be parallelized, maximum speedup = 2, meaning the code will run twice as fast.
- 34. Limits and Costs of Parallel Programming • Introducing the number of processors performing the parallel fraction of work, the relationship can be modeled by: 𝑠𝑝𝑒𝑒𝑑𝑢𝑝 = 1 𝑃 𝑁 + 𝑆 • where P = parallel fraction, N = number of processors and S = serial fraction
- 35. Limits and Costs of Parallel Programming
- 36. Next • Parallel Computer Memory Architectures