Pandas data transformational data structure patterns and challenges final
Download as PPTX, PDF0 likes189 views

The document presents a comprehensive overview of data transformational patterns and the usage of Python's numpy and pandas libraries, emphasizing their differences and functional optimization patterns. It discusses the importance of efficient data structures for handling large datasets, real-time data changes, and the limitations and challenges faced in current practices. Key topics include memory management, indexing, time series analysis, and future considerations for big data analytics.





![NumPy Data Structures - ndarrayNdarrays - Data Transformation Optimizations
PyArrayObect
typedef struct PyArrayObject {
PyObject_HEAD
char *data;
int nd;
npy_intp *dimensions;
npy_intp *strides;
PyObject *base;
PyArray_Descr *descr;
int flags;
PyObject *weakreflist;
} PyArrayObject;
>>> import numpy as np
>>> matx = np.arange(15)
>>> id(matx)
139892166884368
>>> mat3x5 = matx.reshape(3,5)
>>> id(mat3x5)
139892020117712
>>> matx
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
10, 11, 12, 13, 14])
>>> mat3x5
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> matx[4] = 100
>>> matx
array([ 0, 1, 2, 3, 100, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14])
>>> mat3x5
array([[ 0, 1, 2, 3, 100],
[ 5, 6, 7, 8, 9],
[ 10, 11, 12, 13, 14]])
>>> _
Dim:2
strides:(40,8)
shape:(3,5)
reshape
Ndarray 1:
matx
Ndarray 2:
mat3x5
Dim:1
strides:(8,)
shape:(15,)
DATA](https://image.slidesharecdn.com/pandas-datatransformationaldatastructurepatternsandchallengesfinal-180908044625/85/Pandas-data-transformational-data-structure-patterns-and-challenges-final-7-320.jpg)





![Pandas - Time Series - C02 Emissions in India (1858- 2014)Time Series Example
>>> import numpy as np
>>> import pandas as pd
>>> import matplotlib.pyplot as plt
>>> dateparse = lambda dates:
pd.datetime.strptime(dates, '%Y')
>>> co2emission =
pd.read_table('inco2.csv',delimiter=',',header='infer',
parse_dates=True,
index_col='Year',date_parser=dateparse)
>>> co2emission.plot()
<matplotlib.axes.AxesSubplot object at
0x7fd79d20bcd0>
>>> plt.show()
>>> co2solidemission = co2emission['Solid']
>>> co2solidemission.plot()
<matplotlib.axes.AxesSubplot object at
0x7fd79be3bf50>
>>> plt.show()
>>> co2solidemission.mean()
50129.979310344825](https://image.slidesharecdn.com/pandas-datatransformationaldatastructurepatternsandchallengesfinal-180908044625/85/Pandas-data-transformational-data-structure-patterns-and-challenges-final-13-320.jpg)




Pandas data transformational data structure patterns and challenges final
- 1. Pandas - Data Transformational Data Structure Patterns and Challenges Rajesh Manickadas OrangeScape 07 Sept 2018
- 2. Objective The Objective of this Presentation is to elaborate on Numpy/Pandas and more in the following light ● Differentiate python data structures and numpy/pandas ● What is Data Transformational Design Patterns ? ● Numpy / Pandas Data Structures and Usage ● Contemplate on Such Patterns for Future PROGRAM = DATA STRUCTURES + ALGORITHMS
- 3. Python Data Structures - Primer A Refresher to Python Data Structures Tuples Immutable Containers Lists Mutable Containers Dict Key Indexed Containers
- 4. Python Data Structures - Functional Optimization Patterns The Prime Objective is to optimize the data structures for functional programming Scalars are Python Objects designed with functional optimization patterns. >>> a = 45 >>> b = 45 >>> id(a) 16790784 >>> id(b) 16790784 A B 45 16790784 List and Lists and List of Lists and List of List of Lists….Arrays ? Good for Functional Work and Not Designed for Large Data Processing Examples: Transpose, Slicing, Pivoting, Vectorization
- 5. Data Transformational Design Pattern Needs ● Data is Memory. Large Data is Huge Memory. Memory is Expensive ! ● Data in Real Time changes all the time. It's not a csv :). - Speed ! ○ Data Warehouses Vs Databases Vs Pandas ● We try to move from the Functional arena to a Data arena - Data Structures are to be designed for Data Processing Algorithms ○ Data Needs are Dimensions, Measurable, Searchable, Visualize, Views etc. ● The World of Big Table, Bigquery, Hadoop et al is mixed up with Offline Data, Slow Processing (Design Needs), Append only, Queryless ● It's just not scientific. Its Business !! ○ Realtime Vs Offline/Batch ○ Reporting and Intelligence Vs Analysis and Research ○ Simple Lookups are going to be tricky in future Exodus from Functional Program Optimization to Data Transformation Optimization
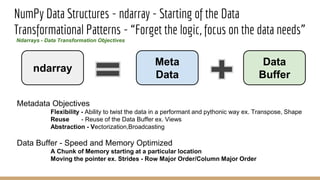
- 6. ndarray NumPy Data Structures - ndarray - Starting of the Data Transformational Patterns - “Forget the logic, focus on the data needs” Ndarrays - Data Transformation Objectives Meta Data Data Buffer Metadata Objectives Flexibility - Ability to twist the data in a performant and pythonic way ex. Transpose, Shape Reuse - Reuse of the Data Buffer ex. Views Abstraction - Vectorization,Broadcasting Data Buffer - Speed and Memory Optimized A Chunk of Memory starting at a particular location Moving the pointer ex. Strides - Row Major Order/Column Major Order
- 7. NumPy Data Structures - ndarrayNdarrays - Data Transformation Optimizations PyArrayObect typedef struct PyArrayObject { PyObject_HEAD char *data; int nd; npy_intp *dimensions; npy_intp *strides; PyObject *base; PyArray_Descr *descr; int flags; PyObject *weakreflist; } PyArrayObject; >>> import numpy as np >>> matx = np.arange(15) >>> id(matx) 139892166884368 >>> mat3x5 = matx.reshape(3,5) >>> id(mat3x5) 139892020117712 >>> matx array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]) >>> mat3x5 array([[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14]]) >>> matx[4] = 100 >>> matx array([ 0, 1, 2, 3, 100, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]) >>> mat3x5 array([[ 0, 1, 2, 3, 100], [ 5, 6, 7, 8, 9], [ 10, 11, 12, 13, 14]]) >>> _ Dim:2 strides:(40,8) shape:(3,5) reshape Ndarray 1: matx Ndarray 2: mat3x5 Dim:1 strides:(8,) shape:(15,) DATA
- 8. NumPy Data Structures - More Concepts The More you know, The More you apply the Data Transformational Patterns for Optimizations (to reduce memory footprints, improve execution speed etc). It is a Swiss Army Knife Broadcasting N-D Iterators Indexing Scalar Types Routines Shapes and Views
- 9. Pandas - Where Python Meets the Tables(Databases) For what people see is what they manipulate Series (1n) DataFrame (2n) Panels (3n) Tables DataFrame Data Indexing Set Algebra Immutable Ordered Set Hash/Dict Joins Unions Filters Intersections
- 10. Pandas Data Structures- Differentiating from Databases/SQL Pandas take on Data ● Select and Filters - Shaping and Slicing ● Joins - Joins, Merge, Concat ● Aggregation and Operations - Vectorization, Broadcasting ● Advanced/Dynamic Aggregation ○ Dimensions and Measures Patterns ■ Pivots ● Close Collaboration between the data structure and algorithms ○ Statistical Functions ○ Scientific Functions ○ Machine Learning etc. ○ SciPy
- 11. Block Manager - There enters the manager !!!The Manager Data Transformational Pattern, If you want to call it “Under the hood” or “Internals” I am fine with it
- 12. Pandas - Indexing a DataFrame Indexing Organization Year Total Gas Liquid Solid 1997 250255 12561 66649 159191 1998 255310 12990 71750 158106 1999 271548 11549 77852 169087 2000 281389 11974 82834 172812 ... Label Index DateTime Index Data Array, ordered, immutable, hashtable,int64 Array, ordered, immutable, hashtable, timestamp Ndarray data dype Index (axis) columns
- 13. Pandas - Time Series - C02 Emissions in India (1858- 2014)Time Series Example >>> import numpy as np >>> import pandas as pd >>> import matplotlib.pyplot as plt >>> dateparse = lambda dates: pd.datetime.strptime(dates, '%Y') >>> co2emission = pd.read_table('inco2.csv',delimiter=',',header='infer', parse_dates=True, index_col='Year',date_parser=dateparse) >>> co2emission.plot() <matplotlib.axes.AxesSubplot object at 0x7fd79d20bcd0> >>> plt.show() >>> co2solidemission = co2emission['Solid'] >>> co2solidemission.plot() <matplotlib.axes.AxesSubplot object at 0x7fd79be3bf50> >>> plt.show() >>> co2solidemission.mean() 50129.979310344825
- 14. Data Transformational Patterns - Where Pandas Fits Courtesy:Dremio
- 15. Challenges “Nowadays, my rule of thumb for pandas is that you should have 5 to 10 times as much RAM as the size of your dataset. So if you have a 10 GB dataset, you should really have about 64, preferably 128 GB of RAM if you want to avoid memory management problems.” - Wes McKinney BDFL, Pandas “10 Things I hate about Pandas” 1. Internals too far from "the metal" 2. No support for memory-mapped datasets 3. Poor performance in database and file ingest / export 4. Warty missing data support 5. Lack of transparency into memory use, RAM management 6. Weak support for categorical data 7. Complex groupby operations awkward and slow 8. Appending data to a DataFrame tedious and very costly 9. Limited, non-extensible type metadata 10. Eager evaluation model, no query planning 11. "Slow", limited multicore algorithms for large datasets - Wes McKinney BDFL, Pandas
- 16. Contemplate on Design Patterns for Realtime Analytics and Big Data ● In-Memory Sessions ● Distributed processing ● Realtime Data Collaboration, Unified Datastores ○ Portable Data Frames - Apache Sparrow ● Strings - Data Management ● Performance - Numba, PyPy ● Snapshots and Visualizations What can future be...
- 17. Thank You Q & A
Editor's Notes
- #3: Good Morning. We are going to objectively see why numpy and pandas in a plethora of Big data tools and how to harness them. Fundamentally functional programs have to be rewired to solve data transformation work, as they were not designed for it.
- #4: Python lists and Numpy array lists difference
- #5: Optimization of Memory for functions, data is tightly associated with functions/classes. They are titlly coupled. Think of Pivot, Transformation, Inserts, Views Functional Programming aims at solving functions. Functions are Mathematical, Expressions, Polynomials, Identities, Equations so on and so forth. Softwares are memory driven and they are limited. Hence Arrays, especially dynamic typed and size not mentioned are super bad for functional programmers to design so they transfer the problem to the developers or give us something cheap called Lists, which is super efficient. I call the “Marginal/Practical Optimizations” exists in programming languages like python stores the first 500 or 5000 as constants.. Everything is a reference to it. Non Metadata based model. No Items
- #6: Large Data is like a Titanic Ship, You can either move it like a Sukhoi fighter nor can you create one all the time ! Data Structures designed for Functional programs are incapable of handling them. Neither are the Numpy, Pandas and so forth. SQL is pythonic Amen. We are in the world of cloud and look at the memory cost and machines of higher grades. We run 300+ AWS Instances and 4000+ Google Instances for large volume of customers. Where t1.small to a t1.medium is huge. Data warehousing folks knows it all, no secret trick it's all dimension and measure
- #7: That's the starting of the Data Transformation Patterns. It all started with Numpy. Forget the logic, Focus on the data. Data Transformation is quite easy. It's only manipulating the real data, then why change the data (copy) but rather change only the metadata/meaning. There is no point to write for loops or create new in memory objects, do housekeeping so on and so forth
- #8: Reshaping or applying a Data Transformational Pattern. Explain the Metadata and the Data is just a pointer. Speak something on the Algorithmic optimization, precompiled c code etc.
- #9: It's a Swiss Army Knife.
- #10: R, r2py, SQL are leveraged for the first time. Now what we know are all data transformation patterns from the simple relational algebra to indexing to
- #11: Int64Index, Float64Index,MultiIndex,DateTimeIndex,TimedeltaIndex,PeriodIndex. You are trying to create a mini
- #12: The Problems are on the table. Ndarray are fast than Pandas yes they are !!! (don't talk the obvious). Its complex data management (data buffer). It deals with Strings. It uses multiple performance optimizations. It's only by long working and expertise you can do it with the simple concate and append. It
- #13: R, r2py, SQL ,
- #14: Int64Index, Float64Index,MultiIndex,DateTimeIndex,TimedeltaIndex,PeriodIndex
- #17: R, r2py, SQL ,
- #18: R, r2py, SQL ,